谈谈格式
一个程序员的工作可能包括:服务器实现了 HTTP 或者 Rpc 协议,接受用户发送来的 JSON/文本/RPC Idl,然后用 JSON/文本/RPC idl,给一些其他服务发送请求,拿到想要拿到的东西。上述处理完之后,可能对数据库 CRUD,在 RDBMS 中,程序员可能定义了表,表中的一行有多个列。用户可能会更新某几行数据的某几列,然后把请求返回给用户。写完数据库后,可能会有 binlog 流/CDC 流,去异步的把你的写入导出到某个数据仓库里头,这里可能会把行组织成类似 Apache ORC 或者 Apache Parquet 的形式,便于快速做分析。
在这个流程中,用户可能和 JSON、Protobuf、数据库的行等东西打了交道,而计算机可能最终只知道 0和1,bit 和 byte。这里面隐藏了无数的编码:
- 接口请求/返回值的编码:可能是 JSON、Protobuf、Thrift、Avro 等格式。在这里,用户预期 debug 方便,能够对接口进行一定的修改、扩展。
- 数据库的行 Schema,本身可能要求读/写性能和存储空间的高效、节约,便于CPU 高效在内存访问行上的数据,这里还有一些小小的区分:
- Schema-on-read/Schemaless: 不一定要求系统存储同一个模式,可能同时存在多个版本的数据
- 某个行集合的数据,拥有相同的 Schema
- ORC / Parquet 的 Schema,和行的 Schema 相比,可能还会把列存在一起。
程序员可能每天或多或少要和它们打交道。这些数据格式需求是不一样的。尽管有一些学术上多维的区分,比如说:
- 数据是否有 Schema
- 是否支持 nested
- 存储的行列
- 是否支持 Streaming
- 是否 human-readable
- 是否是和某个语言绑定的(例如 Python pickle, Java Serialize 等,ddia 认为这些编码的兼容性不是很好,同时可能有些安全隐患、性能缺陷)
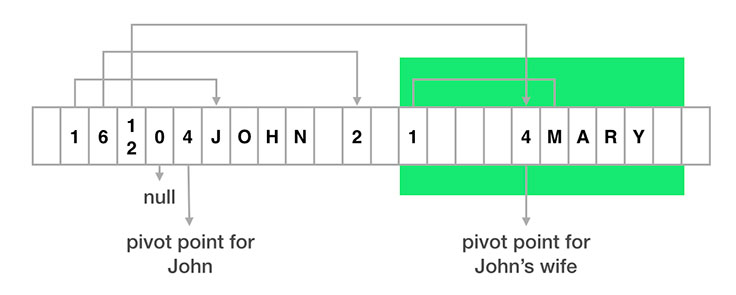
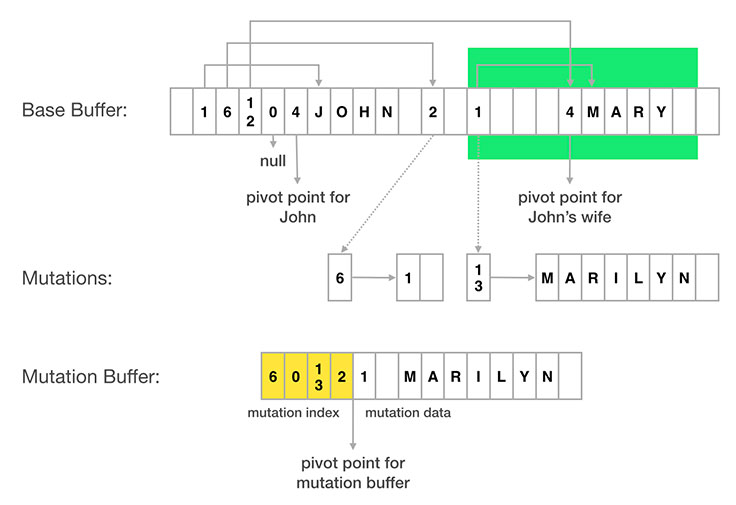
但我们这边还是松散的随便扯扯,而且尽量不讨论语言绑定的东西。下面有一张扯图,图一乐?我们这里也不会涉及消息边界等内容。
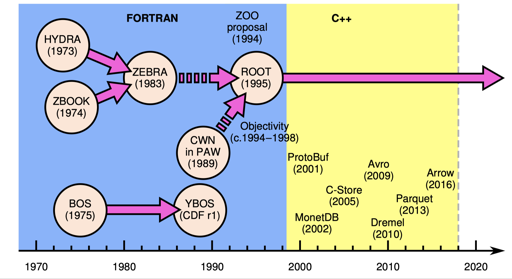
另外,本文只代表本人个人理解和一些记录。如有错误还烦请各位读者矫正。
接口的编码数据
JSON
一个常用的选项是 HTTP + REST + JSON. 按照分类,JSON 可以视作 弱schema + human-readable 的数据。这样的数据也包括 XML。JSON 被诟病的地方如下:
- 格式上性能不一定很好,包括本身空间大小较大
- 对二进制数据不一定有很好的支持
- …
上面这些内容让它可能会受到一定的诟病,但是对于接口而言,它有着开发方便、程序员可读、跨语言等诸多优点,此外,它的工具链相当齐全(当然,这也有 fast-JSON 等问题?)。JSON 已经支持了大规模的 web 系统,相信它还会起到很多的作用。
关于空间放大就不谈了,都 JSON 了,也别考虑这个了。
Thrift && Protocol Buffer: 常见的 rpc 消息格式
