Performance Analysis and Tuning on Modern CPUs: Micro Arch
跟着 Performance Analysis and Tuning on Modern CPUs 这本书第二版过了一遍,这本书笔者认真读了 part 1 的 chap1-3 和 part2 全部。前半部分用比较简练的篇幅介绍了一下微架构,写作水平还是非常高的。后半部分讲具体代码优化,作者在 perf-ninja 上有一些例子,但大部分优化其实都比较常见,所以阅读速度也比较快。也看到了一门还可以的课:https://www.inf.ed.ac.uk/teaching/courses/pa 。之前大学学长看完这本书也做过一些分享:https://jsjtxietian.github.io/2024/12/19/cpu_perf_presentation/
本文尽量会分分开,对于性能工程而言,知道原理(微架构等)是重要的。但另一方面很重要的是系统的可观测性,不可观测的原理也是不生效的。现代 CPU 是一个很先进的东西。CPU 是以「控制」为中心的,即使是数据指令,某种哲学的角度上(误)也是「面向控制」的。而它在背后做了很多控制流上的优化,从并行角度来说就是指令级并行。同时,它也有一些特定的数据级并行的策略(虽然众所周知,GPU 非常擅长数据级别的并行,并且在 AI 时代这个优势也在各种场景的使用中被加深了)。
这篇文章本来想写一些自己的东西,不过感觉没做过 uArch,写着写着就成抄书了,就此作罢。下列内容虽然都是抄的,但也有引用来源。
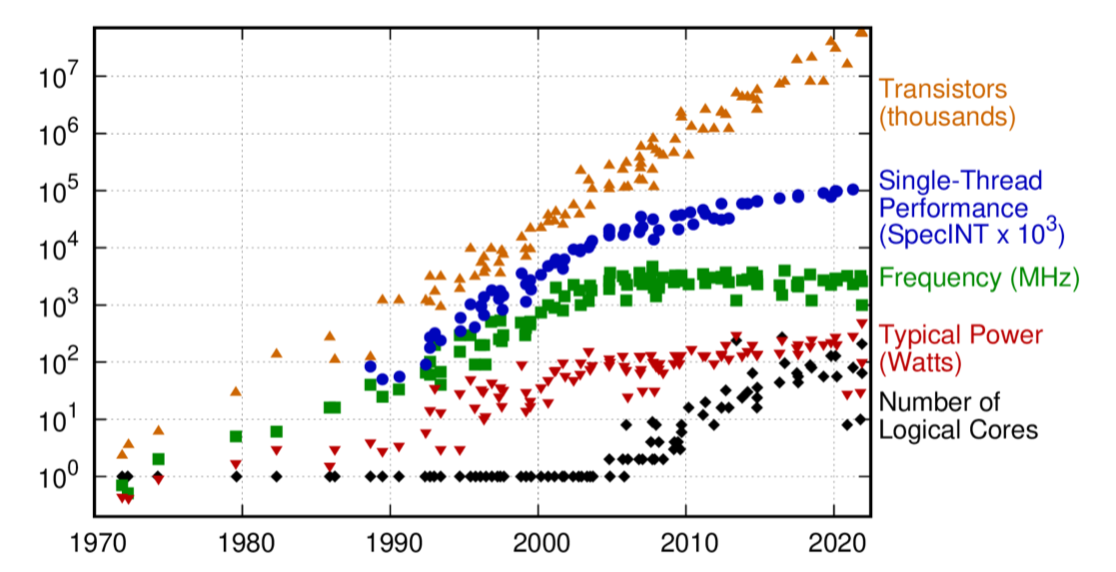
这本书前期内容的核心就是 CPU 的微架构 ( Micro Architecute,后面可能简写成 uArch ),代码下面强调了「优化」的重要性,还是下面这张很熟悉的图:
- 并发的视角来看,因为近十年来单核提升有限,所以要利用多核优势 ( https://blog.mwish.me/2022/05/04/perfbook-notes-hardware/ )
- 从本书的视角来看,因为单核性能不变,但是有 SIMD 之类的新的工具,所以需要优化
- https://blog.mwish.me/2022/11/05/x86-and-SIMD-programming/ 如之前博客和 compiler 优化讨论的,编译器更多时执行一些 as-if 策略,然后去做一些「绝对安全的」优化,有些操作需要用户知道自己的语义来针对性的进行一些优化(比如拆依赖)。编译器也不会改变用户的数据结构、算法复杂度(只要你写的东西不会因为没用到被直接优化掉)。
