CALL: libc 和 C++ 标准库
CALL 是 (Compiler/Assembler/Linker/Loader)的简称。如果你和 C/C++ 打过交道的话,没有理由会对这几个词太陌生。所以今天这是一篇水文。
Levels of Representation/Interpretation
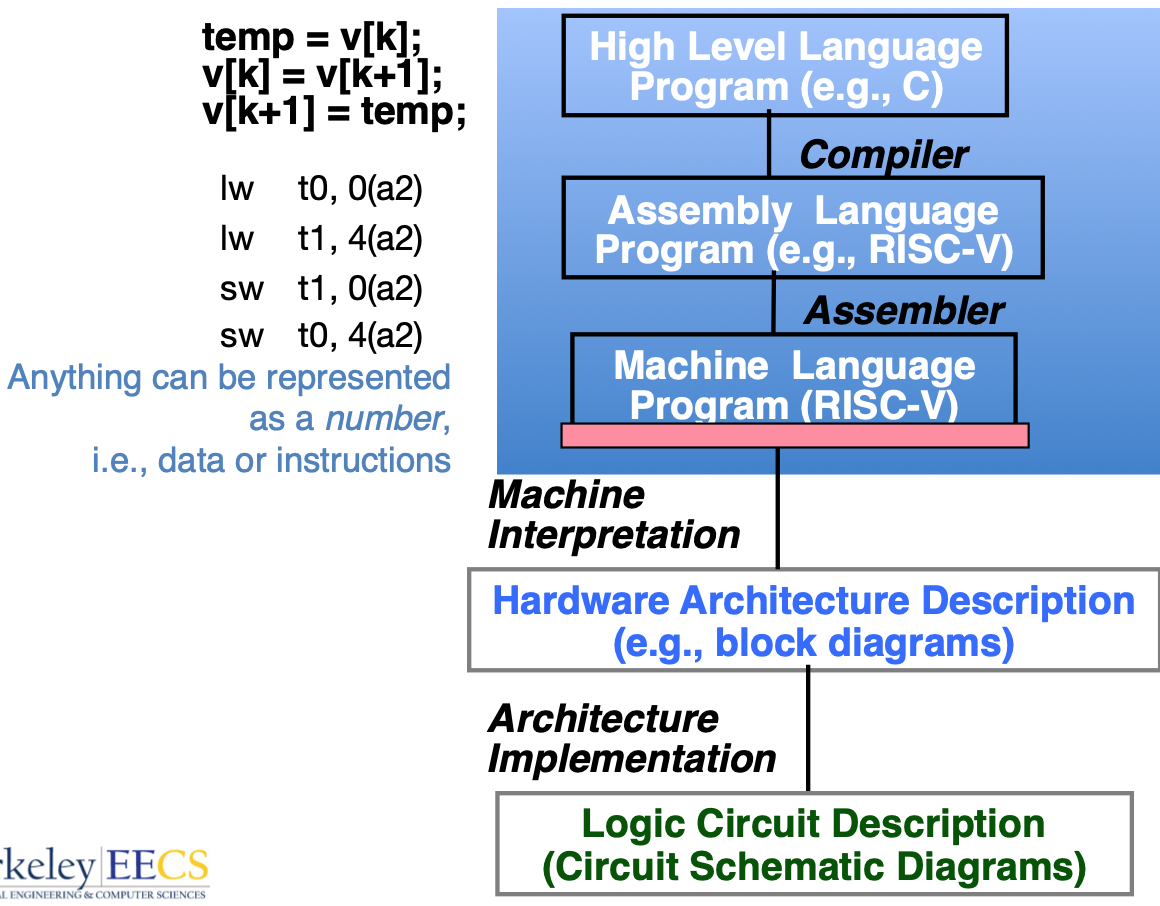
- “XX 是一门 解释型语言”
- “XX 是编译型语言”
抛开正确性,一定程度上我们可以尝试填空(Python / C++、Go)并且知道:
- Python 可能会运行一个解释器(官方是 CPython, 可能有 Pypy 这样的),然后解释 Python 的字节码
- C++、Go 会编译成 binary, 就我理解,这是“机器上的字节码”(这是跟 Python 字节码对应的,实际情况可能手是反过来的), 然后执行。这其中 Go 可能会有 Runtime、GC 这样的开销。
但是同时,Python 也能通过一些方式打包成 exe (虽然很巨大),同时 LLVM 这些层次的引入让我们的理解模糊了起来。所以我们要明确一下这个 Level。

- Language translation gives us another option
- In general, we interpret a high-level language when efficiency is not critical and translate to a lower-level language to increase performance
- Although this is becoming a “distinction without a difference” Many intepreters do a “just in time” runtime compilation to bytecode that either is emulated or directly compiled to machine code (e.g. LLVM)
