Task execution basics in Velox
这篇文章简单介绍一下 Velox 中的 Operator 和 Pipeline。因为刚开这块代码,所以这块知识肯定很多是我很后面才能理解的,这里就当一个官方博客翻译机器,链接一下别的地方写的各种知识了。主要是最近想看看 TableScan,发现不懂别的东西光看 TableScan 的话很多上下文是推进不下去的
参考材料:
- https://facebookincubator.github.io/velox/develop.html
- Velox 的论文 ( 和之前的阅读材料: https://blog.mwish.me/2022/11/13/Introduction-to-velox/ )
Plan in Velox
图一:Pipelines
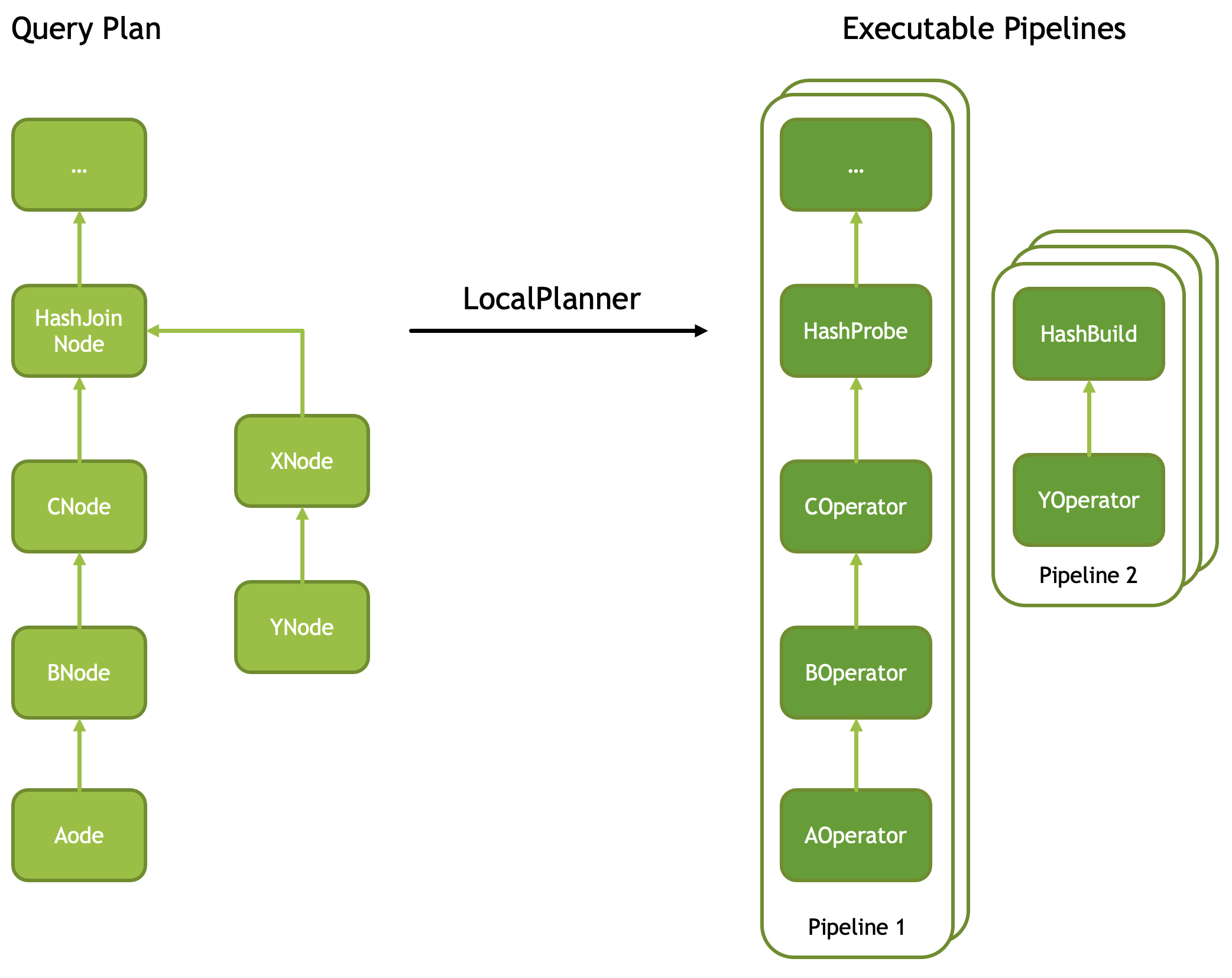
具体:https://facebookincubator.github.io/velox/develop/operators.html
在之前的论文也提到过差不多的内容。具体来说,Velox 接受一个PlanFragment,PlanFragment 对应系统中的 物理执行计划,由 PlanNode 组成. 