衡量性能
(本来这节想细一点写的,但是整理了一些材料自己看着有点隔靴子挠痒,就先随便写点)
现代系统中的干扰
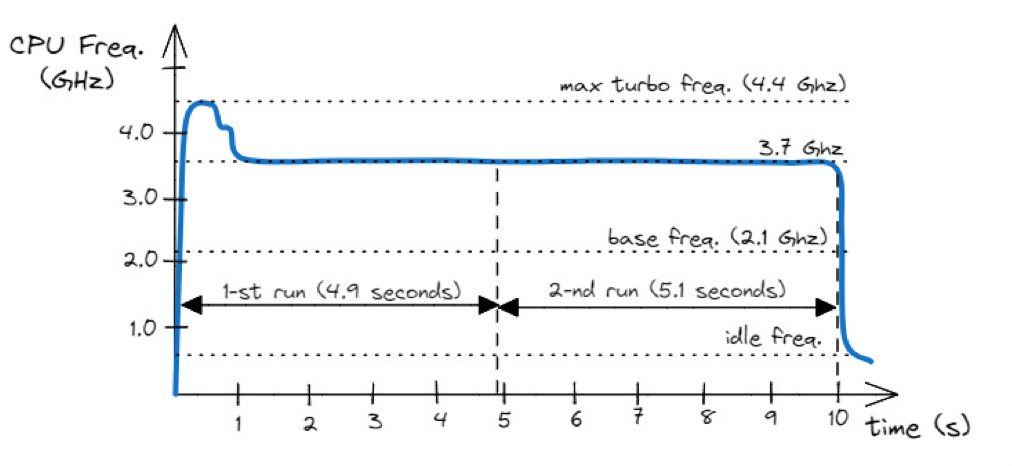
- 动态频率调整(DFS)、Turbo 模式等:https://en.wikipedia.org/wiki/Dynamic_frequency_scaling 。笔记本电脑运行测试的时候,也可能因为过热而降频,比如下图是高频模式运行
- CPU被抢占,尤其在虚拟化或者超线程环境下
所以比较推荐的方式是类似 Arrow Usrabot 一样,持续用各种编译器测试回退。当然我理解公司服务器项目可能偶尔简单一些,因为可能指令集比较固定,或者运行环境能团队自己选择的情况下,这块需要测试的环境可能会少一些。
性能测试和计数器
- 标准: C++ 的
chrono和 Linux 的clock_gettime,约 500 ns - 时间戳计数器: x86 的 tsc 和 arm 的 CNTVCT_EL0,约 5ns
不过 TSC 可能要注意:https://oliveryang.net/2015/09/pitfalls-of-TSC-usage/#32-software-tsc-usage-bugs
CPU uArch
在 ISA 层面:
- 大部分指令集是基于寄存器的 load-store 架构,比如 ARM 和 RISC-V
- X86 ISA 是 register-memory 架构,比如经典的 x86 mov 据说是图灵完备的 ( https://blog.mwish.me/2024/09/01/x86-basics-and-code-analysis-with-ai/ )
- 架构可能有一些增强,比如 RISC-V 的 “V” 指令集、ARM SVE、AVX2、AVX512,和矩阵/张量指令(Intel AMX、ARM SME)
- 现代 CPU 支持 32 位和 64 位精度的浮点和整数算术运算。为了计算和内存带宽,大家也开始支持更多 8 位和 16 位整数和浮点类型(int8、fp8、fp16、bf16)。
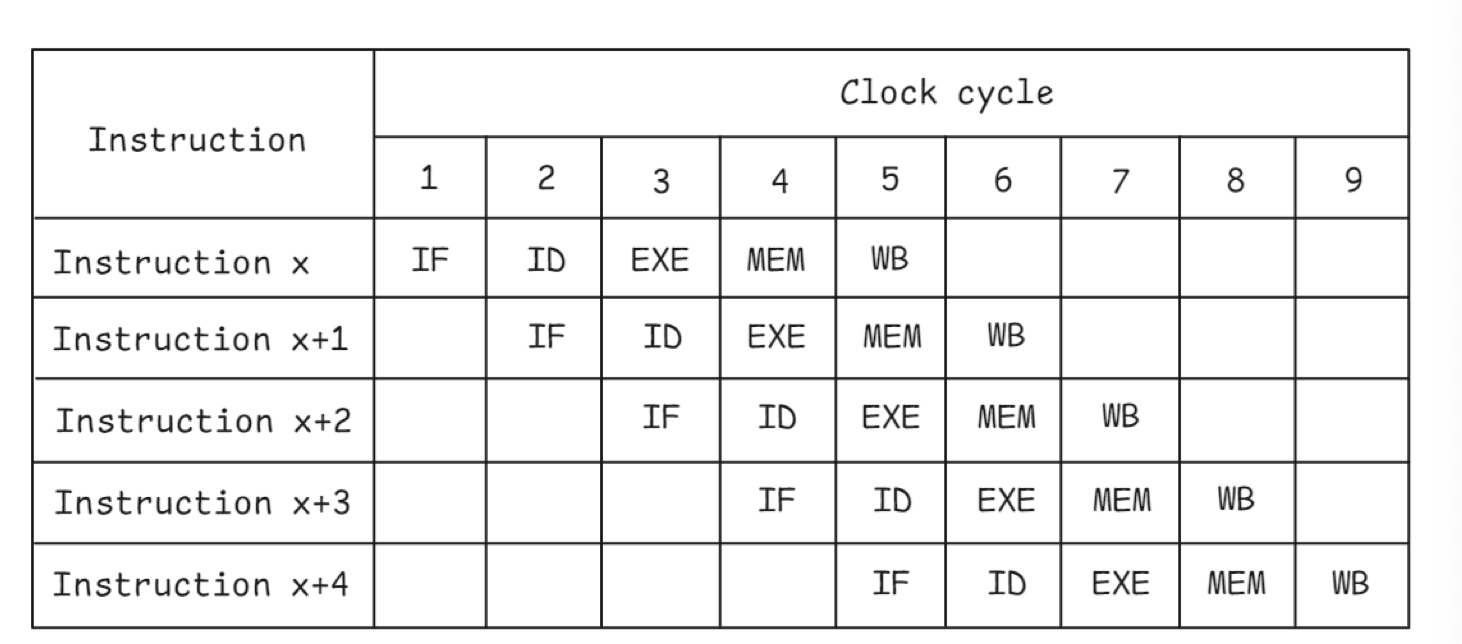
Pipeline & Hazard
Pipeline 层面有一个经典的流水线图,我们也在 cs61c 里面学到过这里面所有的 Hazard : https://blog.mwish.me/2020/10/21/SDS-Intro-RISC-V-Datapath-4-Pipeline/