所以这个问题实际上是很含糊不清的,第三点里面 JIT 等的引入更让事情扑朔迷离了起来。具体其实可以参考这个链接里的说法:https://www.zhihu.com/question/19608553。
一般被称为“解释型语言”的是主流实现为解释器的语言,但并不是说它就无法编译。例如说经常被认为是“解释型语言”的Scheme就有好几种编译器实现,其中率先支持R6RS规范的大部分内容的是Ikarus,支持在x86上编译Scheme;它最终不是生成某种虚拟机的字节码,而是直接生成x86机器码。
实际上解释器的性能劣势也不一定是一种坏事,像我去年去 PyCon 听的“慢解释是一种优势”,虽然有点破罐子破摔的味道,但是如果你在 C/C++ 下开 asan/valgrind 或者带 gcc -g, 和 Go 这种带 Runtime 的、V8这些可以提供的debug比较,难免会有羡慕的想法。
Interpreter provides instruction set independence: run on any machine
就是这样。
CALL chain
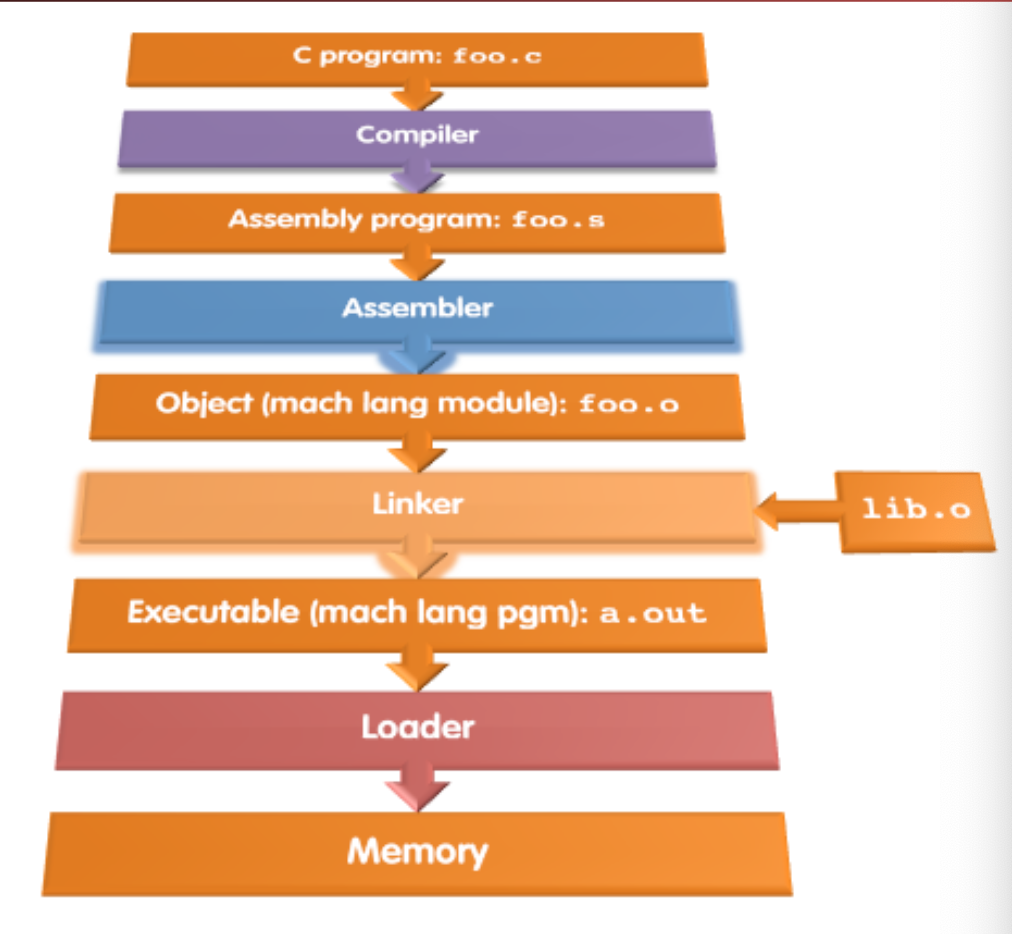
这是一张水图。可能还要处理一下预处理之类的过程,但是大概流程是这样没错。
Compile
Compile 的过程大概是
- Lexer
- Parser
- Semantic Analysis and Optimization
- Code generation
不过看上面转的那篇文章,似乎形式有变,这方面我不是很了解。Lexer/Parser 的部分可以参考我之前的 Lex/Yacc 入门。总之,我们现在把源代码编译后可以转化为一种对应的 IR, 即 nmsl.c -> nmsl.S.
Assembler
Assembler 接下来会nmsl.s -> nmsl.o.
- Reads and Uses Directives
- Replace Pseudo-instructions
- Produce Machine Language rather than just Assembly Language
