如何用 LLM + MTool + AiNiee 翻译 RPG 作品来浪费自己的钱
在跟朋友聊科幻的时候,聊到一个很有意思的话题:过去有一个很有趣的思想实验叫「中文屋」,类似一个程序或者映射,你问他他能答上来,但它没有智能。当时人们以这点来判断「是否有生命」。当然 LLM 时代好像大伙儿已经不会根据语言本身来判断了,尽管「AI 有没有真正的智慧」还是个问题,但现在似乎已经不会用这个来判断了。额我扯远了,言归正传,有能力这么强的 LLM,我们的翻译也能低成本的翻译一些以前没人愿意汉化或者汉化速度相当慢的的内容了,海外的一些新出的书本、知识感觉能被比较快的提取出来汉化,以前很多没有人愿意翻译的上十万甚至百万字的免费 RPG,我们也有很好的机会来汉化了。
这篇文章参考了:https://www.bilibili.com/opus/1038930345281454117 这个文章,不过结合了我自己的心得和工作流。
这一期我们会使用 MTool 作为工具来做一些简单的汉化,然后之后有空会补充一期 Translator++ 的。对于 RPG Maker 游戏,MTool 提取是个很「轻松」的选择,这里能比较快的利用所有都是开源的工具跑完一轮汉化,Translator++ 相对来说能处理的更工整一些,也能打包出完整的汉化之后的游戏 Binary,也能让你更懂一些具体的细节,但是耗时也会更多。我们这篇文章只介绍 MTool 进行翻译,不过相信阅读完这篇文章的下一节,读者也能知道这 MTool 的缺点在哪。
本篇文章还会花时间介绍 AiNiee 这个翻译工具。笔者在之前的帖子里看到介绍 LinguaGacha 和 KeywordGacha 的,不过个人感觉 AiNiee 一个是内容比较全,虽然有一些不是很符合直觉的地方,但是改吧改吧还是能用的,这篇文章也会结合代码介绍一下 AiNiee 这个工具。
提取待翻译内容和 MTool 的 Bad Case
(图我是直接偷上面那个帖子的)
是一个 {key: value} 的 JSON,导出后初始往往是 “原文 → 原文”(待翻译状态),如下,后续翻译完成会变成 “原文 → 译文”:
1 | { |
