Arrow Data System
Apache Arrow 是由 Pandas 作者 Wes McKenny 主导的一款以内存为主体,辐射到数据交换、内存计算、多格式多平台转换的库。它的大概 Idea 可以见下图,写的非常直观。
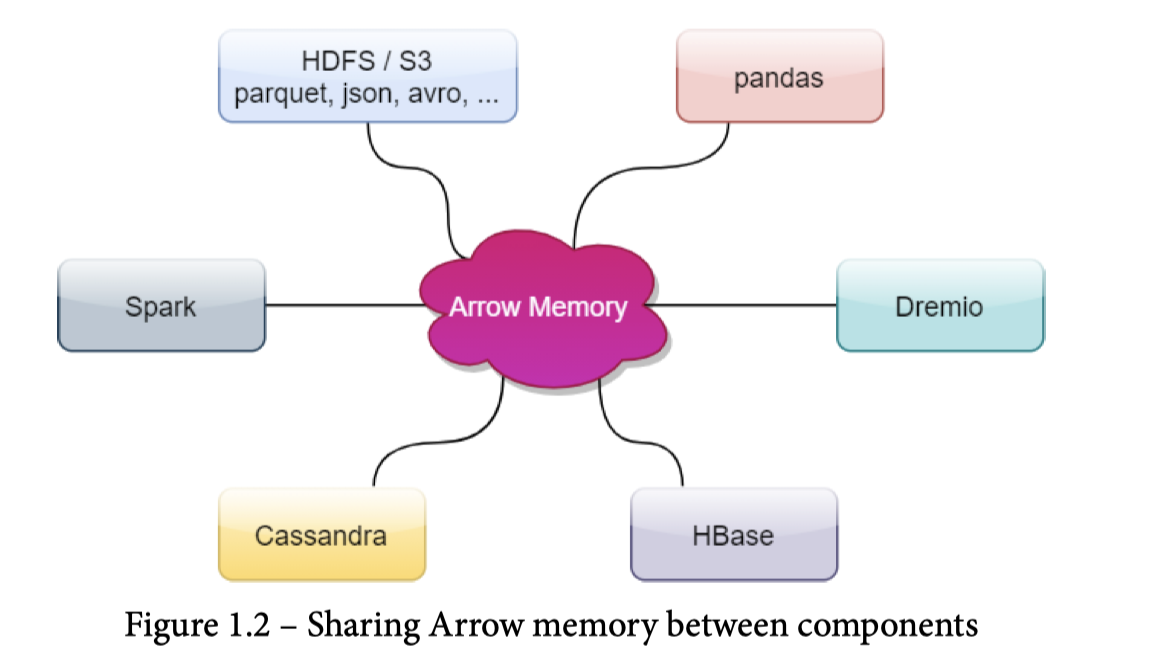
我们简单介绍一下 Arrow 的内容:
- 一切的核心,Arrow 的内存 Columnar 结构(见官方介绍 [1] 和我之前的博客 [2])
- 在这上面的 ExtensionType,支持用户定义自己的类型,包括 Tensor 这样的类型
- IPC File
- 数据交换上成功的工具
- Arrow JDBC Converter [3]
- ADBC [4]
- Arrow Flight [5] 和基于 Arrow Flight SQL [6]
- 一些计算相关的 API
- 向量化计算函数的 Compute [7]
- Push-based Execution 的 Acero [8]
- LLVM Codegen 的执行 Gandiva [9] (已经快死了)
- SQL Planning 的 Datafusion [10]
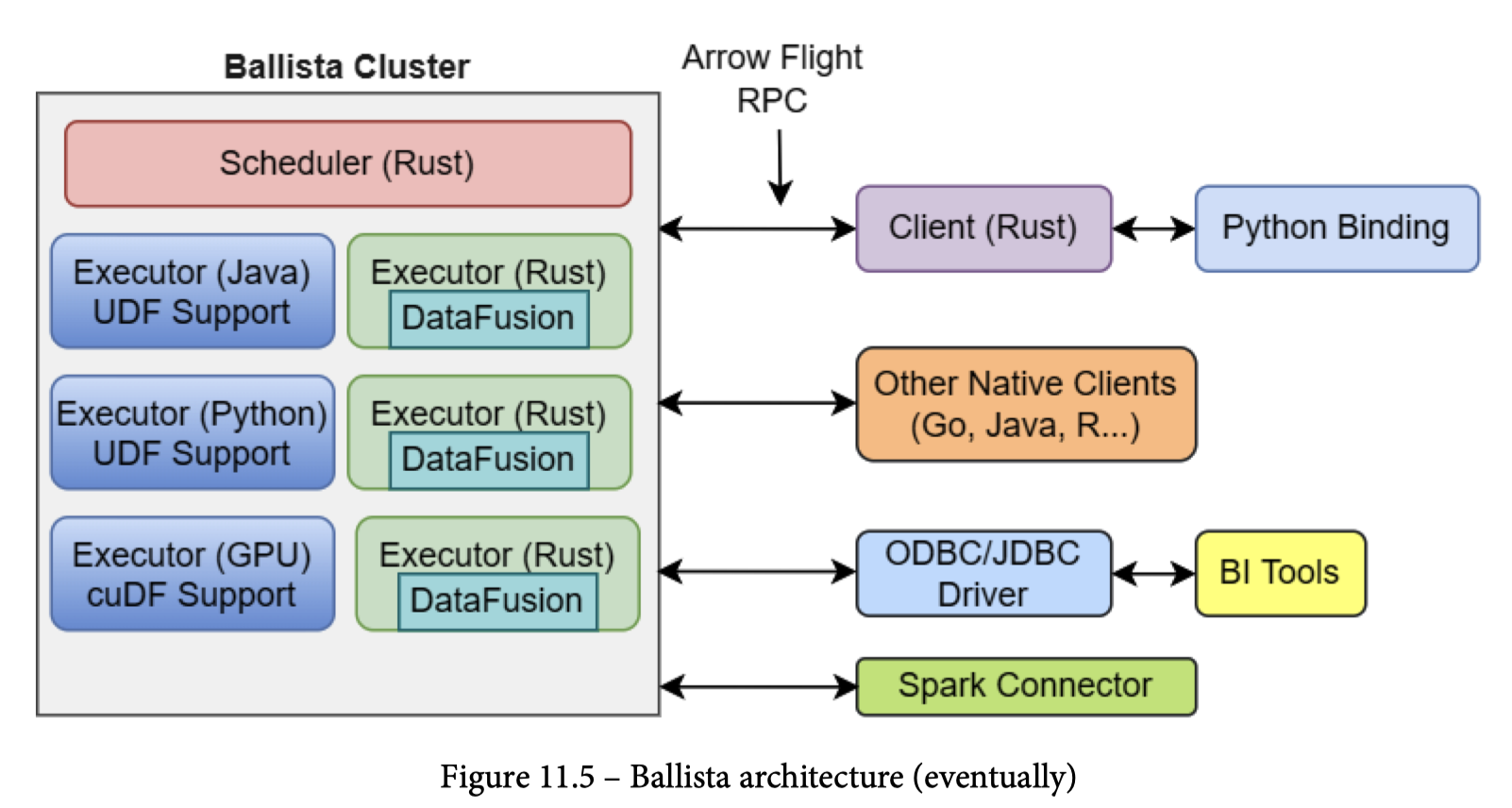
- 分布式执行的 Ballista
- 一些数据源和写入相关的 API
- FileSystem: 对文件来源的层次的 Unify [11]
- Dataset API: 对某个 FileSystem 下的多个文件 / 分区 / 数据格式的抽象,也可以加上 Project, Filter 等操作 [12]
就我个人评价而言,Arrow 在每个领域中很难说得上是性能最好的,但是胜在提供了比较完善的解决方案,api 相对侵入性也不会很大。很多地方扩展性比较强,例如提供了
ExtensionType(可以用ExtensionType去支持机器学习需要的 Tensor 这样的类型 [16] ),也允许用户按照 API 去 Inject 自己想要的东西。Arrow Flight 总体上也是比较开放的。这些合起来的原因和方便的生态导致 Arrow 其实被较为广泛的使用了,包括 Snowflake [13] 和 Bigquery [14] 这几家都在用,开源的数据项目,像 Ray 这样的也会积极拥抱 Arrow。DuckDB 甚至给支持 Arrow 的转换写了一篇博客 [15]。总的来说,Arrow 主要为生态开放的做了不少工作,虽然核心的性能不是最好的(参见 Velox 和诸多的大厂开放的引擎,一个比较经典的例子是 Firebolt,基于开源的引擎自己拼了一个数据仓库出来),但是因为很强的通用性和比较完善的生态,现在已经侵入了很多人的系统。