同时会有一些 Plan 层的别的信息(这个给的不是很多,比如是否去做 Grouped Execution - https://github.com/prestodb/presto/wiki/Stage-and-Source-Scheduler-and-Grouped-Execution ,大概意思是按照 Partition 把数据分组,然后方便做 co-locate Join 之类的优化,这样比如做完了 build 可以立马做同组的 group,在做 group 的调度)
在代码实现上,有一个比较有意思的,就是非 Group 的调度也会有个 GroupId ( kUngroupedGroupId),算是某种程度上的实现上开洞了。
Task 在创建的时候会把 PlanFragment 转化为 DriverFactory 组,即常说的 Pipeline, PlanNode 转化 Operator。还有一些一个 Join 变几个 Operator 的狗屁倒灶,这种都其实是比较直观的。DriverFactory 提供 Driver,每个 Driver 都有一组 Id:(DriverId, PipelineId), Driver 只有一组 Physical Operator,来负责具体的执行。DriverFactory可以提供一个并发度,有的地方,比如 Final Agg 之类的地方,单机并发度是受限的,会固定为 1(比如下图中的 Local Exchange 之后的处理);Group Execution 的情况下可以有 Group Number * 并发度数量的执行器。Task这部分逻辑参考 LocalPlanner,注意几个细节上的边界:
- 多个 Source 的 Operator 会被切分成多个 Pipeline ,这个地方有个值得注意的点是,Velox 的 Pipeline 是直线性的,如果一些复杂的地方如果支持 CTE 的话,可能会有一些奇怪的搞法?
- Driver 的性质可以看上图,Pipeline 1 的 Driver 数为2,Pipeline 的 Driver 数为 3,他们之间靠「Join Bridge」连接起来。在
LocalPlanner里面,如果看到一个HashJoin,那么他会拆分出HashBuild和HashProbe,然后查看一下这里时候可以 Group Execution,并插入 Join Bridge。
这里就是 Velox Task 相关的细节。那么我们扩展到分布式系统中,借用一张 Presto 论文的图:
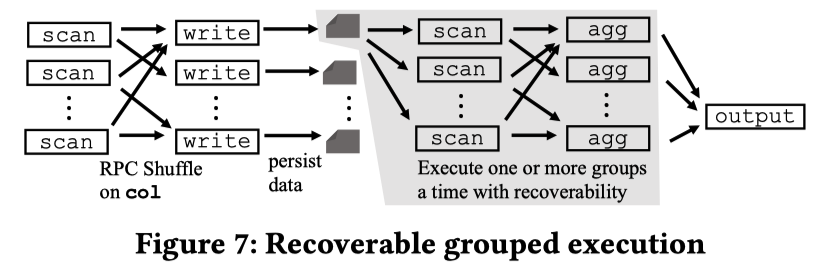
在 Spark 中,数据可能被 Plan 出多个 Stage,然后中间靠 Shuffle 通信。Presto 本来是在内存执行的,后面也做了类似的机制,靠 Shuffle 和持久化来 Persist…额我扯远了。这里是说,Task 这个概念比较接近 Stage 的一个子集,一个 Stage可能被切分成一个或者多个 Task,分布到一个或者多个 Executor 执行。
