Expression Execution in Velox Part 2: Expr::eval
上一节我们介绍了 SimpleFunction 执行的链路,表达式除了 Simple Function 之外:
- 还会能让用户直接继承 VectorFunction 写一些自己定义的 Agg 或者别的方式,这里我理解和 Arrow Compute 里面的定义是相似的
- Register 一些 Agg 之类的函数,然后进行各种操作
Velox 官方很多地方还是靠 UDF 的,很诚恳( 指没有在内部搞各种骚操作 )。他们的展开在上一节(https://blog.mwish.me/2024/01/24/Expression-Execution-in-Velox-Part-1-Basics-and-UDF/) 中有所介绍.
本期介绍的是 Velox Expression 的执行,执行具体的 Expr
执行之前的部分
这里要区分 Velox 的 Expr,下图是个很好的例子:

Velox 在执行前拿到的很大程度上是左侧的表达式,这里可以见:https://blog.mwish.me/2022/11/13/Introduction-to-velox/#Compilation . 简单说这里在执行之前会做一些优化包括:
- CSE 的处理
- 常量折叠
- Flatten ANDs and ORs …
最终这里会生成一个表达式. Compile 签名如下:
1 | std::vector<std::shared_ptr<Expr>> compileExpressions( |
我们这一节不会直接介绍这里的逻辑。这里的生成结果是 ExprSet,它是一组表达式的集合,共享了一些表达式的上下文。在 ExprSet 中有些表达式是会被共享的。
具体而言,这里最后产生的是一个 facebook::velox::exec::Expr。Expr 本身便于执行一些带 VectorFunction (很多又是我们上一节介绍的 Simple Function),而剩下的被处理为 SpecialForm,表示 Velox 自己包装的 if 之类的逻辑。很多错误处理的逻辑也包装在里面。
1 | /// Constant, Cast, Coalesce, Conjunct(And, Or), FieldReference, Switch, Lambda, Try. |
表达式的执行链路
相关的背景
输入: ExecCtx
在上一节介绍过:https://blog.mwish.me/2024/01/24/Expression-Execution-in-Velox-Part-1-Basics-and-UDF/#EvalCtx 。这里的输入是整个表达式的行。
考虑一个情况,比如输入来自 TableScan 之类的,那么这里就很可能是 Lazy 的或者是编码的输入。
输入: Constant / FieldReference
我们不打算太前面介绍一些特殊表达式,但是连 Constant 和 FieldRef 都不知道的话输入就没法介绍下去了。
关于 Constant 和 FieldReference 感觉是大家都有的表达式类型,但是 Constant 比较好玩的一点是,可能是因为复用代码或者内存不好管理,感觉 Velox 中 Scalar 是用 ConstantVector 存储的…
这两个结构如下 ( Vector 一些粗略介绍见 https://blog.mwish.me/2024/01/24/Expression-Execution-in-Velox-Part-1-Basics-and-UDF/ )
1 | class ConstantExpr : public SpecialForm { |
和:
1 | // 以名称的形式来 Bind 在: |
这两者都会尝试计算,然后每次把值输出。这里会尽量尝试直接 reuse Input,然后 reuse 失败才会 EvalCtx::moveOrCopyResult 去输出结果。这里还有一些细节但感觉现在介绍还是过早了,现在把他们当成表达式输入就行,最后在 SpecialForm 介绍。
基础的优化手段和 Compute Metadata
这里可以参考下面几个链接,讲过的东西再讲一遍就不太好了。
- 官方博客:https://facebookincubator.github.io/velox/develop/expression-evaluation.html
- Velox 发表的论文:https://engineering.fb.com/2023/03/09/open-source/velox-open-source-execution-engine/
- 和我之前对论文的 comment: https://blog.mwish.me/2022/11/13/Introduction-to-velox/
这里需要知道的是:
- CSE 识别之类的东西是在 Compiler 的地方发现的,但是会在执行的时候 aware 一些 CSE。具体来说,它会计算某个 child 是否被多次 ref,如果被多次 Ref 的话,可能会尝试缓存计算的结果,并且每次做增量计算(具体而言,对于一个 EvalCtx 和一组输入,一个共享表达式,多次计算的 Selection 可能有重合,也有不重合的地方。每缓存算过的地方,新算没算过的地方即可,这里也是当作计算本身的 cost 比较高?)
