Storage Interfaces
我们之前(很久以前)的几篇博客介绍了 Linux 的 VFS 和 Block Layer。
- https://blog.mwish.me/2025/05/31/Architecture-and-Design-of-the-Linux-Storage-Stack-VFS/
- https://blog.mwish.me/2025/07/01/Architecture-and-Design-of-the-Linux-Storage-Stack-Block-Layer/
同时,我也介绍过数据库人对 Five Minutes Rule 的看法,姑且是一个数据库视角的存储概览:
之前我也在一些地方介绍过一些 SSD Related 的设计,比如经典的 WiscKey、CacheLib ( https://blog.mwish.me/2021/08/01/FAST-16-WiscKey/ , https://blog.mwish.me/2021/11/01/SSD-as-Cache-and-CacheLib/ )。
但老实说,写这些博客的时候我对这些硬件本身没有很多的了解,也没有那么多碰过真正的 SSD 和 HDD,不知道其中的 Pain 或者不太对的地方,回头来看有很多地方可以挑挑毛病的:
- HDD: 比如说对用户来说,如果是访问云上硬件,那么用户是很难跑满一丁点儿硬件带宽的,很多时候是大伙儿吹完 SSD 发现自己一毛钱这个数据优化都打不上。而对象存储呢?对象存储背后跑的很多甚至是经过优化的 HDD + EC + SSD Cache。另外,论文当时认为,比较早的时间内(例如 2026 左右),SSD - HDD 成本就会交汇,然后 SSD 彻底把 HDD 干掉。当然我们知道,2023年大概是 SSD / HDD $/TB 成本比例的最低点,这个比例当时可能接近 3 倍,然而随着大家都知道的 LLM 大爆发、对大容量 SSD 需求增加、 NAND 减产,SSD / HDD 价格比例又发生了变化:消费级和企业级 SSD 价格涨价了 2-5 倍,HDD 价格只是随着供应关系少量增长。此外,这几年 SMR/PMR 之类的技术已经变成了成熟的产品,HAMR 之类的技术让 HDD 最大容量还能增长。
- SSD: 刚才上面这么多会让你感觉我在吹 HDD,但 SSD 还要我吹吗,买了的都发财了。现在主流的个人用户用的是 PCIe Gen4 的 NVMe 盘,而企业则大部分是 PCIe Gen5 的盘。大容量 SSD 能轻松提供高吞吐、高 iops,感觉到了「只要稍微针对 SSD 设计一下,就基本没啥问题」的程度(比如说,TUM 的数据库也选择了 4KiB 作为 PageSize (虽然我个人的低劣品味总觉得 Page 大点会比较合理,比如 16KiB 或者更大的大小)。TLC 的盘读能做到 10+ GiB/s,写也能轻松 5+ GiB/s,容量到 ~30TiB;QLC 盘容量能大不少,可能更适合少写多读一些的场景。这个时代 iops 也是极大富余,原则上设备支持最大 iops 已经在一个「随便打」的状态了,当然作为用户,还是应该平滑一下读写曲线,来降低峰值的延迟什么的,而不是狂打爆打(这个也得根据测试来)。
我们这里主要介绍一下 (1) 更新的 SSD 硬件的知识 (2) SCSI 和 NVMe 接口。
SCSI & NVMe
SCSI
SCSI 协议的发展旨在促进计算机和外围设备之间的无缝数据传输,包括磁盘驱动器、CD-ROM 驱动器、打印机、扫描仪以及其他各种资源,确保高效可靠的通信。 传递给 SCSI 的任何读取或写入请求都会被转换为等效的 SCSI 命令。需要注意的是,SCSI 不会处理用于传输的块的排列或它们在磁盘上的物理位置,这属于 I/O 层级中更高层的管辖范畴。
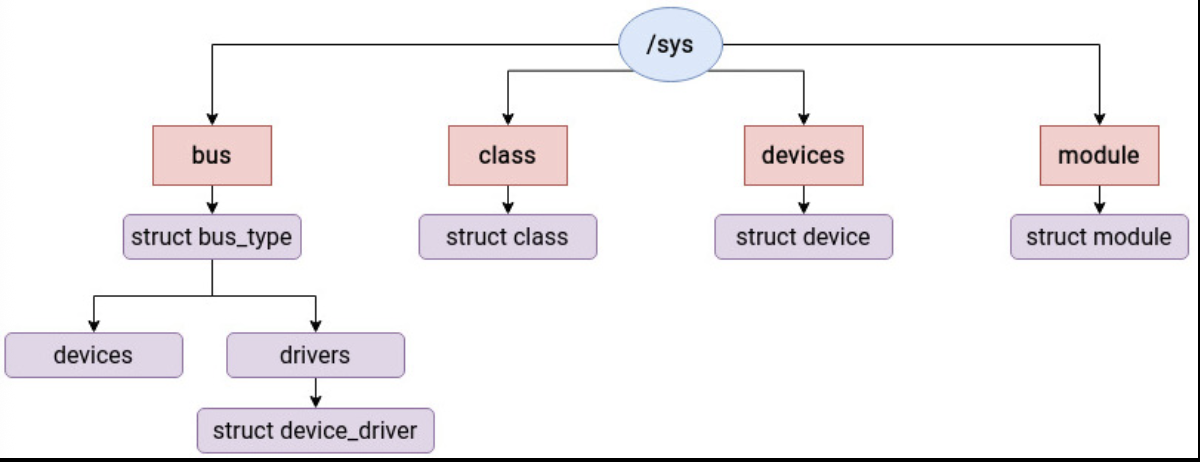
Linux 下有对应的设备模型,对应:
- 设备之间的通信依赖于一个叫总线 ( bus ) 的通道。总线是一个用于传输数据的通道,就像公路一样是用于交通运输的线性通道。为了便于设备模型的抽象,所有设备都应该连接到总线上。设备模型中的总线是基于物理总线的抽象。
- Device 是连接到总线的物理设备。在设备模型中,设备抽象了系统中的所有硬件设备,并描述了它们的属性、连接的总线以及其他信息。
- Driver: 与设备关联的软件实体。设备模型使用驱动程序来抽象硬件设备的驱动程序,包括设备初始化和电源管理相关接口实现。
- Class: 设备的一些内部分类, 类似 SCSI, ATA 之类的.