- Structural Hazard: 多条指令竞争同一个资源,比如多条加法指令在同一周期执行,但只有一个 port。这里可以靠「复制硬件」来消除,但带来了更高的成本和更复杂的芯片结构 ( To a large extent, they could be eliminated by replicating hardware resources, such as using multiple execution units, instruction decoders, multi-ported register files. However, this could potentially become quite expensive in terms of silicon area and power )
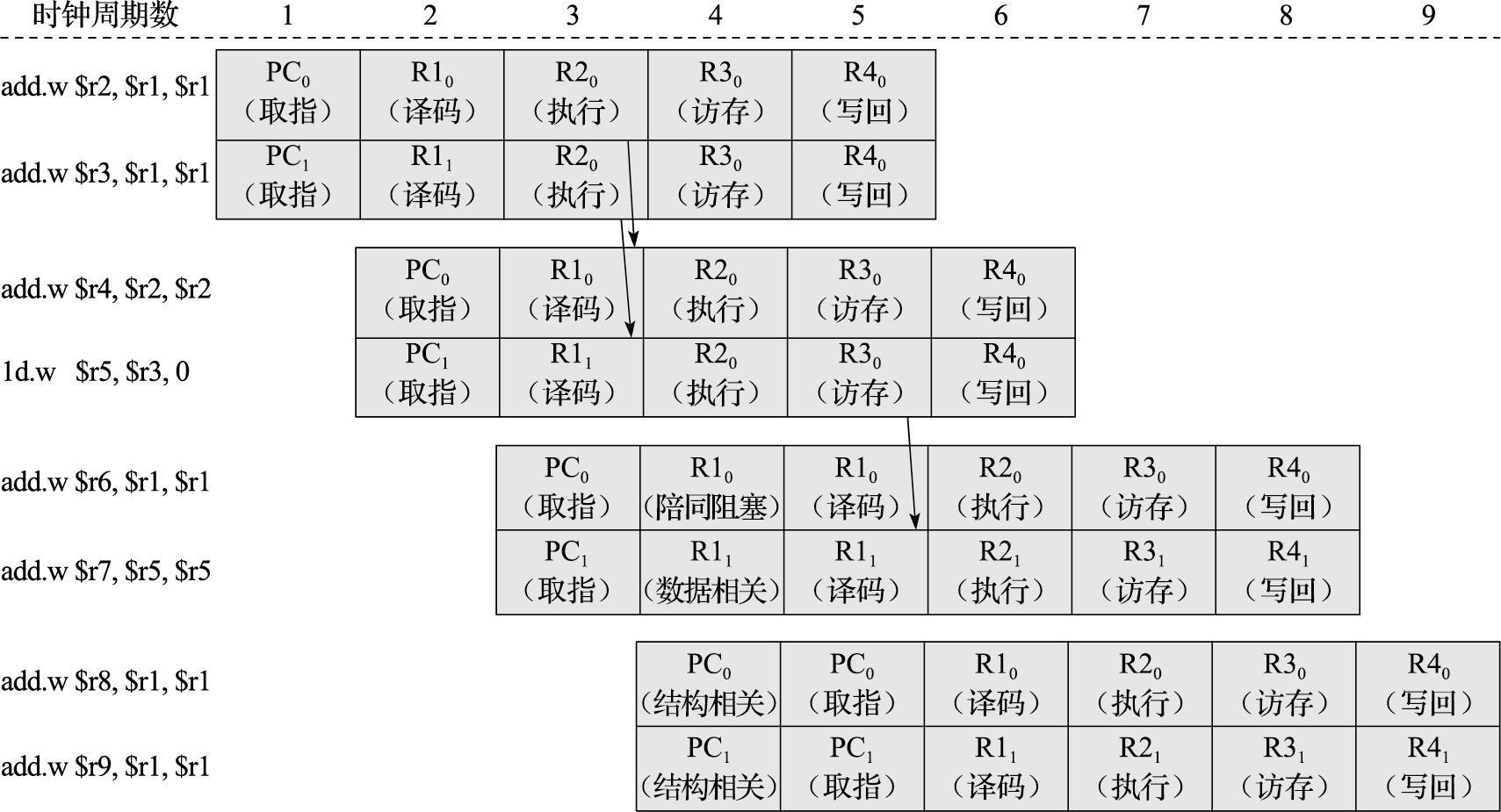
- Data hazard: 指令序列中存在依赖关系,比如 RAW (read-after-write), WAR (write-after-read), WAW (write-after-write)
- RAW: 是一种多个指令对同一个寄存器写-读的依赖,见前面 cs61c 的 slice,可以靠 stalling (需要等待前面的指令完成 ) 或者 forwarding(bypass) 来增加更复杂的数据链路
- WAR: 先读后写同一个寄存器。可以看作读寄存器没执行完的时候,后面写入就执行完了。WAR 可以靠 register renaming。这话有点抽象,可以举下面的例子。这里面 R0 实际上可以拆分成不同的寄存器,即我们有多于逻辑寄存器的物理上的寄存器
- WAW: 反复写入同一个寄存器,如下
1 | ; machine code, WAR hazard |
- Control Hazard: 因为控制(分支之类的)指令,导致指令流水没法继续推进。这里分支预测很大程度上就是用来缓解这些问题的
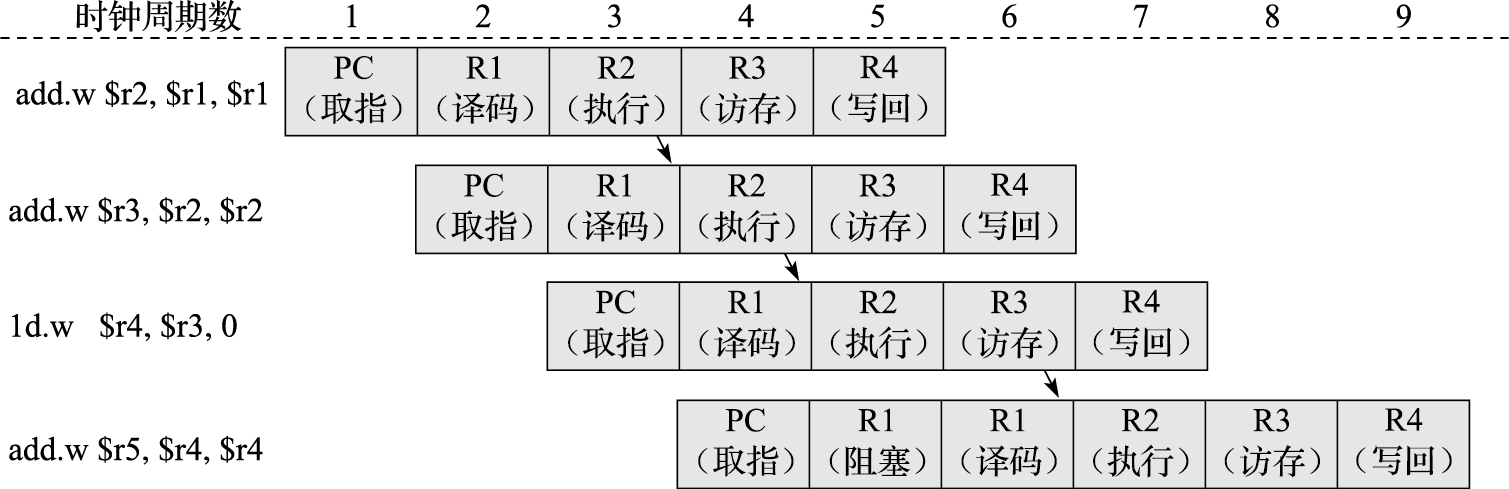
关于 forwarding,胡伟武的书提到了这里的流程 ( https://foxsen.github.io/archbase/%E6%8C%87%E4%BB%A4%E6%B5%81%E6%B0%B4%E7%BA%BF.html#sec-pipeline-cpu ):
指令级并行
- 程序的顺序被称为 Program order
