Introduction to velox
Velox 是 facebook 内部开源出的一套单机的向量化执行引擎,facebook 希望 Velox 能够代替各大 AP 系统的执行层,并尝试用它来做 ML 系统和 ad-hoc 分析查询甚至 batch 查询的执行引擎。同时,在执行之外,它也提供了一点小小的优化能力。暂时不考虑有人提出的 RFC 中和写入、事务有关的部分,它负责的内容如下:
- IO,读取 dwio,Parquet, ORC 等内容(主要是 dwio 格式),同时也包括硬件介质(s3, ssd..)和本地的 cache;和远端资源交互
- 通用的、高性能、可扩展的 vectorize computing 算子、库实现(IO 的 Scan, Sink 也是一部分,但是我们暂且分开了)
- Type system, columnar memory data, expression evaluation, operators
- 资源管理:管理 memory arenas, buffer management, tasks, drivers, CPU 线程池和线程执行 and thread execution, spilling 和缓存
原则上,velox 接受 Query Optimizer 优化后的单机 Plan,用单机节点上的资源。上层要使用它可能要有一个转义层(例如,Presto 据说在尝试用,就起了个单独的项目 Prestissimo),用于要把转义的数据丢进来。当然,它还想处理类似 ML 等场景,这里有点类似前辈 Weld
Velox 比较大的贡献是提供了一套比较好的实际范本,东西算不上有什么新东西,但是在比较干净的情况下,把各点都做到了,项目也比较整洁。虽然行数比较多,但是大头还是在 functions 之类的很细节的东西上。部分代码虽然不算特别好(感觉是开源没开净或者留了坑),但是也算有比较高的完成度了。
Meta 把 Velox 开源出来希望能够共建,目前 Ahana, Intel, Voltron Data 之类的公司在共建 Velox,看了下 commit 频率,不比国内几个明星开源公司提交频率低。他们也希望,这波能一起嫖到标准化语义和新硬件的羊毛(这么看 Influxdb-io 上 arrow-datafusion 贼船是不是有点亏)。尽管有人认为,这东西可能会因为各种 API 都要写个转义层搞得非常恶心,但是这几家现在还是比较期待 Velox 能整出一个好活的
总而言之,闲扯这么多,我们还是介绍一些 Velox 的主要贡献。这里没有研究上的贡献,全都是工程上的:
- 完善的各类 expression / operator / io 实现
- 一些 adaptive 的算子选择、Lazy Eval 等
- 实验的 codegen
下面可以简单介绍一些,也贴一些简单的用户代码。
Type System
这里支持了 Scalar Type 和 Complex Type: https://facebookincubator.github.io/velox/develop/types.html
基本上都是从需求来的,从 Spark 和 Presto 里面弄来的各个类型。值得一提的是,有些个类型就特别纠结:
- (各种编码的)字符串
- (各种精度的)Decimal
- (各种)Timestamp
值得一提的是,对类型的检查被放到了表达式的 Compilation 阶段:https://facebookincubator.github.io/velox/develop/expression-evaluation.html#compilation 。而执行的时候,通常都已经做好了转型,要么就直接报错了。这块本来应该在后面介绍,但是鉴于这其实是 type system 的一部分,所以应该在 type system 这节介绍。
