Beyond Parquet: ORC and new file format
Apache Parquet 是一个功能强大的列存系统,不过也有一些同类的顶级项目,比如 Apache ORC。Google 自己发过一些 Capacitor 格式,作为 Dremel (BigQuery) 的文件格式。此外,Biswapesh Chattopadhyay 在一些新的论文中谈过 Youtube (2019) 和 Shared Foundations (CIDR’23) 一些设计的新的格式。
此外,还有人为 AI workload 做了一些特殊的格式,比如 IndexR. 包括还有历史悠久的 HDF5 和新鲜的 lance。
这些格式的需求各有不同,和我熟悉的 Parquet 相比有同有异。下面可以开始简单介绍
Apache ORC
Apache ORC 由 Hive 社区开发,如果你听过 RC 或者 RCFile 的话,会发现 ORC 这个名字有点熟悉,其实 ORC 前面那个 O 是 Optimized 的概念。Apache ORC 自认为可以:
- typed, self-describe
- 挑选合适的 encoding 方式
- 提供 Index
- 切分 10000 rows,然后 Predicate Pushdown
- 支持 ComplexType: Map, Union, Struct, List
Apache ORC 有三个版本:
- v0: Hive 旧版本使用
- V1: Hive1.0 和 0.12 之后使用
- V2: 不知道啥状态,好像每次看都是 TODO,虽然内容挺多的
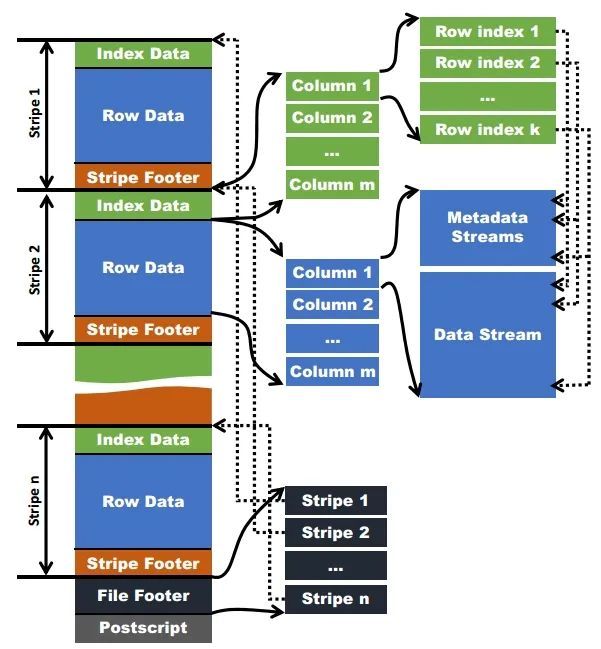
Apache ORC 格式如下图,有一些相似的概念:
- File Tail: 类似 Parquet 的 Footer 和 FileMetaData,在文件的尾部
- File Tail 包含 encrypted statistics, stripe metadata, Footer , file footer, postscript
- PostScript: 文件本身元信息,包括版本,Footer 长度,写者(很奇怪的是竟然有文件压缩方式)
- File Footer 类似 Parquet Footer,是一个 protobuf,内容如下:https://github.com/apache/orc/blob/main/proto/orc_proto.proto#L354
- 包含文件类型,整个文件的 statistics,文件 header,所有 Stripe 的信息
- Stripe 信息包含 Stripe 的起始地,index 长度,Row Data 长度,Stripe Footer 长度,行数
- Type 包含文件类型,整个文件有相同的类型。
- ColumnStatistics 包含各列的 min/max/hasNull
- user metadata: 塞入 key-value
- Encryption 相关的信息,不太懂加密,不写了
- Index: Parquet 有 BloomFilter 和没有实现任何 Index 的 Index Page (笑),ORC 有 Index Data
- Stripe: 对应 Parquet 的 RowGroup,由 Index Data + Row Data + Stripe Footer 构成。Row 不会跨 Stripe。
- Stripe 通常比较大 (~200MB),可以当作并发的单位
- Stripe 数据被存储在相邻的多个 Stream 中。列的数据氛围 Present Stream 和 Data Stream,Present 存放类似 null 的信息,Stream 有自己的 Kind, length。我们之后再来介绍它是如何表示 Complex Type 的。Present Stream 是靠压缩和 Encoding 来减少空间开销的
