[SOSP'11] Windows Azure Storage
现代系统中,对象存储正在成为越来越重要的系统基本组件。以 S3 为首的对象存储提供了平台的层级近乎无限的存储空间。阿里云产品这里有一个比较简单的介绍:https://help.aliyun.com/document_detail/140812.html
相对于没什么介绍的 S3,Windows Azure Storage 在 SOSP’11 提供了比较详细的描述。据 References 中的小道消息,本文很多作者去了阿里云,参与了阿里云 pangu 的制作。这篇论文细节比较多,虽然网上有很多的介绍材料,但我无论如何都看不太懂,所以看了一遍原论文。这篇文章还是相当硬核的,很详细的描述了 Windows Azure Storage 的内容,简单介绍一下本文的亮点:
- 分层的系统:分布式块存储层(Streaming Layer),几乎无状态 Partition - 数据结构层(Partition Layer),无状态的 Front End
- Stream Layer: 在 HDD 和 SSD Write Cache 上提供一致性和性能、后台 EC 节省成本,抽象了很好的 Block / Extent 模型,分布式一致性的语义(比 GFS 那坨答辩写的好很多)。一致性语义可以关注这个是一个 append only 的块,而非 k-v 这种内容,所以很多地方可以优化处理。同时,这块也是多租户的,因为对外提供的是块存储,所以这块相对不复杂,但论文没有深入讨论策略是怎么做的。
- Partition Layer: 相当于 Stream Layer 上的应用层,和 Stream Layer 一些服务做 co-locate 部署,在分布式块存储上协同维护一致性(只靠 Stream Layer 的话,一些 corner case 语义是模糊的),在上面分别维护 wal 层和数据层,来保证性能。同时 Partition Layer 对外提供各种数据结构(可以简单类比 Redis),同时,它也用这个抽象服务内部,来完成内部元信息的存储。此外 Partition Layer 应该还会根据负载做一些 repartition, split, merge (论文记作 load balance)。论文没有讨论 admission control 和多租户的实现。
此外,对于用户而言,系统是上层的 Windows Azure Storage,缩写为 WAS。WAS 会有地区间的(geographic)异步灾备、主和备,在单个地区内,它也有 stamp 的概念,去做一些内部的 replica。
文章亮点还是靠谱的架构和非常详细的内容,包括一致性语义之类的。我们需要关注实现端和应用端是怎么共同实现块存储语义的。上层的 WAS 会比较简单的略过。
Introduction
WAS 在论文中对外提供了几种结构:Blob, Queue, Tables。这几个相对来说都是很重要的产品,就不介绍了。按照 ref 中的暗示,感觉这几个功能都是组织上的考量,感觉这几种还是「被统一」到一起的(比如 queue tables 都可以用快的语义来实现,但是 workload 有一些很细微的差别,不过都做的很好估计也没啥关系) 。大厂看上去总是痴迷统一的架构…
WAS 声称提供了强一致性(Strong Consistency)、高可用性(HA)、分区容忍(Partition tolerant);同时,它对外提供了 global 的 namespace (这个可以类比阿里云或者 aws 买 oss 的 bucket、账号那种概念);此外它还有多地、但机房的灾备。WAS 还提供了多租户,对外提供了存储池的模型。