- Constant Folding 之类的也是 ExprSet 之类的地方发现处理的,会在 Expr::eval 之前,具体代码也在下面:
编译的时候 ( compileRewrittenExpression ) 这里会调用 Expr::computeMetadata. 之前的论文介绍,关于 Metadata 的部分我们跳过了很多,但是这节竟然要深入细节,就要用罗列 API 的气势讲讲这些。这个函数的开头会计算所有 children 的表达式,如果已经计算完成的话,不会重复计算:
1 | void Expr::computeMetadata() { |
当然,Constant Folding 的逻辑也在 compileRewrittenExpression 中
1 | result->computeMetadata(); |
distinctFields, multiplyReferencedFields, sameAsParentDistinctFields
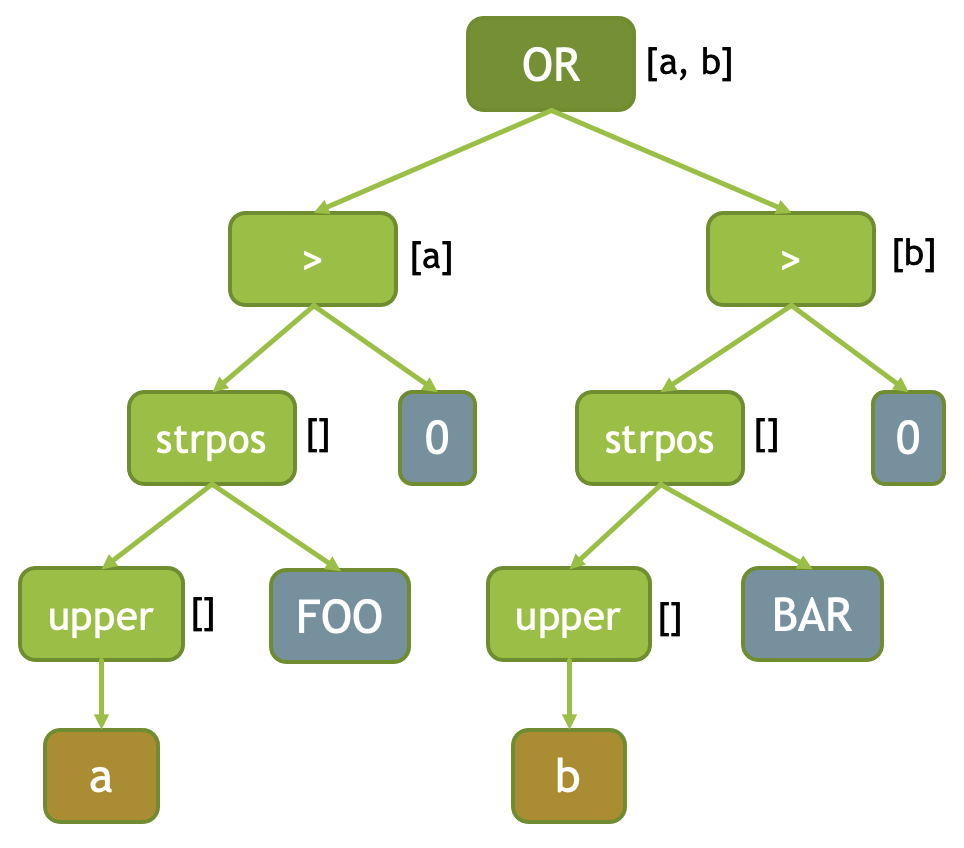
上图是一张非常好的图,介绍了 distinctField 的计算逻辑(但是没有写 MultiReference)。简单的说,这里输入可以调整为各个 FieldReference,然后 Expr 会维护两个变量:distinctFields, multiReferencedFields,具体而言,这里认为所有的对 ExecCtx 中 Row Input 输入的 Ref 都是 FieldReference, 这个时候它会有如下规则:
对于一个表达式,它会 Merge 所有子表达式的 Input 的 FieldReference。FieldReference 表达式本身只会有自己的 distinctField,那么下游的 multiReferencedFields 会直接走到 mutliReferencedFields 中。
- 第一次遇到,并且没有在
mutliReferencedFields,会放到distinctField中 - 多次遇到会放到
multiReferncedFields中
代码如下:
1 | void Expr::mergeFields( |
propagatesNulls
这里我们在 VectorFunction 那讲过类似的,即是否 null-in-null-out。
这里 Velox 的表达式系统拆分了两套接口(见: https://github.com/facebookincubator/velox/pull/5287 ):
1 | bool propagateNulls() const; |
- 对于 VectorFunction 的表达式, 从 VectorFuction 上直接拿到 propagateNull 就可以了. Expr 上也有
bool propagateNulls() const的接口. - 对于 SpecialForm, 额外从
!vectorFunction来计算 propagateNulls.
