[SIGMOD'18] Column Sketches: a index for OLAP workload
<Column Sketches: A Scan Accelerator for Rapid and Robust Predicate Evaluation>是 SIGMOD’18 上的一篇 Research Paper. 它描述了怎么用 Column Sketches 来构建一个合适的、以 Table 为顺序的 Sketch,来优化查询。这篇文章的 idea 比较简单,但是数学部分相对复杂一些,比较值得借鉴。不过这里也得小小注意一下,Column Sketches 和经常用的缩略词 CM Sketch (Count-Min) 是不一样的,后者经常用来做 ndv 的统计,而前者可以看作是 bitmap index 的类似物。背景
抱歉我们需要在背景部分介绍比较长的时间. 本质上,AP 系统的 Index 和 tp 系统的 index 可能稍微有一些不一样:
- 数据的规模大,可能过滤掉的数据规模大,粒度可能也比较大
- (可能会)允许一些 false positive
- (并不一定会)可能不太会考虑 update / insert 的情况
TP 的 BTree / LSM / ART 等索引都不是很适合这个情况。在 AP 系统中,可能还会有几个 consideration(TP可能也有):
- Predicate Seletivity
- 其实我觉得还有一个很重要的,但是论文和 15-721 都没咋提,就是数据的分布的情况。比如 0 1 0 1 0 1 这种,你在 loading 层面如果
- Skewness
- 可能会有高分布的 unique value 数据
- cluster / sorting
- 数据是否预先 clustering 了
在 15-721 里面,整理了一些索引,部分也来自 Column Sketches 的举例,不知道有没有什么专论。
Zone Maps
Apache Iceberg, Apache Parquet, Apache ORC 之类的都有这个东西,我倒是很难想象有谁没有的。本质上是一种超级粗粒度 pruning。一般来说还是有一些各种 corner case 的,比如哪些东西应该放 min-max,一些特殊值的处理,什么时候应该退化。不过这些我理解是什么索引都有。
Bitmap Index
StarRocks / Doris 都引入了 Bitmap Index. Bitmap Index 有一些思路发表在论文
中,论文本身比较简单。bitmap index 的最原始思路是「一个值一个 bitmap index」。然后 Filter 的时候扫那几个 bitmap 就行了。这个 idea 我个人认为本质上是把 domain 拆分成多组,然后 filter 的时候只扫描需要的 domain。 