SCSI 子系统可能包含:(1) 一个连接外围设备到计算机的硬件总线 (2) 用于通过不同总线类型与设备通信的命令集。我们可以看下面对应的示意图(并且之后会比较和 NVMe 有什么区别)。如图所示,SCSI 使用了三层架构:
- Upper Layer 定义了不同的 Driver,这类驱动程序我们会很熟悉的发现他们会对应
sda这样的名字。这里驱动会接受用户的(比如存储块设备的)请求,然后在中间层和底层的帮助下将其转换为等价的 SCSI 请求。转化为 SCSI req。当然我们可以有 bypass 操作,直接给sg这样的 SCSI driver 发命令,绕过文件系统 - Mid Layer 定义了统一的命令结构、完成通知、错误恢复、设备扫描和命令排队策略。上层驱动只需要调用中间层提供的 API 来创建、派发命令;中间层负责把这些命令路由到正确的底层驱动,并处理公共的异常流程。这里也会监督 SCSI 命令队列的管理、确保错误处理的效率,并促进电源管理功能的实现。中层还实现了命令排队。当从上层接收到请求时,中层会将请求排队进行处理。一旦请求得到服务,它就会从下层接收响应并通知上层。如果请求超时,中层负责执行错误处理或重新发送请求。
- Low level driver: 具体的硬件控制器。
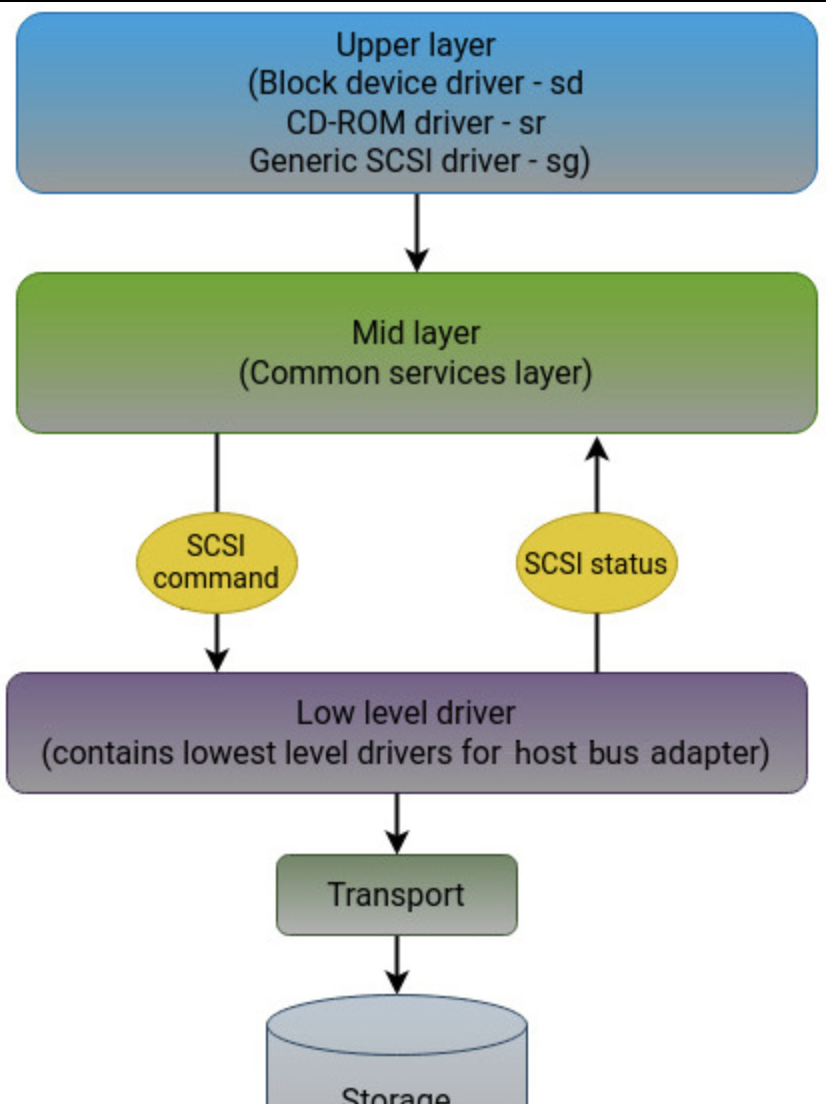
我们也可以看到这里上面的图有一个 Transport 的部分,这里可以对应为 SCSI 的传输层,我们可以找一张有点花哨的图:
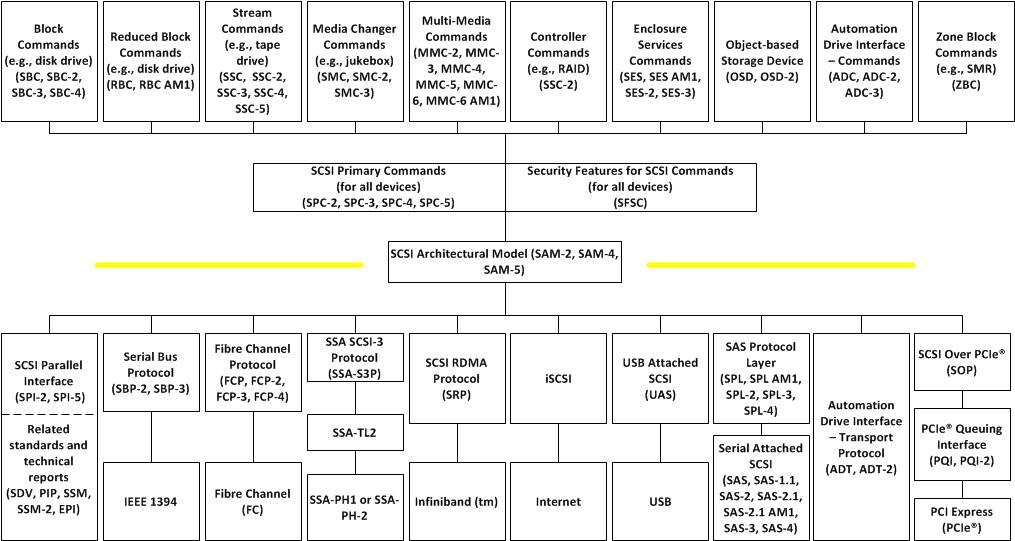
