Cache and Related Part3: Coherent
(图来自 CMU 15-418 Spring 2020 和 UCB CS152)
当我们涉及多核的时候,我们的多个核可能会共享一份内存:
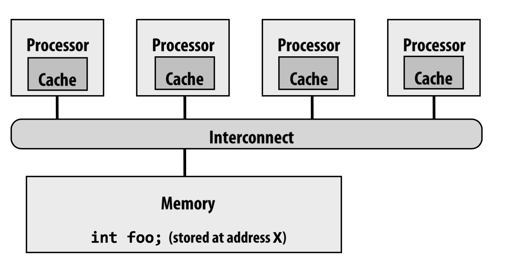
单个变量的访问可能会有问题:
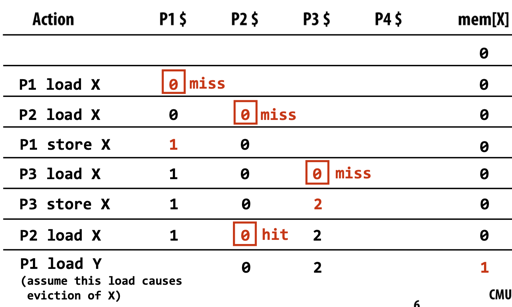
我们访问 memory, 可能在直觉上会是:
读到最近一级别存储 x 的上一个写入的值
但是,memory 会遇到的问题是
- 有 global 的 storage 和 local cache,而且这两个可能是不一致的
- 所以我们有 write back 和 write through 的策略,来 trade 性能和 consitent
- 有多个 local cache 的话,可能也会导致这种视图上的不一致
但是说到底,“读到上一个写入的值”,或者,“写入时间最近的值”,究竟是什么语义呢:

事实上,我们之前介绍过 CPU Cache, 现在给出一个 L1 L2 L3 的视图
显然,现在我们对同一个变量的访问,如上上张图所示,我各个处理器本身是顺序处理的,而它们在一起,会得到一个诡异的偏序,而 P1 P2 P3 的 x 值和内存中的 x 值是 inconsistent 的。这是问题所在:我们无法定义“上一个”逻辑意义上是什么。
要在保证性能的同时,也作出各个处理器对 x 的值读写的偏序保证,我们需要 coherence
Single CPU System: I/O
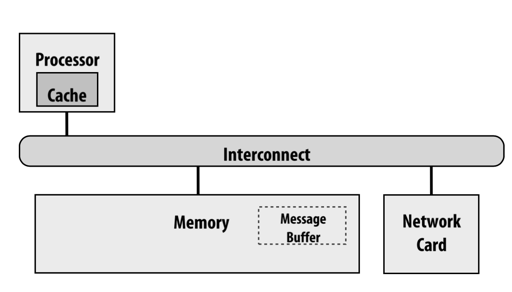
单核 CPU IO 的时候,假设要读/写数据,可能会:
- processor 写到了 write-buffer 里,而网卡可能没有读到 buffer 中的数据,而是读到了 memory 中的 stale data,造成写 stale data
- 网络中数据写到了 memory 中,通知 processor, processor
lw读到了 cache,造成读 stale data
某种意义上说,这也是一种不一致导致的,为了解决这个问题,需要下列的支持
- CPU 写的时候可以写到和设备的 shared buffer 中,而不是本身的 write buffer。让设备能够读到正确信息
- OS 可以把读写的 page 设置成不可 cache 的,同时,IO 完成的时候 flush cache page
- 在生产中,DMA transfer 的频率远比
lwsw少,所以可以接受代价较高。
Coherence
终于到了 conherence 了,那么我们来讲讲,memory coherence,我必须要说,下面这张图理的绝对很清晰了:

.
