PolarDB IMCI: Row/Column in RO node
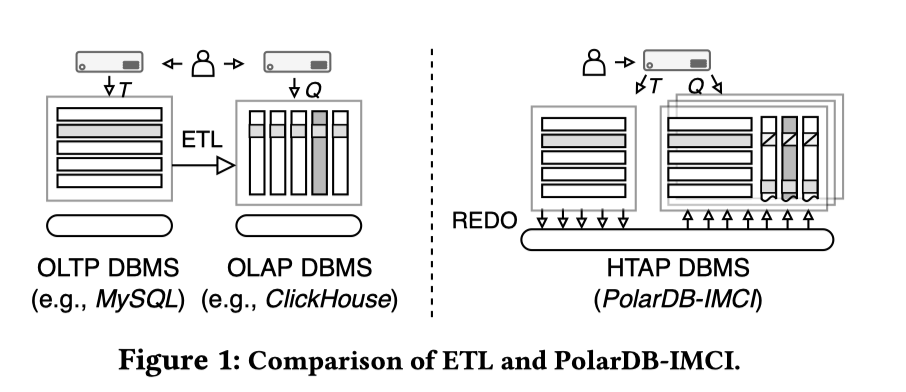
PolarDB-IMCI: A Cloud-Native HTAP Database System at Alibaba 发表在 SIGMOD’23 上的文章,简单介绍了 IMCI 的列存实现。PolarDB 是一个基于共享存储 PolarFS + RDMA 的云存储数据库。Redo/Page 共享在 PolarFS 这一共享层上。PolarDB 之前能够在这个架构上实现 Serve 类似数据的 RO 节点(实际上我感觉 RO 节点在工程上还是有不少难度的)。在 IMCI 上,这套 RO 扩展为行/列皆有的存储,靠 InnoDB Redo Log 来同步。在 RO 从节点上,通过行存的 Page 和一套额外的定位索引完成 Physical Page - Logical in Page 的日志到列存地址的定位,并用一套简单的列存 Serve MVCC 读查询。这套架构会增加一定的存储成本,并且对机器的内存和 io 可能有一定的要求,因为相对于原来的节点,感觉需要多 Serve 一部分数据,可能需要一些相对高规格的机型。但是本身这种架构可能服务的对象也比较具体,因为 PolarDB 虽然是共享存储,但是还是那种 TP 数据库,所以数据规模应该相对可控,面对的用户需求可能也相对具体一些。这样本身可能 workload 也和数据分析各种跑批然后 INSERT OVERWRITE 到一个新的表,各种算 T+1 的需求之类的不一样,只是 OLAP 查询。在这种场景下,这套架构可能是很轻而且很靠谱的。
论文设计的时候提出了五个目标:
- Transparent Query Execution: 靠对上层提供同样 SQL 接口,只要用户设计 Index,然后内部开出节点(其实我也有点感兴趣他们这方面怎么做收费模型的)
- Advanced OLAP Performance: (typically through the introduction of columnar data storage).
- Minimal Perturbation on OLTP Workloads: OLTP queries are usually more mission-critical and are more sensitive to performance degradation.
- 这里靠 RO 节点来实现,通过 Redo log 来做同步,并且不考走 binlog 来避免引入写侧的额外开销 [1]
- High Data Freshness: using the visibility delay as a freshness score for a query. By definition, the visibility delay is the time interval during which updates to the database can be visible to OLAP queries. (这里在论文第六节提到有一些 Proxy 的设计能保证更强的语义)
- 这里走了 commit ahead log shipping 和 conflict-free log replay (2P-COFFER)(就是直接 redo 而不是 binlog 同步😅真能取名)
- 使用 Append-Only Storage 做一个 LSM-T 列存索引加速查询,根据 insert-order 来组织列存(但是这样显然就要后台调度 compaction 了,无论是列存的还是索引的,不过论文也没讲?可能是尽量在前台做一些操作)
- Excellent Resource Elasticity: should ensure high resource elasticity (e.g., scale-out in minutes or even seconds) to adaptively serve the changing data volume and analytical workloads with stable performance and high resource utilization.