Operator in Velox
官方的开发文档:https://facebookincubator.github.io/velox/develop/operators.html
Operator 本身的代码并不复杂,概念也很好理解。但是实际上反过来说 Operator 也是整个 Velox 的「业务逻辑」,整个 Operator 大概分类为:
- SourceOperator ( 即 Pipeline 或者执行链路的最右侧 Leaf,从 Split 或者上游拉数据,甚至可能是个 Values)
- Consumer:
TableWriter,ConsumerSink等,是 Pipeline 的最终节点 - 中间的节点
每个 Operator 对外的接口大概有
- Operator 的 Projection ( 输入-输出的 Projection 处理,感觉这种都是查询编译定下来的)
- Operator 初始化
- Operator 是否需要更多的输入 (这个地方在这里看会有点奇怪,为什么是否需要更多输入需要配置在 Operator 上呢?等我们介绍 Pipeline 执行的时候就会理解了)
- Opearator::addInput: 输入
RowVectorPtr - Operator::getOutput: 输出
RowVectorPtr(你会发现这里没有直接一个next搞定全部,这里我们在最后 Pipeline Execution 一节会介绍)。 isBlocked: 返回 Operator 状态是否是 Blocked 的- dynamicFilter 相关:是否能下推 df, 清楚 df,下推 df
- Agg Pushdown 相关,比如是否是 Filter
- Memory Reclaim 相关,比如
Spill的实现 ( 见下面 Spill 一节,上层表示是否能回收内存和内存状态等)
各个 Operator 的实现并不在本篇博客的范围内,因为本篇博客只是一个框架层的介绍。但从 DF, Input, Output, Memory 来看,读者很容易得到一个(显而易见)的事实就是 Operator 是有状态的
Shared States in Task and Driver
你会发现我们从 Plan in Velox 就介绍了 Task,但是介绍完 Operator,我们又回到了 Task?思考一个问题,Driver 内的状态是 Operator 带给下一个 Driver 的,但是还有些信息可能是自上而下的,比如 TopN cutoff 和 Join DF 之类东西。另一个是跨 Driver 的地方的通信,包括数据传递,提前停止等信息;还有输入这种信息,会被放到一个 Task 共享的池子中处理。