Velox 会有个 resolveVectorFunction 函数,它有个函数名称的 map 工厂,输入一个 ITypedExpr,然后可以拿到一个表达式里面所有的参数,然后走对应的列表,找到名称下所有的函数组,进行类型匹配,匹配通过就用,没有就找下一个,都没有就告诉用户。
用户还可以添加自己的类型扩展,比如 Presto 添加了 HyperLogLog,eg: https://github.com/facebookincubator/velox/commit/1e8e0d7c1db3f11ff322f702322070a968dab3df 。简而言之,用户可以比较方便的在 Velox 上封装类型和对应的实现。
Vectors
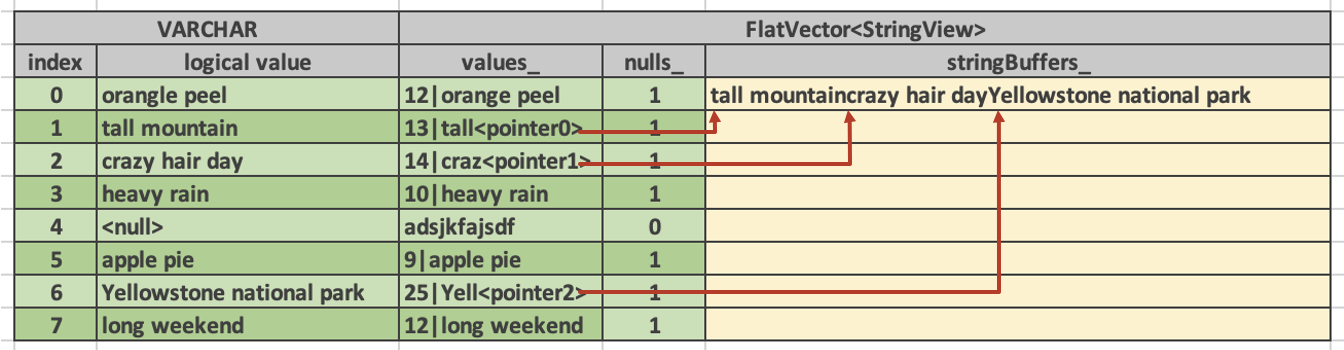
类似 Arrow 的 Array (这篇博客有很多不错的图:https://blog.mwish.me/2022/10/04/Parquet-Part2-arrow-Parquet-code-path/ ),Velox 也有一套表示列存的格式:Vector,内容和 arrow 差不多,我们主要关注区别:
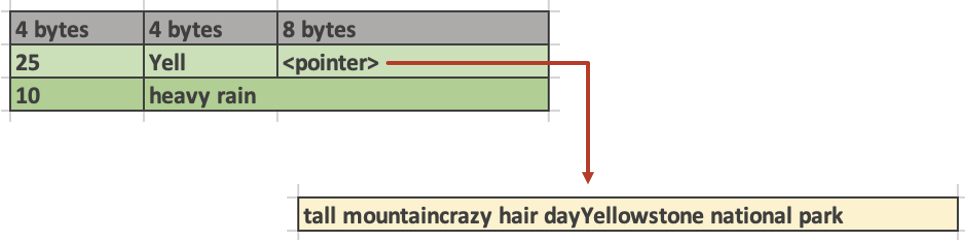
- 数据从 MemoryPool 中申请(记得 arrow 的 memory pool 吗?申请数据 64B 对齐那个),数据会被引用计数管理,只有一个 owner 的数据才可更改,否则要拷贝,不过允许 cow。
- 提供了 encoding 支持,类似 abadi 论文的 expression on compressed data:
- 支持 flat, dictionary, constant (前几种 arrow 也支持), Sequence(RLE), bias(FOR) 的编码
- 提供了
DecodedVector的抽象,来避免写一些if (XXEncoding) then ComputeOnEncoded() else if (encoding ) flatten的面条代码
- 支持 Lazy Evaluation。这个类似我们在 Presto 论文提到的,可以减少一定的 filter 量,同时甚至可能减少 IO ,比如(减少 io 是个很 hack 的事情,尤其是你如果做了 prefetch…我对论文的态度抱有苦笑般的怀疑)
- 这里还支持 pushdown,这个感觉像是和上面 encoding 有点重复,相当于把计算下推来避免 materialize 的开销
- 在字符串处理上,参考了 TUM 的 Umbra,如下面的读。这里相当于在数据库方面做了短路负载,让大部分操作熔断在短字符串处。此外,arrow 的 string 本身要求是在一个 buffer 中连续的,处理方式类似 array。Velox 认为这也能加速 substr 之类的操作,让对应长字符串减少 copy。
- Out-of-order write: 对于 switch case 或者 if else,在向量化中,会算出一组位置或者 true/false 向量,然后让对应的地方写。这个对一般的类型优化不大,但是对变长类型可以有一定的优化。比如说,有一组 if else 向量,然后写 string 类型。对于 arrow 来说,因为内容在 buffer
- Velox 还提供了转成 arrow 的 api,我觉得这用来拉屎非常方便

Expression Eval
Velox 的查询最早会是一个 Plan Node 组成的树,经过 Planner 成为一个 Pipeline + Operator 的结构。
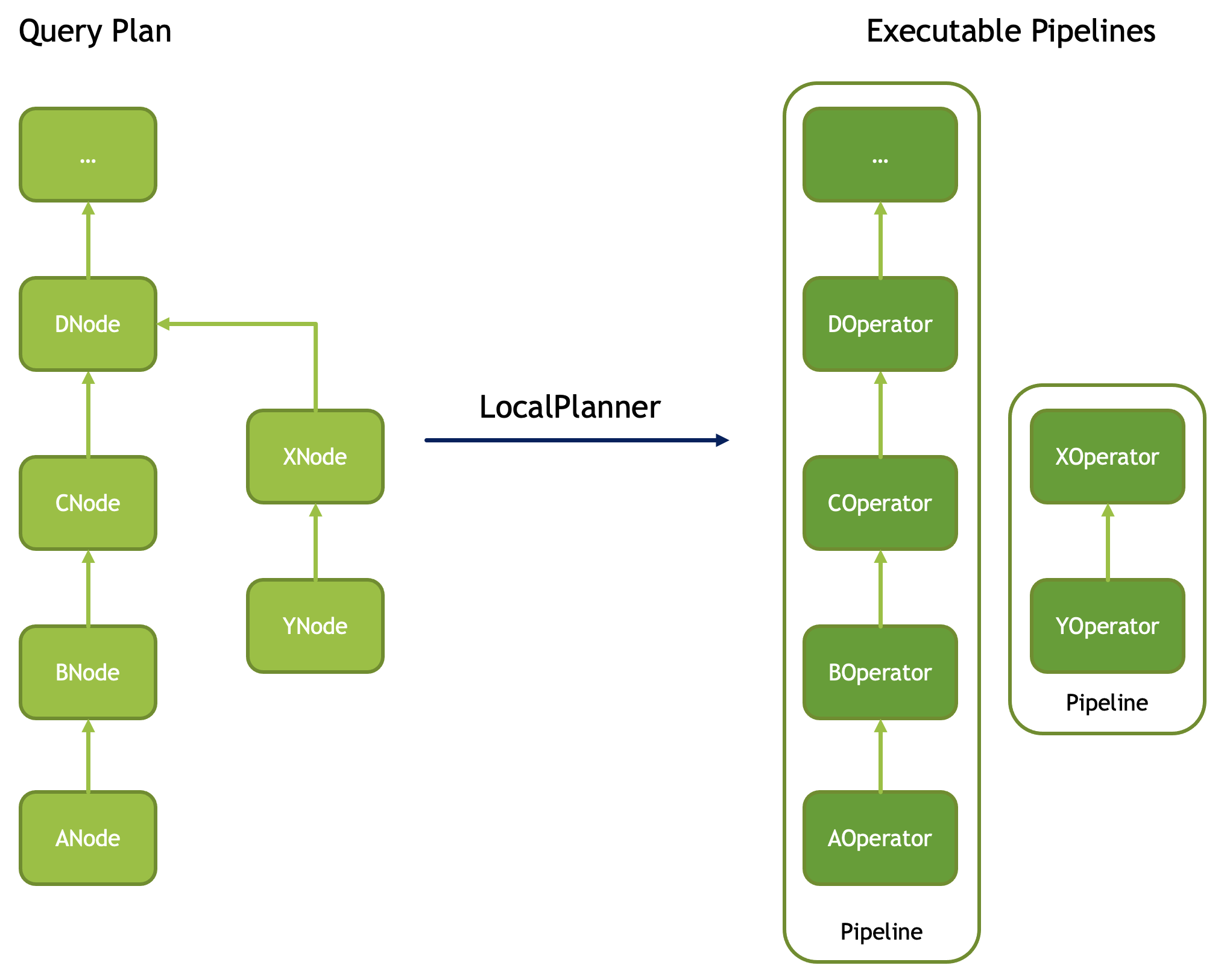
而在 FilterNode, ProjectNode, AggregationNode, 各种 Join 的 Node 和 OrderBy 的 Node 中,会有各种 Expressions。在 Velox 中,处理前的 Expression core::ITypedExpr 会在 compile 后绑定执行需要的 core::Expr. Expressions 包含:
- FieldAccessTypedExpr
- ConstantTypedExpr
- CallTypedExpr
- 前几个都比较简单,这个包含了 and, or, if, switch, cast, try(try 一个表达式,有问题返回 null), coalesce (返回第一个非 null 的表达式)
- CastTypedExpr
- LambdaTypedExpr
这些 ITypedExpr 会组织成一个表达式树的关系,从 root 连接到子节点,可能是个 AND 树之类的。同时,表达式也会有一些 metadata 作为标记,比如是否 determinstic、null propagation 的性质,见:https://facebookincubator.github.io/velox/develop/expression-evaluation.html#expression-metadata
表达式树的执行不是 push / pull 的单向流,而是每个 batch 自 root 到叶节点的求值,然后根据下层节点的结果,最后产生一组某个类型的 Vector。
- 表达式是否是 deterministic 的(rand, shuffle 外的大部分函数都是)
- propagatesNulls: 输入为 null 的时候,输出是否为 null,可以在输入为 null 的时候免去一些计算
- …
这些 attributes 能在执行端在表达式上给出很大的优化的空间。举个例子,如果输入被发现,虽然有很多行,但是限定在字典内等,就会有很大的优化空间。或者发现会 propagate null 的话,是 null 的表达式就不用再被折腾一茬子,直接 null set 传递。
Compilation
Compile 阶段会拿到一个或多个表达式树,首先会进行类型匹配的计算(详见之前的 Type System 一节),然后会进行一些简单的表达式优化。这一点其实有那么点点怪,有的优化是执行上的,因为 Velox 自己执行的时候可以抽出很多上面所说的 attributes,然后利用里面的特性来优化。感觉一般的系统中,因为没有这种 plan - plan 之间的 gap,所以没有这么一个「再优化」的转换层。
这里他会把 TypedExpr 转成具体的 expr,具体链路如下:
1 | - compileExpressions // 处理多组 (vector<ITypedExpr>) |
在这个流程中,还有一些特殊的优化:
Common SubExpression Detection
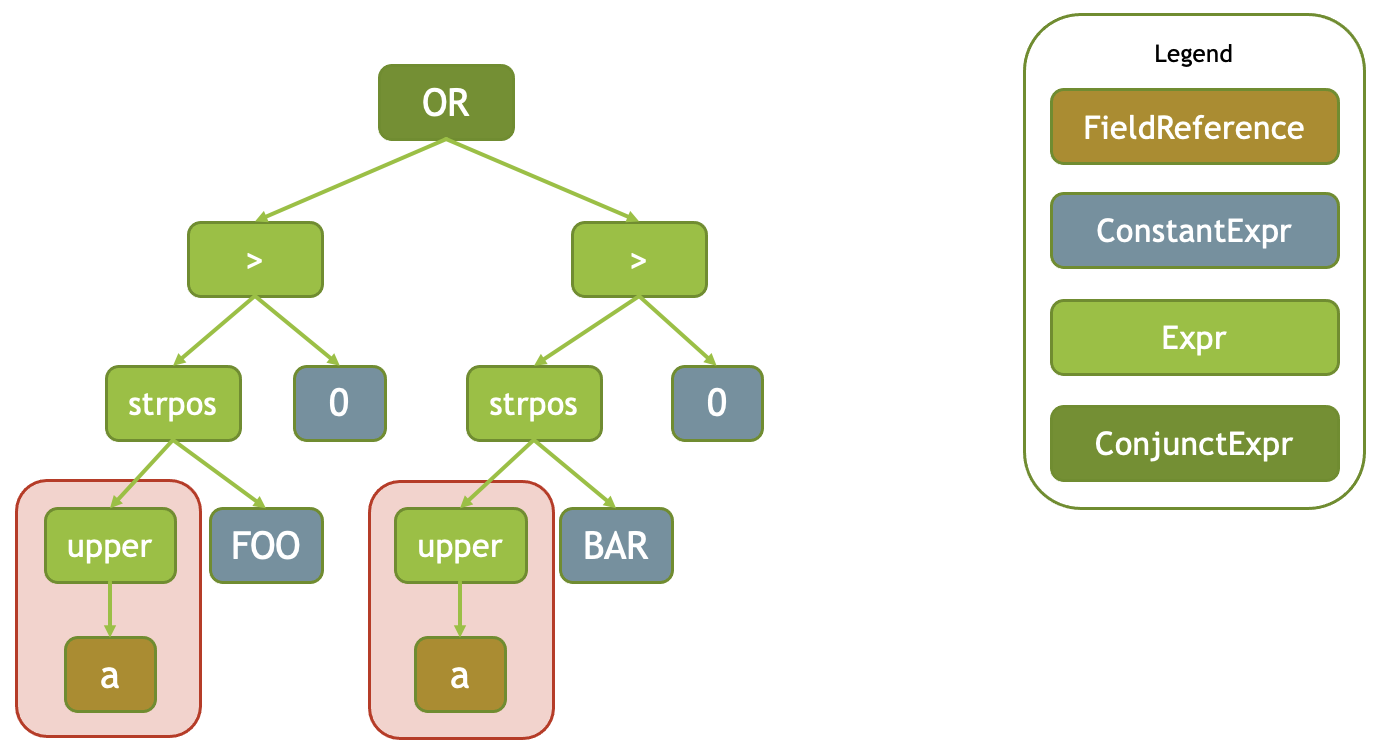
在 Expression 编译的时候,会有一个 Scope 做上下文。Scope 间也有父级关系。这里它会把编译好的表达式丢到 Scope 中,当表达式生成了两遍 upper(a) 的时候,他们会被用同一个表达式进行计算。
Flatten ANDs and ORs
表达式会标注可否 fold。velox 会尝试去 fold 这些表达式树,这一部分发生于 Compile 阶段
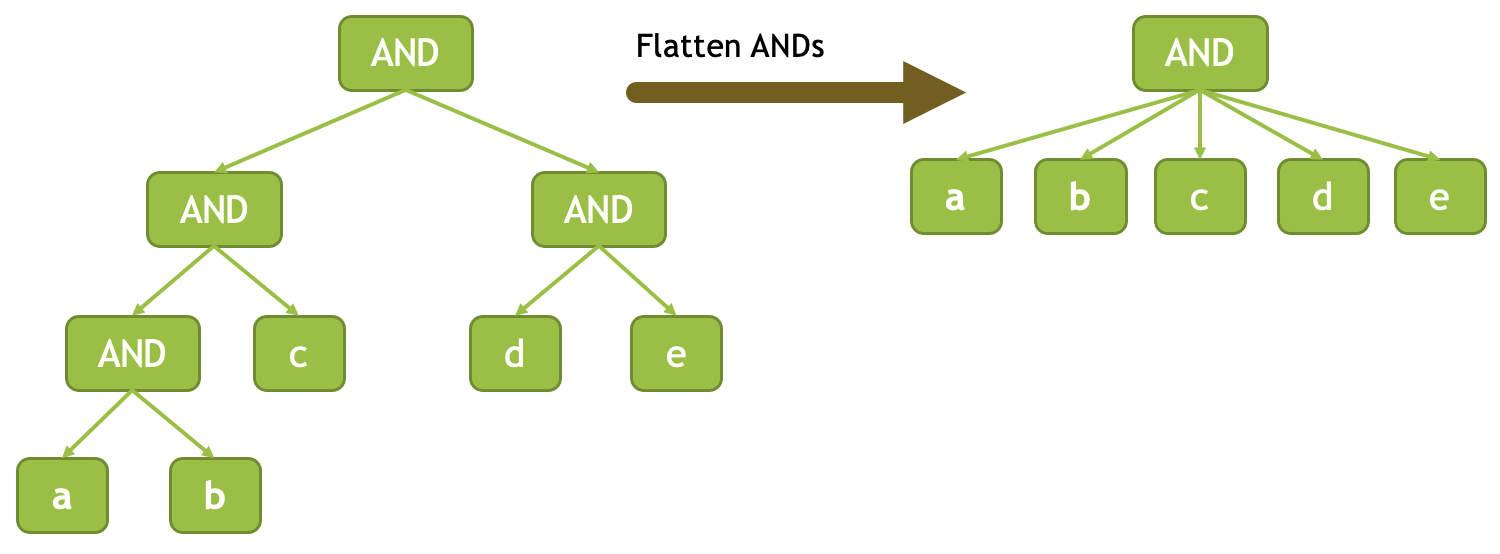
flatten concat-like functions
这里和上面类似,比如 f(x1, f(x2, f(x3, x4))) == f(x1, x2, x3, x4),这里会尝试折叠,避免深栈
Constant Folding
做一些常量折叠,相当于提前计算。
Adaptive Conjunct Reordering in AND and OR
这个在官网上是一个执行端策略,而在代码里…我在 compile 没看到,在 ConjunctExpr::evalSpecialForm 里面,发现了相关的方法 maybeReorderInputs()。看来论文也存在吹牛逼成分?还是后面被移走了?
