SSD Internals
上一篇文章( https://blog.mwish.me/2026/05/18/Storage-Interfaces/ )计划介绍一些 SSD 知识,但是因为 copy 比较多,也没好意思把文章写的比较长。这里在这篇文章介绍一下一些从各处抄来的 SSD 细节。这里需要说明的是,本文比较多内容来自于 <深入浅出SSD 第二版> 作为读书笔记,感觉国内能出这种写的比较细的书还是比较厉害的,笔者还买了实体书支持。我们 Bottom up 的简单分析一下,我只发我看得懂的东西,我如果看不懂,就会尽量简单的去写这部分内容。
SSD 是如何存储数据的
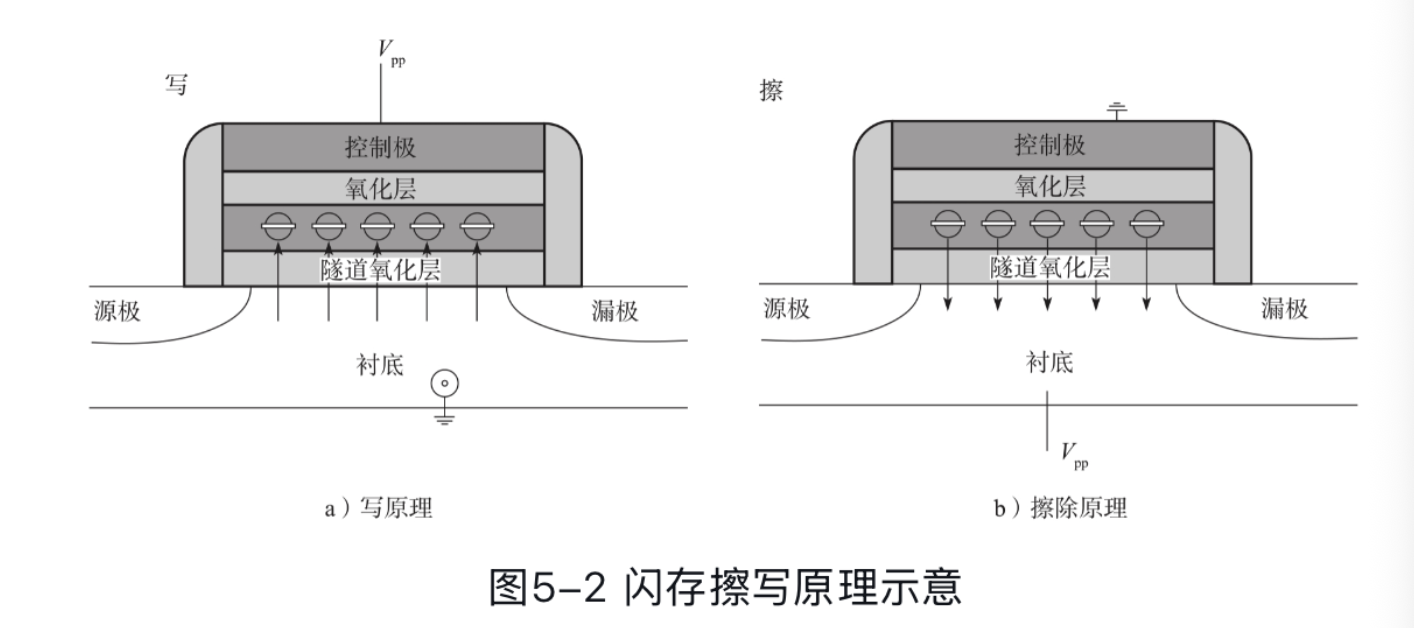
我们会有下面的 2D NAND 芯片,存储电子代表 0,不存储则代表 1。擦除即加压吸出所有的电子。那么这里有几个点:
- 看下面的图,这里外部可以通过加一个不到擦写电压的(小一点的)电压,来判断这里通不通,看里面有无存储电子
- 因为即使关掉电源,电子仍然会被「夹」在里面,所以它是 non-volatile 的
- 一大组元素共享一个衬底,所以写是一起写的,擦也是一起擦的。
- 擦写过多之后,隧道氧化层会有损伤,所以 SSD 也是有对应的寿命的。
- 当然,如果长期关电源,电子可能会一点点漏掉,这里 SSD 可能还是需要开机,然后靠一些行为来重新写入别的地方,之后可能讲 FTL 的时候会介绍这里
