x86 and SIMD programming Part0: Background
作为指令集并行的一部分,SIMD 已经被大幅度用来提高程序的性能了。而在数据库系统中,分析型数据库也大量使用 SIMD 来做 vectorize,来提高性能。本栏尽量介绍一下基本的 SIMD 的历史、需求和基础,然后后面也会讲到 AVX2 的入门、xsimd 库和让编译器自动来做向量化。在这里,了解硬件和指令集是比较重要的组成部分,而虽然 ARM 平台也有自己的 SIMD 指令集,但作为 db 研发,我们还是以 x86 的为准(倒不是看不起 arm,就单纯先不花时间吧)。
CPU 有一些技术来帮忙优化,比如 Hyper Threading / Super Scalar,CPU 也有专门的 SIMD 处理单元。这使得人们可以给出更好的实现。在数据库里面,近年来卷到爆炸的分析型数据库领域也希望能够利用好 SIMD。
言归正传,程序员早期其实是没那么懂并发编程的,原因大概在 perfbook 那节 也讲过,以前硬件提升都是可以直接反映到程序上,啥都不做性能就提升了,但是现在的程序员必须 get hands dirty,来了解一下下层的抽象,来一把捅下去获得性能。同时,有的时候性能、生产力、通用性是个不肯能三角,这个在 perfbook 那节也有提到。这话有点太俗了,下面的图其实是比较好理解的:
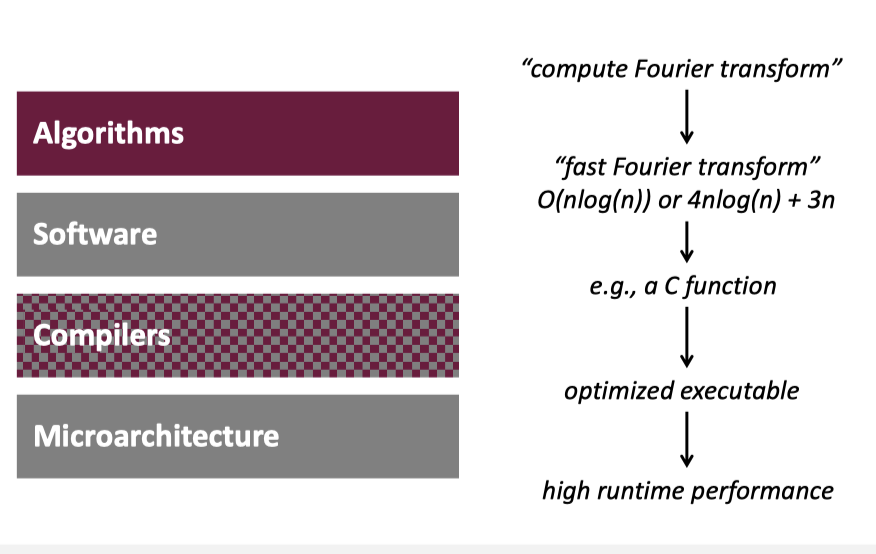
这里还有一张关于内存带宽和频率有关的图:
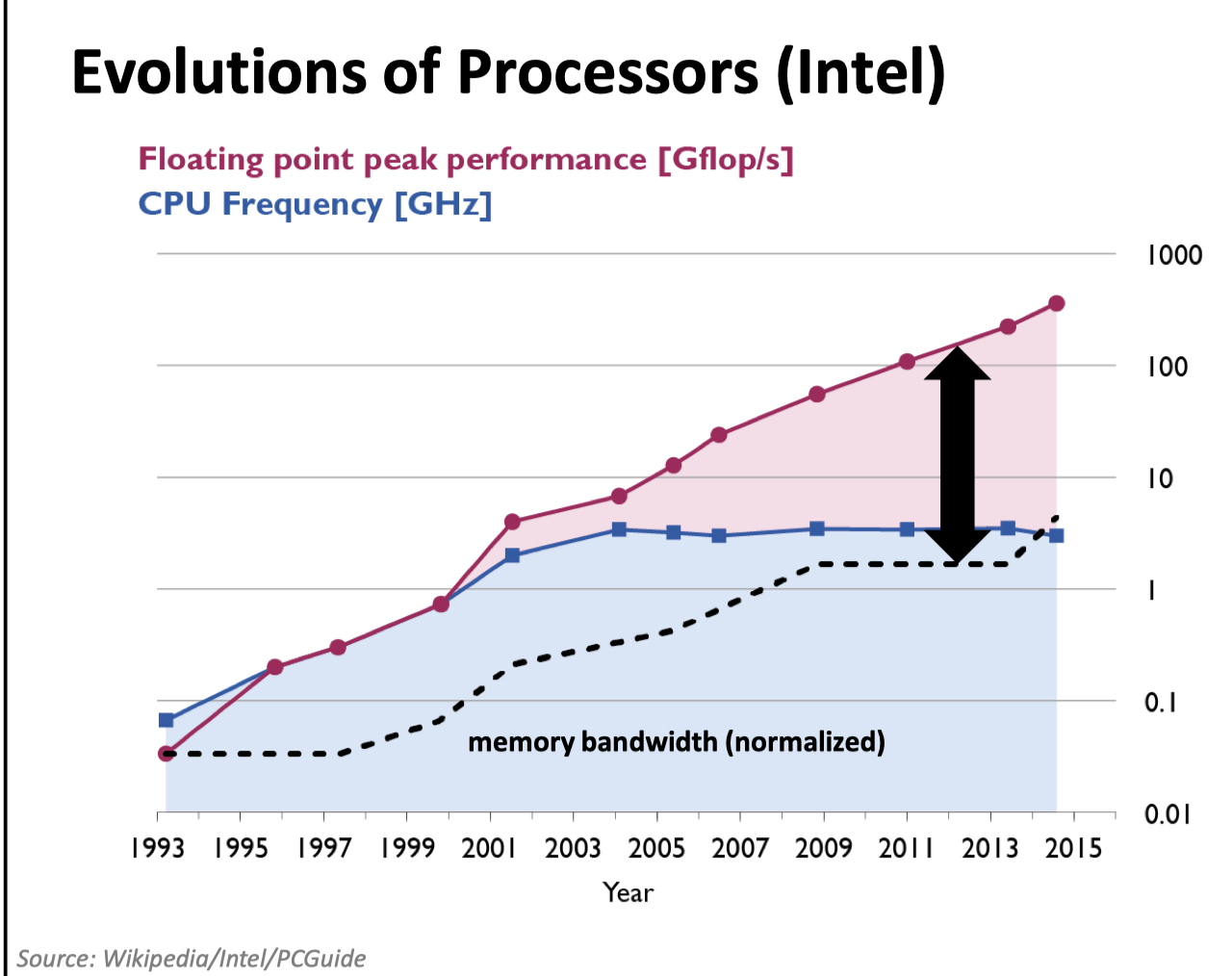
(实际上,可以看 ref 4,单线程已经跑不满内存带宽了,不过内存带宽仍然受到限制)
关于性能,这里还有一些 hints:
- cache miss 可能很重,可能相当于几十几百条指令,当然,IO 就更重了
- 需要利用 SIMD、多核、多线程甚至 GPU 甚至特殊硬件来改善性能
- 写 fastcode 可能涉及代码量大、多线程协调、不跨平台(比如单平台 SIMD 的问题),同时,Compiler 可能也不一定能够生成合适的代码。多线程必不多说,SIMD 可能也没法生成很好的选项,实际上很多地方(例如 TiFlash、ClickHouse)都是写便于向量化的代码,尽量让编译器自动向量化然后加一些编译参数来检查,一些关键路径也得自己手搓 SIMD 或者用 SIMD 库。
