SQL Server Columnar Stores
SQL Server 在 2012 年 - 2015 年间推出了好几篇有关列存的论文。在差不多同一时间,它还有一系列内存数据库引擎相关的讨论。在 2015 年的论文中,这些内容被合并起来了。随后,SQL Server 又有一些评估对应效率的论文,这里提到的列表如下:
- [SIGMOD’11] SQL server column store indexes
- [SIGMOD’13] Enhancements to SQL Server Column Stores
- [VLDB’15] Real-Time Analytical Processing with SQL Server
同时,在内存数据库方面,论文其实还更多一些:
- [CIDR’11] Deuteronomy: Transaction Support for Cloud Data
- [VLDB’11] High-Performance Concurrency Control Mechanisms for Main-Memory Databases
- [SIGMOD’13] Hekaton: SQL server’s memory-optimized OLTP engine
- [ICDE‘13] The Bw-Tree: A B-tree for New Hardware Platforms
- [PVLDB’14] Trekking Through Siberia: Managing Cold Data in a Memory-Optimized Database
- [IEEE’14] Compilation in the Microsoft SQL Server Hekaton Engine
在 VLDB’15 的论文中,这些东西终于被结合到一起,可以在 Hekaton 上跑列存引擎了。
这些东西也可以被放到所谓的 HTAP 宏大叙事中:

当然我们可以认可 HTAP 是个商业概念,但是技术是真的,我们还是要看看这些东西是怎么做的。
先回顾一下列存的三篇论文,简单介绍一下他们的包含的内容:
- SQL Server Column Store Indexes 这篇文章是最早的,介绍了 Column Store Indexes,值得注意的是,这里基本上是没有更新的 handling 的,应该只有 Batch 插入,这里功能应该类似 Secondary 的覆盖索引,用户的查询如果可能的话,可以直接走这个 Index,然后可以不走主表。这篇文章也描述了执行和优化器上做的一些优化工作
- Enhancements to SQL Server Column Stores 这篇文章支持了更新和把它当作覆盖索引,同时,增加了 UPDATE Handling 和一些 Join 算子的细微实现。现在 SQL Server 引擎把数据的 schema 组装成 RowGroups 和 Delta-in-row-group。这里有一些 hacking 还没贴出来。这里应该是支持了操作很重的 Update
- Real-Time Analytical Processing with SQL Server 结合了 Hekaton 引擎,同时,给 Column Stores 做了再增强,现在可以支持 Primary 和 Secondary 的 Column Index 上 Update,然后内存对接 Hekaton 引擎,这套操作在 Delta-in-row-group 上再封了一层逻辑。
我将循序渐进简单介绍一下,这套系统是怎么实现的
SQL Server Column Store Indexes
这个版本是相当于给 SQL Server 添加一个 secondary index 版本,然后设计了一个类似 Parquet 的格式。