- 此外,索引、Stats之类的内容也被统一到了 Stream 中,由 Stream 表示
Orc 的 Compression 到处都是,它除了 Postscript,各段都会用 Postscript 指定的 compression 来编码,此外,这里会有一些 is_compression flag, Parquet 的 Page V1 是没有这个东西的,Page V2 才有。压缩效果不好的时候,可以通过这个 flag 来取消压缩。
在数据层,Orc 针对不同的类型支持了不同的 Encoding 方式,其实我感觉类似 Parquet 了。Present 强调用 Boolean RLE 编码。ORC 支持了:
- RLE
- Dictionary
这样的编码方式,具体而言,RLE 类似 Parquet 的 RLE,可能也会有 delta 之类的逻辑。Dict 编码会分成多条 Stream 来写。此外,ORC 还有 SECONDARY Stream,用来表示一些异构的值。简单来说:
- Orc 把列拆成了多条 Stream
- 优化好了 Stream 的对各种类型的简单编码方式
- 用这种简单编码 + 多条流表示类型
编码方式我就不介绍了,之后专门开个专题啃算了,感觉放这不太好。
对于 Complex 类型的表示,简单来说如下:
- Struct 只记录 Struct 本身的 PRESENT
- List = Present Stream + Length Stream
- Map = Map 等价于一种很奇怪的 List 和 List 表现一样,但后面有一组 Key 一组 Value
- Union 分成 PRESENT + Tag,后面接不同种类的 Stream
Statistics & Index
书接上回,Orc 的 format 支持了一大把不同的 Statistics. Parquet 的 Statistics 靠 bytes 来怼通用性,Orc 则是定义了一堆 adhoc 的东西,但是这并不要紧…
1 | message ColumnStatistics { |
我们的关键是,Statistics 可能出现在什么地方?
1 | // StripeStatistics (1 per a stripe), which each contain the |
你会发现,这里 Statistics 都是 Stripe 级别的。那么有没有更细粒度的 Statistics 呢?有,Row Group Index。
这里的 RowGroup 和 Parquet 的 Row Group 是不同的概念,类似 Parquet 中的 Page Statistics,不过有一些 trickey 的 RLE 细节:
1 | message RowIndexEntry { |
To record positions, each stream needs a sequence of numbers. For uncompressed streams, the position is the byte offset of the RLE run’s start location followed by the number of values that need to be consumed from the run. In compressed streams, the first number is the start of the compression chunk in the stream, followed by the number of decompressed bytes that need to be consumed, and finally the number of values consumed in the RLE.
这个地方就是 hack 到 RLE format 内部了。
ACID?
ORC 是 Hive 的亲儿子,在 format 标注上,它写了一些 Delta。这个感觉翻翻 iceberg 就行了.