这里会根据 and or 的 selectivity 选择,计算的时候,这里会统计 selectivity,and 会尽量前置 false 的表达式,or 会尽量前置 true 的表达式,来动态适应性熔断表达式计算。
Evaluation
在执行端,FilterProject 的 operator 会一次性完成 Filter + Project 的执行,输入是 EvalCtx,包含 RowVector 和 SelectivityVector. ::eval 方法用来评估表达式。
ExprSet 包含一个或者多个 Expr, 它会调用 Expr::eval。执行的时候,这里会判断是否是一个重复的子表达式,如果是。这里会缓存计算结果。
当输入是字典编码的时候,确定性的表达式可以只算字典中的 distinct value。文章举了个例子,UPPER(colors), 然后 colors 只有 red, blue, yellow 三种,但有很多值的时候,算这三种就行了。这种技术具体执行大概如下:
Expr::peelEncodings (): f(g(input)) 中,进入表达式,表达式发现这一点,然后把输入换成字典的 distinct 输入了
这里还有字典的 memorizing,结果就比较简单:字典没变更就一直用同一个字典对象。
会 propagate null 的话,是 null 的表达式就不用再被折腾一茬子,直接 null set 传递,如果是字典的话,允许把字典里一些东西设置成 null。
Velox 官网有个一图速通,我看了下,和代码是对的上的:
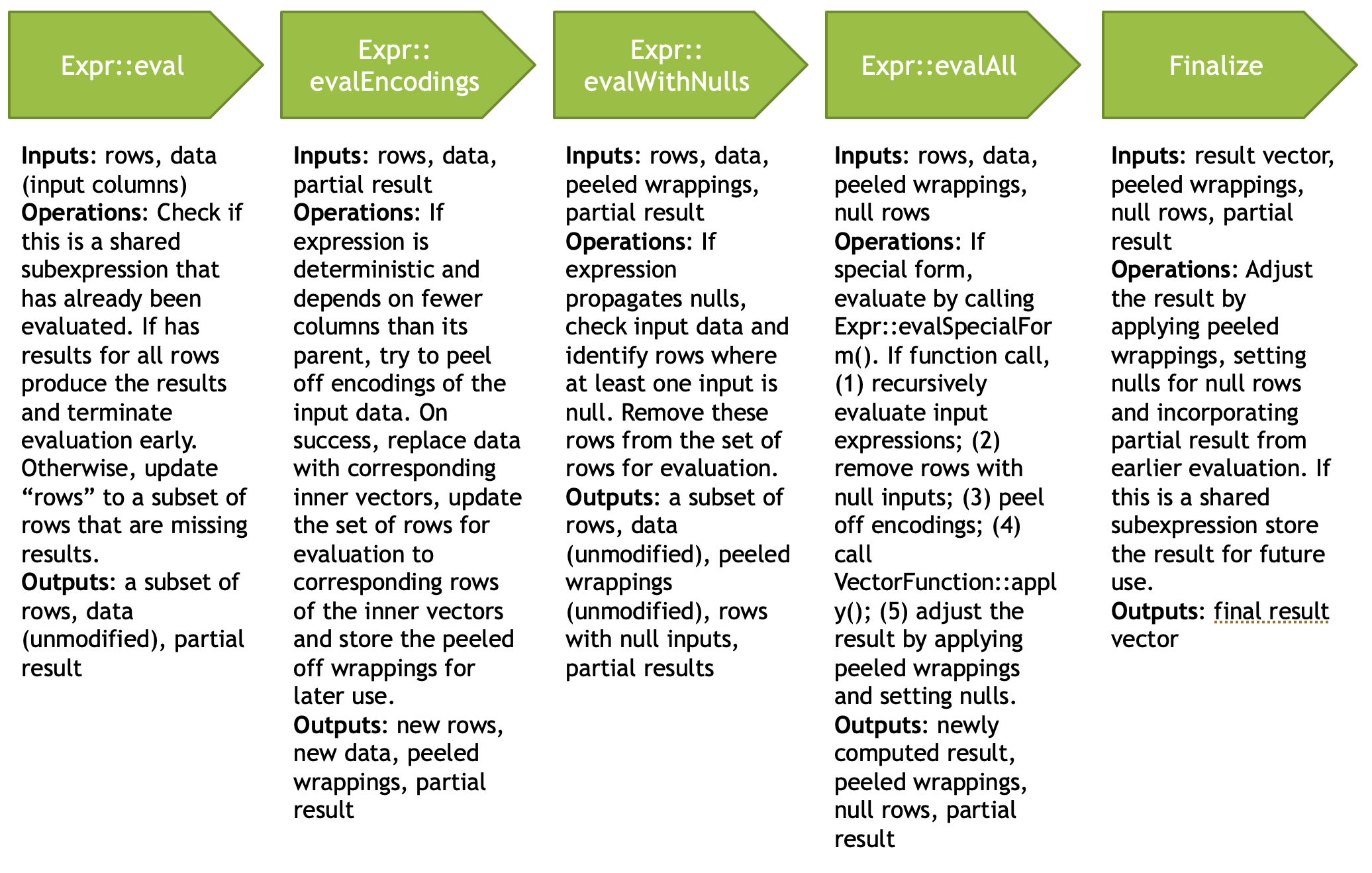
Flat No-Nulls Fast Path
和我们刚才的 propagateNulls_ 和处理相对,这里如果全部非空,那么可以 skip 一些 null handling,根据原文,在小于 1000 rows 的短表达式中,这种优化相对能起到比较好的效果。在 Velox 中,Vector functions (后面会介绍) 会提供一个 supportsFlatNoNullsFastPath() 的语义,来帮助评估走 fastPath
Evalution If/Switch..
先执行 condition,然后去按序执行 cases: https://facebookincubator.github.io/velox/develop/expression-evaluation.html#evaluation-of-if-switch
Codegen
在论文写作的时候,Velox 会讲表达式生成 C++ 代码,然后动态链接到程序中。日前,Velox 采用的还是直接用编译器编译,而没有用时髦的 LLVM-codegen。文章认为 codegen 对 ETL 这种大 job 可能效果好一些,因为表达式整体都不会变,而 ETL job 反正会很大。
目前,Velox 基本还是全部向量化的方式,codegen 代码在 experimental 下面。
Functions
