Parallel and Distributed Query Processing
这一节对应的是 Database System Concept 的分布式查询执行部分。这一部分可能本身描述的内容是分布式执行(也可以联系到一个现在很流行的词:MPP),但同时可能涉及一些非分布式执行的内容,包括:
- 在单机系统上,也能用 exchange 等算子做一些并行化。特别是,如果你按照 NUMA / Core 切分负载,就可以发现这些部分的事情也是一种分布式执行,当然 bus 可能比网络通信靠谱很多
- 生成 Plan 方面,本身 Plan 就很难生成了,然后又搞这么一套,就更难了
教科书上这节写的相当相当细,甚至包括一些 fdw 和数据湖的内容。虽然我本人不是很懂分布式查询处理,但是这块内容确实讲的很好。
分布式数据库的架构
其实网络还是个挺复杂的东西的,但是目前大家都很能抽象,实际上目前很多地方部署的网络都类似下面的 (e):
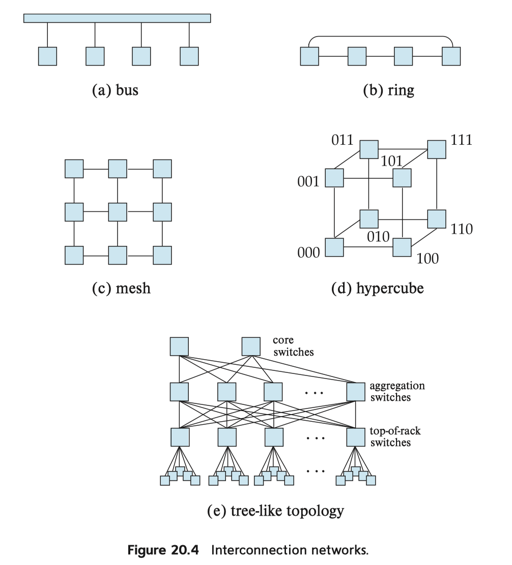
当然,随着硬件发展,实际上大家也会有一些其他方案,比如构建 RDMA 网络。
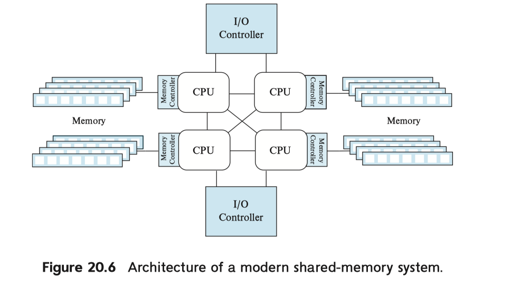
对于单机而言,博客(https://blog.mwish.me/2022/05/04/perfbook-notes-hardware/)提到了其中的访问效率,总之访问临近内存 bandwidth 是访问远端的数倍,速度也快了很多:
最后是一些共享 XX 的架构,这图既可以是单机房的,也可以是集群概念上的(比如我们经常说 ClickHouse/TiDB 是 Shared Nothing,而 snowflake/Aurora 是 Shared Storage):
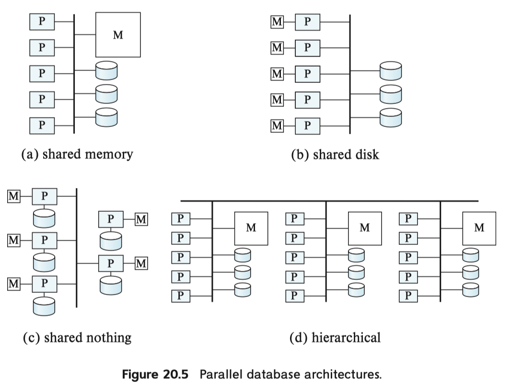
关于并行执行查询,经典的例子是 interquery parallelism 和 intraquery parallelism。这两种操作是互补的。前者比如对 Sort、Join 等操作做并行化,后者例如 Pipeline Execution 的时候,并行处理不同的 Pipeline。并行查询通常和架构相关,这里以 shared nothing 架构为例子做讨论
Sort/Join 等操作的并行执行
并行排序
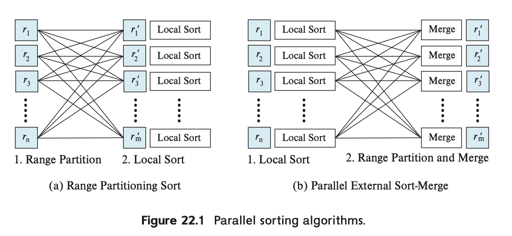
方案 (1) 是 先做 range partition, 然后再 Local Sort;方案 2 是先 Local Sort,然后再在各个节点串行 Merge。
对于方案 1,这里我们显然会联想到数据的 Skew 上,对于 (a),可以用虚拟节点等方式,把数据切碎,当然这个可能引入别的网络通信流程。对于方案 2,实际上,本地排序完后,在走 (2) 可能会变得很奇怪,这里可能会有 execution skew,即在每个节点接收完后,才能处理到下一个节点。这里也有改善成并行处理的方式:这里可能需要提前对数据范围分区,然后按照数据应该被分区到哪 并行 + Chunk 发送。
观察到,如果数据在每个地方已经排序好,或者是范围分片的话,相当于很多东西已经执行好了,这还是挺爽的。
并行 Join