Join: JoinBridge
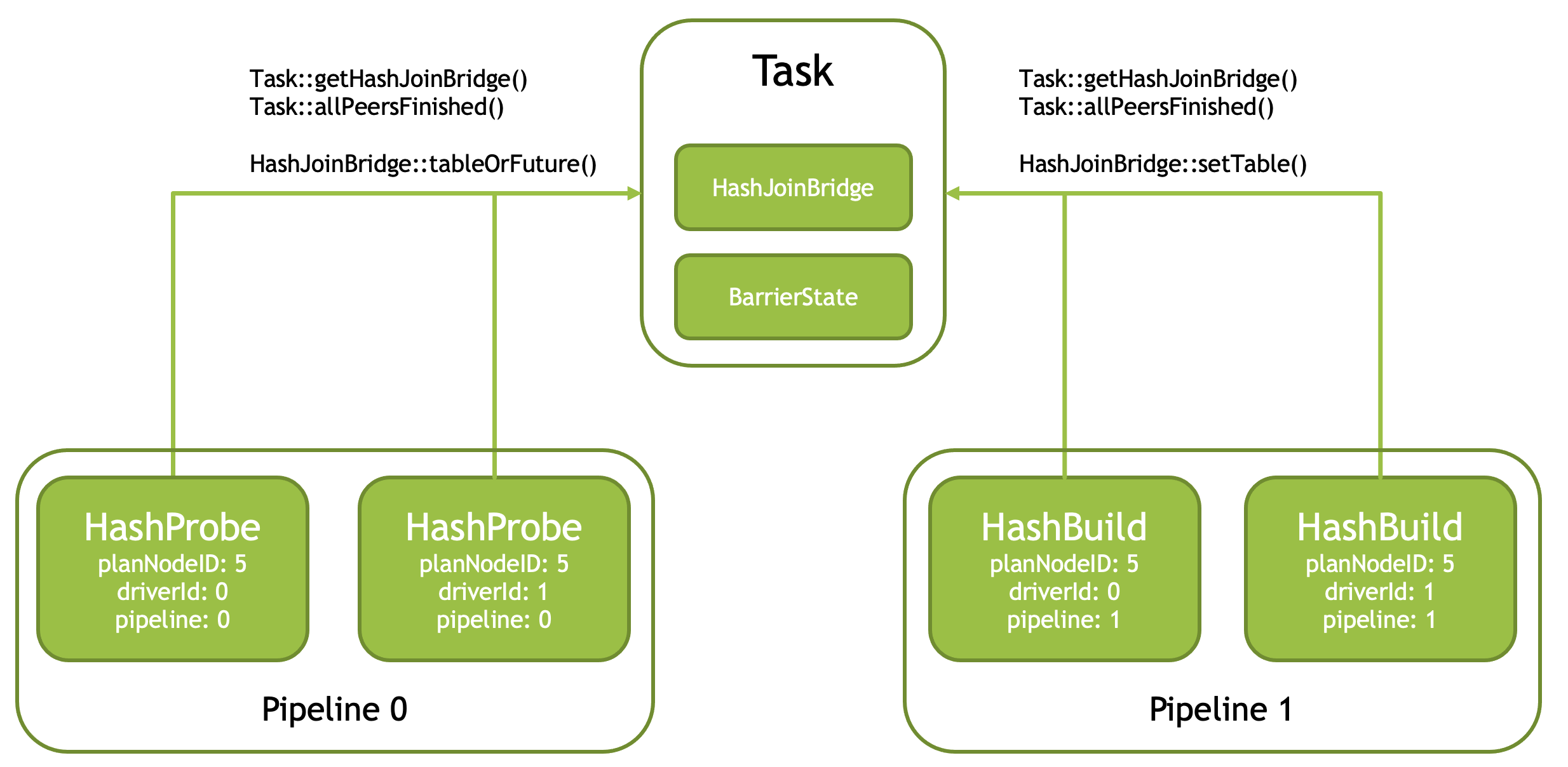
HashJoin 会被拆分成两个 Pipeline,Build 和 Probe,一般:
- 整个 Build Pipeline 完成了 Probe 才会启动,有着顺序依赖关系。如上图,在 Probe 侧会调用
tableOrFuture - Build Pipeline 之间也需要同步(比如非 Grouped Execution 中,两个 HashBuild 同时写一个 HashTable)
Input: Split
Split 是 Task 的「输入数据切分」,TableScan, Exchange 和 MergeExchange 的地方允许去添加 Split,api 在 Task 上:
1 | void addSplit(const core::PlanNodeId& planNodeId, ...); |
这里有个有意思的点是外头和 Task 里面调用的方式。 Task 外部去 addSplit,Task 内部则有一个共享的池子,当 TableScan 等 Operator 执行的时候,它们绑定了一个 DriverCtx,即 Driver 内执行的上下文,然后又可以通过这玩意来 pull 到 Task 内的 Split.
