perfbook notes: parallel, mutex, fastpath
在介绍完硬件后,perfbook 用 scalable-counter 为例子,介绍了并发数据结构的设计。这里面有一些大概的要点:
- Partition
- 根据 Core 或者线程来 Partition。比如 counter、allocator。
malloc()和inc()可能不指定具体的 key,因此这个资源可以池化,绑定在 CPU、Thread 之类的对象上 - 根据 key 来 partition。
get(key)本身可以做一些 Partition,来保证粒度
- 根据 Core 或者线程来 Partition。比如 counter、allocator。
- Fastpath、Slowpath 和开销
- 理想情况下,所有操作开销都很低,但是不可能,所以要有个 trade-off
- 「开销」可以根据操作的粒度来权衡,不能说「锁操作很重」「atomic 很轻」就行,而要对比临界区、执行 Path 的内容和执行时间,来考量这个开销是不是过大。
- 可以区分 Fastpath 和 Slowpath,很少情况执行
- Batching
- 将操作批量处理
这里先用 counting 做了一个入门介绍,然后引入了 Paritition/Synchronize Design,最后介绍了一些 Locking 和 Locking 相关的设计。
Counting
Scalable Counting 是一个比较开放的问题,这里列举了下面的需求:
- Statistics
- Approximate limit / Exact limit
- Ref-count
最朴素的思路当然是 std::atomic<uint64_t> 一把梭。但是它不是 scalable 的,回顾一下我们上一节描述的,可能它要保证操作的时候,数据由你的 Cacheline 保护:
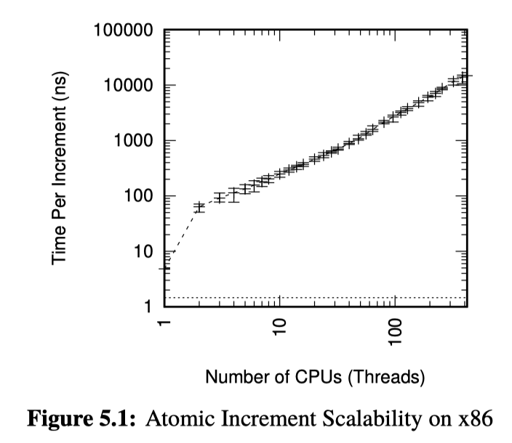
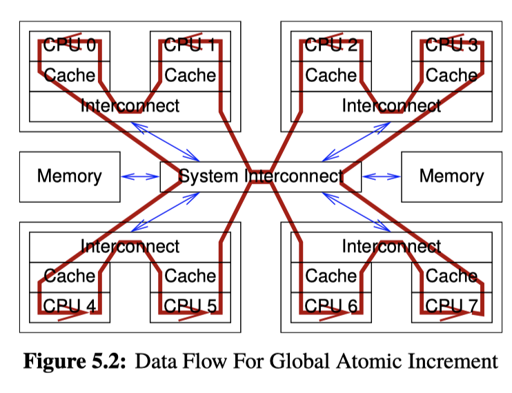
这里就有个严肃的同步问题。而且可能是跨 socket 的。当然可以保证这里的统计信息是准的。这里下面有几种 counter :
- statistical counter: 统计,计算总和,很可能不准,但非常高效
- Approximate Limit Counters: 少许超过 limit 限制也可以
- Exact Limit Counters: 不允许超过限制
这里程序用了 Per-CPU,这个在内核其实不难做,在用户态的话,可以参考 TCMalloc 用的 rseq(2):
- https://www.efficios.com/blog/2019/02/08/linux-restartable-sequences/
- https://google.github.io/tcmalloc/rseq.html
相对于 Per-CPU,一些地方会使用 Per-Thread 的程序。perfbook 介绍了为什么没有提供 Per-Thread 设施:
A key limitation that the Linux kernel imposes is a compile-time maximum bound on the number of CPUs, namely,
CONFIG_NR_CPUS, along with a typically tighter boot-time bound ofnr_cpu_ids. In contrast, in user space, there is not necessarily a hard-coded upper limit on the number of threads.