Core: In Memory Format
关于 Arrow 的 In Memory Format,之前尝试介绍过了:
- https://blog.mwish.me/2023/05/04/Type-and-Array-in-Columnar-System/
- https://blog.mwish.me/2022/10/04/Parquet-Part2-arrow-Parquet-code-path/
这个地方本身没啥好说的,值得说的都在上面的内容了
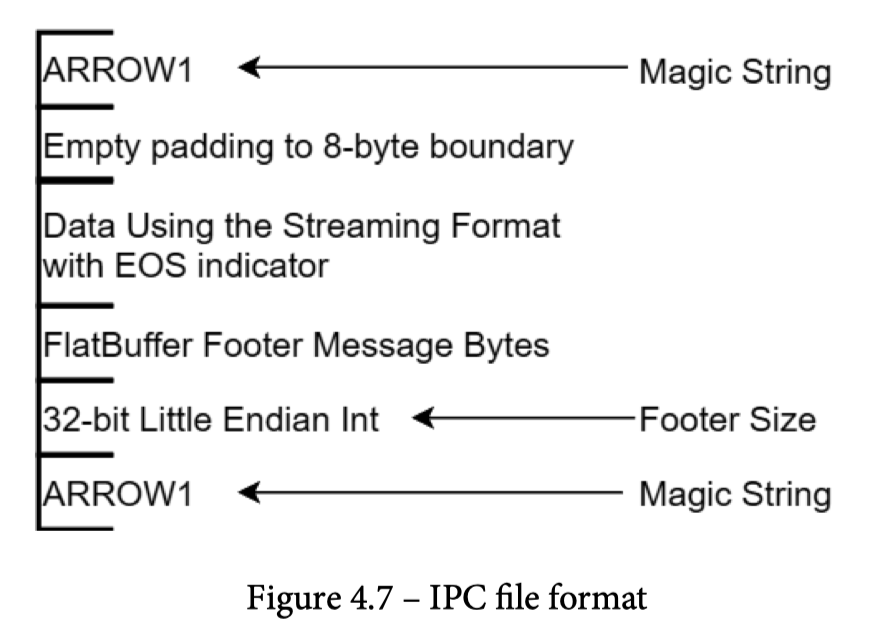
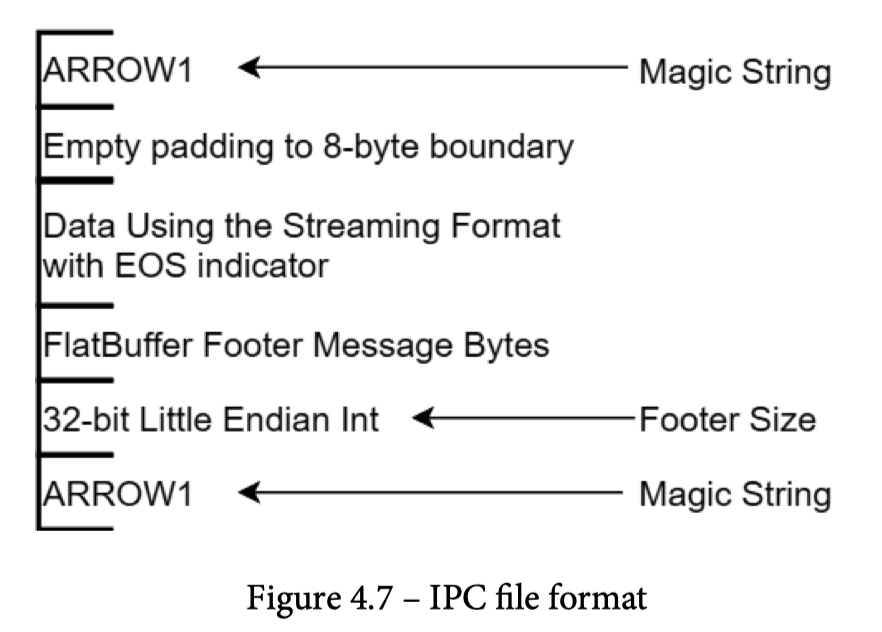
IPC Format
IPC File 格式 基本等价于 内存中 Format 的 RecordBatch,这里它会尽量在 package 里面做 alignas (比较有意思和关联的 patch 看这个:https://github.com/apache/arrow/pull/35565/files ,在计算层要求输出是满足 align 的),然后让数据能够被 Zero-Copy 的解析到 Arrow 格式上。这里应该关心可能的数据和元数据
IPC Format 有两种格式:
- Streaming Format: Appendable,必须整个解析
- Random Access: 一整个 RecordBatch 写的文件
在协议上,这里允许(不定大小的)下列元素:
- Schema: 文件或者 Stream 的 Schema(这里需要注意,ipc 既可以写在文件里,又可以为了整个流来设置)
- DictionaryBatch
- RecordBatch
在定义的格式中,基本的元素是 Message,下面是对应的 Message Format:
这里元数据由
FlatBuffer组成( https://blog.mwish.me/2022/01/14/format-thinking/ )它的格式定义在 https://github.com/apache/arrow/blob/main/format/Message.fbs 中。这里包括:1
