谈谈格式: 列存
列式存储
自 GFS/Hadoop 时代以来,在一个无 Schema 的存储上存储用户想要的数据也成为了用户的重要需求。Stonebraker 批判了这种情况,在 Redbook 4th 上,坚持用户还是需要 Schema 的。事实证明这些 Schema 确实是很好的东西。尽管有类似 Apache Hudi 这样的系统和部分系统用户存储行式的数据。但数据仓库都倾向于将数据存储成列/行列混合的格式。
简单来说,这样的存储方式有几种好处:
- 对某几列数据的访问,能够有不错的局部性和更低的信息熵
- 相同的 type 可以用一些非通用(snappy,zstd 等)方式来压缩、延迟物化。同时能减小占用的空间. 通常占用空间这点是会被忽略的,但是它能起到很多意想不到的收益
- 更好的 IPC、对 SIMD 的利用
对于列的存储来说,我们仍然有很多通用的格式,例如 Parquet、ORC。部分 shared-nothing 的数据仓库自己会实现一些格式,ClickHouse;也有数据仓库用这些开放的 Parquet 格式来提供支持,比如 databend。这些格式有共性、也有不同的地方。
同时,也需要注意,把一行存成列式不一定代表每列都分开存,可能有一定的折衷方案,比如数个 column 一起存。
此外,有一些项目也在为列式计算提供帮助。Apache Arrow 是一个处理计算和交换格式的项目,用 SIMD 等形式完成计算。
我们将简单介绍一些列式存储和压缩的想法,然后介绍一些通用的思路。编码本身是一种 speed 和 compression ratio 的 trade-off,而计算系统可能能利用压缩的优势,来减小它带来的开销,大大提高查询性能。
编码的单位/clusters/skipping
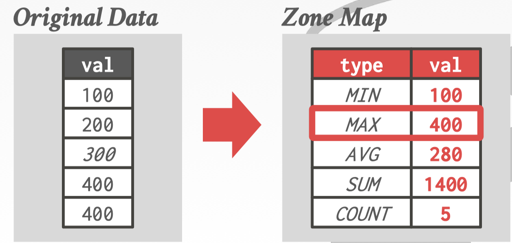
Zone Maps 提供了一种便于 skipping 的抽象。
具体可以参考:https://zhuanlan.zhihu.com/p/354334895
编码
C-Store 提到的方法
C-Store 论文提到过一些编码的形式,这部分标记在论文的 RS 部分:
Type 1:有序的且大部分值相同的序列
这种序列用 (v, f, n) 来表示
f is the position in the column where v first appears, and n is the number of times v appears in the column.
为了支持 query, c-store 对这个结构支持了 B树索引,加快了对这个内容的查找。
Type 2: 无序且大部分值相同的序列
这种序列用 (v, b) 来编码,v 是可能的值,b 是是这个值的数的 bitset:
For example, given a column of integers 0,0,1,1,2,1,0,2,1, we can Type 2-encode this as three pairs: (0, 110000100), (1, 001101001), and (2,000010010).
