Cache and Related Part2: Cache 的优化
我们上一个 part 聊过了 direct-mapped cache,这一节我们重复一些 cache 的 basics,然后聊 cache 相关的优化。
Recall
我们之前介绍过了 direct-mapped cache,之所以叫这个名字,是因为:
This cache structure is called direct mapped, since each memory location is mapped directly to exactly one location in the cache.
我们上一节中,一个地址可以被分成:
- tag
- index
- offset
而 cache 本身的存储不只是存放地址,它需要存放的是:
- Invalid bit
- tag
- block data
我查了一下,这里 block 的概念比较接近 cacheline 的概念. 我的电脑 lscpu 下试试:
我的台式,使用 lscpu
1 | 架构: x86_64 |
当我们读取的时候,我们在 RISC-V Datapath 的图像上是经过 icache 和 dcache 读取 memory,但是实际上我们更多是说读/写 cache。
当我们产生读 cache miss 的时候,我们可能会保存寄存器,然后noop或者停止,来暂停执行。而我们如果有 out-of-order 的执行,那么别的部分仍然能在语义正确的情况下执行。然后等缓存加载。
处理写的时候,我们有 write-through 和 write-back 两种形式,我们在上一节提到过。但是,我们需要考虑到,如果每次write都写到底层的话,无疑,每次写都会带来很大的开销:
With a write-through scheme, every write causes the data to be written to main memory. These writes will take a long time, likely at least 100 processor clock cycles, and could slow down the processor considerably.
实现的时候,一个比较好的解决方案是 write-buffer。当处理写请求的时候,写到 cache 层的 write-buffer就算写成功了,处理器可以接下来进行,cache 把写给 memory 之后,write buffer 会被清空。不过 write-buffer 会面临两个问题
- 乱序(所以某种意义上需要 memory model)
- write-stall
If the write buffer is full when the processor reaches a write, the processor must stall until there is an empty position in the write buffer.
还有一种方式是 write-through,写到 cache 上,然后被 evict 的时候写回。不过这个会面临的问题是需要自北 evict 的时候可能会 stall. write-through 也有 write allocate 等策略。write allocate 是指:如果目标内存不在 cache 中,是否要把它捞上来。
其他模式与性能优化
我们之前提到 cpu cycles 都是 CPU 和 time 的 cycle,但是,考虑 memory 和 cache 之后。这几个变成了:
- CPU execution clock cycles
- Memory-stall clock cycles
上述两个乘 clock cycle time
对于 memory-stall, 我们可以分为读写:
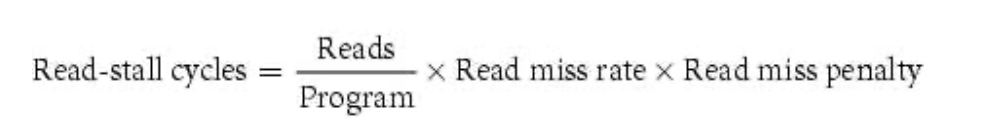

Fully associative cache
A cache structure in which a block can be placed in any location in the cache.
这个其实类似没有 index 了,每次查询的时候对所有的 cache tag 并行做一个比较(我其实不太懂硬件的实现,不过这个听上去太极端了)
在 fully-associative 和 direct-mapped 之前,也有 set-associative:
In a set-associative cache, there are a fixed number of locations where each block can be placed. A set-associative cache with n locations for a block is called an n-way set-associative cache. An n-way set-associative cache consists of a number of sets, each of which consists of n blocks.
内存中的每个地址,之前是 map 到 cache 中的一个 index, 现在允许 map 到一个 set, 这个 set 是 n位的,在这个set 中进行比较
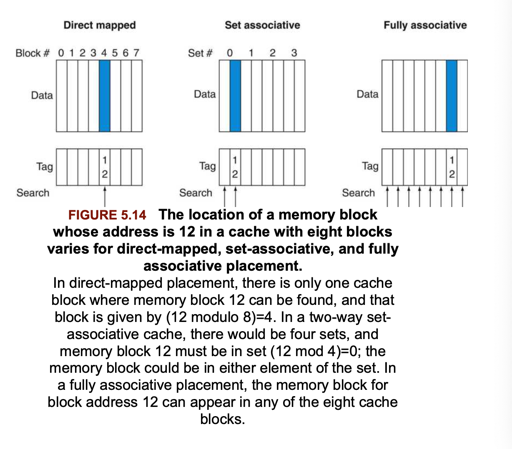
所以其实来说,也就是一个 associate 大小的关系,direct-mapped 的情况下,这个值为1,fully-associate 的情况下,这个值为缓存的大小,下面我们来看看具体的对性能的影响