文章的逻辑顺序大概是:
- WAS 的 namespace 抽象和实现
- WAS 的架构分层,这里介绍了 WAS 的三层架构
- 块存储层 Streaming Layer 的实现,包括单机和 replica、一致性语义
- Partition Layer 的介绍
- 吹逼环节和内部使用
- …
Global Partitioned Namespace
在这里,WAS 把对应 namespace 的内容做到了 URL 中:

然后,WAS 引入了一个 DNS 系统,来做对应的处理:
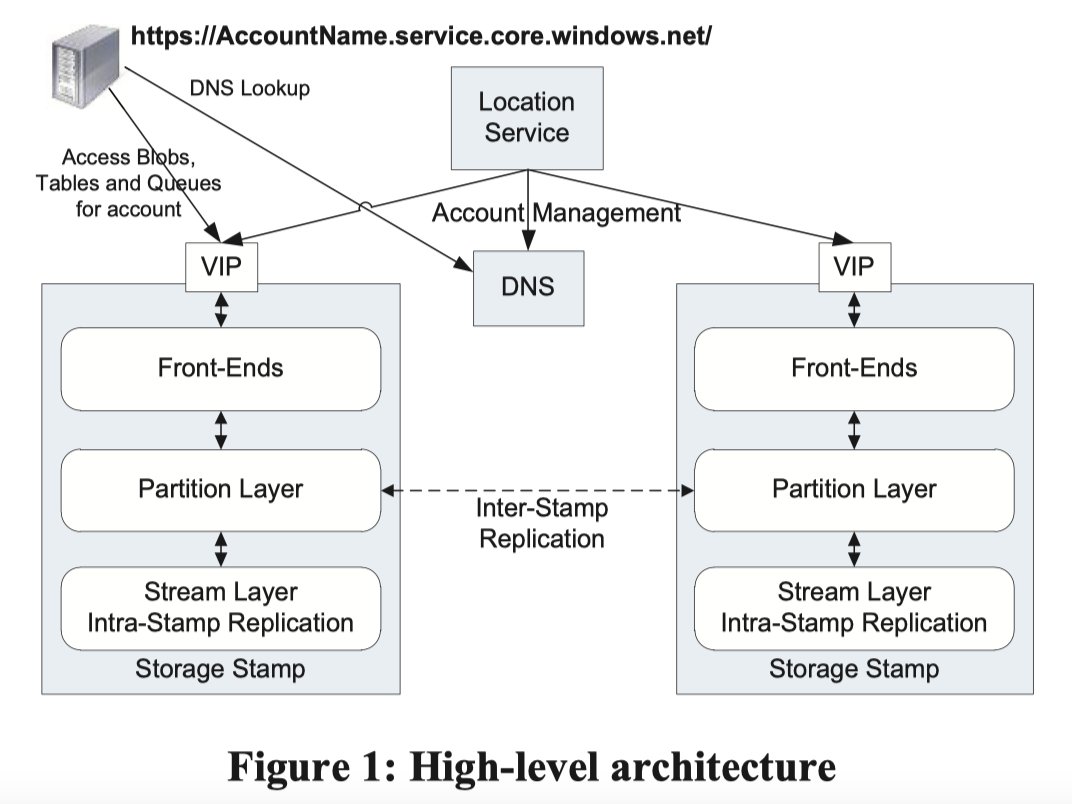
这个 URL 其实非常好理解:
- AccountName: 用户添加/选择的账户(或许包含子账户)的名称, 作为 dns 的 host name
- PartitionName 具体定位 Storage 上的数据,这个 PartitionName 感觉类似子对象
- ObjectName 不一定所有的内容都有,它用来定位确切的 object. 在同一个 PartitionName 下的多个 Object 可以完成事务操作
具体而言,这个只是一个模型组织,不同数据结构会用不同的方式使用这个数据,已知上云肯定有 AccountName:
- BLOB 没有 ObjectName, 对应一个 PartitionName (
Blob: PartitionName) - Table 中的一个 PrimaryKey 对应一个 PartitionName 和 ObjectName,这允许 Table 把表组织到不同的 Partition 下(感觉要涉及分布式事务了 orz)。(
Table: {Partitions: {objects}) - Queue 名称是 PartitionName ,对应的每个对象有一个
ObjectName:<PartitionName, [objectNames]>
High Level Architecture
Windows Azure Storage 的服务被托管给 Windows Azure Fabric Controller,运行在各地,这个感觉类似一个云平台,做容器/节点的管控。WAS 本身负责各个容器/节点内数据的 replication 和 data placement。
如上面的 Figure 1, WAS 服务器包含 Storage Stamp 和 Location Service。
Storage Stamp 是一个物理一些的概念,感觉像是部署在一起的一组高密存储机器组成的容错的集群,拥有一个虚拟 ip (VIP),我们摘录一下详细的定义:
Storage Stamps – A storage stamp is a cluster of N racks of storage nodes, where each rack is built out as a separate fault domain with redundant networking and power. Clusters typically range from 10 to 20 racks with 18 disk-heavy storage nodes per rack. Our first generation storage stamps hold approximately 2PB of raw storage each. Our next generation stamps hold up to 30PB of raw storage each.