代码如下:
1 | // (3) Compute propagatesNulls_. |
这里可以看到一个逻辑,即 vectorFunction 已经不是 nullPropagete 的情况下肯定不是 nullPropagete。vectorFunction 是 nullPropagete 的情况下,需要检查所有的输入。这里有个性质比较好玩:
- 抽取所有 nullProgate 的 Input Fields 和所有 !nullPropagate 的 Input Fields
- 如果 !nullPropagate 是 nullPropagate 的子集,那么任何一个 child 的
!nullPropagate列,都会产生一个 null input,然后目标是 null,所以是 nullPropagate 的 - 反之,不是 nullPropagate 的
Determinstic
是否是确定性的表达式。这里逻辑很简单,我就不讲了…
1 | // (1) Compute deterministic_. |
hasConditions
这个任何一个子表达式包含 condition 就会判断,逻辑很弱智:
1 | // Returns true if input expression or any sub-expression is an IF, AND or OR. |
Expr for VectorFunction
我们以下列简单的表达式来表示这里的逻辑:
11 + a(1 + a) * 2 + b
我们也补上官方的一张图,作为一个比较好的参考
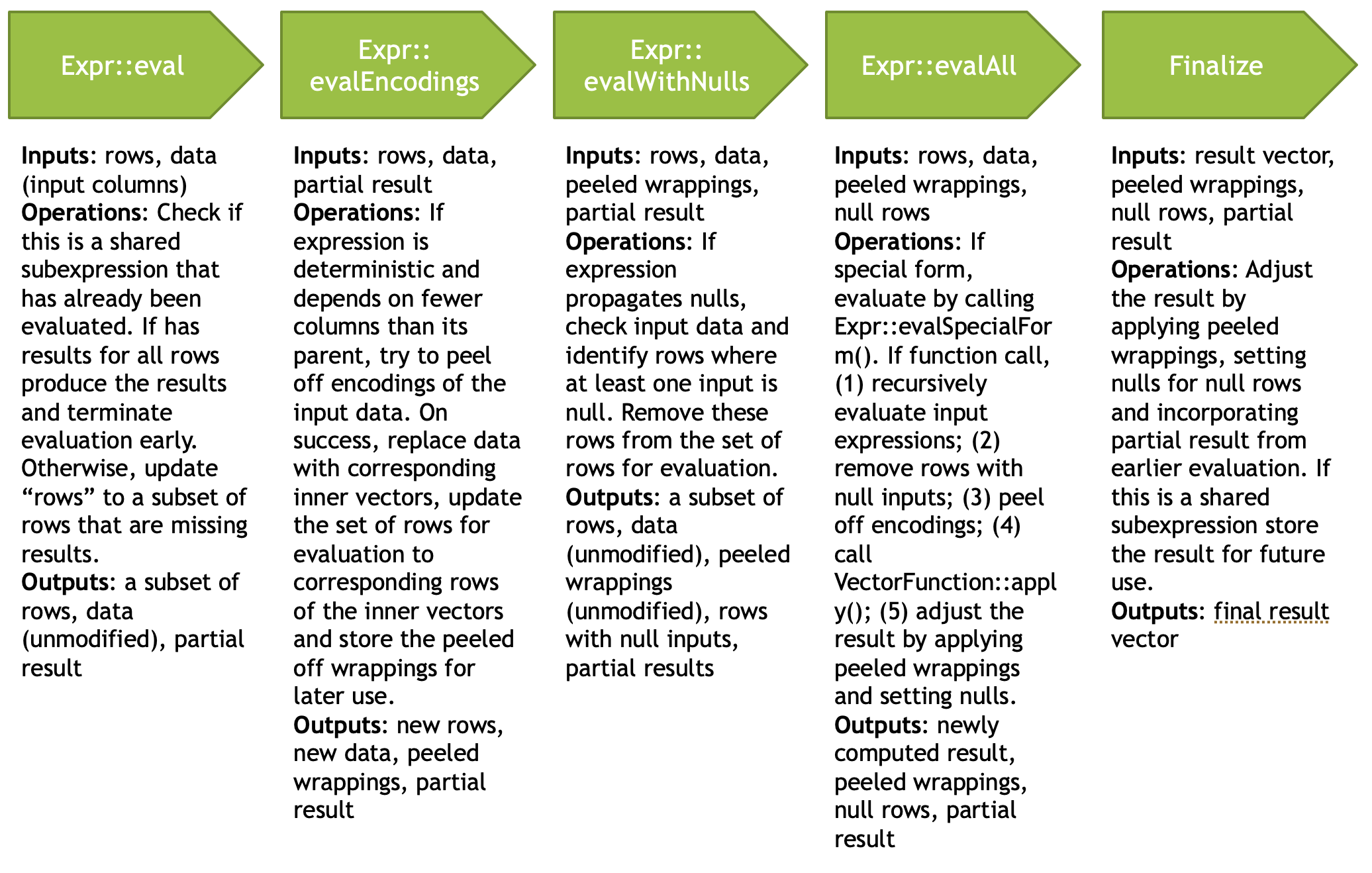
(这张图少了 evalWithMemo: https://facebookincubator.github.io/velox/develop/expression-evaluation.html#memoizing-the-dictionaries )
我们可以在下图画出一个实际的路线图:
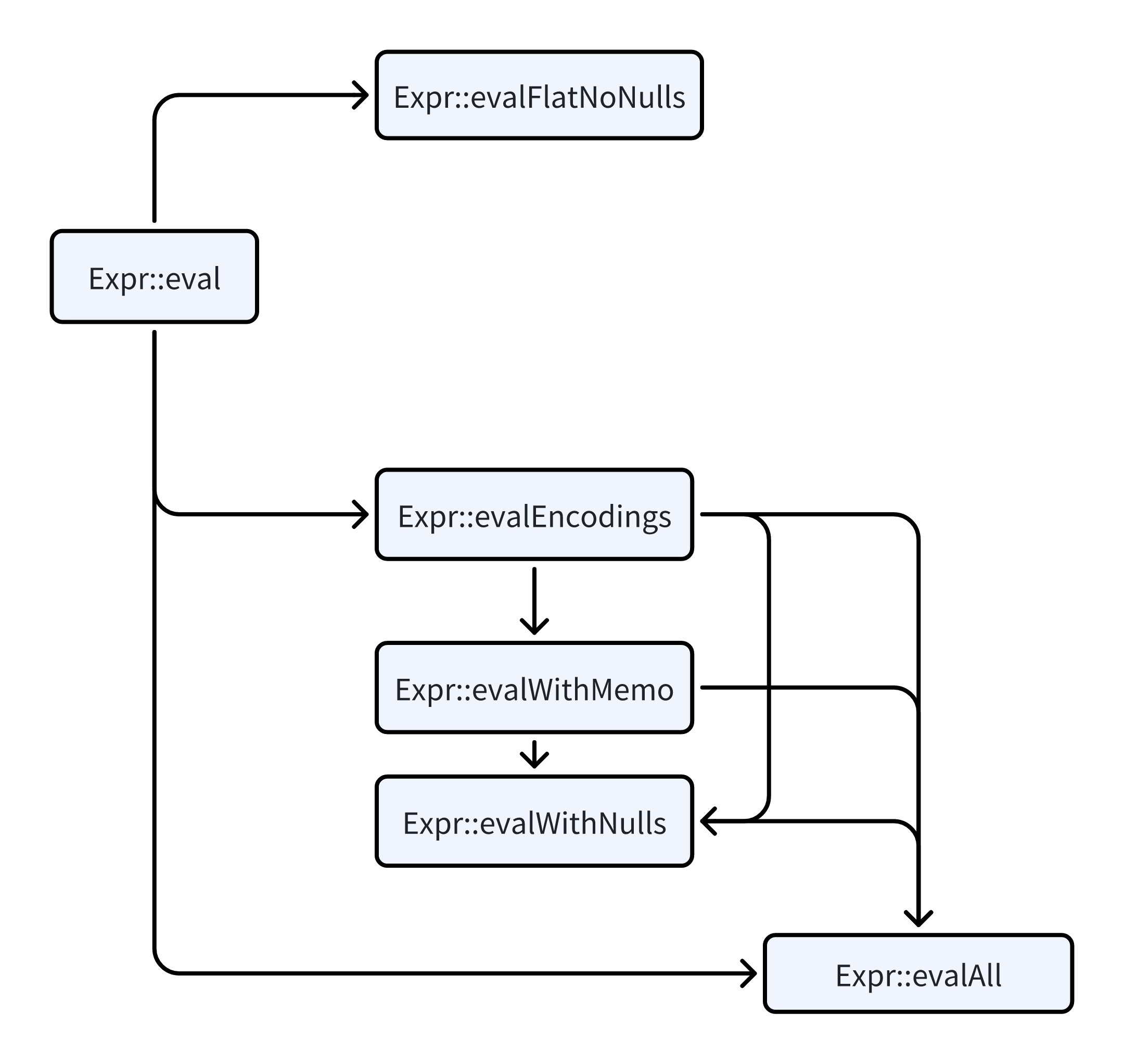
Flat no null fast path
这一段可以见下面的环节,官方文档说的很好。主要是在 ML 之类的场景,处理 encoding 和 Null 本身有一定开销。官方博客这段放在比较后头,但是比较早介绍这个能比较快的 introduce 一个不处理 Null、不处理 encoding 的简单模型,我们可以在这个模型上再扩展出后续的能力,所以我觉得这样讲也不坏。
