Apache Hive: A History on Hadoop
(这是最近写的最烂的一篇文章了)
对于 OTAP 和传统的数据库来说,执行引擎 / 前台 / 存储即使有一些拆分,总体上还是单个程序执行。在前台由 SQL 解析,然后 Planner 下发到执行层,执行层可能会带一个 Context 来部分限制资源的执行。然后 Queuing 的话,有一些全链路的 Queue,然后在 overquota 或者内存过大的时候,触发一些内存上的限制。
Hive 由 Facebook 开发,发表于 ICDE’10,后来 Cloudera 也进行了不少开发,感觉基本上是他们在管,Hive 经历了 0.x、1.0、2.0、3.0 版本,在过去 SQL on BigData 不甚完善的时代,是大数据的事实标准。即使现在新技术一代代出现,他们也要兼容一些 Hive 相关的语义,同时,即使 Hive 哪天真的死了,它在 HDFS / S3 的表结构相关的信息也会存活。大体来说,Hive 是一个数据仓库,你可以说「Hive 流程大致和它们差不多」,但具体还是有蛮多设计上的比较大的区别的,我们可以简单从一张架构图来延展:
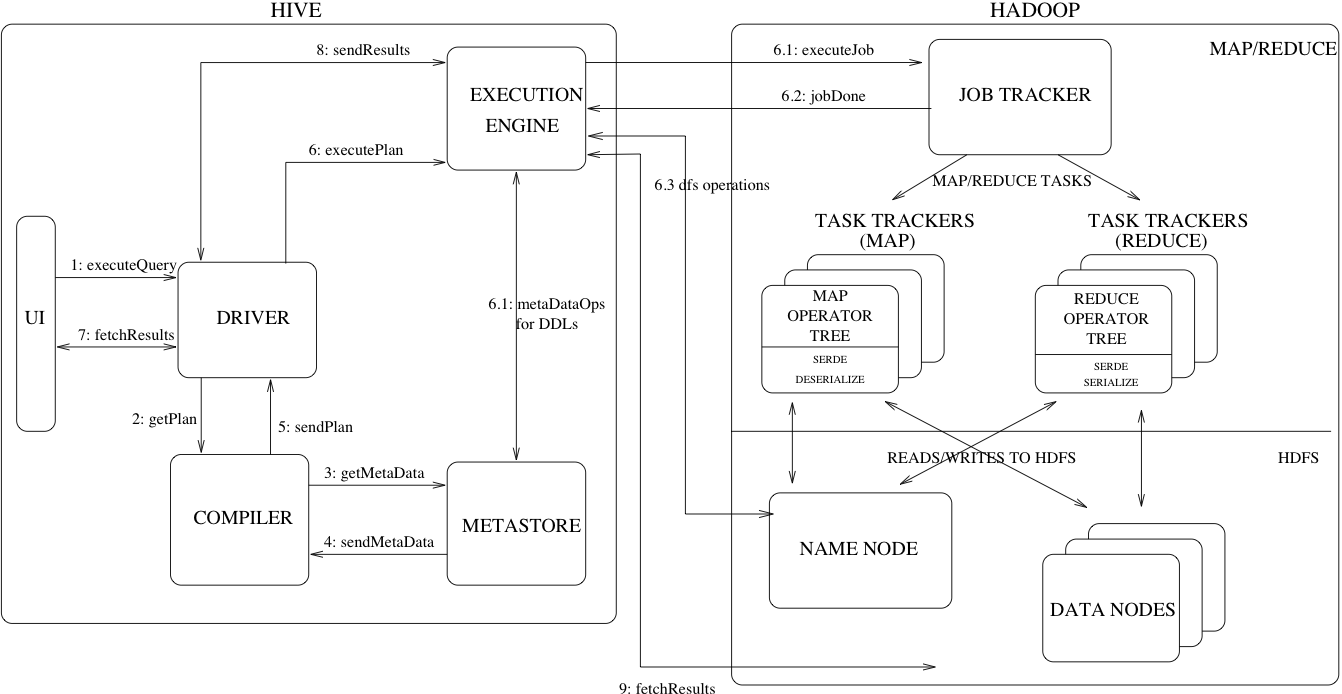
- MetaData 存储在单独的服务(MetaStore)上
- Hive 自己不完全负责查询的执行,而是下发给 MapReduce/Tez 之类的 Runtime
- Hive 自己不完全负责任务的调度,而是下发给 Yarn 之类的,在 Yarn 的框架下进行调度
- 数据存放在 HDFS 上。对外部数据源的尊重,不分情况支持对托管表的处理
- Planner 并不是那么「物理」的 SQL Operator,很大程度上是下推给执行引擎的 Plan
在 Hive 中,任务调度如上图所示。
同时,Hive SQL 和 OLTP 的 SQL 使用区别还是比较大的,它提供了 Partition / Bucket 的概念,在操作的时候,经常对 Partition 和 Bucket 做 Insert Overwrite 等相对比较重的处理操作. 这里可能可以让它的 SQL 被弄进 SQL 标准,但总的来说,这个和 TP 系常用的那些 SQL 差别还是不小的。