一般的用户程序可能会用 Doubly List 来挂一些统计信息。
statistical counter
一种方式是,用 Per-CPU 或者固定大小的 Array,然后每个线程/CPU 用 WRITE_ONCE 写本地 counter,读的时候读起来所有的 counter。这个地方统计不一定完全准确,因为统计的时候可能 counter 还会增加。这种方法几乎是 Linear scalable 的,但是受限于 固定大小。
Counter 可能可以根据 TLS 来实现。inc 对应的操作应用在 TLS 上,线程销毁的时候,会获取 lock, 然后把操作挂靠在 global_count 上。读取的时候,需要读取 每个线程的 count + global_count。这里具体代码如下:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/count/count_tstat.c
这里有一个小瓶颈在于,读取 global_count 可能需要锁。线程销毁也需要锁,这个是准确的,但是不 scalable。这里可以考虑 Eventual consistency,达到最终一致性即可:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/count/count_stat_eventual.c
这里引入了一个额外的线程来处理数据,读的时候只需要读取 global_count,写也只要直接写,额外的线程会定期把值合并到 global_count.
这些实现能够牺牲准确性,但是提供近线形的可扩展性。
Approximate Limit Counters
Suppose further that these structures are short-lived, that this limit is rarely exceeded, and that this limit is approximate in that it is OK to exceed it sometimes by some bounded amount.
这里会有频繁的 inc(size) 和 dec(size) 操作,希望不要越界过于离谱。
一个简单的想法是,比如计数是 10000,有 100 个线程,就每个 100 个。但是这对任何有 skew 的 workload 都太垃圾了。这里有一个方法,是上面一个方法的修改版:
- 正常分配的时候,每个线程会有一部分剩余的
counter分配器,它有countermax和counter。正常情况(fast path) 会++counter,然后保证counter < countermax - (Slow path): 如果
counter == countermax,那么这里会把counter中的一半移动给globalcount,再回到 (1). 这里还涉及到一个限制,我们会有globalcountmax, 如果globalcount超过了 max,那么计数器就溢出了。 - (slow path): 如果
counter == 0, 且还需要减少,类似 (2),从globalcount来 Steal.
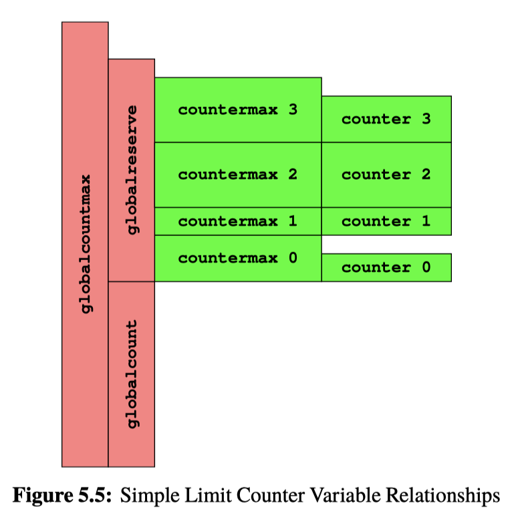
具体代码:https://github.com/paulmckrcu/perfbook/blob/master/CodeSamples/count/count_lim_app.c
