RISC-V GetStart
RISC-V and C Toolchains
ISA && RISC-V
指令(Instruction) 是 CPU 的 primitives operations, 我们可以知道有这样的保障:
- 指令顺序执行
- 每条指令完成很轻量的、基本的操作
- 每条指令会作用在 operand 上,甚至可能变更指令的顺序。
CPU 会有某个 “family”, 实现了它自己的 instruction set。这个独特的 instruction set 又实现了某个具体的 ISA,例如:
- ARM, Intel x86, MIPS, RISC-V, IBM/Motorola PowerPC (old Mac), Intel IA64
RISC-V 希望保证简洁的特性(以下摘自 RISC-V v2p1):
RISC-V的不同寻常之处,除了在于它是最近诞生的和开源的以外,还在于:和几乎所 有以往的ISA不同,它是模块化的。它的核心是一个名为RV32I的基础ISA,运行一个完整 的软件栈。RV32I是固定的,永远不会改变。这为编译器编写者,操作系统开发人员和汇 编语言程序员提供了稳定的目标。模块化来源于可选的标准扩展,根据应用程序的需要, 硬件可以包含或不包含这些扩展。这种模块化特性使得RISC-V具有了袖珍化、低能耗的特 点,而这对于嵌入式应用可能至关重要。RISC-V编译器得知当前硬件包含哪些扩展后,便 可以生成当前硬件条件下的最佳代码。惯例是把代表扩展的字母附加到指令集名称之后作 为指示。例如,RV32IMFD将乘法(RV32M),单精度浮点(RV32F)和双精度浮点 (RV32D)的扩展添加到了基础指令集(RV32I)中。
RISC-V basic: RV32I
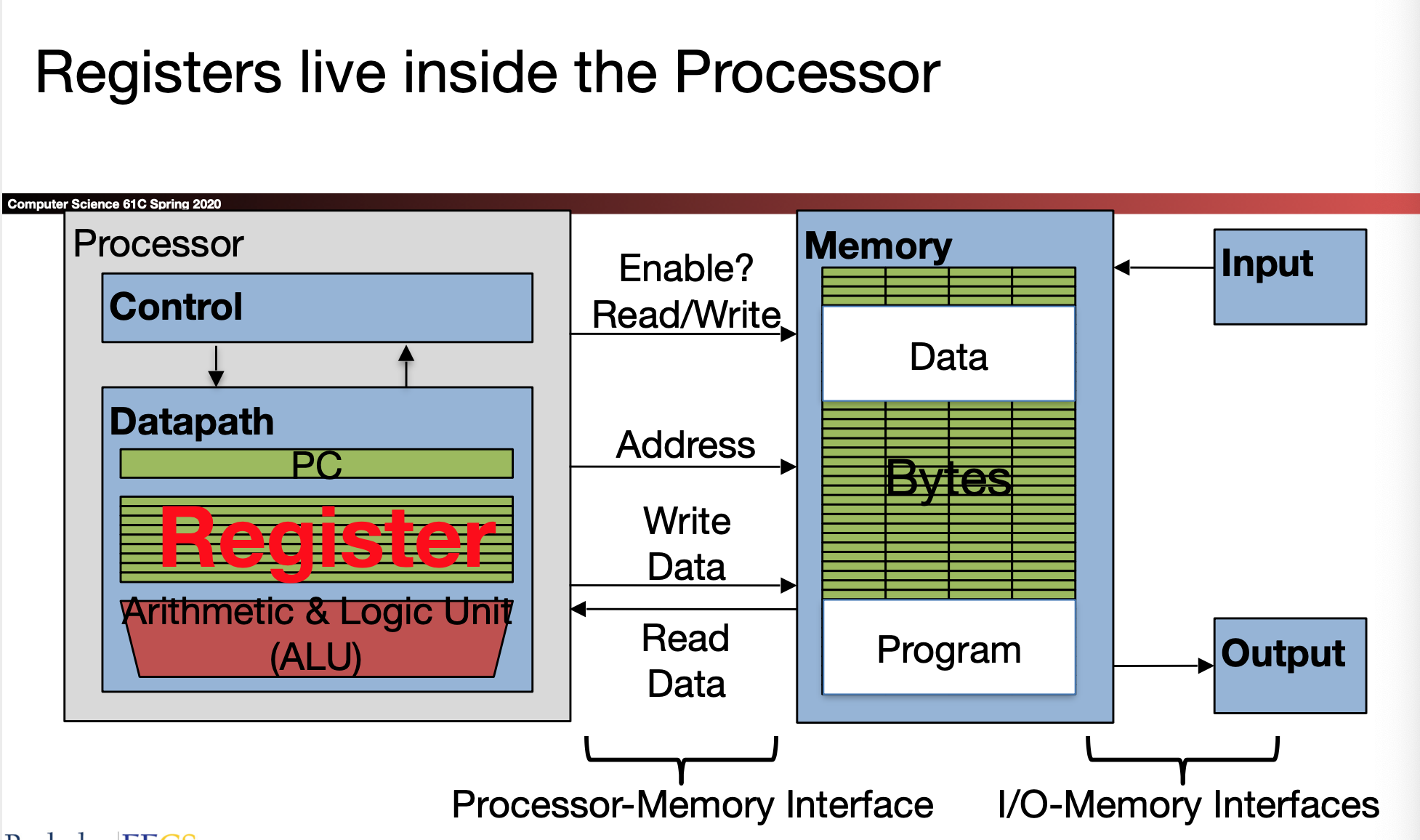