这种方式直观看是没有问题的,但是问题是多方面的,比如 domain 需要很小,但是又不太好过小(想象一下,如果 domain = 2,那么是不是就没有区别了…),同时还有各种问题,所以这里可能要引入一些 pattern 和压缩方式。
论文 Bitmap Index Design and Evaluation 提出了对应的比较框架,来给这个一个量化的渠道。这篇论文发表的比较早,不过其实评估还是很好的。
这篇论文拆分出了两个维度,作为评价的标准:
- Space-Time Tradeoff
- Encoding Scheme
同时做了一些 bitmap eval 相关的工作。同时定义了一些 bitmap 相关的启发式工作
这里:
- C = attribute cardnality
- 定义下列 Decomposition:

也就是说,这里可以把值拆成 n 组 bitmap 的集合 {B0, B1, B…, B_{n-1}},共同构成对应的数字。这里展示同一组数据的两种表示方式,可以看到 Filter 性能和占用空间上的区别:
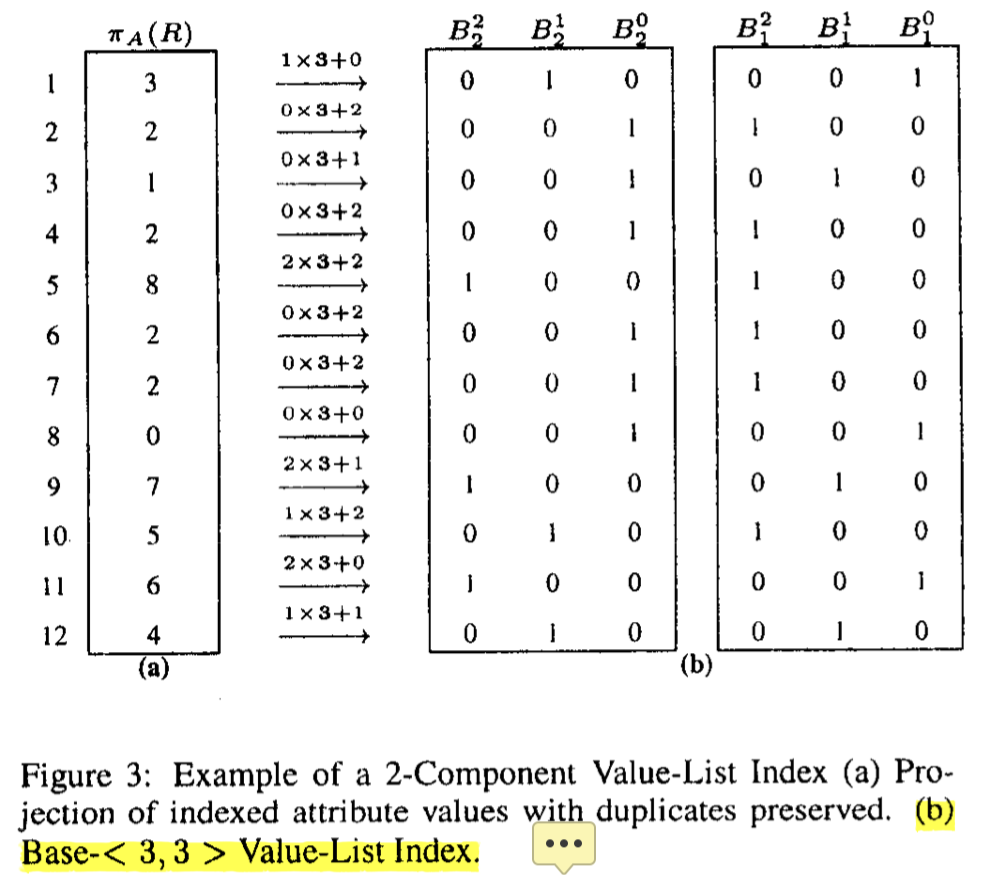
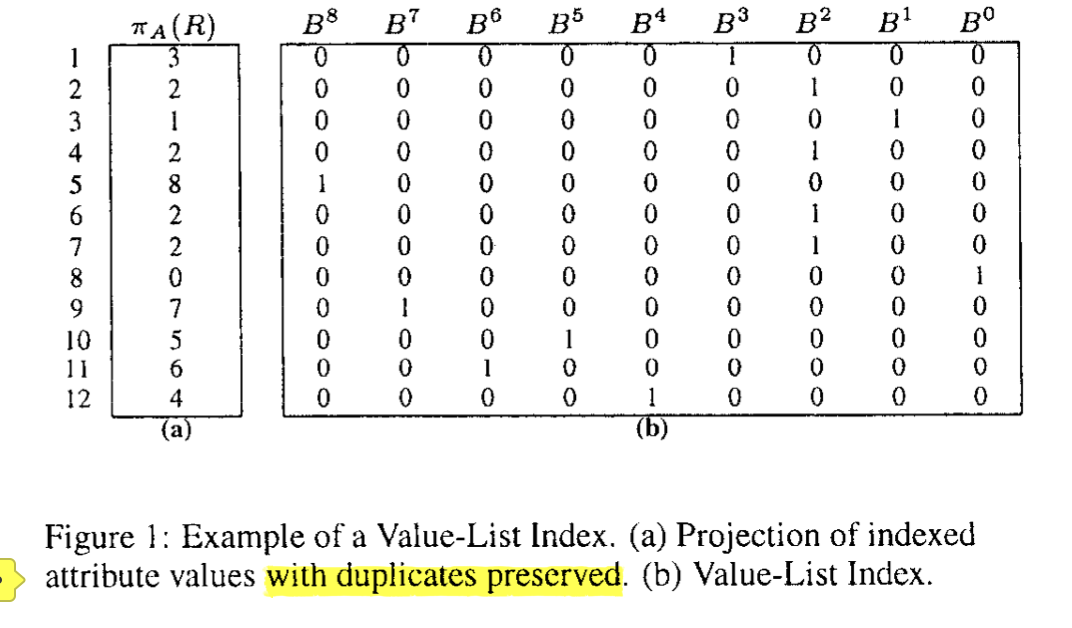
这里还有一个 Encoding Schema 的问题,这里分为两种:
- Equality Encoding: 单组数据内,等于要求的mark 为 1
- Range Encoding: 单组数据内,大于等于要求的全部mark 为 1。它的宽度会少一,因为它相当于用 range 的方式缩减了需要的信息。
Figure1 和 Figure3 内容均为 Equality Encoding,下面展示 Range Encoding:
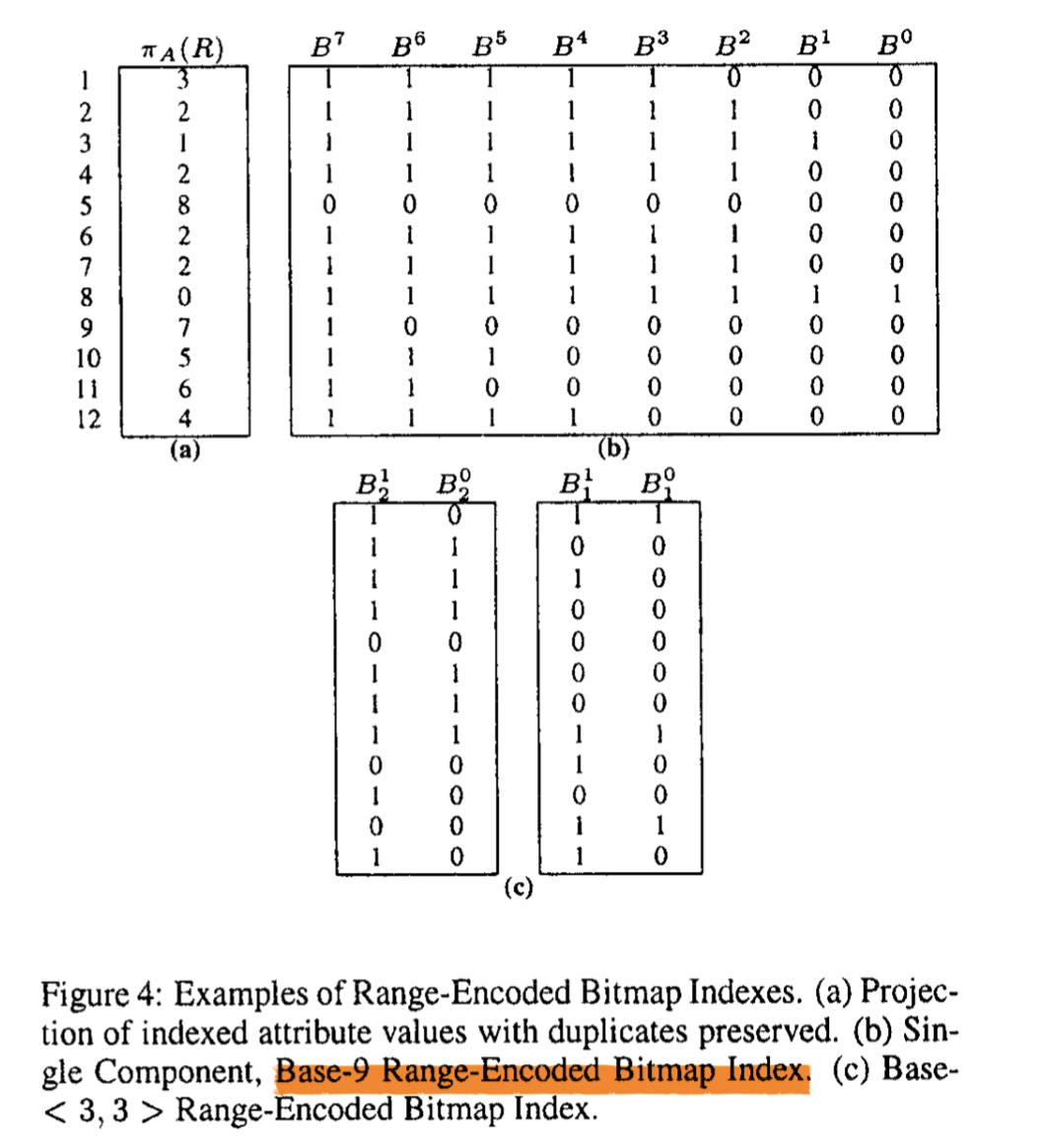
演算

这里有两种算法:
- RangeEval: 对于
>=和<=,维护每个 bitmap 的 Eq, GT 或者 Eq, LT。然后推算。- 初始化的 GT, LT 为全 0 的向量,Eq 为 non-nulls
- 每一轮中,求解需要的 Eq, LT, GT
- RangeEval-Opt:
- 把
>=和<=推成> v - 1和< v + 1,然后执行操作。
- 把
(我其实没完全看懂这里,可能之后得翻翻代码)
总结
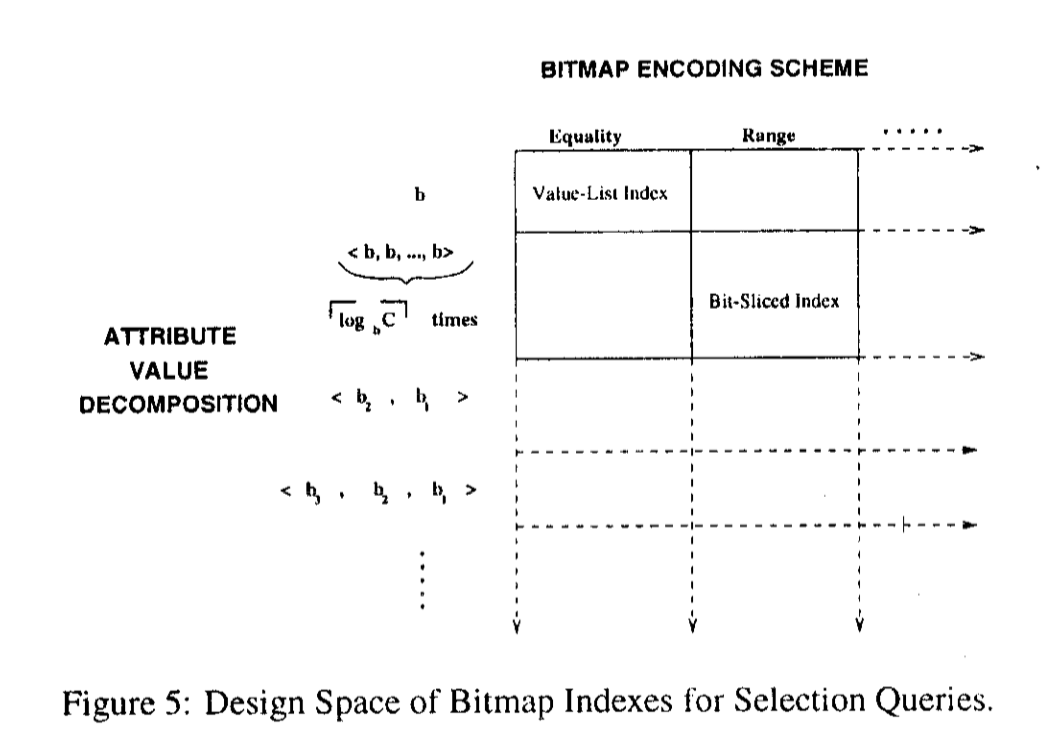
论文中提出了对应的 space-time 抽象,来评估对应的实现。
你可能会注意到右下角有个 Bit-Sliced Index,这个东西…和 Bit-Weaving 一样,算是极端特化的 bitmap index,算法大致类似之前贴出来的部分(但是可能有 SIMD),类似一套提前的裁剪