同时,Storage Stamp 会希望多租户来保证占用,系统会保证 70% 左右的容量 / 事务(tps?) / 带宽利用率。Storage Stamp 会尽量避免磁盘占用达到 80% 以上,来避免一些突发的错误导致 stamp 内容量不足,同时,因为当时硬件大多是 HDD,HDD 外道比内道快(分过硬盘懂的都懂),所以 它也更希望用外道上的空间。当单个 Storage Stamp 资源利用率超过 70%,这里可能会尝试在 Partition Layer 做一些调度。
Location Service (LS) 是一个元信息或者 Catalog 性质的系统,它会存放区域的 account namespace,同时管理各个 Storage Stamp 的集群信息。类似 BigTable,LS 自己会把数据落在 Storage Stamp 上,然后也有备份和恢复的流程。
LS 会知道有哪些地区哪些机房,然后会 track 一下对应机房的情况和存储占用。当一个新的创建账户请求过来的时候,它需要指定 location affinity(用户在什么地方用),LS 会根据这个请求的 location affinity,来预测并决定这个资源的 primary storage stamp。它会在这个 stamp 记录元信息,然后更新 DNS 路由,把资源 url 的 domain 指向 storage stamp 的 VIP。
Storage Stamp 内的三层架构
这里自底向上的介绍 Storage Stamp 的三层架构:
Stream Layer: Storage Stamp 内的分布式块存储. 它有几个概念
- Stream:一个大的可以 append 的 bit stream
- Extents: 不固定大小的 Chunk (可以对比 GFS Chunk)
Partition Layer: 这里机器可能和 Stream Layer 做 co-locate 部署,它提供了
- 单机
- Blob, Table, Queue 的语义管理
- 和上层的 dns 协同处理 PartitionName 等逻辑,毕竟 dns 只会 resolve host
- Transaction Ordering / Strong Consistency,部分和 Stream Layer 协统管理,部分自己管理
- Storing/Caching 各种数据
- 分布式: 类似 TiKV HBase,对数据按照 PartitionName 进行 Range Partition,并做了可能的 Merge / Split 等管理
- 单机
- Front-End Layer: 由 stateless 的服务器组成,接受请求,然后把请求路由到 Partition Layer 的服务器。系统会有一个 Partition Map 来维护相关的 Partition 的映射区间。FE 会缓存这个 map,然后转发请求。感觉这个某种程度上相当于一个内部 Proxy 或者客户端
Two Replication Engines
- Stream Layer 会做 stamp 内部的 同步复制,来保证 stamp 内的数据安全。这个会在 critical path 上进行,需要等待复制完成才能返回用户 success。它关注的是复制的 bits。因为这个在主链路上,它的主要优化点在 latency 上。
- Partition Layer 会做 stamp 和 stamp 的复制。它会在主链路之外异步复制给别的机器。它关注 Transaction 之类的语义,和 Objects,但可能不太关注具体 layout。相对于 Stream Layer,它提供的是机房的可靠容灾。因为这个不在主链路上,但可能数据量比较大,优化点则在 bandwidth 上。
这里还有个别的问题是,两个 layer 之间管理的对象不同(用论文的话说就是 namespace 不同)在 stamp 内复制的时候,这里需要管理的信息都在同一个 storage stamp 内部,元信息大小相对可控,可以 cache 在内存中。
作为对比,Partition Layer 元信息其实是依赖上层的,这似乎并不在意你怎么分片路由的,只在于 global object namespace 管理的其余 replica,然后把对应信息(我猜类似 binlog)丢过去。
Stream Layer
在介绍 Stream Layer 之前,我们可以简短回顾一下 GFS 的 consistency:
- 客户端给 primary 发请求,请求以 chain replica 的形式复制
- 数据以 Chunk 的单元存储,Chunk 大小大概是 64MB 或者数倍,meta 在 master 作为内存中的一棵树