https://facebookincubator.github.io/velox/develop/expression-evaluation.html#flat-no-nulls-fast-path
这段逻辑的入口在下面:
1 | void Expr::eval( |
我们观测到有一段 shouldEvaluateSharedSubexp 和 evaluateSharedSubexpr ,这些是 MultiRef 的 CSE 表达式求值的逻辑。我们下一节介绍。
我们直接来贴 evalFlatNoNullsImpl 的逻辑,关注几个点:
1 | ExprExceptionContext exprExceptionContext{this, context.row(), parentExprSet}; |
这里是异常处理的上下文。Velox 使用了一个 ThreadLocal 的 ExceptionContext, 在抛出异常的时候,这里会加入 ExceptionContext 里面的字符串。这里内容是加上了这个表达式的 ToString,来在抛异常的时候,能够定位到表达式的上下文。
我们再看下面具体的逻辑:
1 | void Expr::evalFlatNoNullsImpl( |
applyFunction 的逻辑很简单直接,就是调用我们上一节的 Expr。这里注意一下参数的 ConstantInput 处理,因为这里需要把 Constant 的 Size 调整到和 Row 的范围内。
最后有个 releaseInputValues, 这里需要注意的是,这里按照引用计数来释放。
这里介绍有点抽象,我们举例子:(1 + a) * 2, 这里的表达式是:
Expr(input = ConstantExpr(1), input = FieldReference("a"), vectorFunction="add")Expr(input = ConstantExpr(2), input = Expr(1), vectorFunction="mul")
在 Expr2 求值的时候,逻辑如下:
- 假如输入有 500 行,对 Constant,resize 到 500
- 对 Expr1 递归的执行
evalFlatNoNulls, 拿到一个Vector(是FlatVector) 作为输出 - 执行的时候,发现 input reuse, 输出和输入是一个类型,选中
