[VLDB'22] CloudJump: 存储层上云优化
Aurora 风格系统用分布式块存储 / S3 等服务代替(或者加深了)了 SSD / HDD 的存储栈,获得了更深一层的存储栈、更大的存储可扩展性。但在这点上,了解这一层新的栈的性能就变得更加重要了。CloudJump 是 PolarDB 团队的在块存储上的一些研究产物,虽然论文主体研究对象是 InnoDB 为主的 Btree,但它也允许把这部分结果扩展到 LSM-Tree 上,论文描述了对 RocksDB 的一些修改。这篇文章提出的内容和解决方案是实在的,做的工作非常 Solid,但是,但看这篇文章感觉作者很多思路没有很好的告诉我们,或者是把内部黑话直接写外面了,很多东西我看的很懵逼,而且图片偶尔冒出两个错字,尼玛。文章最好的阅读方式是看 baotiao 的 talk 「揭秘 PolarDB 计算存储分离架构性能优化之路」和文末一个离职了的大佬写的评论。然后抱着这部分理解再去读原论文。
读本文之前,假定读者对 InnoDB 有着一定的了解。
本论文分了很多优化细节,但是核心点其实只有一个:
云存储有着更高的延迟、更大的聚合带宽、更不好的 IO 调度能力、更好的随机读性能。需要利用带宽,优化延迟。
在阿里云 NAS、块存储这些东西越来越好买的今天,我们应该把块存储当成新的版本答案,所以应该去看看这个文章是怎么写怎么优化的。
Block Storage 可以瞅一眼我之前写的 WAS: https://blog.mwish.me/2022/11/24/SOSP-11-Windows-Azure-Storage/
一般来说,云上块存储会提供:
- QoS
- Admission Control
- 弹性计费
- 本身接口比较 general,可以避免 vendor in
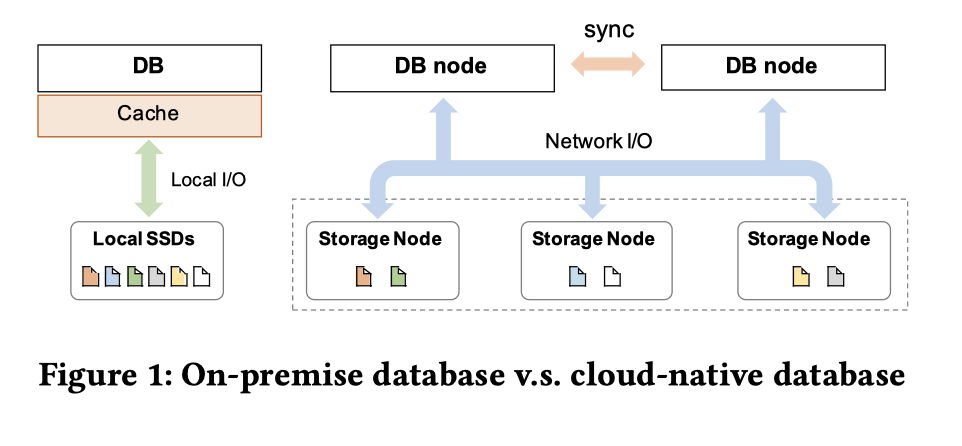
图上是一个对应的架构. 这套东西现在有:
- MySQL 等
- Aurora
- PolarDB
- Socrates
- LSM
- Anna
- RocksDB-Cloud (Rockset)
注意一个很容易忽略的一点,DB node 上没有 Cache 相关的信息,这里是文章后面会提到的一个地方
这里还提供了一种 Aurora 的思路:在 Storage Tier 去 Apply Log,做到真正的 Log-is-database (可以想象一下为什么 PolarDB 不是完全的 Log-is-database) 通过减少存储通用性来减少带宽开销。这相当于定制存储层的实现。Socrates 其实也是一种这样的思路。这样减少了写带宽的限制,而提升了系统的上限。