可以看到,这里待翻译的都是一些短句,MTool 会把语句切分成若干子句或短语,可能这个来源于 RPGMaker 的游戏编排句子吧。这里要注意,这里的文本比较全,即包括游戏对话的文本,有的时候也包括一些脚本,然后这里的编码可能也不是 UTF-8 的编码,而是包含日文的编码。此外这里甚至会包含一些代码,我们之后可能会把这些东西弄到禁翻表中。
这里翻译的大概逻辑是,A->B 之后修改成正常的原文 -> 正文的映射,如结果:
1 | { |
奇怪的数据
我们在进入下一节之前,具体解释一下奇怪的数据长什么样子
奇怪数据1 (可能来自脚本)
1 | "# ● バトルステータス表示/非表示": "# ● バトルステータス表示/非表示", |
奇怪数据2(可能来自 rvdata 之类的 binary)
1 | "¸ý\u0017-ð/": "¸ý\u0017-ð/", |
这里我个人建议写一个简单的脚本,把这些内容判断一下,抽取出来的是不是 Ruby 脚本或者 Binary 的部分就删除,然后导出一个新的 Json 文件。当然,有的时候重要的内容也会出现在这些 binary 或者脚本里面,所以这里实际上也需要我们按照情况看着办。
Bad case
语气词
默认 Prompt 可能会出现下列的情况,这里会有「っ!」「・・ッ」之类的语气符号,可以改 Prompt 来解决这个问题。
1 | "ごめ、ん・・・\n 兄さ―――": "抱、歉・・・\n 哥哥―――", |
神秘的 chunking?
注意下面第五行,懂日语的人感觉完全不会碰到这个问题
1 | "「私は": "「我是", |
MTool 顺序问题?
1 | "本来ならばパートナー殺しは、重罪の中の重罪。\n裁かなければ、周りにも一切示しがつかぬケース。": "本来杀害伴侣是重罪中的重罪。\n若不加以审判,对周围也完全无法交代。", |
额,这个就是因为这里的内容取的不太对…感觉原则上 LLM 能够处理这些,但处理不了我也能理解,它也尽力了…
はい\C[26]❤️\C[0]ヴァルグ様の赤ちゃんなら
在导出的 json 文件中其实是分成了
はい和ヴァルグ様の赤ちゃんなら这两个 key 吧
RPG Maker 会有一些文字的控制符,比如 \N, \C 等,分别表示人物或者变色。MTool 会 split by 这种控制字符,这里会导致出现上面这种奇怪的 Chunking。