这里定义列存为一种新的索引类型,这个索引我推测不是 RDBMS 那种索引,感觉是一个仅支持插入对部分列的一个 mv 。这里主要任务还是给 AP 查询。它基于 SQL Server 做的 BLOB(LOB) 功能(感觉这套单机和分布式都研究得比较透彻了)。基于 BLOB,它有如下的视图:
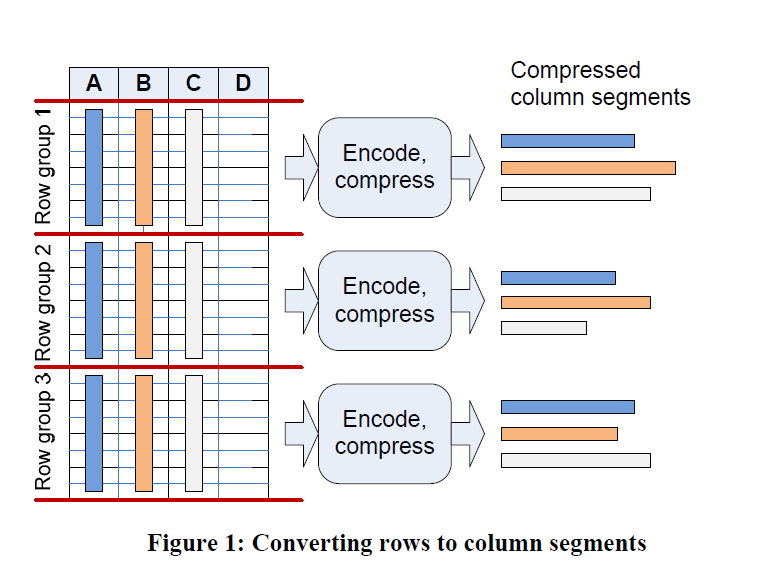
和
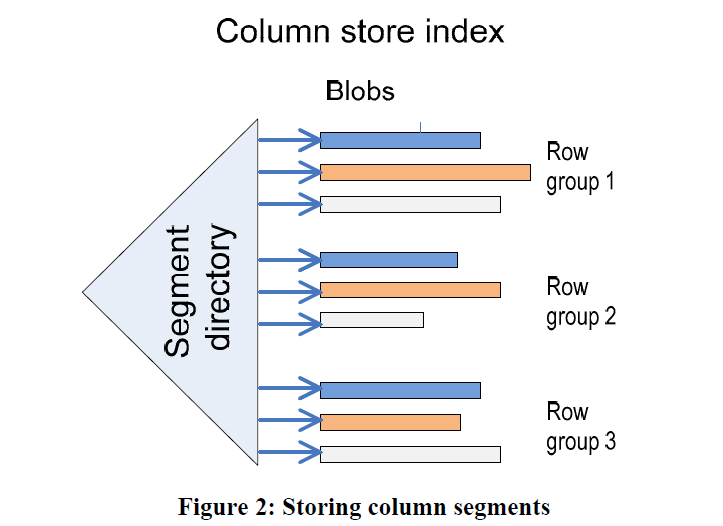
- Page:基本概念可以平移自 Parquet 的 Page,变长
- (Column) Segment: Parquet Column Chunk
- RowGroup: 对应 Parquet 的 RowGroup,在这篇论文里面大概有百万行级别的数据
- Directory: 类似 Parquet 的 Metadata / Footer
上层的一些 Locking / Logging / Recovery / Partition 之类的策略尽量用 SQL Server 的代码
Data Encoding and Compression
Encoding 部分很草台,没啥说的,我相信微软,不过这篇文章描述确实很糙。微软后面好像出了一些 CompressDB 之类的论文,这里不介绍了
后面还描述了一些 RLE + Bit-packing 相关的,可以直接参考 Parquet 的 RLE 格式,总的来说是没有什么新东西的。
Optimal Row Ordering
这部分比较有意思,其实某种程度上有点 Auto Clustering 的味道,我们考虑以下逻辑:
- 数据有一致性的情况下,encoding 性能和效率会很好,一个非常好的例子是 RLE / DELTA
- 因为只会在这个索引上跑一些分析,所以 Order 并不重要
所以会根据数据来重新组织,提高性能
当然,对多列数据进行这样的操作是个比较复杂的问题,因为本质上需要一个衡量措施来保证这个东西对用户是有效的,多列的某个 optimal 的策略可能损害单列的性能。
论文说这里采用了 Vertipaq™ algorithm。好像 auto clustering 会使用 z-ordering 一类的算法。
Caching 和 IO
BLOB 因为是变长的,在 Disk 上可能会跨多个 Disk Page。这里设计了一个 Buffer Pool (感觉类似 TUM 新项目那套?)来缓存对象
这里会有两种 read-ahead:
- Column Segment 内部的 Read-ahead
- Column Segment 间的 Read-ahead
我个人感觉这个还是很难做的。
Query Handling and Optimization
这里作者基于下列逻辑推断:
- Column Store Index 会大大减少读 Disk 的 IO 开销
- 所以,CPU 可能会成为一个瓶颈点
这里会采用 vectorize 的方式做计算。
这套东西本身比较复杂,不过尽量简单的说:
- 复用了之前的 SQL Engine
- 减少实现开销,保持用户透明度,同时 Query 可以同时包含 Row 和 Column 的处理模式
- 允许 Query 在运行期动态变更执行模式(这里目的写了一些奇怪的东西,感觉上是早期实现原因,不过这个姑且也很诱惑人)
- 允许列存为正交 feature,为事后搞别的事情做出铺垫
在执行的时候有一些 tricks,考虑到这些 tricks 实际上还是挺重要的,具体列存是不是可以参考一下 Velox:
- 添加了 Batch Operator
- Access Method 允许下推 bitmap filter 和谓词
- 尽量直接在压缩的数据上做操作
- 使用 Delayed String Materialization
- Bitmap Filter 被改成一种很泛用的格式,根据数据分布的不同,执行不同的逻辑(类似 Roaring Bitmap?)