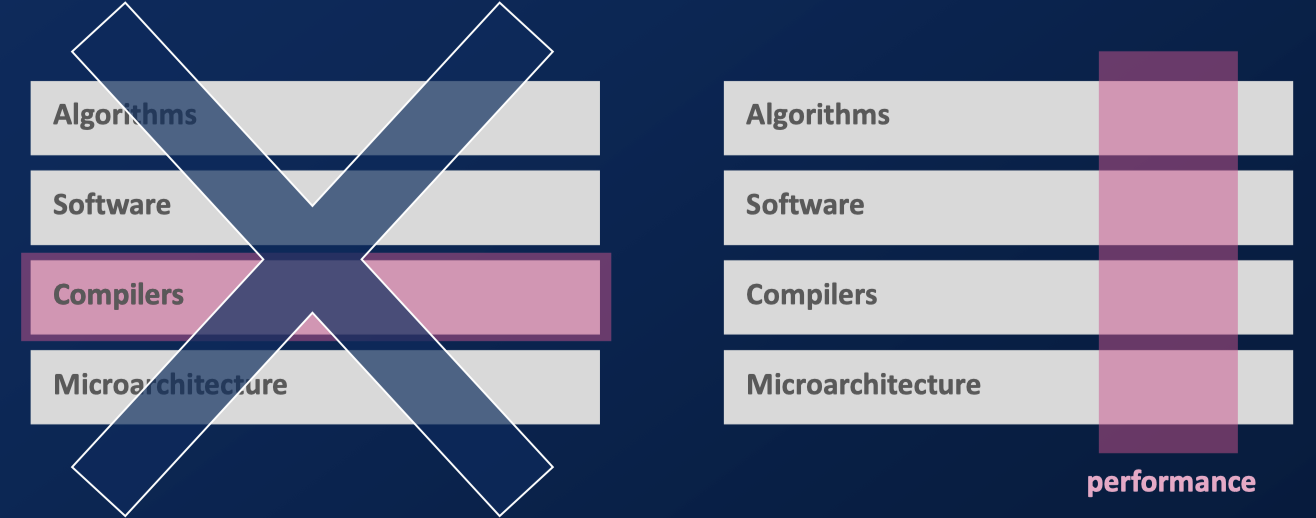
硬件发展和硬件基础

X86-64 平台是 x86-32 的一个扩展。当然,这里 x86 指的是 ISA,与之等同的是 RISC-V、ARM、POWER、MISC 等。而不同的是下层的实现和 microarch,比如 cacheline 的长度。x86 是一个 CISC 指令集,但是它的指令会被处理成 RISC 的,以获取性能:
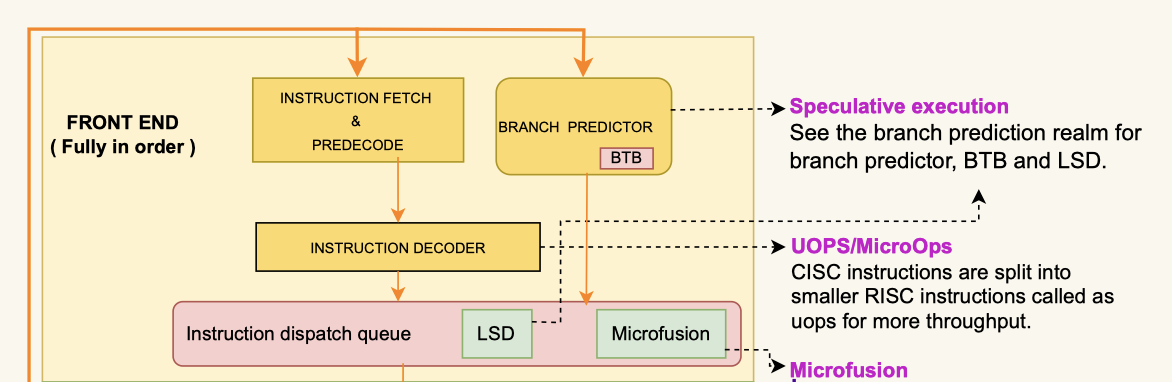
下面是一个 Intel 芯片的图,来自 wiki:
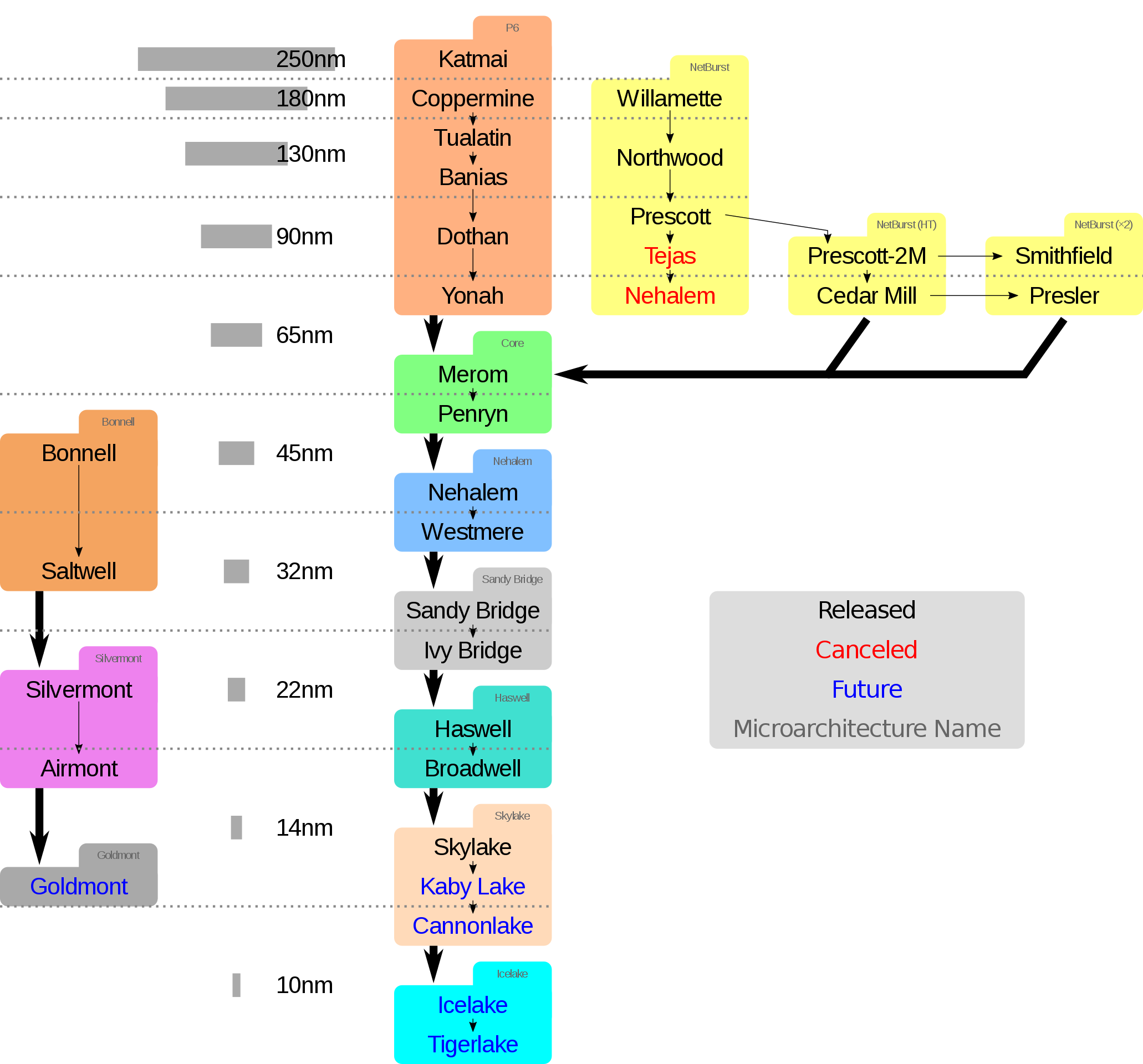
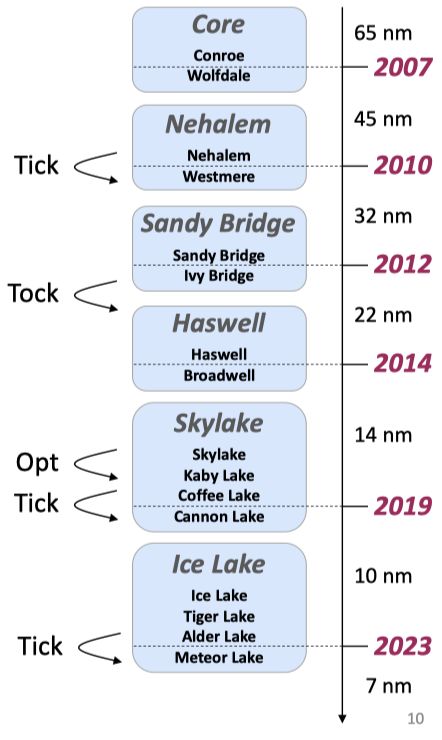
Intel 在 06 年提出 tick-tock 模型: Tick 一次代表制程(Process)更新,利用硬件提升;Tock 代表作出新的架构。这个策略后来被更新为 Process–architecture–optimization 模型:
最早出现的芯片是 16位的 Intel 8086, Intel 8088, Intel 80186, Intel 80286。游戏的开端是 1985 年的 Intel 80386,它最初采用了 32位的 IA-32 架构( 此外,还有个名字很像的、创造者同样包含 Intel 的 IA-64,则是另一个指令集。),它有各种寄存器、4GB 的虚拟地址空间、基于页的虚拟内存。80386 有独立的 80387 FPU。在 80486 中,这些被集成到了系统中,即 x87 FPU。实际上,FPU 和 SIMD 很多处理的逻辑类似,一定程度上,它们是被整合到一起的。
x86-32 平台在 93-95 年推出的 P5 microarchitecture 中,MMX 技术出现,它用 64-bits 位宽的寄存器来同时处理多个整数。
在 P6 架构的 Pentium Pro (1995) 和 Pentium II (1997) 中,Intel 引入了 superscalar,decode / dispatch / execute 可以乱序执行。Pentium 有个你可能很熟悉的名字,叫「奔腾」。
99 年引入的 P6 架构的 Pentium III 中,SSE(Streaming SIMD extensions) 指令集被引入了,它加入了一组 128bits 的寄存器,可以进行 SIMD 的单精度浮点运算.
一年后,2000 年,Intel 推出了 Netburst 架构,并引入了 SSE2,它补全了 SSE 处理双精度浮点数的能力,同时,它在 SSE 引入的寄存器上补齐了整数运算的能力。04 年,SSE3 推出,并运行在制程 90nm 的 Pentium 和 Xeon 架构上,这一代架构有 hyper-threading. 06年推出的 Core 架构(酷睿)做了不少优化、降低了能耗,同时引入了 SSSE3 指令集和 SSE4.1,他们没有引入新的寄存器,同时,hyper-threading 也被去除了。2008 年的 Nehalem 再次引入了 hyper-threading,同时也引入了 SSE 最后的 SSE4.2 指令集,这个指令集扩展了 SSE 寄存器上的字符串/文本处理。
2011 年 Intel 推出了 Sandy Bridge 架构,它引入了 Advanced Vector Extensions (AVX) 这一 SIMD 指令集,它用 256-bits 的寄存器来处理数据,这提升了寄存器的宽度,一定程度上减小了开销.