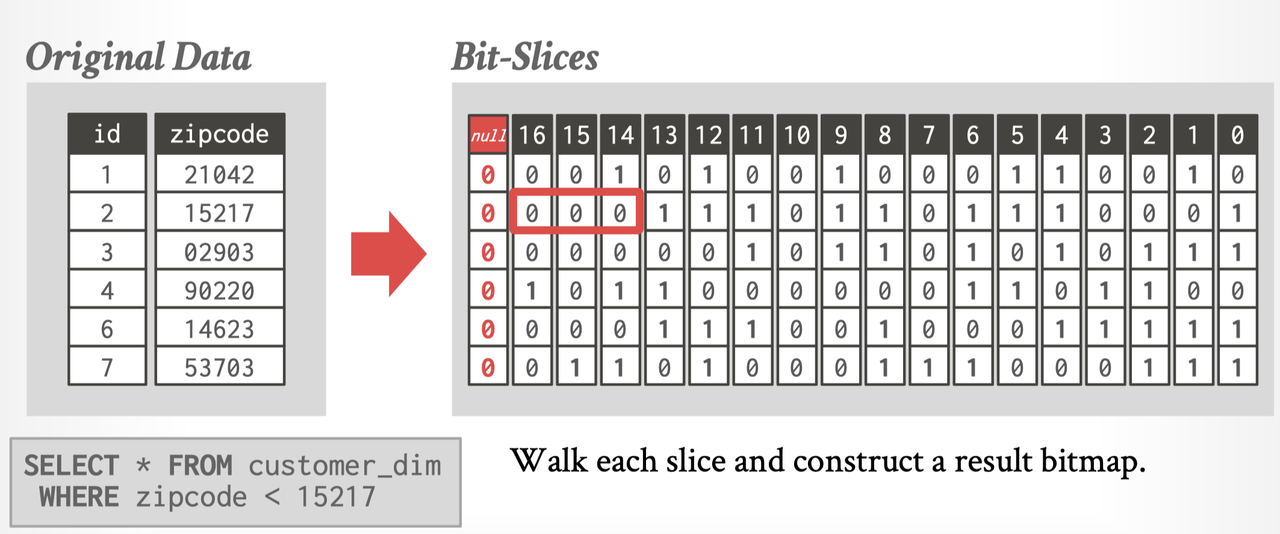
在实践中,有的数据库实现了 Bitmap Index:
- Oracle
- Greenplum, 这套做的比较细,直接做到 Page 上头了
- StarRocks/Doris, 这个做的相当于是多列无序字典
(其实我认为某种程度上 bitmap 相当于一种奇怪的 encoding 了,而不是传统 Index 那种含义,我目前没找到很好的材料,所以语言上说不太清楚,懂我意思就行)
Bit Weaving
Bit Weaving 有 wisc 的作者们发表于 SIGMOD’13 的论文 BitWeaving: Fast Scans for Main Memory Data Processing 上。某种程度上,Bit Weaving 有点像 Bit-Slices 这一套,它往前走了一步:对整数(尽量)压缩,对位采用特殊的模式,使其适合于 SIMD 的执行。
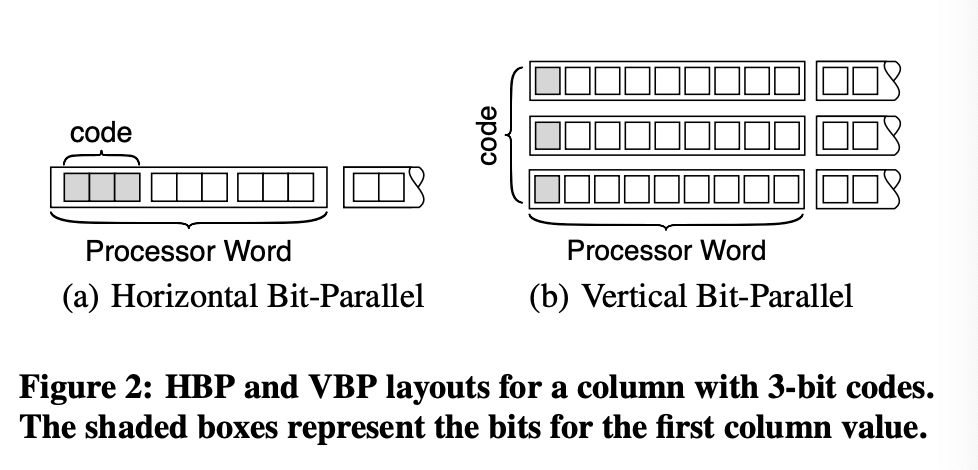
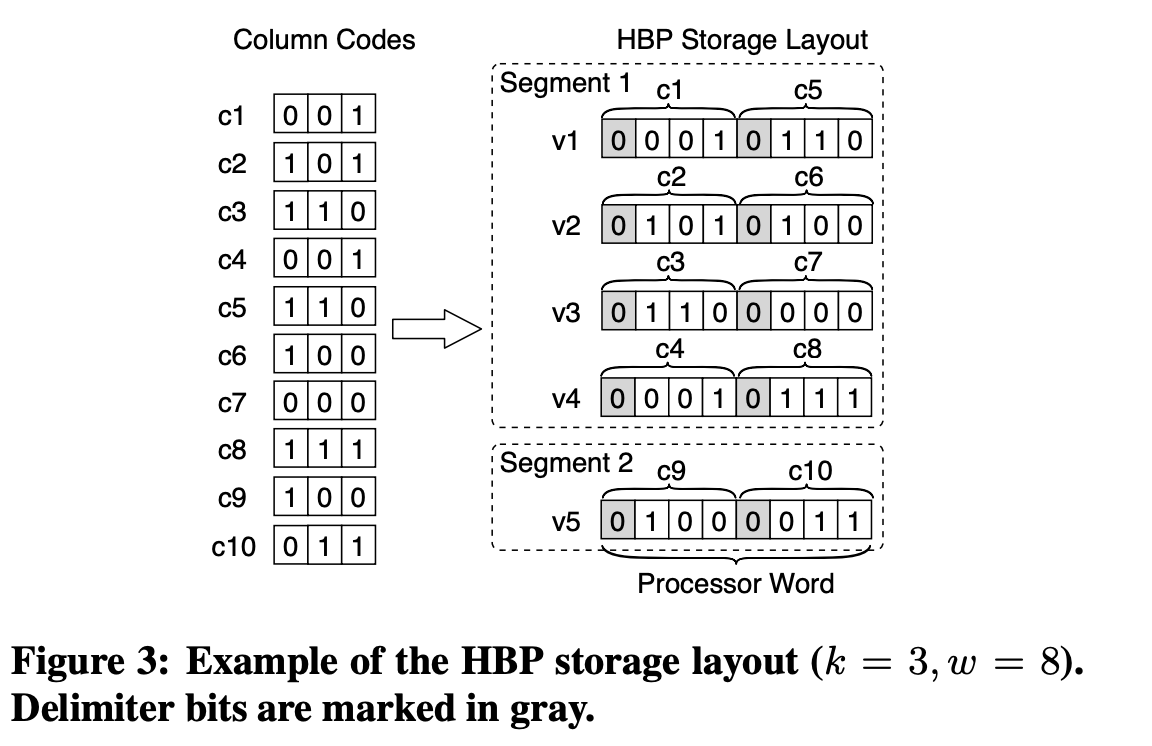
这里给各种算子都做了基本的实现。性能评估如下:

这里我建议还是回到论文的标题,「一个 fast-scan」 来理解。
Column Sketches ( and Column Inprints )
(下面是 Column Inprints,思路很简单)