- 因为读会需要电压,这里可能会造成读干扰,随着闪存块读的次数越来越多,越来越多电子进入浮栅晶体管,最终可能导致位翻转(由1翻转成0)。
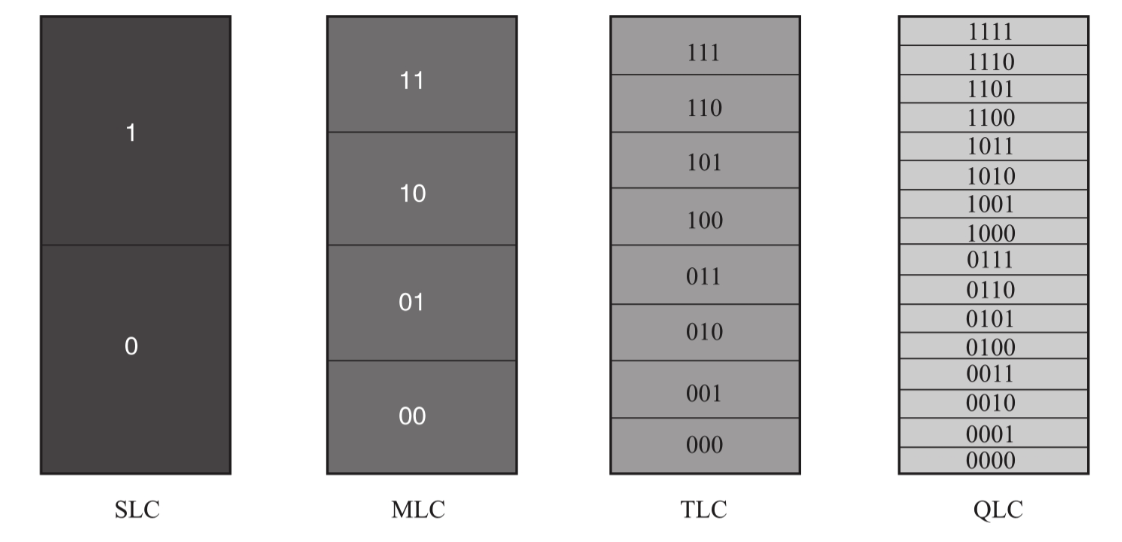
我们说到 QLC 之类的可能会相对复杂一点,不考虑上面的主控之类的因素,也是因为它可能要考虑更多状态。现在主流可能是 TLC,然后大容量在推 QLC 之类的产品。它们能存储更多的状态(更大的容量),读、GC 之类的也会更复杂。
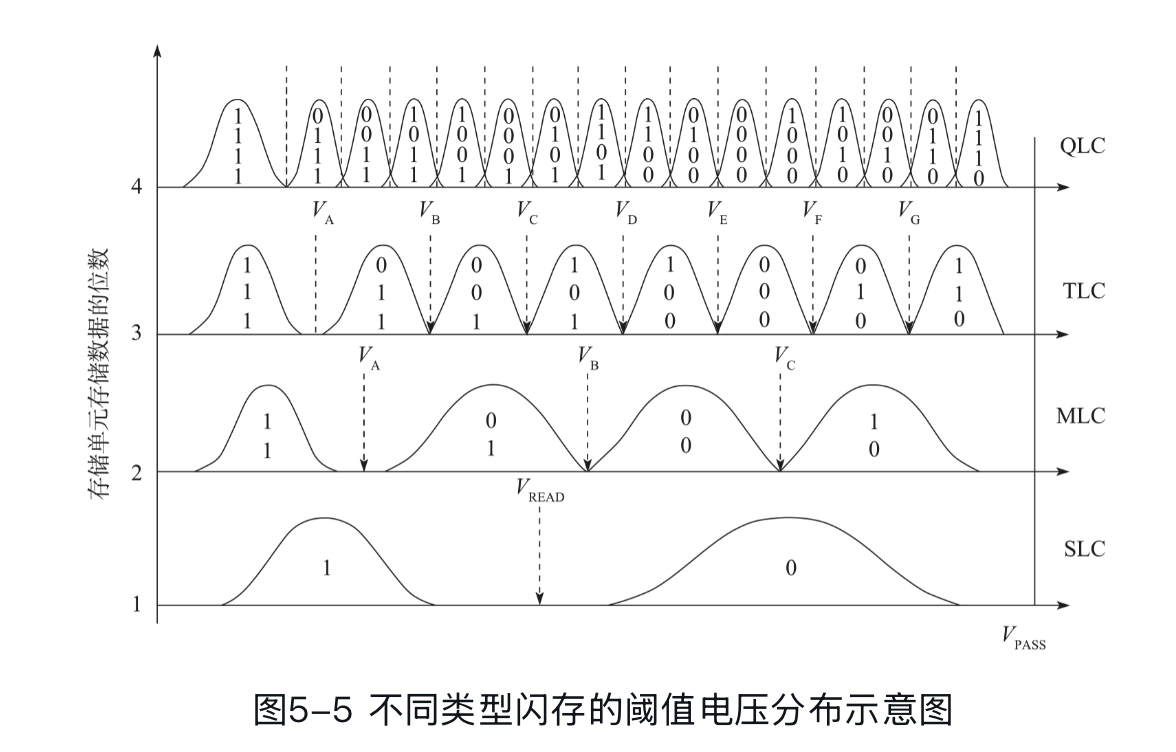
下面是 SSD 的逻辑的结构:
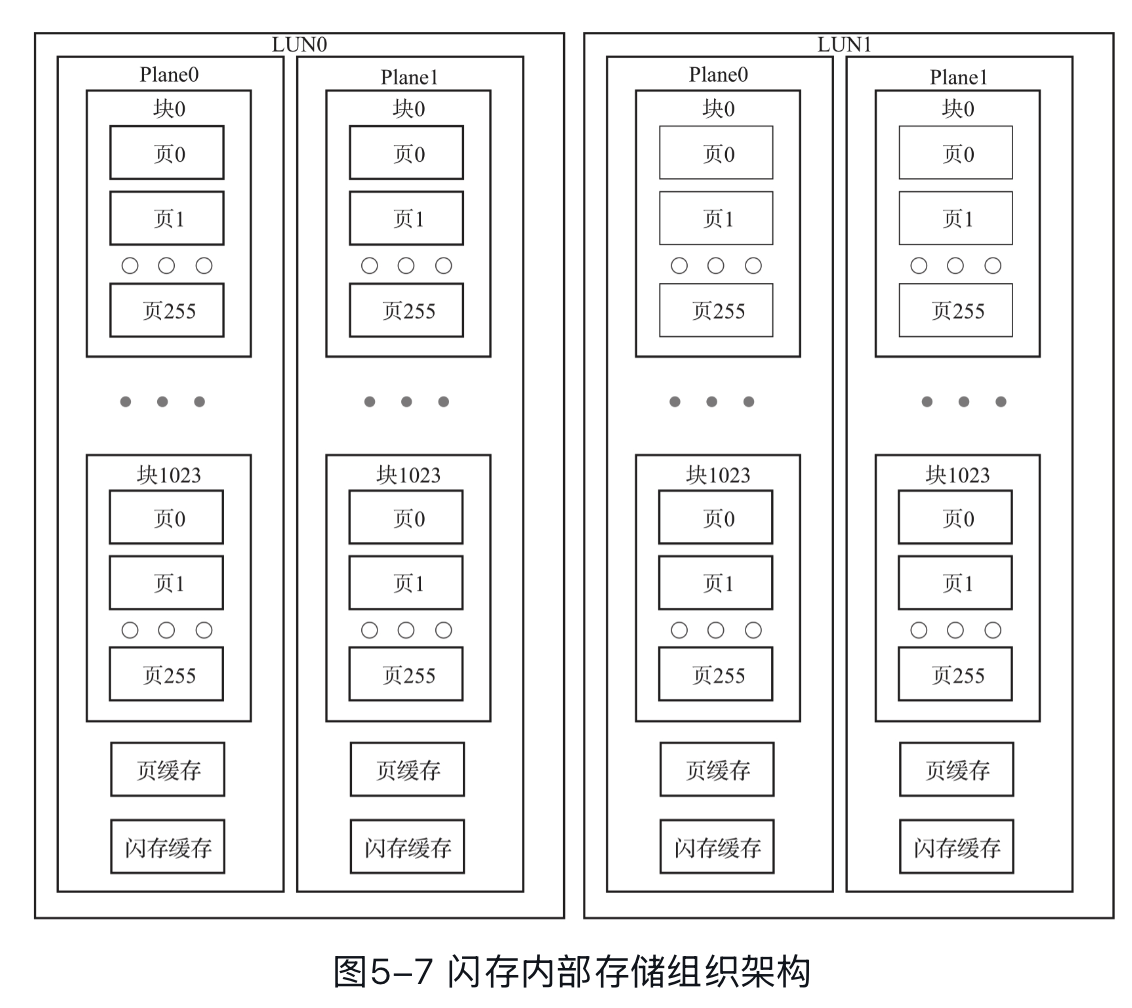
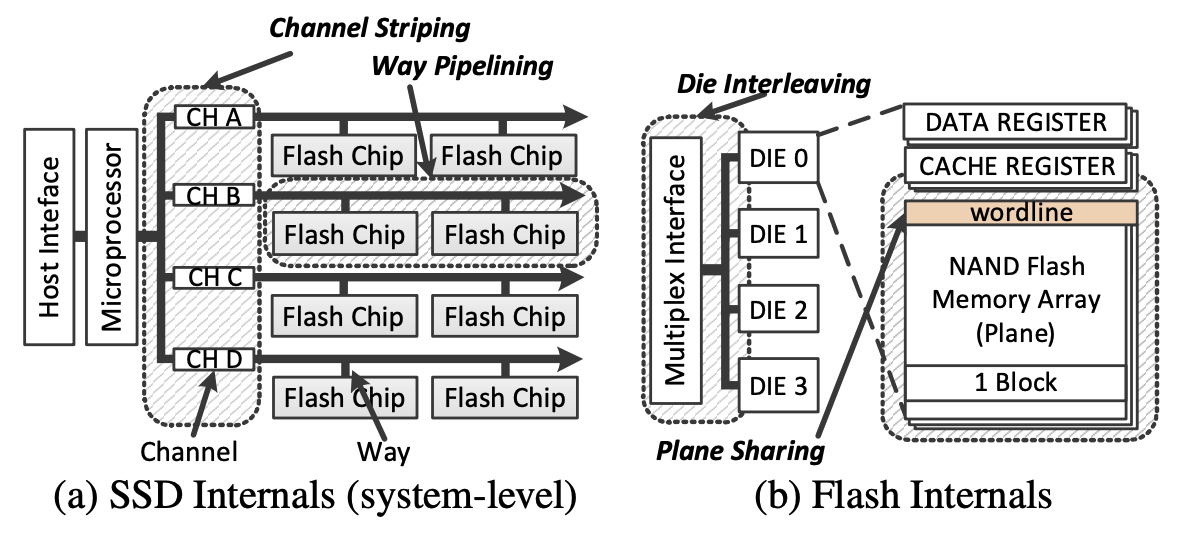
现在 SSD 的 Die 大小从 256Gib, 512Gib 现在到了 1Tib,2Tib 了。比较早的时候,一个 Die 内的操作是串行的,后来大家可以 multi-plane 执行一些相同的操作,来做到 Die 内 Plane 级别的并行,也有一些新的技术,力图让各Plane独立启动和完成读取,从而提升随机读性能。一个Die的Plane越多,多Plane操作并发度越高,闪存读写性能越好。