SDS Intro & RISC-V Datapath(4): Pipeline
CPU 的水太深了…我只能保证介绍比较基础的 case, 难免讲出问题,希望假以时日我能回头轻松啃下这几块吧=,=
上一节我们介绍了流水线的基本概念。相对于 Single-Cycle 的处理,并假设我们有最简单的5个 stage:
- IF: 取指
- ID: 译码
- EX: 执行
- MA: 访存
- WB: 写回
在 15-418 里面,分为下面的:
- Fetch – get the next instruction from memory
- Decode – figure out what to do & read inputs
- Execute – perform the necessary operations
- Commit – write the results back to registers / memory
当然需要说明的是,这是教学的一个非常简化的版本,真实 pipeline stage 会比这个多不少。
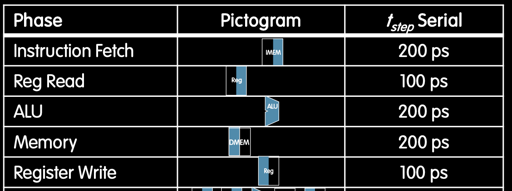
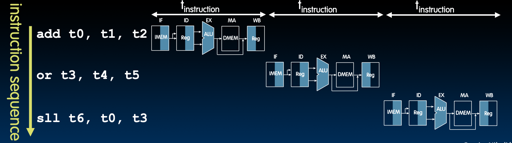
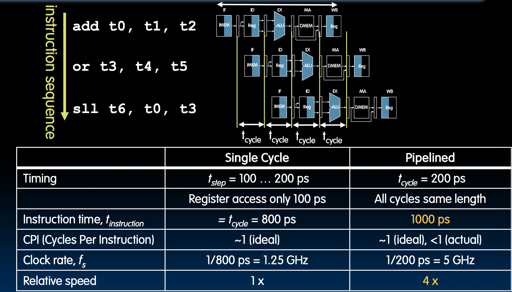
Pipeline 的基本思路是,“因为每个指令的每个阶段,用到的结构可能都是不一样的,所以我们和流水线加工一样,每个阶段都在处理不同的指令”。但是这个实现起来相对 Single-Cycle 就有各种各样的新问题了。
Idea1: 准备必要的 Pipeline registers,把每个 stage 需要的 control logic 和上一阶段的数据拆分出来,让下个阶段能够正确的运行
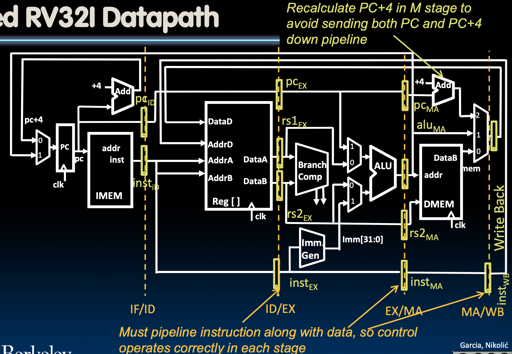
这里有:
- 存储下一阶段需要的 inst 的 寄存器
- 存储下一阶段需要的数据来源,如 rs 等寄存器
- PC Register
- …
而control logic 也是类似“多阶段的”,来完成这个控制。
Pipeline Hazards
A hazard is a situation that prevents starting the next instruction in the next clock cycle
咋一看流水线这么运行就完了,但是细想还是会有很多问题,这里划分了3种:
- Structural hazard :Datapath 组件的冲突,可能会有同时对memory 的读/写
- Data hazard:寄存器等冲突,比如在不同 stage 的数据同时读写一个 reg
- Control hazard
这让我们不能简单的单个指令执行。
Structutal hazard
- Solution 1: 需要冲突的指令需要 stall
- Solution 2: 增加硬件(下面我们会看到这是怎么实现的)
- 永远能靠增加硬件来解决这个问题
具体而言,在 decode stage, 可以读到两个 operand reg; 在writeback 阶段,可以写回一个 reg, 这个时候会产生冲突。这个时候可以分离对寄存器的读写 port,来维持状态。
这里还给出了一个访问 memory 的例子:IF 阶段取指令,MA 阶段访问存储,那么这个就有一个结构冲突了,这个时候解决方式是:
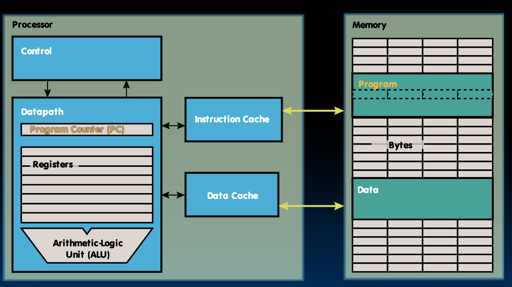
所以总结一下,RISC-V pipeline 出现 structral hazard 主要还是在于 memory
最佳的方式是拆分指令和数据的访问,拆分成 IMEM 和 DMEM。(我只知道有 icache 和 dcache 就是)
Data Hazard
这里是指寄存器上前后指令的冲突,具体如下图:
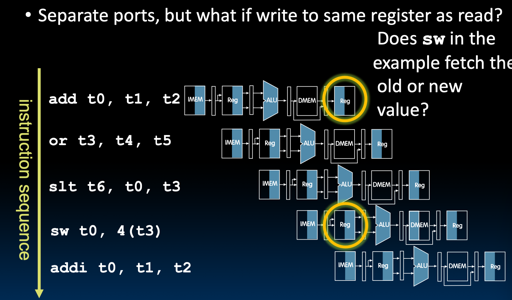
你这会儿会问,咱不是已经分离 Reg 的读写 port 了吗?为啥还会这样呢?分离端口不代表同一 stage 时间数据写/读能够有符合预期的结果:
Might not always be possible to write then read in same cycle, especially in high-frequency designs.