此外,对于 Hive 而言,有一点比较乐子的地方是,它虽然能做一些优化,但是你可能是用 Calcite 来优化,最后跑在一个 MapReduce 上,多少有点隔靴子挠痒,然后 Plan 也是对应 Stage 的 Plan,因此 Hive SQL 也得专门抽时间学习才能写好,而不如 DB 那样 EXPLAIN / PROFILE 那样直观。(还有一些比较好玩的 case 是,因为 MR 几乎总是 Shuffle,所以我们某种程度上可以发现,一些公司 Data Stack 会在查询引擎逐步降级,从 Presto -> Spark -> Hive 这样逐步的降级,直到跑出任务)。
Hive 在历史上也进行过不少优化,包括从 MapReduce 换 Tez 等模式、向量化、LLAP。很多用户的观念还停留在 0.14 之类的版本。
Hive 一些常用的 SQL
表的创建和加载
Hive 的 config 用 set 之类的定义,数据源也可以定义 Serde 之类的 config:
在创建表的时候,内容如下:
1 | CREATE TABLE pageviews (userid VARCHAR(64), link STRING, came_from STRING) |
这里:
- 注意 Partition BY 的内容不完全出现在表 Schema 中
- CLUSTER BY 指定分 bucket 之类的信息
- 还可以指定表的一些 Schema
然后用户可以通过 load 等方式来加载数据,这里加载甚至可以选择 OVERWRITE 某个 Partition 的方式进行
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] |
然后,INSERT 可以选中数据,分别有 INSERT INTO 和 INSERT OVERWRITE. 大致上,INTO 是插入的时候直接插入,OVERWRITE 是覆写,插入的对象是 Table 或者 Partition。
1 | LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] |
Hive 的 Insert 还支持 Multi-Table-Insert,这是什么玩意呢?答案是它希望只读一遍数据然后插入多个 Partition / 表,借用一个 SQL:
1 | FROM my_table |
恶心吧!