- 做了 Runtime Resource Management
在 Query Optimization 阶段,Query Optimizer 可以根据 RowGroup 的大小来估算一些 IO 开销,来进行优化。在这篇论文里面,感觉 RowGroups 都比较静态,都是 immutable 的,所以感觉这块做的会不算很复杂
直观感受是,Column Store Indexes 对 Point Get 和 Range Scan 性能比较差。
实现上,Batch 操作会被定义成 Batch 是一个 Physical Property,用这个来保证查询的性质。
在 Join 中,这里会尝试在 Build 阶段构建 bitmap,类似 dynamic-filter,然后下推到 Probe-Side。这里如果有多张表 Join,它会抽取出 Join 的条件,查看哪些表是事实表,哪些表是维度表,根据这个构建 DF.
下面举几个查询的例子:
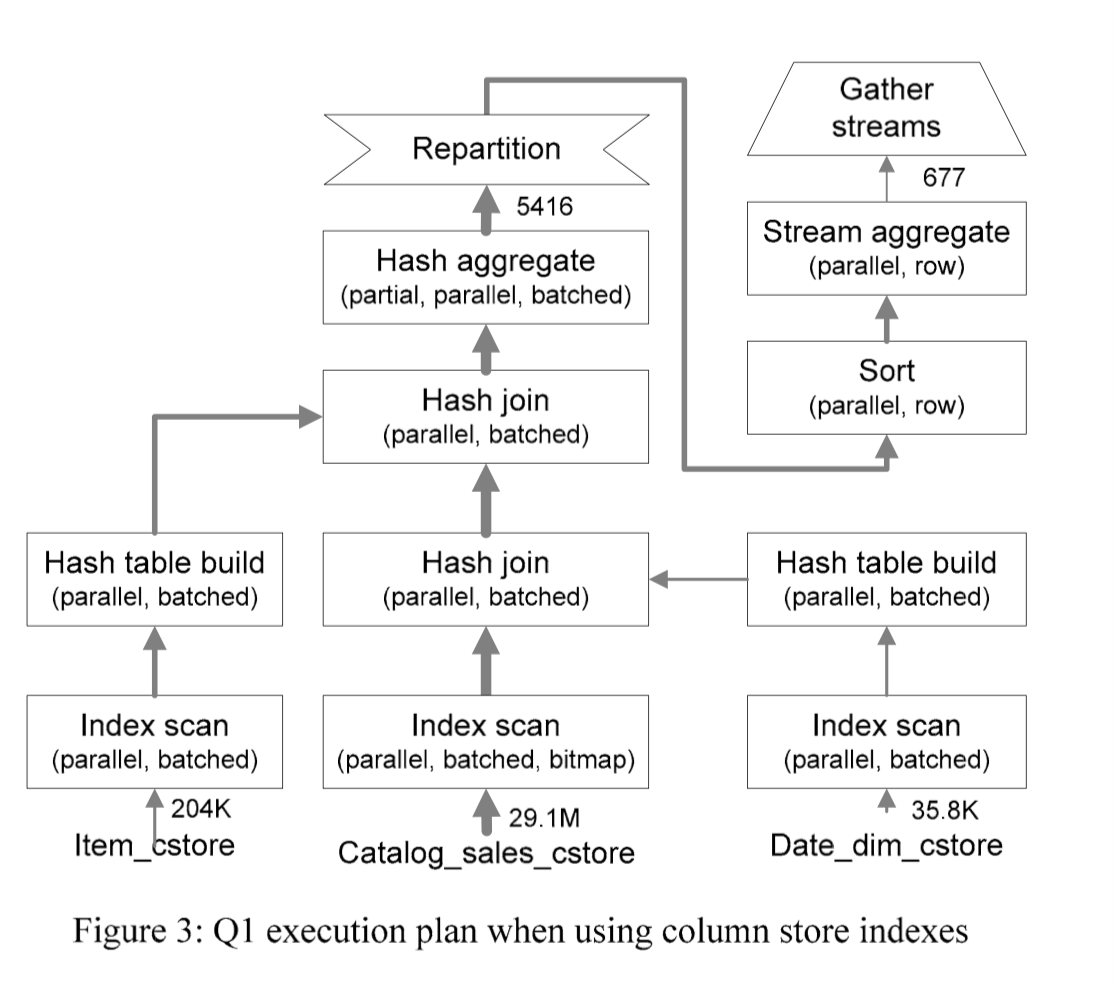
Enhancements to SQL Server Column Stores
这篇文章允许 Column Index 可以更新,并且可以作为 Primary Index(可以类比成 MySQL 的 Cluster Index) 存在。需要注意的是,这篇文章本身没太提,但是结合后面的论文可以看出来,它这个是给数仓型应用设计的
这文章前面逼逼叨叨了一下之前的设计:
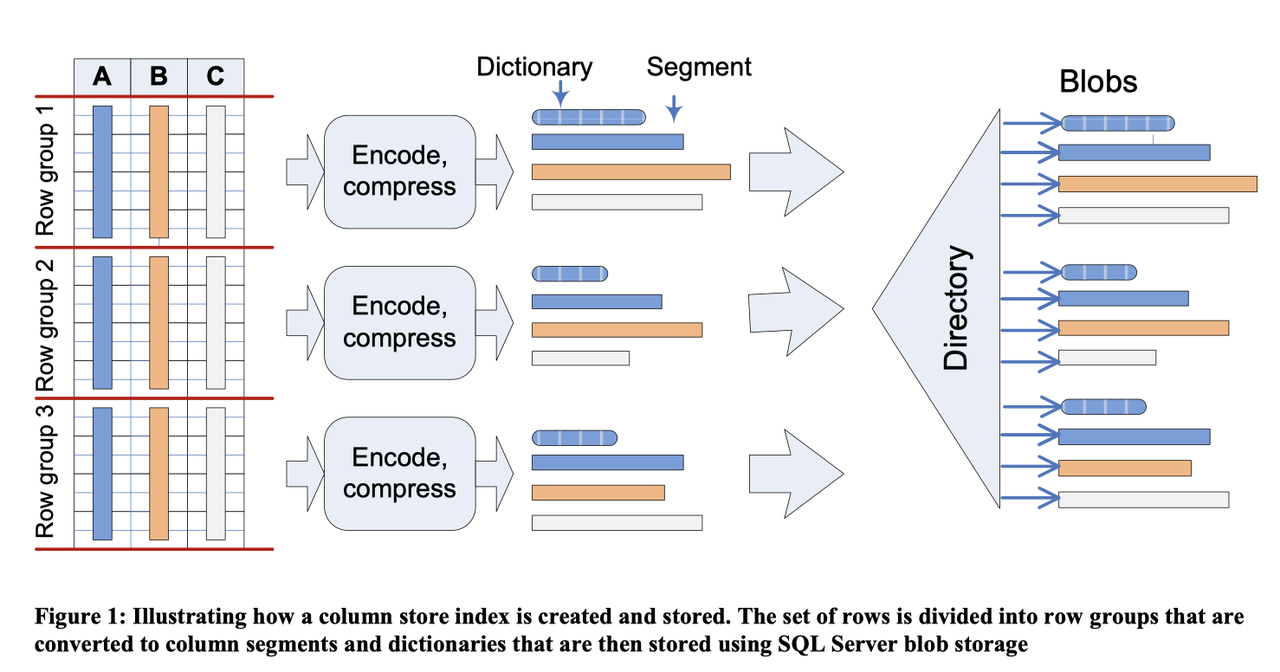
优化之前的设计
和 Parquet 不同的应该是字典的处理方式。论文感觉没特别详细指出不同列字典是怎么处理怎么 fallback 的,不过感觉也不 care 了。
SQL Server 有两种字典:
- Global Dictionary: 某个 Column 的全部字典
- Local Dictionary: 某个 RowGroup 的字典
这里的构建采取了这样的流程:
- 采样,决定是否要构建 global index
- 构建 Index
比较值得一提的是,Index Build 阶段内存开销会比较大,这里需要:
- 提前申请好内存的一个阈值
