Type and Array in Columnar System
Type 和 Array 是 Columnar System 最底层的东西之一了。因为本身任何列存系统无时无刻都要和它们打交道。作为系统的 Building Block,存储到 Runtime 都有 Type System,同时处理的数据大部分时候都是 Columnar 的。
Type & Array System 本身不是很有花头的东西,主要考量的是某个编程语言下的:
- 直接的平坦非变长数据的实现(这是最简单的一层,可能需要关注 alignas、内存管理等)、Null 的处理、读/写的接口
- String(等变长) 类型的处理
- Struct / Map / Array 等变长/嵌套类型的处理
- nullable / nonnull 的逻辑的处理(这个逻辑并不简单,想象一下
nullable struct<list<nonnull int>>,那么怎么表示这样的结构
- nullable / nonnull 的逻辑的处理(这个逻辑并不简单,想象一下
- Union 等数据的处理(本质上其实有点类似变长 / 嵌套结构)
- 各种编码的格式,比如 Dictionary / RLE 等 format。这里要考虑的是编码格式本身的抽象之类的。
Arrow
Apache Arrow 将系统分为了好几层( https://arrow.apache.org/docs/cpp/overview.html ):
Physical Layer
Memory Management 物理的内存管理,涉及 MemoryPool , Buffer 系统
- Memory Pool 支持 JeMalloc MiMalloc 等 backend,也允许用户自己在上面包一层,比如用
std::alloctor来当作系统的内存申请者,申请的内存默认 64B alignas- Jemalloc, MiMalloc 有对应的 Pool,可以直接使用 Jemalloc 等 Pool 管理
- Memory Pool 接口类似
std::allocator,甚至有直接适配的,这两个还能互相适配,笑嘻了。反正 calloc 之类的是没有的,Free 和free也不完全对应,知道就行 - 默认甚至是 System Allocator,就丢给 OS 了
MemoryManager/Device:Device是对专有内存和设备的抽象,目前只支持了 CPU MemoryMemoryManager感觉也是在某个设备上的抽象,允许把内存 dump 到另外的 mm 中 (然而CPUMemoryManager包了一层 pool,真是惊人的大黑暗)- 上述的内容在这个 patch 中被引入:https://github.com/apache/arrow/commit/9f0c70c8337b1a8c75df5cc9410b54e97351bfc0
- 这个 Patch 提到了一些 GPU 内存的管理 https://github.com/apache/arrow/pull/34972
Buffer: Arrow 的内存系统,有着一套类型树。Buffer本身: 包含is_cpu,MemoryManager,is_mutable,data,capacity,parent. 本身不管理内存,作为基类存在。Buffer 本身不关心 64B 对齐,但是MemoryPool造出来的可以当成是 64B 对齐的- 认为
size和capacity中间的内容是 padding 部分,允许 zero padding is_cpu并不完全代表这是 CPU. 是 CPU 的可以用data()拿到u8 pointer,否则只能用address拿到uintptr- 允许有一个
shared_ptr<Buffer>作为父级关系
- 认为
MutableBuffer: Buffer 的子类,标注了一下is_mutable = true,其他啥都没做ResizableBuffer:MutableBuffer的子类,接口上允许 Resize- 上面几个都是外部的接口,实际上「本身并不管理内存」,下面还有几个内部的实现:
PoolBuffer: 和MemoryPool绑定的 Buffer- 其实产生出来的,因为绑定了
PoolBuffer,所以事实上全是 Resizable 的
- 其实产生出来的,因为绑定了
StlStringBuffer: 包了一层 string
- String 本身允许包一层
shared_ptr然后丢给儿子,这样单层的继承关系,但是不允许多层的关系
The one-dimensional layer