用户可以认为,某种程度上 functions 是 expr 的一个小部分(Call 有关的 Expr)。Velox 内部提供了不少该有的函数,同时,用户也可以相对方便的添加函数。比较恶心的是,这帮人感觉没那么那么懂 C++,所以…加起来也有点小蛋疼。这体现在什么地方呢?一来 Velox 区分了 Vector 的函数和 Simple Functions,然后还有之前我们提到的各种 determine 等等,这些东西叠起来,加上类型系统做的比较糙,总的来说加东西也没有那么方便。当然,相对自己从头开始写,肯定是很丝滑的。
对于接收单个输入返回单个输出,确定类型的函数,即 Scalar Functions。 Velox 认为,Simple Function 不是那么好优化,而且向量化也容易出错的情况下,可以使用 Simple Functions + 向量化的方式来处理问题。Velox 会使用一套框架来包装 Simple Functions,然后尽量让其能自动向量化。
Velox 在编程框架上也做了很多优化,比如标注是否 nullable,使用 zero-copy,处理 deterministic。论文还提到了一项关于编码的优化:让用户指定 ASCii, Utf8 等编码,同时可以尽量优化其中的拷贝,可以 ref 原内容的地方不需要拷贝。
(越写我觉得越像 TiKV Coprocessor 了,想起我的青春年华和失败记忆了)
(论文甚至没怎么提 Vectorize functions,估计是觉得跟用户介绍最简单的就行,不过我觉得 Vectorize 的部分也挺有意思的:https://facebookincubator.github.io/velox/develop/scalar-functions.html#vector-functions )
Aggragations
Aggragations 在 Agg 相关的 Operator 下头,使用 HashAggregation 进行相关的计算
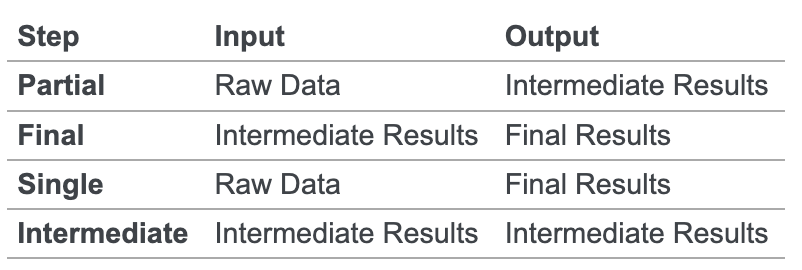
- Partial: 类似 shuffle 中使用的,根据数据生成一些中间结果
- Final: 处理
Partial的结果 - Single: 数据很小不用 shuffle,或者数据已经被按照 group key 来做 partition
- Intermediate: 类似 MR 中的 shuffle,从中间数据生成中间数据,在 Partial 和 Final 之间
Sum, min, max 中,partial 和 final 做的是同一种计算,而有的操作则不同。比如:
1 | SELECT a, b, count(c) FROM t GROUP BY 1, 2 |
partial 会做一些分区操作,Final 则是将 partial 数据合并起来。
Aggregations 结果的内存管理
这里类似行存的数据库,会有如下的格式:
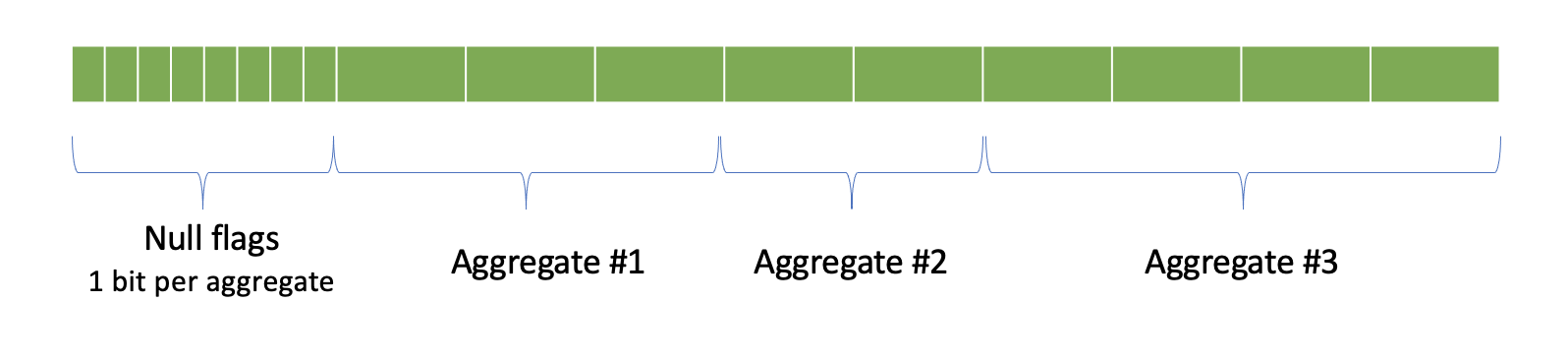
Velox 会识别出操作是否是定长操作,然后做处理。
如何添加一个 Aggregator