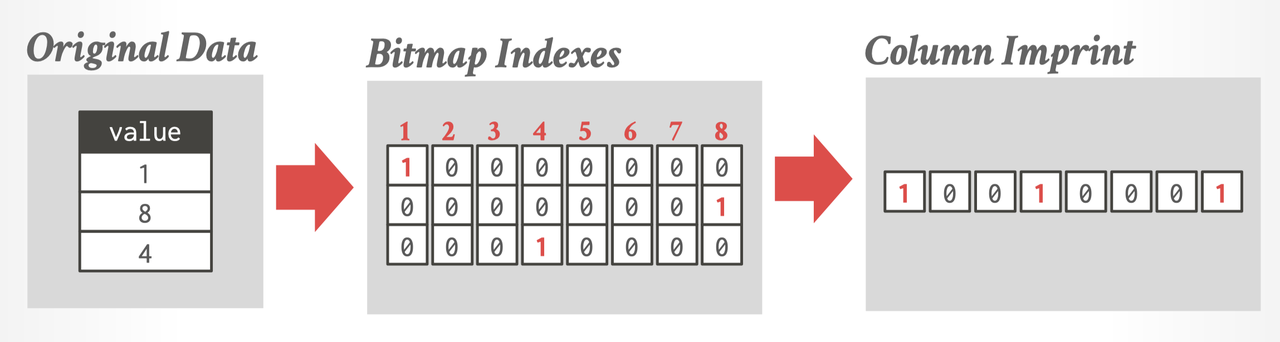
这部分相当于进行一系列有损压缩,来拿到一个帮助裁剪的 sketches,感觉这个方式明显合理很多。我觉得在现代 AP 系统中,属于值得一试的方案。
论文来自哈佛大学的实验室: https://stratos.seas.harvard.edu/publications/adaptive-data-skipping-main-memory-systems
LSM 著名的 Dostoyevsky 也是来自这个实验室,感觉他们是工程能力没有那么强,但是对各种 metrics
论文里面评估了 Zone Map, BitWeaving, Btr 之类的策略,下列内容评估范围是:
- Selectivity 3%
- 数据分布有 skew (可见 Figure 1 是有利于 sketch 的,因为数据分布有 skew 的场景是它的优势区,这就是论文做实验的方式,嘿嘿)
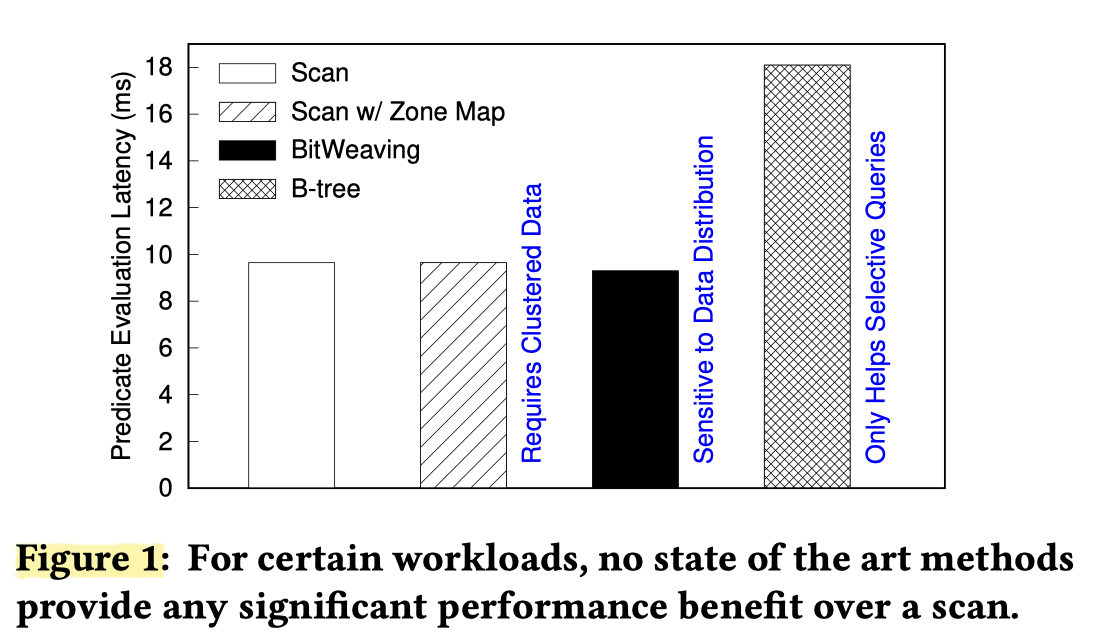
Compared to standard scans, Column Sketches provide an improvement of 3×-6× for numerical attributes and 2.7× for categorical attributes.