尽管 pb 有不同版本,thrift 也是不同格式,但是它们原理是类似的。可以看:https://thrift.apache.org/static/files/thrift-20070401.pdf
协议上,thrift 本身是二进制的协议,对于给定的格式描述文件,它能够生成出对应语言的 序列化/反序列化 代码。用于处理这样的格式。(当然,不同语言处理可能有一定的问题,比如 thrift-0.9.2 生成的 C++ 代码中,生成了 virtual dtor 和 copy ctor,但是没有生成 move ctor )。
- https://github.com/apache/thrift/blob/master/doc/specs/thrift-binary-protocol.md
- https://github.com/apache/thrift/blob/master/doc/specs/thrift-compact-protocol.md
Thrift 本身对于每个字段需要做一些定义,比如:
1 | enum TweetType { |
我们不讨论编码细节,它大致会将每个字段做编码,表示成:
1 | Binary protocol field header and field value: |
- 字段类型
- 字段 id
- 字段值
- Stop field
Compact 格式与上述类似,不过采取了更紧凑的格式,不影响我们前面介绍的逻辑:https://github.com/apache/thrift/blob/master/doc/specs/thrift-compact-protocol.md#struct-encoding
需要注意的是,这样的格式花了不少部分在处理兼容性上。可以当作这是字段 id 参与实现的。假设传来的字段没有某个字段 id,这里会在解析后的结果做对应的标记;如果传来的包含自己的 idl 没有定义的 field id,这里也会跳过去。通过这种方式,thrift 完成了一些扩展性的支持。
当然,这也衍生了一些骚操作。如果你的 thrift 结构有 10个字段,但你又的地方只关心两个字段,你可以写个只有对应两个字段的 idl,让它生成结构来解析。那问题来了,这个停止是什么情况呢?假设原本有 0-10 个字段,然后这个解析检测到 stop field 就会停止,所以不会有问题
那么,这个结构一些放大在什么地方呢?本身 字段类型、字段 id 会有一部分空间放大,然后变长字段存储也有部分放大。
thrift 和 pb 经常用于作为一些 Rpc 对应的格式,因为便于增和改,这使得它们在开发上有着一定的优势。同时,虽然它们本身不是 human-readable 的,但是 thrift 会生成一些转化成 DebugString 或者 JSON 的方式。
代码生成和效率
默认生成的 cpp 代码其实比较草台,对于 cpp 代码而言,可以指定生成模版代码、生成带 move 的代码、开启一些编译相关的优化来提升性能。
Avro
Avro 的编码模式可以见: https://avro.apache.org/docs/current/spec.html 。这里不讨论 Avro 的 JSON 模式。相对于 Pb/Thrift,Avro 的二进制格式不会携带 type 和 field id. 相对的,它应该标示出写入自己的应该是什么 Schema。
