notes: Skiplist-based lsm-tree
The Skiplist-Based LSM Tree
读这篇论文是因为原始 SkipList 那个 Btree 读的脑阔疼,我又不是很了解 Btree。这篇文章又和使用最广的 RocksDB/LevelDB 比较接近。
LSM Tree 提供了层级的数据来提供写优化的数据系统。原始的论文中,作者在每个层次中使用的都是类似 B-Tree 的结构,在 sLSM 中,Buffer 结构都是一系列的 Skiplist.
LSMTree Paper 有一套冷热数据计算的式子。把新插入的 hot 数据放在内存中,冷的下层数据放在 secondary storage 中,来让写被均摊。同时,原论文介绍了 two-component (即可视作只有内存和 disk)的 LSM 之后,也介绍了 multi-component 的 LSM Tree, 通过多层次来均摊 Compaction 的开销。这个在这有一些简洁的答案:
https://www.zhihu.com/question/396452321
同时,LSM Tree 可以用 Bloom Filter(这个用的应该很多)、fence pointer(我记得是 FD-Tree 里的?)
The remainder of this paper will proceed as follows: Section 2 will detail the design of the Skiplist-Based LSM (sLSM), including the in-memory component, the on-disk component, indexing structures, key algorithms, theoretical guarantees, and the range of design knobs; Section 3 will provide extensive experimental results, including parameter tuning and performance analysis; and Section 4 will discuss and conclude.
阅读这篇文章也是因为,这个 LSMTree 相对来说和 LevelDB/RocksDB 有一定相似之处。
SLSM 设计
- 内存中有 R 个 SkipList, 只有一个是 active 的。
- 如果 Insert 出现,现有的 SkipList 达到了大小的上限(好奇这个上限是怎么设置的)后,会尝试把现在的 SkipList 变成只读的,然后尝试在新的 SkipList 写。如果内存满了:
- 按比例把 m 个现有的 SkipList 与 Secondary Storage 进行 merge
读取的话会按照 SkipList 的新旧读,再访问磁盘。
SkipList
这篇文章介绍了 SkipList 的两个优化:
- Fast Random Levels:利用 random bits 生成 random Level
- Vertical Arrays, Horizontal Pointers
While the differential densities of the levels precludes an array-based structure in the horizontal direction, it is wasteful to include links from nodes of value k to another node of value k on the next level. Instead, in our implementation a skiplist node includes one key, one value, and an array of pointers to other skiplist nodes. This array can be thought of as a vertical column of level pointers, where pointers above the node’s level are null and each pointer below points to the next node on that particular level. In this way, skipping down a level is a matter of reading a value that was already loaded into the cache, rather than chasing a pointer somewhere random in memory. Because we implemented the skiplist in this way from the beginning we do not report differential performance between this cache-conscious and the alternative, naive way.
其实感觉说的比较像 LevelDB 的了:
1 | struct SkipList<Key, Comparator>::Node { |
Disk-Based Storage
“is only touched by merges from the memory buffer”
There are L disk levels, each with D runs on each level. A run is an immutable sequence of sorted key-value pairs, and is captured within one memory-mapped file on disk.
Each disk run is indexed similarly to the in-memory run, with max/min keys and Bloom filters.
除此之外之外这里还引入了 fence pointer, FD-Tree 也有 fence pointer, 这是带层次的查找优化:
These are fixed-width indices that store the key of elements in increments of some logical page size in memory.

Merging
LSMTree 的 Merge 还是很复杂的:
- merge 是把某一层按比例 m 和下层合并,用写来减小读放大
the number of elements at level k is O((mD)^k).- 可能会有 cascading 的 merge
We propose a heap-based merging algorithm that runs in O(n log(mD)) time and O(mD) space, where n is the number of elements being merged.

具体来说,每个 list 都是 sorted 的,LSMTree 会对它们 heap sort .