这里在 add, sub 的时候可能会有超限制的情况。导致无法推进。为什么呢?这里可能会有能分配,但是实际上分配不出的情况:
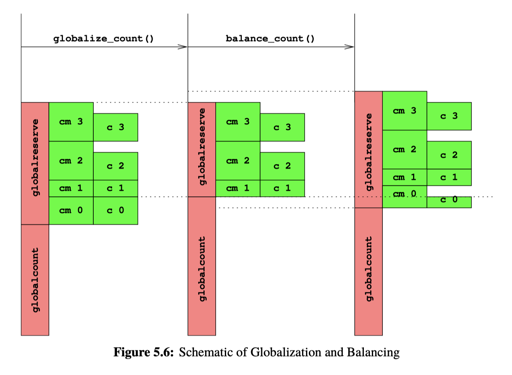
这里,0 需要增加,但是可能别的 countermax 还有剩余,但是它申请不出来了。
Exact Limit Counters
如果要能准确分配,这必定涉及 slowpath 下向别的 counter 索要内容。这个就涉及跨线程交互了,这里提供了两种方案。方案1是全部走原子指令:
这个的 read_count 不一定完全准,但是上线和下界都是准确的,缺点是所有写操作基本都是个 CAS。
这里还用信号和状态机做了个比较复杂的系统,大概思路是:
- 本线程的添加是
WRITE_ONCE原子即可(类比于relaxed) - Slowpath 需要走
pthread_kill,别的线程收到信号后,会自己提交信息 - 因为信号是可重入的,所以需要写一个很复杂的状态机,如下图:
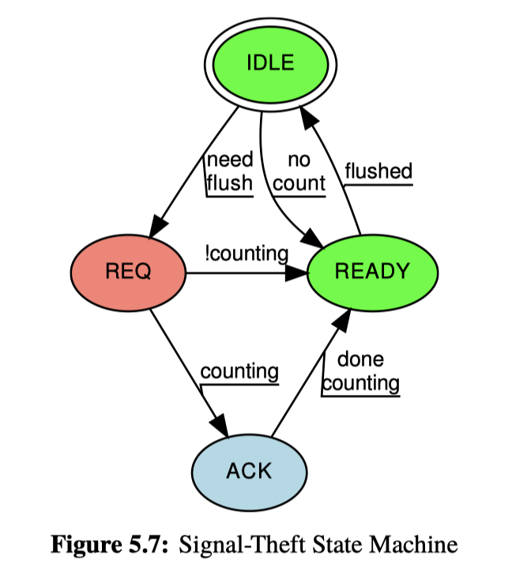
讨论
- Partitioning promotes performance and scalability.
- Partial partitioning, that is, partitioning applied only to common code paths, works almost as well.
- Batch Updates
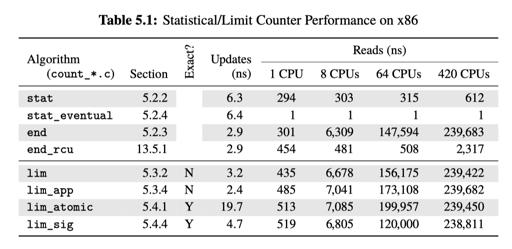
- Read-only code paths should remain read-only: Spurious synchronization writes to shared memory kill performance and scalability, as seen in the count_end.c row of Table 5.1. (记得我们的 eventual 吗?)
- Parallel performance and scalability is usually a balancing act: Beyond a certain point, optimizing some code paths will degrade others.
- Different levels of performance and scalability will affect algorithm and data-structure design, as do a large number of other factors. Figure 5.1 illustrates this point: Atomic increment might be completely acceptable for a two-CPU system, but be completely inadequate for an eight-CPU system.
后面又总结了三点:
(1) partitioning over CPUs or threads, (2) batching so that more work can be done by each expensive synchronization operations, and (3) weakening synchronization operations where feasible.