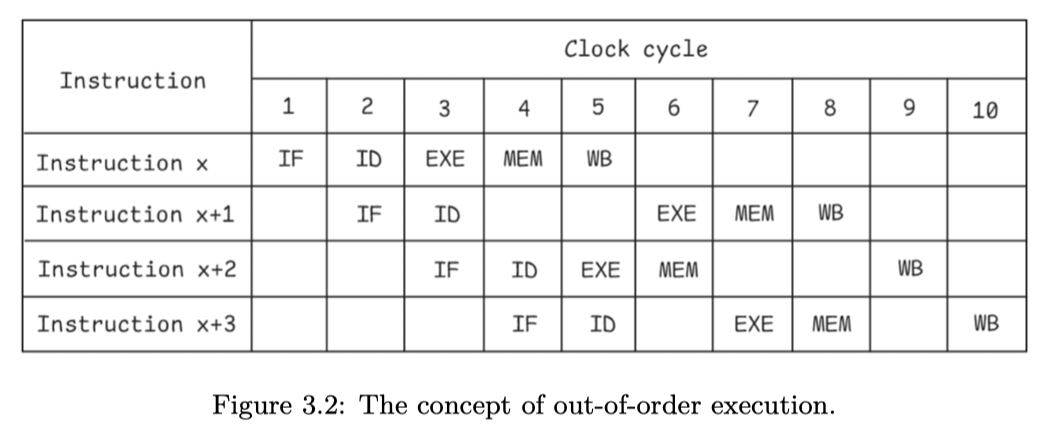
- 大部分的 CPU 允许 Out-of-order execution,如下图 Figure 3.2,
x + 2和x + 3没有按照 program order 进入 EXE 阶段
OoO 执行通常带来很大程度上的性能提升,但也带来更多复杂性和更高的功耗,这个调度的流程被称为指令调度 ( intruction scheduling ),用来尽量减少 pipeline hazard,增加硬件资源利用率。
静态调度:Intel Itanium 有一种 VLIW(超长指令字) 技术,希望编译器选择正确指令组合来帮助调度,但似乎不是很成功。
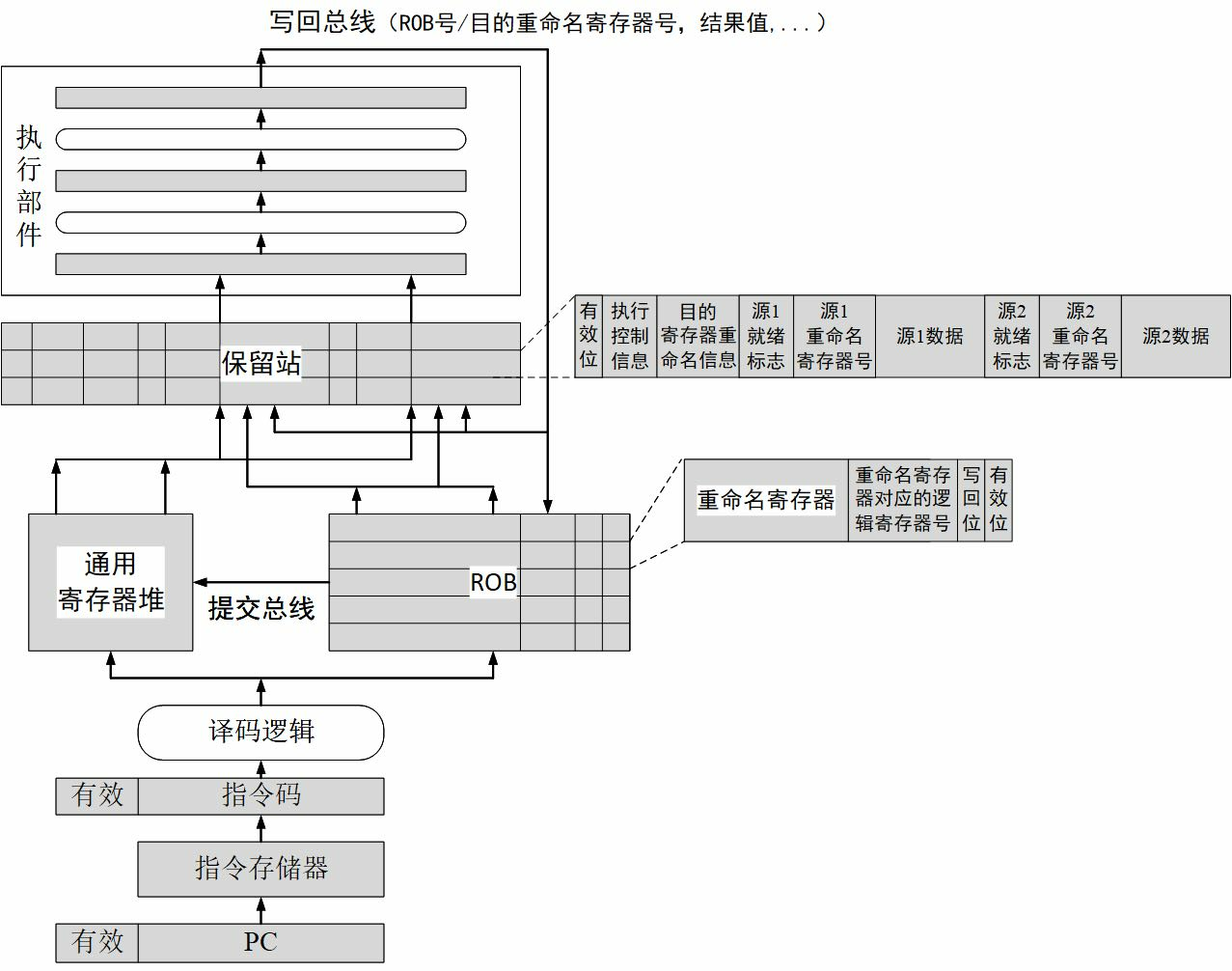
现在的 CPU 大部分使用动态调度,这里的关键是 Scoreboarding 算法和 Tomasulo 算法,下列大部分都是摘抄的,非笔者原创
1966年,Robert Tomasulo在IBM 360/91中首次提出了对于动态调度处理器设计影响深远的Tomasulo算法。该算法在CDC6000记分板方法基础上做了进一步改进。面对RAW相关所引起的阻塞,两者解决思路是一样的,即将相关关系记录下来,有相关的等待,没有相关的尽早送到功能部件开始执行。但是Tomasulo算法实现了硬件的寄存器重命名,从而消除了WAR和WAW相关,也就自然不需要阻塞了。
为了实现动态调度,大概需要下面的结构:
- 首先,要将原有的译码阶段拆分成“译码”和“读操作数”两个阶段。译码阶段进行指令译码并检查结构相关,随后在读操作数阶段则一直等待直至操作数可以读取。处在等待状态的指令不能一直停留在原有的译码流水级上,因为这样它后面的指令就没法前进甚至是进入流水线,更不用说什么提前执行了。所以我们会利用一个结构存放这些等待的指令,这个结构被称为保留站,有的文献中也称之为发射队列,这是动态调度中必需的核心部件。
- 译码并读寄存器的指令进入保留站,保留站会每个时钟周期选择一条没有被阻塞的指令,送往执行逻辑,并退出保留站,这个动作称为“发射”。
还有一个 ROB,这是一个比 RS (保留站)更大的缓冲区,可以当成某种意义上是指令提交 Buffer:
那么在乱序调度的情况下,指令已经打破了原有的先后顺序在流水线中执行了,“前面”“后面”这样的顺序关系从哪里获得呢?还有一个问题,发生异常的指令后面的指令都不能修改机器的状态,但是这些指令说不定都已经越过发生异常的指令先去执行了,怎么办呢?