- 单个 Processor 对单个变量 x 的读写是顺序的
- write propagation: P 对一个变量的写入必须最终对其他 Process 可见
- write serialization : 写有全局的顺序
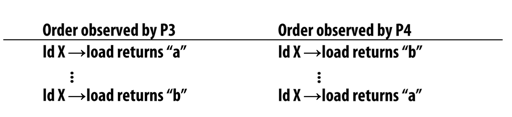
以上便是违背 write serialization 的例子,对于 x 写入 “a" "b", P3 P4 观察到的顺序不一致。
那么,在这种假设下,假设有三个线程 t0, t1, t2:
1 | // t0 |
那么,数组 s 中,可以看到我写的脑瘫程序可以输出:
1 | 26980 626437 1226236 1806376 2449353 3083919 3382384 3734980 4165338 5994059 |
这里奇数/偶数都是强 order 的,但是他们之间并没有什么保证,只能保证全局有一致的 order
(题外话:但是我看到这有个问题,就是 atomic + relaxed 和 non-atomic 有什么区别,瞅了眼: https://stackoverflow.com/questions/63810298/what-is-the-difference-between-load-store-relaxed-atomic-and-normal-variable 这似乎保证单个操作的原子性,比如我们 RV32I 的 auipc 和 add…)
关于实现 Cache Coherent,是下一节的内容,我们再次先看 Memory Model 吧。
Memory Consistency
最实用、最有挑战性、最令人困惑的部分来了。我们现在有了变量 x 的 coherence,我们还需要什么呢?
Cache Coherence 保证了单个 cache block 的 loads and stores 是按照定义运行的,但是我们假设有一个 produce-consume:
1 | // produce |
那么,很尴尬的是,你会发现 cache coherent 没有提供可靠的保障。
“Memory Consistency Model” (sometimes called “Memory Ordering”): do all loads and stores, even to separate cache blocks, behave correctly?
实际上,你会发现问题的来源很多,而且来源不是上层应用,而是我们讲了2节的 cache write-buffer multi-level cache 这些给我们带来利好的东西,和 OoO 执行、编译器乱序等正常对程序员透明,现在全冒出来了的东西。
Uniprocess Memory Model
单个程序按 program order 的语义执行、读写
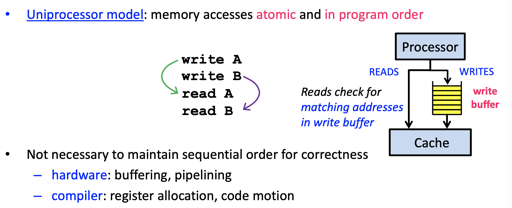
这图相当于我们 Part2 说的。
那么,在并行的时候,也就是我们说的 producer-consumer 中,可能会有下图的问题:
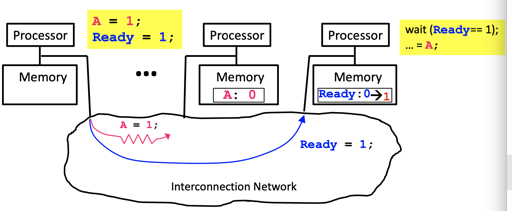
write buffer 和 OoO 等乱序不能保证写入会被顺序的传播,没有 happens-before 的语义。
更要命的是,cache 也会在其中添乱:(当然不止是 cache,所以回头来,你要理解到,volatile 这个词在 C/C++ 中是危险的,不能认为它们读写内存就万事大吉了,不过我也不太清楚搞 NVM 的大佬们会不会用到这个)
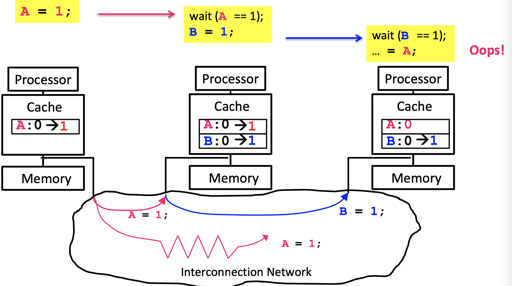
由于 P3 上有 A 的 cache, 它并不会从内存中读取应读的值,cache coherent 也没被违背,但是这会儿程序的语义就没法保证了!