系统/图片
有的时候,一些系统里面的东西不会完全抽取出汉化,例如装备系统之类的,可能在 RPG Maker 2003 之类的地方 MTool 不一定提取/翻译了系统界面之类的内容
或者有的地方用了图片之类的方式来提供文本,这些内容可能需要汉化者来努力
用 AiNiee 跑傻瓜式翻译
AiNiee ( https://github.com/NEKOparapa/AiNiee ) 是一个AI 翻译的工具,这篇文章有 :
- 「导出待翻译文本」→「抽取词表」→「翻译正文」→「排查失败/停止/继续」的一个大概的流程。
- AiNiee 在工程上如何组织 CacheItem、如何切分 chunk、如何检查与重试的关键机制(带关键约束点)
下载和运行 AiNiee
我个人是在 MacOS 上直接 Python 运行的,这里是一个提供了 Qt 界面的 Python 项目,下载好依赖直接运行即可。官方 release 会提供 Windows 上的 Release Binary。
AiNiee 会缓存一定的数据在启动的目录下,同时,它的日志系统会打到 Terminal 中,可以自己注意一下或者重定向日志,来优化使用体验。比方说我会 Dual 一下各个级别的 logging,主要是在翻译的时候我会想看如果失败了,失败的 case 是什么样的,根据日志来调整一下运行的状况。
前置流程
这里首先要配置 API,我个人建议:
- 你需要一个你觉得最聪明的 API 来提取词表
- 需要一个还算聪明的主力模型来跑翻译
我用 Gemini Pro 模型来跑词表,然后用 Deepseek V4 Pro 或者 Gemini Pro 来跑内容的翻译。
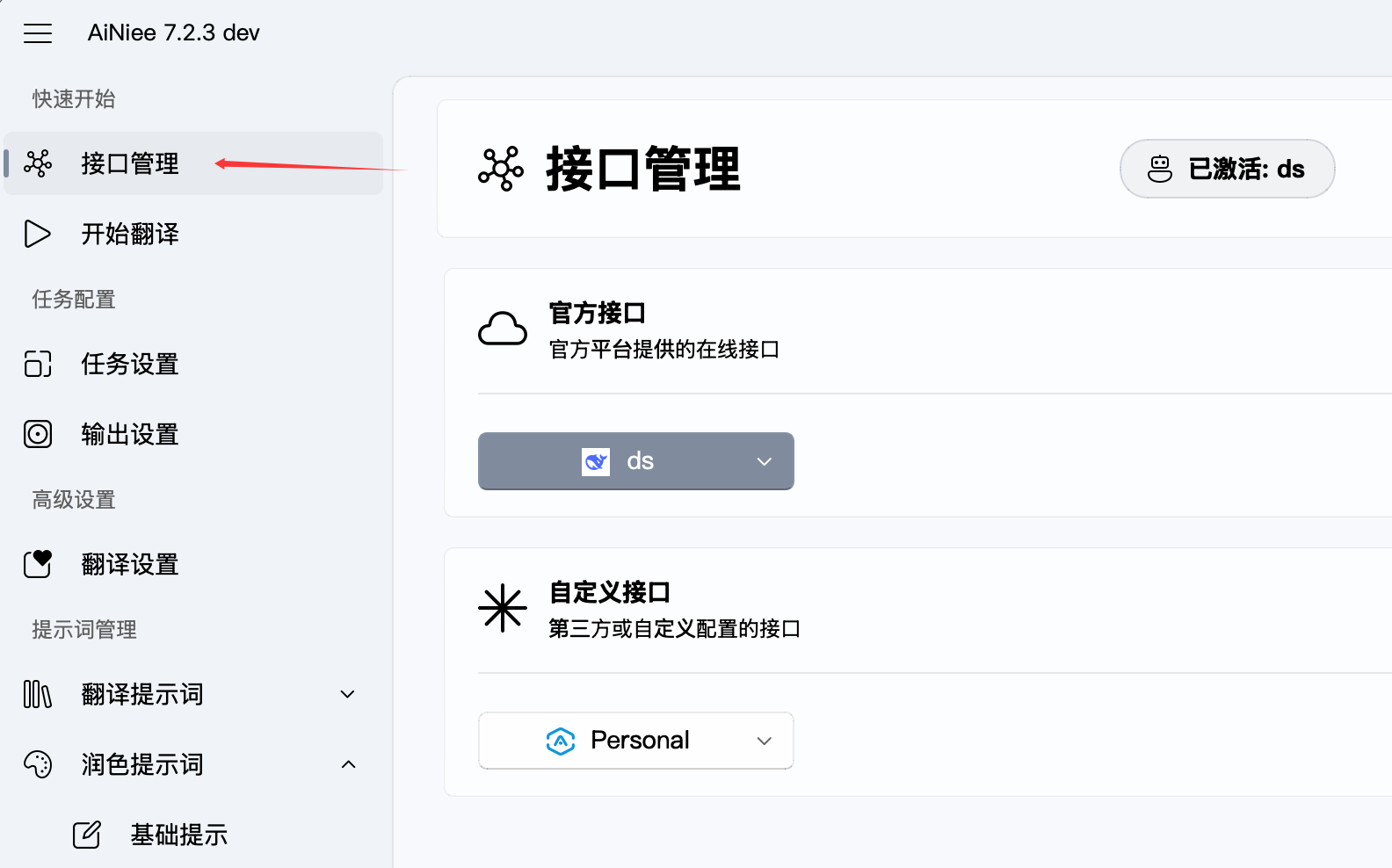
上面是 Deepseek 官方的模型,下面 Gemini 我用的中转,反正你偷我翻译数据就偷吧。「激活」代表是「现在使用的模型」。可以跑一下「测试」看看接口通不通
AiNiee 的翻译框架和导入项目

