perfbook notes: Hardware
Perfbook 全称是 Is Parallel Programming Hard, And, If So, What Can You Do About It? 作者是 Paul E. McKenney,也是 RCU 的发明者。这本书相对来说语法有点点难,我个人看的有那么点小吃力,但是作者能够非常形象的描述并发数据结构是怎么设计的,并且从 scalable-counter、partition、lock、data-ownership 介绍到 RCU。书具体内容很好,也值得我做一些笔记以便未来回顾。
书的编写会包括一些 Quiz,有的还是比较有难度的,帮助自己理解问题。我的笔记只供自己做一个回顾和一些工业界实现的参考,所以不会完全参考原书的布局。
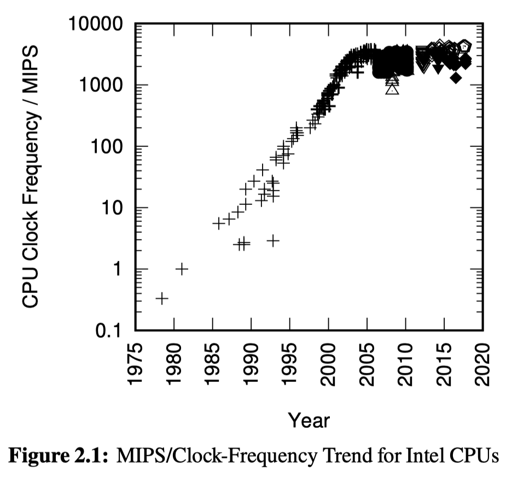
Chap2-4 描述了一些 smp 的原语和性能
并行编程的需求、基本性能与原语
并行编程在上世纪是个非常小众的领域,只有专业人士会写。但是随着 CPU 撞上功耗墙,这一小众领域现在已经成了大众卷 b 之地。现在有 tbb、folly 等库,也有 thread atomic 等编程工具/原语。此外,还有一些用户态线程、协程也在近年重新受到关注,它们可以减少线程调度和切栈或者申请栈的开销、和 async 等语法结合,用于优化代码和改善性能。
并行化的优势在于:
Performance: 包括 scalability( performance per CPU) 和 efficiency (performance per watt), 这两个东西都重要,一起才能拼出个不错的最终结果。同时如果你的程序够快、没有性能问题,那串行就串行吧。
Productivity: 通过你的东西,实现内容的生产力
Generality: 方法的通用性。事实上我们之前讨论的 RCU 什么的 api 相对来说性能好,但是通用性确实差不少。
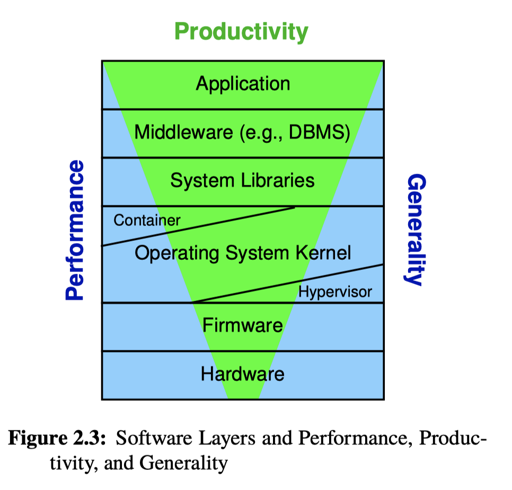
这里考察了 C++ POSIX Thread API(Performance、Generality),Java (相较 C++ 牺牲了一点性能)、SQL (不太泛用、领域专一,但有着好的性能和 Productivity)。
然后作者整了张图,再讲了下 OS/硬件 层面是如何对上述内容取舍和抽象的。因为 OS 本身是一个很「通用」的东西,所以它的 Performance/Generality 的要求是很高的,而越上层的应用可能对 Productivity 要求越高。
Alternatives to Parallel Programming
这一节的内容非常的工程师智慧,介绍了如何「不编写一个并行的系统,又用上硬件这些功能」:
- 运行多个串行系统的 instance,并能够对 workload partition
- 用已有的并行系统
- 串行上进行优化,优化到不用并行也运行的挺好
What Makes Parallel Programming Hard?