更要命的是,还有编译器的乱序,关于编译器乱序可以参考没有使用 atomic 的 LevelDB 的 SkipList, 它只是写了一个编译器 barrier,而没有用 CPU 的 barrier 和指令。
Sequential Consistency: SC
这个是老熟人了:
Formalized by Lamport (1979)
- accesses of each processor in program order
- all accesses appear in sequential order
我理解就是简单说所有操作有一个全序,就所有操作偏序变全序。你可以用 seq_cst 来体验一下(
下面是它的硬件模型,描述的非常详细:
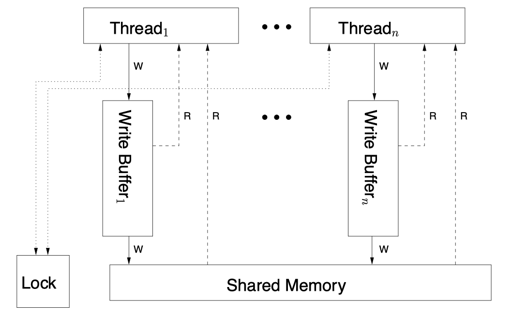
这个时候,写入要求:
For each processor, delay start of memory access until previous one completes: each processor has only one outstanding memory access at a time
读取要求
a read completes when its return value is bound
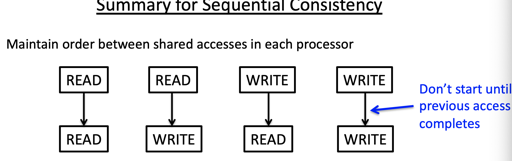
上述会带来严格的限制和可靠性,但是性能…
顺便可以提一下,对 x86 而言,一些 LOCK 指令会获取 Lock 相关的信息,而 MFENCE 会清空 Store Buffer。这里指令会按照发送的顺序来提交。
Relaxed Memory Model
于是我们有 relaxed 一些的模型,例如 TSO/PSO 等:
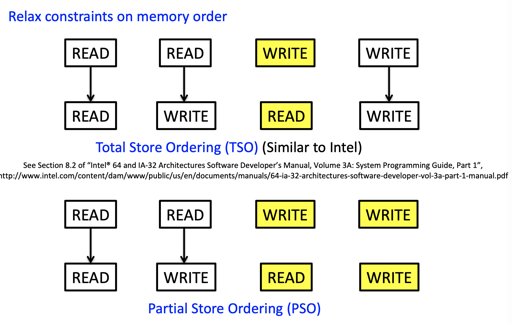
注:x86的 memory model 类似 TSO,只允许 store-load 乱序。
这在优化中获得了权衡:
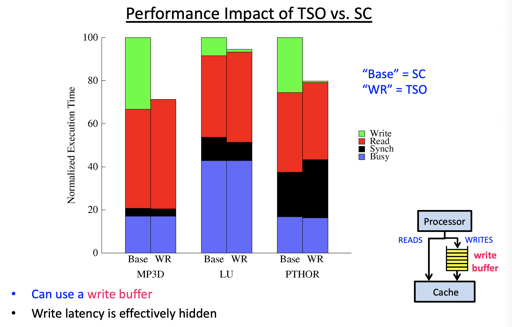
ARM & IBM Power 的内存模型
在这里,我们的硬件和指令可能有下面的语义:
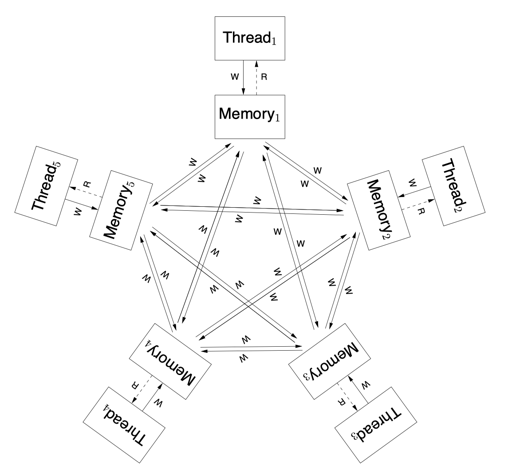
(上图实际上是一个 non-multi-copy 的模型)
下面是指令,它的 commit 可能是乱序的,而且指令可能会在分支预测阶段:
- 读取的时候,可能会直接读取
- 写的时候,要等待之前的内容 Commit
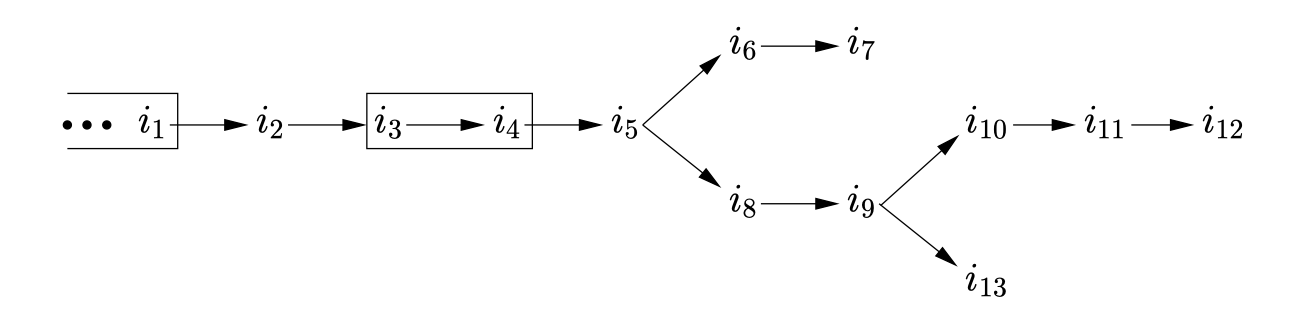
摘录一下原文:
For a read instruction, as soon as an address for the read is known, the read might be satisfied, binding its value to one received from the local memory (or in some cases forwarded from earlier in the thread). That value could immediately be used by later instructions in the thread that depend on it, but it and they are subject to being restarted or (if this is a speculative path) aborted until the read is committed.