- 允许用 ddl 类似的方式快速在别的机器上拉起构建索引
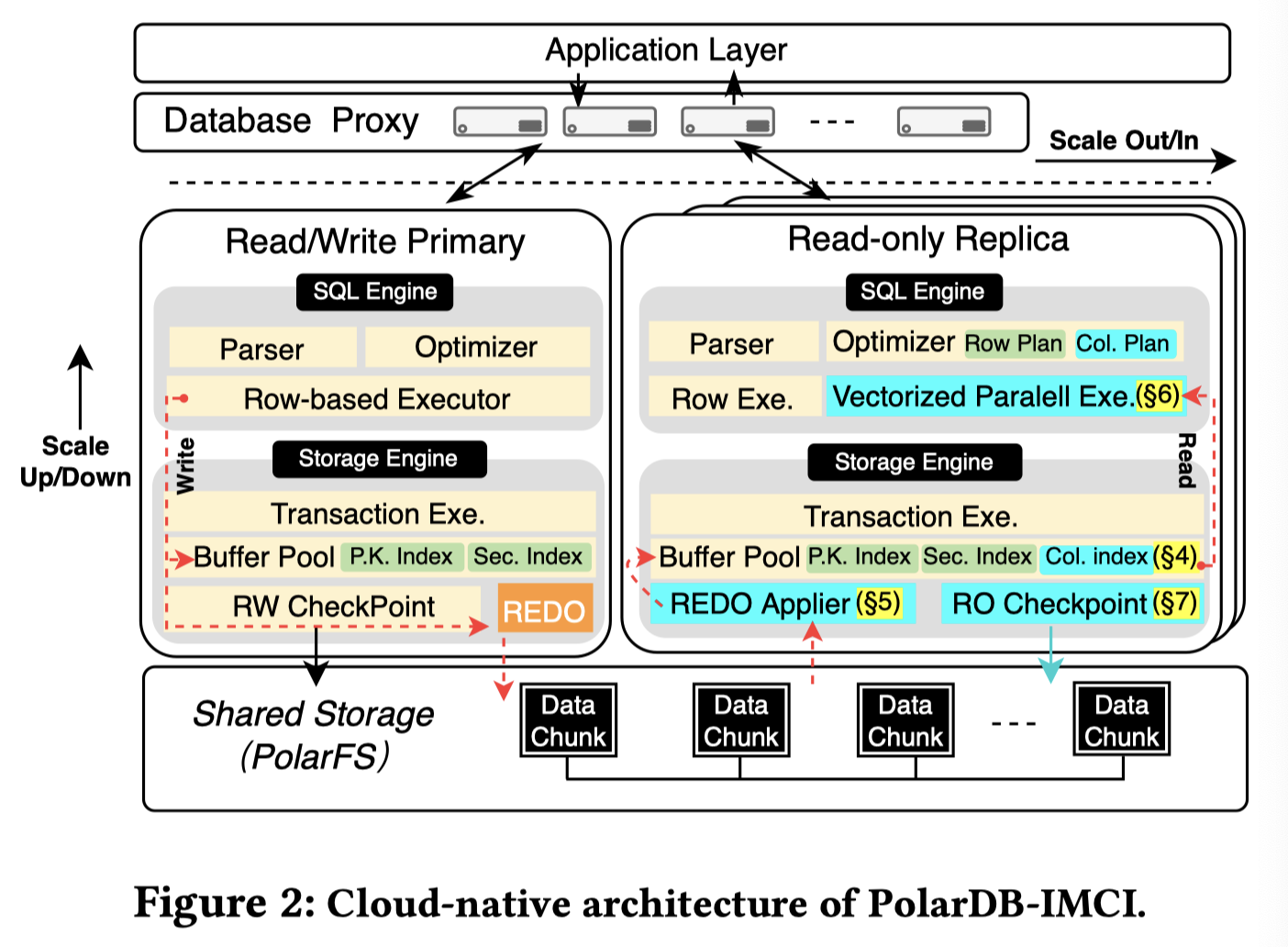
IMCI 架构如下:
使用的时候需要建表:

然后 Planner 会生成一个混合行列的 Plan。因为在这个节点上是行列都有的。不过感觉这里的隔离级别和同步时间之类的没有特别好的定义,论文提到了一个同步延迟,但是没有提到具体的实时和一些语义,感觉这个得看看产品文档了,我个人感觉上应该是只有 RR 的。我们在之后也会介绍这个行列混合的执行模式。
具体拉起一个节点的时候类似在 RO 上 DDL ,然后这里会 Online 构建一个索引。
COLUMN INDEX STORAGE
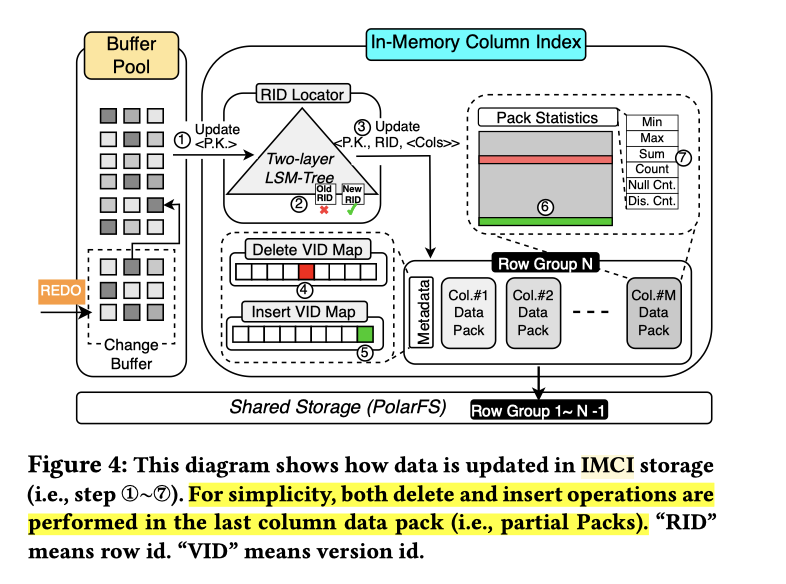
这块具体如上图。观察到几个成分:
- 外部数据来自 Redo Log,这里可能作用于 Page, Change Buffer (但不完全考虑 Undo)? 这里有个细节是可能要改 MTR,比如 Update 的 MTR 需要变成拥有所有列的 UPSERT。我还一下没想到 Undo 是不是有影响,可能 DDL 构建完 Index 后可以忽略 Undo?
- 内部有个 2-Level LSM-Tree, 作为一个 单版本 最新数据定位器。映射
<P.K. -> RID in Physical Location>. - 文件划分为 RowGroups, 64K 行一个 RG。RG 的 Column 称为 Pack,有一个正在写入的是 Unsealed pack. 这个 Pack 的概念类似 Parquet 的 Page。正在更新的 unpack - rowgroup 不会被压缩。