我们可以先回顾一下单机 Join 的执行方式:https://blog.mwish.me/2021/02/08/Notes-on-Query-Execution/#Join
JOIN 有很多形式,一些简单的形式中,比如内连接 + 等值连接,可以使用类似单机 Hash Join 的方式。当然,这里分片可以按照 Range/Hash 任意一种方式分片。Hash Join 的很多优化这里也能用上,比如部分缓存在内存中。
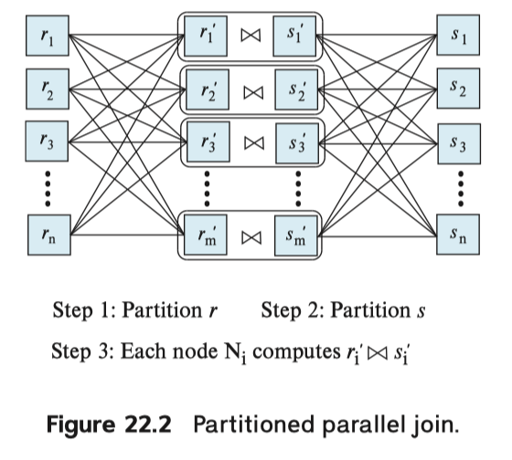
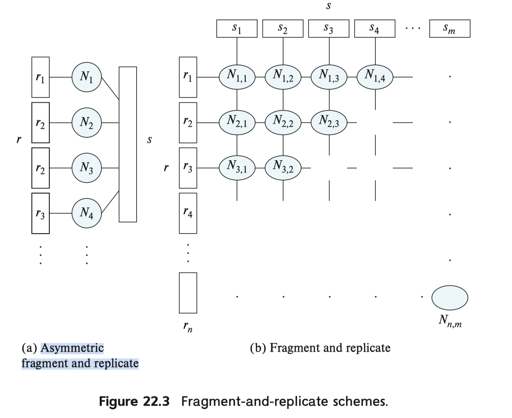
对于一些连接条件非等值的,可以采用 broadcast-join 的方式:将某个关系分区,并且将另一个关系(尽量要小)复制到所有的节点上,这种方式被称为 Asymmetric fragment and replicate。还有更狠的方式,就是两边全部拆了,然后全部拷贝:关系 s, r 都被拆成 m, n 份,分配到 $m * n$ 个节点上,产生 Join。 Fragment and replicate 方式更普适一些。而对于 skew,可以用类似虚拟节点 + work steal 的方式处理或者拆分。
对于其他操作来说,执行方式如下:
- Selection 中,如果有对查询的属性有分区,那么给固定的分区发送查询。如果没有分区,那么需要所有的节点并行走查询
- duplicate elimination 中,可以借助排序 + 去重执行
- 对于 Projection,可以按照是否 dedup 来分类,如果去重,那么可能走 2;否则可以直接推下去
- Aggregation: 这里比如说 sum/count/avg 可以分区,然后单机返回对应的 sum/count/(sum, count),然后对每个机器返回的综合处理
实际上,这里还可以考虑到 Map-Reduce 的模型:
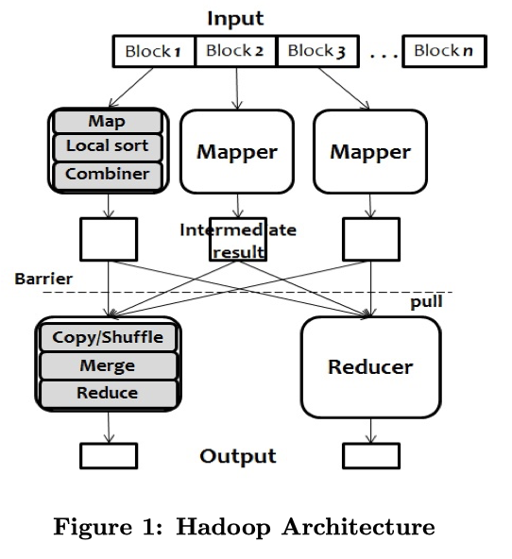
- Map 可以视为某种类型的 Projection 算子
- Reduce 可以视为一种用户定义的 Agg 算子
- Combine 类似一个 pre-aggregate,相当于部分 agg 的操作
- Shuffle 定义打到 Reduce 上的分片规则
- 根据工作进展动态调度
- BSP 模型,执行完 Map 才能执行 Reduce
实际上,Map-Reduce 还有 Map-side join 和 Reduce-side join:
- Map-side join 会在 map 阶段产生不同的 join-key,这样能够在 Reduce 之前就划分到一起
- Broadcast join 也是一种 map-side join,小关系会被 Map 阶段 broadcast 到所有地方
- Reduce-side join: Each mapper tags each row of two relations to identify which relation the row come from. After that, rows of which keys have the same key value are copied to the same reducer during shuffling.
