notes on craq
Notes on CRAQ

这篇文章介绍了 CRAQ,链式复制的改进。
本人主要阅读了 1-3 章,第三章的 scaling 和 5.3 的 membership changes 没有完全理解它的思路,4.1 的 mini-transaction 没有读的很细,以后可能会回头来改。
也欢迎懂的朋友留言或者给 [email protected] 邮件。
Recall
GFS
GFS 分为 Master 和 Chunk Server, Master 有 Chunk 的 metadata,负责文件映射的信息、Chunk信息,也负责管理 lease、回收 Chunk、Chunk 迁移。Master 节点使用心跳信息周期地和每个 Chunk 服务器通讯,发送指令到各个 Chunk 服务器并接收 Chunk 服务器的状态信息。
ChunkServer 维护自己的逻辑,运行在 Linux File System 上。Chunk 类似系统的 block 这种概念,默认 64MB。它的大小会影响内部碎片和通信效率/空间效率:Chunk 越大,内部碎片肯定越小,但是 metadata 空间效率也会变大,请求次数也会变更。不过这样也不利于存储小文件。
ChunkServer 会有备份的模型。当写入的时候,我们需要保证多个 replica 写入顺序上是一致的。Master 会给 Chunk 分配 lease,这个 chunk 会给出写入的操作序列,被称为 primary chunk。
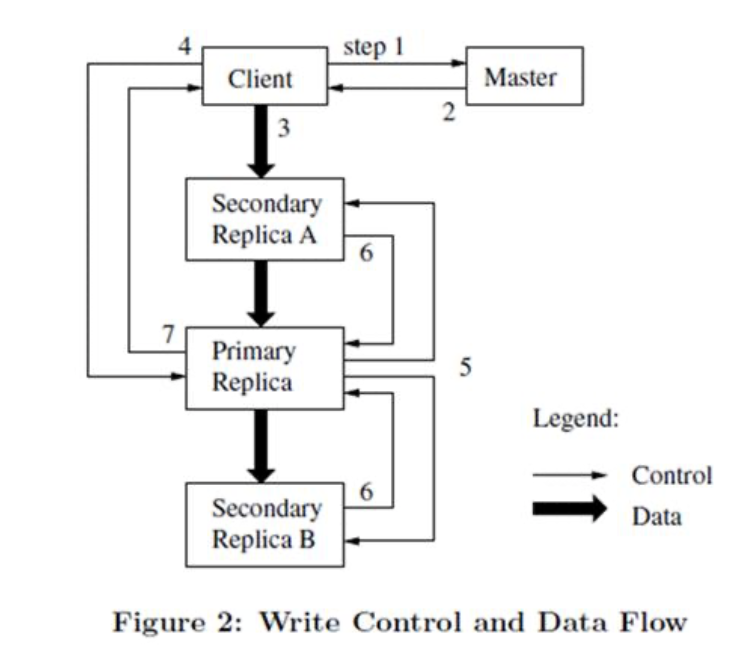
GFS 的数据流和控制流是分开的,写入的时候,client 会拿到某个 chunk 的元数据并做缓存,然后想上图3一样:
数据沿着一个 Chunk 服务器链顺序的推送,而不是以其它拓扑形式分散 推送(例如,树型拓扑结构)。线性推送模式下,每台机器所有的出口带宽都用于以最快的速度传输数据,而 不是在多个接受者之间分配带宽。
为了尽可能的避免出现网络瓶颈和高延迟的链接(eg,inter-switch 最有可能出现类似问题),每台机器 都尽量的在网络拓扑中选择一台还没有接收到数据的、离自己最近的机器作为目标推送数据。假设客户机把 数据从 Chunk 服务器 S1 推送到 S4。它把数据推送到最近的 Chunk 服务器 S1。S1 把数据推送到 S2,因为 S2 和 S4 中最接近的机器是 S2。同样的,S2 把数据传递给 S3 和 S4 之间更近的机器,依次类推推送下去。我们 的网络拓扑非常简单,通过 IP 地址就可以计算出节点的“距离”。
某种意义上,这也是一种链式复制。
CRAQ
为什么要 CRAQ
这篇论文介绍的就是一种链式复制和优化,论文介绍了 CRAQ 和普通链式复制的区别,以及它是如何在保证性能的情况下提供强一致性和别的loose一点的一致性的的。
文章还介绍了 geo-replication 相关的实现。
2
Ceph, Parameter Server, COPS, FAWN.