哦对了,虽然不是很想在这个阶段介绍 Partition,但是 INSERT 的时候,如果打开了动态分区,Hive 会根据最后几列的内容,创建新的分区,具体见:https://cwiki.apache.org/confluence/display/Hive/Tutorial#Tutorial-Dynamic-PartitionInsert
CRUD 就不介绍了,另一些有意思的包括 MERGE INTO, Merge 在 Hive 2.2 支持:
1 | Standard Syntax: |
Merge 是一套相对恶心的东西…就是对匹配到的数据进行操作,举个例子:
1 | MERGE INTO customer USING (SELECT * FROM new_customer_stage) sub ON sub.id = customer.id |
好用是蛮好用的,就是 SCOPE 太大了点,有点震撼,相当于做出一定的筛选,再对筛选出来的数据处理。好像 Oracle 也支持这样的语法。
查询
INSERT OVERWRITE 从一张表插入另外一张表这种 SQL 我就不说了,这里着重贴一下分区相关的 SQL 和 JOIN
1 | INSERT OVERWRITE TABLE xyz_com_page_views |
注意到 date 不一定是 table 中的字段,这里可能作为对应的分区字段。
这里还支持了 SAMPLING,Array/Map/Struct 类型,Schema Evolution 等:Tutorial - Apache Hive - Apache Software Foundation
总之,Hive 提供的这套语义在大数据场景下,还是有用武之地的。这里专门提一下 Co-Groups:
1 | FROM ( |
这里后台需要是一个 MapReduce 程序,然后定义 reduce_script。这套东西就能泡在它上面了。
此外,大数据还需要一些作为 CUBE,ROLLUP 之类的语义,比如:
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+GroupBy (GROUP BY,GROUPINGSETS,ROLLUP,CUBE)
- 使用窗口函数来获得一定的 WINDOW 信息(TODO(mwish): 丰富这里)
- Coalesce, CASE WHEN 之类的,处理类似 if 的语义
在 JOIN 的时候,Hive SQL 还支持类似 HINT 的语法(我看了下,Spark 也支持),来手动干预 JOIN 的 Plan: https://cwiki.apache.org/confluence/display/hive/languagemanual+joinoptimization
恶补一些查询的时候需要的 SQL
本来 Hive 和 SQL 标准应该尽量分开讲的,除非一些标准的 SQL,不应该在文章正文部分介绍,但是我又不想专门花一篇内容介绍高级 SQL, 所以干脆在这里说了