比如前几年,一般企业级SSD内部有8~16个数据通道,每个通道内部有4~16个并行逻辑单元(一般一个通道挂多个 Die/LUN,每个 Die 内部又有个 Plane),那么这里可以乘法起来当做这个可以并行的命令数。
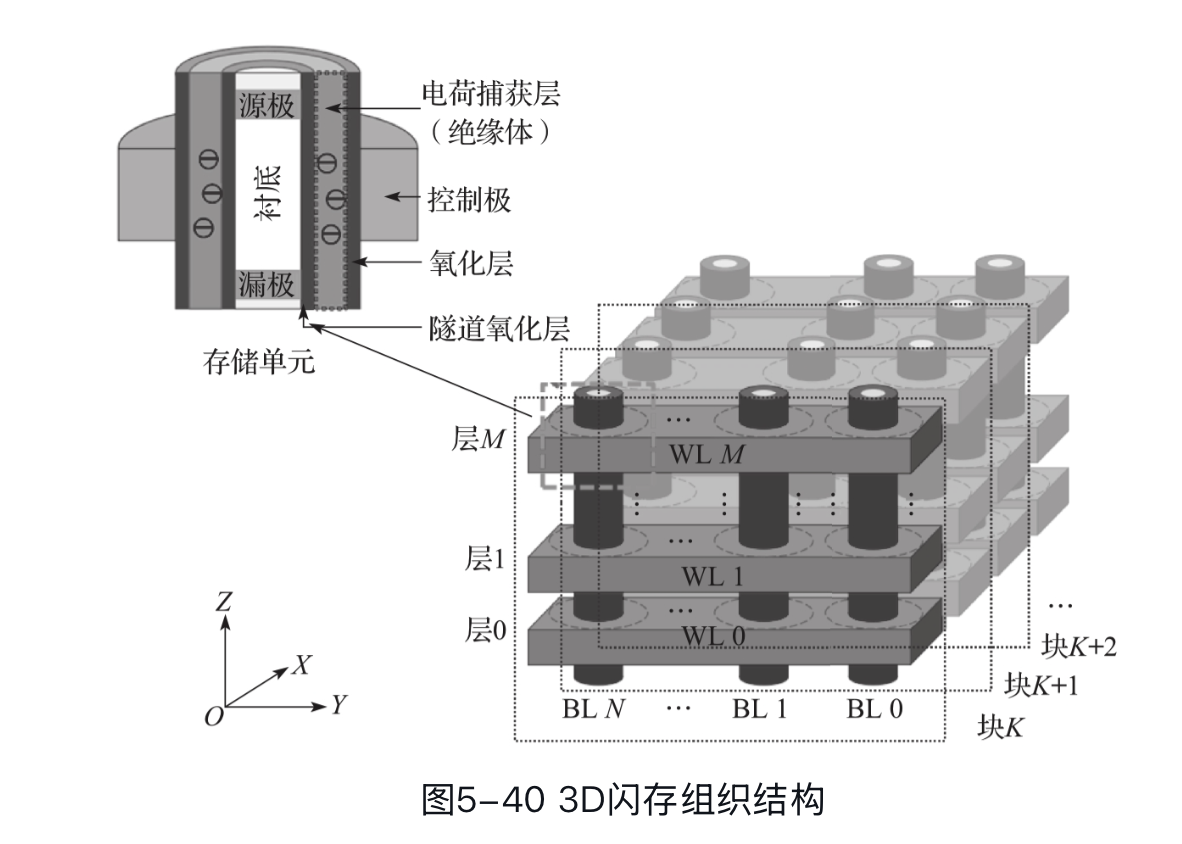
这里还有 3D NAND 堆叠的新方向,但我没咋看懂,就不发了
FTL
基础
这里解决的问题是(我都是抄的,反正大家都懂,前文很多地方也解释了为什么):
- 闪存块需先擦除才能写入,不能覆盖写,也不能重复写。因此,SSD的固件需要维护一张逻辑地址到物理地址的映射表,以跟踪每个逻辑块最新数据存储在闪存中的位置。往一个新的位置写入数据,会导致老位置上的数据变成无效,这些数据就成为垃圾数据了。
- 闪存块都是有一定寿命的。FTL需要做磨损均衡(Wear Leveling),让数据的写入尽量均摊到SSD中的每个闪存块上,即让每个块磨损都差不多,从而保证SSD具有最大的数据写入量。
- 存在读干扰问题/坏块/数据保持问题,需要刷新、管理
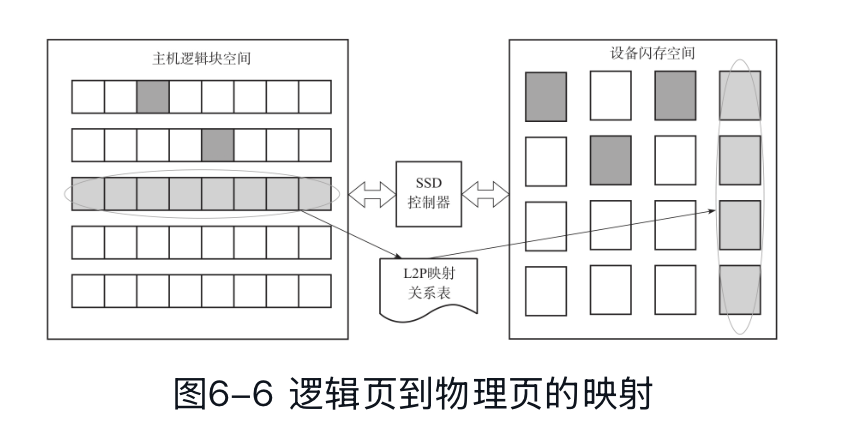
这里(如同我们在外面做 Database Page 存储),会需要一个映射表。SSD 上的 L2P 映射关系表。这里会有个 Logical Page <-> Physical Page 的关系:
- LBA 是主机访问存储设备的逻辑扇区地址,每个 LBA 对应一个逻辑扇区(传统 512B,现在很多是 4KiB)。另外「Logical Page」这个术语一般指 FTL 映射表中的映射粒度,通常是多个 LBA 组成一个 Logical Page(如 4K 或 16K)
- 主控以闪存页为基本单元读写闪存,这被称为 Physical Page。(实际上一般 Physical Page 对应多个 Logical Page,它大小可能会大一些,比如 16KiB,这也可以减少 Mapping 的大小,类似页表)
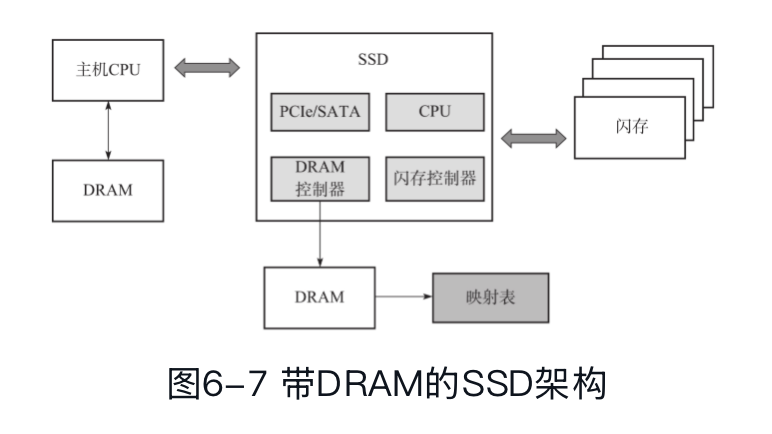
我们在外面做 Key-value storage 的时候,这种表(类似 LLAMA 的 Mapping Table)可能也类似,但是它那种表需要定期 Dump + WAL 之类的方式来恢复。在SSD掉电前,需要把映射表写入闪存中。下次上电初始化时,需要把它从闪存中全部或者部分加载到SSD的缓存(DRAM或者SRAM)中。企业级的SSD一般都带有电容。带电容的SSD,还配有异常掉电处理模块,因为电容不能绝对保证SSD在掉电前把所有的信息刷入闪存。此外,这里也可以扫描 SSD 来恢复映射表。
企业级 SSD 和中高端消费级都会把映射表尝试放在 DRAM 里,但入门消费级是没有这些设计的