这里还额外在 Metadata 维护了两列 MVCC 列:Deleted VID Map 和 Inserted VID Map. 这个类似事务系统的 insert_ts 和 delete_ts (但是可能不一定有直接的顺序性,应该类似 Innodb 的事务 id,是一个虽然递增,但是系统的 id 不一定代表提交的 ordering)
- 思考: 系统本身如何恢复?实际上可依靠 RO 的 WAL 恢复,所以可以不用及时直接把 Unsealed 去 Seal 了,这是有行存和 RW 系统的一套好处
在这个系统中,Update 被抽象成 Delete + Insert 。Delete 其实相当于只在 RID Locator 和 Metadata 做删除。然后 INSERT 全行插入最新的。考虑到这个表可能不会很大,暂时可能没有分区之类的功能?这样应该还蛮简单的。压缩文件删除只删除 Delete VID 的 Metadata 的话,这块开销也不是很大。
这里考虑到 MVCC 的细节,实际上在 Snapshot 推进之后,Insert VID Map 是可以不读的(当系统的 lowest trx id 大于最大的 insert vid 的时候)。这里的处理按照下面的顺序:
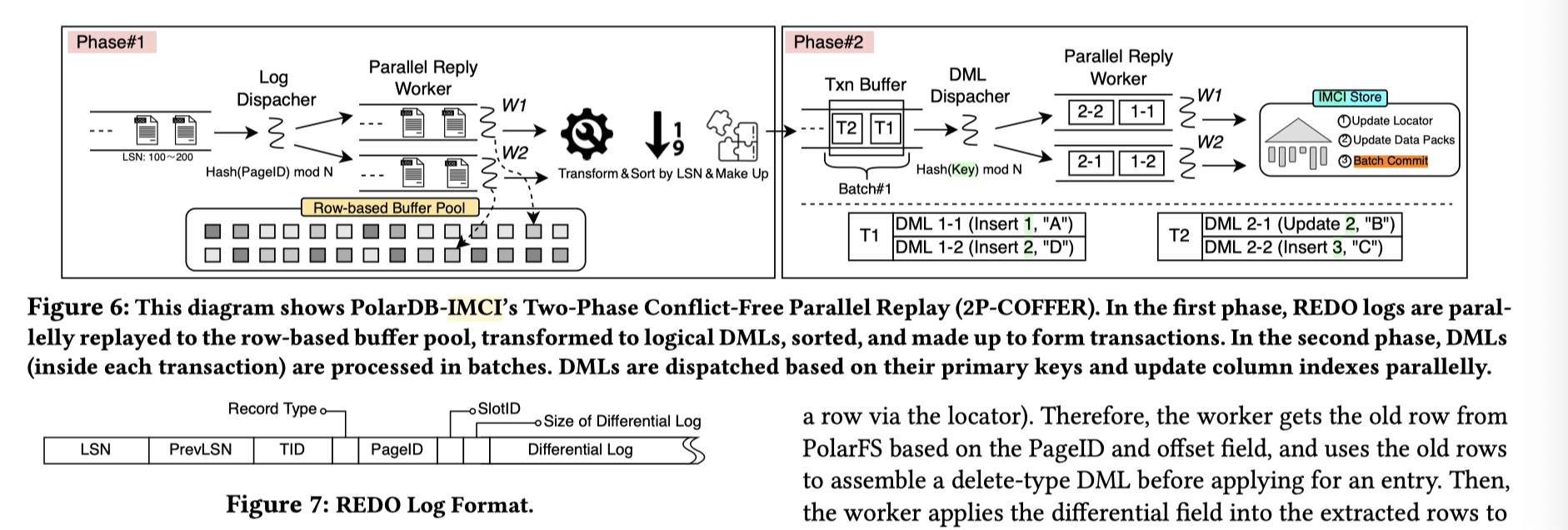
在提交之前,事务攒在 Transaction Buffer 中,等待最终的提交或者 abort。思考:如果走 binlog 的话,这套东西就相当于直接走 CDC 了,RID Locator 仍然需要,但别的应该不会了。这里也不需要判断事务冲突,因为事务冲突应该在行存系统处理了。我理解其实只走 binlog 的话这套会干净一点,然后考虑 binlog in redo 的架构,这套应该是可以做的。
但是在处理大事务的时候,这套方式推成了不处理写冲突的 MVCC,即这里大事务会做 pre-commit: 当事务 txn record 大小超一定限制的时候就会做 PreCommit,写到 unpack 的列存中,MVCC 列标注为一个不合法的列。那么怎么定位这些数据呢?这里可能需要一些临时的 RID Locator:
First, request a continuous RID for all rows in the current transaction buffer, and save this RID range. It is important to note that the global RID locator cannot yet be changed during the pre-commit phase to avoid the exposure of uncommitted transactions. Thus, PolarDB-IMCI creates a temporary RID locator instead of updating the RID global locator to cache new PK-toRID mappings. Then, PolarDB-IMCI writes the updates to Partial Packs while setting the insert and delete VIDs as invalid to make them invisible. Finally, PolarDB-IMCI frees the memory used by the transaction buffer unit.