这里 SCSI 会需要保证 SCSI 的图经由下面的传输方式发到了目标,然后能收到 response,类似一个 Client - Server 模型。你或许也会看到,这里甚至能在 TCP 网络,Fibre Channel 之类的地方运行。我们后续介绍的 NVMe-oF 也会与这里定位有些许类似。
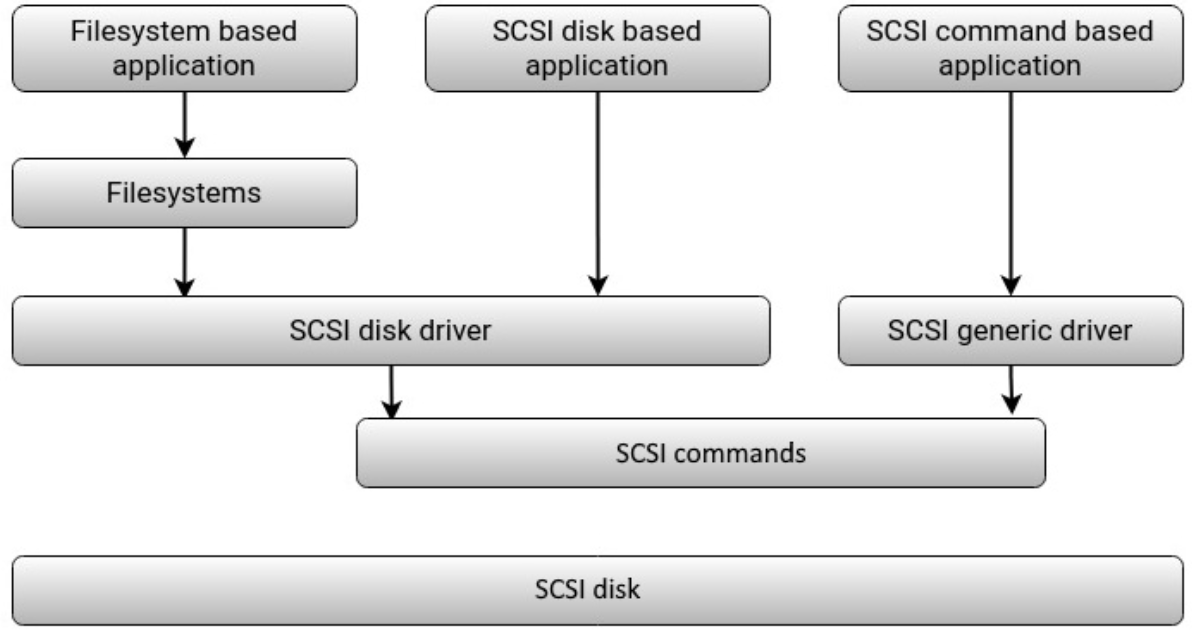
SCSI 调用路径也如图所示:
NVMe
SSD 自身读写带宽不断提高、低延迟高带宽需求增加,同时,网络的带宽也在渐渐增加。新的更薄的、更靠谱的协议应运而生。HDD和早期的SSD绝大多数都是使用SATA接口,跑的是AHCI,它们能满足系统性能需求,因为最慢的永远是磁盘。