Expr(1)结果存放表达式_ * 2的结果 - 还回去 constant
releaseInputValues,这里因为有 reuse input,所以Expr(1)结果只是减少了 ref-count,没有背释放掉,这个结果被返回。
CSE 计算
shouldEvaluateSharedSubexp 和 evaluateSharedSubexpr 这些和 CSE 的计算有关。后面字典求值一些逻辑也和这块很相似。我个人认为 CSE 是出于一种设计:表达式计算相对比较重,输入容易重复。
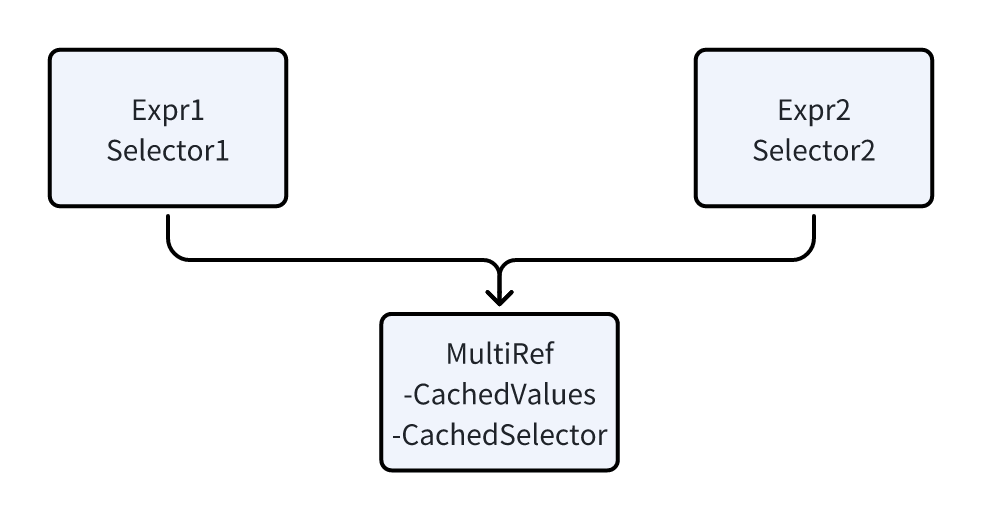
上面是一个 CSE 的典型场景。对于同一个 Row Input, 两个表达式计算的 Selector 可能相同也可能有不重合的地方.
这里逻辑大概如下:
- (显然的)必须要 deterministic 才能执行 CSE 缓存
- 必须是 MultiReferenced 的(也很显然…)
inputs_.empty(),这里逻辑是inputs_只包含子表达式,没有子表达式又是 deterministic,基本上就是 FieldRef Const 这类了,CSE 也没啥意义。
1 | /// Returns true if this is a deterministic shared sub-expressions with at |
在 Expr 中,有 CSE 对应的成员:
1 | struct SharedResults { |
在计算的时候,逻辑如下:
- 如果是 CSE,找到上一次的 CSE 缓存(即上面的
sharedSubexprResults_) - 如果没有找到,就地对
selection进行计算,并且尝试加入 CSE 缓存 - 否则,比较这次的
selection和计算缓存的sharedSubexprRows_,然后加入结果集。
EvalAll: 相对 flat no null 多了什么
Expr::evalAll 定位有点类似 evalFlatNoNulls, 它是这里最泛用的一套东西了。
我们简单看 Expr::eval,它也有设置 Exception 上下文的逻辑,我们不再赘述。我们忽略掉一些 Lazy Eval 的逻辑,直接看下面:
1 | void Expr::eval(...) { |