但是这种方案本身是作为一种特质化的存储,在 PolarDB 设计者思路中提到,PolarDB 这种抽出一个 FS 层可能在这个方面上并不优雅,但是可以提供更好的对 MySQL 适配的能力,同时,PolarDB 也可以依赖任意的块存储服务,这也提供了云上的扩展性。不过再说下去感觉就涉及一些类似阿里云政治问题或者产品售卖服务的问题了,思考这个就不是我这个技术员的专长了。有什么评论倒是可以提一下。
本论文提供了一种优化框架,通过对比 云上块存储服务和 SSD 的 bandwidth, latency, 弹性, 容量,来介绍它们对数据库实现的影响,然后进行相关的优化。下面有一个对比的硬件性能表格:
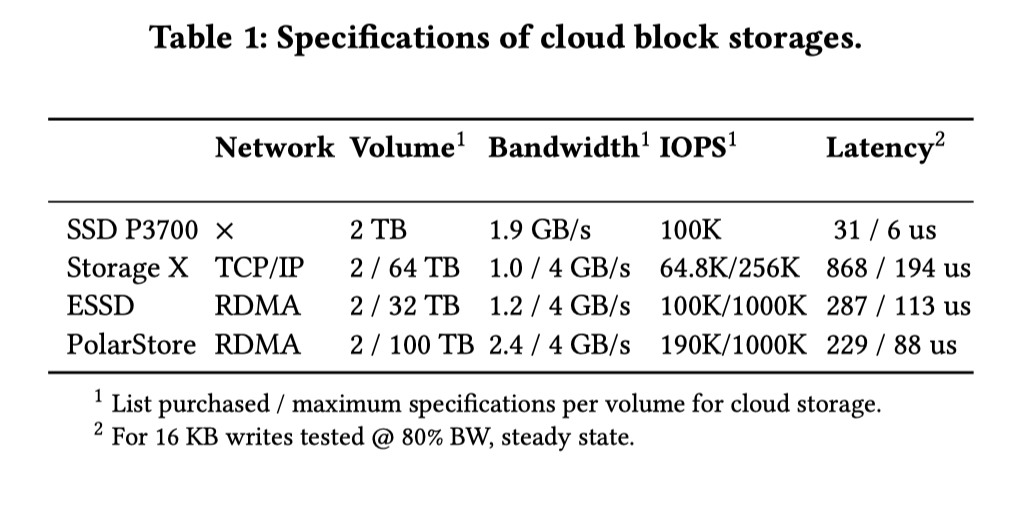
可以看到:
- 从 baotiao 的演讲上看,Storage X 其实是 ebs 盘。为了避免 benchmark 碰瓷,这里会避免提到名字,不过这个测试应该是对 PolarDB 非常有利的
- Latency 这里左边是平均,右边是方差。其他的都是氪金可以买的大小上限。这里可以提一下,阿里云的 ESSD 和 PolarStore 都走的是 RDMA,相对来说提供了很好的性能和暴力优化空间。
- 云存储有着更大的 Volume,更大的总带宽,但是 latency 可能会非常高. 据 baotiao 说,刷 Page 一般延时是 50us,在云盘上会升到 200us。和本文测试数据基本上是一个量级的。
- 在云存储中,多个节点之间的分散访问读写都可以利用更多的硬件资源,例如将单个大I/O并发分散至不同存储节点 ,充分利用聚合带宽。
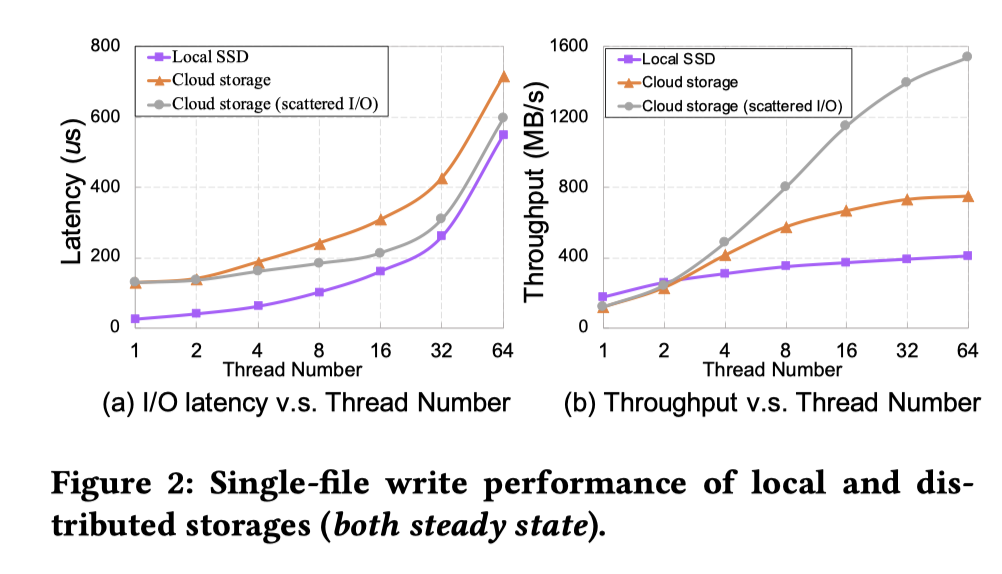
文章演示了一下带宽打满的场景,我感觉虽然属于拼凑,类似 WiscKey 讲 IO 串行和并行的,但是在迁移代码而不是很精细的从零开始写的时候,还是有一些道理的:
下面 Local SSD 和 Cloud storage 对比可以看看,同时 scattered I/O 是利用打散 IO 之后的策略。当然我个人觉得线程是 Polar 的工程,而不是严谨的 IO 测试术语,不过这个图已经能比较好的表示一些结论了。
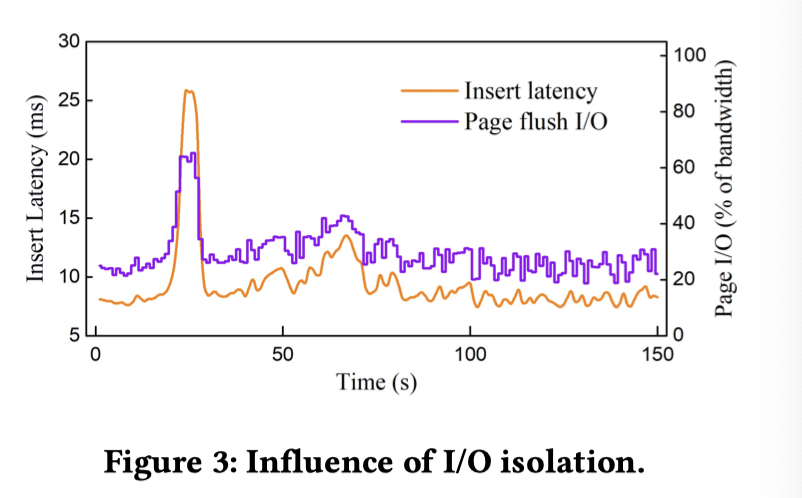
同时,这里共享一组 IO 池子的话,如果并发上去了,把 IO-queue 打满了,延时可能会受到一定的影响,而 WAL 这种前台作业应该大部分时候是延时更敏感的(用户 SQL 可能卡在 Page 读和 WAL 写上),Flush Page 则带宽更加敏感,这里也做了一些实验。这里 Flush 占了 80% 的带宽,然后在带宽占瓶颈的场景下, Flush 卡了一下前台 Log 感觉就爆炸了:
CloudJump 面临以下技术挑战:
- 远程分布式存储集群的访问导致云存储服务的I/O延迟高;
- 通常聚合I/O带宽未被充分利用,这个问题体现在比较多方面,后文细讲;
- 在具有本地存储的单机上运行良好但需要适应云存储而导致特性改变的传统设计,例如 page cache(这个地方应该是指 RW / RO 节点的 Page Cache,之间同步按照 CPU 那样设计相当于走一套 MESI 协议);
- 长链路导致各种数据库I/O操作之间的隔离度较低(例如,日志刷写与大量数据I/O的竞争,一般日志刷写在用户前台链路上,数据 I/O 在后台的链路系统上);
- 我理解本身 SSD IO 也有这个问题,但是 SSD IO 带宽基本不那么能打满,上云加剧了这个问题,不知道 ScyllaDB 是怎么处理的。https://www.scylladb.com/2022/08/03/implementing-a-new-io-scheduler-algorithm-for-mixed-read-write-workloads/ 看上去这个地方 CommitLog 应该会单独有一部分 IO
- 云用户允许且可能使用非常大的单表文件(例如数十TB)而不进行数据切分,这加剧了I/O问题的影响。
这里也引入了一些优化因素(下面论文的用词极其混乱,看内容比词汇更重要):
- Thread-level Parallelism:例如依据I/O特性实验,采用(更)多线程的日志、数据I/O线程及异步I/O模型,将数据充分打散到多个存储节点上。
- 本质上这个其实和 InnoDB 应该关系很大,因为无论本身 InnoDB 还是 RocksDB,WAL 都是单线程写的,甚至有的库 Page 都是单线程刷的。这里会把这个单线程进行拆分。这里指的当然不是 Morsel Driven Database Exec 那种 Parallelism,下文 Task-Level Parallelism 同理
- 实际上,单线程的这种写,在单机环境可能可以打满存储,但是在云存储延迟爆炸的场景下,这个就很成问题了。这里会导致这个成为瓶颈。PolarDB 切分了日志大小,然后写入的时候去 log writer 会根据每个 Partition 的 Log 状况去做具体的 IO(可以回顾一下 InnoDB Redo Log,它本身也是分成不同不同小块的,见其 LSN 获取逻辑)。当然 baotiao 说这里有一些对齐块大小的优化,和不用 ftruncate 初始化块全0的优化,来降低用户链路上的开销。
- Task-level Parallelism:例如对集中Log buffer按Page Partition分片,实现并行写入并基于分片进行并行Recovery。