- 根据内存,可以分配切 RowGroup 之类的大小,还可以切成多个 DOP 来构建,每个线程拿着一大块内存
- 这个地方,线程过多,可能会切的过碎,造成一个次优的选项。所以这个地方会动态调整 DOP,来动态控制线程的数量。这里调整方式是根据系统每个线程实际占用的内存可以反映这批数据的分布,用这些情况来动态的决定,在预估的这些内存资源下,开多少个线程比较合适。
SQL Server 相关语义兼容
采样
采样 / 统计是个比较常见的需求了,数据库内部需要采样来支持 statistics,ClickHouse / Snowflake 以及很多现代数据产品还要高效支持 SAMPLE 算子,来帮助那些不知道在做什么的科学家来高效的随机 SAMPLE 一些行。
SQL Server 的查询优化会需要统计信息,非 Primary Index 的索引不需要做 Statistic,因为它认为可以在 Primary Index 上做收集即可。这里有两种收集索引上信息的模式:
- 高性能,低 Accuracy
- 随机选中 RowGroup,在 RowGroup 内随机选中 Row。上面的选择率由采样比例来手动定义
- 在构建字典的时候尝试采样,选择这种方式
- 高准确度,高 IO 和 CPU 开销
- 扫描所有 Column Segmentsm,在里面随机选中一些 Row
- 在构建 Histogram 的时候使用这种方式。
UUID(Bookmark) support
这里 Bookmark 类似 PG 的 (page, slotId), query optimizer 之类的都会依赖这个 Bookmark。这里用 (rowGroupId, rowId)来代表 bookmark。
突然发现,本质上这个和 id 变更或者 WiscKey GC 是一样的场景。
Update Handling
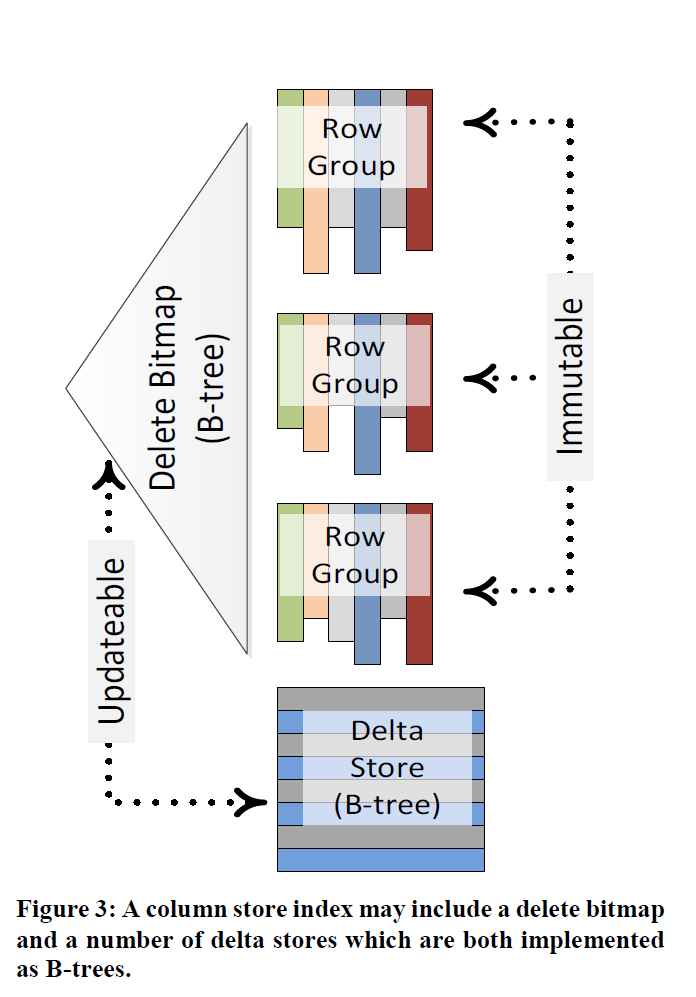
Columnar 的直接更新是一个很大的性能下降,这里希望在不损害压缩性能(有的格式,像一些 HTAP 的格式,通过 micro-block 之类的方式来做直接更新。感觉压缩率肯定比不过这些列的格式)。这里还是希望写比较快。
这里表格更多是 data warehouse 的事实表,数据一般会有大量的插入和比较少量的更新和删除。这里可以看上图:
- 内存中:
- 新插入的记录被写道 delta store 中,这是一个 btree。这个阶段应该还没有产生一个 RowGroup Id,系统会给它生成一个 unique integer 的 key。
- 磁盘的删除记录被表示在 delete bitmap 中
- 磁盘中:
- Delta Store 的 Btree 对应磁盘结构
- 包含多个 RowGroup 的 Column Store
- 内存中的 delete bitmap 在存储中可能是个 Btree
做不同操作的时候:
- Insert: 插入 delta store
- Delete: 如果是 delta store 的记录,那么直接删除它。否则插入 delete bitmap
- Update: 拆分成 Delete + Insert
- Merge: 拆分成 Delete + Insert 等操作
Delta Store 感觉上有那么一点类似 RocksDB 的 MemTable 或者 Kudu 的 MemRowSet,本身行存 + 1 份 active,后面的会被慢慢移动到 Disk 上的列存结构上。这里需要说明的是,和 RocksDB 的 MemTable 不同,这里的实际上都还是 active 的,但是 delete 可能还是会进来
在 move 阶段中,写正在 move 中的 Delta 会被 Block 住,直到 move 操作完成(其实这个 Kudu 好像都有实现)。move 和读取是可以并发的。在 move 完成之后,可以在元信息中做提交,队之后的事务,写入的 RoiwGroup 可见,然后 Delta 不可见。等待依赖 delta 的事务都完成后,这个 delta 就可以 GC 了
Bulk Insert 会被额外处理,通常 Bulk Insert 可能是某个 ETL Job 的一部分,Row 很多会直接构成一个 RowGroup。如果 Row 不够多,这个地方会先 Build 出一个 Delta Store。这里 SQL Server 强调了一下,希望保证每个 RowGroup 有百万行数据。