这里逻辑应该非常好理解,没 input 的话,那就 rows 本身有关的叼毛 Null 没有、Encoding 也没有了(当然,子表达式还是会产生这些逻辑的,我们延迟到 Expr::evalAll 处理。它为什么不先求值呢?我猜也是和 Expr::eval 的中间各种对 NULL 之类的优化有关)。
我们直接贴逻辑:
1 | void Expr::evalAllImpl( |
这里我们观察到多的地方是:
- Null 的处理 (
evalArgsDefaultNulls,evalArgsWithNulls) - Peeling 的处理 (这个我们可以放在下一 Part 介绍)
我们观察一下这里 Null 的处理,非 Default Null 的处理是最简单的:
1 | // 这里不会按照 Null 来增量展开, 但是会按照 Error 来做增量展开. |
这里只要处理错误,然后返回即可( deselectErrors )。
有 Null 的地方逻辑也比较简单,维护一个 MutableRemainingRows 对象,然后每次反选 Null 的地方:
1 | // 以 default null 方式展开子表达式(args), 这里需要按照 Selector 增量展开 input 的表达式. |
你会看到这里有个相对 Hack 的地方是借助了 LocalDecodedVector。我们之前没介绍过 DecodedVector 的逻辑,这玩意在官方链接 https://facebookincubator.github.io/velox/develop/dictionary-encoding.html#decodedvector 提到。Velox 的 Vector 对象可以是多层的,比如:Dict(DICT(DICT(T), 而每层都可能包含一些 Null。DecodedVector 逻辑是拍平成一层,即 DICT(DICT(DICT(Flat))) -> DICT(Flat),然后也获取真正的内层 Nulls。这里通过 DecodedVector 来拿到真正的 nulls,然后反选这些 Nulls。从而避免这些行的表达式执行。
Encoding - Peeling
Peeling 的逻辑在 evalEncoding 内部,应该是这里比较难读懂的一块逻辑,而且实际上在代码里,Peeling 分为了两部分:
evalEncoding里面处理 rows 的 PeelingevalAll里面applyFunctionWithPeeling,处理子表达式输入的 Peeling。