- 本质上,这个类似刷 Page 的时候的 IO。你如果走一条流,刷到一块盘上就很尴尬,这里也对这部分进行了切分,让不同的 Page (或者说 SST 甚至是 SST Block)能够刷到不同的 Chunk 上,来提供优化。
- 这个优化不仅是写链路上的,恢复链路上也可以以同样的方式得到读的 super bonus。
- Reduce remote read and Prefetching:例如通过收集并聚合原分散meta至统一的superblock,将多个I/O合一实现fast validating;通过预读利用聚合读带宽、减少读任务延时;通过压缩、filter过滤减少读取数据量。与本地SSD上相比,这些技术在云存储上更能获得收益。
- 这个地方是说,多个碎 I/O 合成一个真实对远端的 IO,Linux 的一些 deadline 之类的队列也会做 IO 合并,感觉是线上可能比较类似
- 当然,Prefetching 不是万灵药,本质上 Scan Task 会让 DB 层做 Prefetching,但是 Prefetching 也会占用系统的内存。感觉做起来是一个很难很精细的事情,又是嘴皮动一下,实现很难的东西。
- Fine-grained Locking and Lock-free Data Structures:云存储中较长的I/O延迟放大了同步开销,主要针对Update-in-place系统,实现无锁刷脏、无锁SMO等。
- 带锁 I/O 本来就比较重了,在云环境带锁 IO 感觉会重上加重。这个地方可以用一些方法来暴力优化。当然这部分是吹牛两个字,工程做死人的重要典范。
- Scattering among Distributed Nodes:在云存储中,多个节点之间的分散访问可以利用更多的硬件资源,例如将单个大I/O并发分散至不同存储节点 ,充分利用聚合带宽。
- 这个地方看上去和 Reduce Remote Read 矛盾,其实是小 IO 合并,大 I/O 猜测 Chunk 的分布来并行访问。感觉这个需要有一些对 Chunk 内容的先验知识。或者手动干预这中间的物理分布。
- 需要注意的是,这里读写都能从 Scatter 中受益。但本身 Scatter 也意味着很多奇怪的东西。我个人觉得这玩意在大公司能找到存储层的人正面 PVP 或者拉他们一起优化的话会比较好做。
- Bypassing Caches:通过Bypassing Caches来避免分布式文件系统的cache coherence,并在DB层面优化I/O格式匹配存储最佳request格式。