为啥这个要专门写呢?因为这个我们可以考虑一下,Agg 很多时候是带一些上下文的,比如对列的 map。论文里面连 function 都只介绍了 simple…
(这个地方我又想起了 TiKV Coprocessor 那堆 proc macro 和我那失败的青春)
参考:https://facebookincubator.github.io/velox/develop/aggregate-functions.html#aggregate-class
这里会考虑几种 agg:
Global aggregation, two aggregates: “count” and “sum”:
1 | SELECT count(*), sum(b) FROM t |
Aggregation with three aggregates: “count” and two “sum”s.
1 | SELECT a, count(*), sum(b), sum(c) FROM t GROUP BY 1 |
首先,需要考虑各个阶段,比如 Prepare阶段的数据准备,其次考虑中间数据是否是定长的,这个会影响行相关的访问和写入(Accumulator size)。然后可以分别实现对应 global aggregation 和 groupby aggregation 相关的内容了。
Plan Nodes and Operators
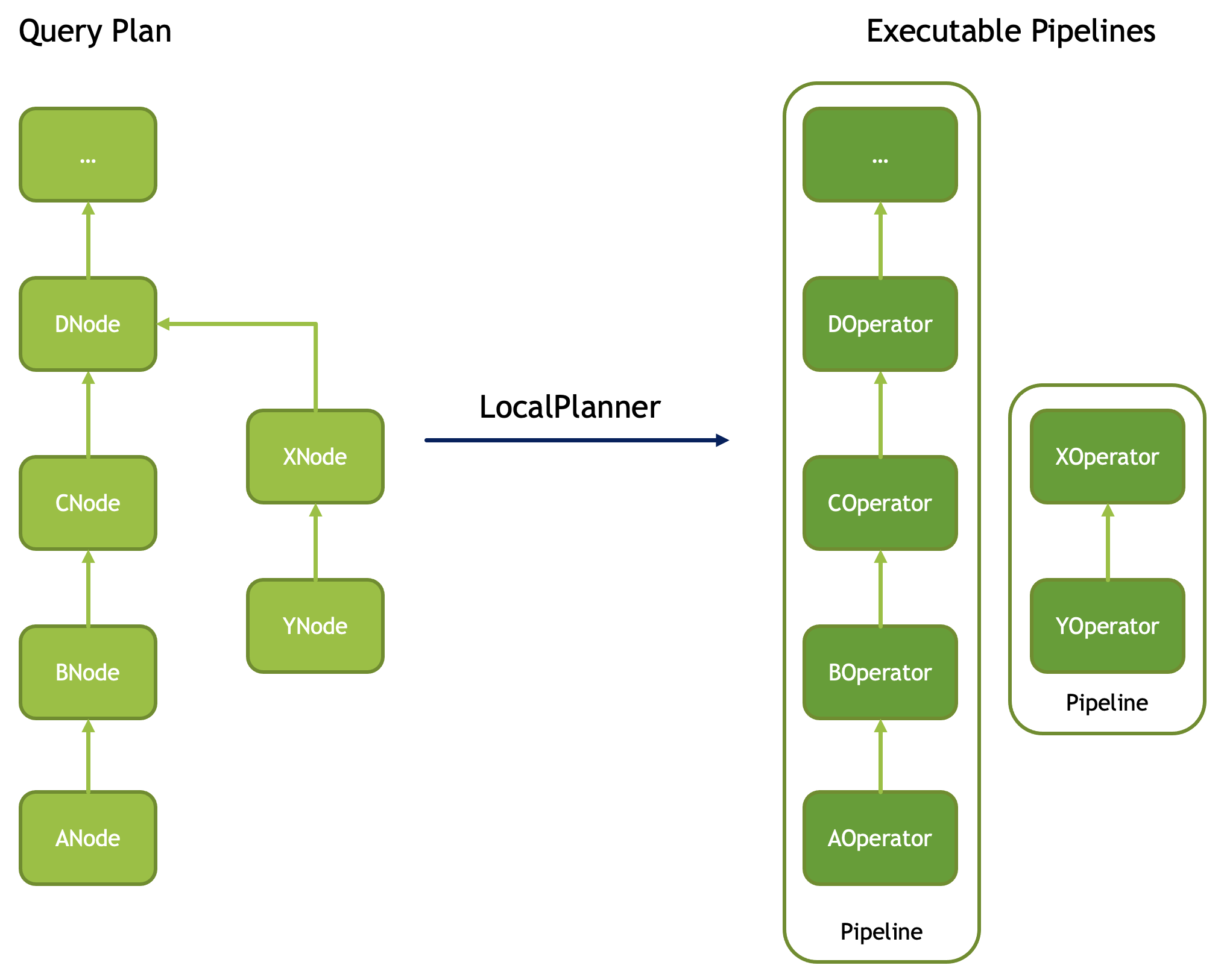
Plan Node 和 Operator 的映射几乎是一对一的,当然有几个例外:
- Filter node + Project node 会被折叠成
FilterProject( 我们之前还提到过它,嘿 ) - 多于两个子节点的会被拆分,比如说 HashJoin 会拆成 HashBuild 和 HashProbe
有一些特殊的地方可以参考:https://facebookincubator.github.io/velox/develop/operators.html
类似 Presto 的概念,里面的执行单元上层概念叫 Top ( Presto 的 Job 是一个带点分布式意味的单元,而 Velox 则是单机的)。Task 数据可能来源于 TableScan 或者 Exchange,然后可能以另一个 Exchange 结尾。这里会有 Pipeline 来驱动执行,每个 Pipeline 可能有一到多个执行的 Driver,Driver 可能 bound 在一个线程上,并管理执行的状态。这部分类似 Presto 了,感兴趣可以回头看看。我们就专门挑一些 Velox 介绍细一点的概念图来贴吧,都读到这了,高低得学点新东西是不。
这里举了一些 HashJoin 和 Local Exchange 的例子,这些都是为了扩大并发,注意,下文为例子,不代表实现一定会这样:
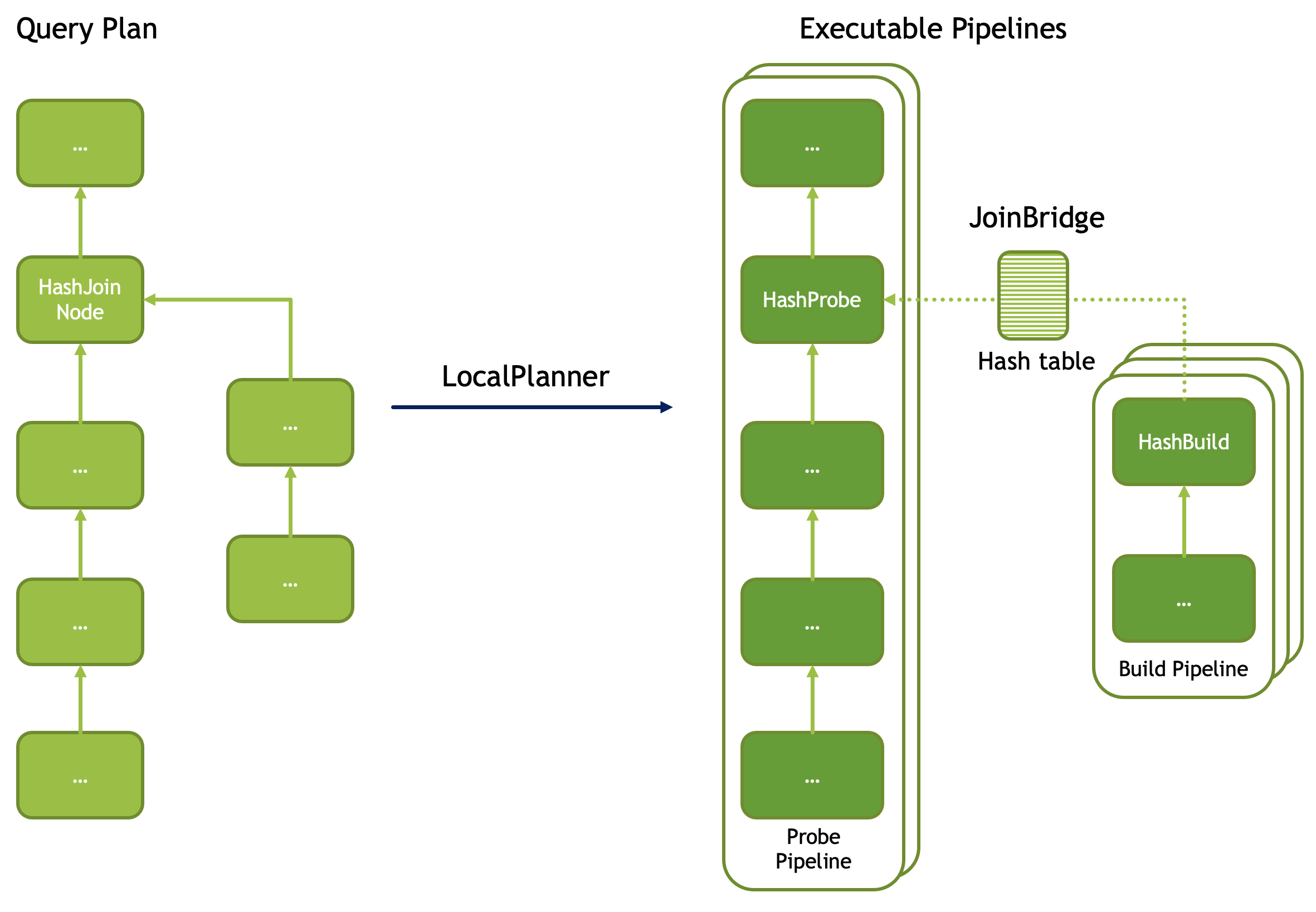
这里 Build 和 Probe 都是并发的,Build 有三个线程,Probe 有两个线程去执行。然后结果被放到 JoinBridge 中。
