ARIES/IM
<ARIES/IM: An Efficient Management Method and High Concurrency index Using Write-Ahead Logging> 描述了 ARIES 是如何维护索引相关的 Latch 和 Lock 的。在 B+Tree 上可能会涉及 IO 、SMO 等情况,在这种情况下,对一个树的查询要保证高性能、并发安全。
ARIES/IM 在索引和 Lock 上的想法是:
- Data Lock, 只在 Data 上上锁,Index 上不上锁
- 为了并发,尽量少的获取要等待到 Commit 阶段的 Locking
- 允许查找/删除/插入和 SMO 一起执行
ARIES/IM 本身使用 ARIES 做恢复,会对 Page 进行 Redo 和 Undo,ARIES/IM 保证这些都是 Page 级别上执行的。
2/3 都比较常见,(1) 需要额外解释一下,我们从 hedengcheng 的 slide 里面引一张 InnoDB 锁的图:
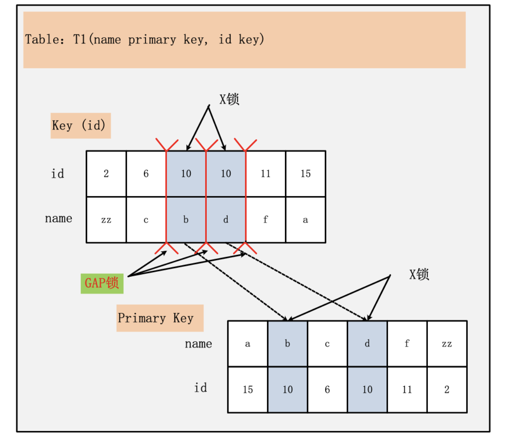
这里的锁是 Index + Data(Primary Key), 然后查询使用的 Index 也需要上锁。ARIES/IM 这里只需要给 Primary Key 或者 Heap Tuple 上锁。
ARIES/IM 论文应该使用的是 Heap Tuple 模型。在论文中,索引的叶子结点包含 <key-value, recordID>, 模型中,叶子结点被双向链接,非叶子结点有指向下层的指针和对应的 high key。非叶子结点的 High Key 一定比下层的 High Key 大。
ARIES/IM 提供了下列的索引原语:
Fetch(Key or Partial-key, starting-condition),starting-condition包含Eq、GT和GTE,然后拿到整个 KeyFetchNext(stopping-condition): 对Fetch的结果,然拿到下一个 keyInsert(key-value, RID): 插入(key-value, RID)对. 对于unique的索引来说,这里需要查找到这个key是否重复,儿对于nonunique index,(key-value, RID)对需要查找是否重复Delete(key)删key(这个接口我觉得怪怪的,是不是还得加个RID?)
那么,这套东西考虑并发和 Recover,可能有下列的问题:
- 对 Index 需要记录什么样的日志,来保证完整(不丢数据)、高性能恢复
- SMO 在发生的时候崩溃了,恢复的时候保证没有问题
- 如何提升 Page 上访问的并发度
- 假如事务在 Rollback 的时候,已经完成了某个 SMO,它可以不用 UNDO 这个 SMO
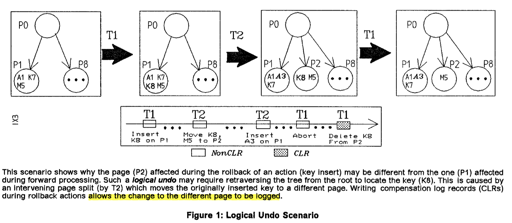
- 如 Figure1,如何保证 SMO 发生的时候,Page 被移动到了别的地方,这个时候,如果要 rollback T1,这种基于 Page 的 Undo 可能会啥都删不掉,需要从上层来做一个 Logical Undo。需要能够阻止或者检测出这种结果
- (5) 讲述的是插入 - SMO - abort 的情况,同样这里还有 删除 - SMO - abort 的情况,也要能够正确恢复
- 怎么防止 Rollback 的时候,事务出现 Deadlock
- 怎么设计不同级别的锁
- RR 的隔离级别下,怎么做谓词锁
- 怎么保证一个 Unique Index 中,A 删掉了一个 Key,B 需要插入同一个 Key,而 A 可能 Abort 的情况
- SMO 发生的同时,Tree Traversal 也能正确执行
关于 ARIES Recover 可以参考我之前的 Blog: https://blog.mwish.me/2021/08/07/Database-Recover-System/
