How to Write SSD
我们之前介绍了 SSD 的基本知识,但是描述的非常基本。这里基本没有涉及到一些 SSD 的接口的部分。这一篇文章介绍一下:
- SSD 的一些接口,包括 GC 的一些原理
- 如何 (友好地)去写 SSD
旧接口和原理介绍
如果你还记得 https://blog.mwish.me/2026/06/03/SSD-Internals/ 的内容的话,你就会回忆起来,SSD 单个 Block 写入的并发是受限的,我们通常会有 Die/Plane 级别的并行。我们下面可以介绍一下 SuperBlock 的概念:
SSD 为了打满多通道的读写带宽,会从每个 Channel、每个 Chip 上各取一个擦除块,把它们绑定成一个更大的逻辑块,这个逻辑块就叫超级块。这里他们可以当作逻辑上的一个或者一组 Block,顺序写入,一起 GC。
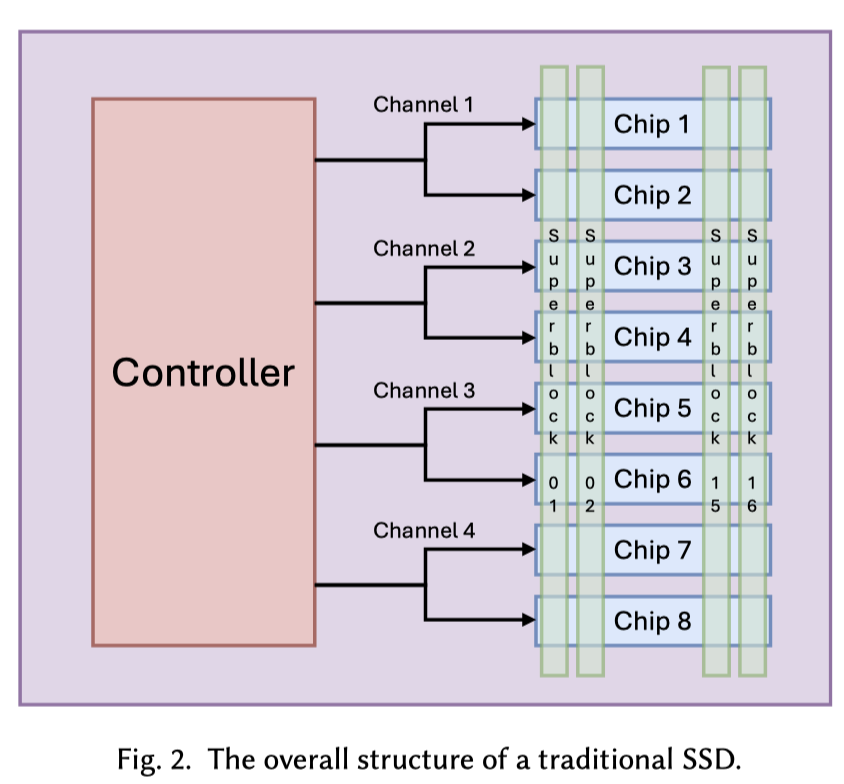
如果你还记得 https://blog.mwish.me/2025/07/01/Architecture-and-Design-of-the-Linux-Storage-Stack-Block-Layer/ 的内容的话,bio 层会组织给下面发送的块请求。块设备会有 /dev/nvme0n1 这样的名,然后这里面大小就是块设备对外暴露的 LBA 长度之类的。