在我的这篇博客( https://blog.mwish.me/2022/10/04/Parquet-Part2-arrow-Parquet-code-path/#Arrow-cheatsheet ) 贴了很多 arrow 的图,当时一直在解释这套东西,现在来看,我当时贴的图还是挺有质量的。后来 arrow 的一些进展我也可以补充到这篇博客里来。
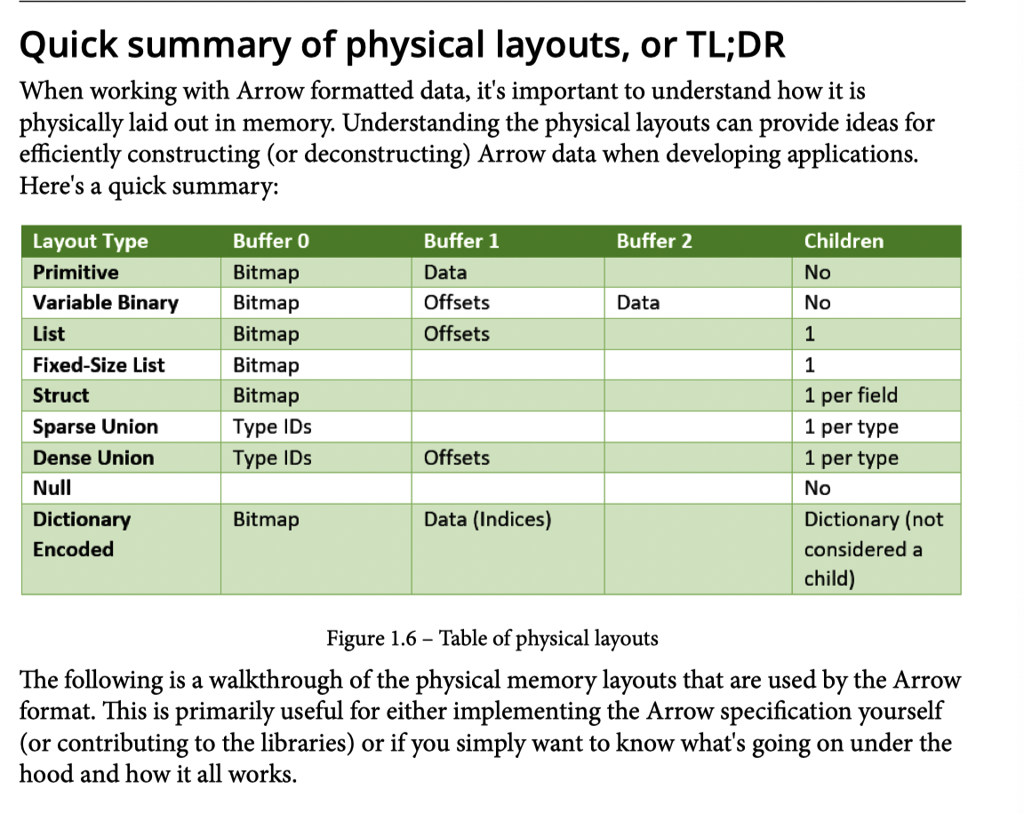
除了上图,在一些新的提案中,arrow 也增加了新的类型,eg:
- REE: https://arrow.apache.org/docs/format/Columnar.html#run-end-encoded-layout
- (提案中) ListView https://github.com/apache/arrow/pull/35345
我们先简短介绍一下这里的类型系统和对应的限制:
DataType: 类型系统,包含嵌套等方式Array: 目前可以当作 POD 之类的东西的包装器,大部分是没有对象语义的- (Extension) 扩展的类型系统和 Array
- Chunked arrays: 物理不连续,逻辑上连续的 Array 序列。
- Scalar: (Typed) 单个类型的值
我们简短介绍一下这些系统:
DataType 包含 DataType ( 一个类型系统树 ) 和 Schema (具名,允许额外信息的 Schema)
DataTypeLayout: 递归的包含 Layout (定长、变长、全 NULL、Bitmap)DataType: 可以是树形的、带有 PhysicalType (比如 Timestamp 实际使用 Int64) 的 array,子节点是Field- Arrow 的 Type 不包含 Nullable,并且 关联实际物理的 Layout,比如
Dictionary甚至被抽了一个类型出来。然后可以用 Visitor 模式来访问类型树 FixedWidthType is DataType,PrimitiveCType is FixedWidthType,这里有一套对应的链路,然后 FP, Integer 什么的都是它NullType用来表示全 null 的BaseBinaryType is DataType, 其余类型继承了它。注意我们之前说的,LargeBinary和Binary之类的 offset 长度不同的,属于两个类型,FixedSized也有自己的类型- 令人唏嘘的是,
DecimalType是FixedSizeBinaryType的子类…然后它还有Decimal128和Decimal256两个子类 ParametricType是一个奇怪的类型标记,我现在还不知道这玩意有什么用NestedType是DataType和ParametricType的子类。儿子包含ListMapStruct之类的Union也是NestedTypeDictionaryType是一种FixedWidthType, 而RunEndEncodedType是一种NestedType
- Arrow 的 Type 不包含 Nullable,并且 关联实际物理的 Layout,比如
Field:(name, type, nullable, key-value metadata). 允许带子类型和 Flatten。嵌套的DataType儿子都是Field.FieldPath: 一组schema->field(5)->type()->field(9)->type()->field(3)这样构成的{5, 9, 3}的 schema 上的路径FieldRef: 相对于FieldPath,还多一个FieldName用名称来寻址的语义
Schema: 可以看作Endianness, {Fields}, endianness 是为了读另一种 endian 的 Schema。一般结构的 Root 就是一个 Schema。- 可以通过 Schema Builder 来构建 Schema
顺带一提这个 Layout 接口真的很直观,比如下面是 Binary 的 Layout
1 | DataTypeLayout layout() const override { |
Array 的系统类似 Type,不过我老实说 Array 的 Mutable 还是挺蛋疼的,思考一个问题就是,Primitive Type 可以比较简单,平坦的搞出来,但是 Binary / List 之类的其实不太好搞。
Array 本身的核心是 ArrayData, 它也是一个可以递归的类型,以组合的形式内嵌在 Array 中,Buffer 按照 Type 对应的 Layout 来排布。一般 [0] 是 validity bitmap,其他的随便。
1 | std::shared_ptr<DataType> type; |