RANK 之类的,可以在序列中,额外提供一个 RANK 的数字,相当于在 SQL 中提供了一个 idx 的抽象:
1 | SELECT ID, rank() over (order by (GPA) desc) as s_rank |
这里没有指定输出排序顺序。还有一些能替代 rank 的函数,比如:
percent_rank: 排序中的比例cume_dist:累积分布row_number: 类似 rank, 作为排序的时候唯一的行号。ntile把结果分成对应的桶,来处理相关的逻辑
SQL 还提供了窗口函数和对应的功能。这个是可以向前滑动的,就是一个row可能被算进多个窗口:
1 | SELECT year, avg(num_credits) over (order by year rows 3 preceding) as avg_total_credits |
range over 可以提供窗口有关的靠谱功能
pivot做的时期相当于把SQL中的 enum 展开,从 table(a, b, c) 展开成 table(a, b, c_value1, c_value2 ...):
1 | SELECT * |
这里还有一些 rollup, cube 和 grouping sets 来表达一些混杂的 GROUP BY. 简单来说,这些不同于多列 GROUP BY (GROUP BY c1, c2), 他们相当于多列 GROUP BY 的 UNION。
rollup相当于前缀的 group by 和,rollup(a, b, c...)相当于UNION{(a, b, c..), ... (a, b), (a), ()}cube相当于所有按照顺序排列的子集 (CUBE(a,b,c) == GROUPING SETS((a,b,c), (a,b),(a,c),(b,c),(a),...()))grouping sets相当于手动列出这些集合
这些还可以和 COALESCE 连用
Hive 简单使用
知道了上面的内容之后,就可以写基本的 Hive SQL 了,Hive 的 EXPLAIN 有点难懂,会输出一大堆和 Stage 有关的东西:
- https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Explain
- https://cwiki.apache.org/confluence/display/Hive/Cost-based+optimization+in+Hive
- https://zhuanlan.zhihu.com/p/352076174
EXPLAIN 这里可能输出对应的 Stage,Hive 高版本还引入了 CBO。
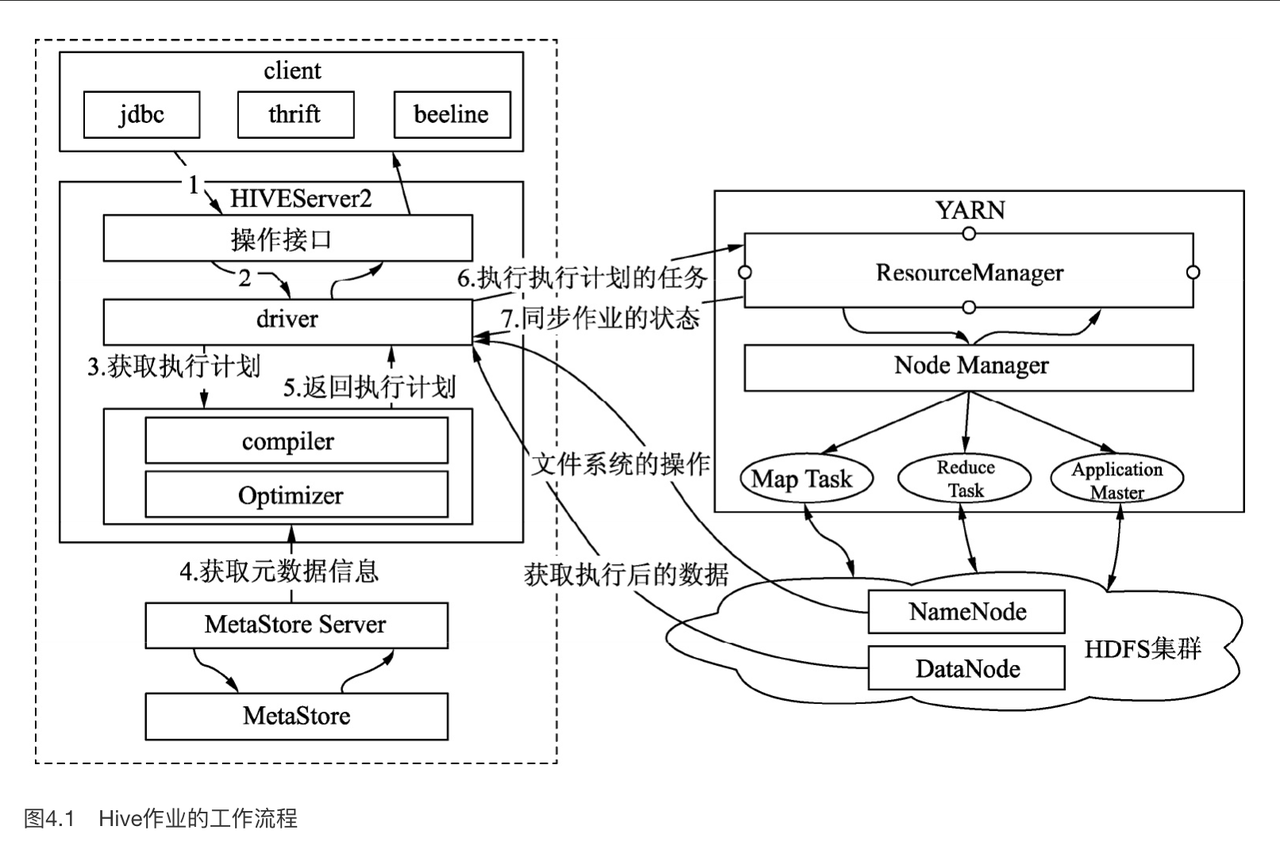