在 Velox 中,Local Exchange 可以从多个线程/一个线程 <-> 多个线程/一个线程中转换,帮忙完成这个工作。
Split
在 Velox 中,系统也有 Split,Velox 不负责分布式,但是外部可以通过Task::addSplit(planNodeId, split) api 来添加 Split,Split 被组织在队列中消费:
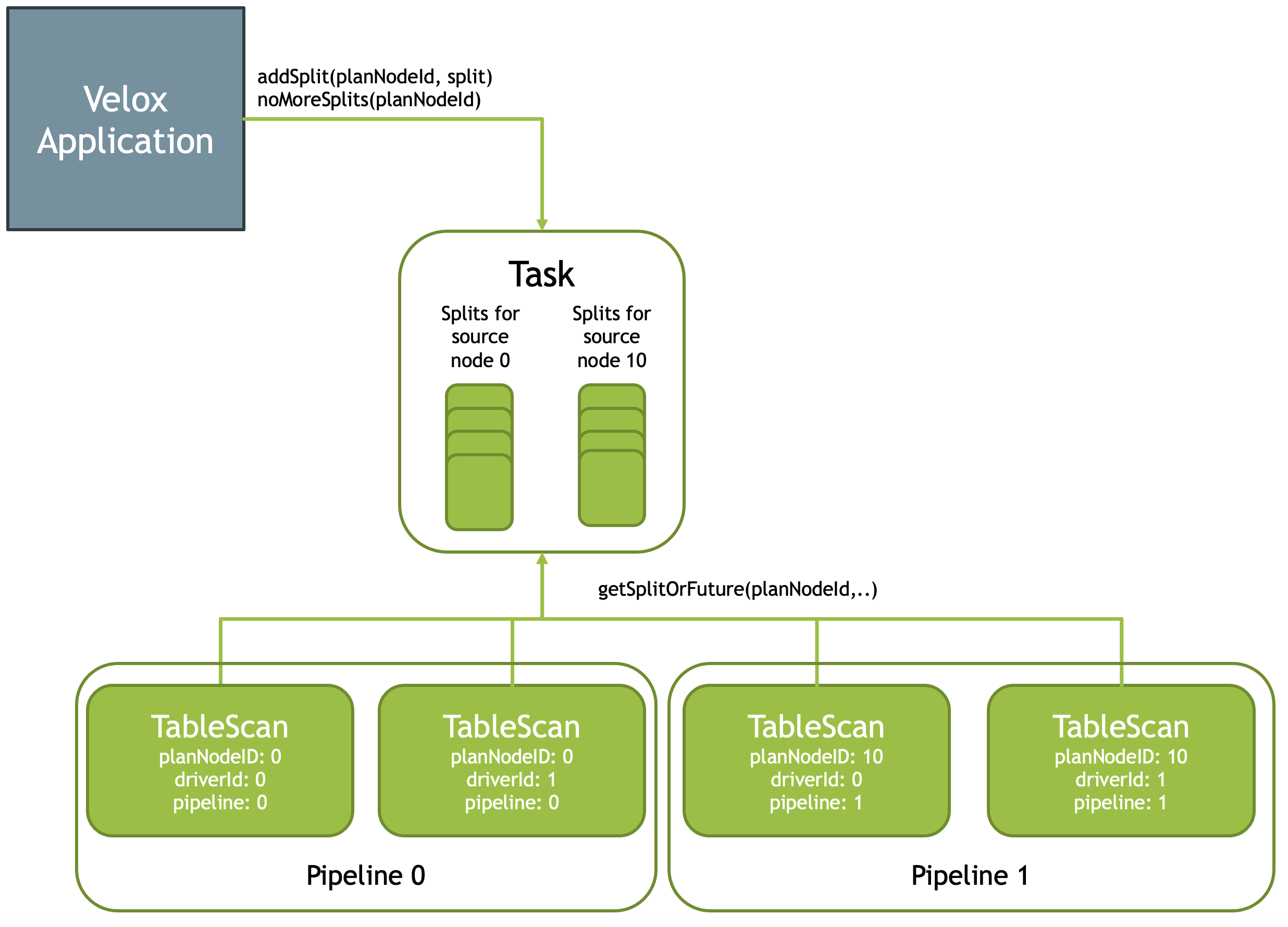
Local Exchange 等操作也会被从 Queue 中消费
IO
读取算子和 FilterProject 可以和 IO 整合在一起。Presto 侧重去读远端的数据源和开放的接口,Velox 则是有一套 IO。它默认使用 dwio 格式可以很好的去做算子下推等操作,同时,这里也有 adaptive 调整算子顺序的操作(如前文所述)。
最近 Velox 也在做一些 Parquet Native 的优化,见:https://github.com/facebookincubator/velox/discussions/2411
Hash Joins
对于 HashJoin,Velox 有 kInner, kLeft, kRight, kFull, kLeftSemi, kRightSemi, kAnti 这几种。
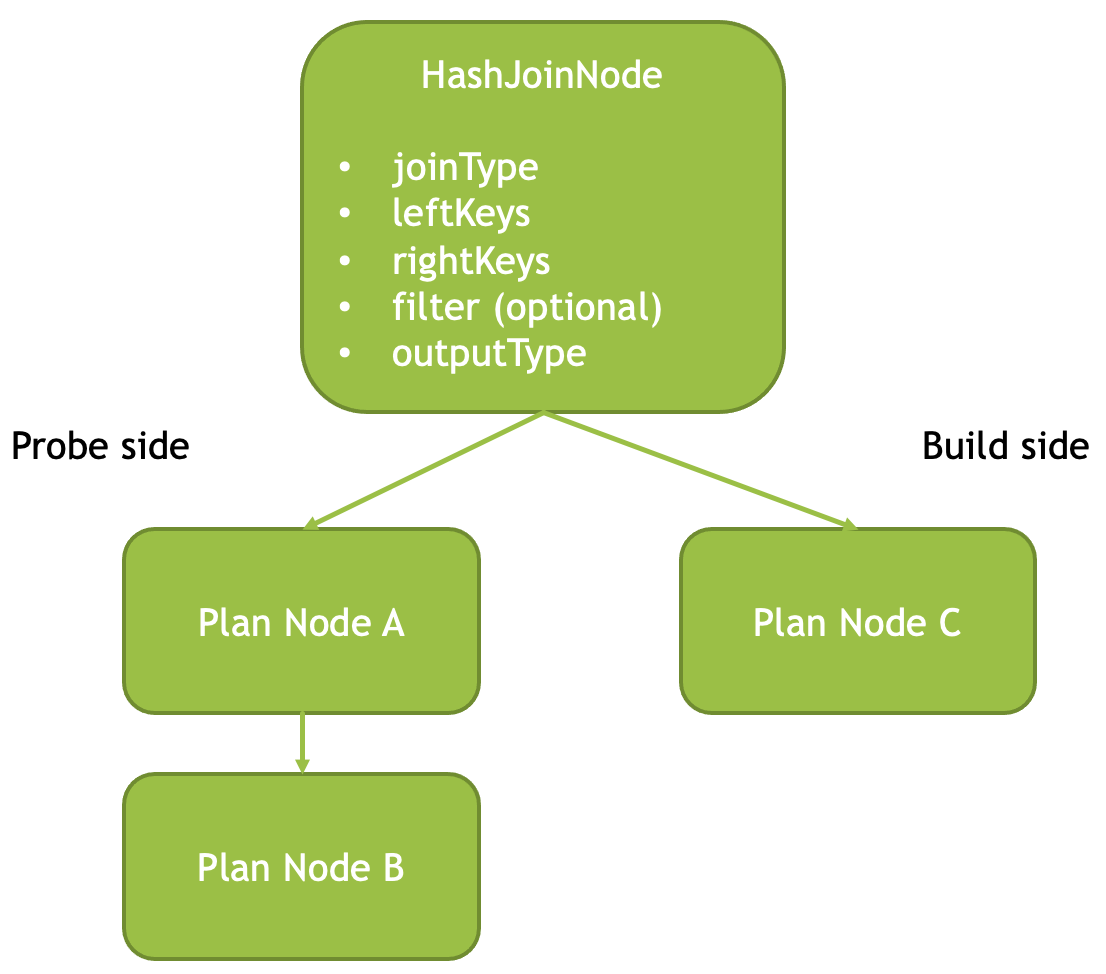
Velox 在 Agg 和 HashJoin 中,都使用 velox::exec::HashTable. 它根据是否忽略 null keys 做了一些特化,JOIN KEY 等会呗存成一个行存的 RowContainer 来处理
Velox 会使用 velox::exec::VectorHasher 来 hash 对应的 key,当 key 空间可以被简单整理到 u64 中时,Velox 会使用这些优化,来避免嗯算哈希。
velox::exec::HashTable 是一个单线程的哈希表,这里有一些下面的策略:
- https://github.com/facebookincubator/velox/commit/765cc2d793cc194f5f44b97ad011e29666ceed70 (每个 executor 去处理不同的部分)
- https://github.com/facebookincubator/velox/commit/0d38da85bae9c6e87a4bbdbc42d428c6c3cd4d87 (合并多组 hash build)
题外话,folly 这里说实现参考了 F14,这里使用行存的 hashtable,作者认为这里 hash 相关的 attributes 还是存一起好,然后会使用 prefetch 等方式交错内存读取。Databend 最近实现了字符串特攻的 SAHA,优化效果贼好,感觉这种就是特化场景特化实现一定是无敌的。
Dynamic Filter Pushdown
对于 inner, left semi, right semi 这几种 JOIN,Velox 允许使用 Dynamic Filter Pushdown:
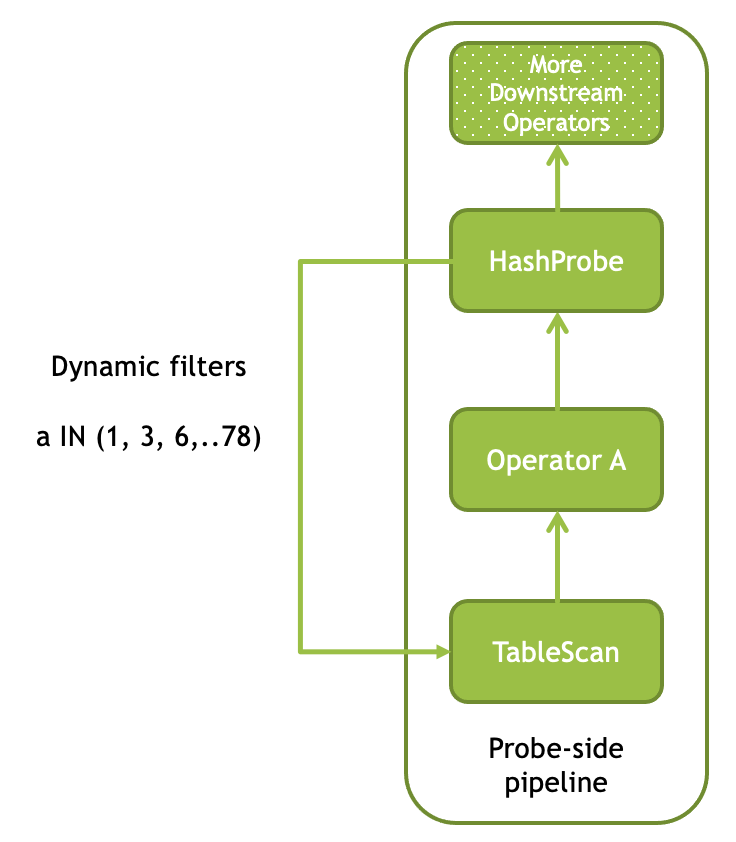
HashProbe 中,VectorHasher 如果发现对象集合很少,可以把信息推到存储上,来做相关的优化。
杂项
这里还实现了 broadcast join, anti joins 等,此外,这里还有 statistics 相关的数据,防止做负优化:https://facebookincubator.github.io/velox/develop/joins.html#execution-statistics
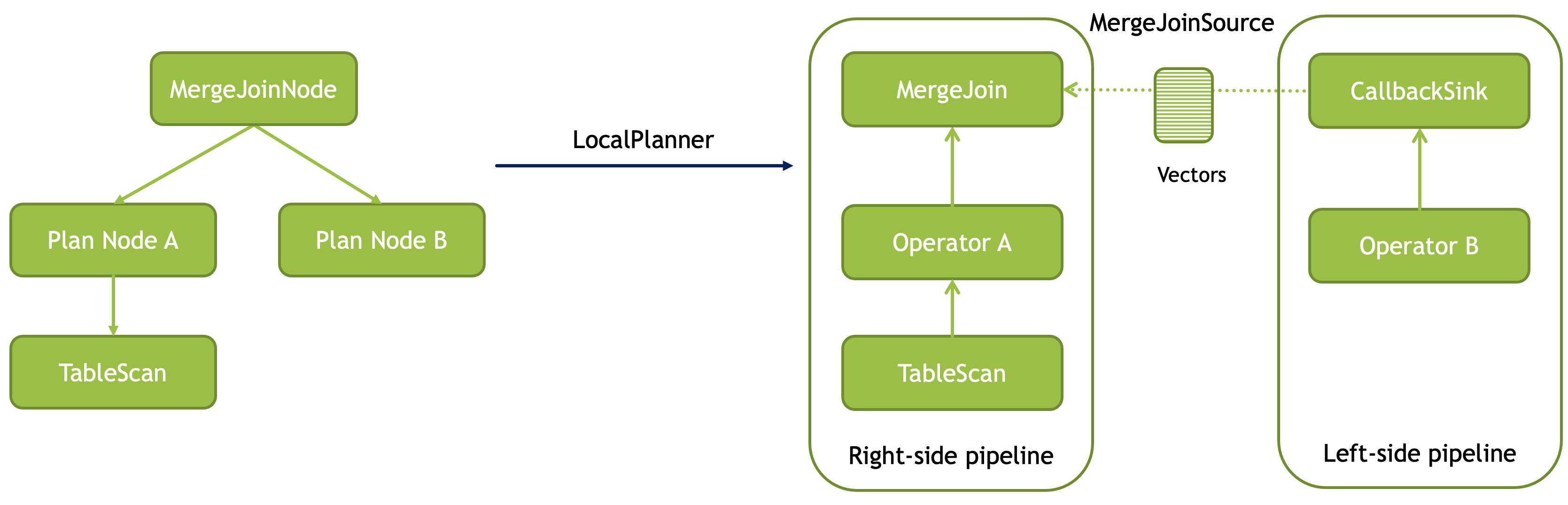
这里还实现了 merge join,不过感觉篇幅不长:
Memory Management
Velox 的 caching 的内存管理有点类似 umbra。它表示:
- 小对象会从 heap 上申请
- data cache, hash table, 读数据的 buffer 会使用 mmap 和 madvise 来管理
这里会有层级的 MemoryTracker,来管理这些内存,然后上层可以通过 spilling 来让内存写出。Spill 相关的部分和 Presto 论文描述的差不多,没有什么特别的,都要在 Drive / Operator 上开洞.
值得一提的是缓存部分,Velox 写了一套稍稍复杂的大对象缓存(没用 CacheLib,感觉是没啥小对象需求?我不懂啊)。类似 Umbra,它会有不同大小的 mmap 空间做内存池,当没有人 pin 这些内存的时候,这部分可以换出。
Velox 还能够合并 IO,读取 S3,HDFS,然后丢到内存/SSD 缓存。Velox 读取远端的时候,会合并相邻读,对 SSD 会合并读到 20K ,对 SSD 会合并读到 500K。这几个感觉可以参考 arrow 去玄学调参。
Velox 还会做 Prefetch,这里,访问列存对象的方式如下:
- 读 metadata,这个通常不会很大,通过 metadata 可以拿到对象大概的大小
- 读具体的 buffer
Velox 这里会记录各列的 selectivity,然后尝试去 prefetch selectivity 高的,来降低延迟。
结语
尽管 Velox 这个项目的未来尚不明晰,同时没有数据写和事务相关的部分,但是它给我们展现了一个单机测的完整查询引擎,包括 IO, Executor, Operator, Driver, Pipeline 和各个算子。
Velox 代码注释算不得好,感觉作者们也没有那么懂 C++,我看的时候非常蛋疼的一点是,这些人传参数感觉都是瞎几把写的,一点都不管读者的感觉,但是 fb 相关的经验确实很丰富,虽然待完善,但确实给他们搞出来了,还搞的不错。还是要虚心学习,看看他们是咋搞的。
References
- https://facebookincubator.github.io/velox/develop
- Facebook Velox源码浅读 - 不要叫醒我的文章 - 知乎 https://zhuanlan.zhihu.com/p/438656081