Partition and Synchronization Design
这里介绍的是 Partition 相关的设计。介绍了哲学家用餐问题和双端队列。这里有几个要考量的点:
- performance
- scalability
- response time
对于哲学家进餐问题,很多地方会考虑 Dijkstra 的编号算法。这里有一个问题是这个算法可能有活锁,可能真的没人在推进。一种可靠的方式是固定谁拿什么叉子,直接 scalable 了。
另一个问题是双端队列。对于 Compound Double-Ended Queue,这里类似 Btree 的 iterator,会规定一个获取锁的方向:
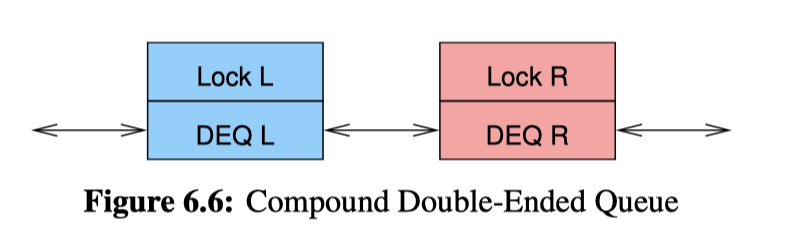
获取锁的方向都是 左->右,如果右向左前进,需要先释放自己的锁,拿到左边,再 grab 回来(感觉这还涉及 data-ownership 的问题,哎…)。
关于这种队列,还有一个最先插入一些元素的问题,也就是队列是空的、只有一个元素的时候应该怎么操作。参考:https://github.com/paulmckrcu/perfbook/blob/46ff2e75ea1b645dabc7405884ddf666f94b4b07/CodeSamples/SMPdesign/locktdeq.c
这里做的还是比较 hack 的。有一个讨论是关于这个 queue 的语义(如果你写 Rust,其实会见到什么 mpmc 之类的,或者一些 Linearizable 之类的):
In fact, as noted by Dice et al. [DLM + 10], an unsynchronized single-threaded double-ended queue significantly outperforms any of the parallel implementations they studied.
Furthermore, these strict FIFO queues are strictly FIFO only with respect to linearization points [HW90] that are not visible to the caller, in fact, in these examples, the linearization points are buried in the lock-based critical sections.
All that said, if you are pushing all the data used by your concurrent program through a single queue, you really need to rethink your overall design.
Design Criteria
这里考虑的是一些并发的设计原则,其实还是比较重要的。包括临界区大小,对什么上锁之类的。以前我确实只会觉得「xx并发好」「xx有瓶颈」,但是没有比较细的思考这些问题。
第一个是什么让你竟然需要并发,可能是:
- Speedup (这里考虑阿姆达尔定律)
- Contention: CPU 数量上来之后,会不会有 Lock/Memory 等资源的竞争
- Work-to-Synchronization Ratio: 并发可能有 message latency, locking primitives, atomic instructions, memory barrier 的开销。如果临界区之类的里面的东西比同步开销操作重,那就可以( for example: https://github.com/apache/incubator-brpc/issues/363)
- Read-to-Write Ratio: A data structure that is rarely updated may often be replicated rather than partitioned
- Complexity: 可能并行的程序会复杂很多,其实一个工业界很贴近的例子就是 Redis,可以考虑一下给 Redis 增加并行之后会有什么问题
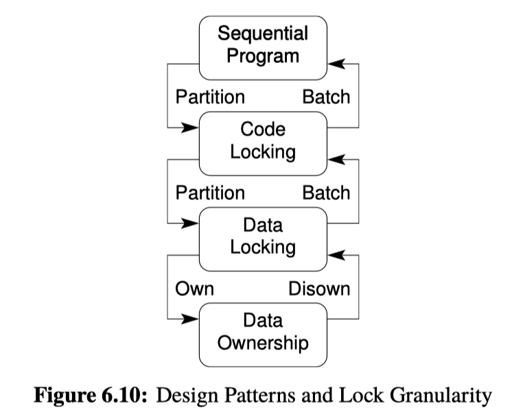
Synchronization Granularity
如果程序全是串行的,那么卵粒度都没有,不过:
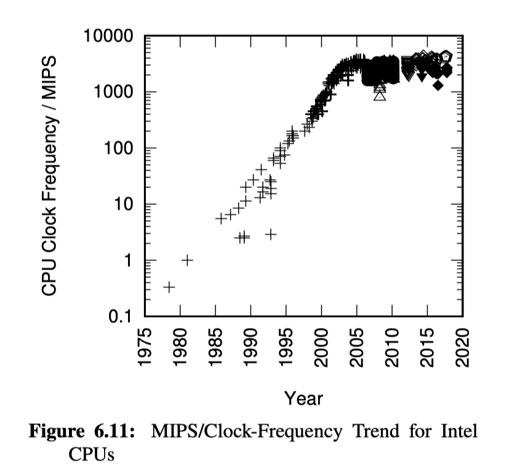
(我觉得很反我作为一个 16 年才学计算机的人的直觉就是,不改代码程序竟然会越跑越快…可能这就是摩尔定律吧)
最常见的方式被这里称为 Code Locking,就是我们最常见的:
1 | void C::func() { |
对整个代码段上锁。
另一种被称为 data locking:
You should use data locking when contention must be reduced, and where synchronization overhead is not limiting speedups.