随着SSD技术的飞速发展,SSD盘的性能飙升,底层闪存带宽越来越高,介质访问延时越来越低,系统性能瓶颈已经由下转移到上面的接口和协议处了。我们听过 io_uring 和协议层的故事,这里我们会介绍一下 NVMe 和 NVMe 依托的 PCIe。
整个PCIe拓扑结构是一个树形结构。Root Complex(RC)是树的根,它为CPU代言,与整个计算机系统的其他部分通信,比如CPU通过它访问内存,通过它访问PCIe系统中的设备。原生PCIe主控与CPU直接相连,而不像传统方式,要通过南桥控制器中转再连接CPU,因此基于PCIe的SSD延时更低。我们这节只是简单介绍一下,并不会介绍 SR-IOV 这样的东西。此外我们可以关注到,PCIe 设备之间也是能通信的,
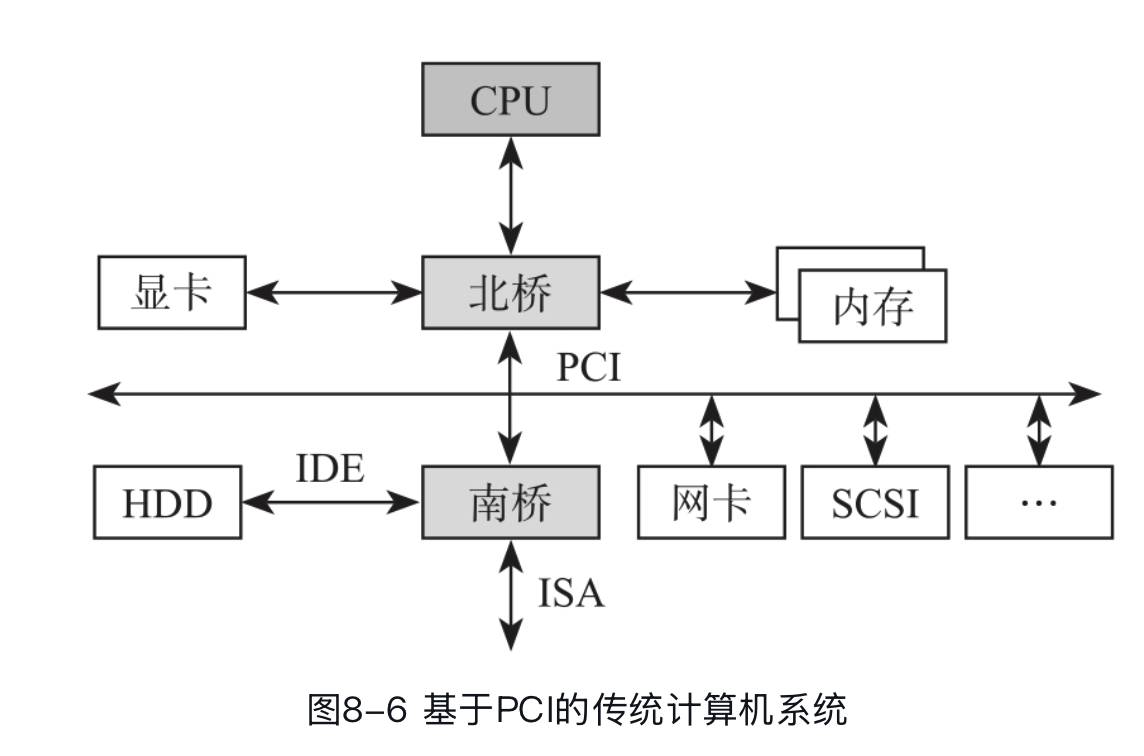
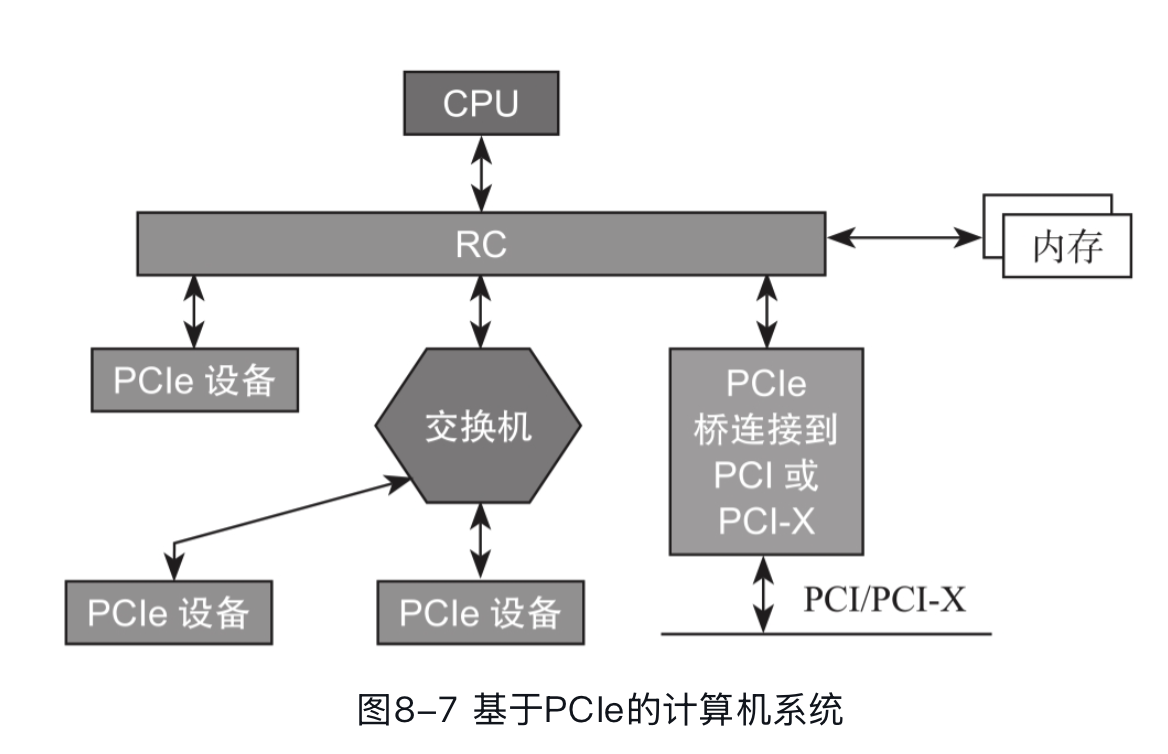
我从 Wikipedia 偷了个图:
各式不同的PCI Express插槽(由上而下:x4, x16, x1,与x16),相较于传统的32-bit PCI插槽(最下方),取自于DFI的LanParty nF4 Ultra-D机板

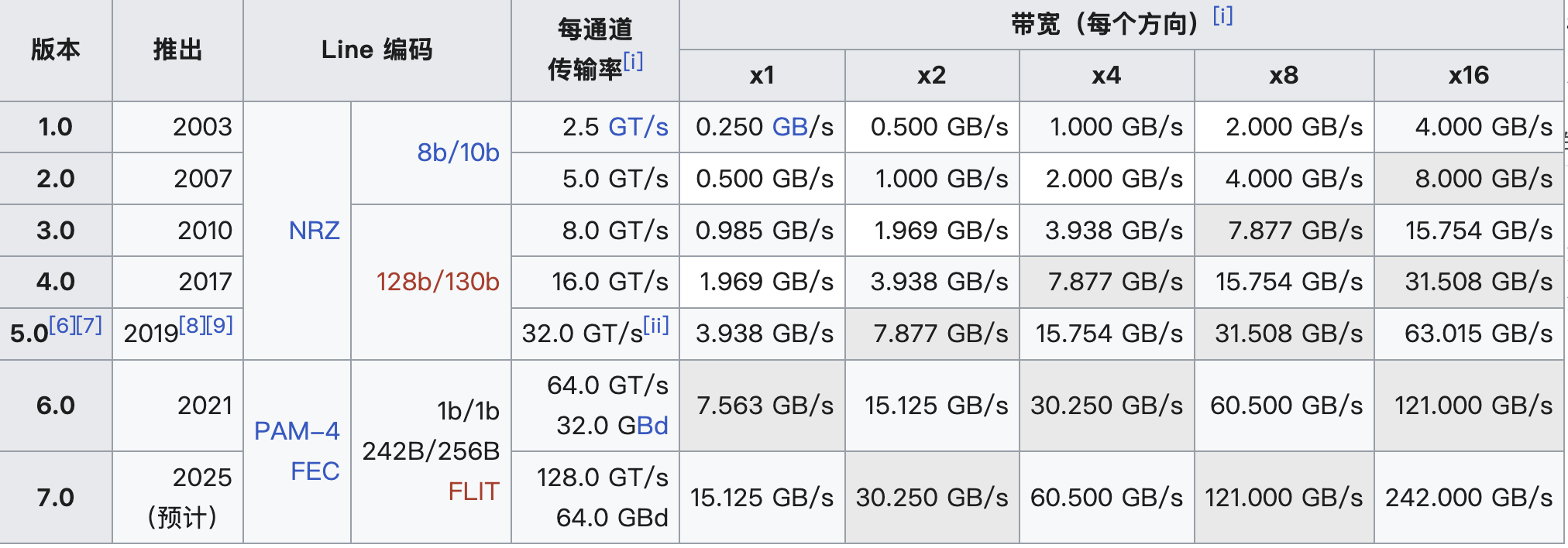
这里硬件上有 PCIe 对应的传输通道。现在企业级 SSD 通常是 x4 的 PCIe Gen5,消费级可能在用 PCIe Gen4,这些数字指的是一个方向(发送或接收) 的理论速度。因为发送和接收可以同时进行,如果两个方向都有满负荷数据流,整个链路的总吞吐量可以达到单向带宽的 2 倍。