这里也实现了 <position, value> 的 B+Tree 查找结构。
Type 3: 有序且值较少相同的序列
采用 Delta 的形式进行编码(我感觉这里有点怪,因为 delta 本身应该和压缩没关系,感觉像是用了 delta + varint 啥的…)
Type 4: 无序,且值较少相同的序列,相对比较难编码。
The Design and Implementation of Modern Column-Oriented Database Systems
这里提到了几种编码方式
RLE: Run Length Encoding
同上述的 type 1。
Bit-Vec Encoding
同上述的 type 2
需要注意的是,bit-vec encoding 还能够进一步压缩,如果 bitmap 很多 0 或者 很多 1,可以用标准的压缩算法压缩;也可以用 RLE 的方式来压缩。Oracle Byte-Aligned Bitmap (Oracle’s BBC) 和 WAH(word-aligned hybrid)提供了一种方案。当然,这种方案只有数据非常稀疏的时候,才值得使用。
Dictionary
Dictionary 某种意义上和 Bit-Vec Encoding 很像,我个人理解可以放在不同场景使用。它对某一列的数据构建了一个字典表,然后里面的数据表示在字典的哪一项。当然,如果数据分布很多的话,这个字典会膨胀的非常大。
一般的情况下,数据可能会以「每个 Block/File/ …」 不同粒度的大小来构建字典。保证字典本身不会膨胀很大。
对于一些相同模式的字符串,字典编码可以让他们每一项有相同的长度,这也能大大加速查询、降低存储空间。
此外,考虑到对上层执行的优化,而不仅仅是压缩的话,字典压缩可能要考虑一些奇怪的东西:
- 在构建的时候是一次性构建,还是碰到新的值,就给一个新的
- 字典的 order 和原本的 order 是否一样呢?比如我们把几个字符串字典压缩了,然后需要排序或者取 top 之类的,可能希望这个序号和原来有一样的顺序(Order-preserving encoding)
在 Dictionary Encoding 构建的时候,可能要考虑:
- 值的 cardinal number 有多少种
- 包括这些数据,处理的时候,是否能 Fit 在 L1/L2 Cache 中
- 是否需要让数据 byte-aligned. 按位对齐的数据通常来说处理会快很多,不过压缩/解压缩 CPU 开销也更大
在解析的时候,单纯 Dictionary Encoding 也能够很好的解析到单个值上。此外还有一些保序的压缩算法,比如 ALM 或者 ZIL。
Frame Of Reference (FOR)
当数据有一定局部性的时候,可能可以组织成 frame 的形式,例如:
1 | 1003, 1001, 1007, 1006, 1004 |
可以组织成:
1 | 1000, 3, 1, 7, 6, 4 |
的形式。这里可以注意,3, 1, 7, 6, 4 是以 Delta 的形式存储的,更多的时候可能会让它们占尽量少的位,例如以 varint 的方式存储。
Increment Encoding
Increment Encoding 常见于 Key 的压缩编码。对于 key/value 的上层输入,常常会有相同前缀/后缀的 string,可以采用增量编码。LevelDB 使用了前缀压缩 + Restart。
具体可见 wiki。
The Patching Technique / Mostly Encoding
上述有的方法中,不一定适合完整的集合,比方说,只在某一段中,数据是有局部性的。Patching 相当于:
- 有一些控制段,表示某几段是以特殊编码方式存储数据的
- 在控制段外,不压缩。
此外,如果有极限的值的话,可以标注出来,做特殊处理:
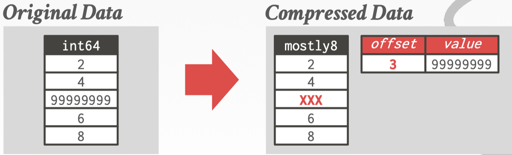
杂谈
对于编码的选择,有一些论文表示了如何自动切换,以达到很好的效果。例如 SIGMOD 2021 的 CodecDB。
有很多可供参考的代码,比如 ORC/Parquet 的压缩格式,和 Facebook 的时序数据库 Gorilla(提出了时间压缩的 delta-of-delta,double 类型的压缩方式)。
关于 int 的压缩,可以看:https://kkc.github.io/2021/01/30/integer-compression-note/ 和 https://arxiv.org/pdf/1908.10598.pdf
ORC/Parquet
Apache ORC 和 Apache Parquet 可以说是列式存储这些开放格式的事实标准了。它们有很多相同的部分,也有部分区别
基本原理
ORC 全称是:Optimized Row Columnar。这个格式本身似乎是为 Hadoop 项目设计的。
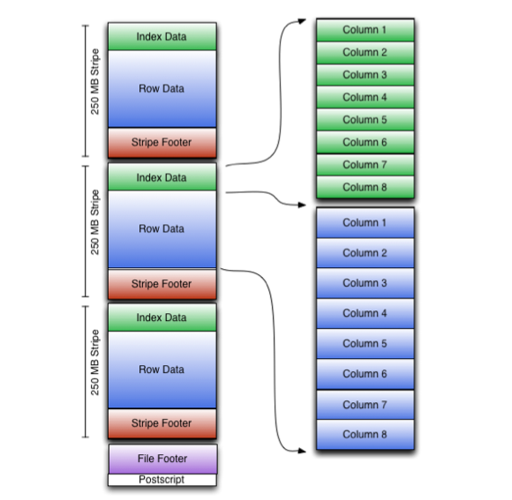
我们以 ORC v3 为例介绍一下这里的基本原理。忽略 Index Data 部分。多个行会被组织成 RowGroup/Stripe (名词很多,懂意思就行),然后里面切分为 Column。
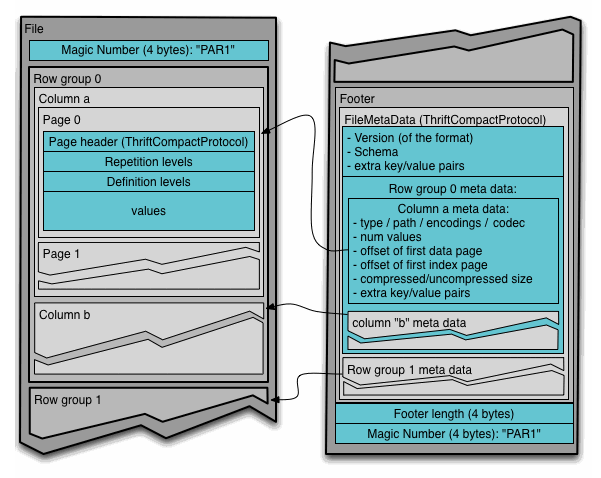
ORC 文件解析是从后往前的,在 HDFS 中,文件内容本身是不会直接被修改的,所以一些元信息会被存在文件的尾部。为便于更新,元信息可能用 PB 描述。Postscript 部分包含整个文件的元信息,而 File Footer 部分可能包含各个 Stripe 的信息,便于获致更具体的文件信息。
1 | message Footer { |
文件的主体部分被分为多个 Stripe,在别的格式中,它可能被称为 RowGroup。它包含:
- 数据的索引
- 各列的数据
- Stripe 的 Footer
Stripe 支持下列格式的各种数据:
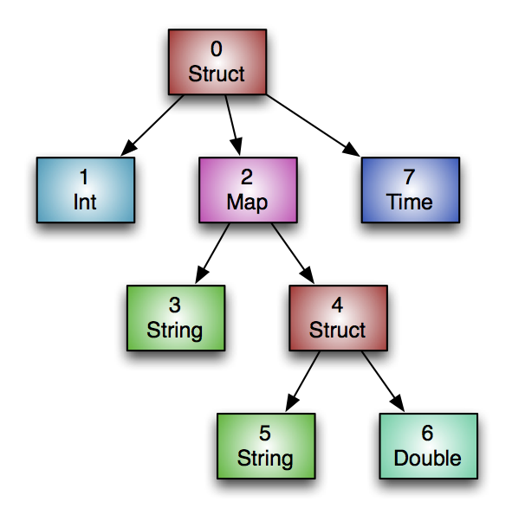
在 Stripe 的指示下,可以把 Column 做如下的压缩:
- RLE
- Dictionary
- Delta
对于 Column,ORCFile 定义 Stream 为一串字节流。这里有如下分类:
1 | message Stream { |
在下面的段,描述了它们是怎么被支持的:https://orc.apache.org/specification/ORCv2/ 的 Column Encodings 一节。
变长字段和 Null
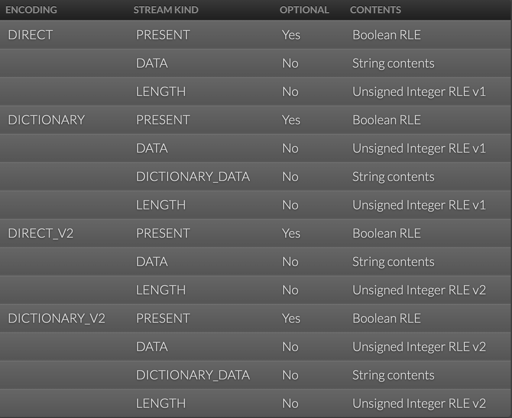
这里有不同的模式,比方说,direct 存放:
- Null 的集合,以 RLE 的形式存放
- Data,连续的非 Null 内容
- Length 具体的长度
而 dictionary 则用字典来存储。
Parquet 和 Dremel
(需要注意的是,Parquet 这个词很容易读错,可以去搜搜看你读错了吗)
Parquet 的主要思路来源于 Google 的 Dremel。Google 大量数据用 Protobuf 存储,所以当时搞列存,也要兼容它。推过内部系统的话就知道兼容是一个强需求了。
我们不关注这个格式和 ORC 的细微区别,比如 RowGroup 或者 Stripe 的命名。Dremel 关注一个包含 optional, repeated 且可能嵌套的结构是怎么实现的:
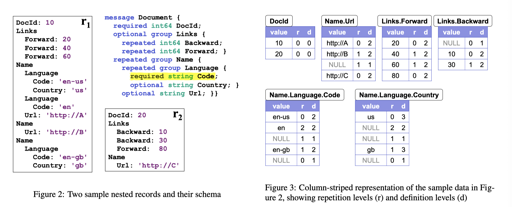
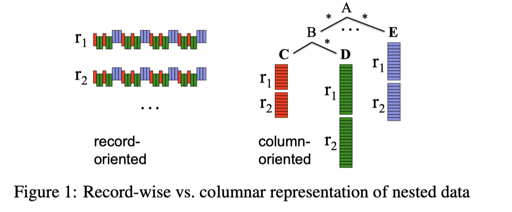