Array 基类是一个 ArrayData 的包装器,其他类型也不外如是,只是提供了很多相关的方法。或许我们需要额外关注 Flatten 的语义,这里子级别的 Validity 需要手动处理父级别的 Validity,这逻辑还是比较复杂的。
Scalar 和 Array 相反,语义上是一个单值,逻辑上差不多相当于用继承实现了一套 tagged enum,我感觉其实我不是很在意这一层的开销。
Datum 相当于一个泛用的类型,或许没有什么能比贴几行代码说的更清楚了:
1 | /// \class Datum |
就这样.
Velox
相对 Arrow 那套被很多地方用到的 Type,Velox 的 Type 一方面代码质量可能没那么读起来舒服,另一方面其实功能覆盖是广一些的。Velox 的内存管理 Hack 了一套 MemoryTracker,类型系统也更 “SQL”:
1 | /// Velox type system supports a small set of SQL-compatible composeable types: |
它的 Type 系统是一棵树,分别为 ScalarType 和别的复杂的复合类型:
1 | /// Abstract class hierarchy. Instances of these classes carry full |
Velox 的 Buffer 自己做了一套侵入式的 RC,并由 MemoryTracker 记录内存,这套代码实现在 velox/buffer/Buffer.h
1 | using BufferPtr = boost::intrusive_ptr<Buffer>; |
(一个有意思的 intrusive_ptr 使用,这里感觉上是节省了 weak_ptr 的内存开销)
- (在
velox/buffer/Buffer.h)Buffer: 可能由 MemoryTracker 来追溯内存的、允许 asMutable /as<T>的 内存池,允许存放 non-pod type - (内存管理的逻辑在
velox/common/memory下面)MemoryPool: 可以有父级的树形结构,MemoryPool 分为 Leaf (具体的叶子结点)和 Aggregate(汇总节点)。这里并发上 children 由folly::SharedMutex维护,parent_是不会变的,内存永远按照 alignas 申请。这段逻辑最近在重构,变动比较大,我这版本理解基于 https://github.com/facebookincubator/velox/commit/c82d9f9bd335c6411fcc1f1f99c5d82796535733MemoryPoolImpl是MemoryPool实际使用的逻辑,它的内存添加会走一把锁(还是std::mutex,我日)。它自己有一组统计信息,同时绑定了一个MemoryManagerMemoryManager几乎是类似单例的全局内存分配器,它有一个单例,然后可以根据他产生MemoryPool和绑定MemoryPoolMemoryArbitrator是一个MemoryManager中的怪东西,感觉上类似一个 burst 内存处理器。当内存不够的时候,可以根据MemoryArbitrator去向别的地方租借内存MemoryReclaimer是MemoryArbitrator的 RAII 包装器,负责借/还内存的管理
这里有个 Hacking 的地方是,MemoryPool 自己和父级别 allocate 一遍还要去 MemoryManager 搞一遍,感觉是因为各种地方的上限不是简单硬从父亲那里分配多少,而是每个级别有一些内存,然后允许去 steal。
和 Arrow 不一样,Velox 的 Vector 和类型和物理的 Layout 没有直接对应。
这里给 Vector 提供了不同的 Encoding 方式:
1 | /** |
Velox 的 null 也是个 bitmap。值得一提的是,Velox 代码中 BaseVector 都快有 1000 行了,我们先看点简单的内容:
1 | const TypePtr type_; |
这些是它的成员,这里没有处理数据,但是包装了很多 wrap 之类的反解方法。这里上面再套了一层 SimpleVector:
1 | // This class abstracts over various Columnar Storage Formats such that Velox |
SimpleVector 有几个不同的子类,对应文档里的编码:
- Constant
- Bias (Delta + Base)
- Dictionary