GC 、写放大和盘的寿命
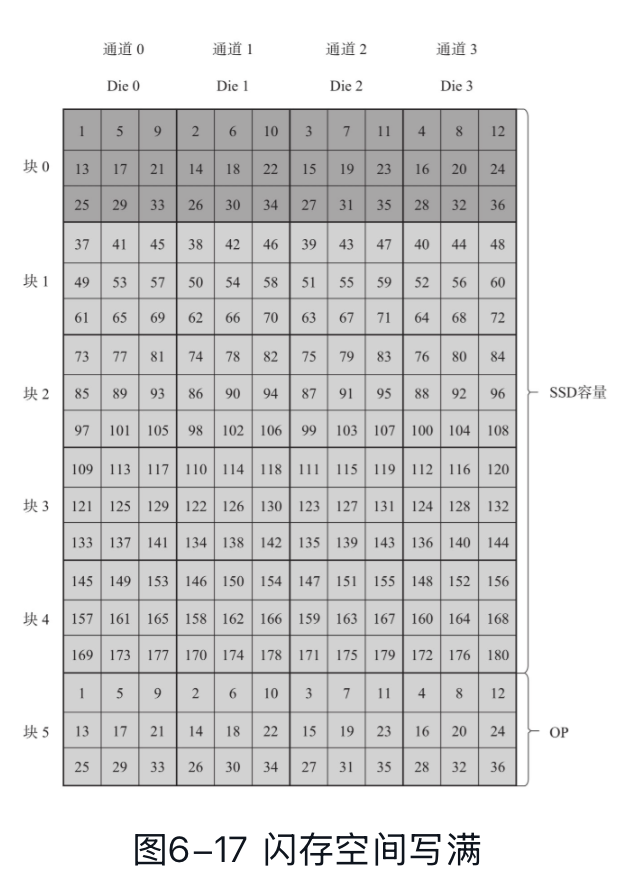
这节作为 FTL 的一小节,我们来介绍一下 SSD 的 GC。很早以前我们就知道 SSD 有 GC 的概念,但它究竟是什么呢?OP 空间怎么配置又代表什么呢?这里其实非常简单,我们可以看看下图:
- 这个地方你会发现 OP 和用户空间都写满了。我们知道系统的 OP 是「用户逻辑空间不会有的空间」,比方说,我们盘是 8T,配了 256G 的 OP,那么可能我们挂载块设备
lsblk会发现这个设备就是 8T,丝毫不提那 256GiB 的空间。这些空间会被 SSD 用来腾挪数据…?你会发现诶不对,我的用户数据无论如何都会写到这上面吧!某种意义上这也是正常 SSD 的空间,只是你用户没法写这些空间 - 这个地方 GC 意味着,用户的正常的对 LBA 的覆盖写(比如文件系统拿着块设备,然后 fs 去写块设备的 6T offset 对应的 16KiB),如果盘比较满,这里会导致 SSD 多进行一些些写入。这里我们可以认为
NAND 写入 / 用户前台写入等于这个写放大。- 这里我们也能推导出来,这里盘(如果用的比较满),在开始写的时候 LBA 不会写满,这里写放大在第一轮写满之前都是 1(即写入比1,表示没有任何额外写放大),随着越写越多,可能需要更多的空间腾挪出来,写放大开始增大