Hive 在执行的时候,在进行数据处理时先将计算发往数据所在的节点,将数据以键-值对作为输入,在本地处理后再以键-值对的形式发往远端的节点,这个过程通用叫法为Shuffle,远端的节点将接收的数据组织成键-值对的形式作为输入,处理后的数据,最终也以键-值对的形式输出。
这里非 LLAP 的模式可能还要通过 Yarn 拉起一个进程,然后选出一个管理器,来协调任务的执行
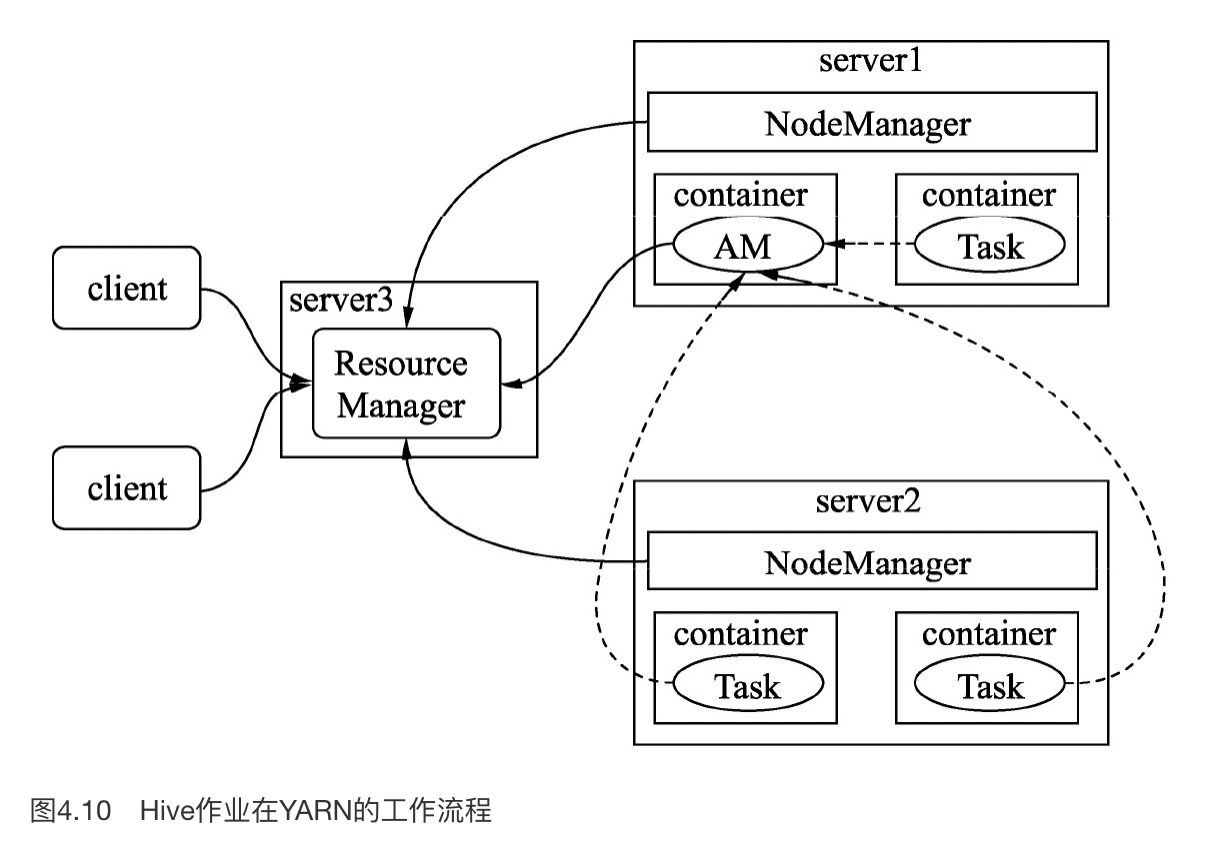
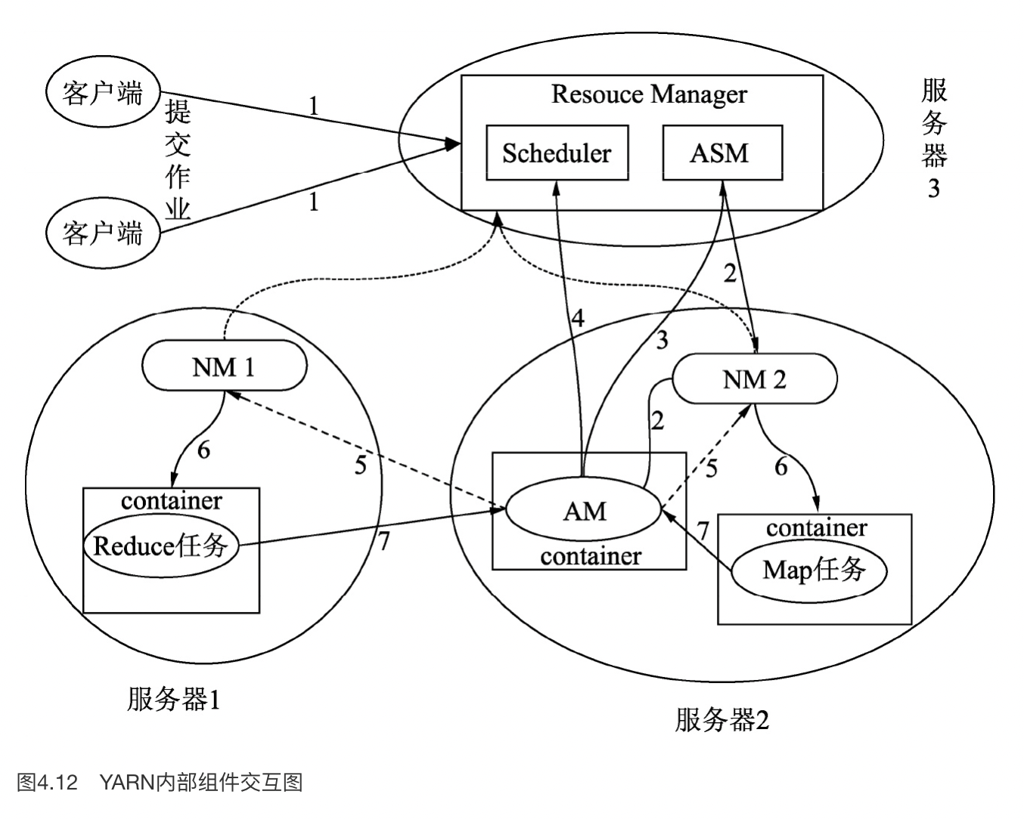
这里要关注一个问题,就是,在 Hive 1.x 执行问题按我们最早贴的那张图所述,这里 YARN 会有调度器和队列,然后进程都是拉起一大堆的,整个流程相对于 OLTP Database 都很重量级。YARN 按照 DRF 之类的方式进行调度。
数据在这里存储在 HDFS 上。
这里计算引擎还有对应的:
- MapReduce
- Tez
MapReduce 如下图所示
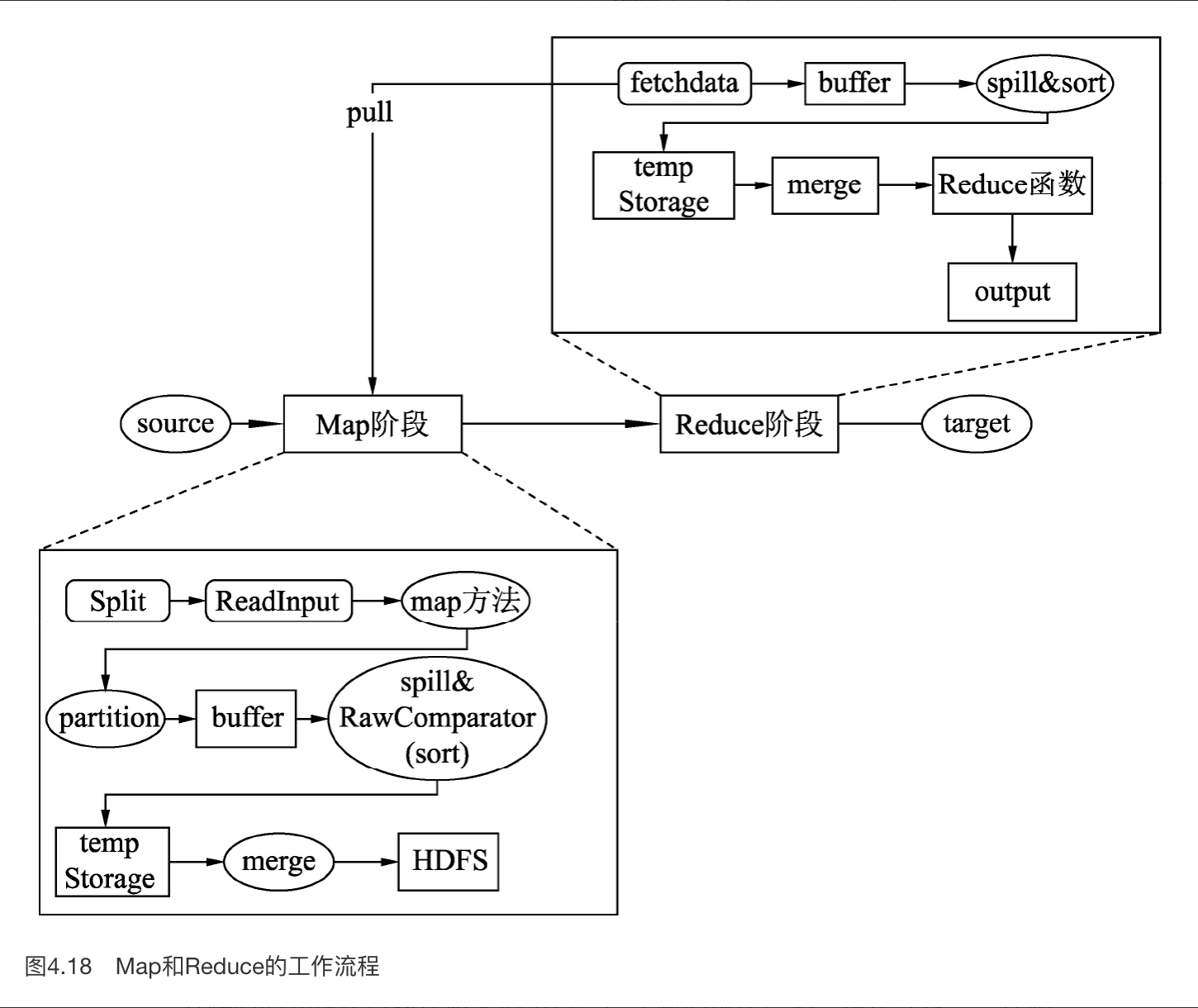
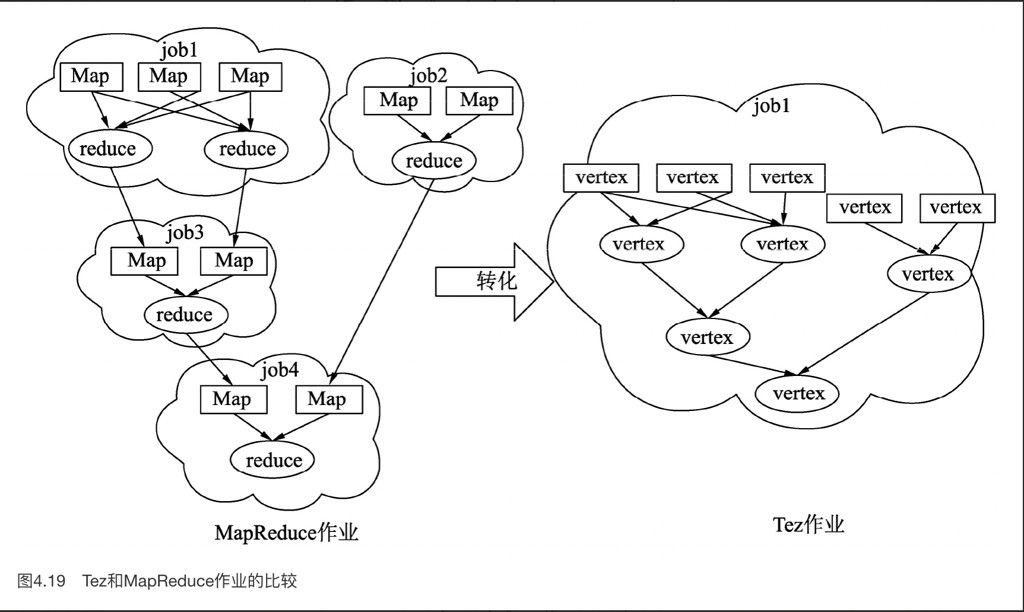
Hive 还有 LLAP 模式,这里相当于持久驻留进程,有点类似现代人心目中的 database (但话又说回来,某种意义上,非 LLAP 那套还挺云)
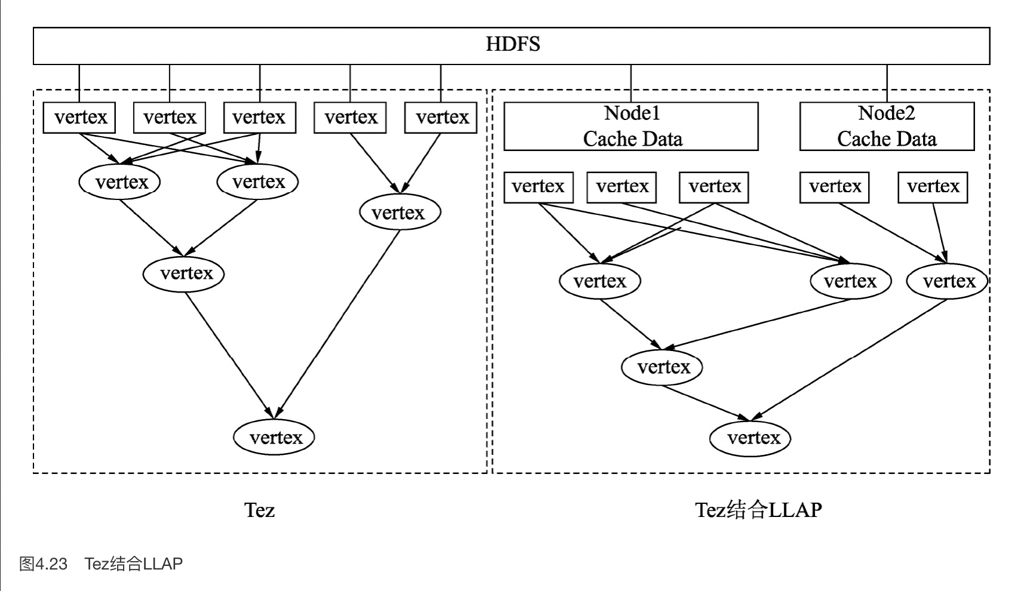
LLAP 模式中,可以:
- push 对应的数据,而不用必须 shuffle 到 HDFS 上
- 缓存数据
- …
此外,这里还支持计算调度到 Hive 上.
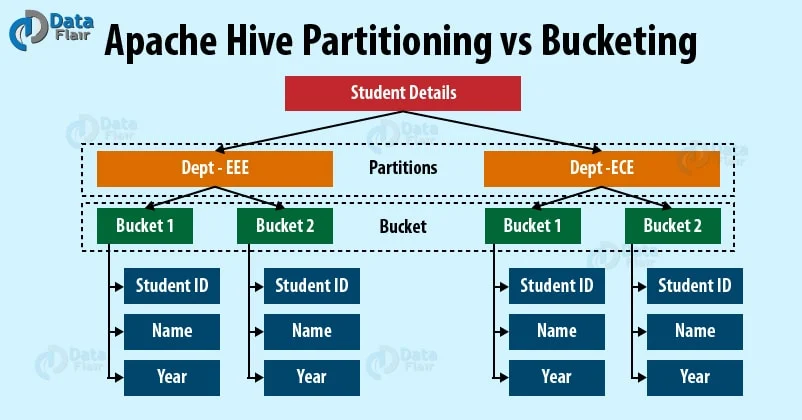
Partition & Bucket
Design - Apache Hive - Apache Software Foundation
- Table 是 HDFS 上的一个目录
- Partition 被设置成 HDFS 上的一个目录
- Bucket 作为一个文件来被存储
这就是 Hive 的表结构,Iceberg 优化了这个表结构。
References
- 面试|不可不知的十大Hive调优技巧最佳实践 - 大数据技术与数仓的文章 - 知乎 https://zhuanlan.zhihu.com/p/296254978
- SQL to Hive CheatSheet: https://hortonworks.com/wp-content/uploads/2016/05/Hortonworks.CheatSheet.SQLtoHive.pdf
- Hive性能调优实战
- Hive Wiki: https://cwiki.apache.org/confluence/display/Hive/
- HCatalog Wiki: https://cwiki.apache.org/confluence/display/Hive/HCatalog