我们先简单介绍一下 Peeling, Peeling 实际上是一种 单个或者多个表达式的 DICT 剥离。举个例子:
1 | /// Few important examples of how vectors are peeled: |
简单的说,Peel 就是把外部的东西抠出来,然后改变 ndv,用内部的 cols 来执行。希望有更小的开销。然后执行完后,结果也可能会 Cache 起来,再包装给外侧的输出。我们举几个例子:
- 某列 ndv 很小,返回的是一个字典,那么只要在字典上执行表达式,不用再值上执行
- Ndv 不小,可以缓存一下,每次做增量 eval
(不过我理解对于超大字典,而且 ndv 很大重复值很少,实际上这块可能是个负优化。)
我们简单看一下 evalEncodings 里的条件:
1 | /// NOTE(mwish): 这里 Peeling 的逻辑其实比较 Hack, 实际上分为两层: |
这里需要:
- Deterministic
- 满足
skipFieldDependentOptimizations,这个地方逻辑比较有意思,比如和父亲输入一样,那么显然父表达式就会做了这个逻辑(呵呵万一你爹不 deterministic 呢 2333) - 输入都不是 Flat。
Peeling 会把行和 Selector 换成内部 Const / 字典,所以显然,它会修改 EvalCtx, 实际逻辑如下:
1 | /// Typical usage pattern for peeling includes: |
换成代码即:
1 | VectorPtr wrappedResult; |
注意这里 ContextSaver 是在 Peel 失败的时候恢复原来的 Row 信息的。
EvalWithNulls
evalWithNulls 逻辑非常简单,当表达式是 propagateNull 的时候,deselect Null input 即可。
Dictionary Memo
我们假设场景是一个 TableScan,Parquet 可能会有 Row-Group 级别的 Dict。这个时候,每次 Scan 产生的 Dict 大概都是同一个。我们之前介绍的 CSE 是缓存一个 row 的输出,但是 Memo 则是跨 Row Vector 缓存输出。这里对输入的要求是,表达式输入必须只能有一个,而且必须是 Dictionary。
Wrapup