这里 Avro 的交互可能包含双方的 Schema 交换,因为读者需要知道写者的编码,例如:https://avro.apache.org/docs/current/spec.html#Handshake
如上所述,Avro 的空间少去了 字段类型、字段 id 的空间放大,是一个还算紧凑的格式,但本身它需要知道数据是什么版本的。当然,我们最好不需要每条 Avro 数据都带一个 JSON 的格式描述文件,这里可能有不同的方式,来使这个开销变得更小:
- 通过 Handshake 交换版本
- 有一个版本号
[0, 1, 2, 3]. 然后自己二进制数据带上这个版本号,让读者能够成功解析 - 对于一些大文件,可能可以在文件头带上 Avro 格式描述,然后后面存放同一个版本的写入内容。
Avro 可以用于 RPC,但笔者在生产中少有见到用 Avro 做交换格式的地方。似乎它的使用场景更多还是在存储数据的时候使用。如果有读者知道对应的场景不妨联系笔者。
总结
大部分 RPC 格式中,用户希望有一定的 Schema,同时也支持对结构进行一些变更。用户通过 Rpc 发送的信息通常不会很大,而且大部分时候也并不应该很大,例如 pb 在官方文档中表示,它不应该处理 Large Data Sets。如果你有数 kB 甚至数 MB 的数据,那么你可能要考虑一下一些其他的方式。毕竟,对这些 RPC 消息的解析一般包含连续或者不连续内存的 memcpy。
行格式
需求和大概的设计
在关系型数据库中,我们有行 (Row/Tuple) 和 列 (Column/Attribute) ,直观的描述如下所述:
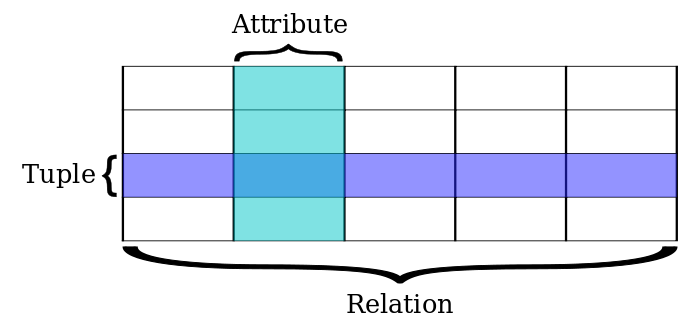
这样的格式本身是用户定义的,列可以是变长/定长的(行也显然可以)。我们忽略 BLOB 等对象。用户通常会有下列的请求:
1 | SELECT table.col1, table.col5 FROM table WHERE table.col3 < 100; |
我们不考虑索引等优化,也不考虑 Row 是以 k-v 还是 Page 的形式组织,仅从行的方面考虑,这里需要读到对应每个行的 col1 col5 和 col3 字段。
通常,RPC 协议要求的是对变更敏感,且能够完整解析。而行格式更多不会完全解析,而是要求能在内存中快速寻找到每行中用户指定的列。同时,行的大小会占用盘/内存的空间,故其大小也应受限制。
一般的数据库当中,会有 Catalog System。大部分情况下,可以认为,在某张表中,每行的 Schema 都是相同的。这给我们提供了很大的便利。当然,这里可能加一列之类的 DDL 执行的时候,系统需要做比较多的事情,来给原来的每行添加一列。之前也看到阿里的数据库团队对这点进行的优化: http://mysql.taobao.org/monthly/2020/03/01/
此外,这里还要关注某列数据为 null 的情况。这一点也会影响格式的实现。另外一个影响实现的内容是变长字段(甚至 nested 字段)的存储。
最后一点需要注意的是,我们刚才谈及 RPC 协议等,它们大部分都是非常通用的协议。但是对于行数据来说,它们通常和数据库系统别的地方实现有很强的相关度:
- 是否使用读时模式?