- Flat (啥都没有)
- Sequence (RLE)
复杂类型的处理逻辑和 Arrow 差别很大,见:https://facebookincubator.github.io/velox/develop/vectors.html#flat-vectors-complex-types
对 Null 处理而言,区别有:
Struct
Child vectors may include nulls buffers of their own, therefore, it is possible to have a non-null top-level struct value with some or all child fields being null. A null struct is not the same as a struct with all its fields being null. Values of child fields for rows where the top-level struct is null are undefined.
Map:
Null map and empty map are not the same.
Keys and values vectors may have nulls buffer independent of each other and of the nulls buffer of the map vector itself. This allows us to specify non-null maps with some or all values being null. Technically speaking a map may have a null key as well, although this may not be very useful in practice. Null map and a map with all values being null are not the same.
Map vector layout does not guarantee or require that keys of individual maps are unique. However, in practice, places which create maps, e.g. ORC and Parquet readers,
map()function, etc., ensure that map keys are unique.
Array:
Null array and empty array are not the same.
Elements vector may have a nulls buffer independent of the nulls buffer of the array vector itself. This allows us to specify non-null arrays with some or all null elements. Null array and array of all null elements are not the same.
总之,这块语义本身也需要一定 checking。
ClickHouse
内存见 https://www.jianshu.com/p/4b15fae5d400 ,比较值得借鉴的地方是各种 Hook
相关的 Doris 也可以见 https://cwiki.apache.org/confluence/display/DORIS/DSIP-002%3A+Refactor+memory+tracker+on+BE
Reference
- Arrow 的介绍:https://arrow.apache.org/docs/cpp/arrays.html
- 向量化的查询引擎里使用Bitmap还是Select Vectors表示过滤后的结果更优? - 码上DX3906的回答 - 知乎 https://www.zhihu.com/question/546231083/answer/2601582280
- ClickHouse 的内存管理: https://www.jianshu.com/p/4b15fae5d400
- Jemalloc: https://jemalloc.net/jemalloc.3.html (
sallocx等) - Doris 内存管理:https://cwiki.apache.org/confluence/display/DORIS/DSIP-002%3A+Refactor+memory+tracker+on+BE