Concurrency Control
这部分的 Concurrency Control 不涉及 Recover. 有一部分 Del_Bit 和 Recover 有关,可以不用理解。
这里贴一下 Data-Only Lock 相关的上锁规则:

细心的你可能发现了,这里还有个 index-specific locking,ARIES/IM 认为 index-specific locking 可能可以提升并发能力,但是会增加实现的复杂性和维护锁的代价。
在支持 RR / 维护 Unique Index 的时候,在删除或者插入一个 key 的时候,需要对下一个 key 上锁,这种策略被称为 next-key locking. 在 Fetch 和 Fetch Next 的时候,若 Key 不存在,也要考虑这个问题。
Latching: Latching 维护了 Page 和 B+Tree 物理结构上的一致性。在 Index 访问的时候,不会 Grab 数据页的 Latch。获得 Latch 的顺序是下降获取的,这个流程要遵循 Latch Coupling:
- 先锁定根节点,从根节点下降
- 按照锁叶子结点 — 切换 — 下降 — 释放父节点锁的过程进行下降。中间全都是 S Latch,到根节点的时候,根据操作类型来决定是 S 还是 X
这里还有 SMO 对应的处理,当一个 Txn 执行 Split 的时候,别的事务要保证正确处理。ARIES/IM 会要求「向右分裂」,即把 higher key 移动到下一个节点。然后 Bottom-Up 的分裂,Bottom-Up 这个顺序和查找的时候下降的顺序是相反的,为了避免 Latch 的死锁,ARIES/IM 引入了 SM_Bit,然后在 SMO 的时候会做 SM_Bit 标记,随之释放锁 - 上升。而下降的时候会注意到 SM_Bit, 进行一些别的操作,等待 SMO 完成。
那「别的操作」 是什么呢?ARIES/IM 引入了一个 B+Tree 级别的 RWLatch: TreeLatch,供 SMO 同步使用,SMO 会 Grab X Latch on TreeLatch,然后下降的时候,如果注意到了 SM_Bit,这里需要放锁 -> Grab S Latch on TreeLatch,等待 SMO 完成. 然后如果某个节点拿到了 S Latch,这里它就可以清掉 SM_Bit 了,因为 SMO 已经完成了。这个 TreeLatch 同时也保证了写入的串行性。
上面的部分是算法的大意,下面这里要讲一讲具体怎么实现,值得一提的是,下面的部分有一个 Del_Bit,这个和 Recover 有关,先不用管,然后论文估摸着是假设 Page 全在内存中,没有考虑不在内存中的情况。
Fetch
1 | /* for simplicity, root = leaf case not specified here */ |
上面表现了一个 Descend 的流程,具体还有一个 Fetch 的流程:
1 | Find requested or next higher key(maybe on NextPage) |
这里 Lock 需要拿到了 Latch 再上, 保证正确性。而为了保证 next-key locking,甚至可能要捞右侧的 Page。在获取下一个页面的 Page 的时候,上一个页面的 Latch 不能被释放。
这里还有个特点就是捞 Page 的时候会记 Page_LSN,没被更新的话就该咋样咋样,Page 被更新了就要重来,检查一下发生什么事了。
conditional 应该是「没获取到就失败」,而「unconditional」是一直等待获取到。这里的 Lock 是 Commit Duration 的。如果拿到了最后都没有,应该要对一个最高 Key 的特殊 Maximum 记录上锁。
