ICDE'19: Presto: SQL on Everything
本栏想介绍一些大数据和 OLAP 相关的东西,因为本人对大数据相对没有存储那么熟悉,所以很多地方可能早期写作的时候不会有太多自己的理解,以后读代码或者什么的时候会尽量补充一下。这里的 Ref 段也会引用一些国内介绍的二手文章,来便于做一些简单理解。
Presto 在 facebook 内部比较早的时候会在 Hadoop 系的系统上查询。13 年左右的时候开源出来了,据说 facebook 自己没那么管,然后 fb 出来一波人搞了个 Presto DB,后来更名为 Trino。在国内使用者中,用户会使用 Presto 来做一些 ad-hoc 的 AP 查询,然后用 Spark 做一些 batch job。本文在 19 年发表于 ICDE,作为 Presto 的总结。论文比较简单直接,没有扯很多花头,而是比较简单的介绍了一下 Presto 都在做什么。文章细节还是很多的,基本上可以作为一个引擎的详细介绍。
论文的标题是 SQL on Everything,用户可以设置 connector (数据源) 之后,运行 SQL。源头包括 HDFS、S3,也包括一些对应的外表。它会解析 SQL,然后去分布式的执行它们。Presto 包括了
- SQL 对应的解析和优化。这里的重点应该关注这个 Plan 是怎么分布式调度和执行的。
- Connector,对应类型丰富的数据源。新数据源应该也可以编写自己的 connector。
接下来上论文吧
Introduction
Presto 认为自己的关键字是:adaptive / extensible / flexible:
- Adaptive: 多租户、可扩展到数千节点庞大的集群中、能处理 memory / io / cpu bound 的各种优化。
- Extensible: 允许用户对接各种数据源的数据,只要 connector 靠谱
- Flexible: 支持各种类型的负载
此外,它还要求支持高性能:新的查询不会起新的 JVM 容器,而是在单机 worker 的 long running JVM 进程中运行。这用调度和资源管理的复杂度来优化了 response time。
这篇论文描述了:
- Presto 的架构和实现
- 一些关键优化对性能的提升指标。
Use cases
论文描述了几个 use cases:
- Interative analytics:
- 处理少量数据 ( 50GB-3TB 的压缩数据)
- 并发 50-100
- 对响应时间比较敏感
- 可能会 kill, 或者 limit 来限制查询结果
- Batch ETL
- transformation 带来的 CPU 开销大、aggregation 和 Join 内存开销可能大致数 TB
- 吞吐量很重要,响应时间没那么重要
- A/B Testing:
- 数小时内完成分析
- 结果完整且准确
- 可以拿到各个时间段的分析,所以预聚合可能不太适合
- 可能需要 JOIN 几个非常大的数据集,比如 user, device, test, event attributes
- 查询相对之前几个比较固定
- 开发者/广告 分析 (好家伙,我用的 Google analytics 应该就是这种)
- 给用户而非开发者使用
- 查询相对比较固定,包括 Join / Aggregation with window
- 数据总量很大,但是可以过滤掉非常多的数据
- 查询时间尽量在 ~50ms - 5s
Architecture overview
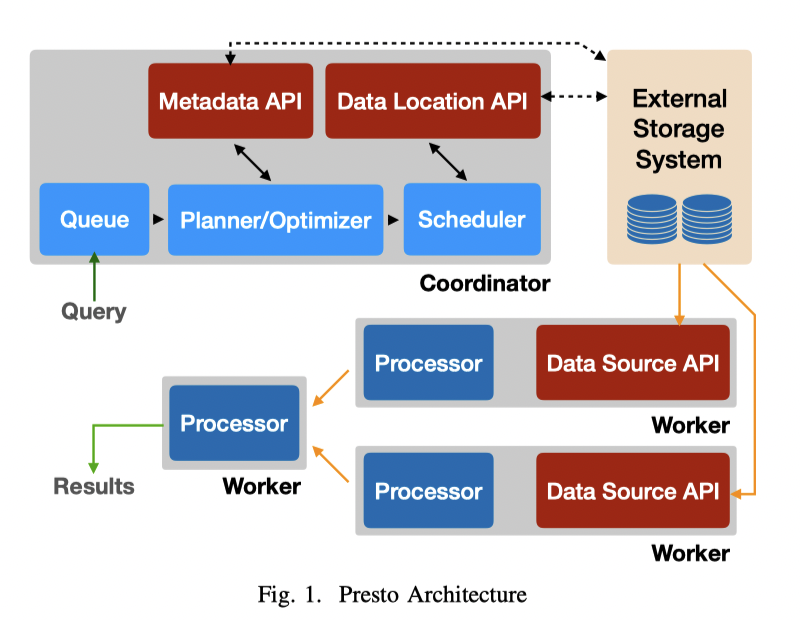
Presto 的进程分为两种:
- Coordinator
- Worker
这个 Coordinator 和 2PC 那个不是一个东西,它负责解析 SQL、分发查询(可能一些特别轻的 SQL,或者在 meta 直接处理完的、schema 相关的不会发给 worker?)。它负责:
- 请求的 queue
- 生成、优化 distributed execution planner
Worker 则负责读取数据、执行 Coordinator 产生的各个算子,它也负责读取对应数据源的各种数据。最底层的 worker 会分配到对应的 split,split 是外部存储系统的对应数据/数据范围。执行的时候有下列几个基本组成部分:
- Statement: 用户对应的 SQL 查询
- Query: Presto 收到用户查询的时候,生成的 Query,这里可以当成 Presto 处理 sql 后的结构
- Stage: SQL 会被拆成多个 stage
- Task:单个 Stage 内会有多个 Task
单机的并发中,机器靠并发执行 Task 来做到并发,Execution 尽量是 pipeline 执行的。Stage 间的数据会尽量存储在 memory 中,当在 node 间 shuffle 数据的时候,也会尽量用 buffer 来降低 latency (recall: Spark RDD)。
Presto 提供了很多 Plugin API,包括:
- Data types / functions / ACL / event consumer / queuing policies
- 最重要的是,它开放了对应数据源的 connector 接口:
- Metadata API: Data 对应的元数据,比如 schema 等,其实是一组繁杂的 api
- Data Location API: 数据分布的 api
- Data Source API: 读取数据的 API
- Data Sink AP: 写入数据的 API