这个地方,Scan 可以做的非常干净,因为对 Delete 的处理可以完全在算子层(Scan Operator)解决。不过我想了下,比方说查询优化本来可以简单从 Zone Map 读 Count(*),但是现在需要 Zone Map 的 Count 记录减去 Delete 对应的数目,这个流程稍微变得 Trick 了一些。总之上层做一些优化的时候要考虑到这一个流程。
有大量删除记录的 row 会大大降低性能,在大量的删除后可以做一个 Compaction 来提高性能,不过我感觉 Compaction 流程也类似 Kudu 的 Compaction 或者 WiscKey 的 GC,需要注意映射关系的维护。
不同的 delta store 可以分给不同的线程去读,因为读 delta store 很慢。
在执行的时候,这里会尝试推一些 bitmap 下来,类似 dynamic-filter。存储层会处理这个 BF,来优化扫描(感觉 BF 字典之类的可以合作):
To avoid this explosion, hash join operators now store information about bitmaps and their estimated selectivity. At implementation time, the selectivity information is passed to the child, enabling it to adjust its cost to account for the bitmap selectivity. In order to limit the amount of optimization requests to child groups the optimizer does not treat each request as different, but rather clusters requests based on their selectivity thus being able to reuse far more than it would otherwise.
这里对很少访问的分区,还会采取更激进的方式去压缩,来节约空间。
Real-time analytical processing with SQL server