Fetch next
Fetch next流程首先定位一个key,然后记下 Page_LSN 和位置,然后不断顺序遍历符合范围查找要求的key,每次返回一个符合要求的key时都需要记录相应的page_lsn。下一次查找时需要比较page_lsn,若page_lsn变更,说明页被修改,此时需要再次走一次 Fetch,来重新定位。
Insert
如果 Leaf Page 有足够空间,这里会定位到相同或者比自己大的 key 上,然后 Grab X Lock,进行插入的 key 的 locking。上锁后,再进行 unique check。这个锁是 Commit Duration 的。
这里还要对 next-key 进行 X lock,来保证锁定。这个可能还会需要锁定下一页。这个 lock 是 instant 的,它只用来避免 RR 上出现 Phantom Data。
1 | IF SM_BIT | Del_Bit THEN: |
如果需要分裂,为了维护 B+Tree 结构,这个需要把邻居节点捞上来(维护双向链表),然后把涉及的 Page 全部弄到内存中,再 Grab X Lock,进行 SMO。这里我们只需要了解 SMO 会创建一个 sibling page,然后处理结构,标记 SM_Bit,层层向上。
Delete
Delete 会对 Next-Key 上 Commit Duration X Lock,用来防止之前问题 (10) 等场景。此外还有一些用于恢复的逻辑,比如删除边界值的时候,需要给整个 Tree 上锁;同时需要引入 Del_Bit。之后会在 Recovery 里面讨论这些个细节
这里实现的不一定是标准的 B+Tree,只有删空一个 Page 的时候,才会执行 DeletePage 的 SMO。
1 | IF SM_Bit == 1: |
SMO

SMO 重点是和 Insert/Delete 一起考虑并发。还有一些 Del_Bit 的 hacking。
讨论
为什么 Delete 要 Commit Duration;Insert 只要 Instant Duration 呢?实际上,没有提交的 Insert 对外部是一条可见记录,而 Delete 则是看不到了(记录直接没了)。所以插入的时候放个 <key, value, RID>记录在这,看看后面是不是有记录,然后嗯插就行,反正自己上面有把锁。删除的时候清掉 <Key, value, RID>,自己 RID 别人也锁不了了,就只能嗯锁下一个。
Recovery in ARIES/IM
论文之前的问题也提到了 Recovery,SMO 由 Delete/Insert 触发。如果 SMO 做完了,而事务 Abort 了,SMO 会照常推进下去,如图:
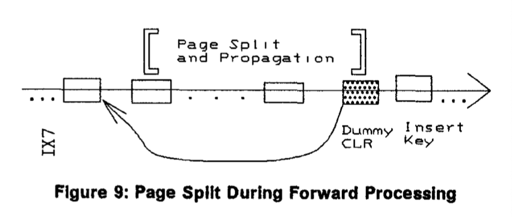
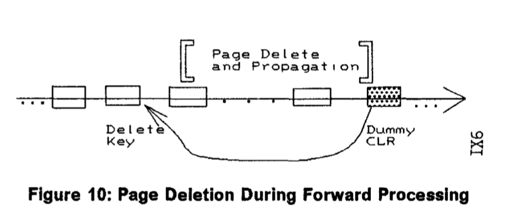
在 Rollback 的时候,Delete/Insert 可以被撤销,对于 Delete,Redo 的时候反正先 Delete 了,SMO,然后再对整个树插入;Insert 的时候,插入的记录再被滚掉。如果 SMO 没有写 Dummy CLR,那么 SMO 会被回滚。在 SMO 期间,操作需要对 TreeLatch 同步,所以对 Page 回滚是安全的。
当然,你会注意到,不是所有操作都能在这个流程中做到对 Page 回滚的。如 Figure 10,当这个事务失败但 SMO 成功的时候,Page 都没了,怎么回滚呢?这个时候,ARIES/IM 策略是 尽量对 Page 物理回滚,不行的话整个树下来做逻辑删除,具体而言,假设事务在 $t_1$ 时刻进行,$t_2$ 时刻 Undo,需要执行 Logical Undo 的规则是:
- Undo Delete 的时候,Page 没有足够空间进行插入,说明 t1-t2 期间,有一个事务占有了删除的空间