块层包装了读写,也能处理下发 TRIM 之类的命令,一些这篇文章会介绍的 STREAM 之类的概念也能被放在块层来处理。用户层也可以通过 fstrim(8)之类的命令去发送 Trim 的请求给对应的挂载的 fs,或者直接在块设备上 TRIM。这里会 hint SSD 说这段连续的 LBA 可以不用了。不过 Trim 的时间可能会比较长。
需要知道的是,bio 层支持了很多 NVMe 和 SSD 有关的新 Feature:

但也有很多块层不一定支持的命令,新一些的系统或者类似的行为可能需要
- io_uring Passthru, 这块可以参考论文 I/O Passthru: Upstreaming a flexible and efficient I/O Path in Linux
- 字符设备 passthrough, 给设备
ioctl发送相关命令,是绕过文件系统的裸盘应用 - 有的未来可能有上层的支持,即块层等支持之后暴露给上层的接口。
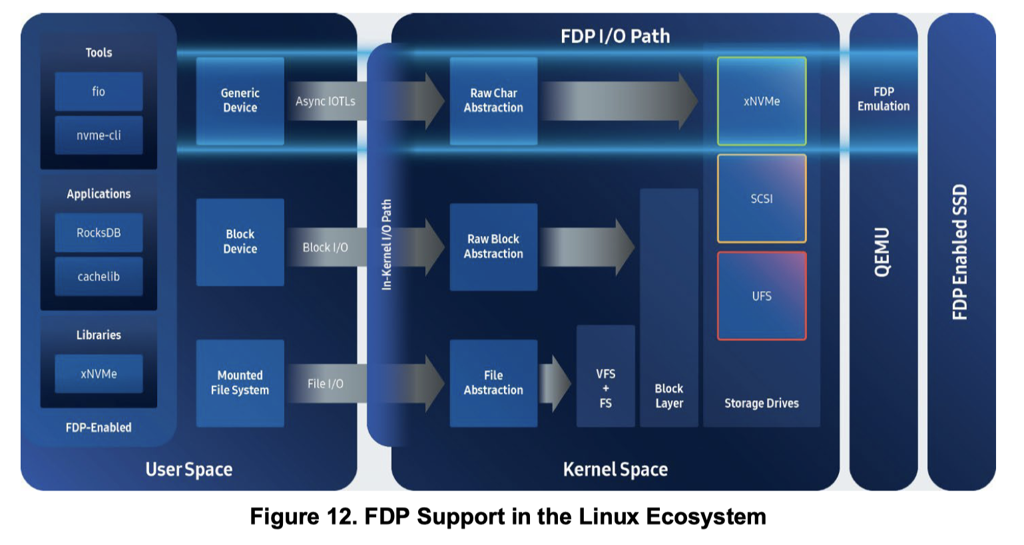
我们可以以接受度之类的视角来看这些,一些新的内容通常就需要 io_uring passthru 或者 SPDK 等方式来处理了,TRIM 之类的广为流传的则可以在系统中找到已有的上层暴露接口。
减少写放大的方案