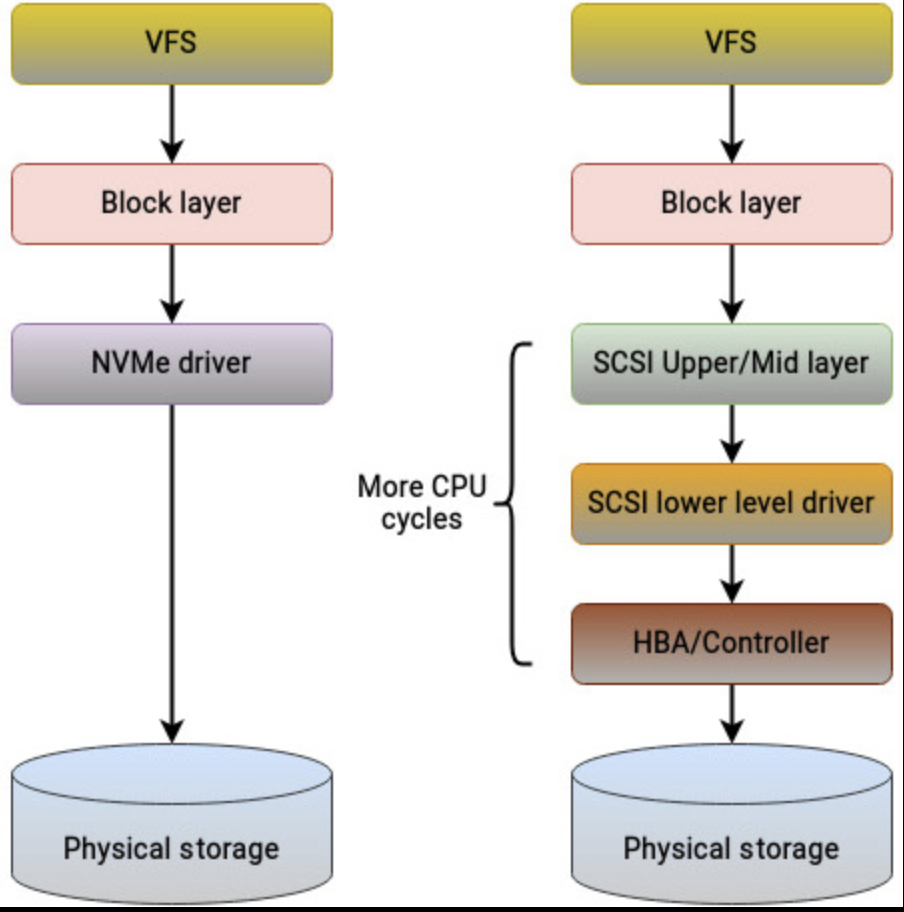
我们会看到 NVMe 在存储上大致有如下的架构,其实可以看出来,这里某种意义上可以理解为 NVMe 有着更轻的 io-stack,能高效去直通 Physical Storage:
NVMe 协议的设计会让我们有点眼熟,SPDK, io_uring 之类的模型我们都见过类似的图了。
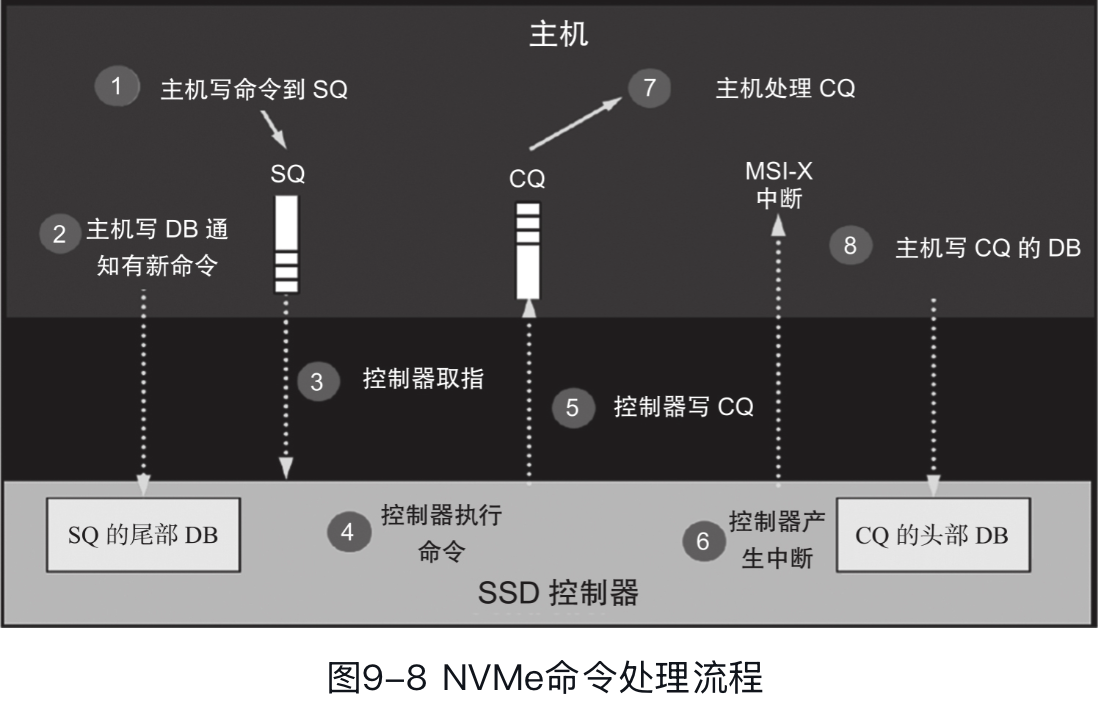
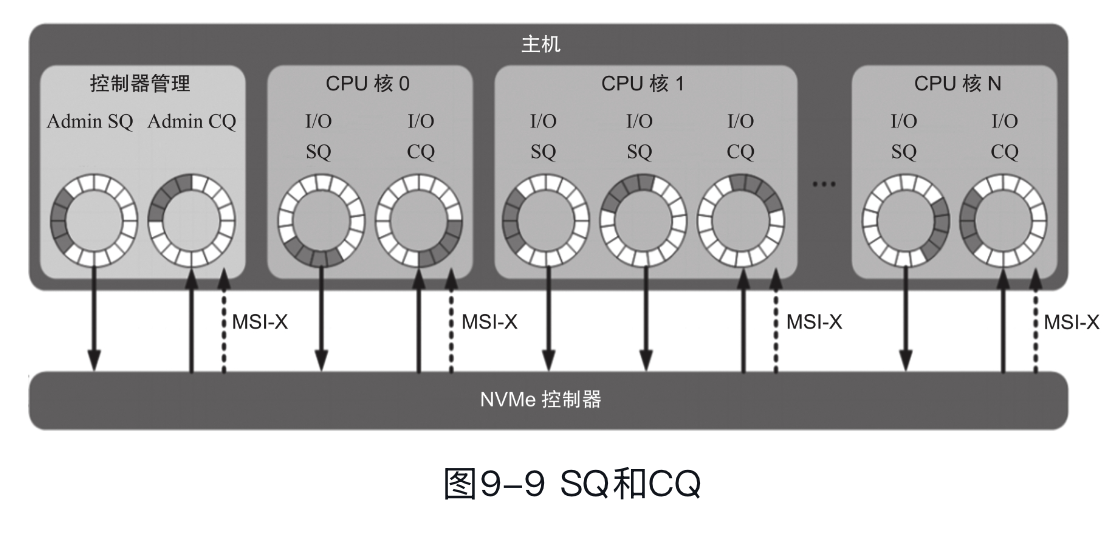
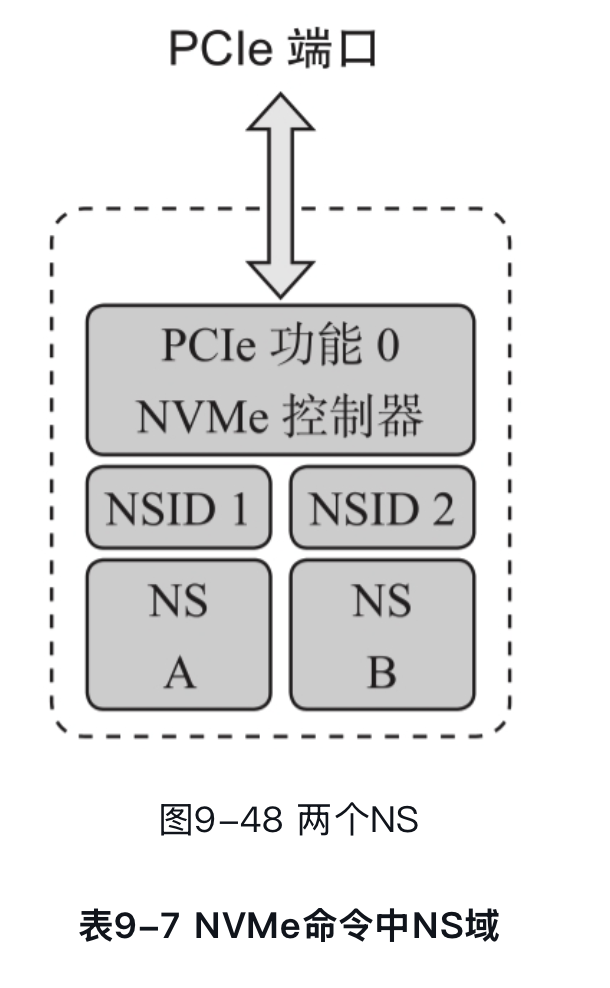