2
3
4
5
6table Message {
version: org.apache.arrow.flatbuf.MetadataVersion;
header: MessageHeader;
bodyLength: long;
custom_metadata: [ KeyValue ];
}Stream
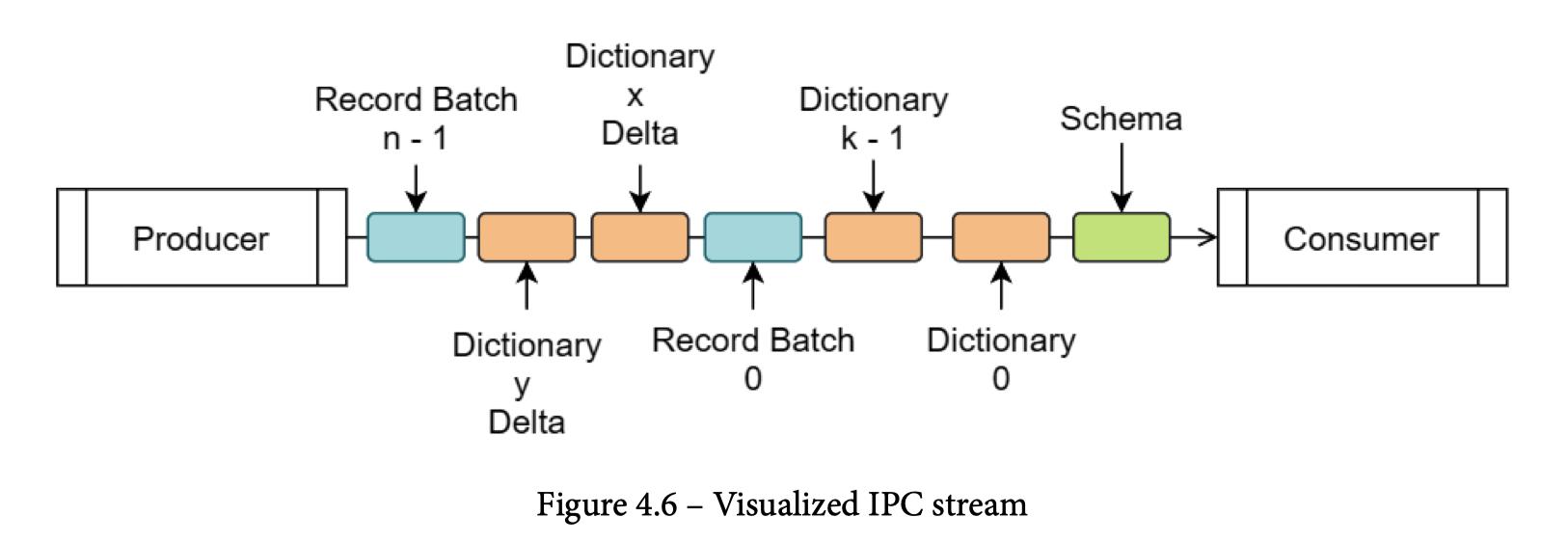

为什么之前强调了是文件/Stream的 Schema 呢,因为它本身是没有文件(内)级别的 Schema Evolution 的
比较重要的是 Record Batch Message,这里会在写文件和读取的时候都保证 alignment (8B,也可以手动指定),这里有:https://arrow.apache.org/docs/format/Columnar.html#recordbatch-message
这部分实现的内容很像 ORC 那套格式。
同时,这部分字典格式是 INCREMENT 的(看上面的 DICTIONARY DELTA),增量的字典带来了一部分的扩展性:https://arrow.apache.org/docs/format/Columnar.html#dictionary-messages
File
Extension Type
用户可以以 Key-Value Metadata 的形式去做 Schema 上的扩展,GeoArrow,Tensor 这些,都可以收益于Arrow 包含的扩展:https://arrow.apache.org/docs/format/Columnar.html#extension-types
数据交换的工具
如果说之前的部分是内存和 Stream 层面的 kernel,那么下面来介绍数据交换。提到这部分,可能首先想起的是 IPC 层 CWI 的相关的论文 「Don’t Hold My Data Hostage – A Case For Client Protocol Redesign」。其实和文章结论比较接近,但是这部分其实比较有意思,也给用户可以科普一下 client-side 的 dirty work 和复杂度。
Arrow Flight
Arrow Flight 其实是在 grpc 和 protobuf 上开了一套洞的 Arrow 传输协议。
Q: Arrow Flight 和 Arrow Streaming Format 有什么关系?