我们在之前的文章中知道,SSD 要 GC 单位至少是一个 Block,而这一篇文章我们学到了,这个单位也可能会是一个 SuperBlock。这里有一个想法是,如果一个 GC 单元中,用户知道数据有几种不同的生存期,所以写入的数据中,数据要么不 GC,要么可以尽量一起被 GC,这样就能大大减少 GC 的时候,重写这里有用的 Page 的开销。下面有种种方案来优化这一流程。
- 提供某种 hint,表示写入的数据会聚在一起 (FDP/Stream)。需要注意的是,这些方案一般默认需要修改的代码比较少,如果什么都不改,和正常 SSD 可以一样的处理,可能这里会 assign 一些默认的流或者 RUH (后文辉介绍这些概念,先当成 assign 全局的大默认 id 即可,不做任何隔离/hint)。
- 把 GC 单元和内部一些逻辑交给上层处理 ( ZNS / FDP ),下面只处理 SSD 容错的一些东西。这里如果要靠谱的用上一般需要一些对应代码的适配。
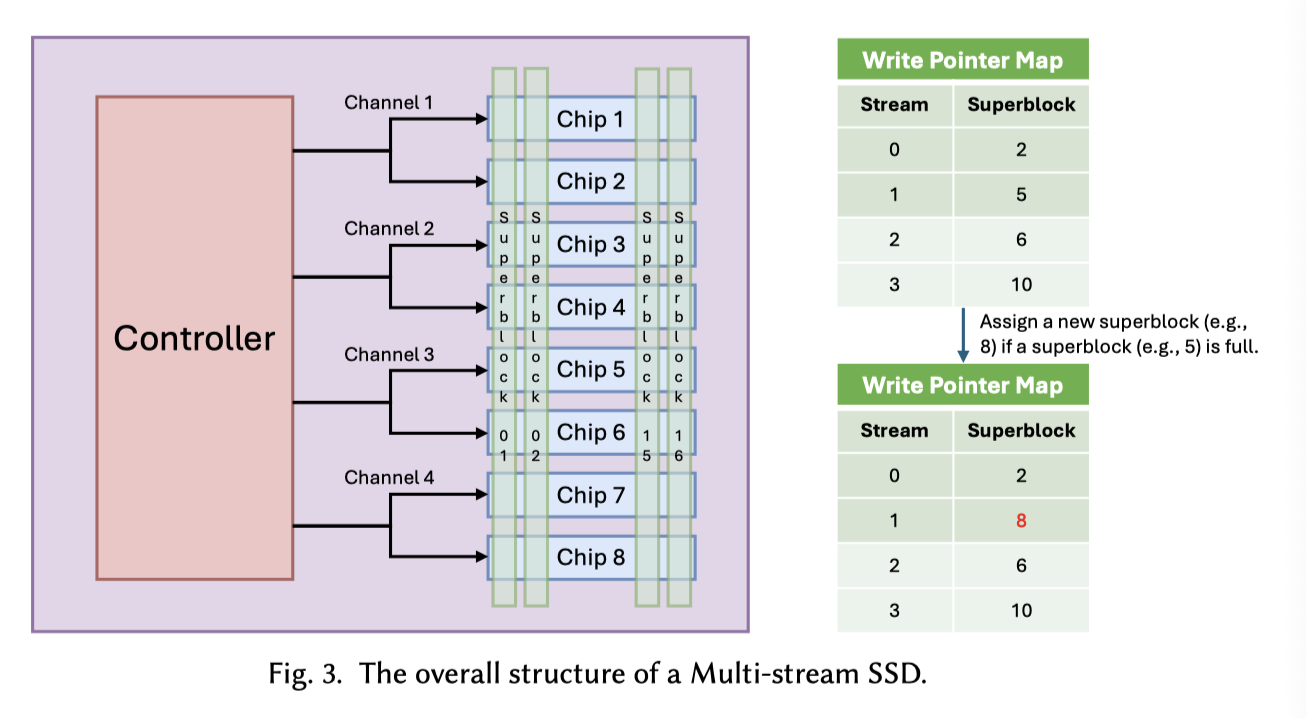
Stream 模式如上图,通过给 SSD 提供一些 Write Hint ( RocksDB 也有相关的代码,搜索 write_hint 即可),给流加入一些 stream_id,然后这里会把流 ID assign 给不同的 SuperBlock 来写。这里如上图所示。