实际上,Presto 不仅可以借助这些 API 完成和优化对数据源的查询,甚至可以借助这套 api,比较轻松完成一些任务,比如说联邦查询
System Design
Presto 接受 SQL 查询,同时,有 RESTful HTTP 客户端和包括 JDBC 在内的各种连接,查询生成包括你们都听到腻的几部分:
- Parsing: 用基于 Antlr 的 Parser 来将 SQL 转成 ast,然后做一些语义上的分析
- Logical Planning: 处理 ast,生成 PlanNode 的树,如下图(这个 SQL 要用到很后面)
1 | SELECT |
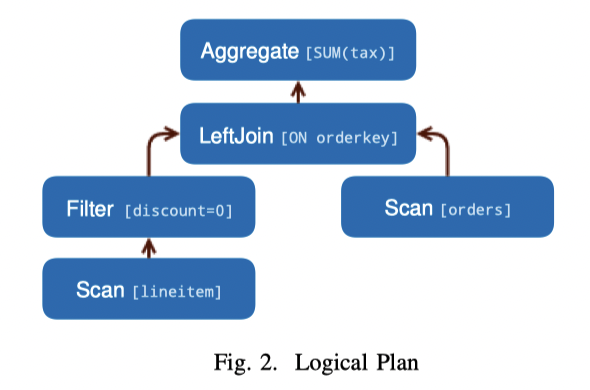
然后进入 Optimization 阶段。论文里 Optimizer 描述的比较简单,CMU Talk 2021 介绍了一些 Trino Optimizer 的设计。它有 rbo 和 cbo 部分,会根据代价算各种 MPP 优化,之后我应该会专门介绍。比较关键的是这里会根据下列信息作决策:
- Data Layouts: 根据 Data Layout API 拿到 partitioning, sorting, grouping, indices 相关的 properties。
- Predicate Pushdown: 根据 connector 选择是否下推 range / equality,提升查询性能
- 这包括可能推一些 selection filter 之类的东西,或者要不要推一些东西到存储上,connector 会提供一些相关的信息,还是很管用的
- inter-node parallelism (增大 node 间并发): 可以并行的部分可以拆分成专门的 stage,举个最简单的例子,扫描大量简单数据,然后 agg。这个因为扫描大量简单数据在有些情况下拆分开来并行扫描是可能更优的,所以这里可以唱分成一个 stage,每个 stage 在部分 input data 上执行同样的操作。stage 计算完毕结果会放到本地的内存 buffer 中。Stage 之前依靠 Shuffle 来进行交互。Shuffle 将带来比较重的 CPU 和网络开销,所以 Optimizer 应该慎重作出抉择。Figure 3 表示了 Optimizer 大概生成的内容(后面会对这个再优化):
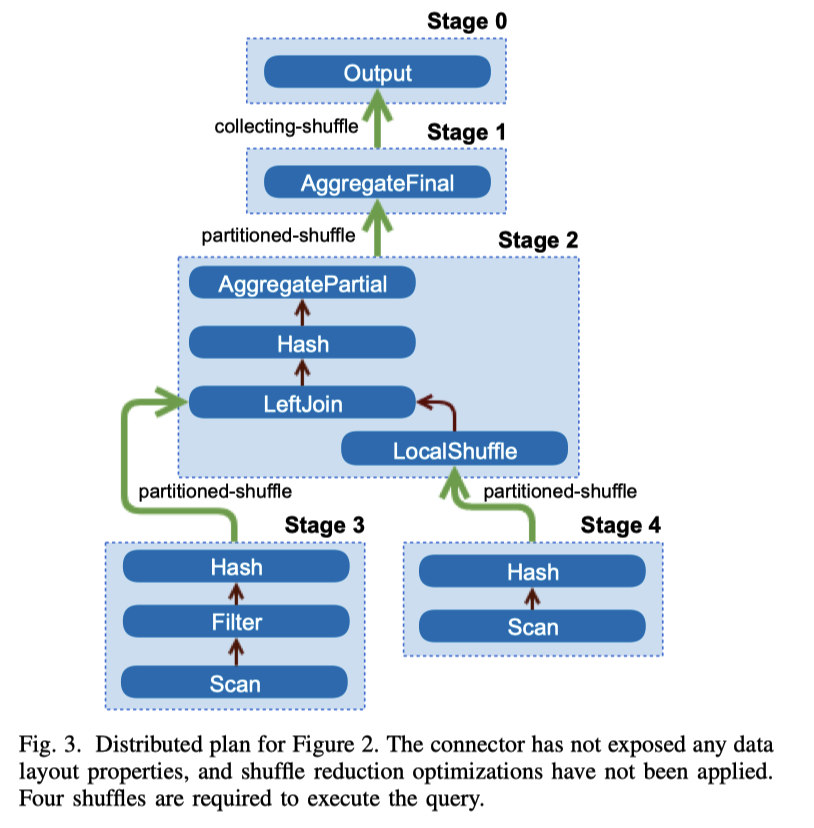
生成之后,优化器需要根据一些 API 来进行优化,包括:
- Data Layout Properties: 可以根据 partition 之类的,来做一些 co-located join 相关的优化;或者如果发现某个 Join Column 是 Index 的时候,走 index nested loop join;也可以根据 MySQL 的 Partition 和连接的性质来做优化。在 Batch ETL 或者 AP 查询中,这里也可以做很多的数据裁剪。