上面这些都用了 chain replication(哇我以前都不知道),它的大致思路如下:
- A->B->C->D 构成一条链,
- client 在头写,在尾读,A落盘后写 B,B 落盘后写 C,D中落盘即可读
- 这种方式比较好 pipeline 化
- 节点变多的时候,可能需要 Consistet Hashing 来 sharding。
上面的缺点是:
- 读在尾部,很容易成为潜在的瓶颈
- 单个节点 failure 可能会影响系统
- Consistet Hashing 仍然有潜在的热点问题(这个我没研究过),读请求会全部落在热点的尾部。
MIT 6.824 的 course notes 指出了 CR 的优点
1 | Why is CR attractive (vs Raft)? |
而对象存储特点是,不需要所有操作的 total order,需要的是单个对象的order。
CRAQ 提供:
- CR 一样的强一致性
- CRAQ的设计自然支持读操作之间的最终一致性,以降低写争用期间的延迟读取,以及在临时分区期间降级为只读行为。CRAQ允许应用程序指定读取操作可接受的最大 stale 可能性。(论文里是 Apportioned Queries)
- 在读分摊的 load-balance 之外,提供了 geo-replication 的方案,读可以从本地的集群读,同时借助 ZooKeeper 维护 members。
CR 的一致性讨论
1 | Intuition for linearizability of CR? |
- 没有 failure 的时候,显然是 Linearizable 的,毕竟是单点 apply
- failure 的时候,因为 apply 的顺序是一致的,所以没关系。
(不过我感觉这论文主要重点还是单对象的一致)
CRAQ
1 | The CRAQ paper admits there is at least one other way to skin this cat: |
在 CRAQ 中:
- 每个 node 可以存储多个版本的对象,版本可以是 clean 或者 dirty 的。
- 当 node 接收到写入的时候:
- 如果是 tail, 那么接受写入,并 ACK 通知之前的节点,写入成功
- 否则把
(key, value)添加到版本链中,标记为 dirty.
- 当非 tail 的节点收到 ACK 的时候,把对应版本 dirty 标记为 clean,然后删除之前的版本
那么,当一个节点收到读请求的时候,如果不要求一致性,可以返回最新的版本,否则:
- 如果查询的对象是 clean 的,返回(意味着写入 tail 完成,前面即使有些这个 key, 也是 dirty 的)
- 否则,向 tail 进行一个 version query
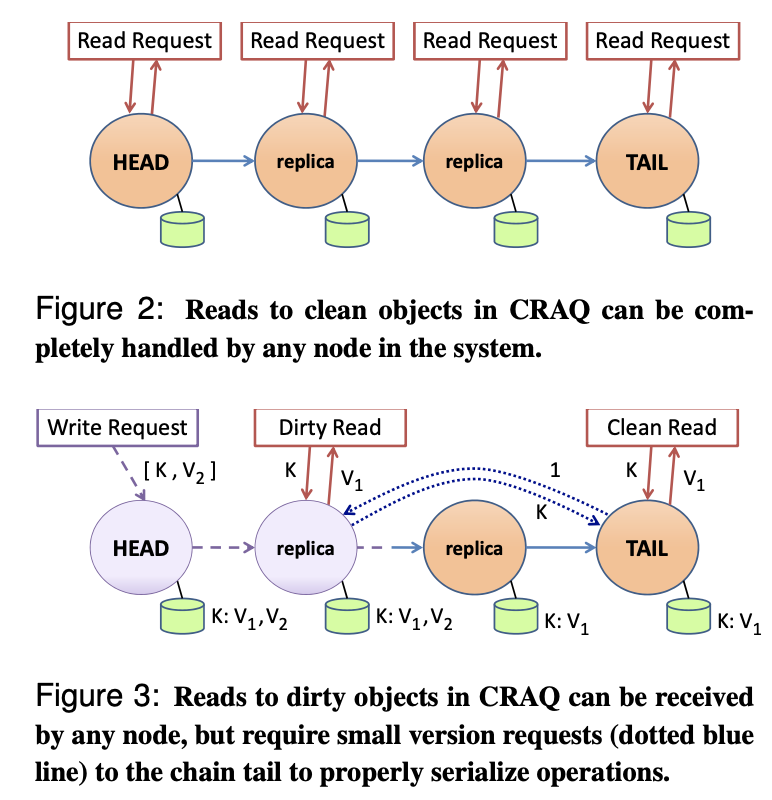
论文认为,在两种情况下,性能是有提升的
- Read-mostly workloads: 读多的情况下,读会被均摊
- Write-heavily workloads: 对 tail 查询版本比全部落在 tail 轻量,这意味着读请求依然是均摊的。
这样的情况下,认为任然是 Linearizable 的:
1 | Intuition for why same as CR (i.e. linearizable) (assuming no failure): |
不过,在以上的情况之外, CRAQ 仍然提供别的一致性:
- Eventual Consistency:允许读最新的 seesion 版本,同时,如果读不垮节点,那么系统有单调读一致性
- Eventual Consistency with Maximum-Bounded Inconsistency: 允许返回
recovery & membership changes
主要在论文第五节