Stream 进入了 NVMe 标准,但因为没有任何主流厂商真正交付可用的硬件实现,也没有已知的真实业务在使用,所以没啥人接着用了。但这套东西很多优势被吸收到了下面的 FDP 中。
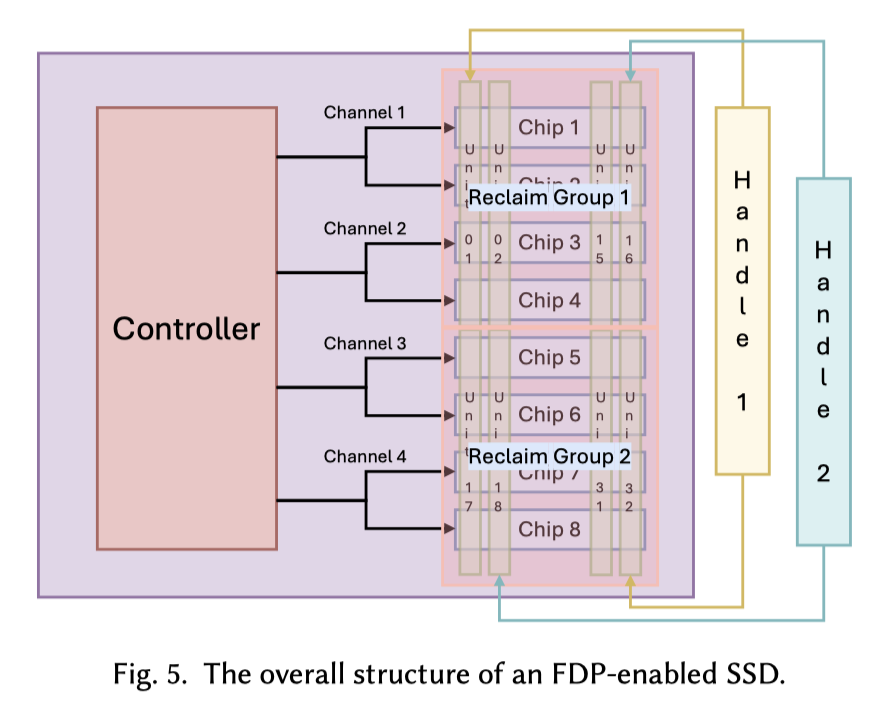
FDP 和 Stream 很相似,但它允许:
- 配置 Handle (RUH) 来写入
- 回收的单元为 RU,RU 虽然在有些文档中被推荐为和 superblock 对应,但它只要是 A set of NAND blocks on an SSD 就行
- 回收单元为 RG,有的地方默认为 1 RG(整盘一起回收),不过也可以独立配置
这样,可以有不同的 RUH 来写入,每种 RU 对应一种类型的写入流,比如说:
- 元数据频繁更改,对应一种 RUH;数据对应一种
- 数据会有 TTL catagory,1天内对应一种,1-3天对应一种,长期 living 对应一种
- …
这样既能切分租户写入隔离,也能提供不同的生存期。
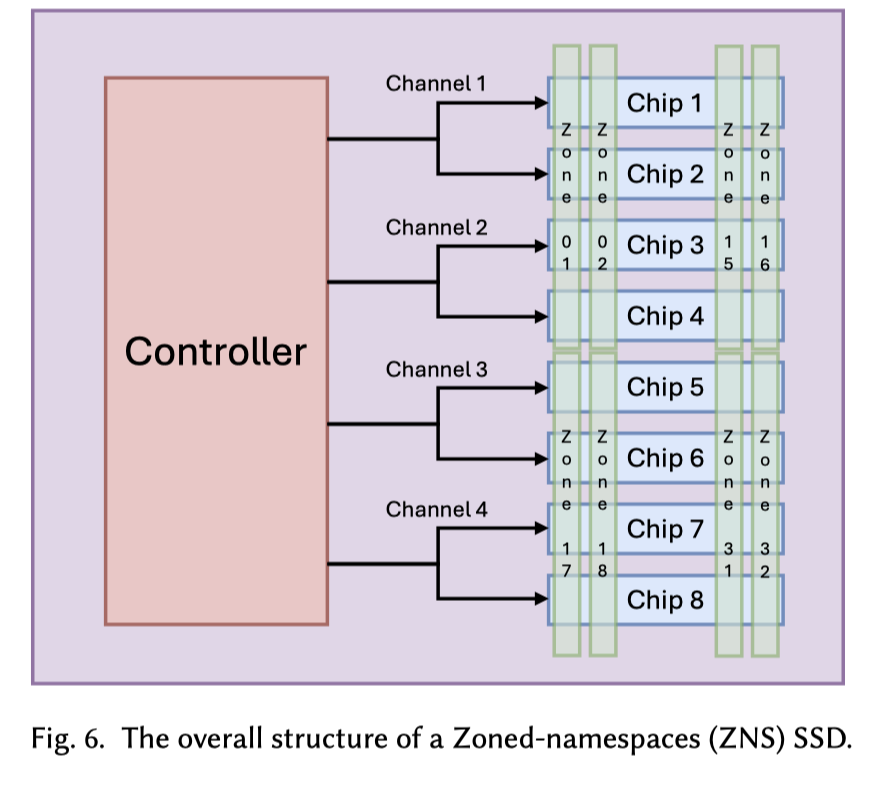
ZNS 可以把盘空间切分为不同大小的 GC 和写入单元 Zone,上层知道这个信息并写入。ZenFS 就是这个场景的使用者。SMR 的机械硬盘也有类似的逻辑。
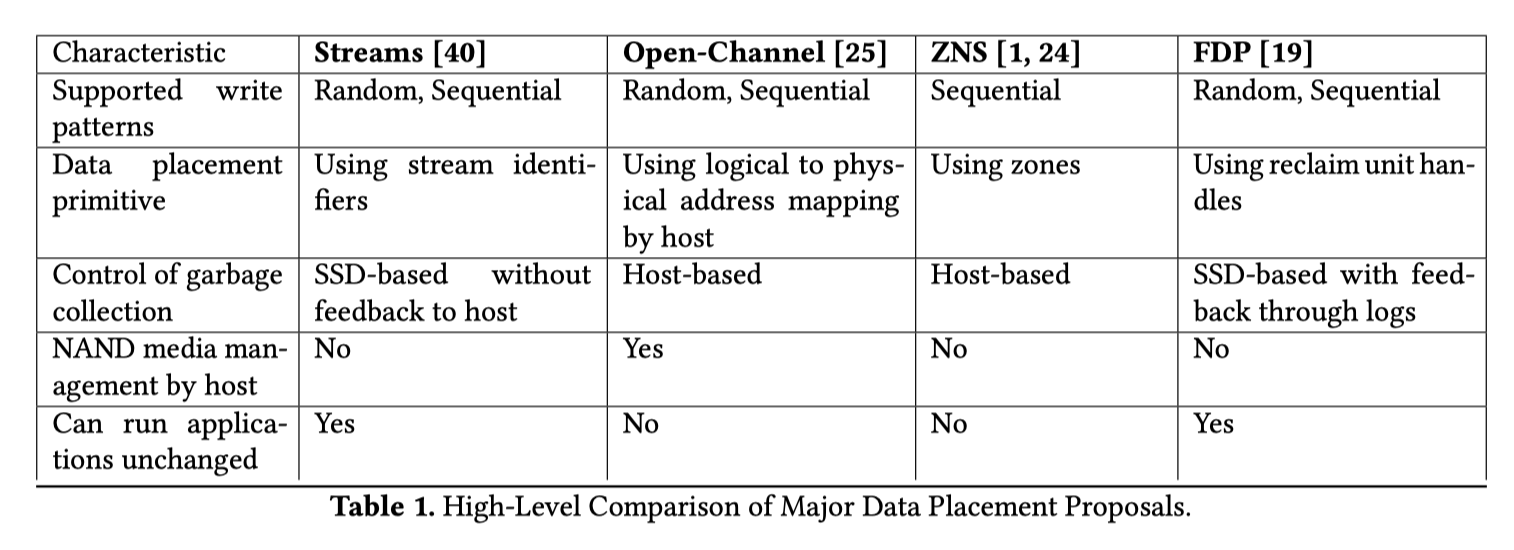