- 如果存在并发,那么可能需要重试,可以保证,写入成功的时候,偏移量在所有副本上都是一样的
WAS Stream Layer 提供了更加清晰的定义和抽象,在单机存储上,引入了 Block - Extent - Stream 这一个多级别的结构概念。分布式存储上,引入了更加详细的描述语义。
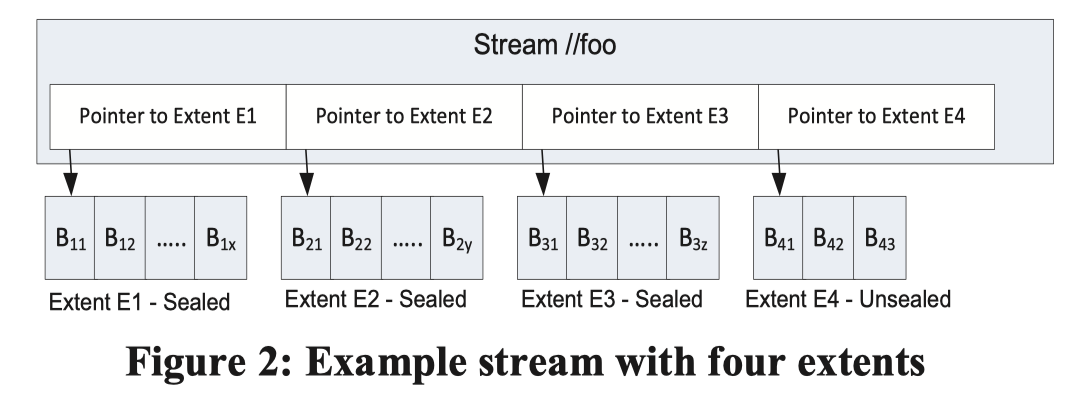
- Block 是用户 Append 和读取的基本单元,用户可以 append 一个或者多个 Block,Block 也不需要有固定大小,Block 会被 checksum。读取的时候,也需要做 checksum validation (这里似乎是前台读取的时候做的)。同时,除了前台验证,这里也会有一个天级的后台线程做 validation。
- Extent 包含一个或多个 Block,Extent 的大小不固定,它只有一个 appendable 的 Extent (Unsealed),其余都是 Sealed 的,里面的 逻辑的 bits 内容 是不可更改的。Extent 是 Stream Layer 复制的基本单元。在论文发表的时候,extent 会被存储在一个 NTFS 文件上,(这个可能是因为实现完成度问题?因为感觉 fs 自己也会写 log,基本 log-on-log 了…)。
- 上层使用的时候,Partition Layer 会定一个 1GB 左右的 Target Extent size,然后可能会 batch 多个小对象的写到同一个 Block 中 append 过来。如果要写一个很大的对象,可能会拆分成很多中等大小的(GB)的 Block 去写。
- Stream 是 Stream Layer 对上层提供的抽象,它本身是指向多个 Extent 的指针
[Pointer-to-Extents],这个状态由 Stream Master 管理。这个抽象有点类似 fp,因为 Extent 是不可修改的,Stream 可以等于 Stream + Append Operations。只有最后一个 Extent 是可写的
Stream Manager and Extent Nodes
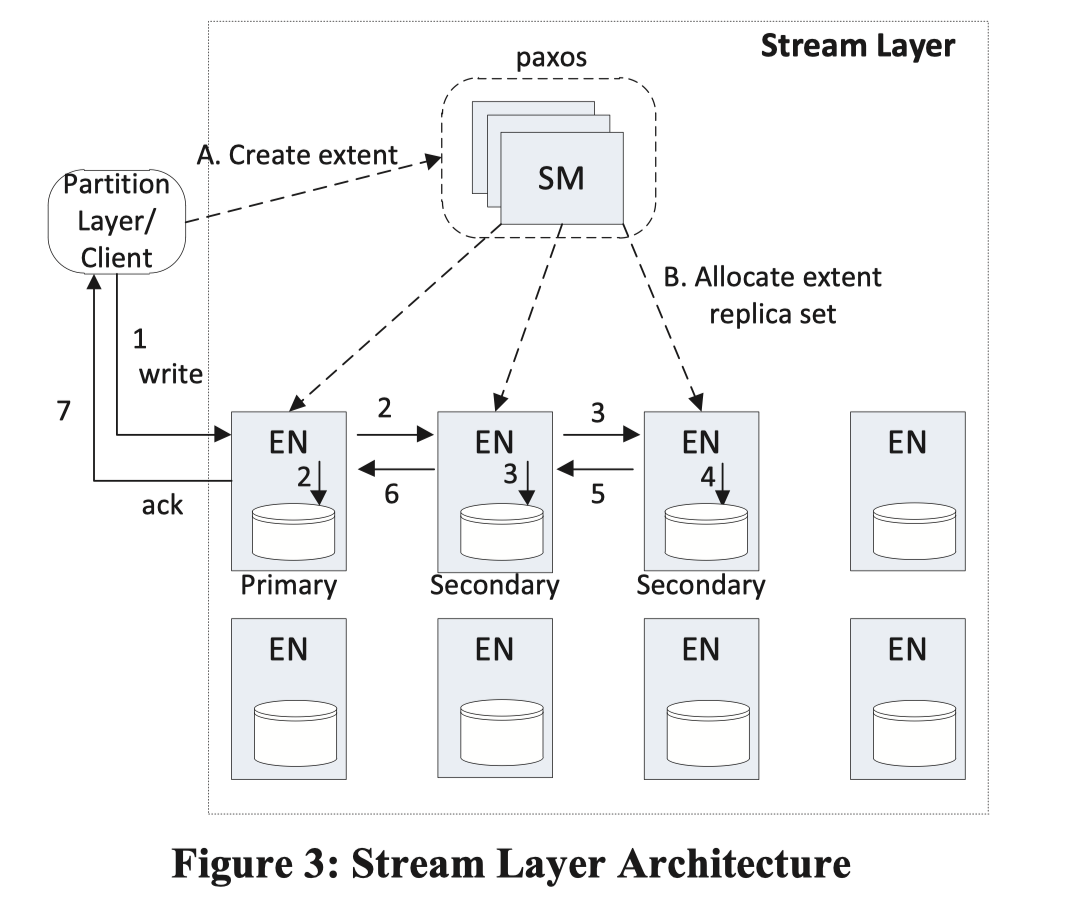
Stream Manager (SM) 管理 Extent 的抽象,而相对而言,数据存储在 Extent Node( EN ) 上。类似 Chubby,它是一个 Paxos 集群,因为元数据数量相对可控(问题:如果有很多很小的 Extent 感觉这个会疯狂劣化,不过应该不是常见场景)。SM 负责做的事情相当于管控的 master:
- 负责响应 client 的 create extent 请求,挑选对应的主备机器,然后创建 Extent
- 维护 Stream - Extent 的映射和状态
- 监控 EN 的状态
- (3) 中 EN 状态出问题,或者出现 corrupt 等情况的时候,去拉起备然后修复数据,维护多副本
- GC 掉没有被 reference 的 Extent
- 做一些后台操作,把 Sealed Extent 给 EC 优化(现在应该有很多不需要这样,在前台写的时候直接 EC)
论文里提到了几个点:
- SM 会周期性拉 EN 的数据,然后来检查是否一致
- 对于 Extent 的 Replacement 策略,这里 SM 挑选 EN 是 randomly 的,但不会挑选在同一个 fault domains 中,不知道为啥选 random
SM 只管理 Extent,不管理 block(实际上 SM 不去 aware block 信息),用户 append 的时候,这里一般不会跟 SM 打交道,直接走最后一个 Extent 去 append,所以绝大部分情况下,SM 不会 block critical path。
下面论文提供了一个 SM 管理元数据的简单计算,这里使用了 32GB 内存的节点,然后 SM 打交道的 client 只会有 Partition Layer,在论文估算中,Stream 不会多于 100K 个,Extent 不会大于 50M 个,所以总内存可以限制在 32GB 内。
EN 则不知道 Stream 的概念,它会知道 SM assign 给它的 primary / backup 的 topology,
- 单个 Extent 存储上,Extent 会被存储成一个文件,每个 block 会有 checksum,然后还会有一个 Block Index,来映射 Block 的位置 (我猜类似 LevelDB?).
