/// This class represents the fixed-point numbers. /// The parameter "precision" represents the number of digits the /// Decimal Type can support and "scale" represents the number of digits to the /// right of the decimal point. template <TypeKind KIND> classDecimalType : public ScalarType<KIND> { public: inlineuint8_tprecision()const{ return parameters_[0].longLiteral.value(); }
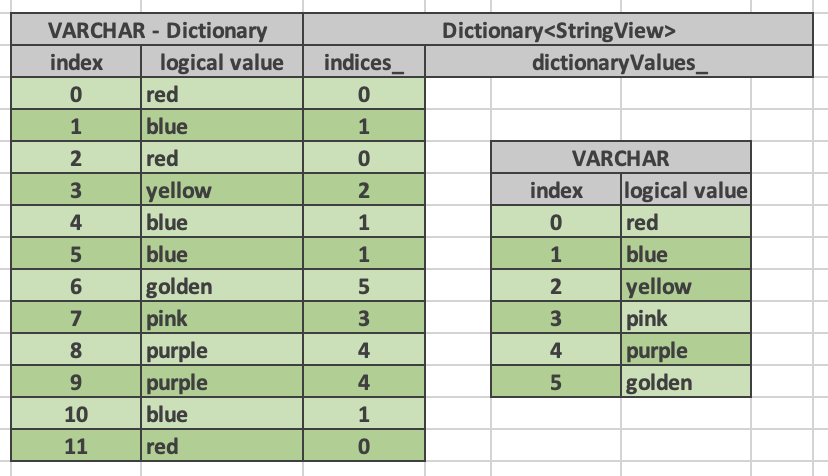
VectorPtr dictionaryValues_; // Caches 'dictionaryValues_.get()' if scalar type. SimpleVector<T>* scalarDictionaryValues_ = nullptr; // Caches 'scalarDictionaryValues_->getRawValues()' if 'dictionaryValues_' // is a FlatVector<T>. const T* rawDictionaryValues_ = nullptr;
// Indicates whether internal state has been set. Can also be false if there // is an unloaded lazy vector under the encoding layers. bool initialized_{false}; };
// FlatVector is marked final to allow for inlining on virtual methods called // on a pointer that has the static type FlatVector<T>; this can be a // significant performance win when these methods are called in loops. template <typename T> classFlatVectorfinal : public SimpleVector<T> { // Contiguous values. // If strings, these are velox::StringViews into memory held by // 'stringBuffers_' BufferPtr values_;
// Caches 'values->as<T>()' T* rawValues_;
// If T is velox::StringView, the referenced is held by // one of these. std::vector<BufferPtr> stringBuffers_;
// Used by 'acquireSharedStringBuffers()' to fast check if a buffer to share // has already been referenced by 'stringBuffers_'. // // NOTE: we need to ensure 'stringBuffers_' and 'stringBufferSet_' are always // consistent. folly::F14FastSet<const Buffer*> stringBufferSet_; };
template <typename T> classConstantVectorfinal : public SimpleVector<T> { // 'valueVector_' element 'index_' represents a complex constant // value. 'valueVector_' is nullptr if the constant is scalar. VectorPtr valueVector_; // The index of the represented value in 'valueVector_'. vector_size_t index_ = 0; // Holds the memory for backing non-inlined values represented by StringView. BufferPtr stringBuffer_; T value_; bool isNull_ = false; bool initialized_{false};
// This must be at end to avoid memory corruption. std::conditional_t<can_simd, xsimd::batch<T>, char> valueBuffer_; };
// A selectivityVector is used to logically filter / select data in place. // The goal here is to be able to pass this vector between filter stages on // different vectors while only maintaining a single copy of state and more // importantly not ever having to re-layout the physical data. Further the // SelectivityVector can be used to optimize filtering by skipping elements // that where previously filtered by another filter / column classSelectivityVector { private: // The vector of bits for what is selected vs not (1 is selected). // 这里的需求还是 bits 按照 8Byte 来对齐 std::vector<uint64_t> bits_;
// The number of leading bits used in 'bits_'. vector_size_t size_ = 0;
// The minimum index of a selected value, if there are any selected. vector_size_t begin_ = 0;
// One past the last selected value, if there are any selected. vector_size_t end_ = 0;