我们某种意义上可以把这里当成 SSD 厂商和用户(FS 和更上层用户)妥协的过程。
FDP 和 CacheLib FDP 改造
这项工作似乎主要由三星的成员完成,核心优化来自 SSD 的 SOC/LOC 的大小对象区分,这两种对象写放大/生存期不同,配置不同 RUH 即可。
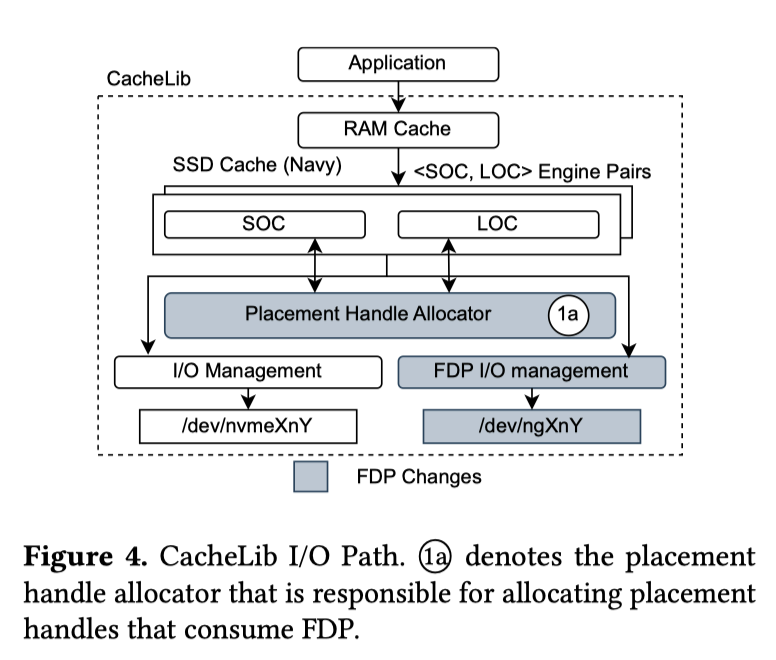
How to Write SSD 的实践
TUM 的论文引入了一系列实用的方法在 LeanStore 这个 Btree 存储上
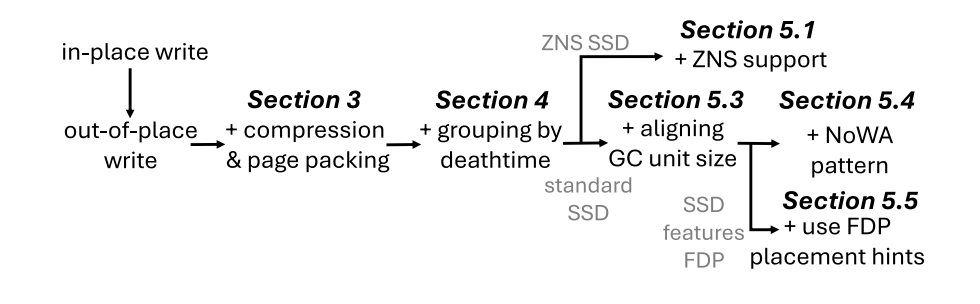
Out-of-place write
人人都用 LLAMA 有没有懂的?这里核心是每次写用新地址,然后老地址 + WAL == 新地址的,充当一份数据写的 Double-write Buffer。同时,这里写入的时候可以 assign 一个新的 LBA,为后续优化做准备。
Page Packing
和 EROFS 的思路很像。但没有那么细,核心问题是 out-of-place write 之后可以引入 (offset, length],然后一起 IO。但我个人觉得这个效果不一定好,反正我一直认为这东西做到上层或许会好些。
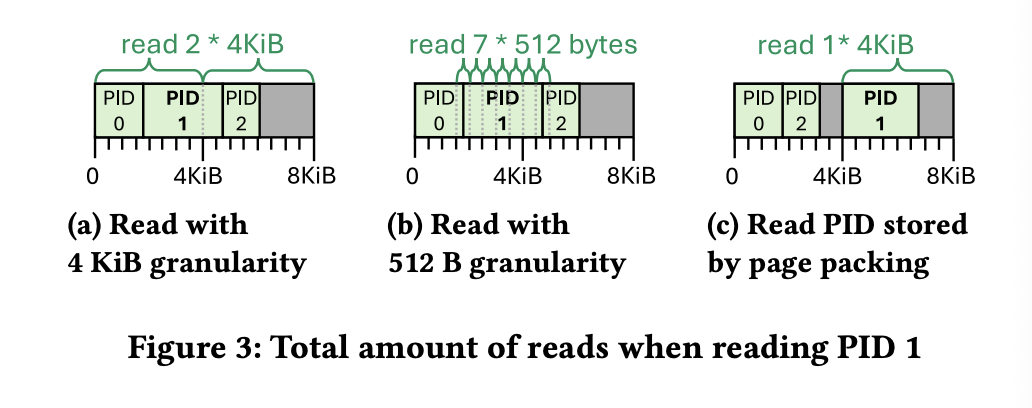
DEATHTIME-BASED GC
这里需要注意的一点是,这个地方因为是 Out-of-place write,所以 DB 需要自己负责 GC Old Block。一般的 LLAMA 之类的 Log-based System 本身有比较完善的 GC 了,参考:https://arxiv.org/abs/2005.00044
但这篇论文观点比较有意思,因为这个地方是 Btree Page GC,一个 Btree 对应的页面可能会反复写,所以对于 Btree 而言,能比较好有一个 Death time 估计:
- 记录 Page 最近的 n 次写入 timestamp,维护一个 write history ( WH ),根据
current_lsn和WH,线性估计下次写入的时间(EDT) - EDT 类似的会 grouping 到一起写,再选择平均 EDT 最匹配的活跃 zone 写入
- GC greedily selects victim zones until their cumulative invalid pages free the space of one zone. 然后写入对应的 zone,注意 ages that are never rewritten (e.g., read-only pages) are assigned the maximum EDT to be treated as the coldest data.