- Node Properties: 这里 Node 是指 PlanNode,这个类似 Cascades 模型提到的 Properties,节点会有 partition / sorting / bucketing 之类的信息。查询也可以设置 Preference,表示亲和的、必要的 properties,在优化 shuffle 的时候,Presto 会尽量满足更多的 Properties。可以根据这些信息来和 Data Layout Properties 一样优化查询、减少 shuffle。这样当然也可能会导致一定的 da ta skew,因为本来是有一定 dop 被分成 stage 的,现在 stage 合并了,所以倾斜的概率也会提高。这个 Figure3 中的表达式,如果有一些 layout properties 是可以尝试合并的。
还有一些 intra-node parallelism 的处理:在单个 node 中,可能会因为 skew (比如用户随便写了个 SQL,没咋优化,也没咋设计 partition,就很容易 skew)或者 job 本身太大(在少量节点执行重 ETL)导致 Task 很重,然后 Task 的 Executor 没法快速消费下游生成的数据,这也不太行。节点内并行能稍微缓解一些这些症状,如下图:
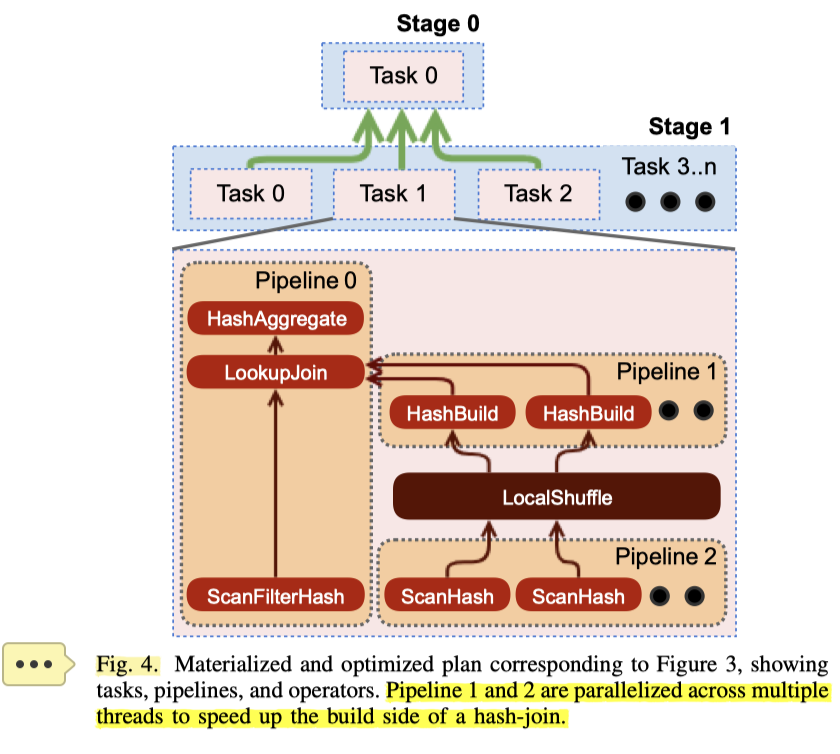
这里在 Hash Join 的 Build Side 中,在 Pipeline 1 和 Pipeline 2 中引入了并发(我感觉这个相当于识别到不需要多 stage 处理,但是执行的时候会在一些 operator 里尝试并发?),原本的 Scan -> Hash 被拆分成了两个 pipeline。
所以回顾一下,Optimizer 大概会:
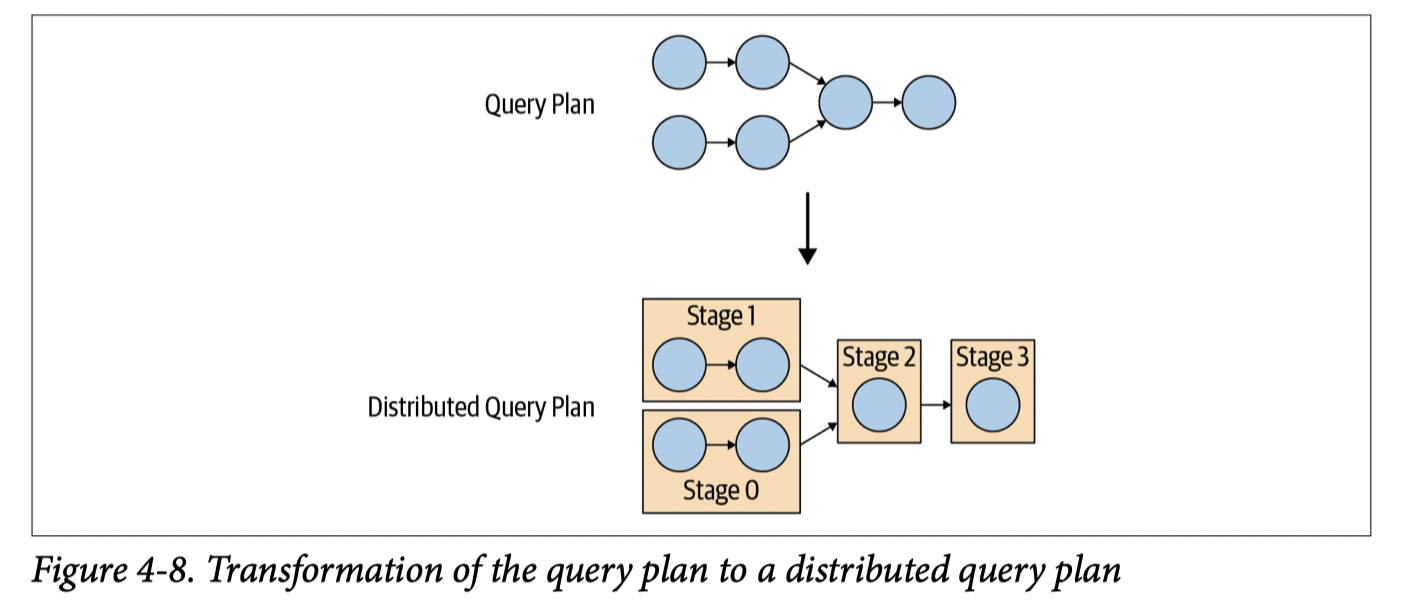
Scheduling
Coordinator 会把 Plan Stage 产生的 Executable Tasks 分发给 workers,然后也会有 task stages -> task stages 的数据通路,让最后有一个执行树。
Task 可能包含一个或多个 Pipeline,Pipeline 是 Operator 的链(like HyPer),当 Optimizer 发现一个 Pipeline 需要内部并行来提高性能的时候,就会尝试并行(我觉得基本上就是 Figure 4)。其实这里可以视作在不同级别做拆分操作:
- Probe Build 可能被拆分成 Stage1 -> Shuffle -> Stage2
- 这里在同一个 Stage 中,成了 Pipeline2 -> LocalShuffle -> Pipeline1