上面两个问题的解决方法是:在流水线中添加一个重排序缓冲(ROB)来维护指令的有序结束,同时在流水线中增加一个“提交”阶段。指令对机器状态的修改只有在到达提交阶段时才能生效(软件可见),处于写回阶段的指令不能真正地修改机器状态,但可以更新并维护一个临时的软件不可见的机器状态。ROB是一个先进先出的有序队列,所有指令在译码之后按程序顺序进入队列尾部,所有执行完毕的执行从队列头部按序提交。提交时一旦发现有指令发生异常,则ROB中该指令及其后面的指令都被清空。
这篇写的也不错
- 【计算机体系结构】Tomasulo算法 - 予梦秋水的文章 - 知乎 https://zhuanlan.zhihu.com/p/499978902
SuperScalar ( 超标量 / 多发射 )
超标量处理器复制执行资源,以保持流水线中的指令流过而不会发生结构冲突。
推测执行
正常的应用程序中转移指令出现十分频繁,通常平均每5~10条指令中就有一条是转移指令,而且多发射结构进一步加速了流水线遇到转移指令的频率。例如假设一个程序平均8条指令中有一条转移指令,那么在单发射情况下平均8拍才遇到1条转移指令,而4发射情况下平均2拍就会遇到1条转移指令。而且随着流水线越来越深,处理转移指令所需要的时钟周期数也越来越多。面对这些情况,如果还是只能通过阻塞流水线的方式来避免控制相关引起的冲突,将会极大地降低流水线处理器的性能。
现代处理器普遍采用硬件转移预测机制来解决转移指令引起的控制相关阻塞,其基本思路是在转移指令的取指或译码阶段预测出转移指令的方向和目标地址,并从预测的目标地址继续取指令执行,这样在猜对的情况下就不用阻塞流水线。既然是猜测,就有错误的可能。硬件转移预测的实现分为两个步骤:第一步是预测,即在取指或译码阶段预测转移指令是否跳转以及转移的目标地址,并根据预测结果进行后续指令的取指;第二步是确认,即在转移指令执行完毕后,比较最终确定的转移条件和转移目标与之前预测的结果是否相同,如果不同则需要取消预测后的指令执行,并从正确的目标重新取指执行。
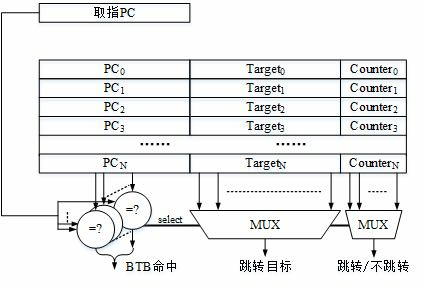
BPU 一般会作用于这个 BTB。这里有几个点:
- 时间相关性:分支解析方式很好地预测其下次执行时的解析方式,也称为局部相关性。
- 空间相关性:几个相邻的分支可能以高度相关的方式(首选的执行路径)解决,也称为全局相关性。
- 某些分支具有偏向行为。例如,如果条件分支 99.9% 的时间都朝一个方向发展,则无需使用复杂的预测器并污染其数据结构。
- 如果分支具有循环行为,则可以使用专用的循环预测器来预测, 该预测器会记住循环通常执行的迭代次数。
如今,最先进的预测由类似 TAGE 的 [Seznec & Michaud, 2006] 预测器主导。Champio nship 43 分支预测器每 1000 条指令的预测错误少于 3 次。现代 CPU 在大多数工作负载下通 常可以达到 >95% 的预测率。
SIMD
- Reduced pressure on instruction fetch
- Fewer instructions are necessary to specify the same amount of work
- Reduced pressure on instruction issue
- Reduced number of branches alleviates branch prediction
- Much simpler hardware for checking dependences
- More streamlined memory accesses
- Vector loads and stores specify a regular access pattern – High latency of initiating memory access is amortized
线程级并行
一种是多核心
- 常见性:如今,面向消费者的设备中的几乎所有处理器都是多核 CPU 。撰写本书时,高端笔记本电 脑包含十多个物理核心,服务器处理器在单个插槽上包含 100 多个核心。
- Freq: 当更多内核运行时,热量很快就会超过冷却能力。这种情况下,多核处理器将降低时钟速度。这就是为什么会看到 具有大量内核的服务器芯片的频率,比笔记本电脑和台式机的处理器低得多的原因之一。
- 多核系统中的内核相互连接,并连接到共享资源,例如:末级缓存和内存控制器。这种通信通 道称为互连,通常具有环形或网状拓扑。CPU 设计人员面临的另一个挑战是随着内核数量的增加保持机器平衡。
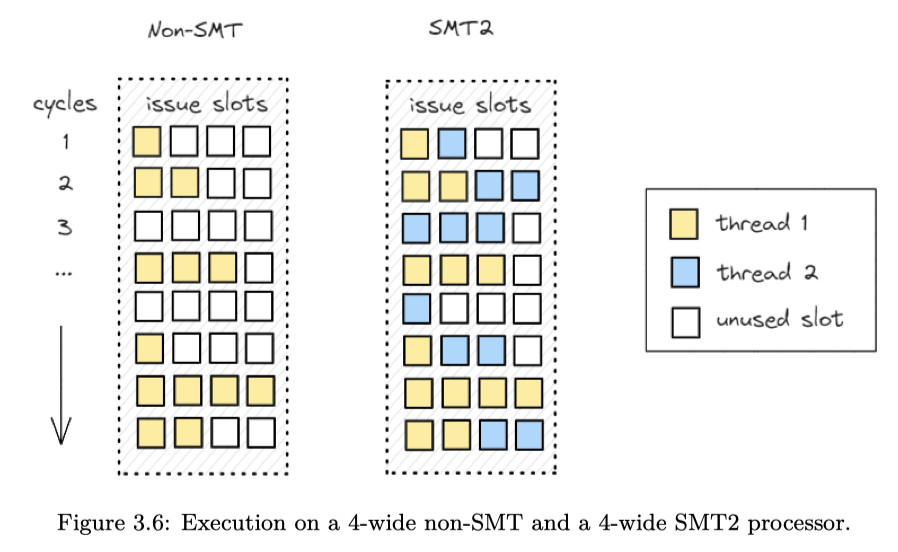
另一种也是超线程(SMT,或者 HT),这里为了支持 SMT,CPU 必须复制架构状态(程序计数器、寄存器)以维护线程上下文。其他 CPU 资源可以共享。实现中, 缓存资源在硬件之间动态共享线程,用于跟踪 OOO 和推测执行的资源会进行复制或分区。
在 SMT2 核心中,两个逻辑核心实际上是同时运行的。在 CPU 前端,它们以交替顺序(每个周期或几个周期)获取指令。在后端,每个周期处理器都会从所有线程中选择要执行的指令。由 于处理器会在两个线程之间动态调度执行单元,因此指令混合执行。
SMT 的缺点是:
- 性能更加难以预测,尤其是单核跑一些 CPU Bound 的东西的时候,这个问题在云环境中尤其明显。
- 有 Memory/Cache bound 的任务的时候,核心上的任务做 L1 L2 Cache 竞争的时候,可能会造成更多的 Evict(这是相对更少的调度机会来说,在亲和的核上执行尽可能久,效果会相对好一些?)