For a write instruction, the key points are when the address and value become determined. After that (subject to other conditions) the write can be committed, sent to the local memory; this is not subject to restart or abort. After that, the write might propagate to other threads, becoming readable by them.
同时,指令发送的顺序和收到的顺序可能是不一样的,这里有一些分类:
- Weak, multi-copy-atomic memory models
- all processors see writes by another processor in same order
- RISC-V RVWMO, baseline weak memory model for RISC-V
- Weak, non-multi-copy-atomic memory models
- processors can see another’s writes in different orders
- ARM v7, original ARM v8, IBM POWER
IBM Power 和 ARM 中,可能会有 Load Buffer,读起来的顺序和写的顺序是不一样的。
可能出现的问题和同步
但是,这个时候,我们仍然要面对最初的那个问题:
1 | // produce |
Data Race:
- two conflicting accesses on different processors
- not ordered by intervening accesses
显然,我们对 flag 的操作本身没有经过同步,这个在仅允许 store-load 乱序的系统中,甚至没啥问题(不考虑编译器乱序)。但是,在 RISC-V 这种系统,或者 ARM 里,你就等死吧。我们需要一些机制来同步:
Properly Synchronized Programs:
- all synchronizations are explicitly identified
- all data accesses are ordered through synchronization
我们可以使用:
- memory barrier
- 显式的锁,来隐式提供 fence
逻辑如下:
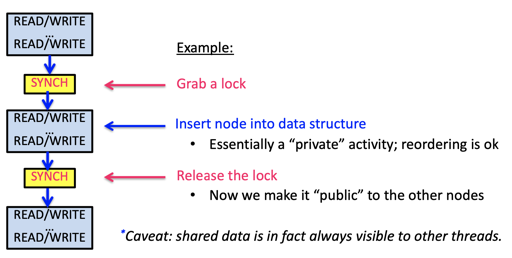
- x86 的