- 在 GC 结束后,给不同满度的 zone ( may be full, partially full, or empty ) 不同的 EDT
SSD 适配
对 ZNS 这里尽量 DB Zone 大小 == ZNS Zone 大小,如下图:
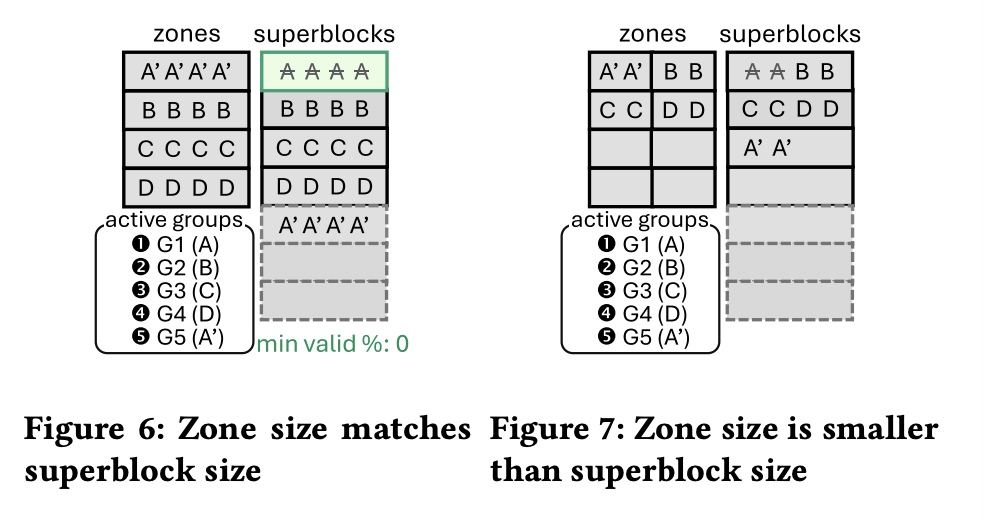
对普通 SSD 和 FDP 就比较好玩了,这里先要测出对应 RU 的大小。FDP 可以直接拿到 RU 大小,我们重点看 SSD:
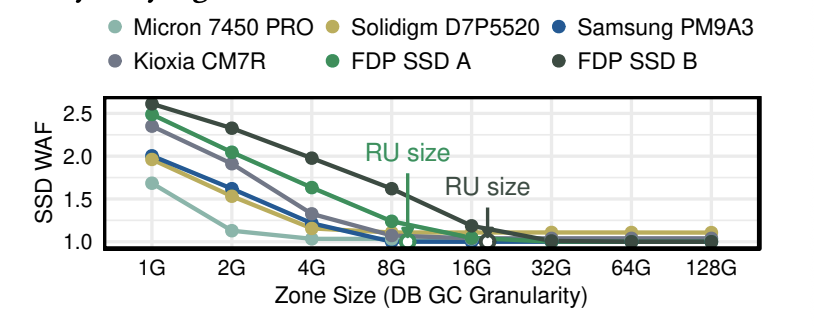
- 通过类 ZNS 写模式推断:单活跃 zone 下,逐步增大 zone 大小,当 SSD WAF 首次降到 1 时,对应的 zone 大小就是内部 GC 单元的上界。实验测得企业级 SSD 的 GC 单元通常在 4~8GB,论文建议 32GB 作为通用安全上界。
写入的时候,这里对 FDP,可以尝试给每个 DB Zone 一个 id,取模拿到对应的 RUH。
这里核心在论文提出了普通 SSD 减少写放大的 NoWA 方式:
- Active Group 是 NoWA 机制中用于管理并发写流的逻辑调度单元,定义为:同一时间段内,数据库并发打开、同时执行追加写入的一组 Zone 集合。
- 论文认为,写放大来自于同时打开多组 Active Zone 的话,SSD 写入的时候,实际对物理空间写入是 Multiplexing 的,可能会写到各处。所以同一个 EDT 应该尽量只对应一个 Active Zone ( When multiple zones are appended concurrently, their write streams interleave across different superblocks [100]. For example, if the DBMS writes to zones A and C at the same time (active group G1(A, C) in Figure 8), writes from both zones become