我们打开 AiNiee 会看到上面的界面,然后我一般会固定在项目的根目录跑 AiNiee 项目,然后创建一个 游戏名/ 的子目录作为项目的目录,把待翻译的 Json 文件放在这个目录下面,然后拖拽过去。我们可以把项目类型设置为 Mtool 导出
1 | AiNiee 项目目录 <- 启动 Python, 然后重定向 logging. 这里需要注意,AiNiee 可能会把打开的项目的配置记录在项目启动的目录下面. |
从图片中可以看到,这里支持很多的项目类型,那么 AiNiee 怎么统一这些项目的呢?他这里会有如下的抽象:
- CachedProject: 上面的
游戏名文件夹,会对应一个待翻译的工程。AiNiee 通常会把项目所在目录当成项目名,记录了项目的翻译进度和文件 - CacheFile: 待翻译的「输入文件」单元,对于我们这里的翻译流程,我们这里只会有一个待翻译的
ManualTransFile.json,但你如果放多个 json 文件在里面,它也会给你记录多个CacheFile - CacheItem: 待翻译的「最小翻译单元」,通常对应:
- 字幕:一条字幕块
- MTool/本地化 JSON:一个 key/value 对应的一个文本值。这里我们
"「その娘の"这样的 json key 就会被整理成待翻译的条目 - 文档:一个段落/一个单元块(取决于一些底层细节的 Reader 实现)
在实现上,CacheItem 内部会整理成 (source_text, lang_code, translated_text, translation_status) 这样的组合,记录了每个 Key 翻译的状况
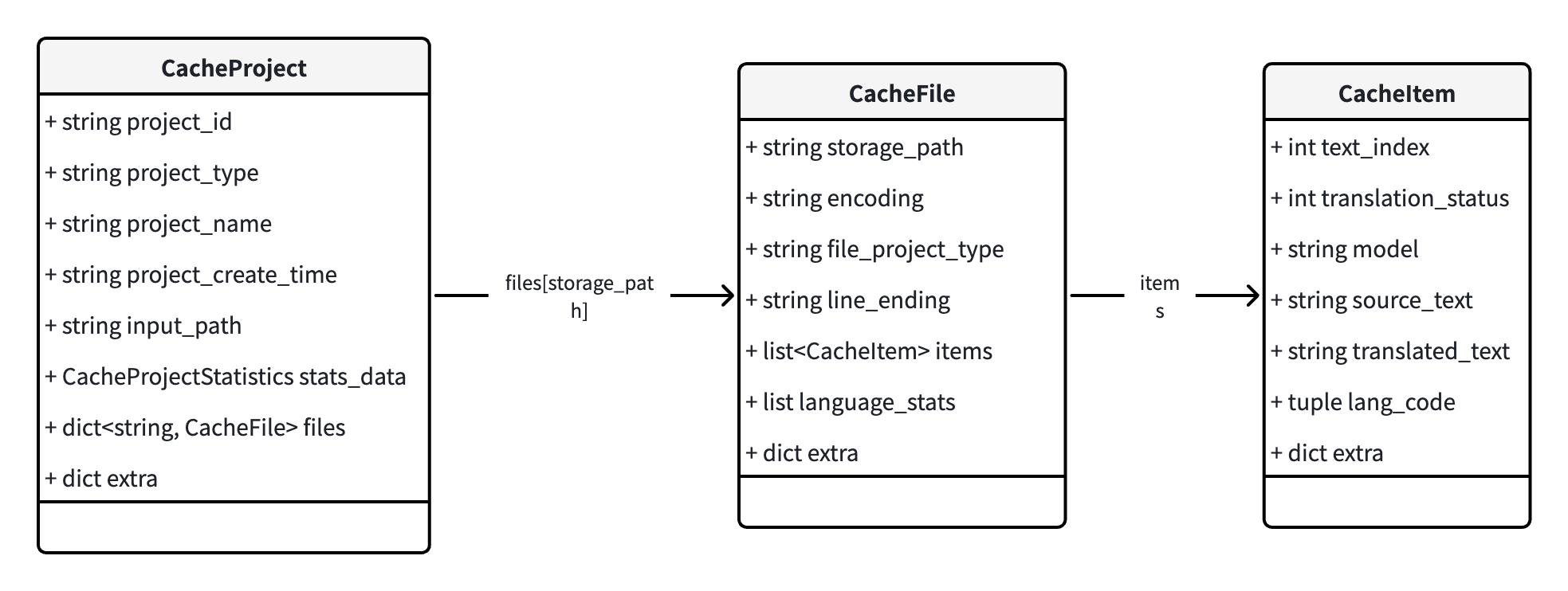
这里我们再额外介绍一下项目的工程,这里上面的内容会被存储到 Python 工作目录的 ProjecctCache 下面,每个项目有个 id,存放到 ./ProjectCache// 下面。然后所有的数据文件会存储成一个(比较大的)Json,感觉也是比较粗暴但是可能有用的方案。AinieeCacheData.json 会包含实际的项目目录,然后 ProjectStatistics.json 包含一些在启动页展示项目的轻量统计。
这里会:
- 对于 CacheItem,它会尽量组织成多个连续 CacheItem 的 chunk,一批一批的去翻译。这里我感觉 Mtool 这个 json 文件最好还是按照 token 来组织。这里会尝试用
tiktoken来算一下CacheItem的 token(也会有英文约 4 字符/Token,中文约 1.5 字符/Token 的降级估算),然后攒到我们需要的大小 - 请求的时候,AiNiee 会按照 RPM 和并发请求限制并发
- 翻译的时候,AiNiee 自带一些检查功能,建议先按照默认的来,然后如果翻译出错了,再判断原因。
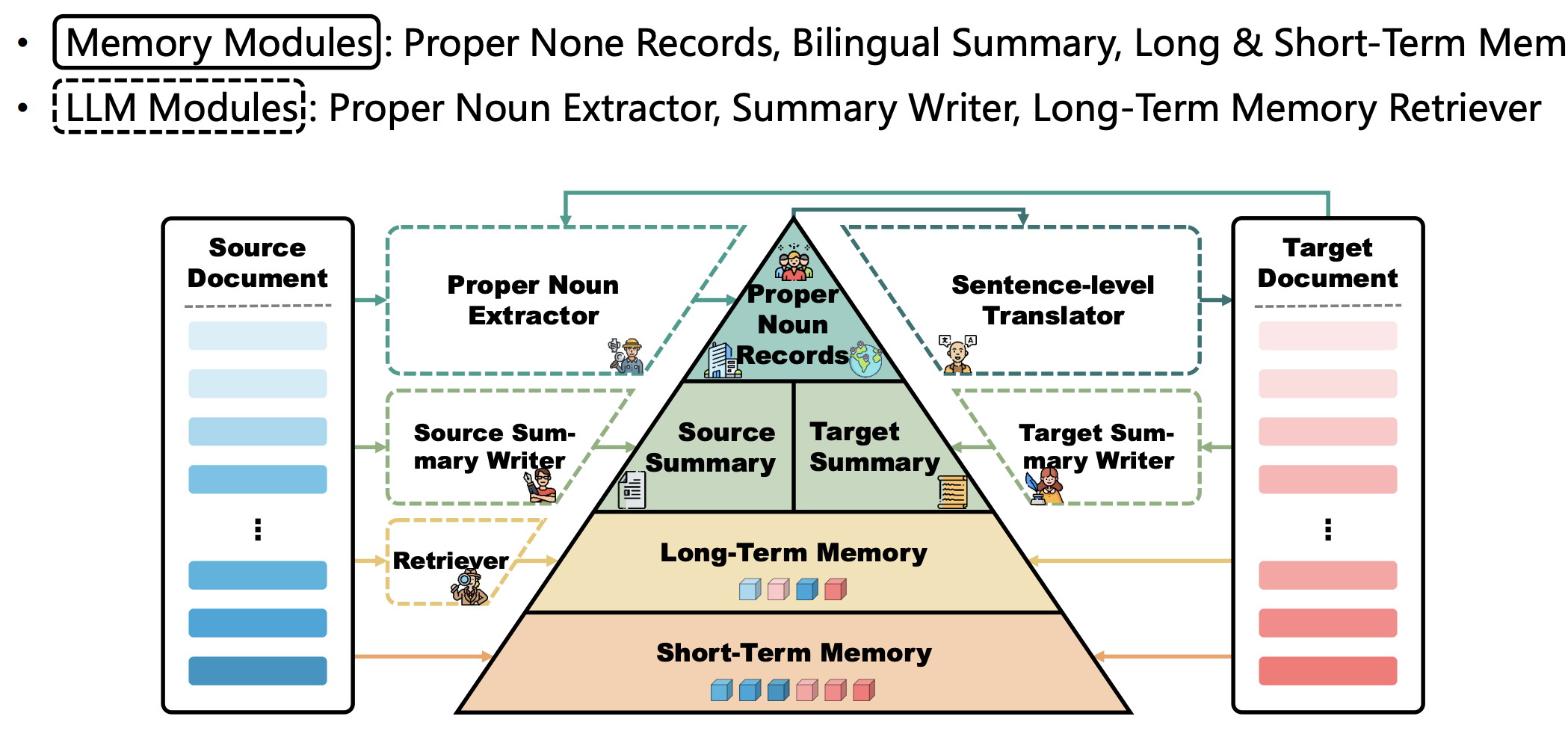
提取词表
这里的“提取”指的是:从项目原文中抽取 角色名(characters)、专有名词/术语(terms)、不应翻译的标记(non_translate),用于后续翻译质量提升(术语一致性、占位符/标签保护等)。
这里主要的优势还是对翻译提供一些「一致性」,主要流程相当于我们用 LLM 过文本,抽取出一些一致的信息,然后等待具体的汉化。这个阶段我建议用聪明一点的模型,因为文本比较乱的话,感觉不聪明的模型会整理出很多奇怪的信息,甚至错误的信息,增加校对的成本或者是直接给你错误的翻译。我个人会用 Gemini 跑这个阶段的模型。
提取词表有两种工具:
- https://github.com/neavo/LinguaGacha (外部工具可以导入)
- 用 AiNiee 自带的提取词表
这里会尝试提取你的文本,然后跑类似下面的 Prompt
下面是 LinguaGacha 的模版:
1 | - 只提取真正的专有名词或作品独创词汇,忽略通用的、已有固定翻译的日常词汇 |
而 AiNiee 会有下面的两组抽取 Prompt
1 | """第一阶段:独立文本提取(优化版提示词)""" |
可以看出来,这里提取词表是两阶段的:
- 把 CacheItem 组成 chunk,逐个 chunk 抽取。ANALYSIS_TASK 的
token_length在代码中似乎写死了CHUNK_TOKEN_LIMIT,为 10000。也就是说这里会按照估算的 10000 token 来一组包一个抽取任务。 - 合并 chunk 之间抽取的的信息