查询处理
这里前台有个 Proxy 来负责 dispatch ro/rw:
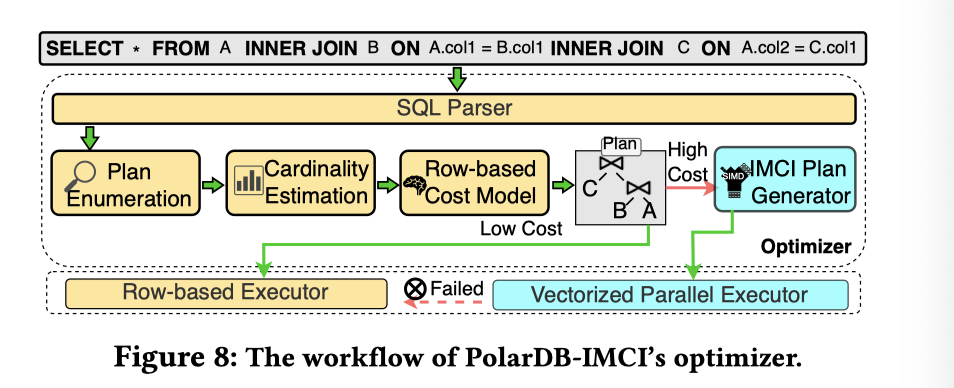
这里其实有点没懂,这个是在前台有个 SQL Parser 然后做代价估计?这一跳会很耗时吗🤔?不知道是像 Preso Coordinator 那样拆分了,还是怎么样,其实有点不是很理解。
关于 Consistency,这里还是 Proxy 靠 track LSN 来解决,有那么一点点类似 Raft ReadIndex 之类的。我倒是有点好奇,如果是靠 binlog ,这块同步有没有什么方案,可能还是给 committed txn 一个 id? 其实下一节提到了个 CSE,让我莫名觉得这套机制也可行。
The proxy keeps track of the RW node’s written LSN and all RO nodes’ applied LSN. The written LSN and applied LSN indicate the transaction commit point for RW and RO, respectively. Transactions before the written LSN were committed on the RW node. Likewise, any log entries before the applied LSN are guaranteed to have been replayed by the RO node. The proxy may only route queries to the RO nodes whose applied LSN is not less than the written LSN to meet the requirements of strong consistency.
Column 数据的持久化协议
Column RO 的 Node 被切成 Leader 和 Follower,类似一种「Columnar RO 数据的一写多读」。Leader 持久化这部分数据,Follower 类似只读节点。这里回头看看感觉实际上这个数据库甚至有一些 MPP 能力。。。
这里的关键设计是 CSN (Checkpoint Sequence Number) 和 Checkpoint。相当于对提交的事务定序:
- VID Map 会 fence 掉大于 CSN 的数据
- Packs 直接下刷即可,Leader 把 unsealed pack 构建成 Sealed 之后就可以下刷
- RID Allocator 可以直接相当于取 Snapshot 然后下刷,也会 fence 吊更大的
关于 VID Map 和 RID Allocator 可能需要一些精细一些的设计,不过感觉其实难度也可控
Reference
- 关于 binlog 的额外开销和 binlog in redo 方案,我感觉如果直接 binlog in redo 就能移除行那套的直接依赖了,除非再去做查询的 fusion: http://mysql.taobao.org/monthly/2020/06/01/
- AWS re:Invent2022 Aurora 发布了啥 - 陈宗志的文章 - 知乎
https://zhuanlan.zhihu.com/p/590576660 。这块我觉得本身也可以上 binlog。