这里 lock 可能会被绑定在某个 bucket 或者结构上,类似分桶 hashing,或者 Linux 的 dcache,可以当作这里比 code locking 提供了更细的粒度,给某个 key 对应的 bucket 或者更细的粒度提供锁定。
这里还有个 data ownership 的问题,比方说给某个线程/CPU 划分一些数据。这个的问题是,回忆到 counting,这里要处理 skew、hotspot 和一些必要的跨线程通信的问题。
Parallel Fastpath
对于并发来说,设计细粒度的并发策略实际上是很难的。一个粗粒度的并发结构会让人想到「一把大锁」,而细粒度的结构则可能从各种 corner case、原语甚至到一些内存回收策略。
fastpath 思路其实在之前的 counter 系统中就基本提到了,就是在常规路径下开销很小,只有必要的时候引入一些重的开销。下面提到了一些使用 fastpath 的场景:
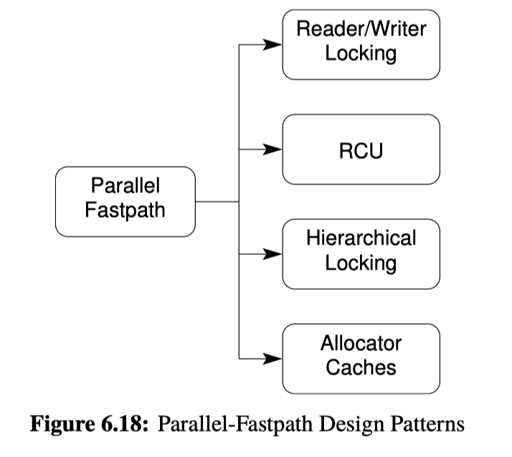
- Read-Write Locking: 当同步开销很小 (例如同步相对于临界区非常小,这点很重要)的时候,可以引入 reader-write locking。当然,这里没有暗示任何实现(RW Lock 可能会有各种各样的实现)
- Hierarchical Locking: 有一个 粗粒度锁 — 细粒度锁的层次。这里引入了多余的锁,但是减小了一定情况下的冲突。当在细粒度锁上操作其实还比较重的时候,这种方式并行化了它的访问。
- Resource Allocator Caches: 这个 pattern 通常是那种不具名的资源,有一些 per-CPU 的资源,和一些全局的资源。具体可以参考
TCMalloc、JeMalloc、MiMalloc甚至PtMalloc.