顺带一提,我搜了下 google,竟然没搜到 LocalShuffle 这个词。
上述是 Optimizer 的部分行为,然后 Execution 的时候,调度行为如下:
- 看那些 Stages 需要被调度
- 看多少人物需要被调度,被放置到哪些 node 上
Stage Scheduling 有 all-at-once 和 phased 两种策略:
- All-at-once 全部调度,减少了一定的 latency(但是资源开销可能比较大?)
- Phase Scheduling 需要避免死锁,比如避免 Probe 比 Build 先运行。在 Batch ETL 场景大大减少了内存开销。
当 Scheduler 需要执行某个 Stage 的时候,这里需要 assign 一定数目的 tasks 到对应的 nodes 上。Stage 被分为 Leaf Stage 和 Intermediate Stage。Leaf Stage 从 Connector 里面读取数据,而 intermediate stage 会拿到别的 Stage 生成的数据。
对于 Leaf Stage,这里会根据 Connector 和 network 相关的配置,来分配任务到各个节点上:
- 极端的说,如果是 shared-nothing 部署,Leaf Stage 需要完全分配到对应的数据节点上
- 此外,会根据之前提到的 Connector Data Layout 相关的 API 做调度。
分析场景有很大一部分开销在解压、decoding列存编码、过滤和数据类型转换上。这些任务算是 cpu + io bound 的,所以它们会被 dispatch 到尽量多的节点上(老实说,我觉得应该有个根据统计算的计算公式,比如:https://github.com/apache/arrow/blob/master/cpp/src/arrow/io/caching.cc#L52 )
这里也会根据网络来做一些配置,比如要求尽量读同一个机房的数据。
对于 Intermediate Stages,这里会根据 properties 和数据分布决定 worker / task 数量,甚至能够一定情况下动态更新 tasks 数目。
在 Leaf Stage 中的 worker 会被分配 Connector 中定义的 split,这个 split 相当于数据源中的一段数据,比如 Parquet / ORC 文件中的某段,或者是 Redis 的 server, key-value 等。Leaf Stage 需要被 assign 对应的 Split 才是可运行的,而中间节点在 assign 后一直可运行,并且在消费完上游数据或者 abort 之后完成。
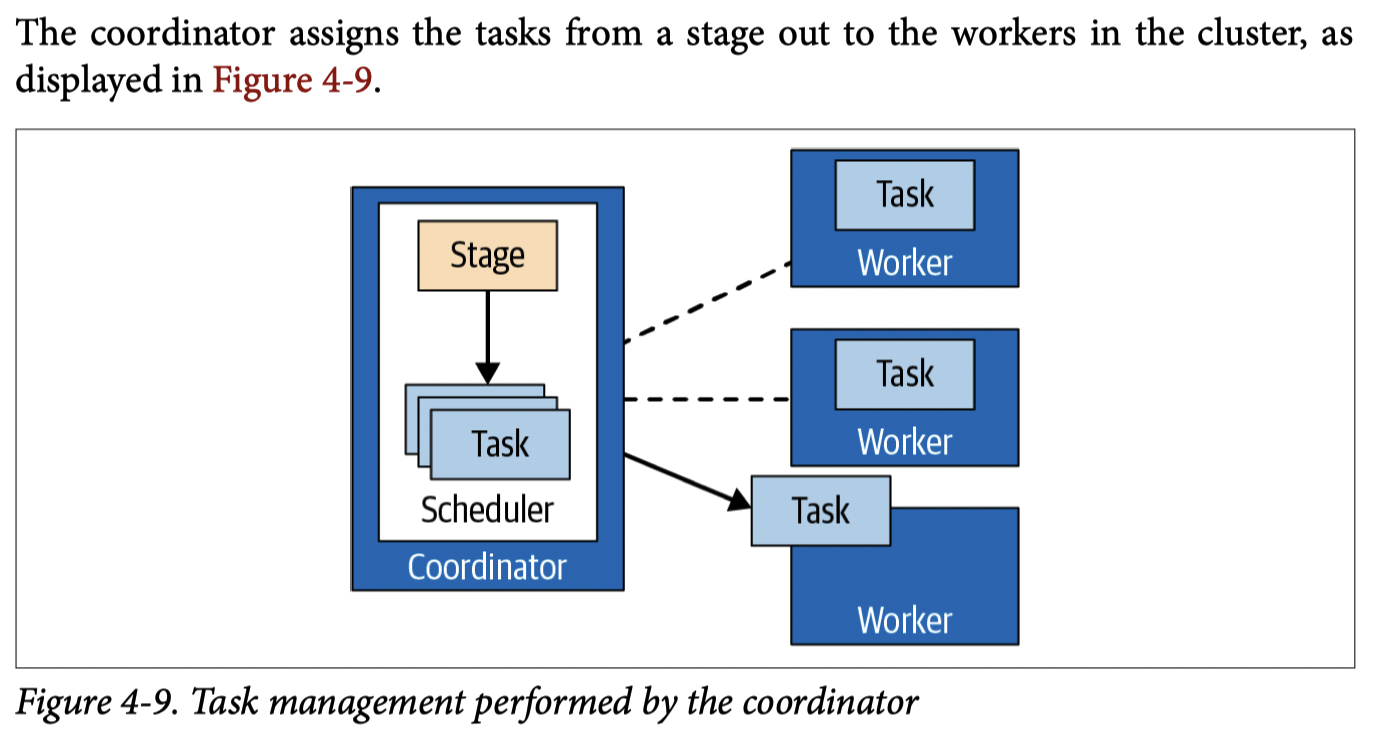