实现的时候,这里采取了多线程的方式:
In our implementation, we also use multithreaded merging to decrease our latency. When an insertion triggers a merge, a dedicated merge thread takes ownership of the runs to merge and executes the merge in parallel, allowing the main thread to rebuild the buffer and continue to answer queries. If a lookup request comes while the merge thread is executing the merge, the main thread searches the memory buffer for the requested key, and if unsuccessful, waits for the merge to complete before querying the disk levels.
下面是 param table 和读的性能分析:

Range
Range 是一个比较复杂但是很需要的操作,我们可能会:
- 拿到 Snapshot 或者迭代器,然后在这上面 iter
这种操作和 PointGet 不一样,是需要知道所有的 table 情景然后查询的。
这里操作是:首先按range和值过滤,然后从新到旧遍历,并构建一个 hashtable 来 O(1) 的去重。
Because collecting elements in the range in both skiplists and disk runs is a linear-time operation, and because hashing is an amortized constant-time operation, a range query over n keys is expected to take O(n) time.
这个 O(n) 是 n keys, 我不太清楚这个放大是什么情况,总觉得不太清楚
Perf
We tested the sLSM on a DigitalOcean Droplet Server running 64-bit Ubuntu 4.4.0 with 32 Intel Xeon E5-2650L v3 @ 1.80GHz CPUs, a 500 GB SSD, 224GB main memory, and 30MB L3 cache.