我们希望结果是符合预期的,即和非 pipeline 执行有相同的结果,那么我们就需要维护这个语义了。我们需要保证:
- 前面写入 reg 的值能被之后的指令读 reg 读到
- 对同一个 reg 不依赖同一时间的读/写
解决方式1: Stalling
(好像我们前面就讲了 stalling 但是没配图?)
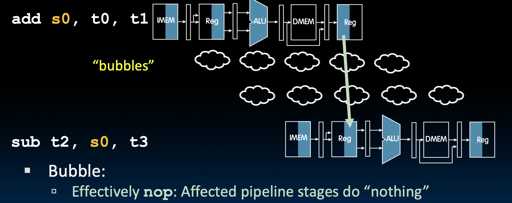
但是 stall 会大大影响效率(这个可以找 perfbook, 里面有数据),不过编译器也可以分析并且插入 add x0, x0, 0 之类的 nop
解决方式2: Forwarding(bypassing)
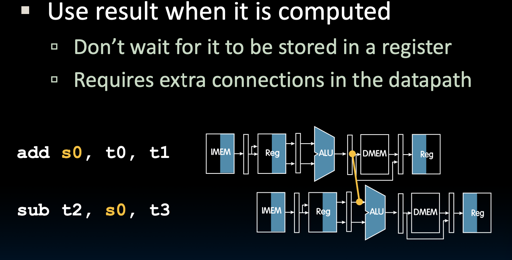
这个是真的牛逼…但是这么一来 path 和 control 感觉会巨复杂..
Compare destination of older instructions in pipeline with sources of new instruction in decode stage.
所以需要一个巨复杂的 forwarding control logic
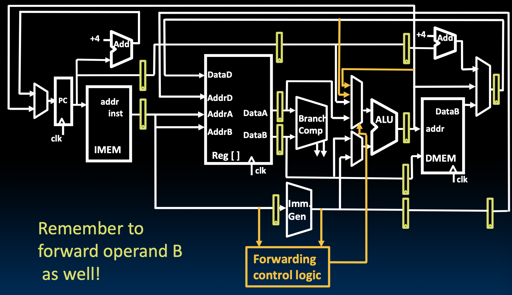
同时,即使这样,我们还是需要必要的 stall:
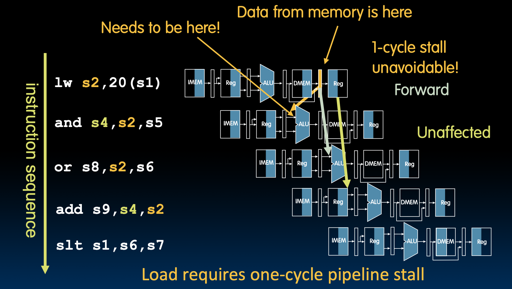
这里第二条指令依赖第一条指令写入寄存器的值,所以这个需要 stall. 当然,编译器/CPU能够完成指令重排,来优化这个过程:

Control Hazard
这个反而是我最熟悉的…
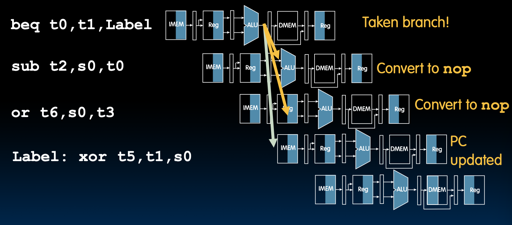
其实可以看看 likely,影响程序的优化儿:https://en.cppreference.com/w/cpp/language/attributes/likely
likely 会静态的影响程序。
- Every taken branch in simple pipeline costs 2 dead cycles
- To improve performance, use “branch prediction” to guess which way branch will go earlier in pipeline
- Only flush pipeline if branch prediction was incorrect
Multiple issue “Superscalar”
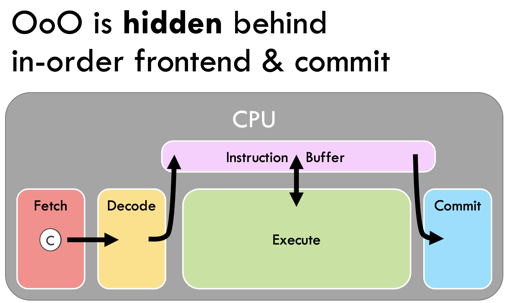
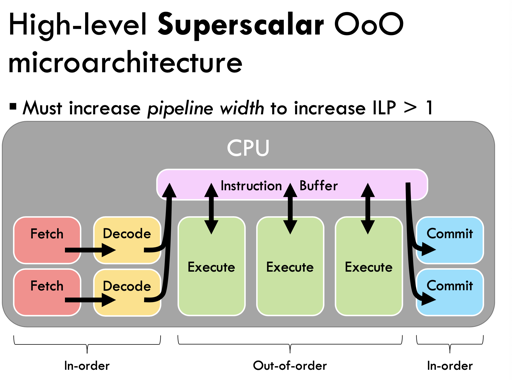
这里需要 Execute 之前完成动态计算,并且去 superscalar 的执行