- Registers: 32 words,每个长度是 32bits。(非基础的有16bit的压缩指令和 64bit 甚至更大的指令)
- Memory: Huge
访问 registers 和 memory 的速度大概差距 100-500倍
RISC-V 有 32个 RV32I 寄存器, 名称是 x0-x31
x0 is special, always holds the value zero
• So really only 31 registers able to hold variable values
注意 6.828 可能会有对应的 name, 下面对原因有一定的解释
Registers are also given symbolic names:
These will be described later and are a “convention”/“ABI” (Application Binary Interface): Not actually enforced in hardware but needed to follow to keep things consistent
Register 本身是没有类型的(废话)。
- RISC-V does not require that integers be word aligned
- 但是,如果不 align,对 atomicity 支持缺乏,同时 load 操作会慢上很多。
So in practice, RISC-V requires integers to be aligned on 4-byte boundaries
RISC-V Instructions
Instructions are fixed, 32b long (话说似乎 b 是 bit, B 是 Byte)

1 | add x1, x2, x3 |
x1 = x2 + x3 与上面等价. add 是 operation code (opcode), x1 是 destination register, x2 x3 是第一、第二个 operand register。以上的格式被称为 assembly comment syntax
x0 在 RISC-V 中代表 no-op, 就是“读是0,什么都不写”。实际上,RISC-V 核心的指令很精简,它依靠 x0 来实现很多伪指令。
立即数(immediates) 和常量构建
1 | addi x3, x4, -10 |
相当于 f = g - 10,当然这里有个问题就是这个立即数能有多大呢? RISC-V 32 中指令是定长的,虽然我们有压缩指令之类的支持,但是 imm 占用的 bytes 仍然是受限的,显然,它没有能力表示 32 位长度的数据:一个 I-type 的指令只有 12bits 来保存立即数。
那肯定我们还需要构建一个 32bit 的数吧!可以看看如下:
图 2.1 剩下的两条整数计算指令主要用于构造大的常量数值和链接。加载立即数到高 位(lui)将 20 位常量加载到寄存器的高 20 位。接着便可以使用标准的立即指令来创建 32 位常量。这样子,仅使用 2 条 32 位 RV32I 指令,便可构造一个 32 位常量。向 PC 高位加 上立即数(auipc)让我们仅用两条指令,便可以基于当前 PC 以任意偏移量转移控制流或 者访问数据。将 auipc 中的 20 位立即数与 jalr(参见下面)中 12 位立即数的组合,我们 可以将执行流转移到任何 32 位 PC 相对地址。而 auipc 加上普通加载或存储指令中的 12 位立即数偏移量,使我们可以访问任何 32 位 PC 相对地址的数据。
data transfer