我就不一一举例了,这里还有个 pool:
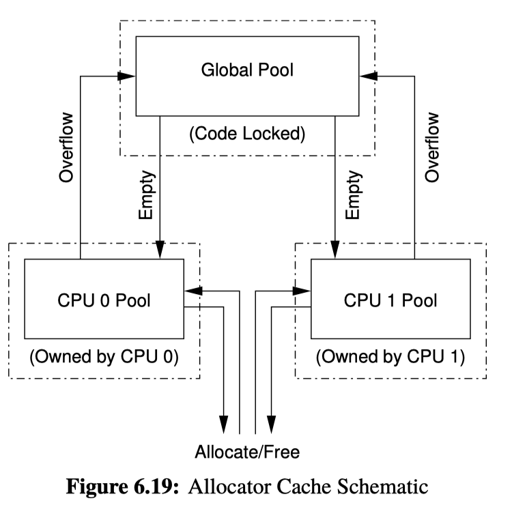
当然,现实中的池子可能会有各种的 size-class,能够把内存返回给系统(munmap 或者 sbrk 缩小),这里也举了一些实际上并发的例子,他们通常是混合的:
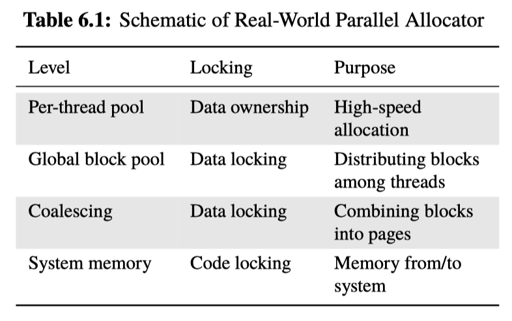
Locking
Locking 是最通用的并发同步手段,尽管可能会有下面的问题:
Locking stands accused of inciting deadlocks, convoying, starvation, unfairness, data races, and all manner of other concurrency sins.
这里有一些 pattern:
- 使用 lock hierarchy 来做死锁避免
- 用工具来检测死锁
- 用一些对 locking 的模式很友好的数据结构
- 使用一些上面介绍的 partition 来减少 lock contention
- 和别的工具协调,只在 slowpath 等地方使用 lock 甚至避免 lock
- 好好地 bench lock 是不是真有问题,会不会影响你(有一些测 contention 的工具什么的)
死锁避免和 Lock Hierarchy
死锁和活锁一直是比较让人头疼的问题,尤其是,如果你跑在一个 stackless coroutine 上,那你 debug 都会要靠一些 user-space 的 locking,把人整吐。
Locking Hierarchies 描述的是锁的层级、获取锁的顺序。比如先拿大锁 -> 拿细锁 -> 放大锁,如果细锁要 grab 大锁估计要涉及一些协议,比如先把自己放了,然后获取下来再查查自己有没有被改。
这里作者引入了一些问题(在 7.1.1),即,library function 和 lock 应该怎么适配,比如你编写了一个并行算法代码,然后把它们中的内容丢到了库里,然后库没有按照你的 hierachy 锁,而是 xjb 乱锁,这就造成了死锁问题(不过笔者认为,现实场景应该很少会这样把带锁内容丢进库?作者也认为应该在这种函数之前释放锁)。作者为了讨论这个引入了 Local Locking Hierarchies 和 Layered Locking Hierarchies:
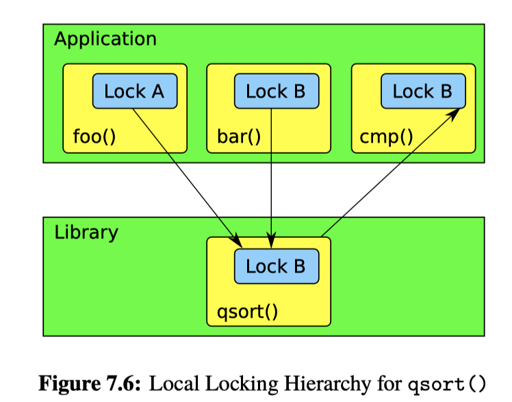
对于 Local Locking Hierarchy, 要获得下一个锁之前,都释放掉未知的锁,那么我们就不会有这种问题了。当然,这表示最多持有 1把锁,可能和层次目标比起来怪怪的。
Layered Locking Hierarchy 在库这里也引入了获取锁的层次,来达成目标:
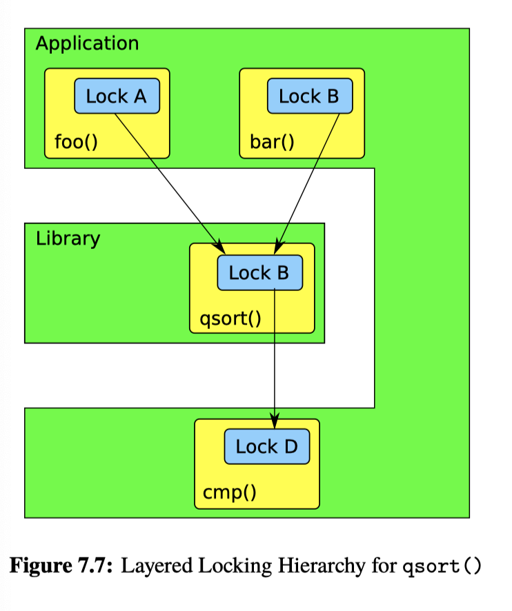
以上描述的都是在层次逻辑上「可以避免死锁」的方案,就是程序本来不应该有冲突,可以让他们没有。但是有的时候,程序就正经就该有冲突,比如:
- 并发 BTree 有一个左向右的迭代器,有一个右向左的迭代器
- 不同层次的系统(比如网络协议栈)里面有一个下降的,有一个上升的
这里可以引入 conditional locking,来让某个方向的 locking 做试探性的上锁,正如:
One way to avoid deadlocks in this case is to impose a locking hierarchy, but when it is necessary to acquire a lock out of order, acquire it conditionally
相对于上面的锁定方案,还有一种粗暴但有效的方案:Acquire Needed Locks First。这就在处理前都悲观的都嗯锁上,类似 2PL,或者 TiDB 的悲观锁模型。这种方式可能会带来活锁的问题,这些系统需要很强的能力来处理 Transaction abort,能够 abort/回滚掉事务。
最后一种方案比较 hacking,就是类似 local locking hierarchy,一个时间同一个地方只持有一把锁。感觉这个需要把并发设计的非常细心。
最后,这里讨论了一下 lock/unlock 和 signal 配合的语义,这可能会让系统变得非常复杂(信号可重入感觉是个非常蛋疼的问题)。
此外,还有 livelock 相关的问题,也会导致 starvation:长时间内米有一个 worker 在正常工作。这可能可以引入一个发现这些问题的 contention manger,然后引入一些 backoff 策略,比如指数退避。有一种大力出奇迹的方案,就是设置一个退避次数,乐观这样重试,不行就上个全局锁,悲观执行。
还有一些奇怪的 unfairness 问题,比如某个 core 或者什么会不会比别的 core 更容易拿到锁;同时,锁也会有比较重的 cache miss,我们可以看看之前的 Hardware 那节的情况。最简单的 spinlock 都每次会走一个 acq 的 CAS,这个也看同步和执行之间的开销对比来决定了。
Types of Locks
锁定通常通过 atomic (用户态不推荐 spinlock )、futex 加上一些用户态的 flag 实现。这里可能不会直接用 pthread 的工具,比如数据库的 Page。
用户态实现一般基于 futex,有的地方会引入一些花活,比如 MCS Lock ,或者 WTF::ParkingLot 这种并发设施。但不管基于什么,这里有一些共性的问题需要讨论。包括锁的互斥、读写和它们的语义。
Exclusive Lock
经典的锁,这里语义可能有:
- Strict FIFO
- Approximate FIFO
- FIFO within priority level
- Random
- Unfair
不同的锁可以有不同的策略,越上面的,保证越强、代价越高。
Reader-Writer Lock
我们经常被介绍说读写锁会引入巨大开销,这是因为读写锁实现的时候可能要引入额外的逻辑甚至额外的锁,这些信息甚至锁的维护开销是比较大的。
The classic reader-writer lock implementation involves a set of counters and flags that are manipulated atomically. This type of implementation suffers from the same problem as does exclusive locking for short critical sections: The overhead of acquiring and releasing the lock is about two orders of magnitude greater than the overhead of a simple instruction.