2013 年 Intel 推出了 Haswell 架构,同时,它引入了 AVX2,实际上,现在比较常用的编译参数包含 -mavx2 -march=haswell,同时,它提供了一组 data transfer 相关的指令:
- broadcast: 把一个值广播到多个位置
- gather: 把多个不连续位置的内存加载
- permute: 给出一组 index, 按照 index 来加载数据
Haswell 还引入了 FMA 操作,FMA 代表 Fused Multiply-Add, eg:
1 | /* matrix multiplication; A, B, C are n x n matrices of doubles */ |
这种 x = x + y * z 的操作,只会舍入(rounding) 一次。
2017 年,Intel 的 Skylake-X 中,引入了 AVX512,使用 512-bits 的寄存器。
作为 Intel 之外最大的 x86 厂商,AMD 也对 SIMD 进行过支持, zen 架构支持了 AVX2,而之前的 K8 架构支持了 MMX、SSE、SSE2、SSE3,AMD 引入了 SSE4a 和 FMA4 等 Intel 不太支持的指令集。
在 ARM 芯片上,也存在 SIMD 指令集。NEON 有 128-bit 的寄存器。此外还有 NEON64 等指令集。
在 RISC-V 上,Vector 扩展前几个月刚刚 stable,不过编译器还有一些 instrinct 没有定下来,有待多方继续推进。
Intel and Skylake
Intel 机器执行指令的时候,大致逻辑如下:
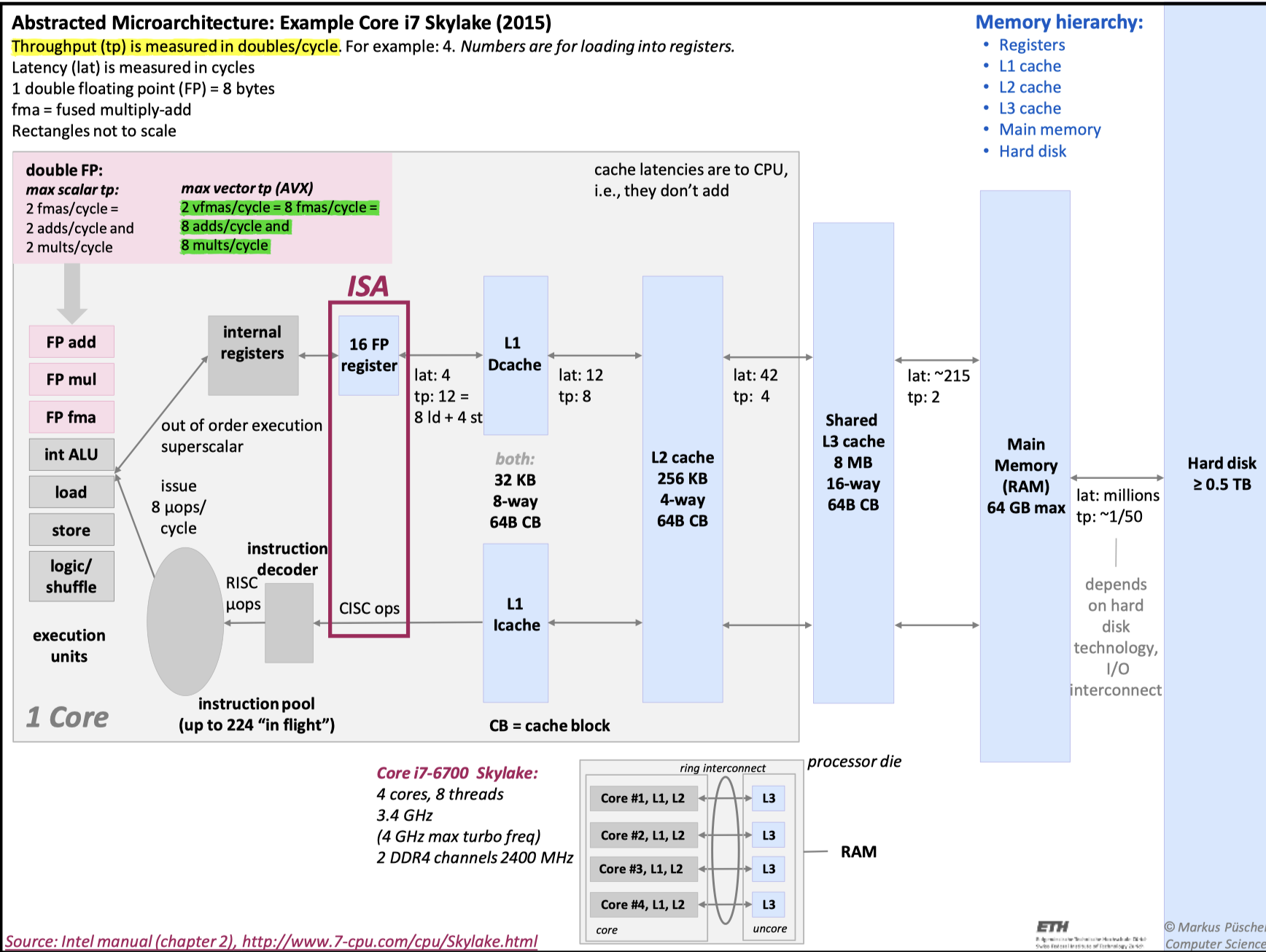
这是一个 Superscalar 的模型,这里可以参考我们之前的 notes:
这里,指令被解码后,你会看到一组 ports,来帮助进行程序的执行
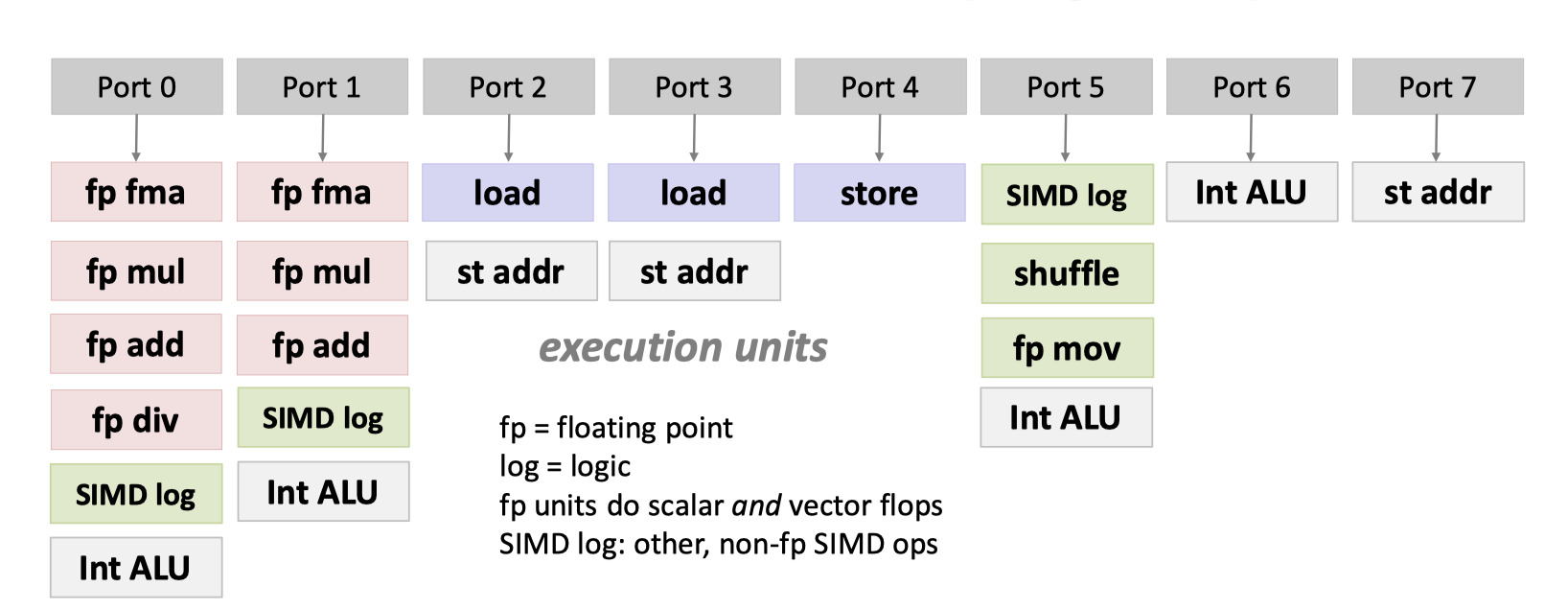