xchg显式的帮你完成这一切,你可以acquire来获得锁,在互斥区维护 invariant,release来释放锁。锁前,锁中,锁后都是可以 re-order 的,但是它们不能越过锁。 - MFENCE
LFENCEMFENCE, fence会 stall 程序,把之前的操作执行完,来创建偏序。
RISC-V 中的同步
RISC-V 提供了 multi-copy model,然后提供了 amo 来支持原子操作,首先它们对操作的数据是原子完成的。首先有 aq 和 rl 两位:
- 如果提供了
aq,这条指令 “Happens Before” 之后的load和store - 如果提供了
rl,这条指令 “Happens After” 之前的store和load
这里可以参考 spinlock:
1 | // Acquire the lock. |
(上面用的仍然是 gnu C 的 __sync_ 扩展,因为没有 amoswap.rl, 或者 ac,所以手动插入了一些 barrier)
关于 fence,可以参考:

举例而言,对于下面的图,fence w, w 和 fence r,r 之间构建了 barrier,来保证顺序:
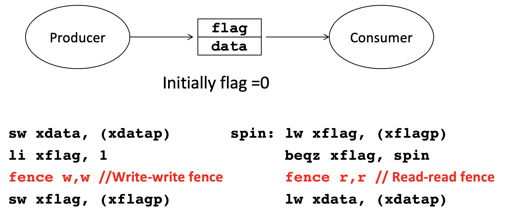
上述例子中,fence w, w 和 fence r, r 构建了一个偏序关系。sw data, (xdatap) 保证被 lw xdata, (xdatap) 感知了。
RISC-V 的支持:RV32A
RISC-V 具有宽松的内存一致性模型(relaxed memory consistency model),因此其他线程看 到的内存访问可以是乱序的。图 6.2 中,所有的 RV32A 指令都有一个请求位(aq)和一个 释放位(rl)。aq 被置位的原子指令保证其它线程在随后的内存访问中看到顺序的 AMO 操 作;rl 被置位的原子指令保证其它线程在此之前看到顺序的原子操作。想要了解更详细的 有关知识,可以查看[Adve and Gharachorloo 1996]。
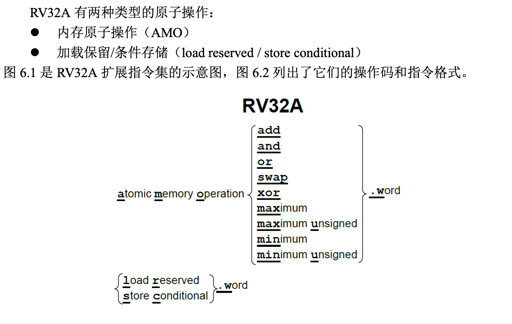
RV32A 没有直接提供了 CAS FAA 的指令,而是提供了两套指令。RV32A 认为这样有更好的可扩展性:

编译器乱序和语言的 memory_order
https://chromium.googlesource.com/external/leveldb/+/v1.15/port/atomic_pointer.h#61
除了内存,编译器也会完成乱序。最佳的例子是 LevelDB 之前的编译器 barrier。
语言会提供对应的语义,如 C++ 的六种 order (实话说我 consume 那几个完全不懂): https://en.cppreference.com/w/cpp/atomic/memory_order
或者简单点可以看看 Golang 的(
References
- CMU 15-418 Spring 2020
- UCB CS152 Spring 2020
- CPU Cache and Memory Ordering 何登成
- RISC-V Reader
- Computer Organization and Design RISC-V edition