When a head fails, its immediate successor takes over as the new chain head; likewise, the tail’s predecessor takes over when the tail fails. Nodes joining or failing from within the middle of the chain must insert themselves between two nodes, much like a doubly-linked list. The proofs of correct- ness for dealing with system failures are similar to CR; we avoid them here due to space limitations. Section §5 describes the details of failure recovery in CRAQ, as well as the integration of our coordination service. In particular, CRAQ’s choice of allowing a node to join anywhere in a chain (as opposed only to at its tail [47]), as well as properly handling failures during recovery, requires some careful consideration.
然后系统有:
1 | Equivalently, why can't 2nd node take over as head if it can't reach the head? |
Scale
- Most or all writes to an object might originate in a single datacenter.
- Some objects may be only relevant to a subset of datacenters.
- Popular objects might need to be heavily replicated while unpopular ones can be scarce.
对象标识符由链标识符和密钥标识符组成。链标识符确定 CRAQ 中的哪些节点将存储该链中的所有 keys,而密钥标识符为每个链提供唯一的命名。论文描述了多种指定应用程序需求的方法:
{num_datacenters, chain_size}分布在整个数据中心,用 consistency hashing 映射. 固定的数据中心存储固定的 chain。{chain_size, dc1, dc2, ..., dcN}每个数据中心使用同样的 chain-size,dc1, dc2 里面 chain 的大小都是chain_size, 由 consistency hashing 决定 dc 内部的节点。{*dc*1, *chain*_*size*1, ..., *dc**N*, *chain*_*size**N*}在每个中心内,chain-size 是提供好的。
2 3 中,dc1 都可以成为 master 集合,这意味着即使有集群头节点变换,写入也要落到这个数据中心。
Otherwise, if dc1 is disconnected from the rest of the chain, dc2 could become the new head and take over write operations un- til dc1 comes back online. When a master is not defined, writes will only continue in a partition if the partition con- tains a majority of the nodes in the global chain. Otherwise, the partition will become read-only for maximum- bounded inconsistent read operations, as defined in Section 2.4.