- Undo 的时候,key 不属于原来的 Page,说明 t1-t2 期间,有一个别的 SMO
- 不知道 Key 是否属于原来的 Page:在 Undo 的时候,可能插入了一堆相同的记录,导致不确定具体啥情况
- Undo Insert 可能导致原来的 Page 变空。这显然不科学,说明 t1-t2 之间有一个对边界 key 的删除。
在 Undo 阶段可能也有 SMO。一般的 Undo 的 CLR 是只有最终镜像的,但是 SMO 可能失败,所以 SMO 的 Undo 也需要完整的日志。
在执行阶段,Undo 的时候如果要 SMO 也需要 X TreeLatch,来串行处理。
对于一个 SMO,当持久化 Dummy CLR 日志的时候,才能释放 X TreeLatch (表示这次 SMO 已经完成,可以恢复)。
这里 ARIES/IM 还需要保证 Undo 是能够进行的,这个点有点奇怪,为什么 Undo 会不能进行呢?可以参考下图:
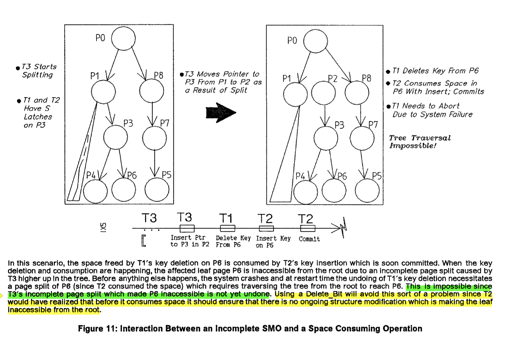
一个 SMO 可能导致 Delete 的 Undo 是不可进行的!这个未完成的 SMO 会导致对 Delete 的恢复无法从根节点找到。这个时候你可以发现 Del_Bit 和串行化 SMO 的妙处了。
我们回到需要执行 Logical Undo 的规则 和 Delete Insert 的代码,可以看到,TreeLatch 这里承担了一个很重要的同步点,来保证并发的安全性。当你需要删除、删边界 key、SMO 的时候,都要主动拿一下 Latch 来强制同步。
优化和其他协议
可以看到,上述一个复杂点是,删除的时候如果物理删除了,可能回滚的时候有额外的功夫。Graefe Goetz 提出过一个逻辑删除。即删除不实际从 Page 上抹除这条记录,而是一个标记删除,来解决问题。不过我不是很清楚这样删了之后,需要用什么条件来 GC 这些数据。
标记删除需要和 Purge 的流程联动起来,这里可能还会需要一些 mtr,比方说标记删除后,确定某个事务的 Garbage 记录可以被回收,那可以写个 mtr 把 Page 上的这个垃圾记录回收掉。感觉这个稍微有点类似 MVCC?
论文里没有提到根节点分裂的情况,但实际上这是一个比较复杂的 case,可能也需要 grab 一把锁来解决。
InnoDB 的 Btree 感觉相对没这么细,不过也可以看的出来为啥。感觉在那上面改并发类似一个不可能完成的任务了…
关于这些,可以看 alibaba 的数据库月报:
- http://mysql.taobao.org/monthly/2020/06/02/
- http://mysql.taobao.org/monthly/2020/05/02/
- http://mysql.taobao.org/monthly/2020/11/02/
- http://mysql.taobao.org/monthly/2021/12/04/
可以看到,MySQL 5.6 的 InnoDB 这里会有一个 Btree Latch,然后在下降的时候可能要 S Latch 它,然后下降,下降之后,根据有没有 SMO,来判定剩下来的操作是否要 Latch 整个树。同时,这里只有叶子结点上有 Latch,non-leaf page 是不会上锁的。
InnoDB 在 MySQL 8.0 引入了 SX Lock(类似 rwlatch?),也引入了 non-leaf page lock,不过仍然是比较粗粒度的锁。
Reference
- ARIES/IM: An Efficient Management Method and High Concurrency index Using Write-Ahead Logging
- 二手文章 ARIES/IM: http://mysql.taobao.org/monthly/2020/05/03/