这里需要矫正的:
- 多个不同道具的名字是否可以折叠(其实可以让 LLM 来 Review 一轮),比如下面
1 | "トレス": "托雷斯", |
这里可以整理出「トレス」是个女性,然后下面可能 chunk 出类似的道具,但是用了别的翻译,这里一个是要把名字改成女性一点的,第二个是统一翻译。你可能很好奇为啥不能全匹配呢,答案是 "ウェイトレス": "女服务员", 啊,是个多简单的分词问题啊。
- 对出现次数少、且你不确定的词:宁可删掉,也不要把不确定的译名塞进词表
- 对容易歧义的词:不要轻易给性别/身份下结论,除非剧情明确
- 这里会自动抽取「短词挂靠长词」,AiNiee 会先在本地做启发式聚合:只要 other_source in source(子串包含)就把短词挂靠到长词的 group 上。
这种不一致的翻译让 LLM 翻译即使很强,但效果上还是会差点。举个例子,我找了本小说,分别用 Deepseek V4 Pro 和 V4 Flash 抽取,V4 Pro 能抽取个大概:
(下面会有一点模糊,有非常少数的事实错误。我突然感觉这个地方可以让模型 Double Check 一下,目前我还是通过手动检查来进行的。)
(跑着跑着我突然发现是不是应该加入一些 thinking 有关的参数比较好,诶)
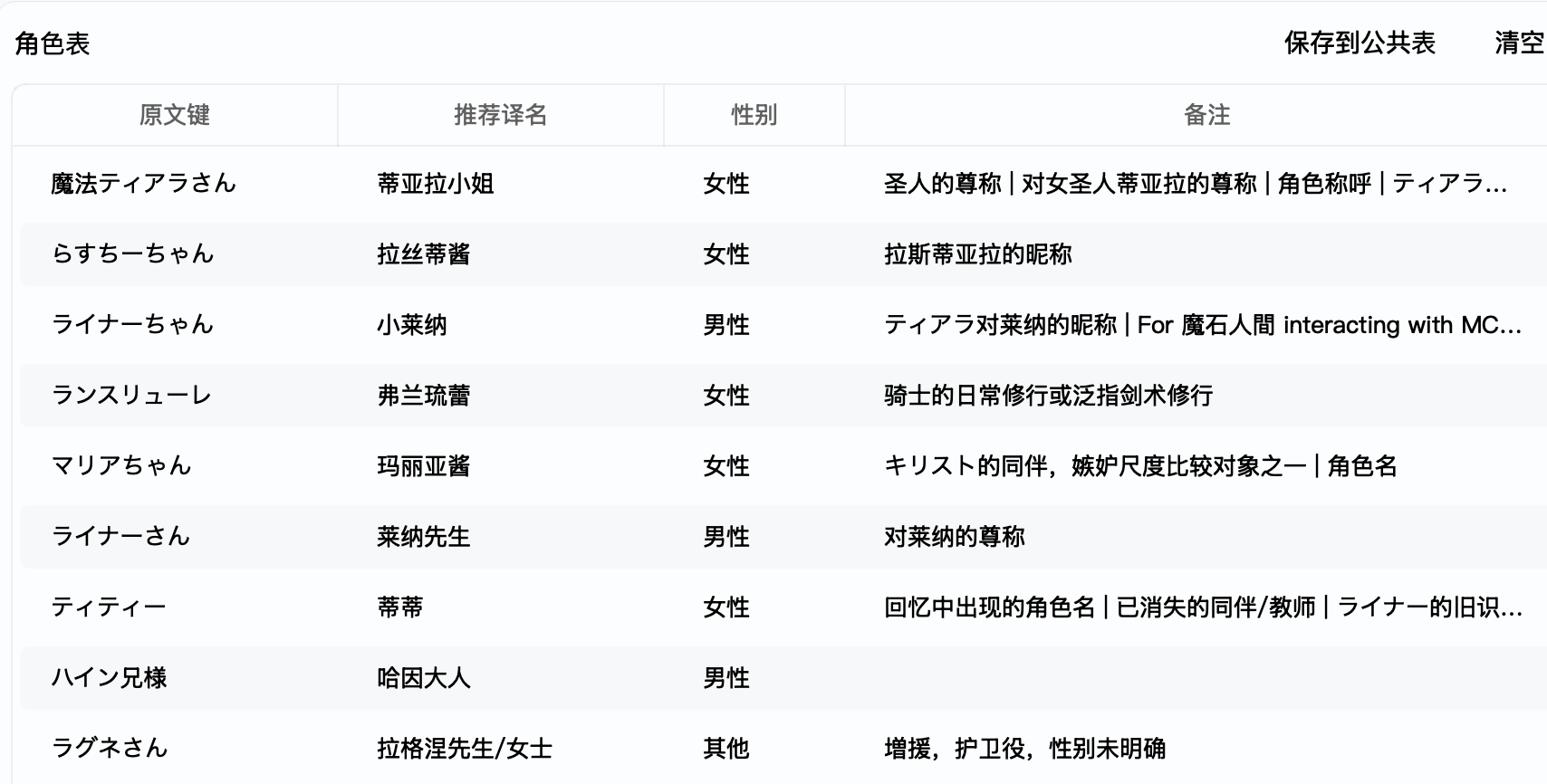
甚至还有

怎么他妈的 V4 Flash 抽取比 V4 Pro 好点,总感觉是 V4 Pro 是不是 RL 不太充分。不过 V4 Flash 还是会有「お兄さん」这种我觉得有点微妙不翻译也行的。
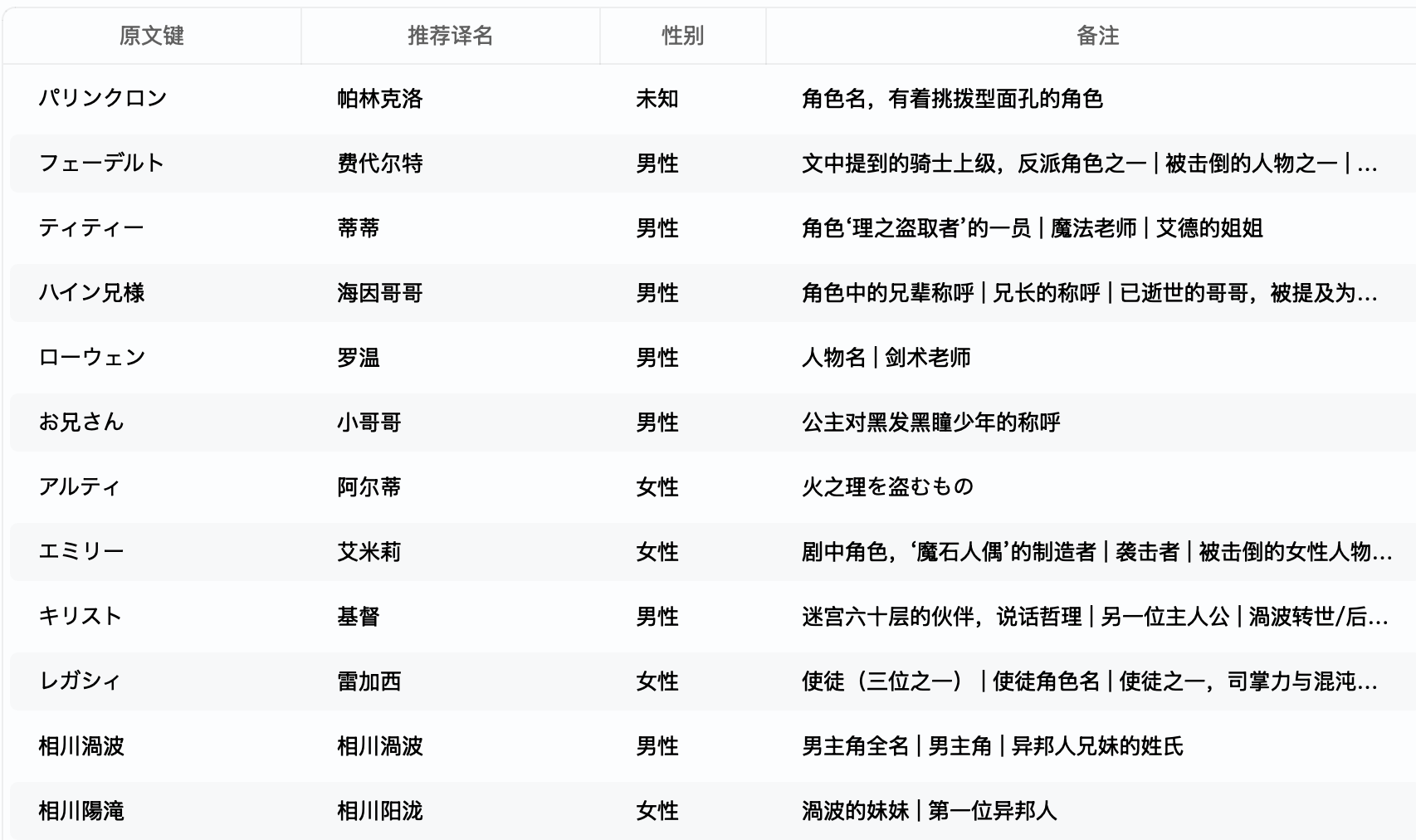
这个阶段,顶级模型感觉会好很多,或者开大点 thinking 也是个好主意,我就不这么试了。这里合并的时候可能会通过 | 放置一些并列的信息
这里我个人还是建议,如果你想精细汉化的话,最好还是审核或者处理一遍这个翻译表。如果有不确定的或者出现次数少的,不妨直接删除。
通过这个流程,我们就得到了一份词表了。
翻译的流程
我们接下来会有一些需要了解的配置:

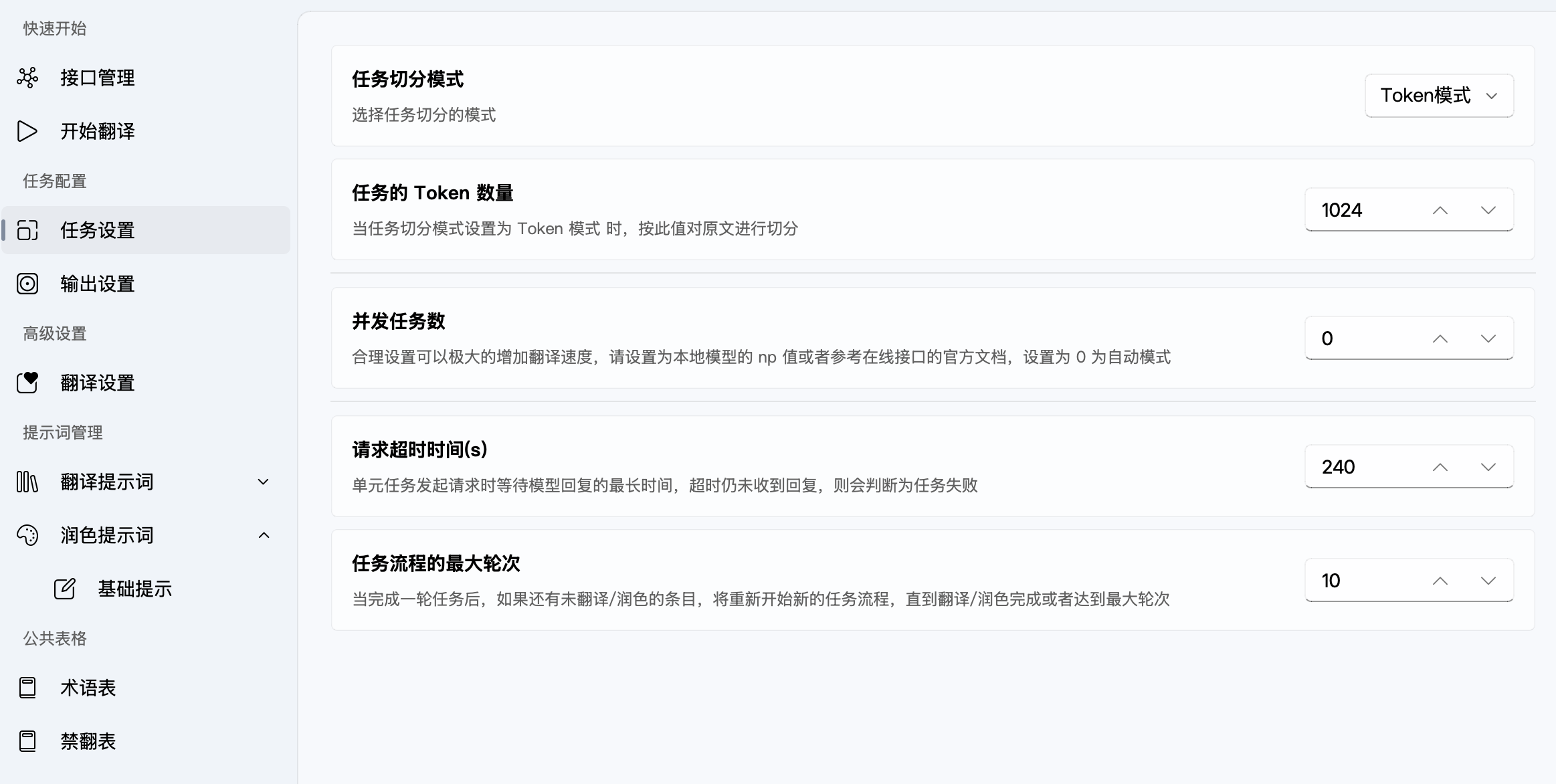