A: Arrow Flight 主要工作在传输协议和分布式上
如图,下面是 Arrow Flight 的工作模式
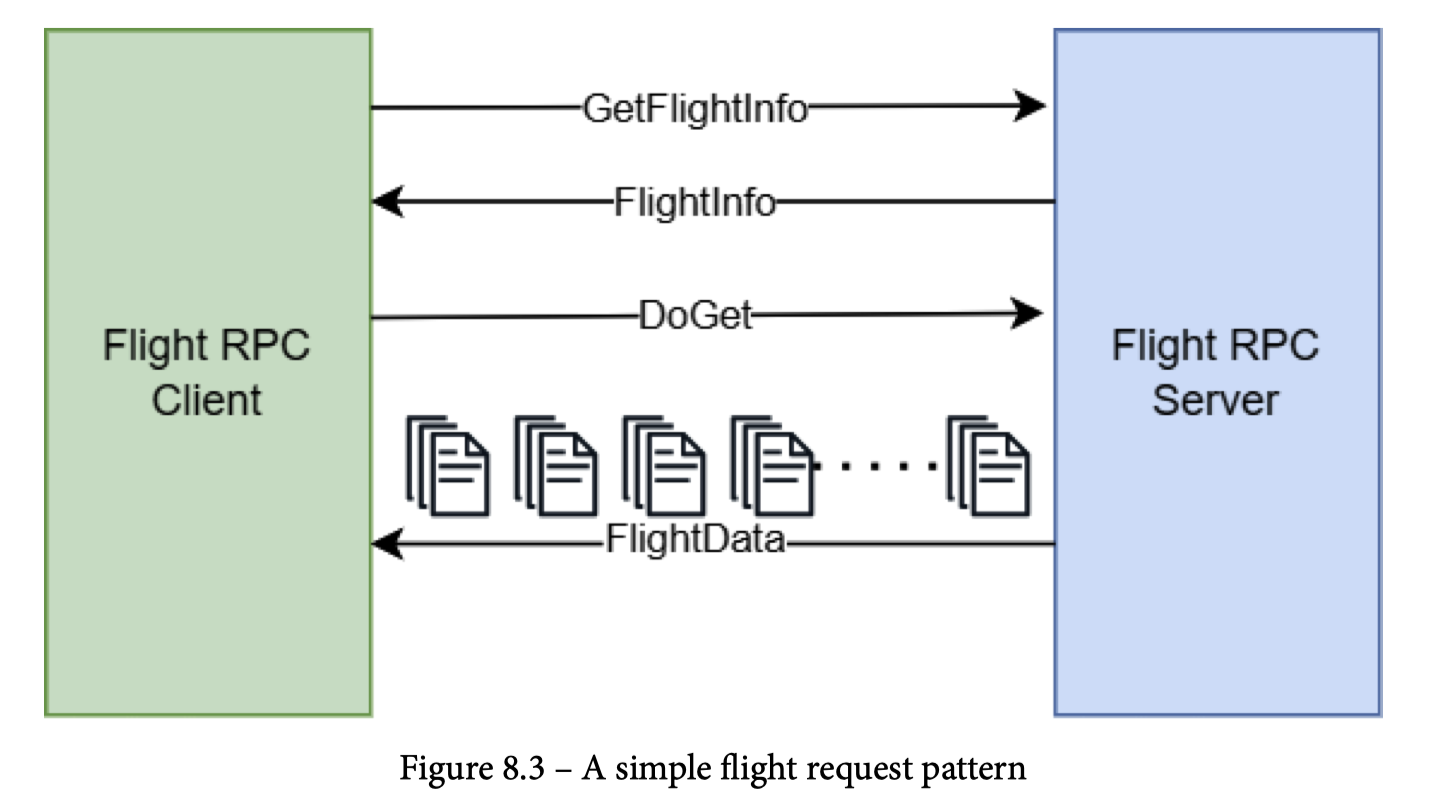
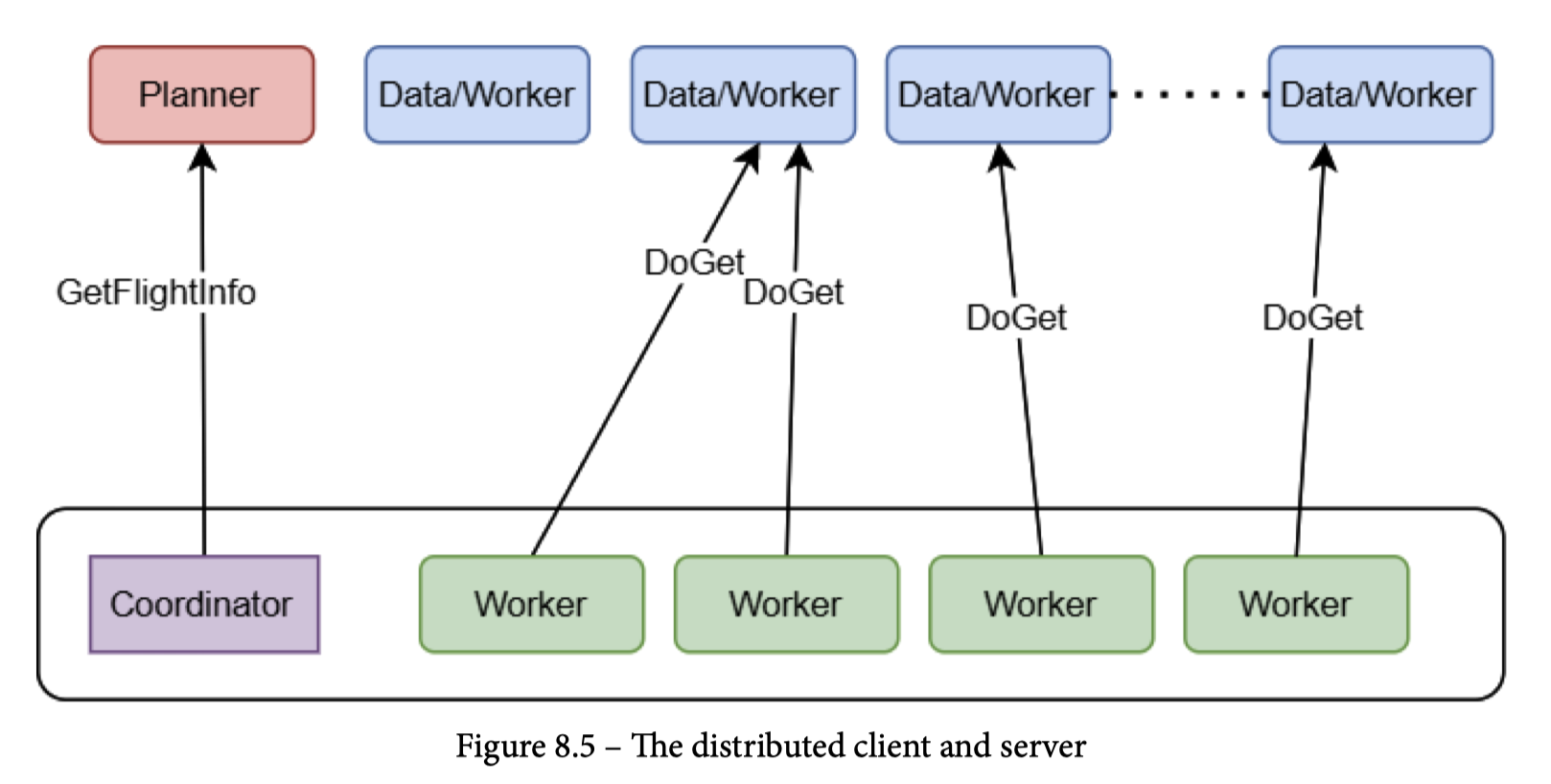
如图,Arrow Flight 允许以如下方式去捞一个 Dataset,和这篇( https://zhuanlan.zhihu.com/p/340520316 )有异曲同工之妙(废话,AP 做法都差不多)
在代码实现上,Flight 在 Protobuf 代码上开了个洞,尽量让他解析 Arrow 数据的时候,被 Arrow 拦截,做到实现上的 Zero-copy (众所周知,pb 本身不是为了传输大对象设计的)。
Flight 还支持一些非 gRPC 的访问,比如协议上准备兼容
From JDBC Converter to Others
JDBC / ODBC 实际上是 90 年代起数据交换的事实标准,如果考虑到使用的话,流程如左图:
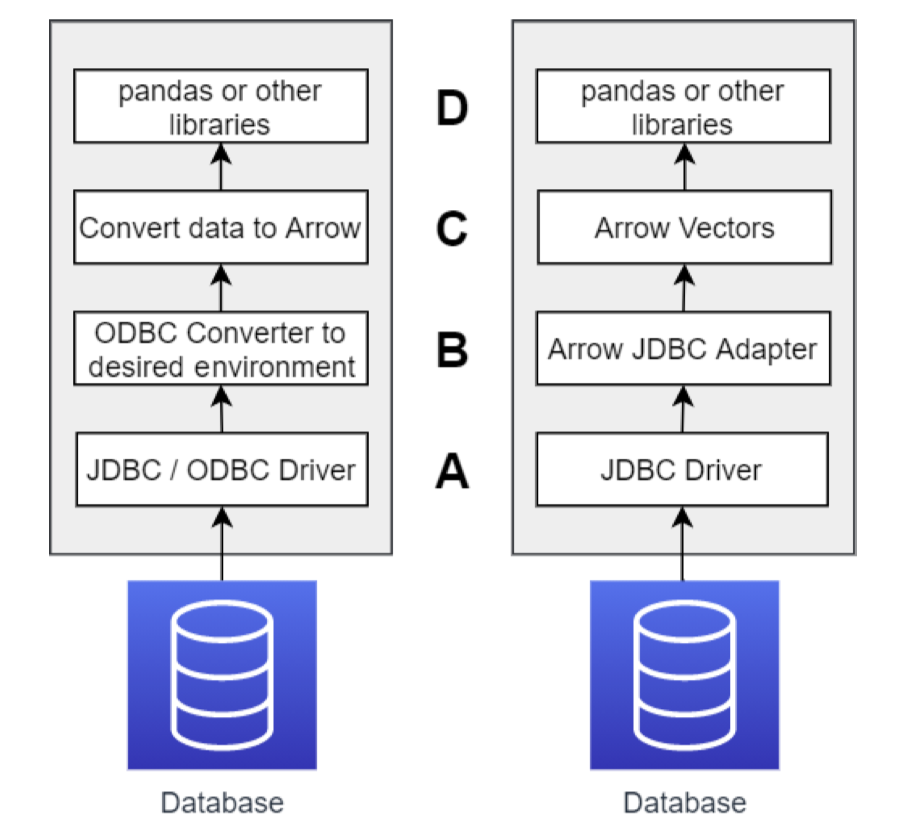
右图首先提供了一种 JDBC Client 的交互方式。即首先需要转一层。当然这并不能让人满意,所以接下来出现了下面的数据流
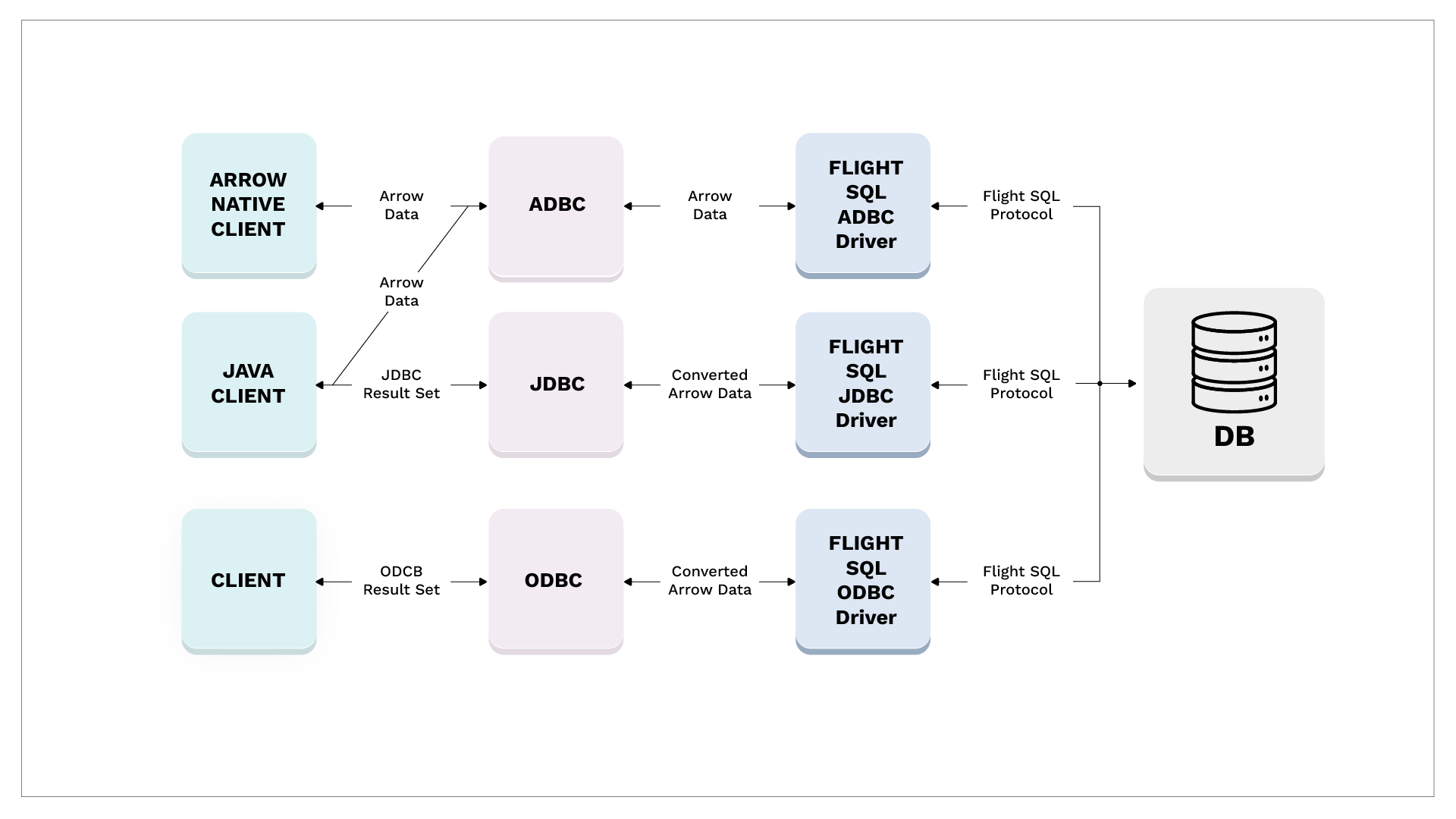
- ADBC: 启发自 DuckDB 作者的论文 「Don’t Hold My Data Hostage – A Case For Client Protocol Redesign」。相当于列式的 JDBC。需要注意的是,这个格式虽然比较有潜力,但是才 0.4,可能需要等他自己发展一下
- Driver: 类似数据库的 Driver,能够把 Arrow 转成 JDBC / ADBC
- Flight SQL Protocol: Flight 之上的 Catalog / SQL 框架。与实现大概无关,愿景是一个通用协议层
说实话这套东西竞争力还挺强的,BigQuery, Snowflake, DataBricks 都或多或少用了这套东西. 主要问题还是用数据库的 JDBC Driver 或者甚至行的接口来处理还是比较菜的。需要专门的接口来 handle 这套内容。