Of course, if the critical section is long enough, the overhead of acquiring and releasing the lock becomes negligible. However, because only one thread at a time can be manipulating the lock, the required critical-section size increases with the number of CPUs.
The canonical use case for readerwriter locking involves very long read-side critical sections, preferably measured in hundreds of microseconds or even milliseconds.
Brpc 也是因为这个原因,不太在库里写 bthread 的 rwlock。
Rw lock 可能有不同的语义和不同的实现,然后通用实现几乎都不那么令人满意,所以需要根据自己的需求来定制:
- 读者优先的实现,可能会永久饿死某个 writer
- Batch-fair 的实现,读者和写者都会互相 Batch 的来访问
- 写者优先的实现
更细的锁语义
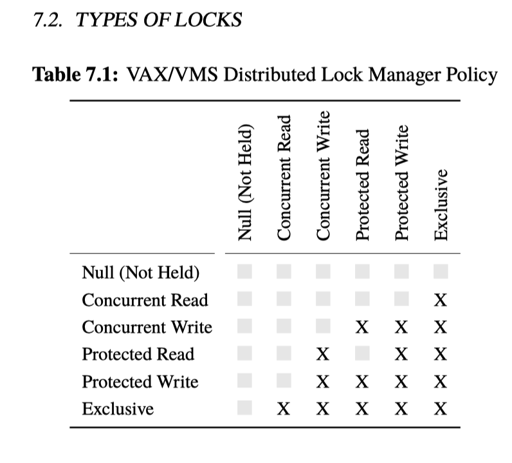
作者这里举例了 VAX/VMS DLM。笔者作为 DB RD,觉得这里其实可以参考 Btree 各种 Latch 协议,比如 SX Latch 什么的。笔者认为,这里关键点是:
- 知道什么可以和什么并发,画出并发的图
- 弄清楚这样开销是否合适,类似 RW-Latch 那个问题,它的开销比通常的互斥锁高了几倍。这是值得的吗?
锁的实现
这部分可以看看我爹 rsygg(征婚中)写的: https://github.com/rsy56640/triviality/tree/master/content/%E8%B0%88%E8%B0%88%E5%B9%B6%E5%8F%91#mutex 或者 futex is trickey
不过这部分其实更多介绍的是用户层次的锁实现,偏向策略而非机制。
Atomic + CAS 自然可以实现锁,在 low contention 的时候甚至可以工作的很好、也有很小的 meory footprint,但是在高占用的情况下可能就炸了。
ticket lock 实现了 strict FIFO 的语义,它的活跃度可能值得商榷。而解锁中,为了不一次通知所有的等待者,则需要引入一些 queue (想象 futex 的语义),这样它只需要通知该唤醒的线程。不过这些策略会导致在 low-contention 的情况下,增大锁相关的开销。
此外,这里还有优先级反转的问题,占锁的线程如果是个低优先级的线程的话,这里就会有奇怪的问题,比如它被调度走整个系统就没人工作了。这里有两种方案:占锁了就不能被调度走;使用优先级反转。
这里作者还提到了不用原子指令实现 lock 的方案,我只能说真的牛逼。
最后:
The Linux kernel now uses queued spinlocks [Cor14b], but because of the complexity of implementations that provide good performance across the range of contention levels, the path has not always been smooth [Mar18, Dea18].
Nevertheless, you should carefully consider this important safety tip: Use the standard synchronization primitives whenever humanly possible. The big advantage of the standard synchronization primitives over roll-your-own efforts is that the standard primitives are typically much less bug-prone.8
Lock-Based Existence Guarantees
Existence 比较奇怪,不过这里讨论的内容挺正经的:
- Global/Static local variable 的 existance
- Global/Static local variable 的加载
- Heap 上变量的存在性,比方说给数据库
LockManager的一个请求,会被放到队列里,等待通知。这个被通知完之后,可能被回收
这里可以:
- 把 Lock 或者一个标志和对象抽开,然后用这个对象来识别