- OP 大为什么能降低写放大?我们(暂且)假设用户的写入是均匀的,那么每个 Block 有效数据比例会是一个
用户写过 LBA ``/ ``(系统 OP + 用户写过 LBA + 用户没写过 LBA), 如果 OP 大,Block 里面空闲就会很多,要腾挪出一定空间就可以移除尽量少的数据块。- 我们根据这里有两个发现,一个是用户写入可以不均匀,如果整个 Block 上的数据都是垃圾数据或者一起被 GC 的话,这里哪怕你 OP 配置很小,只要 GC Block 完全对齐(或者相对对齐),写放大也能变小。这篇 TUM 论文( https://arxiv.org/abs/2603.09927 )就有类似的思路。不过随着 SSD 各种块变大,Block 大小其实也蛮大的,老实说你要攒到这个大小也不容易,另外用户顺序写也不代表 SSD 是完全完全顺序的写入。不过我们可以肯定,某种意义上 SSD 顺序写写放大大概率是比随机写小的。
- 这里式子还有个
用户没写过 LBA, 实际上你如果盘只用 75% 空间,剩下那 25% 也类似 OP 的功能,可以减少一定的写放大。
- 垃圾回收不是没有空间了才回收,这里可能类似 Linux 回收 swap 内存之类的,有对应的水位。当然这个也看 SSD 主控的实现。实现上,GC 也会搬运数据,所以可能一个是写放大,第二个是会跟前台用户写入(甚至读取)抢占一些资源,视主控之类的实现可能会影响性能。