- 行是怎么被组织的?是被存储到 kv 中,还是被存储到 Page 中?
- 有没有什么特殊的记录和标记,例如行删除、事务标记等?
- 有没有什么 hidden column。
为了简化描述,我们将集中于 Tuple 和 Attribute 相关的内容,并忽略那些上层的部分(尽管它们对实现者或者某些用户来说可能更加重要)
PostgreSQL
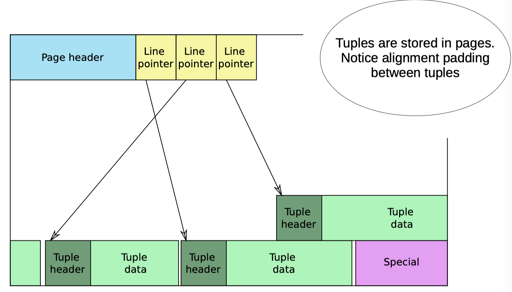
PG 的 Page 格式如上所述。我们关注:
- Tuple Header 里面包含了下面的信息:
- Tuple 中是否有值为 Null 的 Attribute
- 如果有值为 Null 的 Attribute,那么后面会存放一个 BitSet,来表示第
i个字段的数据是否是 Null
- Tuple 里面会存储所有的数据
- 对于 Null 的 Attribute,不会存储对应的值
- 对于非 Null 的数据
- 如果是定长的数据,那么,这里直接会存储对应的内容,比如如果是 i32,那就存储 4bytes。
- 如果是变长的数据,那么,这里会存储 1b 或者 4b 的长度,再存储对应的内容。
我们假设某个表格式是 (i32, i64, bytes, i32),那么,可能存储的格式如下:
1 | -- 对于数据 (1, 2, "abc", 4), 可能是: |
当然,对于计算机来说,访问未对齐的数据可能是有额外开销的。PostgreSQL 还指定了让数据对齐的选项。
比如对 (i32, i64, i32),如果都不为 Null,可能有:
1 | i32 存放的: 4bytes |
(注:以上例子只作为 padding 的演示,实际上数据可能被编排为 (i32, i32, i64) )
下面我们来看看
如果有变长字段、Null 字段的话,需要读取第 k 列,可能要每列读过来,找到第一列:
- 判断它是否是 Null,如果是,那么偏移量不变
- 如果不是 Null:
- 是定长的话,跳过对应长度即可
- 是变长数据的话,可能要读取它的长度,再跳过对应的长度
比方说,假设像 (i32, i64, i32) 的 Tuple 中,保证没有数据是 Null。那我们可以知道(考虑 padding,假设和之前描述的格式一样):
- 第一列偏移量肯定是
0 - 第二列偏移量肯定是
8 - 第三列偏移量肯定是
16
具体一些细节优化内容可以在 PostgreSQL 的 src/include/access/htup_details.h 等文件里找到。PG 也可以用 schema cache 加速字段寻址。
讨论
PG 的格式本身应该是比较省空间的。空间放大来自于:
- Null BitSet
- 存放字符串长度的区域
同时,读取 PG 偏后的字段,可能会导致较低的性能,所以 PG 可能会这样处理格式:
- 先存放 非 Null 且定长的列
- 在存放 定长 且 可能为 Null 的列
- 存放变长的列
此外,有一些别的格式(非 PG)可能会考虑下面几种变体:
- 每隔几列添加一个索引,比方说,每隔8列插入一个偏移量,寻找第
(8n + k)列的时候,可以通过这个偏移量,先寻找到8n列的偏移量,再处理。笔者认为,这种方法相当于空间换 CPU 时间。虽然笔者本人没有试验过,但是这种方法可能对列很多的数据有一定的效果。 - 把格式做成偏移量固定的格式。比方说,如果
(i32, i64, i32)中第二列是 Null,也写对应的 8byte。这种方式让每个字段有一个固定的偏移量,能够快速完成寻址。笔者个人不是很喜欢这种方法,因为对于稀疏格式,它可能带来极大的空间放大。