- 切分模式和切分 token: 我们刚刚提到,整理词表的 chunk size 是 10000 token,这个是不可配置的。但是看上面的图,我们可以选择按句子数量或者 token 数量来切分。这里的策略是装箱的 token 数量会尽量小于配置,除非是那种单条超过你的配置的 CacheItem(意思是,比如我配置 1024,这里会尽量小于 1024)
- AiNiee 帮你处理了很多脏活,比如预处理的日文的一些特殊 token 等,这里也有一些回复的 checking,比如语言检查,翻译残留检查。这些非常重要,建议部分检查默认开启。跑的时候如果发现报错,再去停止任务看 logging 看看是什么原因。举例来说,我用 V4 Pro 翻译的时候会抽风,输出 “翻译” == “原文” 的情况,这里 checking 就能很好检查出来。
- checking 本身让这让跑批翻译更可控
- 代价是失败时会整批重试,极端情况下,如果模型很难处理这个 case,那同一组 case 会一致报错,我个人建议正确率长期低于 90%、错误飞速累积的话,最好还是看一眼。
- 参考上下文指的是,这里虽然会一个个 Chunk 去翻译,但可能 Chunk 的第一句话或者前几句话需要一些前文(其实我下意识感觉后文带一点是不是也行)。我们会在之后介绍。
在翻译的流程中,我们现在会通过词表来翻译正文。AiNiee 在翻译正文的时候,会整理出下面的 Prompt:
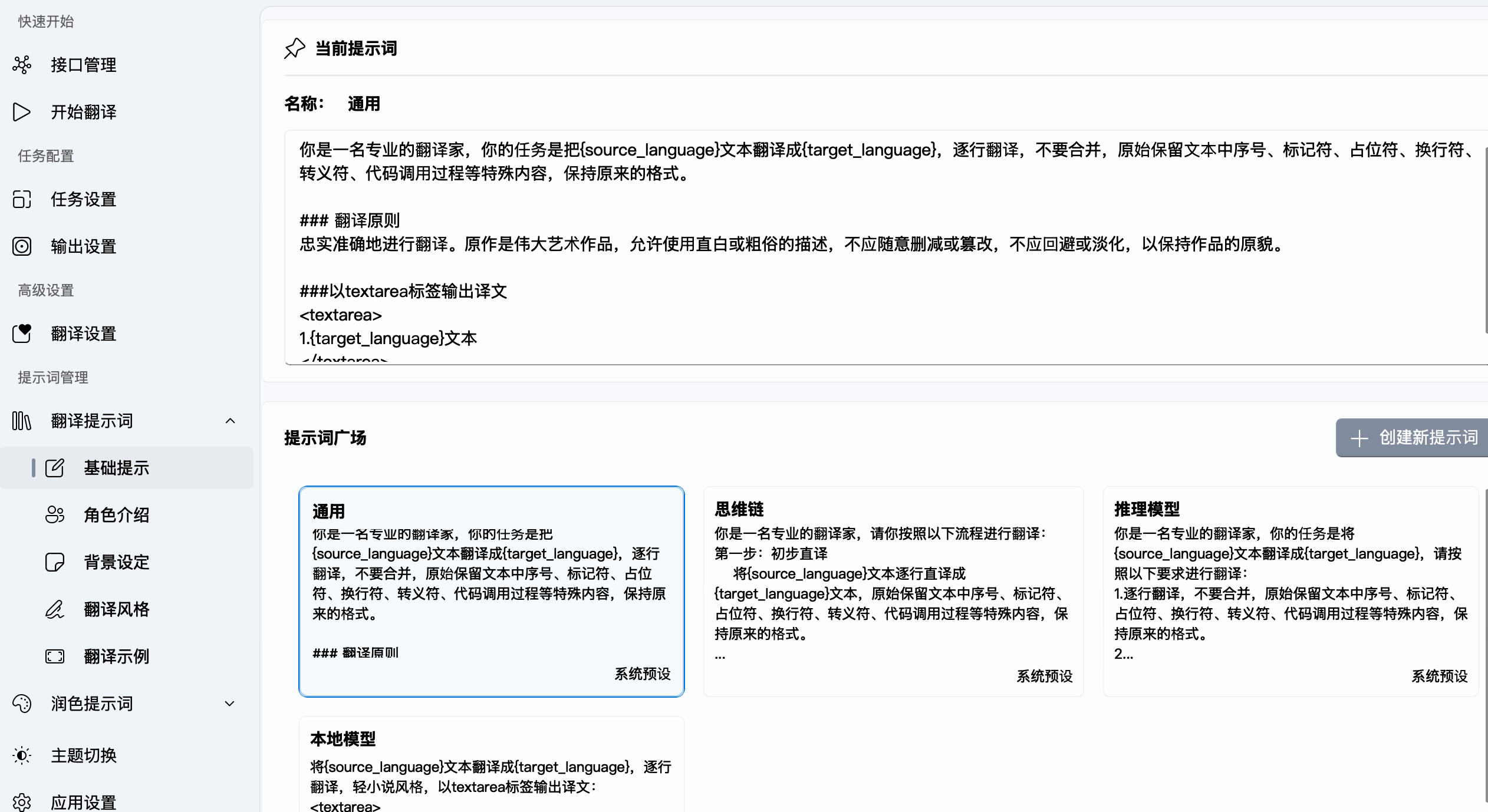
你可以按自己要求修改这个翻译的 Prompt。这里大概会整理出:
1 | ### 上文内容 |
翻译的成功和失败都是一整个 chunk 一整个 chunk 判断的,不存在 chunk 内单个任务成功、失败。那让我们开始吧,长任务会看到下面可能有一些失败请求
我们可以去输出里面看这里具体的情况,这里会有成功和失败的请求:
当我们发现问题的时候,可以按「停止」,如果「停止」,这里会等待 in-flight requests 都结束,可能要一定时间

这个阶段最终会在 output 目录下输出一个 _translated 文件,比如这里的小说翻译
润色?