可以回顾一下之前 notes 里面 OoO 的图,这里又一些 SIMD/fp 等的执行单元。
每条指令执行的效率是不一样的,同时如上图,fp fma、SIMD log 可能有多个执行单元,这不会影响延迟,但会影响吞吐:
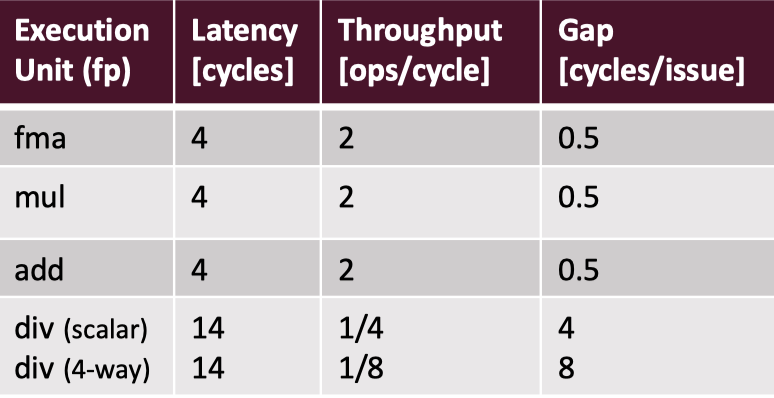
关于相关指令,可以访问:https://www.agner.org/optimize/instruction_tables.pdf
你也许会发现 div 特别慢,可以参考 ref 11 来学习。这个也可以计算出各个指令的 flops/cycle
衡量应用: Besides O(N)
complexity 是程序员都很熟悉的东西,有一个很好的入门回答:
- 为什么时间复杂度中可以忽略常数? - 伊莉雅SAMA的回答 - 知乎 https://www.zhihu.com/question/361692674/answer/2635594762
这里,程序的分析可以引入对内存 - 计算的访问,区分操作是 memory bound 还是 compute bound:

和

有一个很有趣的 case 在 ref 4: https://stackoverflow.com/questions/18159455/why-vectorizing-the-loop-does-not-have-performance-improvement/18159503
查看你的机器
学以致用,笔者有一台搭载了 Apple M1 的 Mac 和 AMD 3800X 芯片的台式机,可以看到,下面对应的参数:
References
- Intel tick-tock: https://zh.wikipedia.org/wiki/Intel_Tick-Tock
- Mircoarch cheatsheet: https://github.com/akhin/microarchitecture-cheatsheet/
- Micro arch 有关的博客:
- 一个非常有趣的问题: https://stackoverflow.com/questions/18159455/why-vectorizing-the-loop-does-not-have-performance-improvement/18159503
- x86 wiki: https://zh.wikipedia.org/wiki/X86
- VLIW wiki: https://zh.wikipedia.org/wiki/%E8%B6%85%E9%95%BF%E6%8C%87%E4%BB%A4%E5%AD%97
- 指令级并行,线程级并行,数据级并行区别?线程的概念是什么? - 用心阁的回答 - 知乎 https://www.zhihu.com/question/21823699/answer/172571488
- FMA wiki: https://en.wikipedia.org/wiki/FMA_instruction_set
- Intel’s Haswell CPU Microarchitecture: https://www.realworldtech.com/haswell-cpu/
- Instruction table: https://www.agner.org/optimize/instruction_tables.pdf
- Div: https://stackoverflow.com/questions/26907523/branch-alignment-for-loops-involving-micro-coded-instructions-on-intel-snb-famil 和 https://stackoverflow.com/questions/4125033/floating-point-division-vs-floating-point-multiplication