还有就是大小核的经典 Big.LITTLE 和大小核调度。
Cache
内存缓存L1 L2 L3 已经很多地方介绍过了,这里不额外介绍。这里 Cache 地位如下:
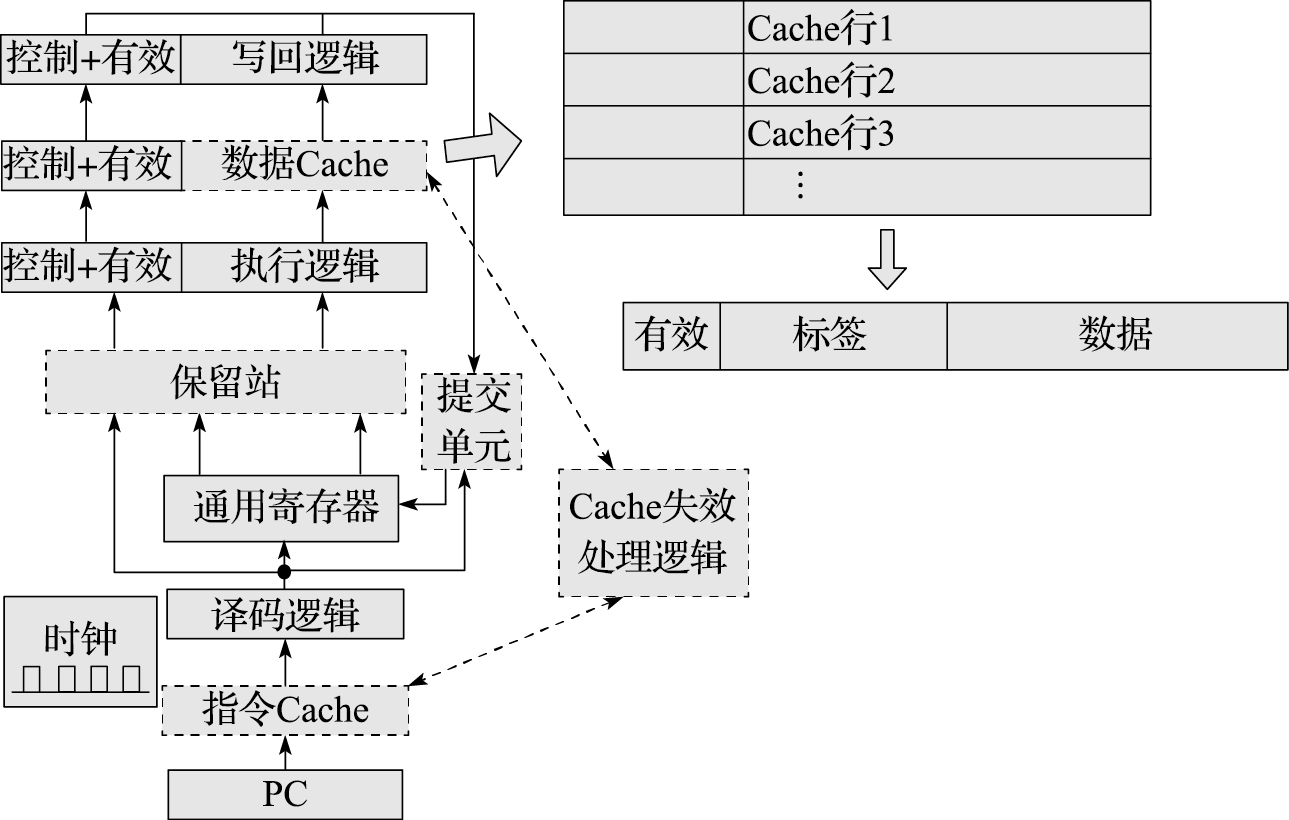
这节专门讲点硬件,main memory 一般用 DRAM,这玩意一般比较的东西会有:memory density, memory speed, price。一般会用延迟、带宽来描述。
DDR
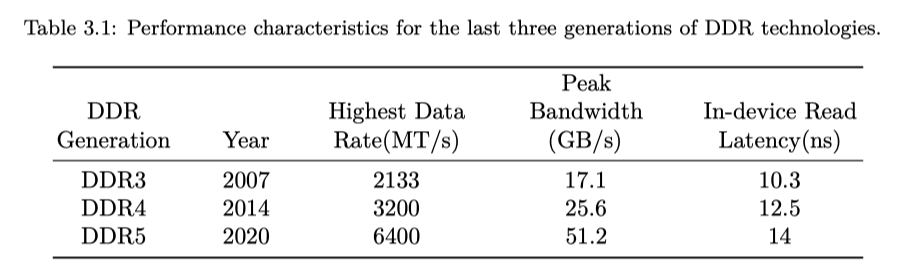
大部分 CPU 支持 DDR 技术,这里参数如下:
从这个网站 ( https://www.corsair.com/us/en/explorer/diy-builder/memory/what-is-cas-latency-ddr5-latencies-explained/ ) 给出的信息来看,DDR5 有更高的时钟频率,但是访存需要的 CL (CAS 需要的周期)却多于 DDR4。
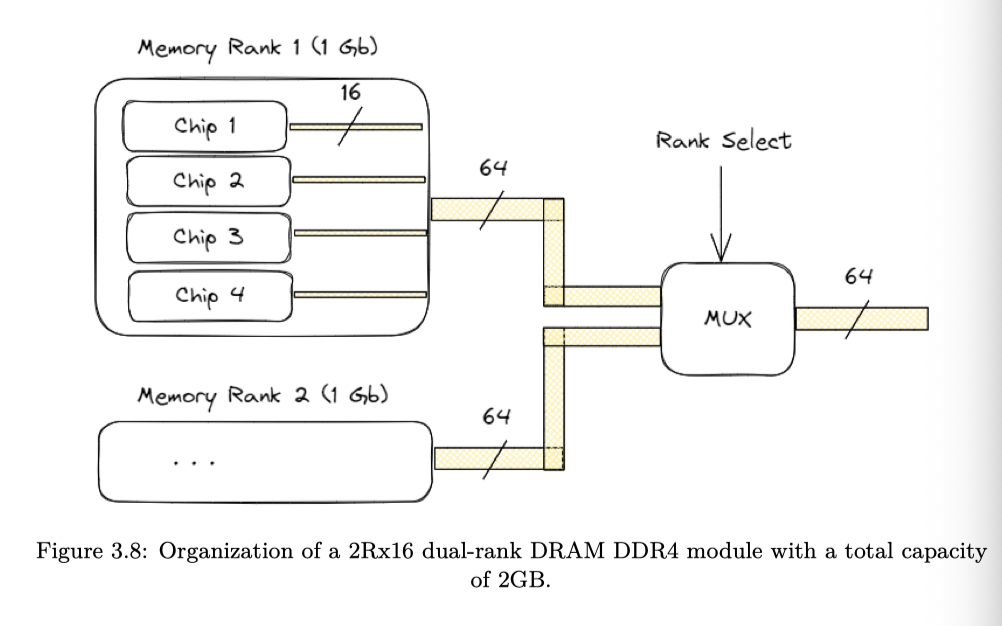
A DRAM module is organized as a set of DRAM chips.