- 其实虽然 Parquet 是列存格式,但是你可以类比迁移到 Parquet 的 Footer。Footer 包含所有 rg 的信息。
- 这个地方应该是绕过分布式缓存,我个人理解是,对 TP 系统而言,分布式缓存本身不是那么好的东西,单机 cache 一下差不多得了
- Scheduling Prioritized I/O Tasks:由于访问链路更长(如路径中存在更多的排队情况),不填I/O请求间的隔离性相对本地存储更低,因此需要在DB层面对不同I/O进行打标、调度优先级,例:优先WAL、预读分级。
- (对着 ScyllaDB 嗯抄!)
- 本质上,这个相当于设计 Log Page 等不同形式的 IO,在 db 层打标,fs 层处理。
需要注意的是,这里可以在实现层次明确一下语义。这里有的东西是 fs 层做的,有的东西是 db 层做的。fs 层可以合并或者操作一些在 fs 上连续的操作,但是很多东西其实是要 db 来打 tag 或者以一些方式来协同完成的。
这里在下图进行了评估:
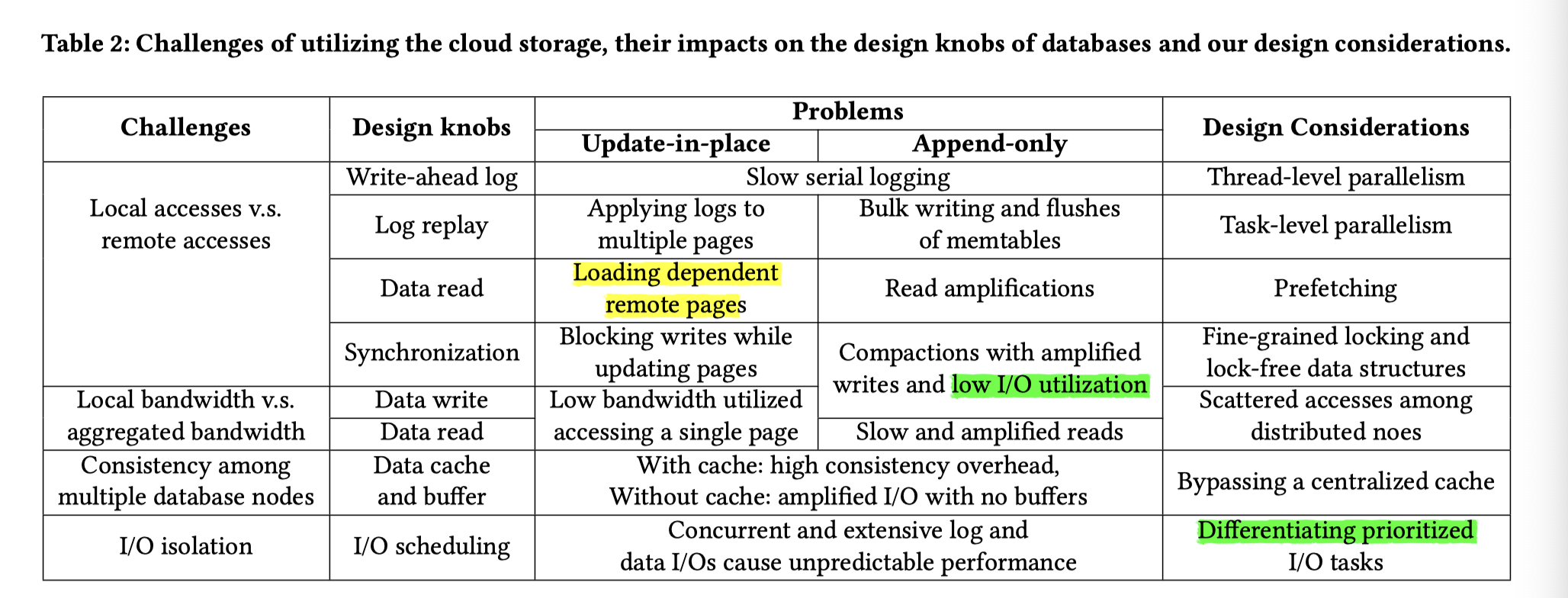
(你看这里全都是黑话,我不给你解释一遍你还在这嗯想他在搞什么花招呢,你是不是得感谢一下我)
这里还有一个细节,是经典的 btr 和 LSM 大战。这个地方可以 Ref 一下作者在知乎上的一点 Notes,不保证对,但是看着确实有自己的思考:
从论文的角度,我们需要追求讨论的完备性,处处都会对比 B-tree 和 LSM-tree,看起来是在回答一个存储引擎技术选型的问题。具体的内容欢迎大家到文章里去看。此处我想区分一个概念,就是产品优先的选型和技术优先的选型是不一样的。
从技术角度来说,LSM-tree 难以提供稳定的性能,其读写放大都太大了。为了做成一个好的产品,像 OB 这样用 LSM-tree 用得比较好的系统,其实是使用了一些成本较高的架构才实现的这一点。比如大家如果点开 OB 的 TPC-C 结果,会发现它的单个数据库节点坐拥 712 GB 内存,而整个集群像这样的大节点一共有 1557 个。如果没有比较大的规模,像 OB 这样的分布式数据库很难实现 8 小时内 tpmC 性能波动小于 2% 这样的性能稳定性要求。在云上,OB 需要使用多租户这样的形式来降低单个用户的使用成本。
OB 做这样的设计是因为他们一开始就假设了充足的内存,充足到一个数据库的内存可以充分缓存一天之内的所有变更,以至于每天只需要在夜深人静的时候做一次 compaction 将内存里面的变更与磁盘上的基线数据合并。这样不仅性能稳定,而且 compaction 对资源的占用也被尽可能地隐藏了,OB 甚至还在同一个 paxos group 内搞轮转合并,进一步隐藏 compaction 的影响。这套设计挺厉害的,就是太贵了。