在单个数据中心中,sharding 可以靠任意的 consistency hashing, 也可以引入 naming service. 多个数据中心中,读写代价会放大:
Even with an optimized chain, the latency of write operations over wide-area links will increase as more datacenters are added to the chain. Although this in- creased latency could be significant in comparison to a primary/backup approach which disseminates writes in parallel, it allows writes to be pipelined down the chain. This vastly improves write throughput over the primary/backup approach.
同时,如果在多集群中引入 ZooKeeper 这样的协调系统,可以:
- 引入某种层次的 zk 的协调
Placing multiple ZooKeeper nodes within a single datacenter improves Zookeeper read scalability within that datacenter, but at the cost of wide-area performance. Since the vanilla implementa- tion has no knowledge of datacenter topology or notion of hierarchy, coordination messages between Zookeeper nodes are transmitted over the wide-area network mul- tiple times. Still, our current implementation ensures that CRAQ nodes always receive notifications from local Zookeeper nodes, and they are further notified only about chains and node lists that are relevant to them. We expand on our coordination through Zookeper in §5.1.
To remove the redundancy of cross-datacenter ZooKeeper traffic, one could build a hierarchy of Zookeeper instances: Each datacenter could contain its own local ZooKeeper instance (of multiple nodes), as well as having a representative that participates in the global ZooKeeper instance (perhaps selected through leader election among the local instance). Separate functionality could then coordinate the sharing of data between the two. An alternative design would be to modify ZooKeeper itself to make nodes aware of network topology, as CRAQ currently is. We have yet to fully investigate either approach and leave this to future work.
感觉还是很麻烦的。
4. Extensions
4.1 Mini Transactions
CRAQ 支持下面的 mini-txn
- Prepend/Append: Adds data to the beginning or end of an object’s current value.
- Increment/Decrement: Adds or subtracts to a key’s object, interpreted as an integer value.
- Test-and-Set: Only update a key’s object if its current version number equals the version number spec- ified in the operation.
如果是第一类和第二类,可以直接添加到头/尾然后传播新版本。写入比较多的话可以 batch。
如果是 test-and-set, 如果本身有 dirty 版本或者未完成的 cache 写就拒绝,否则传播。
下面来考虑具体的实现(4.1.2):
A mini-transaction is defined by a compare, read, and write set; Sinfonia exposes a linear address space across many memory nodes.
本质上相当于在前面三类的基础上控制读写集和冲突。
涉及多个 chain 的事务时候,需要对 chain 之首处理 2PC。
4.2 Lowering Write Latency with Multicast
Raft 的协议会完成一个 majority 的写。CRAQ 也可以利用 multicast 来 bonus 写性能:
Then, instead of propagating a full write serially down a chain, which adds latency proportional to the chain length, the actual value can be multicast to the entire chain. Then, only a small metadata message needs to be propagated down the chain to ensure that all replicas have received a write before the tail. If a node does not receive the multi- cast for any reason, the node can fetch the object from its predecessor after receiving the write commit message and before further propagating the commit message.
通过广播写入数据,然后从头到尾传播 metadata 而不是全部信息,来保证写入是有效的。
同时,单个 dc 尾部收到 ACK 或者完成写入的时候,也可以用 multicast 提升性能:
This reduces both the amount of time it takes for a node’s object to re-enter the clean state after a write, as well as the client’s perceived write delay.
5 Management and Implementation
5.3 Handling Memberships Changes
论文 2.3 提到了一定的要求,即:
- header 出问题了把 header->next 当新的 header
- tail 出问题了把 tail-prev 当 tail
- 在中间加入/删除要通知前后
以上都是 recover 或者下线的过程,原始的论文似乎不会考虑在任何一个位置 Join,只会在尾部插入。这样的话似乎同步完数据然后就可以加入了。Join 会复杂很多,这篇论文介绍了一种新的方式:back-propagation(注意,不是传播写入完成 ACK),这种方式让任意插入的系统 recover。