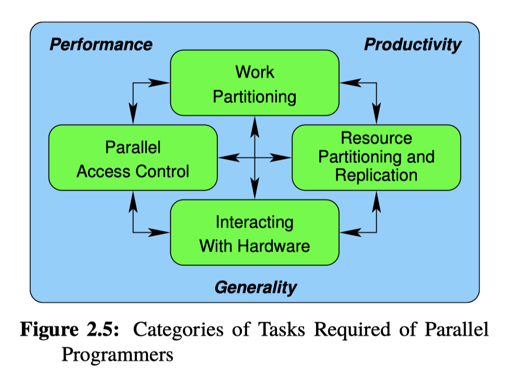
因为这个地方要成功的切分任务,然后既然有切分,那运行之类的还有通信的事情要考虑,同时还要考虑资源管理、回收 etc… 本身这些任务都有相对的复杂性。
这一节相当于介绍了「并发编程为什么这么难」。其实可以看到,跟我个人的想象不同,这个领域是
Hardware and its Habits
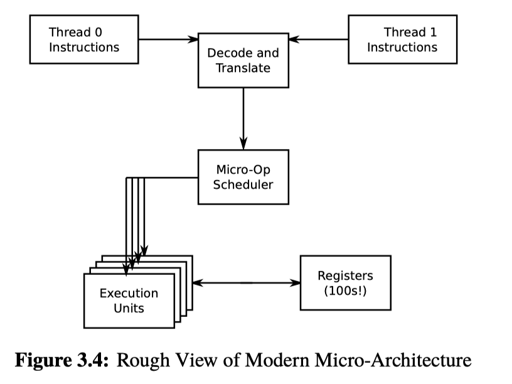
一个现代的 CPU 大概在执行的时候会有:
- pipelines
- Superscalar
- Speculative execution
- …
具体我感觉 15-418 给的材料比较好。
关于现代 CPU,本身性能下降的原因,perfbook 列了:
- Pipeline 相关,比如 branch mispredict/structural hazard: https://blog.mwish.me/2020/10/21/SDS-Intro-RISC-V-Datapath-4-Pipeline/
- Memory Reference: 这里不光是访问内存的开销,更多的是,给出一个地址,然后访问其内存的开销。
- Atomic Operations: 这个地方不涉及 memory barrier, 应该指的就是对某段内存的 atomic 操作。原子操作有的地方是违背 CPU 假设的。atomic op 的操作经常要:
- 保证数据是这个 cacheline 所有的
- 操作完后数据还归属于这个 cacheline
- pipeline must be delayed or even flushed in order to perform the setup operations that permit a given atomic operation to complete correctly.
- Memory Barriers: memory barriers 在语言层面上经常和 atomic op 放在一起讨论,但是这个可能需要对 Writer Buffer 之类的东西做特殊处理,可能会影响应能
- Cache Miss: 懂得都懂。
- I/O Operations: 懂得都懂。可惜我不懂 io_uring,令人唏嘘。
按照我偷来的图:
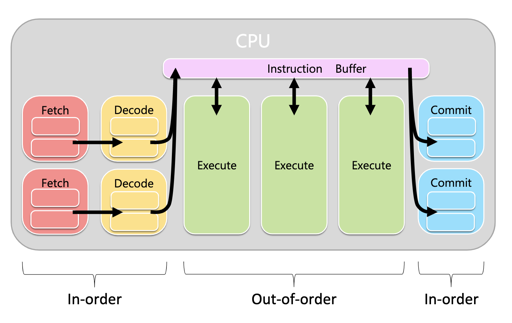
硬件及其假设
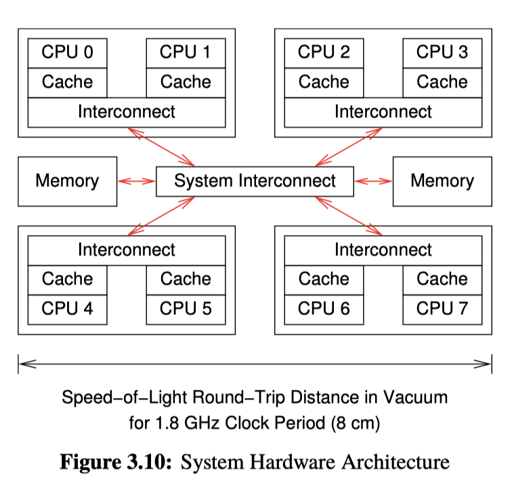
上面是 perfbook 的图,我从 15-418 偷了几张图:
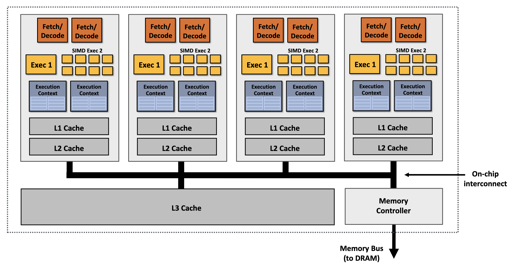
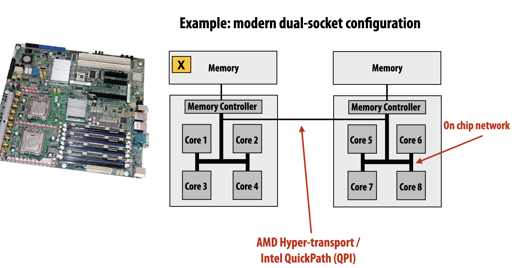
这几张图应该概述了 NUMA、SIMD 之类的。
perfbook 举了个例子,在某个架构中,如果 CPU (CPU0) 想要写一个跨 Socket 的 mem 地址,可能会:
- check local cache(L1, L2)
- 走目录协议,给 CPU0 或者别的 CPU 发送指令,然后让这个 Cacheline 搞到自己上头
- cacheline 到自己上,真正可写
- 具体写
下面一张图介绍了各种操作的开销:
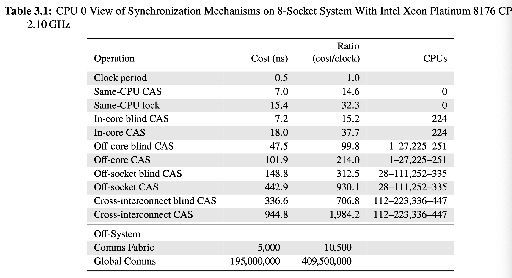
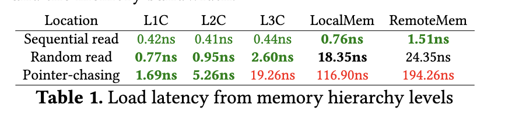
- 同一个 CPU 的 CAS 可以几 ns 内完成,流程基本上相当于在 cacheline 做标记。这里 cas 是 x86 的
lock;cmpxchg - In-core 表示在同一个核心上,共享同一个 cache hierarchy;blind cas 表示「不读旧值,直接 CAS」,而 CAS 是「读旧值 + CAS」。后者可能访存两次
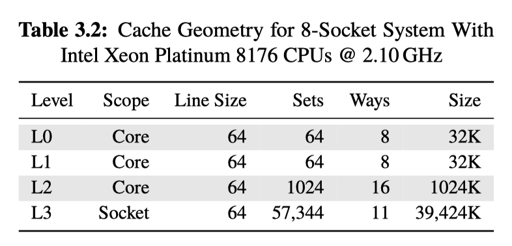
这里还有些 dark side 优化:
- large cacheline
- cache prefetching
- store buffer
- speculative execution
- large caches
- read-mostly replication(想下 MESI)
上面这些策略其实软件也是很常用的。
Tools
本节内容比较难,但我不太打算写。这里用的工具不太是 user-level 的 C++11 atomic 之类的,本节介绍了 Linux 常用的 WRITE_ONCE READ_ONCE,和 volatile 的语义。然后介绍了一下各种并发。
在这之前,chap4 介绍了一些不用上面方式的工具,比如 bash 脚本这一著名、经典的并发程序。详细内容我觉得可以参考 6.null。
POSIX 提供了 fork wait 等进程接口,但这些接口的使用通常和 shm、signal 结合。在 nptl 没实现的时候,PostgreSQL 这些只能依赖这套东西做。
下面介绍了一下 POSIX mutex、GNU 的 atomic 和__sync_。然后着重介绍了 volatile 的语义。我觉得别的地方介绍都没这里好。但是我感觉这段不如直接 atomic,所以感兴趣的自己回头看吧。
这里基本还可以参考一些 futex are trickey 什么的,看看对应接口的实现。webkit 实现了一套并发库:https://webkit.org/blog/6161/locking-in-webkit/ ,可以作为参考(不完全是 futex,相当于在用户态包装了一层 futex)
或者也可以看我 rsy 爹的 blog: https://github.com/rsy56640/triviality/tree/master/content/%E8%B0%88%E8%B0%88%E5%B9%B6%E5%8F%91