关于 Task 的分发,这里会让 Connector 枚举对应的 split,然后一点点分发给 worker,这个地方希望:
- Hive 之类的 Connector 枚举可能需要很久,这里可以部分解耦查询时间
- 不处理完所有数据就生成查询结果
- worker 上维护 split 队列,coordinator 会根据队列剩余长度来做一些调度,来一定程度避免 skew 和适配负载
- split 搞完了就不一定要存在内存中了,在访问几白万个 split 的时候,降低内存和 tracking 的开销。
当然,这个可能也会导致估计查询进度不准确。
Execution
单机执行
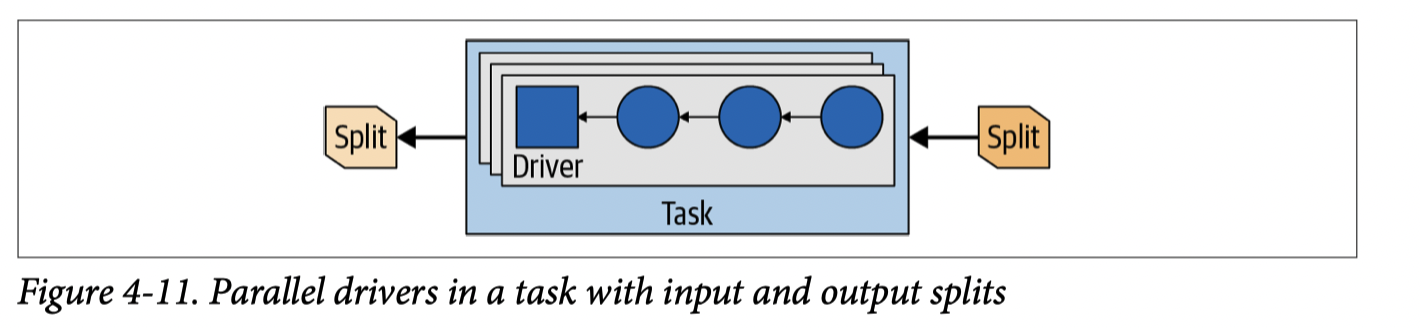
Presto 在单机执行上有 Operator 和 Driver 两个概念,Driver 类似之前执行图中的单个 Pipeline 中的单个并行单元,在论文中,Driver 特点是:
- 以 Page 为单位,处理数据,Page 类似 Figure 5
- Pipeline 的处理 Operator,这里可以很简单的发现哪些是 blocking 状态,然后可以让出线程;非阻塞状态的 Page 可以在 Operator 之间移动
Shuffle
对于 Shuffle 而言,Presto 使用长轮询来拉取数据,即使数据很小,这样也有良好的不高的 latency。buffer 也需要一定的调整,buffer 太小或者消费跟不上导致 full 的话,split 处理就无法继续了,而且会占着大块内存;反之,如果 buffer 利用率不够,每次积攒了一些小 buffer 都被取走了,那么实际上网络这些开销就会比较大。
这里通过监控来调整消费端(下游)与输出端(上游)的数据:
- 当上游 buffer 利用率持续比较高,这里会尝试减少分配给它的 split,来降低生产端数据产生。论文指出这样能优化不少对应的内存开销。
- 接收端会计算自己每个请求平均从下游获取了多少 bytes,然后来算一个合理的获取数据的并发。
写操作
对于写操作,Presto 也会调整对应的并发度。当写入 Buffer 占用过大的时候,这里会增大写的并发度,来调整对应的效率(这里举了个 S3 + Hive 的例子,但我没完全 get 到)。
资源管理
因为需要执行不同的 Task,Task 又包含各种 Pipeline,自然,做 Task 级别或者更下层的调度和资源管理也很重要。这里单个集群可能有数百的并发,同时也有一个资源管理系统。
CPU Scheduling
Presto 最关注的资源就是 CPU。node 级别的 scheduler 对 turnaround time 时间短的小查询做了特殊的优化,同时,对 CPU 资源需求差不多的查询做了公平共享(fair sharing)的调度。Task 的资源使用量等价于每个 split 的 CPU time 之和,同时,调度的时候,节点会记录自己 node 上 Task 执行的时间,然后做 Task-level 的调度。