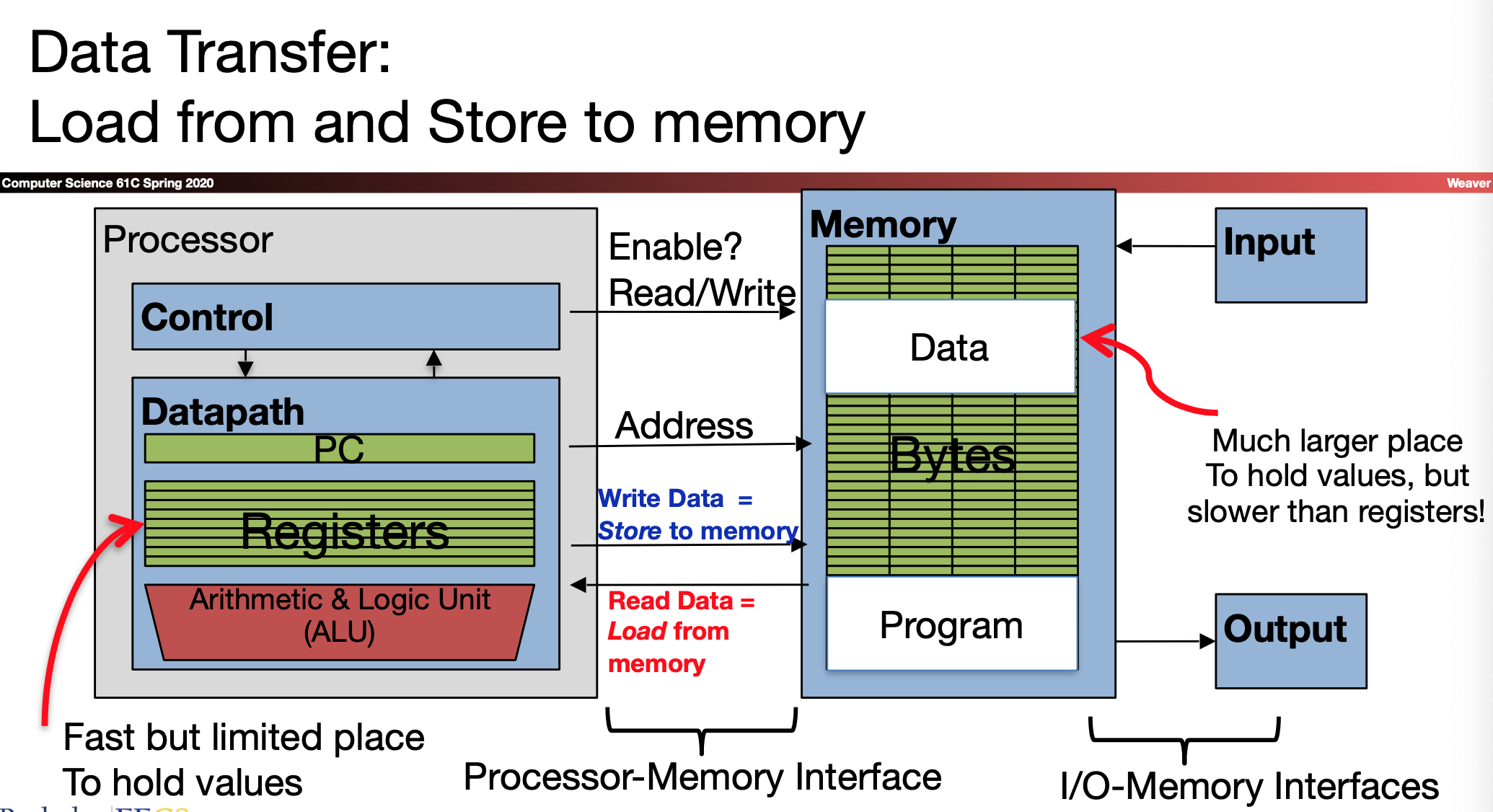
很正常的思路是,要从内存 — 寄存器读写数据,而且地址是 32位的 (肯定不能给立即数了)
- 1 word = 4bytes
- Data typically smaller than 32 bits, but rarely smaller than 8 bits
- Memory addresses are really in bytes, not words
下面的lw sw 表示 load store 单位为 word 的数据
注意,这里提到 RISC-V 是 Little-Endian 的,这意味着我们从下头读 0x000408012
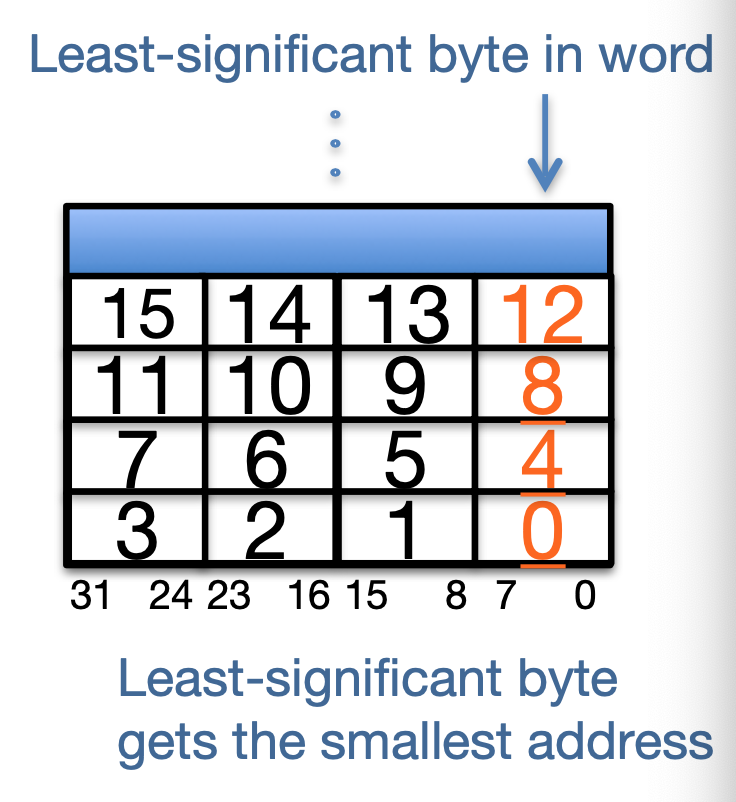
随便从知乎找的图
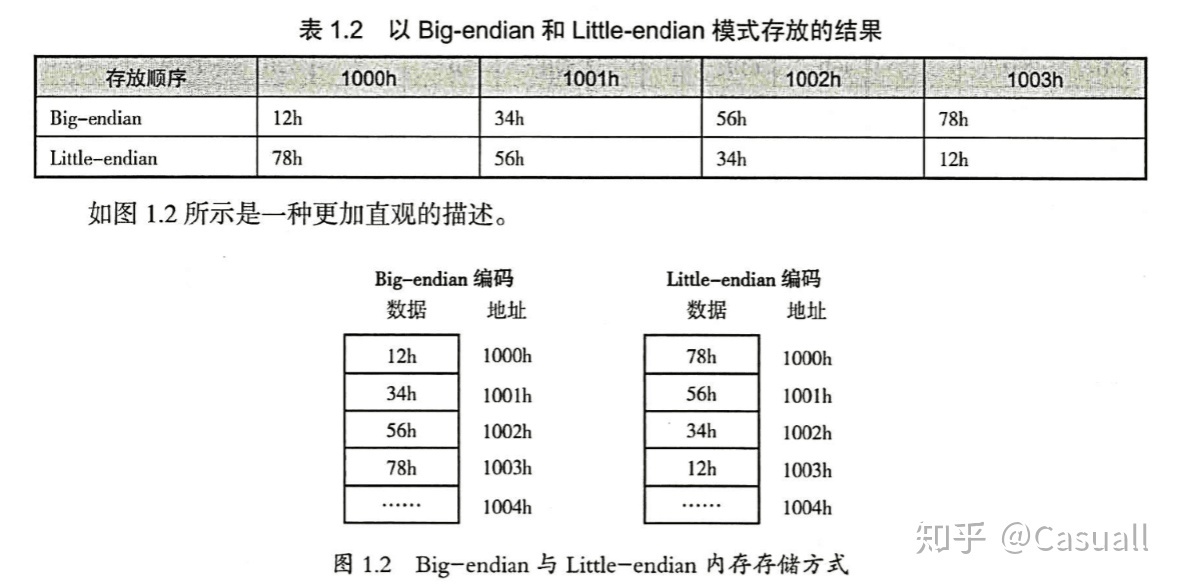
也就是说,一个 int 0x03f5
是:
- f5 : 0
- 03 : 1
- 00 : 2
- 00 : 3
实际上 BigEndian LittleEndian 可以看之前 Post 的那篇文章: https://zhuanlan.zhihu.com/p/254144597

int 如果是 32 bit 的,那么 1word = 4byte, 显然合理对吧,上面这段也很好懂。
- lw 是 reg <- memory on address
- sw 是 reg value -> memory on address
还有 lb sb , 很好懂对吧,就不多解释了。
RISC-V also has “unsigned byte” loads (lbu) which zero extend to fill register. Why no unsigned store byte sbu?