下面是一个论文简单的对比(吊打)框架:

论文评估的范围有:
- B-Tree:
- 对 low-selectivity 效果好,但是当 Seletivity 上去的时候,性能就会暴跌(传统 rdbms 也要考虑回表的 io/cpu 开销)
- 论文中提到 Btree 不适合在 append-only 系统更新、cache-locality 在 modern scan 上表现不好。我理解前者是实现问题,后者感觉确实是个小问题。但我理解某种程度上 btr 和 sketch 确实是两回事。此外还有个问题是,这里 btr 是按照 domain 切分的,切分完可能还要转化成 scan 回表(或者直接 icp)。作者实验中,在选择率大于 1% 的情况下,就不建议用 btr 了(其实我也挺好奇他实验的环境的,不过不深究了)
- Lightweight Indices (Zone Map, Column Inprints)
- 用数据的 Summary 来做 Skipping
- 对于 data 的 clustering properties 不好的时候,效果并不好(像 Figure 1). 这个其实可以看一篇别的论文 Adaptive Data Skipping in Main Memory System 的图,总的来说和 zone map 粒度、selectivity 和数据混乱程度都有关。当某几列数据不太 clustering 的时候效果显然是不好的
- Early Pruning Methods
- 提前(细粒度的)pruning 数据,比如 bit-slicing, byte-slicing。通常策略是按 bit / byte 来切分(partition)值,然后读的时候去把用户的 Operator 也推给需要的 partition 再合并,这里下推的顺序从高到低,然后尽量 skip 已经 prune 掉的数据。
- 当数据或 filter 集中在低位、或者出现 skew 的时候,高位 filter 会做很多无用功,同时也不能 prune 掉什么数据。(the high order bits are biased towards zero, enabling very little pruning. As a result early pruning brings no significant advantage over a traditional scan.)
论文提出了 Column Sketches,特点是:
- Robust to Selectivity, data value distribution, data clustering
- Lossy Compression
- 可以比较粗糙又不影响正确性的摸出一个 encoder
- Space efficient
- 更快的 ingestion speed (就是写的快,因为查表少我理解),同时,Update 之类的不用像字典一样重写字典。
- 把查询拆分为:
- 走 sketched data 粗过滤一遍(会有 false positive)
- 如果有需要,走 Base data 细过滤一遍
- 论文框架中,尽量适配 SIMD、多核优化。论文声称也可以适配 TP数据库。
那么,简单来一张图表示 Column Sketches 的框架:
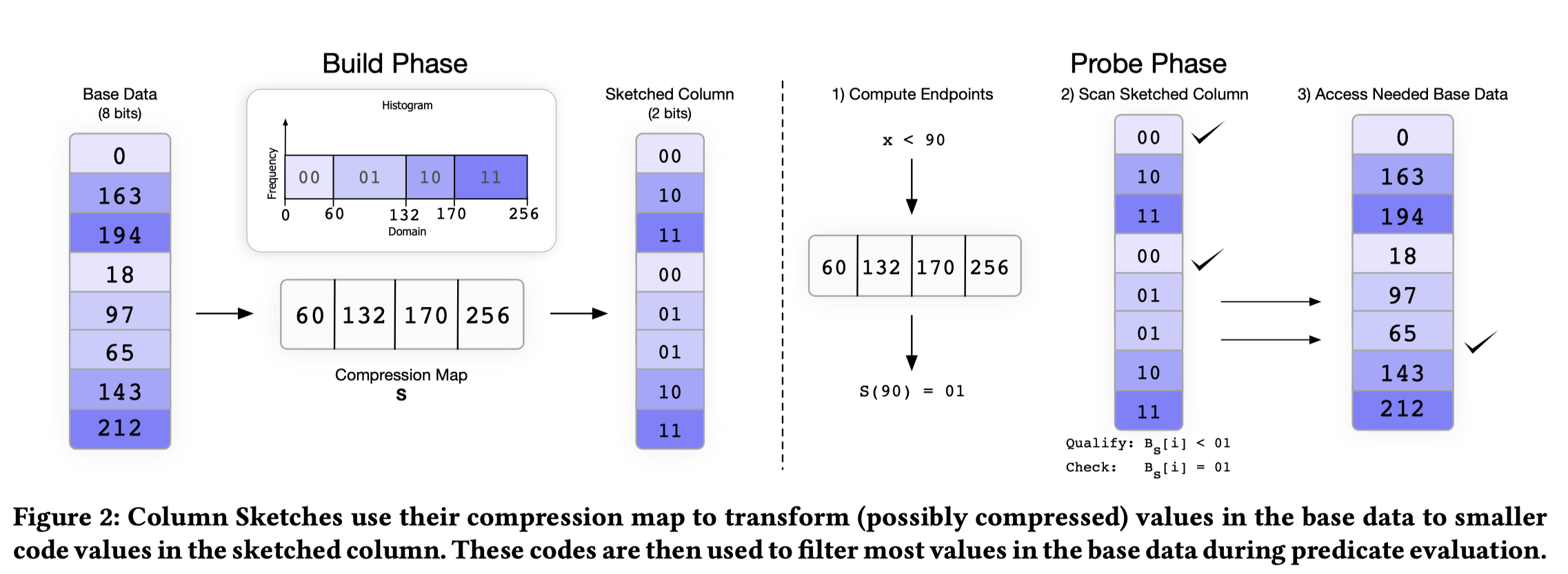
这部分内容在论文第二章,上图一图感觉就行了。
- Column Sketches 支持 Ordered 和 Unordered 两种模式。数据结构分为 Compression Map ( function S(x) ) 和 Sketched Column (固定 bits)。Build 阶段,Base Data 根据 Compression Map 的信息被映射到 Sketched Column 上;Probe 阶段
- 对于 Ordered 结构,Compression Map 类似一个有序的 eq-depth histogram. Figure 2 左侧写的很清楚。根据这个可以构建,然后右图中,根据 Map 可以粗筛一遍,再根据 filter 的结果细筛(这个地方有一个问题是,空间占用和 fpp 都是多少,别急,论文后面会讲)
- 对于 Unordered 结构,Compression Map 是一个含有 unique code 的 HashTable + HashFunction
文章贴了一个算法,然后表示这个玩意最好是 byte-alignment 的,反正这种东西都是实现层面的因素:
Byte Alignment. Column Sketches work for any code size. However, we find that on modern hardware there exists around a 30% performance penalty for using non-byte aligned codes. Thus, we give special attention to 8 bit Column Sketches and to 16 bit Column Sketches.