在并发处理上,Presto 使用了协作多任务的模型。每个任务最多有一个 1秒钟的时间片,在运行完 1 秒后,它需要重新进入任务队列。当 output buffer 满了(下游消费数据慢)或者上游 buffer 空、系统没有足够内存的时候,系统会调度别的任务。
在调度策略上(即选择下一个调度的任务),Presto 使用了 MLFQ 来做调度,用 CPU Time 来做调度的指标。在执行上,这个依靠 connector 提供的 async api 和 yield signal,这样 io-task 就可以让出对应的 cpu 了。同时,相对来说,batch etl 调度优先级会低一些,而短的任务通常会被很快的执行
Memory Management
内存申请需要走 Pool,然后被标记为 user memory 或者 system memory:
- user memory: 和用户的输入数据有关,能够反馈给用户
- system memory: 系统内部的实现,大小和用户关系不大,比如 shuffle buffers
这两个限制是分离的,同时,超过了节点级别内存限制或者各个节点总内存开销超过限制的 Query 会被 kill 掉。而如果机器内存不够,task allocate 不出内存,它会 blocking 直到能够申请内存。
节点级别内存和总内存可以限制并行度、防止 skew,这个都…莫名很好懂,感觉可以参考 DynamoDB 的 WCU / RCU。当然,这里 Batch ETL 会遇到内存不够用的情况,所以这里提供了 Spilling 和 Reserved Pool:
- Reserved Pool: 预留内存池,类似 DynamoDB 的 burst 资源池,已经无了,因为 trino 讨论者认为这玩意没有起到实际的作用
- spilling state to disk. Presto supports spilling for hash joins and aggregations.
- However, we do not configure any of the Facebook deployments to spill. Cluster sizes are typically large enough to support several TBs of distributed memory, users appreciate the predictable latency of fully inmemory execution, and local disks would increase hardware costs (especially in Facebook’s shared-storage deployments).