像 NVMe 盘也能划 namespace,我们扫块设备的时候其实可以看到 nvme0n1 nvme0n2 这样,n 对应的就是 namespace 的划分。
然后之前我们还聊到了 SCSI 跑在不同的协议 (TCP, IB) 上去 Scale,NVMe-oF 也规定了一种协议,能把 NVMe 对应的内容挂在内存 / FC 网络 / RDMA 网络上传输,如下图:
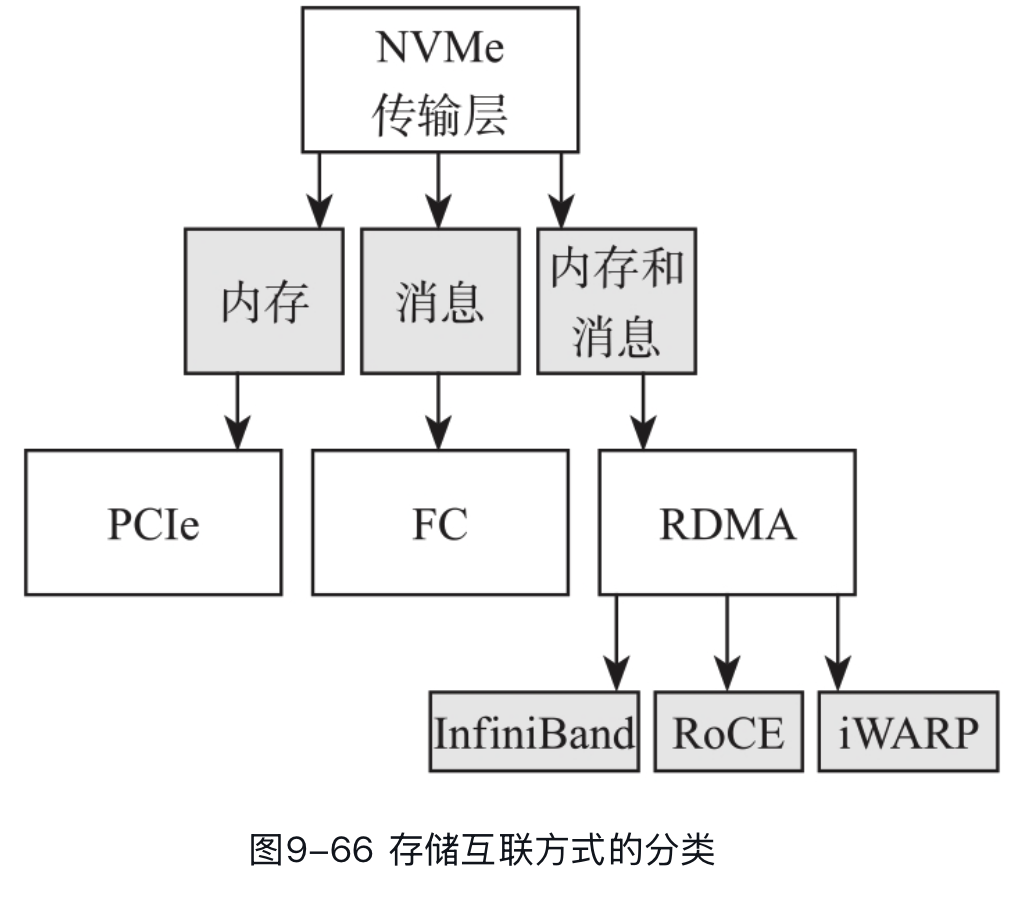
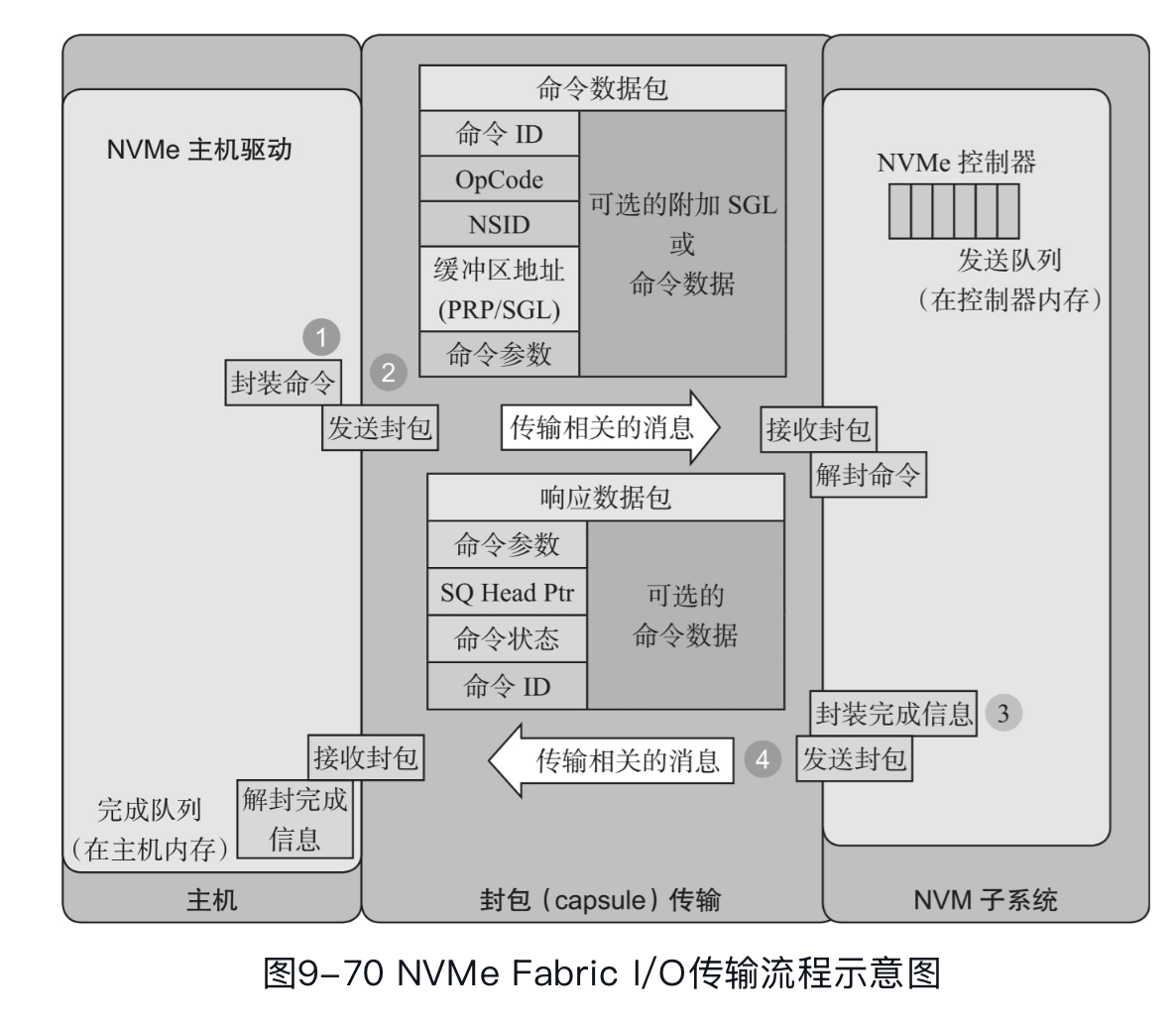
实际上 NVMe-oF over TCP 已经被各大云厂商用于 EBS 后端(AWS EBS io2 就是 NVMe-oF)。