Capacitor in Dremel
Capacitor 是 Parquet 的野爹,之所以说不是亲爹…Google 啥时候成过亲爹?Parquet 是 Twitter 和 LinkedIn 一起实际开发的,然后 15 年成了顶级项目,G+ 就喜欢憋大招的。
Google 这家伙贼喜欢藏大招,但是这里透露的材料还是不错的:
- 参考 Storing and Querying Tree-Structured Records in Dremel: https://research.google/pubs/pub43119/ 做谓词下推和 encoding + query exec。
- 采样数据,存储到 Meta 中,帮助提供了一套 Reordering Record 的方式。这里可以参见 Arxiv: https://arxiv.org/abs/1207.2189
在这里,我感觉这里不是单纯的格式了,而是一套自上而下的 Stats/Reorder + Format + Query Exec 融合的系统了。Query Exec 的地方我感觉我可以借鉴一下,但是 Stats + Reorder 我感觉我就不会搞了 Orz。
HTAP/HSAP Design
在 AP 中,数据经常是下推 Filter,然后扫大量数据。HTAP / HSAP 这种场景,会混杂 Point Lookup 和 Range Filter。对于 Point Lookup 来说,在压缩的 Group 中感觉效果是不太好的,因为这里有个问题是,可能需要走一遍 解压 + Decoding。
HTAP / HSAP 的场景,在这方面能够选出比较好的格式,需要有 Skipable 的 format,快速找到对应的列。
SingleStore 的做法在博客中有提到:https://www.singlestore.com/blog/winter-2022-universal-storage-part-5/ . 简单说是靠索引 + Encoding Skip 来实现,RLE / LZ4 都是有类似 RLE 的性质的,因为有 RLE 的性质,所以可以在有 Secondary Index to RowId 的情况下,做一些快速的 Skipping。
在 Procella: Unifying serving and analytical data at YouTube 这篇论文中,作者描述了 HSAP 中的格式 Artus,系统用这个格式来代替 Capacitor。这个格式也是给相似的逻辑设定的,但是相对于 S2DB 这种靠 Secondary Index 的,它这里还是会做一些(主动的)搜索的:
- (类似 S2DB),避免用通用的 compression,倾向于 Seekable format
- Multi-pass adaptive encoding: 先采集 ndv/min-max/sorting 之类的信息,再 adaptive 选择编码方式。Artus 提供了一套 encoding data 的 evaluation: Dict, Index, RLE, Delta 这些方式,同时,格式提供了一个 Score,能根据 (size, speed) 比较好评估这些格式的代价,来做 eval
- 采用 Binary Search able 的编码方式,允许用户以 $O(logN)$ 的 Complexity 去搜索
- $O(1)$ 的 Seek to RowId。这个在等宽 bitpacking 上没啥问题,但是别的 RLE 之类的,需要准备一些稀疏索引(Skip Block),这里 Block Size 通常是 32/128,来保证这个很小(Parquet C++ 现在 是很傻逼的 32 * 4)
- $O(logN + K)$ 的 Primary Key Searching
- 用 ORC 那种方式来存。我感觉这种格式在 HTAP Nested Search 上有一些优势?毕竟 Parquet 那种 format row-id 对一些东西其实还是要反解 rep/def 的。
- 暴露 Dictionary Index 和 RLE 给引擎,方便 Pushdown
- 尝试暴露很多元信息,然后按照 pk 切分文件,保证(粗粒度的)过滤性
- 支持 inverted index (S2DB 也走了这条路)
感觉 HTAP 的场景上述还是要支持的。
AI, The Old one and The new one
在 AI 领域,有 HDF5 格式之类的老东西,还有新的很多存储系统类似 Feature Store,会存一些稀疏的大宽表,比如下面论文的描述:
For example, it is increasingly common for ML tables to outgrow analytical tables by up to an order of magnitude. ML tables are also typically much wider, and tend to have tens of thousands of features usually stored as large maps.
这个领域可以简单当成可能有稀疏的大宽表,有一些随机访问,但是又是列存?在 这里:
- Shared Foundations 提出了一些元数据优化,因为 Orc / Parquet 列元数据都很大了,但是没提自己是怎么做的
- HDF5 简单的将数据集打包
- lance 是一个新的格式,类似 ORC,坦白的说,它在 PPT 里面写的东西都是垃圾,但是看到它支持了一些 ad-hoc 的 kmeans 之类的东西,还是挺有意思的。
References
Parquet / Capacitor
- InfluxDB-IOx 的 Parquet 使用 https://www.influxdata.com/blog/querying-parquet-millisecond-latency/
- Dremel: Interactive Analysis of Web-Scale Datasets: https://research.google/pubs/pub36632/
- Storing and Querying Tree-Structured Records in Dremel: https://research.google/pubs/pub43119/
- https://cloud.google.com/blog/products/bigquery/inside-capacitor-bigquerys-next-generation-columnar-storage-format
- 值得一提的是,这个文章的老板已经去 firebolt 当老板了
特征平台(Feature Store):序论 - 曾中铭的文章 - 知乎 https://zhuanlan.zhihu.com/p/406897374
Guide to File Formats for Machine Learning: Columnar, Training, Inferencing, and the Feature Store https://towardsdatascience.com/guide-to-file-formats-for-machine-learning-columnar-training-inferencing-and-the-feature-store-2e0c3d18d4f9