Offset-Value Coding
Napa 系统中,排序会被用在 Index Lookup Join, Streaming Agg 和 Hash 的一些对 hash key 的操作中。这篇文章介绍了 RLE 和合并中使用 OVC 的效果。
对于作者来说,他认为 ovc 起到的效果类似 Hash Join 的 Hash Code,也能辅助 Interesting Order。在这里的场景可以当成一个固定 Schema 下的排序,和一种 dynamic 的 poor man’s key。OVC 由:
- offset indicates the first difference between them (the first column or the first byte) and the
- value indicates the data value at that offset, suitably normalized for ascending vs descending sort
- Offset and value are combined into a single order-preserving integer.
在 Napa 中,排序列属性通常比较复杂,比如 20-50列,有的列只有 3-5 的 NDV。下面有一个对应 OVC 的计算例子,即 Table2,假设 Domain 为 100(这个 Domain 我理解可以定义为max(单列的 Domain)):
- 出现区别的是在第三列(以0开始算),所以有 3,为了防止 Negative,所以配置
+ 1 - Domain 是 100,所以
* 100 - 出现区别的列是 44,因为顺序是 ASC,所以这里采用
-44
我们其实可以看到,这里 Fig2 是一个非常非常简化版的 OVC。
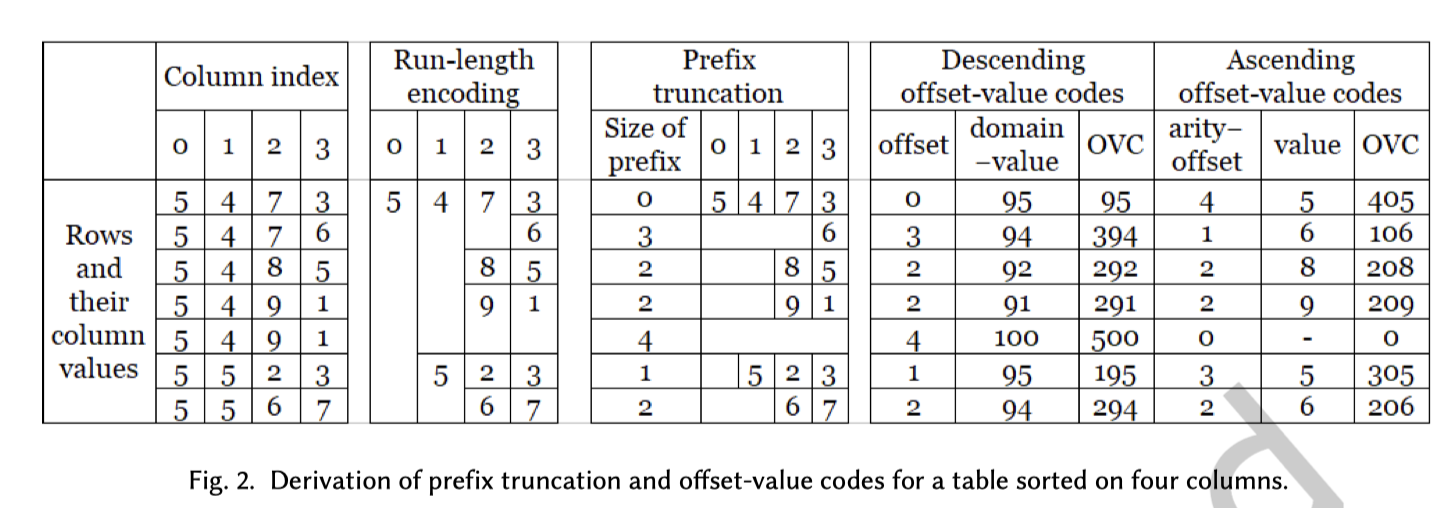
这里 OVC 的规则非常简单(我写到这里,突然想出一件事,就是这个地方 OVC 是「精确」的),我们可以举例,限免用颜色可以定义出对应的 OVC 的机制。
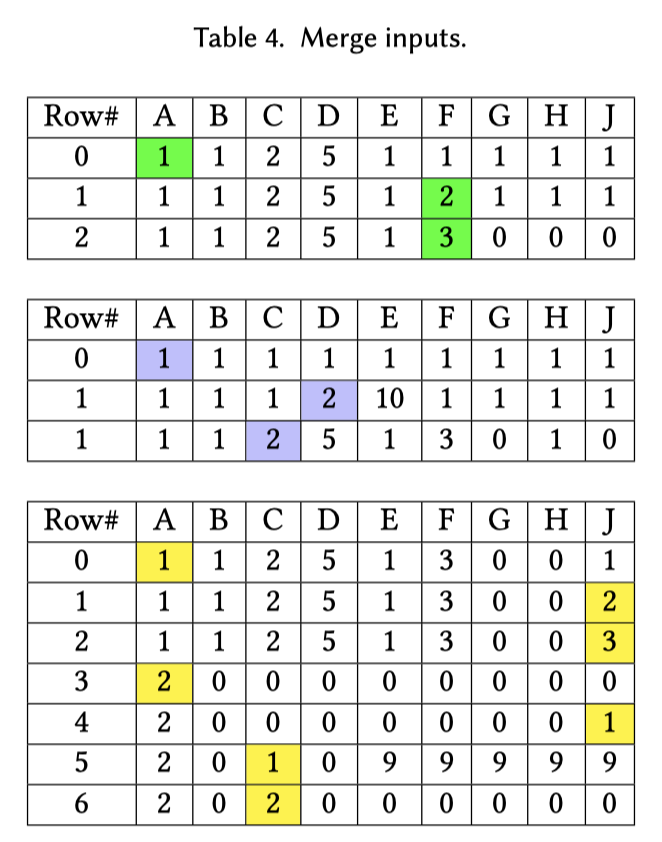
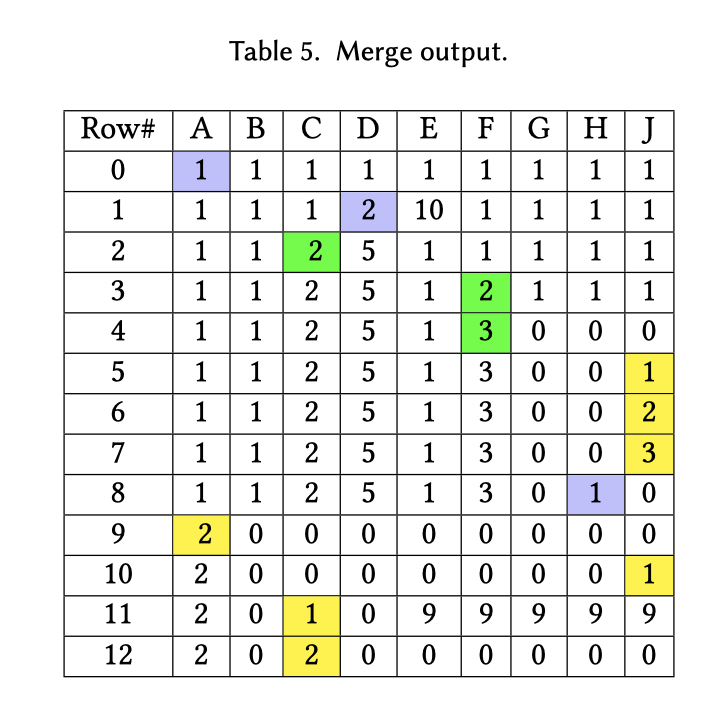
这里合并的时候,比输了需要跨流 Re-compute OVC
论文还提到了 Key 的编码相对 OVC 的修改:

- Low fence keys: 如果 Run 没有初始化,是一个空成员,预留
Run(capacity个 ID ) 来处理 - Current run: 这个意思我当初看的时候理解了好久…最后发现是 Run Generation 的时候那种,比如基于选择的 Run Generation,这个时候 Current run 可能有同一条流有更小(大)的值但不能 flush。因为前面的 id 被 assign 给了
run, 所以 要ovc + capacity - Next run 就是这个加上
maxuint / 2 + 1 - High fence key 是给消耗完的流(但不想调整 LoserTree 的结构)用的
关于 OVC 的计算,可以参考 SIMD 代码 ( listed in paper and generated by ai )
1 | // 输入:二进制串A、B;串长度len_A、len_B |
好的,上述内容之后你懂了 OVC 吗?实际上这里的性质才刚刚开始
OVC 在败者树中的 Compare
我们需要回到之前的图 Table 4。我们假设:
- OVC 流初始化的时候,类似一个最小的空字符串,每条流的第一个值都可以算出