如果 Task 里面没有 Split 怎么办呢?这个地方接口返回的是一个 Future,Driver 就会挂起,等待 Split 发下来去通知等待的 Promise.
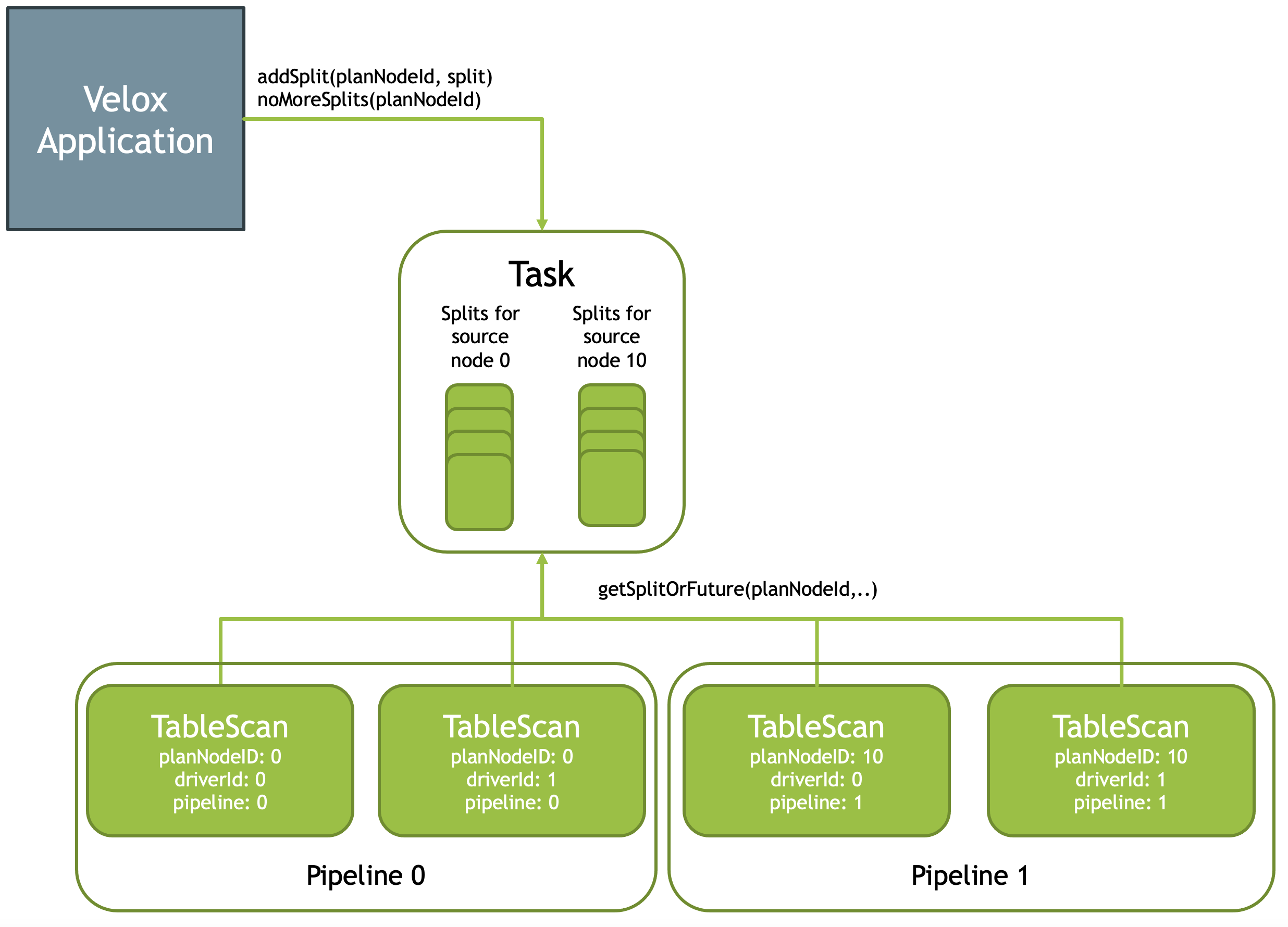
关于 DataSource / Connector 和 “Hive” 有关的东西会在后面的博客中介绍。
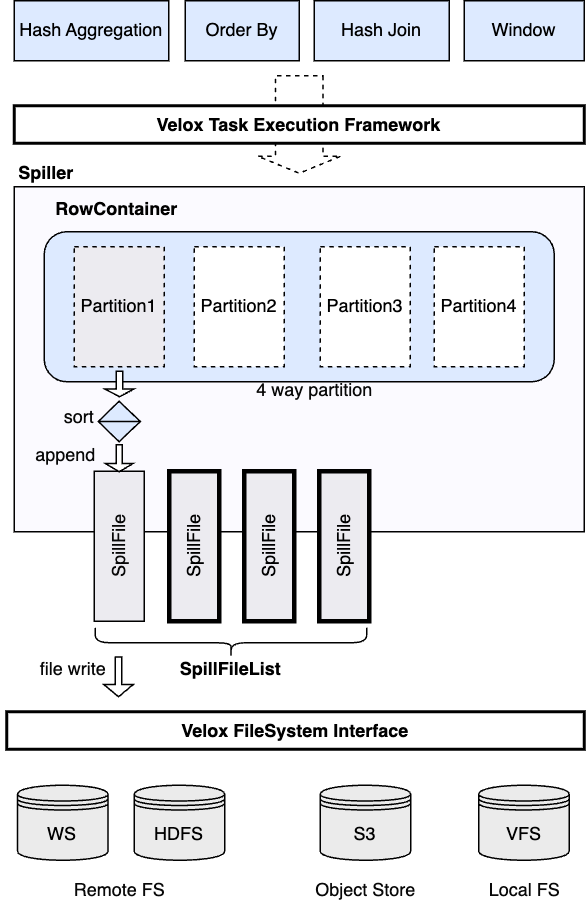
Spill
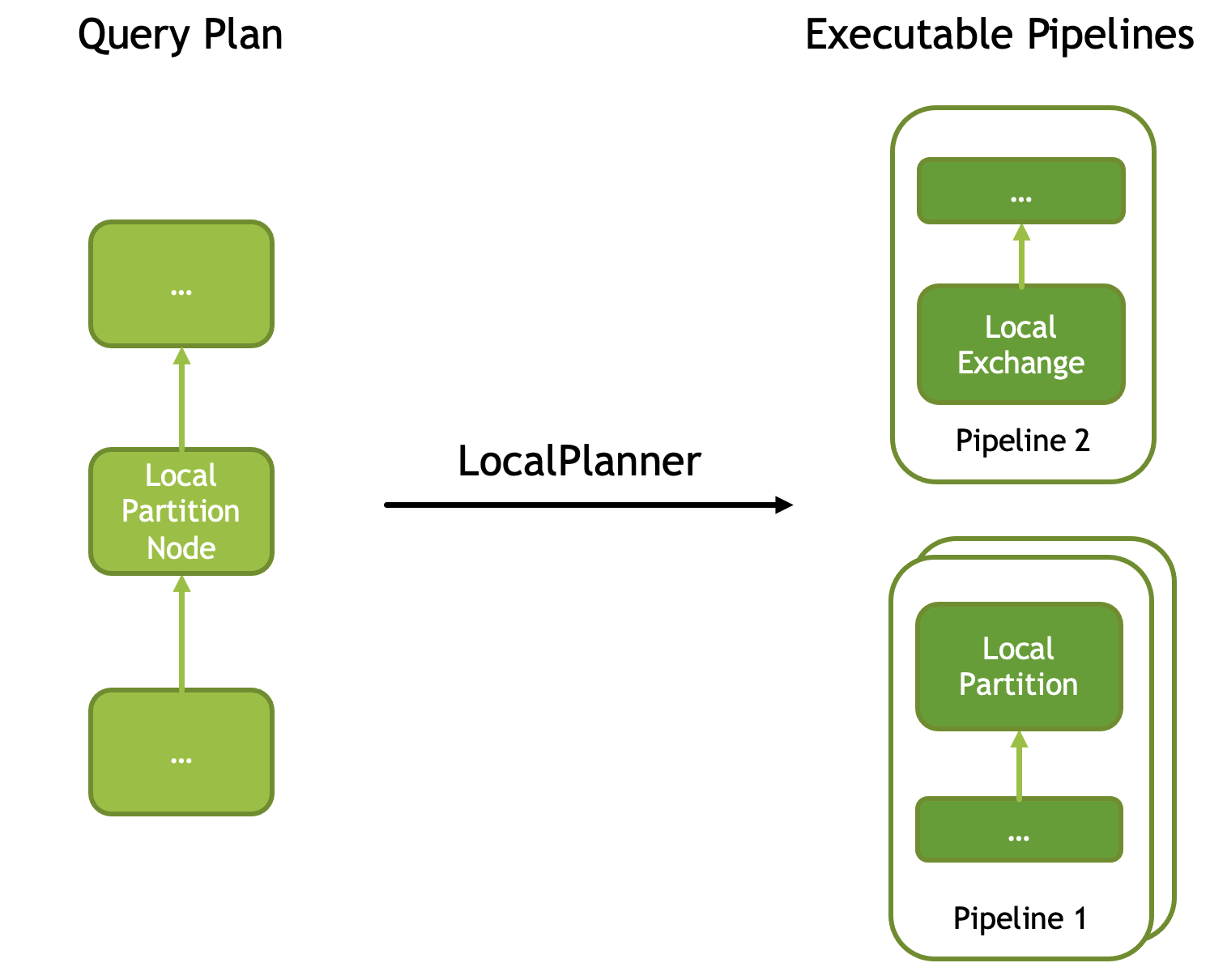
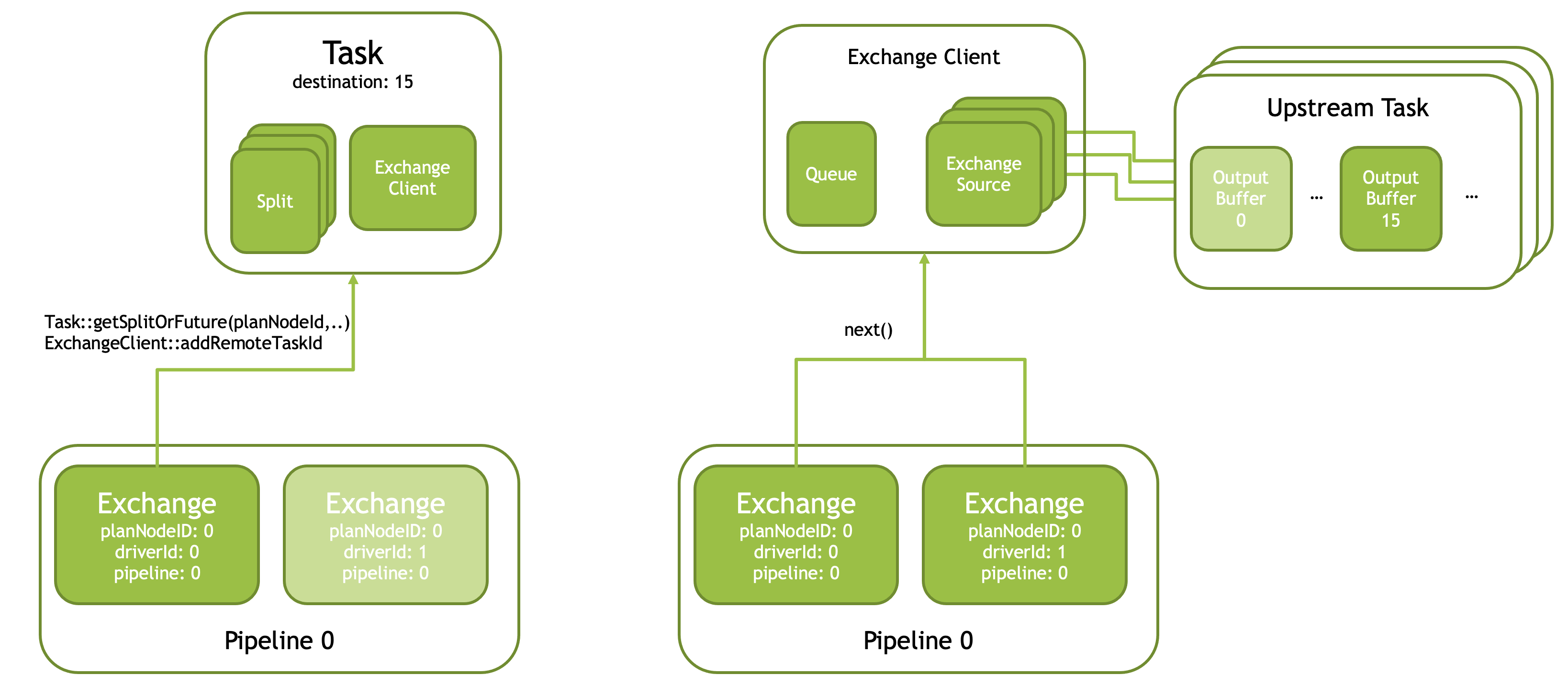
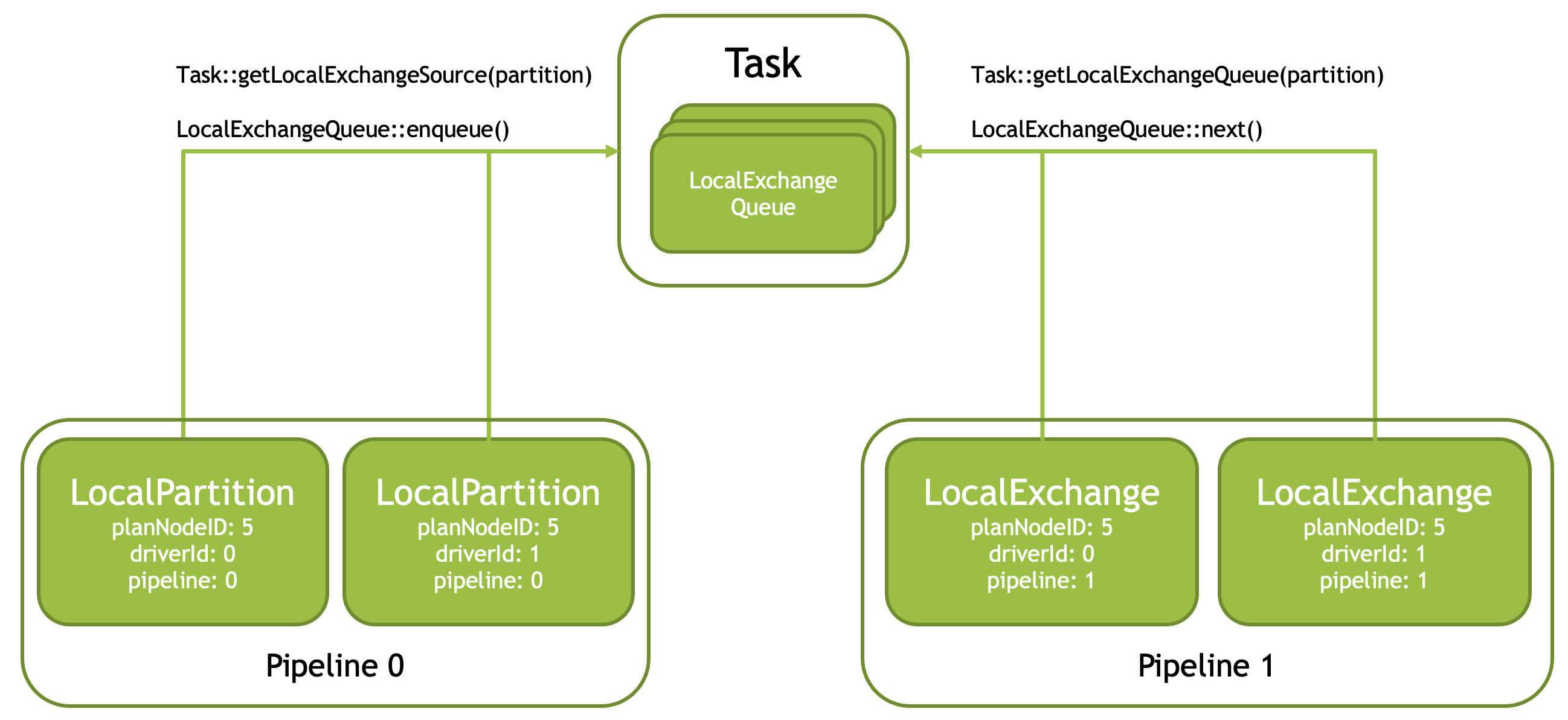
Exchange & Local Exchange
Shuffle 之类的算子可能会切分成 Exchange,此外还有 Local Partitition 之类的 Operator,把输入切分成多个 Partition,后续会有依赖顺序。这类一个是需要管理这个对象,一个是其实这玩意可能可以实时消费,不用像 JoinBridge 那样。在单机系统的情况下,它以「Queue」的形式维护.