- Memory rank is a term that describes how many sets of DRAM chips exist on a module
- Each rank consists of multiple DRAM chips. Memory width defines how wide the bus of each DRAM chip is. And since each rank is 64 bits wide (or 72 bits wide for ECC RAM), it also defines the number of DRAM chips present within the rank. (下面的逻辑就是选择 rank 的)
- 这里文章还提到,single-rank 和 dual-rank 谁好取决于应用类型:single rank 本身热量小、故障率相对低;dual rank 可能需要一个时钟周期来选择 rank,可能会增加访问延迟;但 DRAM 本身也是需要刷新的,DRAM 本身电荷会逐渐丢失,需要靠刷新来恢复电容器电荷。在刷新的时候,时候这里是不能处理内存访问请求的。这里 dual rank 可以很好在其他 rank 繁忙的时候刷新
下图的型号是 2Rx16 DRAM DDR4
具有单个 memory channel 的系统在 DRAM 和内存控制器之间具有 64 位宽的数据总线。多 channel 架构增加了内存总线的宽度,允许同时访问 DRAM 模。例如,双 channel 架构将内存数据总线的宽度从 64 位扩展到 128 位,使可用带宽翻倍。
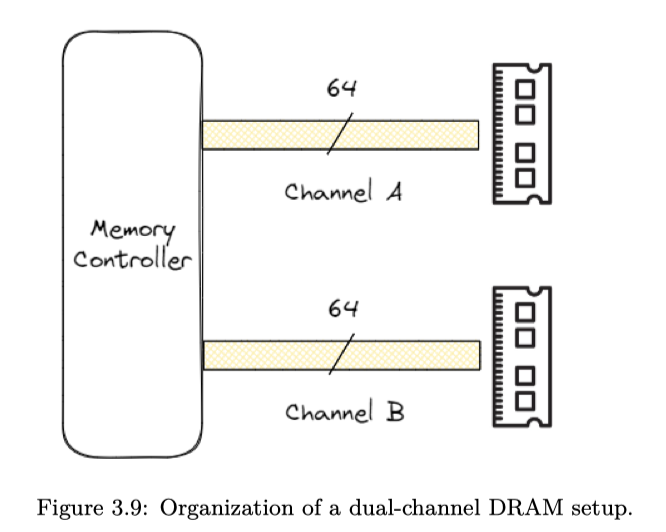
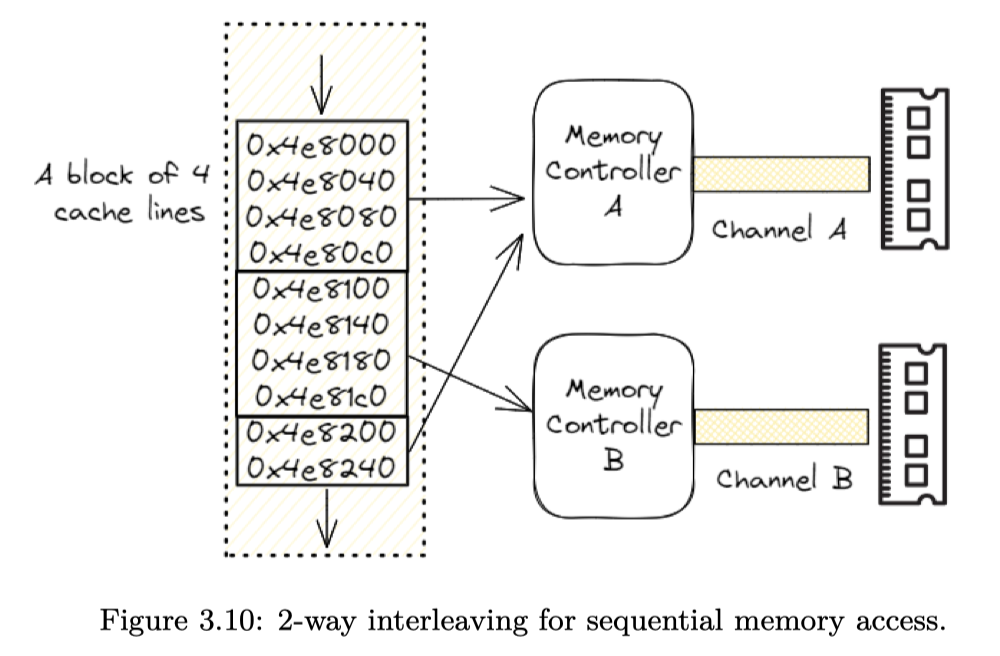