InnoDB Compact
- https://mariadb.com/kb/en/innodb-compact-row-format/
- https://dev.mysql.com/doc/refman/5.7/en/innodb-row-format.html
InnoDB 是笔者心中的开源的地表最强存储引擎,Compact 格式在 MySQL 5.7 之后,作为 MySQL 的默认存储格式而存在。这种格式有着更小的空间大小,相对来说比 DYNAMIC 格式更耗费 CPU 一些。
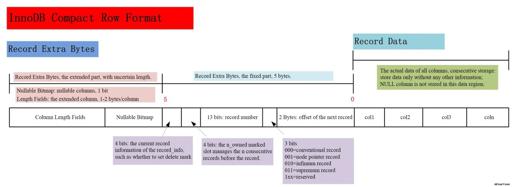
(图片来自:https://www.alibabacloud.com/forum/read-446)
我们忽略一些特殊字段,可以看到,这个格式除了一些标志位,会有:
- Nullable Bitmap (同我们之前介绍的 Null BitSet)
- Column Length Fields:变长字段的内容
- 具体的数据
这里相当于把之前 PG 存放的变长字段长度放到了一个独立的区域中。
杂项: Google FlatBuffers
FlatBuffers 是 Google 的一种序列化格式,相对而言,它是更通用的一种格式,强调了快速的解析(甚至不需要解析),我们可以看到它和行格式有一些异曲同工之妙。它的定义如:https://google.github.io/flatbuffers/flatbuffers_internals.html
这里,它会有一些数据来指向数据具体存放的地方,以保证不需要解析即可访问。同时,这个结构还支持 nested 和一定程度上的更新:
Order Preserving Row Encoding
如果要把行格式存储到 key-value 的 key 中,对于 ordered key-value,显然会希望这些 key 是可以 scan
- https://activesphere.com/blog/2018/08/17/order-preserving-serialization
- https://github.com/facebook/mysql-5.6/wiki/MyRocks-record-format
上面是通用格式,值得一提的是,对字符串编码,两种格式处理方式不一样:
- FoundationDB 会使用
0x00 0xff转换0x00,然后每个类型的字段都有自己的开头(一个固定的 byte)和结尾(0x00)等标志。解析的时候,遇到 0x00,需要前瞻一个 byte,查看下一个 byte 是什么。用0x00 0xff是因为一个性质:如果一个字符串包含内容0x00, 那么它小于所有真实的内容,大于结束在这里的字符串(即0x00表示字符串完了的内容),在这里完结的字符串要么就终止了,要么开启下一个 type 标记,下一个 type 标记必定不会用0xFF作为开头 - MyRocks 这套把字符串分成 Group,比如 8 个为一组,每一组附赠一个 byte 来描述这个 Group 的状态,这个比较 trickey 的是空字符串的处理,我曾经空字符串不留内容,显然这是个 bug。
总结
关于行格式,大部分时候我们不会和 pb 一样,全部读取/反序列化,通常,访问会只访问对应的 column,这要求我们快速读取 column。当然,有的用户也会定义一些变长字段,然后在里面存放 pb 数据。
行格式的逻辑通常和数据库的其他组织挂钩,但我们仍然能看到一些相同的工程设计。除了上面我提到的,还可以看看 TiDB / OB 的行格式,并考量它们是如何权衡 CPU开销和格式空间的开销的。