- Creates Object File
顺便给出这个 part 一个很有意思的 slide:

ELF
- object file header: size and position of the other pieces of the object file
- text segment: the machine code
- data segment: binary representation of the static data in the source file
relocation information: identifies lines of code that need to be fixed up later
symbol table: list of this file’s labels and static data that can be referenced
- debugging information
- A standard format is ELF (except Microsoft) http://www.skyfree.org/linux/references/ELF_Format.pdf
这个我觉得还是 csapp 写得好…总之生成的目标文件会满足这样的形式。
Linker
Combines several object (.o) files into a single executable (“linking”)
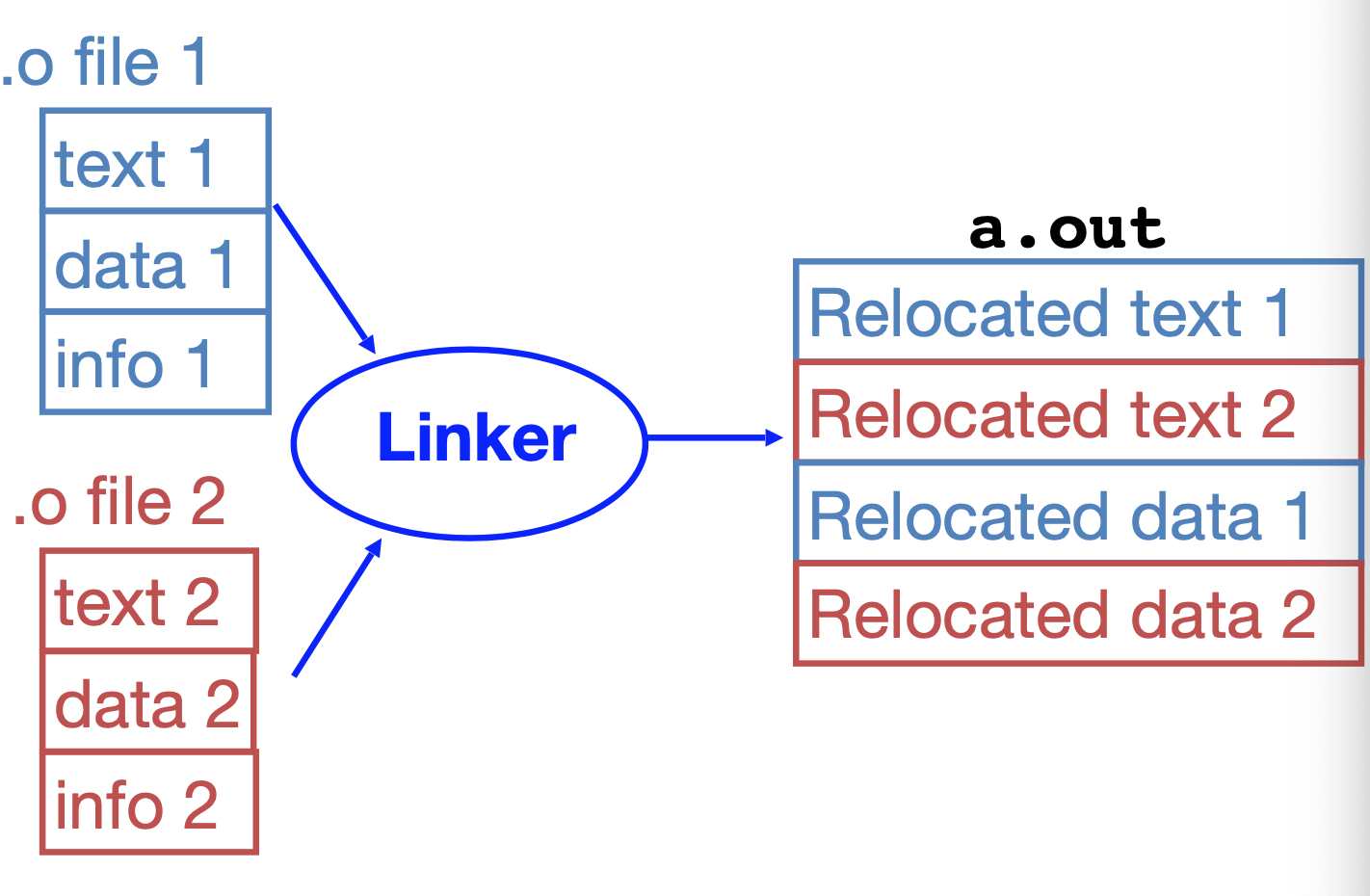
- Step 1: Take text segment from each .o file and put them together
- Step 2: Take data segment from each .o file, put them together, and concatenate this onto end of text segments
- Step 3: Resolve references
- Go through Relocation Table; handle each entry