关于 Map-Reduce,一篇比较好的材料是 KAIST 的 Parallel Data Processing with MapReduce: A Survey
Operator 的并行执行
首先,Pipeline + Push 的模型,相对 Pull 的模型,实际上是很好并行的。各个阶段都是能并行的,一个很明显的地方是,一些非 blocking operator,可以运行生产者和消费者并行。
此外,不关联的 Operator 是可以并行完成的。
最后我们可以引入著名的 Exchange 算子。这个算子最早来源于 Volcano 模型,它对数据进行某种程度的分区,然后按照这种分区来执行:
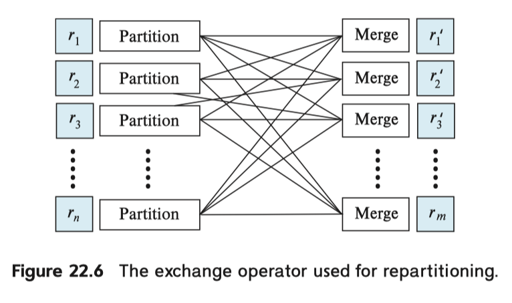
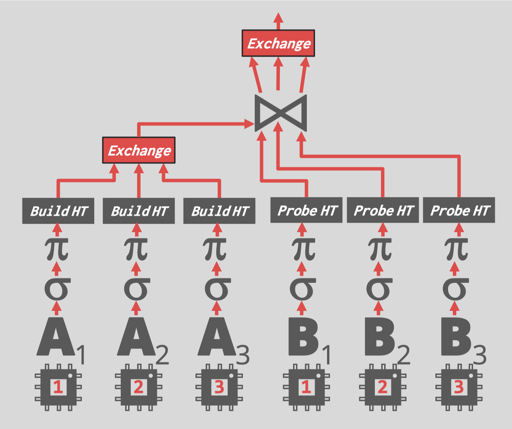
Exchange 算子相当于手动的分区 + 归并,来做数据上的并行。下图为一个分布式执行的 sample:
上面的内容表示了单部分的 Pipeline 和 Pipeline 之间的依赖关系。
分布式查询执行还得考虑一些别的东西,比如故障,这里有两种可以参考的方案:
- Map-Reduce 那种 BSP 的方案
- Spark 的 RDD 方案
共享内存系统的查询处理
这个类似在单机的 NUMA 系统上并行处理查询。之前的内容也是能用上的,但是有一些比较微妙的不同:
- 对于 broadcast join,小表数据可能可以放在共享内存中,用更巧妙的方式共享(不过估摸着也得考虑 cache 什么的,感觉实际区别不大)
- Work-steal 会变得简单很多,尽管多核系统访问别的地方数据也有惩罚,但是会比 shard nothing 系统小很多很多。可以用这种方式避免 skew
- Hash Join 既可以用 shared nothing 的方式处理、也可以让关系 Hash Join 索引表小一些,然后并行 Build -> 并行 Probe (类似 Morsel 调度论文提到的)
最合适的算法一般都是 NUMA-Aware 的,具体可以参考 Morsel 或者一些查询执行相关的论文。
查询优化和代价
这里相对于之前我们介绍的单机 Planner,要考虑的东西更多了:
- 怎么对 Operator 进行并行化:包括使用什么算法、怎么分区、怎么插入 Exchange 算子
- 如何对计划进行调度,包括:
- Operator 使用多少节点
- 将什么计算 Pipeline 化
- 分辨串行/并行的执行
书上举了个有点像 Interesting order 的例子,来说明分布式 Plan 的复杂性:
1 | r JOIN s ON r.A = s.A AND r.B = s.B |
对于上述内容而言,把 r 和 s 按照 A , B, (A, B) 分区中,(A, B) 显然是最合适的,但是如果查询如:
1 | SELECT SUM(s.C) from (r JOIN s ON r.A = s.A AND r.B = s.B) GROUP BY s.A; |
那么,如果按照 (A, B) 分区,这里可能又要按照 A 来做一次聚合,可能按照 A 分区代价又是最小的。
在并行模型中,还有一些关于代价的问题,在 RDBMS 中,我们以之前博客举的例子为例:https://blog.mwish.me/2021/11/05/An-Overview-of-Query-Optimization-in-Relational-Systems/#Statistics-And-Cost-Estimation
这里的 Cost 就是资源消耗的 cost,即 IO Cost + CPU cost + memory + bandwidth…
你可能觉得很自然,但是实际上分布式系统里,两个 Plan 「资源消耗」相同,但是由于并行能力,可能执行时间不一样,这里还要考虑「response-time cost model」:假设 p1, p2 部分能并行,这部分代价可能就是 $max(p1, p2)$ ,它要考虑在多个节点进行运算的启动成本(start-up cost)和 skew。
最后,对于相关的 Plan 生成,因为这里 Card 又大了不少,所以会非常麻烦。优化器可能会用启发式的方法:生成最佳的单机执行计划,然后分布式化。这里可以参考 CockroachDB 的文档:https://github.com/cockroachdb/cockroach/blob/master/docs/RFCS/20160421_distributed_sql.md