计算相关的工具
Compute & Acero
在 Arrow 的核心中提供了 Arrow Compute 这样的工具,它的基本逻辑和定位见之前的博客:https://blog.mwish.me/2023/05/27/Arrow-Compute/
Compute 定位的是向量化的算子( Function )。
虽然 Compute 本身可能没有 Expression 的概念,但是 Arrow 为了别的地方使用,在 Compute 里面实现了 Expression。几乎所有数据库都有 Expression 相关的概念,它可以是:
- LiteralValue Or Datum
- FieldRef of input Datum
- Compute Function,Function Member 都是别的 Expression

Acero 是构建在这套系统上的 Operator 层。定位上,Acero 是一个 Push-Based 的算子层,虽然代码写的不是很细,但是比较易懂:
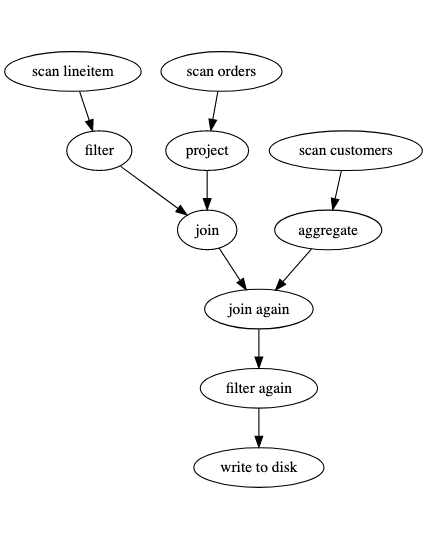
这里可以根据 Declaration 生成一组对应的 ExecPlan / ExecNode,然后下层来驱动数据流的执行。
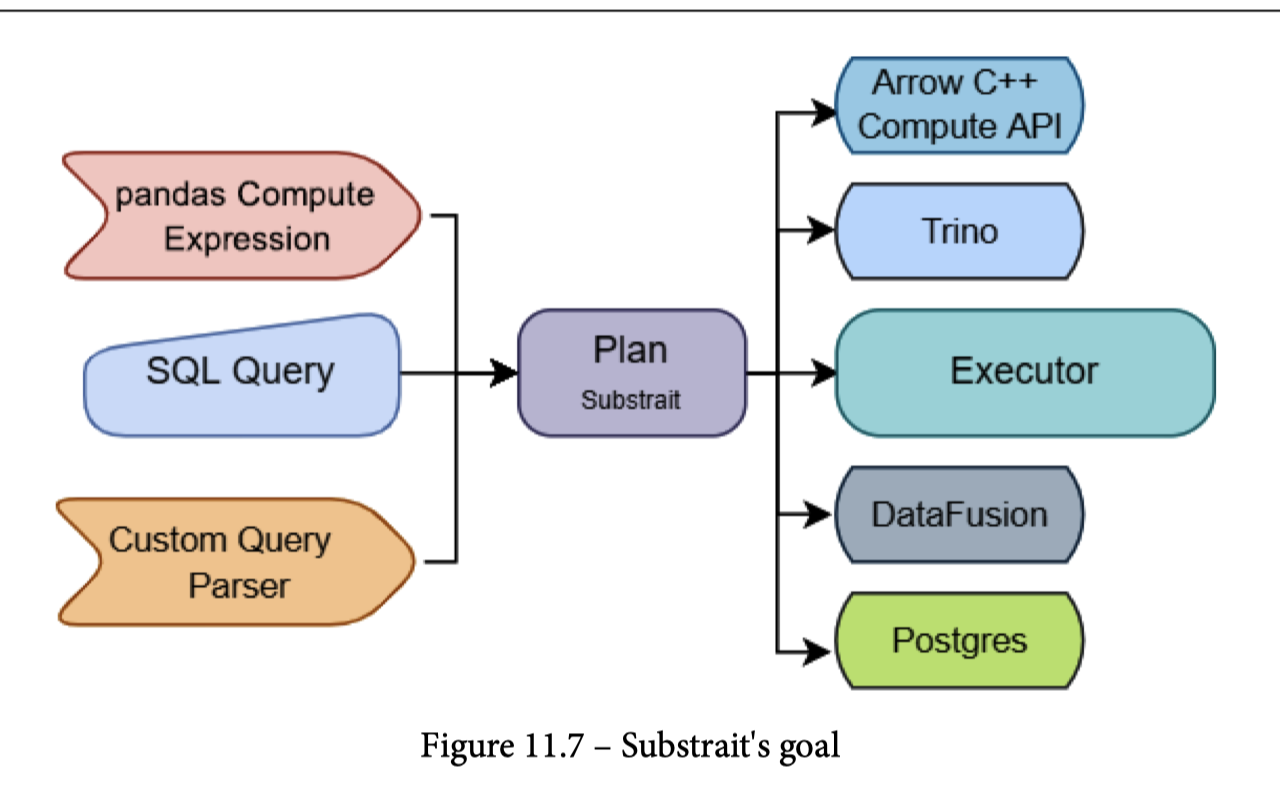
Substrait
Substrait 的定位是一个开放的 (可能被优化过的) Plan,后面可以是对应的执行器,前面产生对应的 Plan。Arrow C++ Acero 本身并不负责 Planning,只是一个执行的对应的流。
Datafusion / Ballista
SQL 和执行对应的逻辑。
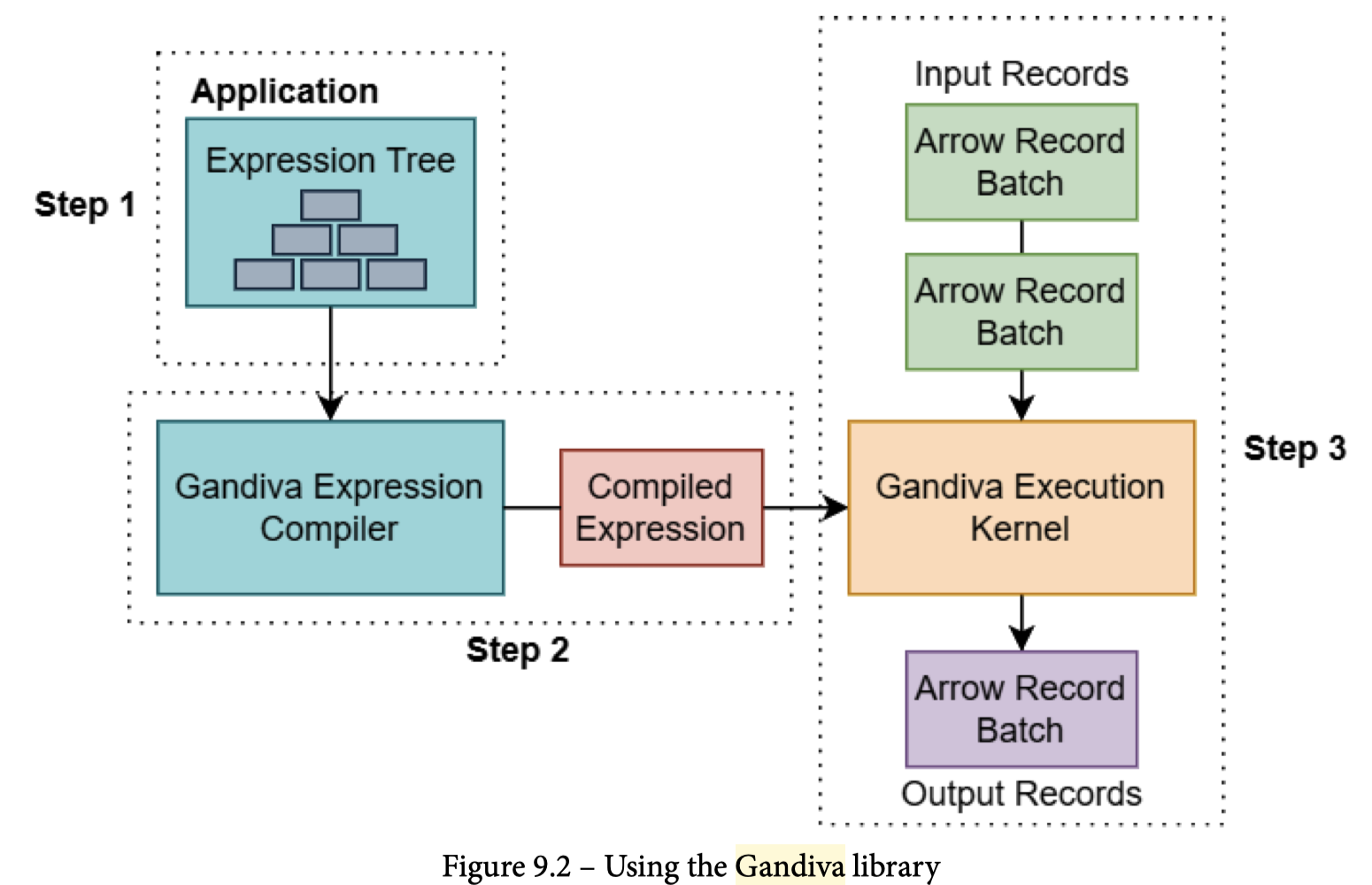
Gandiva
Gandiva 类似 Compute,是 Dremio 捐赠给项目的,对应的逻辑是 Codegen. 这个项目感觉差不多已经似了
数据源和写入相关的 API
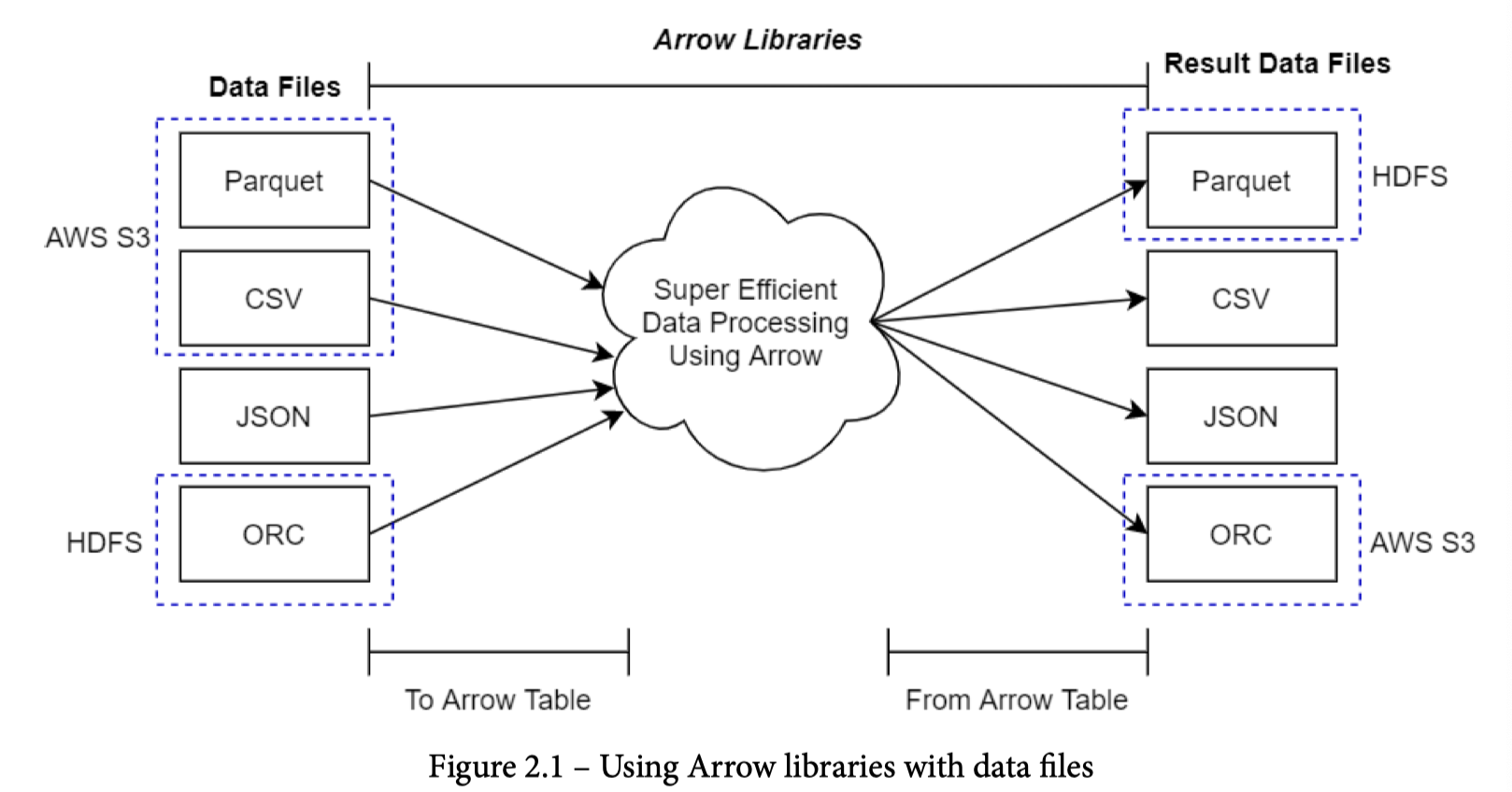
Arrow 在对应的内容上有两层
- FileSystem: 处理 Local, S3, HDFS 等「存储后台」的文件
- DataSet: ORC/JSON/CSV 等文件是在 DataSet 层处理的,这层也使用了 FileSystem。有点像 Presto 的 Connector,可以 Filter Pushdown 和读/写
References
- DuckDB quacks Arrow: A zero-copy data integration between Apache Arrow and DuckDB https://duckdb.org/2021/12/03/duck-arrow.html
- https://arrow.apache.org/docs/cpp/api/tensor.html 和 maillist 的讨论 https://lists.apache.org/thread/95ncmr4two34mxodlds7bzxvrrzmk1s6
- 一切的核心,Arrow 的内存 Columnar 结构(见官方介绍 [1] 和我之前的博客 [2])