- 在 EN服务器中,服务器会有个自己管理的 Extent 列表,每个列表包含对应的 Peers.
Append Operation and Sealed Extents
首先我感觉一般要明确一点,我个人感觉比较合适多见的块存储场景都是单写者,然后有一个分布式锁 / epoch 之类的逻辑来保证只有单个 writer,有的块存储也会在服务内置一套 cas 或者 leader 机制,然后方便用户保证 Single Writer。这里可以参考 Curve 的调研文档 , 这里对多挂载和 leader 做了一些概述,应该比较接近工业界的情况。
回到 WAS Stream Layer,这里 append 会保证:
单个 append,即使是多个 block 的 append,也是 atomic 的。
如果出现错误,客户端可能需要 Seal Extent (感觉现在很多 Truncate + Seal) 然后接着写,或者直接重试。发论文的时候 WAS Stream Layer 应该是没有 Truncate + Seal 语义的,所以如果要重试,可能会和 GFS 一样,需要处理重复记录
- 对 Metadata 或者 Commit Log,这个会在 Partition Layer 根据 LSN 之类的东西去重
- 对 row data 或者 blob, 只有最后一个成功的写会被上层 ref,空白的内容等待 GC(这个地方还是有点奇怪的,因为如果没 Seal Extent 的话,有的内容还在同一个 Extent 里面,这个感觉得暗示有 WiscKey 之类的 GC 机制了,或者单纯就留在那,等待整个 Extent 没有被 Ref 了)
Extent 到达一定大小或者主动 Seal 后,里面逻辑内容不能改,但是实际内容可以被 EC 条带化之类的方式优化
Stream Layer Intra-Stamp Replication
Stream Layer 和 Partition Layer 需要协作,来保证靠谱的 replication。Stream Layer 提供了如下保证:
- record 返回成功之后,后续的读一定可以读到这条记录,对应的记录是 immutable 的(感觉如果支持 truncate, 这个语义也会变得略微有点奇怪, 只能说上层可以约束需要 truncate 的数据是未决的,不会被读取)
- 从 sealed extent 读,永远会读到相同的内容
这个地方 replication 是为了处理软件错误或者各种错误:
We consider faults ranging from disk and node errors to power failures, network issues, bit-flip and random hardware failures, as well as software bugs. These faults can cause data corruption; checksums are used to detect such corruption.