Merge & Local Merge
我们假设有一个 Sort-Partition 切分,消费端会需要从多个 Sorted 数据中 Pull 数据然后合并,这里可能需要上游都生产完成,然后限定 maxDriver = 1。
Pipeline Execution
推荐阅读官方文档:https://github.com/facebookincubator/velox/blob/main/velox/exec/TaskDriverOperatorLifecycle.md (又是 md 又是 doc 的文档能不能不要乱飞)
Velox 的 Task 允许去单线程或者多线程的运行。单线程的话我们本篇幅就不介绍了,基本上是 Task 去 Pull 下一个 Batch 的形式进行。多线程的逻辑是我们介绍的重点。我们需要介绍几个对象:
BlockReason/Future: Velox 使用了folly::Future,并包装出了一个BlockReason, Operator 或者Task很多接口都可以返回对应的 Reason,来出让任务权限。这可能发生在任务真正有 Blocking 的场景,也可能是分时调度中,需要 Yield 出来DriverCtx:Driver执行的上下文,绑定有Task的指针Executor: 使用 folly 的Executor,来绑定 CPU 和 IO 的线程资源MemoryPool,MemoryReclaimer: 内存资源的管理 apiQueryCtx: Task 级别的资源和上下文,包括 MemoryPool, Executor 等资源的上下文。创建数据什么的可以走这个 api
多线程的环境中,上层有启动 Task 的 API:
1 | void start(uint32_t maxDrivers, uint32_t concurrentSplitGroups = 1); |
Start 中的逻辑如下:
- 创建
maxDrivers数量的 Driver, 在这个流程中,会调用LogicalPlanner::plan,这个地方会塞入maxDrivers帮助静态的定一些 Driver 数量之类的逻辑。(见Task::createDriverFactoriesLocked) Task::createAndStartDrivers: 「启动」concurrentSplitGroups数量的 Group。如果是 un-grouped 的话,这里就已经启动了。这里会创建对应的Driver和DriverCtx- 调用
Driver::enqueue去把Driver加入到Task的执行队列中,由QueryCtx的 Executor 来调度执行这些 Driver
我们下面介绍 Driver 层次的执行,它的入口是我们前几行提到的 Driver::enqueue -> Driver::runInternal,在这里,执行层会“永远”从 Driver 的最下面来 Pull 数据上来(猜测是因为执行简单),一旦有 Blocking 之类的,就会停止执行。
上层:
- 尝试调用
Driver::runInternal,runInternal会一直执行直到结束或者出现或者 BlockingReason - 对 runInternal 结果检查,结束的结束,如果是 Yield,会再次 enqueue 到执行队列的末端;如果是 Blocking,会挂一个
BlockingState::setResume,在 callback 中 enqueue task
1 | StopReason Driver::runInternal( |
内部:
- 一直对所有 Operator 执行数据,直到挂起或者结束
这里执行逻辑大概如下
- (如果没有初始化的话,初始化所有 Operator)
- 从 Source 开始 Pull 数据,有任何 Blocking 尝试去处理 Blocking,没 blocking 的话,下个 Operator 在
needsInput的情况下,从自己的Operator去 getOutput,给下个 OperatoraddInput
你会很奇怪,这里有什么 needsInput 呢?假设我们有下面的情况:
1 | Operator1 -> Operator2 -> Operator3 |
在第一轮执行的时候,Operator1 获得了 Output,然后给 Operator2 去 addInput,这个时候我们查询 Operator2 的状态,发现它是 Blocking 的,我们就会把控制权交给别的 Operator
在第二轮执行的时候,这里还是会从 Operator1 开始执行,但是 Operator2 有上次的 Input,所以这次它可能(也不是一定)不需要新的 input,所以这一轮可能没有 Op1 -> Op2 的数据传递。