(offset=0, value=value[0])的一个 OVC - 假设每条流有一个自己的 OVC(per-stream OVC),和之前一样
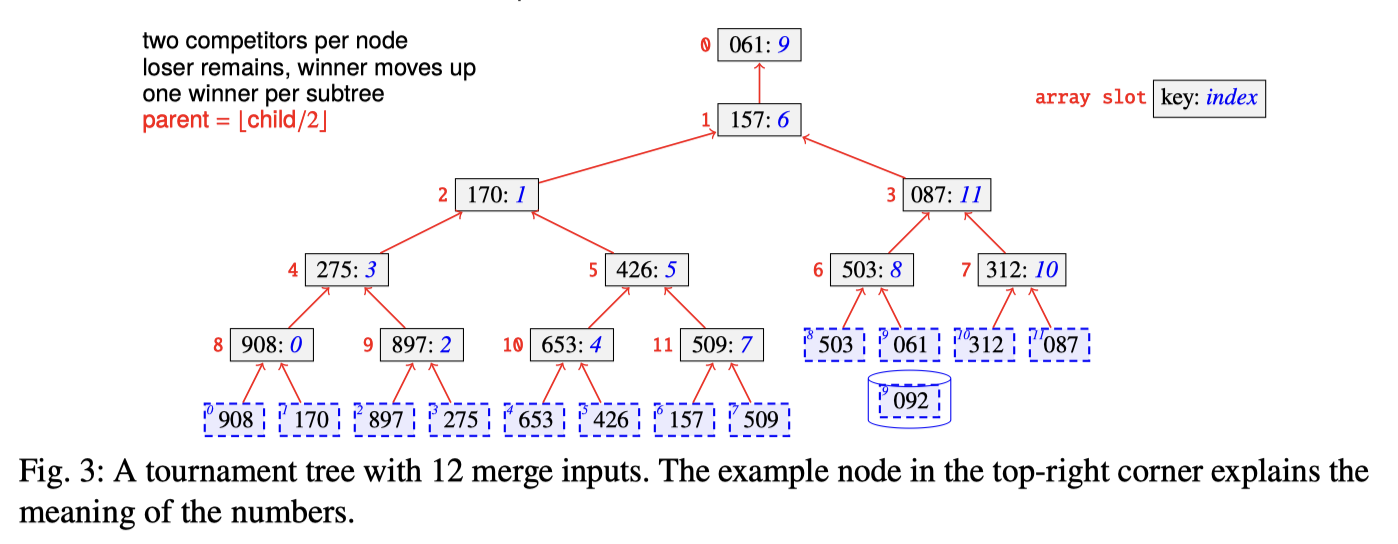
我们可以按照论文列出一个算法:
1 | Data: s₁, s₂: strings of length l with offset-value codes relative to the same base row |
和
1 | Data: S₁, S₂: sorted sequences of rows with offset-value codes |
这个地方有两个地方值得注意:
- 0 的 061 OVC 向上移动的时候,整条链路上的 OVC 都是和上条流本流的值比较的,如果这条流只比较 OVC 就退出,那么这个地方下一条流对比的值
- 另一个比较好理解,
i ← offset(s₁.ovc) + 1,这个地方是从 equal 的 OVC offset + 1 开始比较。
我们重点关注 (1)
- 假设原来 index 都是 0,那么整条链路已知
OVC(A0, A1),OVC(A0, B0),OVC(A0, C0) - 假设最后 A1 还是新的最小,那么我们希望拿到
OVC(A1, B0),OVC(A1, C0) - 如果 OVC 相等,那么会找到相等的 OVC Offset 来重算 OVC,这个地方没有问题
- 如果 OVC 不相等
- 如果 offset 不相等,那么比较失败的应该 offset 还是比较失败的 offset,OVC 保持不变
- 如果 offset 相等,比较失败的 value 更小,还是保留
所以如果 A0 最小,那么最后 OVC(A1, B0) = OVC(A0, B0)
实际上,关于别的论文还提到了个 OVC 推论:
$ovc(A, C) = \max(ovc(A, B), ovc(B, C))$