如 Schema 所示,这里有嵌套的数据结构,还有 repeated 和 optional,这意味着,需要一些额外的标志来解析数据在哪一行。Dremel 引入了 repetition levels 和 Definition Levels 两个向量,来做一些这样的 Resolve。
ACID / Indexes
实际上,ORC 的新版本有对 ACID 的支持,也有 Index 相关的信息,可以存放一些 Bloom Filter 之类的索引。
对于列式数据来说,实际上可以有一些稀疏索引之类的优化,能给到 field 大概的位置。在 ClickHouse 的 MergeTree 里面,有大概的实现。同时,如果以行的方式,进行增量更新的话,这里写放大会比较大。Kudu、SAP HANA 之类的产品为更新提供了方案。
也就是说,根据我个人的看法,ACID/Indexes 更像一个上层的需求。ORC 对这些有原生支持,但是你可以手动在 Parquet 里面增加支持,例如 databend 架构 维护了 sparse index 和 min max 信息。这些通用的格式在这些方面也有着不错的逻辑。
DB: 直接在压缩的数据上进行计算
SIGMOD 2006 的 Integrating Compression and Execution in Column-Oriented Database Systems 论文,描述了怎么能够在压缩的数据上进行计算。它描述的是一种类似延迟物化的思路,在压缩的数据上进行计算,它对数据进行了下列抽象:

Block 在 RLE 中指的是单个条目和对应内容,在 Bit-Vector/字典 中指的是单个值、非连续的一组信息(比如全0 或者全1)。它提供了一个 DataSource operator,允许把各种条件下推下去。比方说,bit-vector、字典都可以处理一些 Eq 之类的 Expr。
对于 JOIN 来说,它可以直接在 RLE 上运行。对于 Bit-vector,执行 Nested Loop Join 且里侧为 bit-vector 的时候,可以执行一些优化:

它还抽了一下下面的 API:
isOneValue()returns whether or not the block contains just one value (and many positions for that value).isValueSorted()returns whether or not the block’s values are sorted (blocks with one value are trivially sorted).isPosContig()returns whether the block contains a consecutive subset of a column (i.e. for a given position range within a column, the block contains all values located in that range).
然后有对应的优化范围:

总之,这里提供了一些 domain-specific 的优化方式。
Apache Arrow
不同于上述的存储格式,Arrow 更多的是一个交换格式和计算格式。利用 SIMD、Vectorize 等方式,完成跨语言的、高效的内存计算,同时也支持和 Parquet 的转化和 nested structure。
Apache Arrow 目前是没有延迟物化支持的。
结语
不同的格式、不同的数据有不同的特征。这里文章没有涉及一些复杂东西,比如 Streaming Parsing 等需求。笔者描述了列存、行存、RPC 等不同格式的需求和特征,及自己对一些特性的看法。感性的也可以在下方评论交流。鉴于笔者水平不行,行文可能存在诸多纰漏。敬请谅解。