S(x) 已知的情况下,构建和查询过程都很简单。显然这个结构的问题就变成了如何构建 S(x)。
CONSTRUCTING COMPRESSION MAPS
需要满足论文画的 Robust to Selectivity, data value distribution, data clustering 这几个饼,构建一个合适的 Mapping 就变得很重要了,论文先提出了一些原则,然后再具体分析:
- 给 frequency value(超过一定比例)去分配独立的 code.
- 分配独立的 code 有一个特殊的好处就是不用回表再套一层这个 Column 的 Filter。同时论文提到,在出现一个 value 对应很多 key 的(假设是 10%)这种数据分布情况下,访问 cacheline 中的任意数据,就会需要访问cacheline 全部的数据,同时也会影响这个 value 里面分布的其他数据。不好做到 robust。(论文里论证感觉不是很清楚,我理解大概是这个意思)
- 给非 frequency value 分配非独立的 code 很合理,压缩空间,访问 base data 的比例也很小
- 允许 order preserving (废话)
- 如果有(sampling 中)没见到过的 value,也可以当成 non-unique code 正确处理(想象一下,作为反例的 dict encoding)
- Optional: Exploit Frequently Queried Values
下面有一段数学证明:
256 那个地方我怀疑是个笔误,当成 n 处理就行。
这里特别做了一个不难证明的上限 (2/n). 这个上线在实现上是有操作空间的。大于 2/n 的能保证分配到 unique value.
有序数列的构建
对于有序 Map,构建方式大概是 CDF 采样,然后构建 eq-depth histogram。这里的方式是 采样 + Sort,然后构建 histogram,根据这个 histogram 来处理。论文列出了 sample 200k 个值,然后构建 256 个 bucket 和 assign unique value 的情况。
Unique value assign 在这里被做了一种很简单的抽样法:
- 假设有 n 个数值,其中,出现数多于 1/z 的要被 assign unique value, c 是 column sketches 中准备分配的 codepoint 数量
- 构造方式:抽样 n/z, 2n/z… 这些轴点上的数据,然后 check 每个轴点上数据的 begin, end,是否超过了 1/z (这个构造方式还是 O(N) 的,不过可以跳过很多非 unique 的数据,采样策略也比较简单)
- Assign c * midpoint / n 的 codepoint 给中间的值。论文中,令 z = c。
- 分配剩下的 code
Category 数列的构建
有序的 S(x) 类似一个 eq-depth 直方图,无序的数列则是 Hash Function + Bucket Size + Unique Values。
这里采样就比较弱智了,给高频值做分配,然后低频值 hash
Eval

Eval 分成两部分:
- Definite
- Possible
然后用来求职,相当于 unique value 比较独立的抽出来了。
总结
对于 AP,相对于 TP 的 Domain-Based Index,AP 更倾向于用 Table-Based Index,来读取数据(类似 ICP)或者对 Table 读取的数据进行裁剪(拿到一个 mask,然后去 filter)。同时,也有一些改变 Table 数据存放模式,方便 fast filtering 的方案。这里也要考虑上空间放大之类的。
目前感觉市面上的 AP 产品都没有什么做的特别成熟的。我要发力了(误)。
Reference
- Bitmap Index Design and Evaluation http://www.cs.tau.ac.il/~matias/courses/sem_fall98/bitmaps/bitmapIndexes.html
- https://www.youtube.com/watch?v=2sRyOTZ5Kh0&ab_channel=Sigmod2018