Logical Instruction
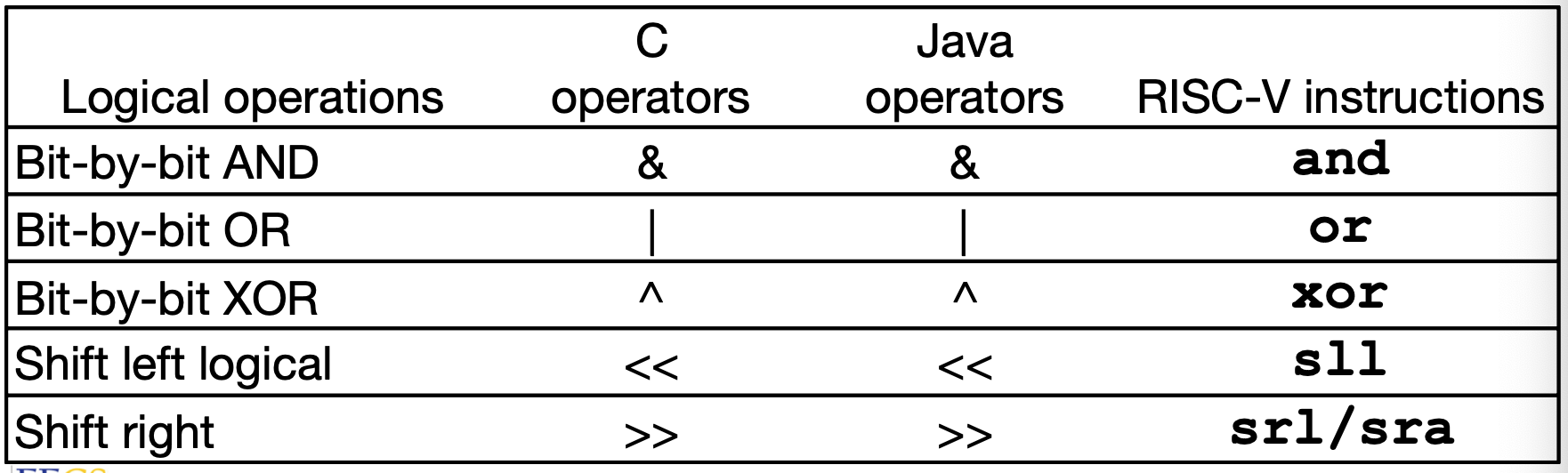
注意算数移位和逻辑移位:对于signed, 算数移位会把符号位移动下来。
然后在 RISC-V 里面,可以把它们最后一个字母当成区分 logical 和 arithmetic 的标志
分支指令
1 | beq register1,register2,L1 |
if (x1 == x2) goto L1, 其中 L1 是一个 Label.
分支指令
1 | beq register1,register2,L1 |
if (x1 == x2) goto L1, 其中 L1 是一个 Label. S
beq 这种 b 开头的指令中,b 是 branch 的缩写,beq 就是 Branch on EQual,同理可以推测:
- blt: branch on less than
- bne: branch on not equal
- bltu Branch on Greater Than Unsigned
值得玩味的是,RISC-V 里面不存在greater ,它会被转成 less 。
上面的代码可以被视为 conditional branch, 此外我们还可以关注 unconditional branch. 也就是 always jump 的 case,这里有语句 j,即 jump。jal 和 jalr 这两个指令,jal 是 jump and link。它的形式大概是:
1 | jal rd offset |
- jal 会把 PC+4 写入到 rd 寄存器中,作为保存“调用者” ,然后把内容跳转到 offset
所以它可能的使用场景是:
- 无条件的跳转(代码里写 goto)
- 调用别的函数(上下文写到rd里面)
如果是 jalr 就是 PC + imm 变成 rs + imm
再论计算
有什么不同之处?首先,RISC-V 中没有字节或半字宽度的整数计算操作。操作始终 是以完整的寄存器宽度。内存访问需要的能量比算术运算高几个数量级。因此低宽度的数 据访问可以节省大量的能量,但低宽度的运算不会。ARM-32 具有一个不寻常的功能,对 于大多数算术逻辑运算中的一个操作数,你可以选择对它进行移位。尽管这些指令的使用 频率很低,但它使数据路径和数据通路更加复杂。与此相对的是,RV32I 提供了单独的移位指令。
RV32I 也不包含乘法和除法,它们包含在可选的 RV32M 扩展中(参见第 4 章)。与 ARM-32 和 x86-32 不同,即使处理器没有添加乘除法扩展,完整的 RISC-V 软件栈也可以 运行,这可以缩小嵌入式芯片的面积。MIPS-32 汇编程序可能用一系列移位以及加法指令 来替换乘法,以提高性能,这可能会使程序员看到处理器执行了汇编程序中没有的指令, 进而造成混淆。RV32I 可以忽略了这些特性:循环移位指令和整数算术溢出检测,这两个 特性都可以用若干条 RV32I 指令来实现(参见第 2.6 节)。