Fault Tolerance
在论文发表的时候,Presto 似乎对 fault tolerance 支持不是很好:
- Task / Stage 之类的错误,会重试
- Coorindator 的错误会导致整个服务不可用。在 fb,Interactive analytics 和 batch etl 用 standby coordinator,A/B 和 analysis 则用多个集群。
- Presto 认为 ckpt 之类的策略都过重了,所以写文章的时候还没支持。听说还有用 Presto on Spark 支持 batch ETL 的,真的牛批
Query Processing Optimizations
JVM
利用 JIT,调整 GC。不懂 Java,不锐评了。
Codegen
不懂,不锐评了。
File Format Features
这个我可太懂了…
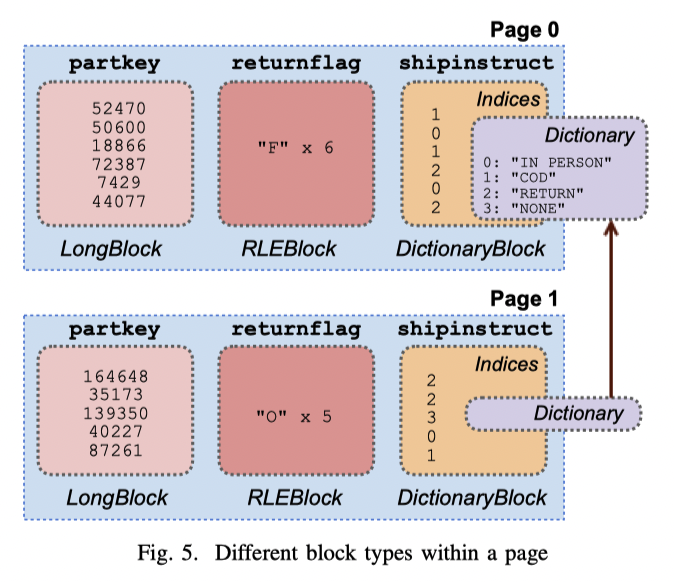
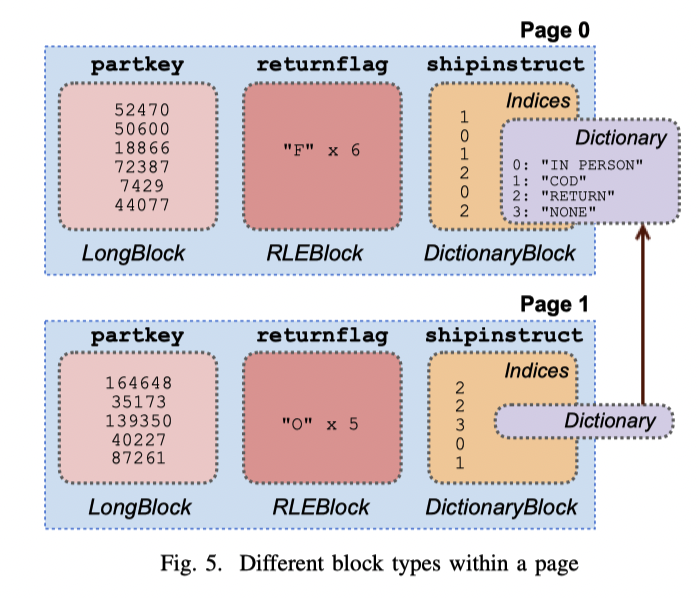
这图有比较细节的部分:
- Page 是有不同的列的
- Page 内列块为 block,可能是编码的数据
- 如果是字典编码,那么字典是可以 reuse 的
Lazy Data Loading
Connectors can generate lazy blocks, which read, decompress, and decode data only when cells are actually accessed.
Given that a large fraction of CPU time is spent decompressing and decoding and that it is common for filters to be highly selective, this optimization is highly effective when columns are infrequently accessed.
这里类似 Select a where b < xxx; 的时候,如果过滤效率好,很多 a 相关的列就不用一起解压了,但实现起来其实是很多脏活的。
Operating on Compressed Data
参考 abadi 的论文,我之前博客也提到过:https://blog.mwish.me/2022/01/15/format-thinking-2/#DB-%E7%9B%B4%E6%8E%A5%E5%9C%A8%E5%8E%8B%E7%BC%A9%E7%9A%84%E6%95%B0%E6%8D%AE%E4%B8%8A%E8%BF%9B%E8%A1%8C%E8%AE%A1%E7%AE%97
References
- Trino: The Definition Guide (这本书有第二版,但我没下载到靠谱的,所以翻了下第一版)
- Presto概述:特性、原理、架构 https://zhuanlan.zhihu.com/p/260399749
- Presto Explain: https://prestodb.io/docs/current/sql/explain.html
- 分布式SQL查询引擎原理(以Presto SQL为例)https://zhuanlan.zhihu.com/p/293775390
- Presto 是如何 schedule task 的? https://zhuanlan.zhihu.com/p/58959725
- Presto 数据如何进行shuffle https://zhuanlan.zhihu.com/p/61565957
- https://docs.qq.com/slide/DZVhBRlhqc2dhVHda