更翻倍的是,处理器还能同时拥有几个 Memory Controller。有一种 memory interleave 技术,就能把分配的内存分到不同的区域上,增大访问的带宽、降低访问延迟。(当然 NUMA-Aware 的时候就需要更注意这个了)
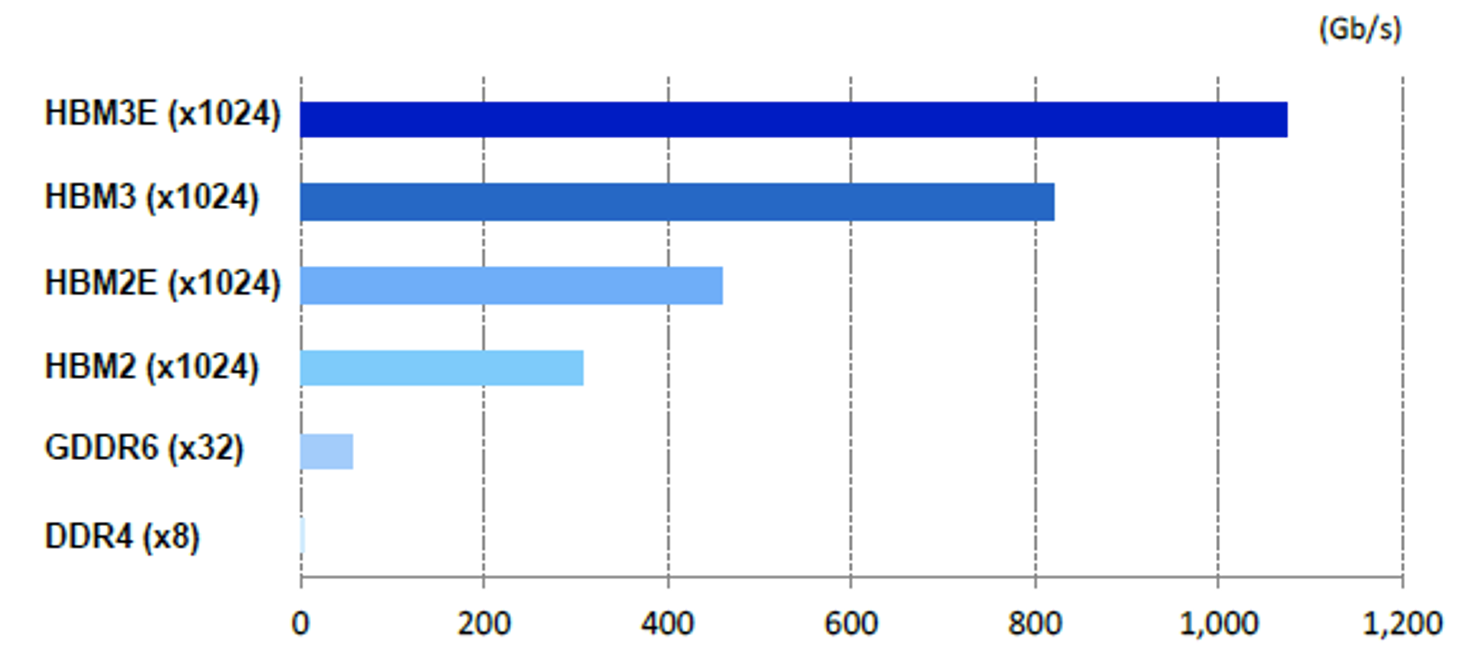
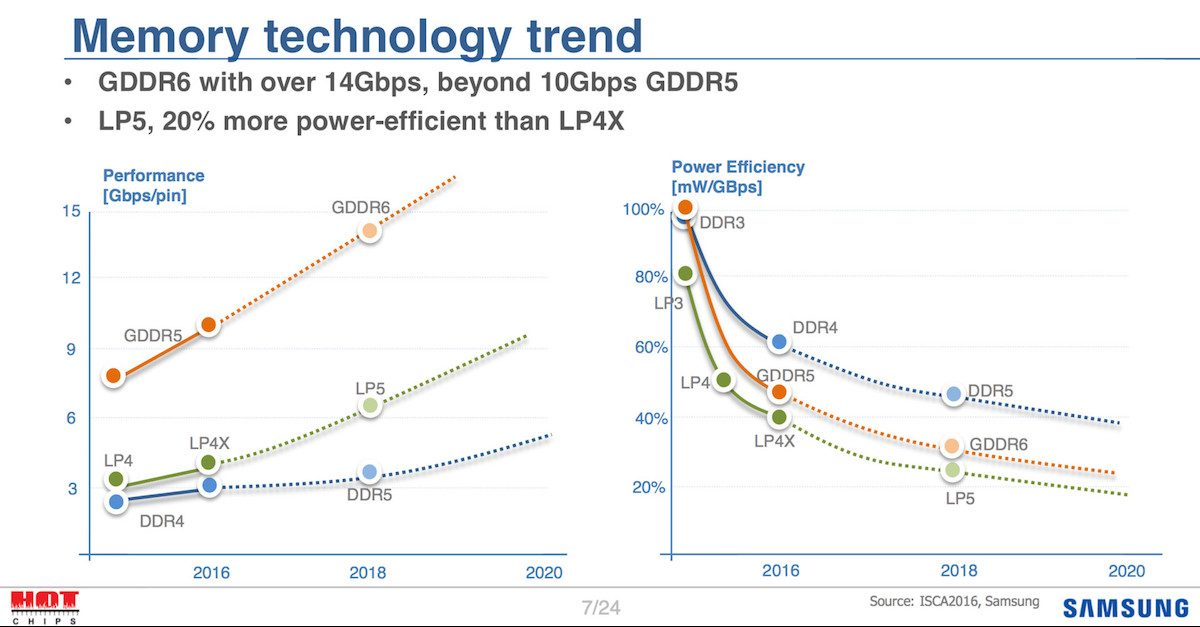
HBM & GDDR
https://www.driehaus.com/perspectives/High-Bandwidth-Memory-Technology-for-AI-Applications
https://www.lowyat.net/2016/112512/samsung-expects-gddr6-to-arrive-in-2018/
GDDR 最初是为图形设计的,如今几乎每张高性能显卡都使用它。虽然 GDDR 与 DDR 有一 些共同的特点,但也有很大不同。DRAM DDR 的设计目标是降低延迟,而 GDDR 的带宽则要高得多
HBM 是一种新型 CPU/GPU 内存,垂直堆叠内存芯片,也称为 3D 堆叠。与 GDDR 类似, HBM 大大缩短了数据到达处理器所需的传输距离。与 DDR 和 GDDR 的主要区别在于 HBM 内存 总线非常宽:每个 HBM 堆栈有 1024 位。这使 HBM 能够实现超高带宽。
Intel Golden Cove
- 前端:用于获取 x86 指令并将其解码为 µops
- 后端:6-wide superscalar, out-of-order
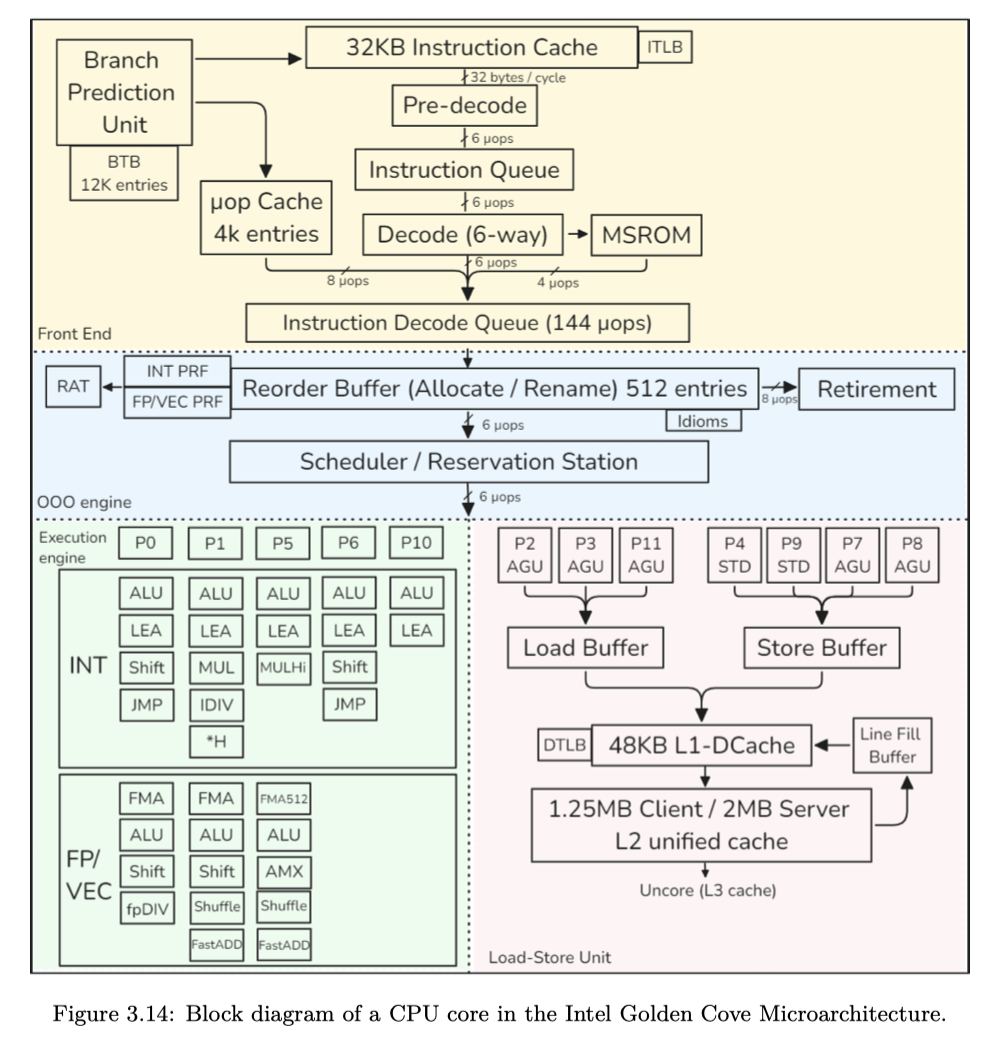
这块看书就行,写的非常细