// Returns the index-th column of the base row. If we have peeled off // wrappers like dictionaries, then this provides access only to the // peeled off fields. const VectorPtr& getField(int32_t index)const;
/// Used by peelEncodings. voidsaveAndReset(ContextSaver& saver, const SelectivityVector& rows);
voidrestore(ContextSaver& saver);
// If exceptionPtr is known to be a VeloxException use setVeloxExceptionError // instead. // // 设置执行的 Error. voidsetError(vector_size_t index, const std::exception_ptr& exceptionPtr);
// Similar to setError but more performant, should be used when the user knows // for sure that exception_ptr is a velox exception. voidsetVeloxExceptionError( vector_size_t index, const std::exception_ptr& exceptionPtr); private: core::ExecCtx* const FOLLY_NONNULL execCtx_; ExprSet* FOLLY_NULLABLE const exprSet_; const RowVector* FOLLY_NULLABLE row_; constbool cacheEnabled_; constuint32_t maxSharedSubexprResultsCached_; bool inputFlatNoNulls_;
// Corresponds 1:1 to children of 'row_'. Set to an inner vector // after removing dictionary/sequence wrappers. std::vector<VectorPtr> peeledFields_;
// Set if peeling was successful, that is, common encodings from inputs were // peeled off. std::shared_ptr<PeeledEncoding> peeledEncoding_;
// True if nulls in the input vectors were pruned (removed from the current // selectivity vector). Only possible is all expressions have default null // behavior. // // nullsPruned_ 和 bool nullsPruned_{false}; // Error Handling 的上下文, 对 Try(T) 这样的肯定要处理一层, 此外 Velox 还会 Filter Reorder, // 这里应该都会影响 Error 的处理. bool throwOnError_{true};
// True if the current set of rows will not grow, e.g. not under and IF or OR. bool isFinalSelection_{true};
// If isFinalSelection_ is false, the set of rows for the upper-most IF or // OR. Used to determine the set of rows for loading lazy vectors. const SelectivityVector* FOLLY_NULLABLE finalSelection_;
// Stores exception found during expression evaluation. Exceptions are stored // in a opaque flat vector, which will translate to a // std::shared_ptr<std::exception_ptr>. ErrorVectorPtr errors_; };
auto* reusableResult = &result; // If result is null, check if one of the arguments can be re-used for // storing the result. This is possible if all the following conditions are // met: // - result type is a fixed-width type, // - function doesn't produce nulls, // - an argument has the same type as result, // - the argument has flat encoding, // - the argument is singly-referenced and has singly-referenced values // and nulls buffers. // // 这个要输出不是 Null 才行,为什么呢? 这块在计算的时候, 对于 producing Null // 的结果, 会 clearAllNulls: // 见 https://github.com/facebookincubator/velox/pull/1521 bool isResultReused = false; ifconstexpr( !FUNC::can_produce_null_output && !FUNC::udf_has_callNullFree && return_type_traits::isPrimitiveType && return_type_traits::isFixedWidth){ // 输入是 NULL 的时候才能使用. if (!reusableResult->get()) if (auto* arg = findReusableArg<0>(args)) { reusableResult = arg; isResultReused = true; } } }
// If this UDF can take the fast path iteration, we set all active rows as // non-nulls in the result vector. The assumption is that the majority of // rows will return non-null values (and hence won't have to touch the // null buffer during iteration).