如果大家了解公共云数据库的话就会知道,绝大部分用户的数据库节点一般是 4C8G 或者 8C16G 这样的小规格,与 OB 的节点规模相差非常大。
同一个 LSM-tree subtable 内部不同的分层之间因为存在数据耦合,为了做一个 get,如果我们只定位一个 extent,是没办法确定其中存储的数据是不是我们所需要的 key 的完整 value。这样不利于 LSM-tree 的数据像 page 一样在分布式存储集群里面自由地摆放。如果 extent 打散了,每次查询的时候都需要做跨界点的 merge。
(上文摘自知乎文章: https://zhuanlan.zhihu.com/p/548215678 上云是存储引擎技术的分水岭。本人保留态度。感觉 LSM-Tree 本质上是把这个开销从 btr 的 implicit 的平常的重操作中暴露给了用户。至于读写,实际上这是一个很古怪的问题,因为 DB 并不是 kv 引擎,有大量的 RWN 场景。直觉和网上关于 LSM 的一句话说清楚的对比材料实际上我觉得都是真空球型对比。我个人觉得,我们只能关注,在具体实现上,每个链路 IO 是什么样的,什么在前台,什么在后台。)
PolarDB 的优化
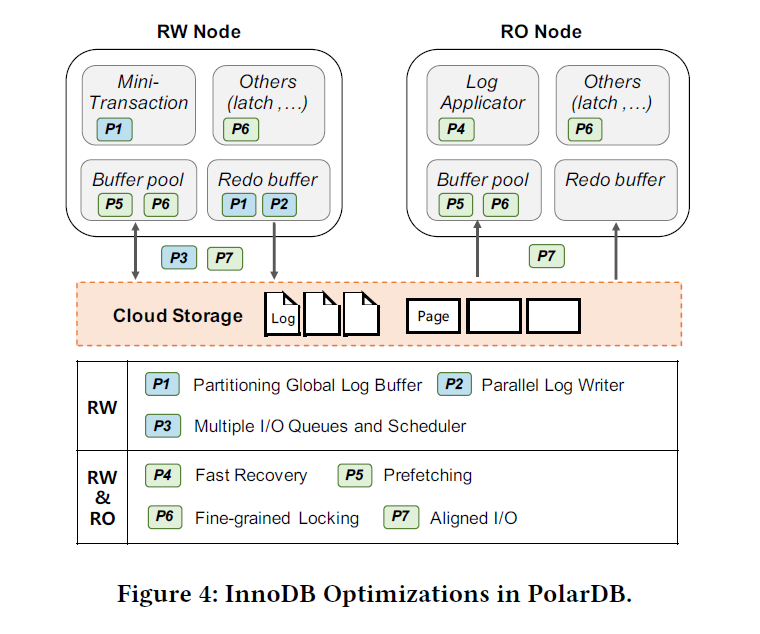
这里的 P 是采用的优化,在 RW 节点上,主要和写链路有关。这里最多可以有 15 个 RO 节点,在 RO 节点上,采取了一些读相关的和恢复相关的优化。一些优化两边都有,包括 Page 和 Log 的 Read。
Accelerating Persistent WAL
这里观察到,大部分 mtr 串行拷贝,而且只写一个 Page,这里用 Link_buf 来 Merge 对下层的 IO,转化为大块的可能跨 Block 的顺序 IO
这里采取的优化是,切分 Log Buffer,按照 Page_ID 做一些尽量细的切分。
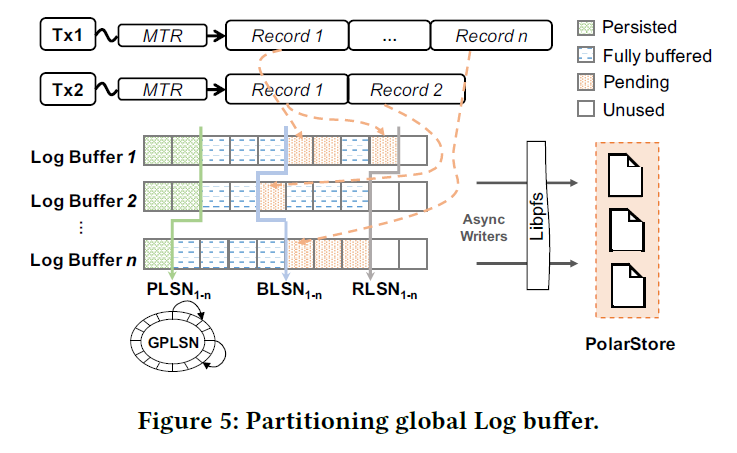
这里引入了一个类似向量时钟的概念,然后把 InnoDB 的日志写切分成了几个阶段:
前台:
- Reserve RLSN
- Copy 多个部分的日志(可能绝大部分时候只有一份?)
- 标记拷贝完成
Log 相关的线程:
- 刷的时候,推高 PLSN
- 拿到 BLSN,然后刷 PLSN - BLSN 的数据
- 并行去刷不同的日志,这里有一些细节要在后面 IO 层讨论。