- 用户删除文件时,系统需要发出一些特殊命令来及时告诉SSD哪些数据已经不需要了。在SSD主机协议中有相应的命令来支持该功能,比如ATA中的Data SetManagement(Trim命令)、SCSI里面的UNMAP命令等。一旦SSD知道哪些数据是用户不需要的,在做垃圾回收的时候就不会搬移主机删除的数据。原则上合理的 Trim / blkdiscard 之类的东西能改善系统的写放大
此外,我们可以知道,SSD 本身有寿命(在前文讲了为什么)。各个块可能磨损不均衡,甚至有的地方可能存储数据读多写少、有的写多读少。SSD 会根据块磨损状态、数据读多写少/写多读少来放置数据,这种叫做磨损均衡。此外这里也有坏块鉴别、坏块管理。同时,SSD 也要对读干扰重新写入这些数据。
SLC Cache & HMB ?
SSD 允许配置 SLC,这里不改变颗粒,而是说我现在就当成 SLC 用,不需要那么多复杂的电压管理了。这里能加速写入。可能消费级 SSD 会配置这种 SLC Cache,但是企业级一般不用,因为企业级还是认为平稳读/写更重要,SLC Cache 如果满了性能就会开始断崖式拉垮。
HMB 也是,允许有「无 DRAM 」的 SSD,借用外部的内存。NVMe 协议也允许这样,不过企业级 SSD 也很少这么玩。可能在一些专门领域会比较常见。