ifconstexpr(fastPathIteration){ // If result is resuing one of the inputs we do not clear nulls, instead // we do that after the the input is read. It is safe because reuse only // happens when the function does not generate null. // // 如果 result 是重用的,那么就不用 clearNulls 了. if (!isResultReused) { (*reusableResult)->clearNulls(rows); } }
ifconstexpr(fastPathIteration){ // If result is resued and function is is_default_null_behavior then we do // not need to clear nulls. ifconstexpr(!FUNC::is_default_null_behavior){ if (isResultReused) { (*reusableResult)->clearNulls(rows); } } }
if (isResultReused) { result = std::move(*reusableResult); } }
// This is called only when we know that all args are flat or constant and are // eligible for the optimization and the optimization is enabled. template <int32_t POSITION, typename... TReader> voidunpackSpecializeForAllEncodings( ApplyContext& applyContext, const std::vector<VectorPtr>& rawArgs, TReader&... readers)const{ ifconstexpr(POSITION == FUNC::num_args){ iterate(applyContext, readers...); } else { auto& arg = rawArgs[POSITION]; using type = typename VectorExec::template resolver<arg_at<POSITION>>::in_type; if (arg->isConstantEncoding()) { // 展开成 constant reader, 然后继续 delegate 下去 auto reader = ConstantVectorReader<arg_at<POSITION>>( *(arg->asUnchecked<ConstantVector<type>>())); unpackSpecializeForAllEncodings<POSITION + 1>( applyContext, rawArgs, readers..., reader);
} else { DCHECK(arg->isFlatEncoding()); // Should be flat if not constant. auto reader = FlatVectorReader<arg_at<POSITION>>( *arg->asUnchecked<FlatVector<type>>()); unpackSpecializeForAllEncodings<POSITION + 1>( applyContext, rawArgs, readers..., reader); } } }
iterate 的代码很长,我们贴一下:
这里分为好几步:
判断输入是否有 callNullFree,有的话,传给 VectorFunction 的参数可能含 Null。需要做一轮 fast check
auto* data = getRawData(); // 写入单个 Result. // row: rowId // notNull: out isNull // out: 输出的类型. auto writeResult = [&applyContext, &nullBuffer, &data]( auto row, bool notNull, auto out) INLINE_LAMBDA { // For fast path iteration, all active rows were already set as // non-null beforehand, so we only need to update the null buffer if // the function returned null (which is not the common case). if (notNull) { ifconstexpr (return_type_traits::typeKind == TypeKind::BOOLEAN) { bits::setBit(data, row, out); } else { data[row] = out; } } else { if (!nullBuffer) { nullBuffer = applyContext.result->mutableRawNulls(); } bits::setNull(nullBuffer, row); } }; if (callNullFree) { if (applyContext.mayHaveNullsRecursive) { applyContext.applyToSelectedNoThrow([&](auto row) INLINE_LAMBDA { typename return_type_traits::NativeType out{}; auto containsNull = (readers.containsNull(row) || ...); bool notNull; if (containsNull) { // Result is NULL because the input contains NULL. notNull = false; } else { notNull = doApplyNullFree<0>(row, out, readers...); }
// 不用类型分发, 只是用 DecodedVector 来处理这块的逻辑,可能有一定的性能损失. template < int32_t POSITION, bool allPrimitiveArgsFlatConstant, typename... TReader> voidunpack( ApplyContext& applyContext, std::vector<std::optional<LocalDecodedVector>>& decodedArgs, const std::vector<VectorPtr>& rawArgs, TReader&... readers)const{ ifconstexpr(POSITION == FUNC::num_args){ iterate(applyContext, readers...); } elseifconstexpr (isVariadicType<arg_at<POSITION>>::value) { // This should already be statically checked by the UDFHolder used to // wrap the simple function, but checking again here just in case. static_assert( POSITION == FUNC::num_args - 1, "Variadic args can only be used as the last argument to a function.");
for (auto i = POSITION; i < rawArgs.size(); ++i) { decodedArgs[i] = LocalDecodedVector( applyContext.context, *rawArgs[i], *applyContext.rows); } auto variadicReader = VectorReader<arg_at<POSITION>>(decodedArgs, POSITION); iterate(applyContext, readers..., variadicReader); } else { // Use ConstantFlatVectorReader as optimization when applicable. ifconstexpr ( allPrimitiveArgsFlatConstant && isArgFlatConstantFastPathEligible<POSITION>) { usingvalue_t = typename ConstantFlatVectorReader<arg_at<POSITION>>::exec_in_t; auto& arg = rawArgs[POSITION]; auto reader = arg->encoding() == VectorEncoding::Simple::FLAT ? ConstantFlatVectorReader<arg_at<POSITION>>( static_cast<FlatVector<value_t>*>(arg.get())) : ConstantFlatVectorReader<arg_at<POSITION>>( static_cast<ConstantVector<value_t>*>(arg.get()));