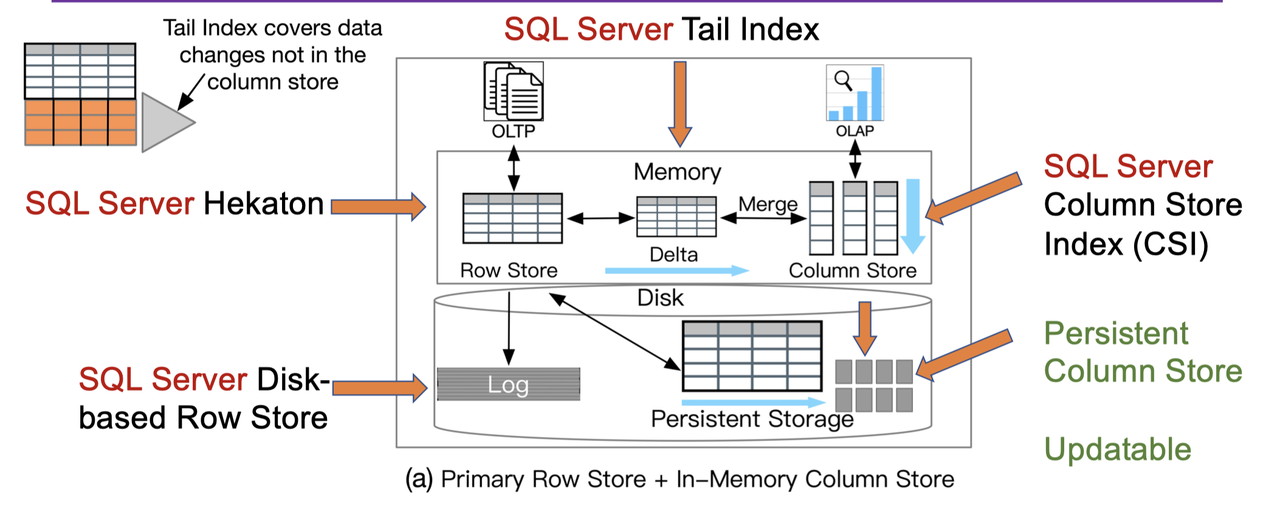
这篇论文大概的结构可以看上图。图片没有什么意思,一些细节还是很值得一提的。
文章作于 2015,算是有个 Hekaton 内存 + Disk 逻辑了。内存数据库不是已经够快了吗?论文认为,这样还是可以优化一些 AP 查询。在之前,添加 CSI 会让表只读,13 年的论文让主表可以是一个 Column Index Store,来给数据仓库提供负载。这篇文章算是提供了一个可更新的 Secondary Index。这个有什么区别呢?答案是他们认为更新 Primary Index,说明整个表都是 Column Index,本身是个数据仓库。Secondary Index 可能主表是个 Btr,是优化某一类 AP 查询,所以希望更新有更好的适配 TP 的性能。SQL Server 用了个很巧妙的方法来操作。
我们可以从结论上推断,类似 TiDB 用 TiFlash 达到了 HTAP,这篇文章设想是准备一个索引,然后用内存中的索引来实现 HTAP,实际上这样不需要 Log 流来同步,但是需要隔离相关的查询负载,同时也要注意对主链路性能的影响。
CSI On In-Memory Tables
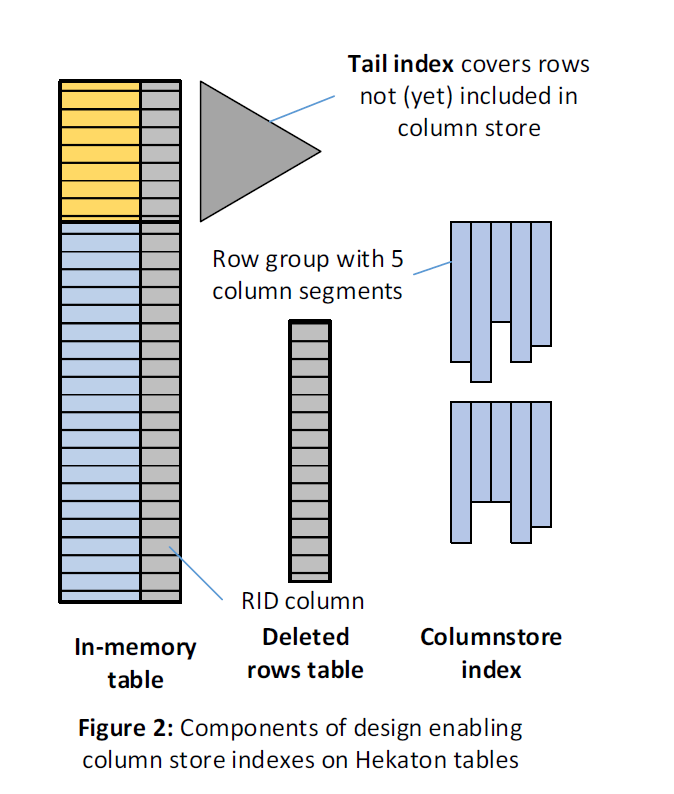
这里所有靠谱的内容都在内存中,Tail Index 部分的内存没有被写入 Column Store。这里相当于用 In-memory Table 部分代替了 Delta Store 的部分,来提高了更新性能。删除的数据会被放到 Deleted Rows Table 中,这也并不全同于 Delete Bit Map。有一个 Data Migration Task 会迁移 Tail Index (没有写入 Column Store )到 Column Store 中,这部分有一个很 Trick 的地方,就是本身 Hekaton 引擎就处理了 MVCC,然后数据不刷下去正确性也是保证的,所以,这里为了不让 deleted rows 被频繁更新,所以不会希望某些被频繁更新的行被刷下去,而是希望这些部分能够一直被 Keep 在内存中。
被实现成了两部分:
- Stage1: 线程把非 hot 的部分刷下去,这个时候使用一个读事务,写完之后这些记录都相当于是删除的。