(哎,突然想起在前司碰到的傻逼事情,集群软件 bug 把所有副本写入了 bug 数据😅块存储这块还是要非常小心写代码的…)
Replication Flow
这里会以 chain-replica 或者星型的形式写入,peers 在 Extent 还活跃的时候不会变更,client 会缓存 active extent,然后直接写 primary,这里必须写 Primary,但是可以从 replica 读。这个地方有个地方,感觉是说需要保证 uncommitted 的数据没啥读者,因为这个内容是 appendable byte stream,所以比 kv 好保证这些。
写入的时候,因为都要走 primary,所以需要 primary 做一些写相关的决策:
- 在本 Extent 中,请求的 append 对应的 offset
- 多个客户端并发 append 的时候,这些 append 的 ordering (我感觉本质和 1 是一个问题)
- 在所有 secondary 都保证成功的时候,才返回 success
- 同时,因为有 (2) 的约束,这里会按序 ack (看着各台机器也是按序 append + ack 的)。最后成功 append 的位置会是这个 replica 的 commit length ,根据简单推理可以知道,这个 commit length 可能比 client ack 大,所以会有 corner case 处理
client 发现错误的时候,需要以最小的 commit length 去 seal,然后 allocate 新的 extent,论文说这个平均时间会有个 20ms(不知道系统自己能不能有个 double buffer?)。被 Seal 的 Extent 如果发现后台掉备份了,SM 会帮它拉起靠谱的 replica,如前文所述。
(不禁翻了一篇自己两年前写的 blog: https://blog.mwish.me/2020/08/06/notes-on-craq/ ,时间过得真快啊)
Sealing
SM 会在 Partition 帮助下去做 Sealing,这里会有可能有三机器 commit length 不一致的情况(论文提到会有两台机器或者有相同的 commit length,我感觉这个暗示了相关的复制流程,不过我觉得这个具体写代码还是很容易三个不一致的)。我个人觉得一个比较理想的状态是 client-side 选出一个状态,当然,client 也有挂掉的时候,回到论文中,论文这里选择方式可以看下面。
SM 会按照 能联系到的机器的 minimal commit length 去 Seal。这个地方我感觉还是暗示就是最短的提交了才是全部集群中提交的长度,然后依靠 2/3 的 safety 去保证这里面最短的一定大家都有、一定已经提交。
在 Seal 之后,这里的长度会被 SM force 然后再也不会改变。所有的 replica 都是 bitwise-identical 的。
Interaction with Partition Layer
client 会缓存 active extent 的信息,并且,在读取 extent 的时候,会有两种模式:
- 读指定位置的内容,读
(extent + offset, length)。这里只会读取 之前返回 success 的内容 - Partition Load 的时候去 seq scan,因为 Partition Layer 会保证这个阶段没有 append 进来,所以可以相对安全的来完成这个阶段的操作。这个会给 Primary EN 发请求,来查询 commit length. 如果出现 commit length 不一致的情况,client 会 seal extent (对照上一节),然后读只会读 sealed extent。
Erasure Coding Sealed Extent
WAS 会把 Sealed Block EC 化,来节省成本。
Read Load-Balancing && Spindle Anti-Starvation
首先可以复习一下前两节的读语义,这里可以保证:
- 对于 active extent 读的时候可以读 replica。
- 对于 ec 条带化的 sealed blob,这里会给所有机器发请求,然后收到能恢复状态的请求就返回给用户
读取的时候还有一些分布式系统和 io 的 tricks。WAS 会有一些类似流控的机制,它会:
- 请求带上 deadline,预估请求是否会超时,如果判断超时会提前返回给用户
- 原则上,WAS 会尝试优化请求吞吐而牺牲公平性,在 HDD 上尽量做 seq scan。这里有一个 io 排队观察的策略,不过论文提的策略比较简单,而且感觉是给 SSD 优化的,感觉可以参考之后的一些论文吧
Durability and Journaling
这里 WAS 利用 SSD 充当一个高性能持久化写缓存,这我不禁想起了刚刚凉凉的 Optane 那套 NVM…这里依靠双写的方式写 SSD,然后SSD写完就可以提前返回,来降低 latency。SSD 在这里只充当快速写的硬件,一旦写在 HDD 上完成,之后的请求都在 HDD 上 serving。论文指出,这点将 e2e stream append latency avg 从 30ms 降低到 6ms。
Partition Layer
Stream Layer 虽然年代所限,有的地方在 2022 年看来还是有优化空间的,但是提供了很多至今还在用的抽象,描述语义也比 GFS 那草台玩意具体多了。
Partition Layer 则是展现了怎么在 Stream Layer 这个分布式块存储层上做抽象,来满足用户的需求,这里即展示了数据,又展示了 WAL,同时也有一些 Partition 相关的抽象,展现了一个半共享存储的系统是怎么实现的。
Partition Layer 抽象出了一个叫做 Object Table (OT) 的结构,这是一个 scalable 的 range partition 的 key-{schema} 的表,被分成数个 RangePartition,部署在 Partition Server 上。因为是 ,所以这部分 range 不会重叠。
Partition Layer 利用 OT 的抽象,制作了下面的结构来支持上层的逻辑。这些结构确实很多地方应该用相关逻辑支持,不过看上去,这个架构确实为统一的一份代码干很多事付出了努力:
- Account Table: Storage Stamp 会上层提供的账户信息
- Schema Table: 存放各种数据的 Schema
- Partition Map Table: 存放 Partition 相关的信息
- 有一堆子数据结构的表格:
- Blob Table: 为 Blob 使用,存储相关元信息
- Entity Table: 为 Row 的 Table 结构使用,存放数据
- Message Table
FE 可以访问这些 table,来提供对应的抽象。每个 OT 都有固定的 Schema,并在 Schema Table 里面存放了对应的 Schema。具体而言,这里会有 pk: (AccountName, PartitionName, ObjectName) ,看,是不是很熟悉…
OT 还支持了同一个 PartitionName 的事务操作和 SI。
Partition Layer Architecture
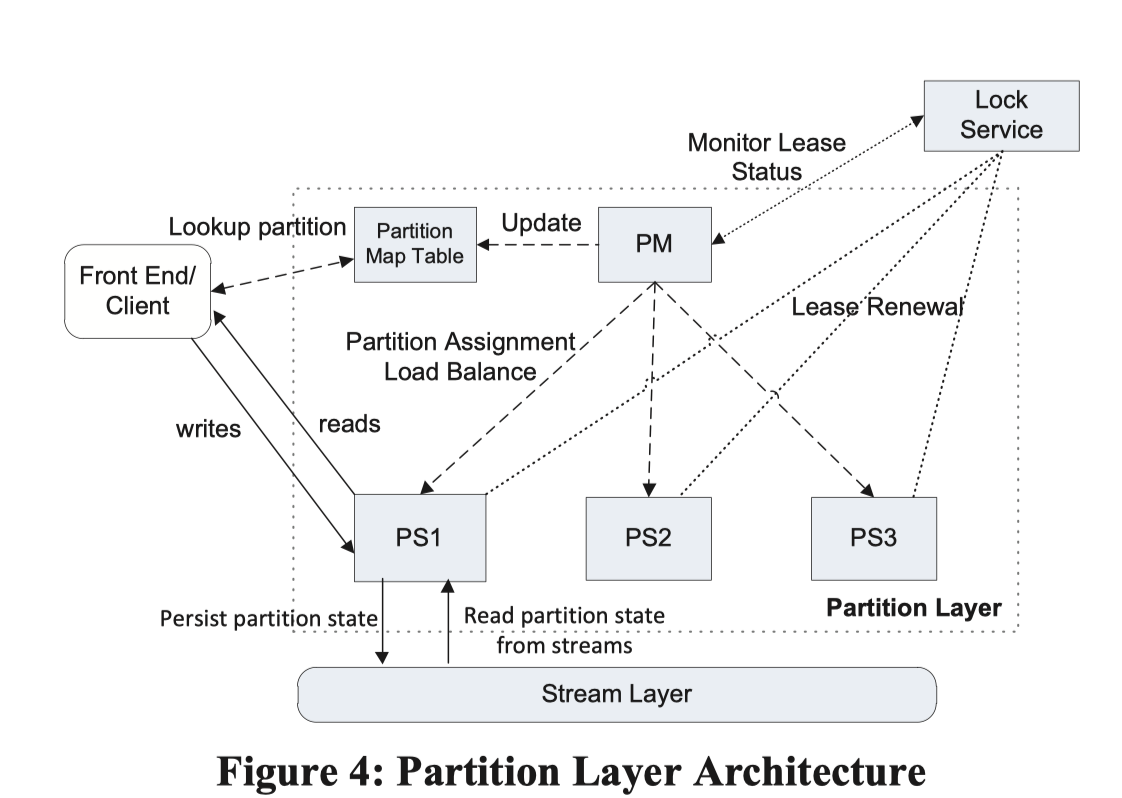
Partition Layer 可以类比为 HBase 或者 BigTable 的架构:
- Partition Master (PM) 负责 track / merge / split / assign 对应的 Range Partition. 类似 HBase,这些信息也被存放到下层的 Partition Map Table。PM 有多台服务,根据 Lock Service 确定 Leader
- Partition Server (PS) 把数据存放到 Stream 中,然后自己会有 Cache。对于 Range Partition 的分配,单机也会持有 Lock Service 来确保这一点(感觉有的时候可以靠调度层强行 fencing?不过这样应该也能做一个很好的保证,相当于带了个 epoch 了)