原先的 LSN 被设计为 GPLSN。这里相当于从原来 LSN 再扩展了一套机制,而不是用向量时钟完全取代 GPLSN。这个地方的正确性感觉是比较 trickey 的,因为我感觉其实有一个 LSN 和日志完整性的问题,因为如果 round-robin 的话还好,不 round-robin 的话,LSN 感觉不太好直接映射到所有的 PLSN,不过感觉工程上也是可以解决这些问题的,看文章似乎是 Log File 有 GLSN — Log 的映射。
这里还设计了 Rw 到 Ro 的 Redo Log RDMA 写,来避免 fetchlog 来大幅度影响 RO 节点(日志流是无限的,一直拉本身是个很 trickey 的事情),不过感觉这部分就很 trickey 了,有点天顶星科技。
Log Writer 实现如下图:
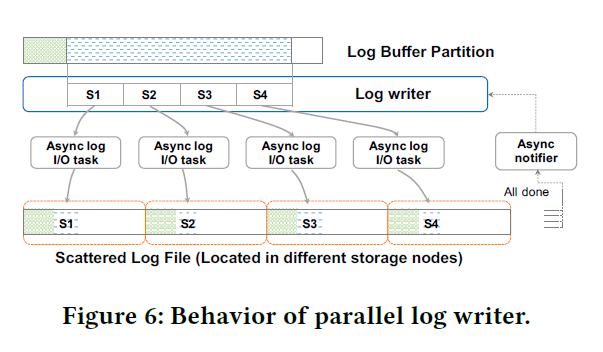
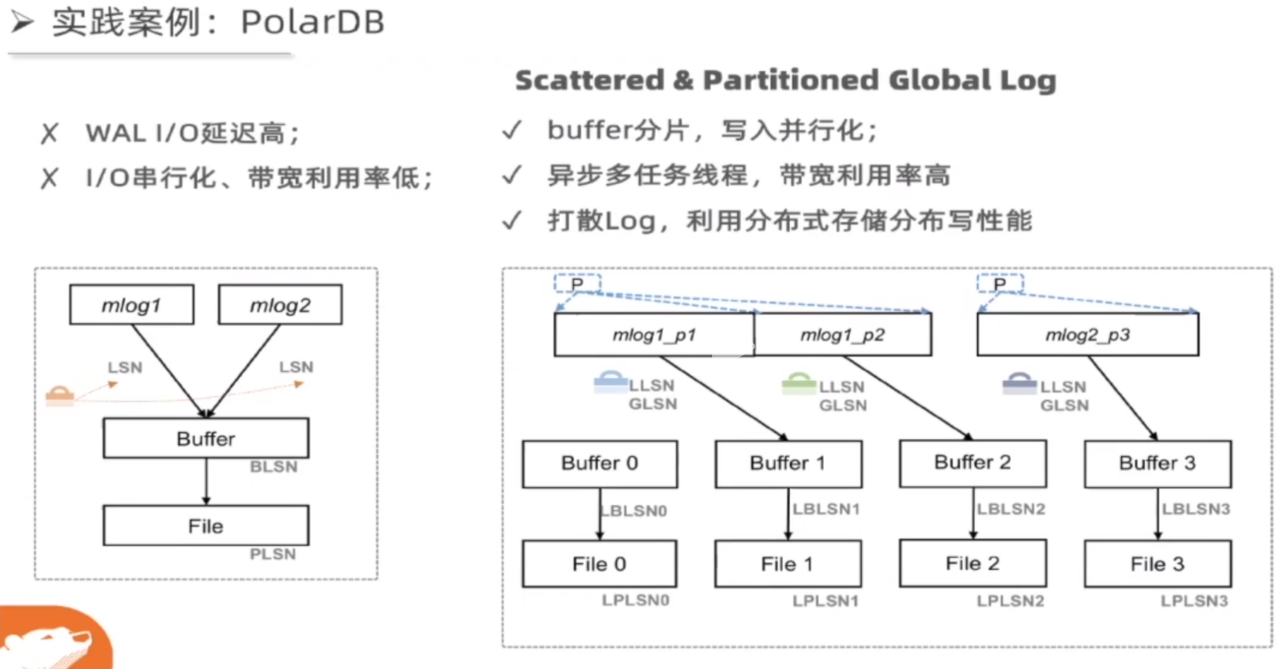
这里会把单段切碎的 Log Buffer 再分成细小的 Log Slice,然后单个打 Buffer 可能会分配给单个线程,找它的 Log Writer 走 async io 发送。达到了即聚合 IO(log 本身是一种聚合)又切碎 IO 的方式。不过 IO 任务多了,本质上也是一种很 trickey 的事情。我感觉这种方法类似大力出奇迹。
Fast Recovery
InnoDB 的 Log Replay 有两种形式:
- Crash recovery
- Log Apply in RO node
传统的 DB 恢复需要读 HDD/SSD 散在各处的元信息,然后根据这些信息,再走 ARIES 协议恢复。PolarDB 中心化了 InnoDB / MySQL 的元数据,进了一个 Superblock (可以想象一下 Parquet 的 Footer 部分作为对比?)
这里和写日志一样,恢复也可以并行恢复,然后在 Log File 的 Header 做了一些 GLSN — Log 的映射,来保证 Fast Seeking。

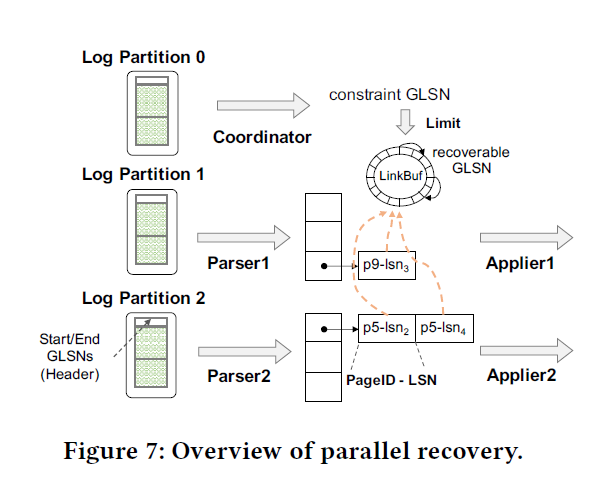
这里回复的时候,如果某个 mtr 涉及了多个 Page,导致涉及了多个 Partition,也要原子恢复。这里的做法是,把所有的逻辑操作和文件操作放在 Log Partition 0,导致有复杂的事务必须由 Log Partition 0 来做一些全局的恢复流程,然后通知 Applier。这里再恢复的时候维护了一个 recover GLSN 来实现这套逻辑。
(卧槽牛逼牛逼牛逼牛逼)
Prefetching
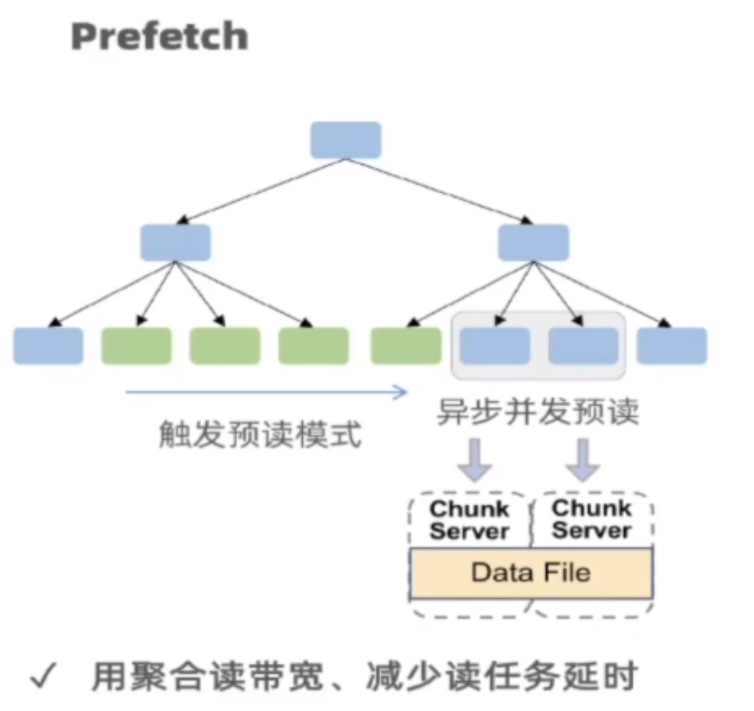
Prefetch 也是个工程上做起来实际上非常恶心的事情,这里有几种 Pattern:
- Cluster Index 上的 Scan,肯定 prefetch
- Secondary Index 的 Scan,Batch Key prefetch
- Locality: 某个 Page 经常被查大概率经常被更新,所以很可能有 SMO,可能需要 Prefetch SMO 需要的 Page
Fine-grained Locking
这里分成两部分:
- Index optimization: PolarDB 优化成了无敌无敌无敌的 Bw-Tree。本质上还是处理复杂的协议和 SMO 问题。
- Shadow Page: 本质上感觉是一种内存换锁开销。因为这里的问题不是更新,而是带 Page 锁 IO。
Multiple I/O Queues and Scheduler
这算是 IO 共享层很常见的策略了。不过这里不是靠存储层根据付费 QoS,而是一个优先级调度层。
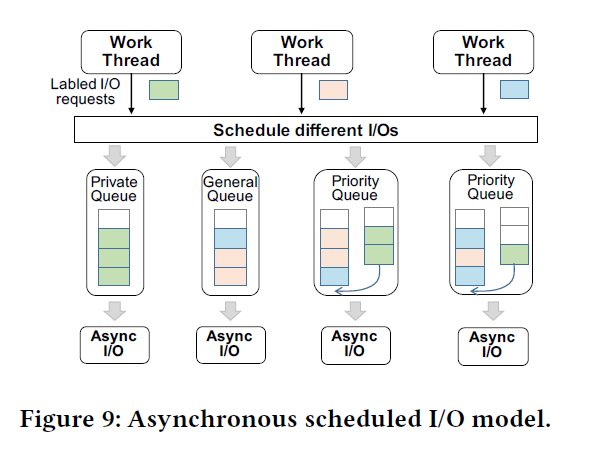
- Log IO 本身是优先的,放到 Private Queue
- Private 满了走到全局的 Queue
- Page 这种操作资源比较重,不能抢占 Log-IO 的资源,但是可以在自己的资源池里面进行。
Aligned I/O
这里分成几个部分。因为块存储的 Block 可能很大,PolarFS 是 4-128 KB,这个地方需要调整对应的 大小:
- Log I/O 需要对齐一定的大小和格式
- Data I/O 需要考虑 Compressed Page 和非 Compressed Page,做一些 IO 处理
- Vanilla MySQL 会合并相邻的 Page 写,这里可能会阻止这种合并来利用聚合带宽
(其实 1/2 我没有完全看懂细节,懂的可以讲讲)
Experiments and Evaluation
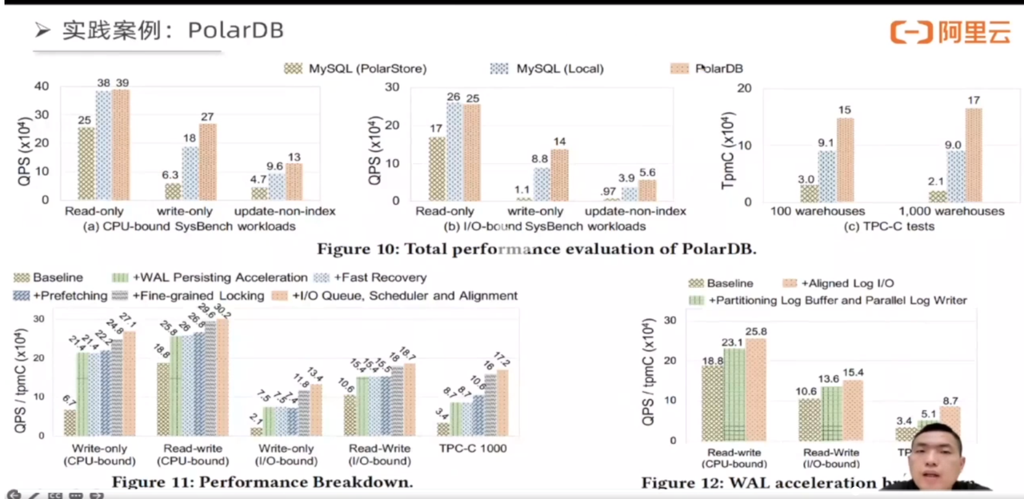
References
- PolarDB-CloudJump:优化基于云存储服务的云数据库(发表于VLDB 2022) http://mysql.taobao.org/monthly/2022/06/01/
- 过去5年,PolarDB云原生数据库是如何进行性能优化的? https://zhuanlan.zhihu.com/p/535421993
- https://zhuanlan.zhihu.com/p/548215678 上云是存储引擎技术的分水岭
- Talk: 揭秘 PolarDB 计算存储分离架构性能优化之路
- https://zhuanlan.zhihu.com/p/547171082 网易的云原生数据库,提到了这里带来的性能优化