- 这个地方有个 Hack 是,Deleted Rows Table 应该是个特化的实现,可以 mark 一整个范围的删除,通过这个来减小插入的时候 mark as deleted 的开销。
- Stage2: 用多个事务回填 row-id 和 mark as undeleted。这部分可能和用户事务冲突。这部分的内部事务做了特殊处理,让它尽量不影响用户的事务。
同时,在 flush 的时候可能会顺带执行一些 RowGroup Cleanup,如果一些 Row Group 被删除的差不多了,那么,在 Flush 的时候可能相当于会把它们合起来(感觉上,这个表示所有 Row Group 都在同一层,没有 L1 L2 的概念)。
Updating Secondary Column Stores
Primary 的一个问题是,需要 Hekaton Table 高度配合。Secondary 相当于 Hekaton Table 没有那么好的能力去配合你。所以这里需要一些别的方式来处理这部分逻辑。
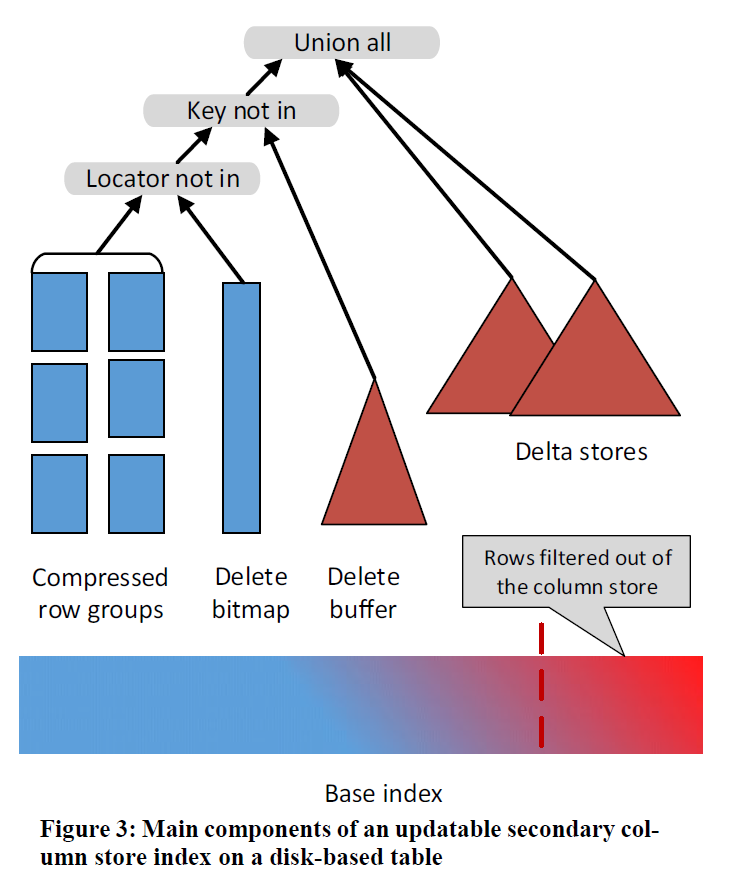
这部分中,相当于添加了一个 Delete Buffer,这是一个类似 InnoDB Change Buffer 的东西,因为找到原记录是非常昂贵的,需要一次点查。这里引入了一个 delete buffer,来专门处理这类场景。Delete Buffer 本身是一个包含删除 key 的 Btree。它的格式是 <Key, Delete-Generation>,这个 Generation 是 Delta move 的 Generation,删除的时候,会用最高的 Generation 来删除。
查询 Delete Buffer 的时候,这套逻辑没有再封在转换层,而是插入了一个 Join 算子(anti-semi-join),来带上 Delete Buffer。这里在 Build 阶段会算出 key 的 min-max 是否在这个 row-group 中,来跳过 delete-buffer 对一些 RowGroup 的访问。
注意,这个 delete bitmap 更接近上一篇论文的定义,而不是 primary index 中那个使用的定义。