Delta Lake & Lakehouse
我的友人 xzt 老师曾经对我说过一个笑话,大概长这样:
高情商:”我们有基于数据湖的数据管理系统”
低情商:”你要在 HDFS 上手写 MapReduce 任务”
我一直觉得这是个没毛病的说法,所以对最近创业的各种东西感觉比较困惑。尤其是之前上网搜了一波数据湖是什么,感觉他们讲的都是一些哲学概念而不是技术。今天看了看 Databricks 的 Delta Lake 和 Lakehouse,想了想,终于知道数据湖这个批词指的是什么东西了。
Delta Lake 提供了一个类似表格的服务,在 S3 上提供了 ACID 语义。它存储类似 Parquet 这样支持 nested 的格式,并且给每列数据一些描述元信息。同时,它本身的 Schema 应该是柔性的,对比到行存类似 Protobuf、Avro 这种软的格式。对前台写入而言,Delta Lake 的上述内容提供了 ACID 的写入,这点对用户还是比较重要的,这里可以对比 Hive,用户瞎几把改了一堆数据然后任务挂了,你这堆东西你看你留不留?Delta Lake 很好的解决了这个问题。Delta Lake 提供了在 OSS 上实现 ACID 语义的逻辑,并支持了 Streaming 等接口(但不太是给 Streaming 原生设计的,感觉写入性能还是受限的)。
对数据分析师或者各种用户而言,比较重要的是 Optimize 操作。这个有点类似 LSM 的 Compaction,会把零散的 Parquet 文件组织成便于分析的 Parquet 文件,这个过程似乎被称作 Clustering : 把你写的那些乱七八糟的 Schema 组织成一些比较结构化的、便于 AP 查询执行的 Schema,然后这些文件对于每列会有一些 min-max 描索引信息,帮助上层查询跳过。这部分在 Delta Lake 论文有简短描述。
对于上层系统而言,Lakehouse 对 Delta Lake 提供了元数据层、缓存和一些端到端的 API,做到了嗯舔用户。
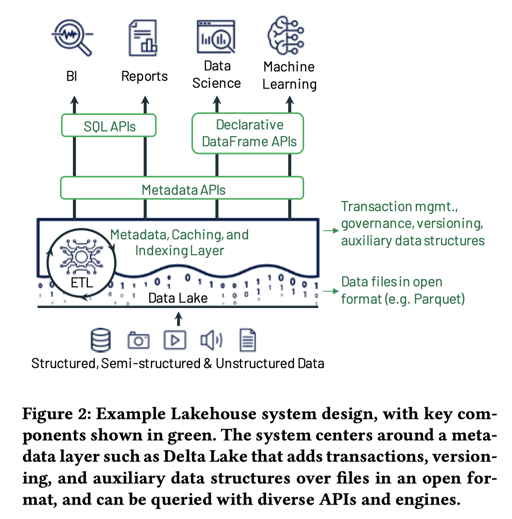
回过头来说,如果说 snowflake 是发现了云上 “不跑的机器可以不收费” + “AP Workload 没有那么延时敏感” + “算不来的东西多调机器就行了”,那么 Delta Lake + Lakehouse 则是 “云上低性能 Batch ACID” + “Compaction 阶段调整格式”。关于 Cache 其实和 Snowflake 差不多。
本来想写点什么的,但是感觉知道它在做什么就索然无味了…所以就发个这么短的了。
References
- 深度对比delta、iceberg和hudi三大开源数据湖方案: https://zhuanlan.zhihu.com/p/110748218
- 通过数据组织加速大规模数据分析: https://zhuanlan.zhihu.com/p/354334895
- 【论文分享】从Lakehouse看Databricks对下一代数据湖架构的理解 - ShallowMind的文章 - 知乎 https://zhuanlan.zhihu.com/p/462094560
- 数据湖竟然能和数据仓库打通?如何评价阿里云推出的湖仓一体解决方案? - 贾扬清的回答 - 知乎 https://www.zhihu.com/question/421711474/answer/1480957849