- Lock Service: 类似 chubby / zk…
接下来我们关注 Partition Server 对应的单机结构是怎么实现的。这里的结构是一个 LSM-Tree,然后论文没提到有 CF 这样的抽象。Stream 只属于一个 RangePartition,而不像 HBase / BigTable 会多流合一。感觉这个既有好处又有问题吧。
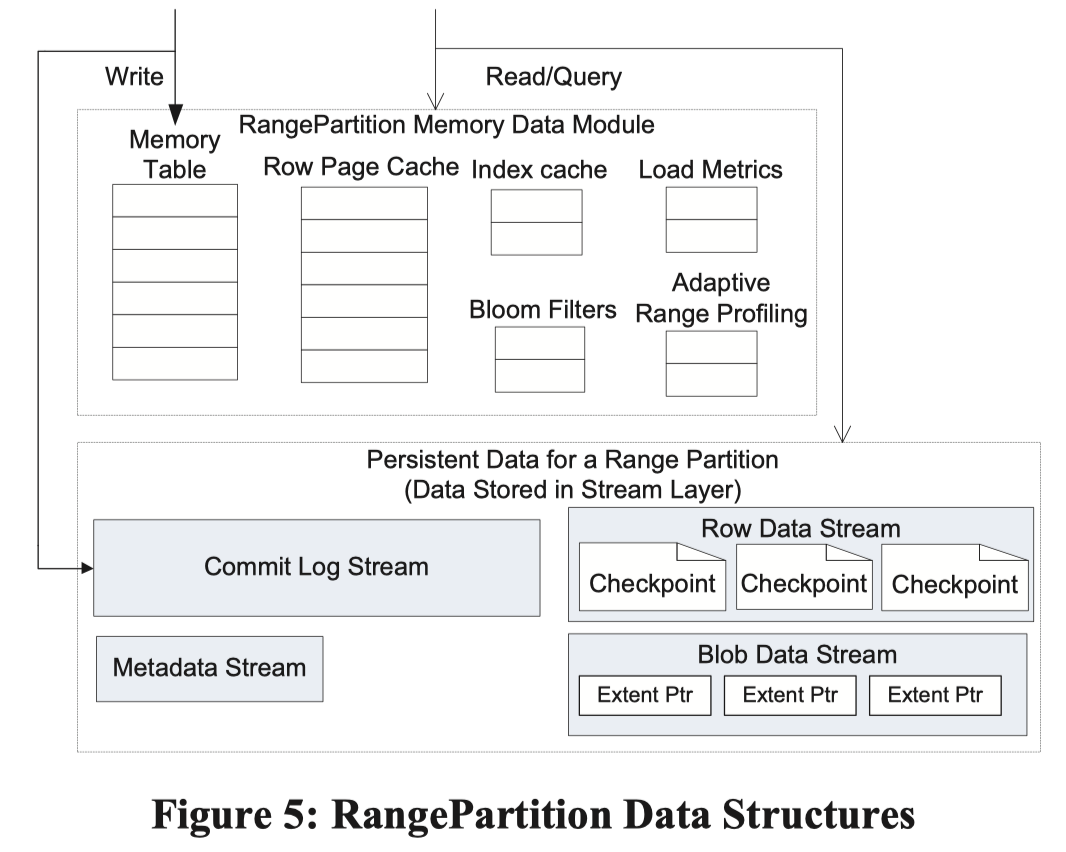
这里区分了几种 Stream:
Metadata Stream: 整个 Stream 的元信息,可以用来 load 别的所有的 Stream,类似传统数据库 Catalog / MetaBlock,PM 靠提供 metadata stream 的名称来提供信息。这个信息包含:
- Stream 的名称
- 类似数据库日志的 ckpt,表示有效区域的 extent + offset
- Commit Log Stream: 不知道是物理还是逻辑的 commit 日志
- 数据层面的 Stream:
- Row Data Stream: data 和 index 对应的 checkpoint,单个 RangePartition 只有一个 data stream
- Blob Data Stream: 专门给 Blob 使用
在内存中还有 index cache , row data cache, bf,但我觉得…都没啥意思。具体可以参考论文 5.3 - 5.4 节,都是比较 trivial 的东西。
RangePartition Load Balancing
这节介绍调度 / merge / split,本来挺没意思的,不过可以关注一下对应的语义和维护流程:
- 在维护的时候,WAS 会记录 Partition 的数量,并保持在 low watermater - hight watermark 之间,这个数量大概是 partition server 的十倍。这里会尽量来维护这个值,并且按照读写流量和 watermark 来触发 merge - split。典型的 stamp 会有 75次 split / merge, 200 个 RangePartition
- 这里会 track tps / pending transaction count / 限流 / CPU 使用率 / 网络 / 延迟 来决定是否 split / merge
- split / merge 类似
hbase,我们关注区别:- 下层 Streaming 实现了对 Extent 的 Ref-Counting
- 在 Split 的时候,同样会触发 ckpt。Split 的时候也是现在同一台服务器上分裂成两份,再调度走;Merge 的时候也会先调度到同一台机器上
- PS 定义了 MultiModify, 根据需要 Split 的流,fork 两个 ref,然后调度流量即完成。没有 HBase 那么复杂
- Merge 操作感觉比较草台,MultiModify单纯合并两个 commit 流,感觉对 Truncate 不太友好?
References
- Blogs
- https://fuzhe1989.github.io/2021/05/02/windows-azure-storage-a-highly-available-cloud-storage-service-with-strong-consistency/ (作者提了一些他看到的相对细一些的地方,然后也介绍了这个论文里面很多大佬去了阿里云)
- https://zhuanlan.zhihu.com/p/33951960 (作者是阿里云表格存储的,感觉介绍相对来说有一些内部一些的观点)
- https://bluexp.netapp.com/blog/azure-storage-behind-the-scenes
- 阿里云的盘古,公开材料也比较值得看:https://developer.aliyun.com/article/291207