润色的本质是 原文 + 译文 => 更新新的译文。其实我不是很喜欢润色,举个例子,如果用默认 Prompt:
1 | | 现在的你,处境究竟算怎么回事? --> 你自身的处境,又何其不堪? | | |
额,我觉得实话说有点太过头了,我自己微调过几轮,感觉这个模版不太好。我目前是不跑的,因为我比较希望翻译会保留原文的风格,不过这种对照原文还是有潜力的。我个人觉得:
- 如果你更希望保留原文风格:不一定要跑润色
- 如果你希望统一文风/增强可读性:润色有价值,但需要谨慎调 prompt(避免过度改写)
这里可以在「开始翻译」这里改成「开始润色」。
费用
我使用的模型有 Gemini Pro 3/3.1 和 Deepseek V4 Pro 两种
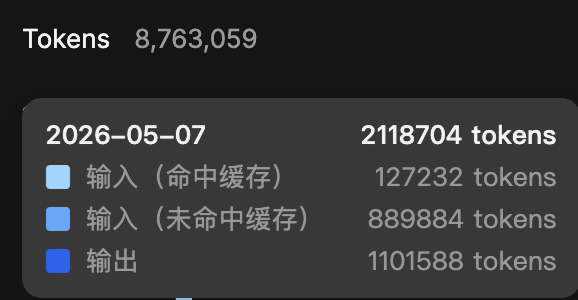
这是汉化 ワールドピース&ピース 正文的情况,使用 Deepseek V4 Pro,4M 文本大概花费 13 元。Flash 会比这个便宜不少,而且并发度会高一些,速度会快不少。
Gemini Pro 的翻译效果会好很多,但是成本也会高不少,我个人体验感觉成本会在 Deepseek V4Pro 的4倍或者以上的开销。
根据原理,这里其实只有 Root 的那些 Prompt 会过缓存,实际上翻译的正文都不会被缓存的。所以缓存命中率理论上就是会很低。
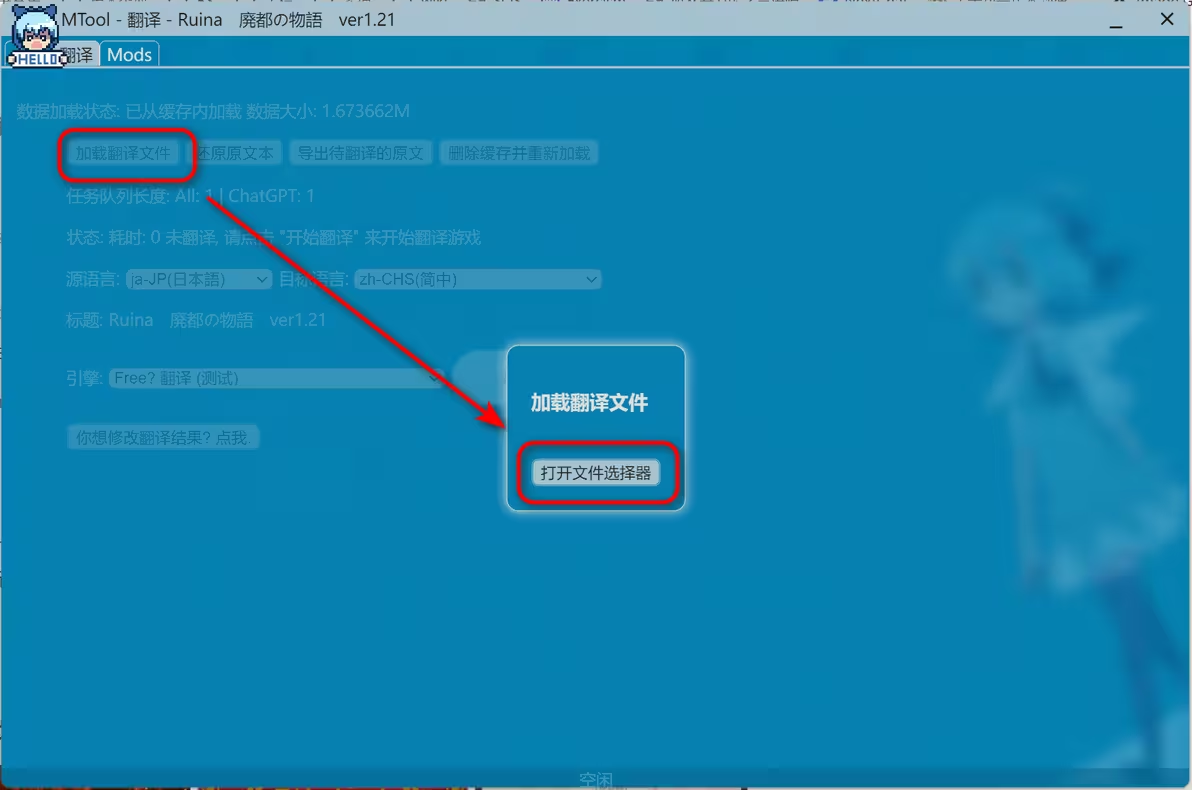
导入回 MTool
这里再借助之前博客的图,我们把翻译的输出文件和游戏放在同一目录下,用 MTool 打开游戏,并选择「加载翻译文件」,就可以玩啦!