(我也想有这么好的机器)
再次贴一下参数表:
R
In determining the optimal R, we found that the smaller R is, the smaller the memory buffer is, and the more frequent merges will be. Thus, lower R leads to lower insertion throughput. However, with few runs to search, lookups are very quick with small R. Analogously, higher R is linked to faster insertion but slower lookup, since more runs need to be searched. With Bloom filters, it is possible to set R high enough to achieve extremely fast insertion while enjoying significant speedup on lookups due to the filters. More formally, R does not enter the amortized insertion time function, and there are significant constant factors hidden in that equation that correspond to the speed and frequency of merges. However, lookups depend linearly upon R, as proven above. The graph in Fig. 2 details the tradeoff between insertion time and lookup time for a number of values of R. As such, setting the number of runs intelligently also allows us to tune the performance of the sLSM to the workload at hand- more runs for more writes, and fewer for more lookups.
发原文总觉得没什么诚意,但是这一段说的比我能介绍的精细多了。
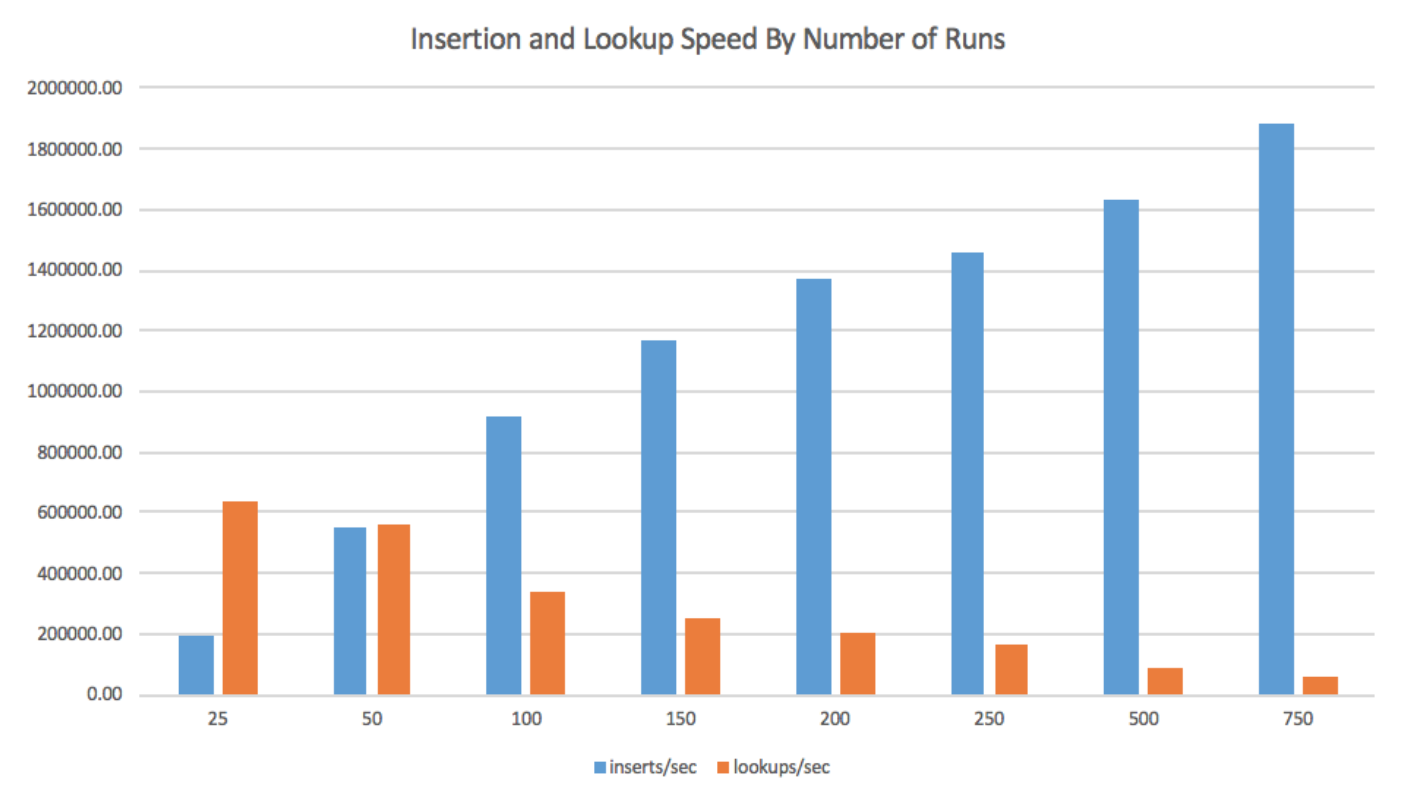
- R 变大,写入受 Compaction 的影响和 Stall 变小
- 读取效率变低,因为要在内存中寻找多个 skiplist
读取效率变低我真的没太理解,感觉走到 disk 上肯定会更慢,但是 R*Rn 值固定的时候,感觉上面的就可以理解了,而且这两个参数也会影响 flush 的效率。
Rn
For each value of R, increasing Rn increases insertion rate while decreasing lookup throughput. This is because a larger Rn allows for fewer merges over the lifetime of the workload due to the larger memory buffer. However, this increase in the size of each run increases the runtime of each lookup, since skiplist queries are logarithmic in their size.
这个应该相对更好理解一些。
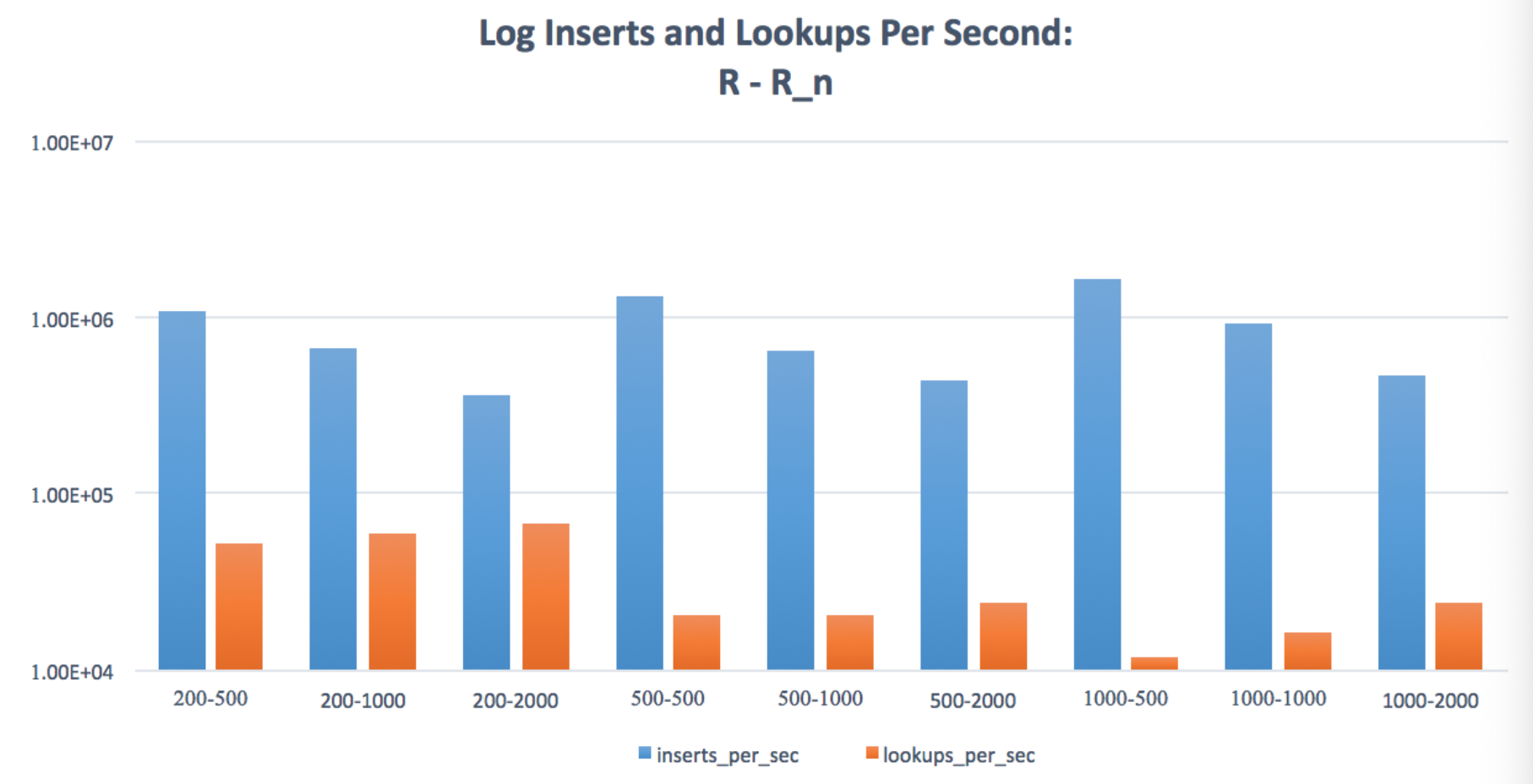
也可以参考 RocksDB 的 Flushing Options
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#flushing-options
Disk and Merge Parameters
也可以参考 https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide#level-style-compaction
- m is set under 0.5, merges would happen too frequently for sizeable datasets, causing the OS to run out of file descriptors
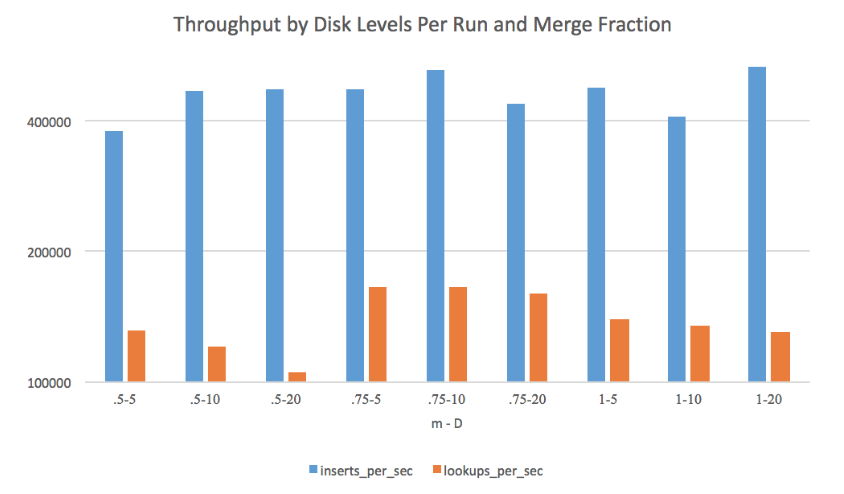
D 变大时,写入性能是提升的,但是读会被放大。m 变大时,compaction 变得不那么频繁。