- That is, fill in all absolute addresses
这段我感觉 CSAPP 讲的稍微详细一些。
在应用层面上,这里其实还涉及(不一定是这里引入的)name mangling,calling convention这种 C/C++ 相关的问题,所以可能 extern "C" 在这种情况下就相对很好理解了。
Loader
When one is run, loader’s job is to load it into memory and start it running
In reality, loader is the operating system (OS)
- loading is one of the OS tasks
- And these days, the loader actually does a lot of the linking: Linker’s ‘executable’ is actually only partially linked, instead still having external references
这里可以参考 CSAPP 里面链接的时机相关的概念。
libc/libc++
qsort 是一个 <cstdlib> 下的函数,如果你去 libc++ 找的话,会发现事情好像不太对:
https://github.com/llvm-mirror/libcxx/blob/7c3769df62c0b3820130aa868397a80a042e0232/include/cstdlib
这里只有 using 和函数声明,没有对应的实现。
实际上 C++ 的标准库(以 libc++) 为例,可能会根据模版生成需要的函数/类。所以我们可以看到对应的一些源代码。
C语言的库函数实际上通常以链接库的形式在 libc 中提供,链接的时候我们找到:https://stackoverflow.com/questions/26277283/gcc-linking-libc-static-and-some-other-library-dynamically-revisited