综上,一定的机制可以保证更小的 data miss rate, 但同时,比较高的 accociativity 却不会提升的太高。而在cache 的设计中,也需要做出一定的 trade-off, 读 cache 成为了下面的形式:
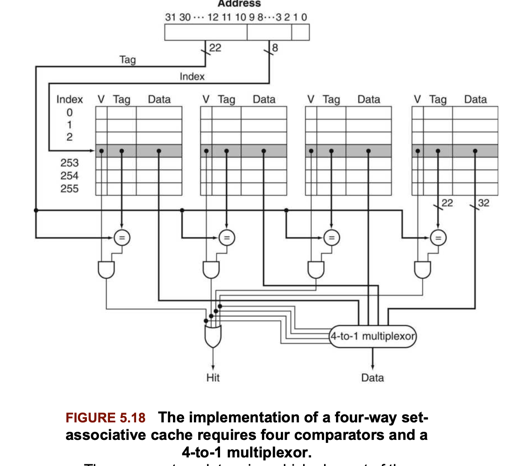
这种 n-way 也添加了开销:
- N Comparators 的时空开销
- MUX 的时间开销
而需要替换的时候,可以用 LRU 或者更简单的 clock 算法来标示替换 cache.
Multi-Level Caches: Reducing the Miss Penalty
This second-level cache is normally on the same chip and is accessed whenever a miss occurs in the primary cache. If the second-level cache contains the desired data, the miss penalty for the first-level cache will be essentially the access time of the second-level cache, which will be much less than the access time of main memory.
好吧,不得不承认,我看这一节之前都以为这些 cache 虽然都是 DRAM,但是造价和成本是有明显差异的。它们确实有差异,但是是体现在别的地方,我们会在下面介绍它们的。
需要明白的是,假设我们有2级的 cache, 且都没有 data, 那么一个皆 miss 的访问将会丢失更多的数据。
With a larger total size, the secondary cache may use a larger block size than appropriate with a single-level cache. It often uses higher associativity than the primary cache given the focus of reducing miss rates.
The design considerations for a primary and secondary cache are significantly different, because the presence of the other cache changes the best choice versus a single-level cache. In particular, a two-level cache structure allows the primary cache to focus on minimizing hit time to yield a shorter clock cycle or fewer pipeline stages, while allowing the secondary cache to focus on miss rate to reduce the penalty of long memory access times.
在i7中,我们有如下的例子:
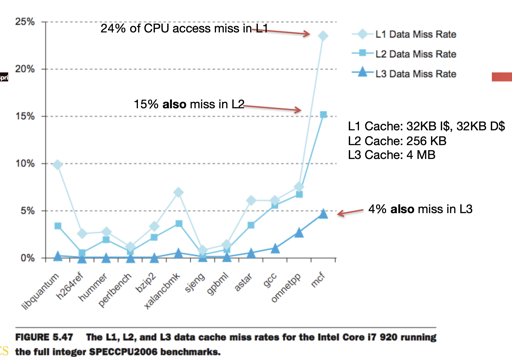
对 multilevel cache , 下层需要更大的大小,允许更慢的反应速度。你可能会很奇怪,为什么都是 cache, 阿反应速度可以更慢,实际上,你可以考虑我们之前讨论的一些 trade-off

那么下层的 cache 允许更多的 ways,更大的大小,和更慢的访问速度。
L1 L2 L3

以上的决策允许我们作出设计
https://superuser.com/questions/269080/why-are-multiple-levels-of-caches-used-in-modern-cpus
https://zhuanlan.zhihu.com/p/31875174
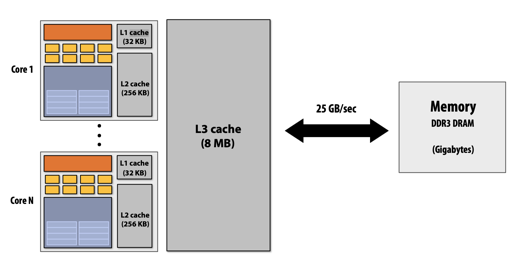
缓存,访问模式,多个缓存
Caching is perhaps the most important example of the big idea of prediction. It relies on the principle of locality to try to find the desired data in the higher levels of the memory hierarchy, and provides mechanisms to ensure that when the prediction is wrong it finds and uses the proper data from the lower levels of the memory hierarchy. The hit rates of the cache prediction on modern computers are often above 95% (see Figure 5.46).
缓存是可以 prefetch 并能够预测的,实际上,不仅是这一层的 cache, 应用层 cache 也有很多不同的算法,来减小不命中的开销。有一些算法会故意让访问模式 cache 不友好,来增加访问 cache 的开销。
LRU Clock 算法这些甚至可以做到硬件,而有一些 arc 之类的算法相对来说可以作为 db 的 cache replacement policy。
prefetch 可以带来不少性能的优势,如下图:
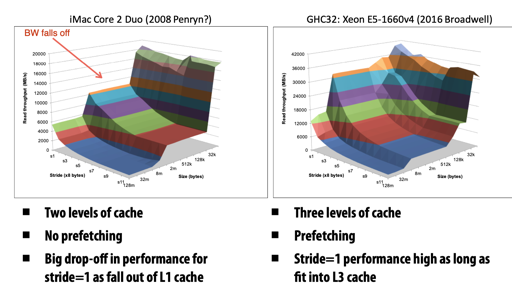
缓存与代码
stride * sizeof(int) == block size 的时候,你的代码必定不是缓存友好地
关于缓存友好这个坑, 可以参考下:
- https://fosschef.wordpress.com/2011/07/08/prefetch-performance-and-toxic/
- http://igoro.com/archive/gallery-of-processor-cache-effects/
- https://www.aristeia.com/TalkNotes/ACCU2011_CPUCaches.pdf
- CSAPP, 3edtion.
我在我的 Mac 和 3800X 都跑过这些代码,有几个坑其实试不太出来,我也不知道咋回事,有没有人可以教教我的