mixed, scattering their data across two superblocks. This multiplexing effect [92] arises because standard SSDs cannot distinguish writes from zones A and C. )
- 因为 (1),所以这里如果不同 Zone 生存期不一样,活得久的会影响早死的回收。这里比如 Fig 10 发现有的组写的少,可能会把 C/D 中部分补偿写(重写 zone 来拖下水),来换得一样的 GC 时间。这里会尝试拉同一个 Active Group 的下水。本质上是用户写放大换 SSD 写放大。
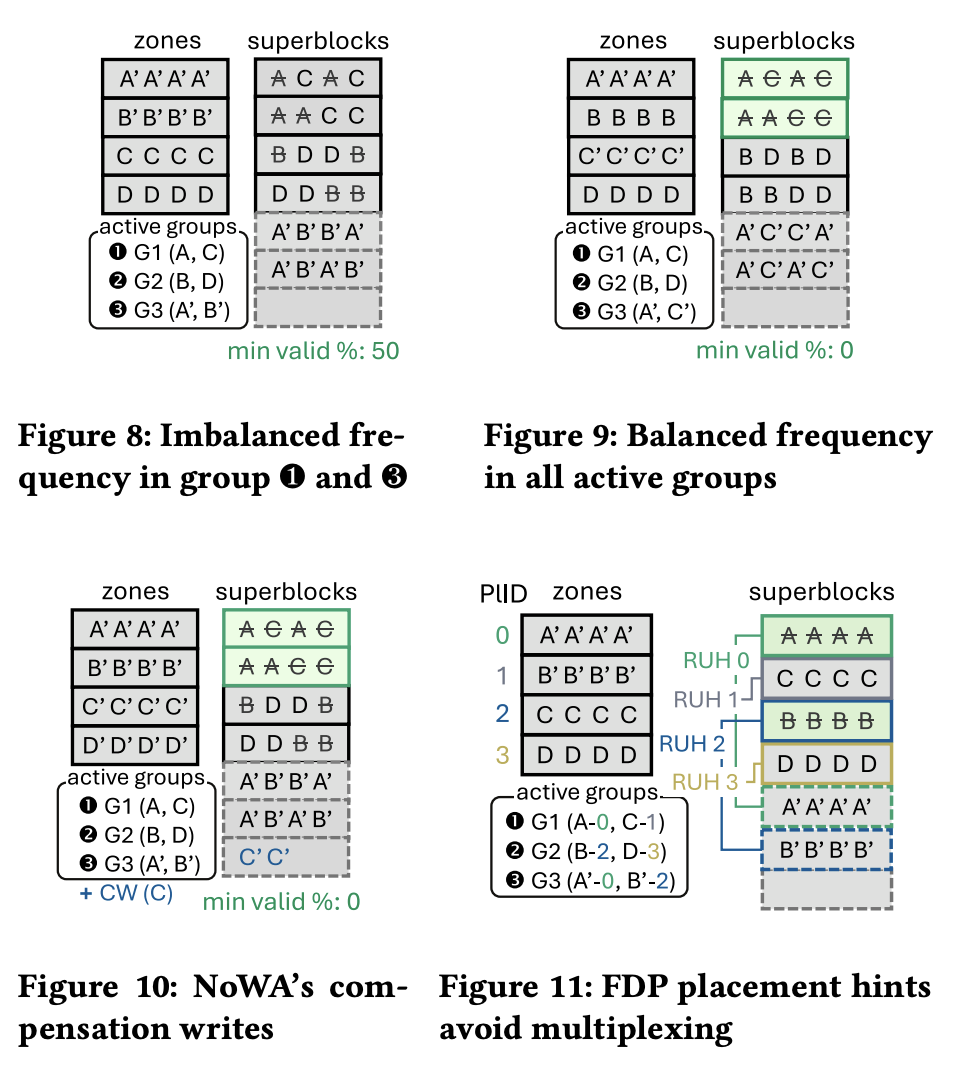
讲道理这段我看的不是很过瘾,因为这个策略看着水很深,CW(D) 都不知道怎么进行,make sense 是 make sense,但感觉没有很简单?
Reference
- Introduction to Flexible Data Placement https://www.snia.org/educational-library/introduction-flexible-data-placement-new-era-optimized-data-management-2026
- Storage Abstractions for SSDs: The Past, Present, and Future https://dl.acm.org/doi/pdf/10.1145/3708992
- Towards Efficient Flash Caches with Emerging NVMe Flexible Data Placement SSDs https://dl.acm.org/doi/abs/10.1145/3689031.3696091
- How to Write to SSDs https://arxiv.org/abs/2603.09927
- https://github.com/sg20180546/FDP-awesome-paper