Mac CPU Tools
这段时间有一次顺手优化了一块代码之后,发现性能提升远比我预期的要多。事情是这样的,我摘取了一个最小浮现代码,最后发现自己写错了。按我之前朴素的理解,这里提升应该在 3.5 倍左右。性能提高了固然好,但是这个地方怎么说呢,如果是非预期的性能提升,后面可能藏着 bug,比如我优化前后逻辑不一致了,如果预期性能 x3,但是实际 x10 的话,我当然要检查这里 (1) 是不是优化的时候藏了 bug (2) 如果没有 bug,这个性能提升怎么来的?答案是写出了 bug,这点再次说明了 (1) 应该让 ai 做 code review (2) 无论优化还是劣化,都应该让它符合预期。超过预期的事情需要尽早清理。
火焰图
在 cargo flamegraph 工具可以看到 flamegraph。https://github.com/flamegraph-rs/flamegraph 。注意 cargo flamegraph 会自己采样的。所以你开着 cargo flamegraph,另一个进程采 perf 的话,会不如您所愿的。
我们先跑起来 benchmark
1 | RUSTFLAGS="-C force-frame-pointers=yes" cargo bench |
用 Instrument 采样旧代码,我们可以看到
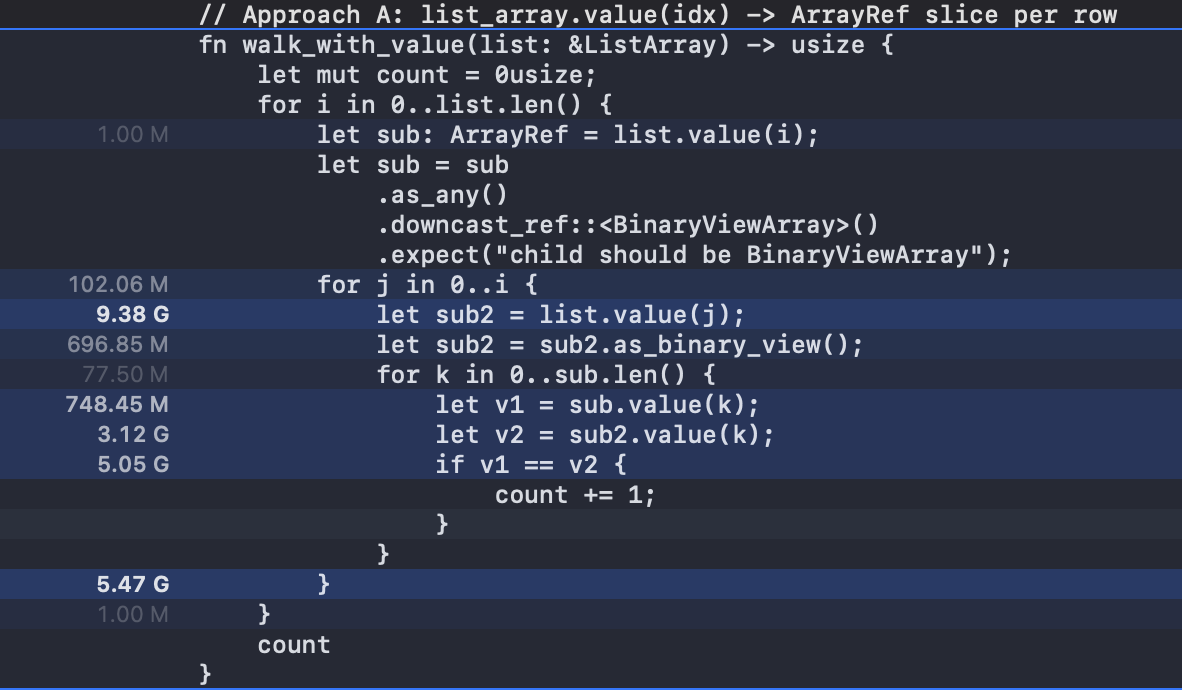
这里逻辑大致上是合理的。
看看 Instruments
那差异是怎么来的呢?我在 Mac 上跑了一下 Instrument,我们来看看。下面两个是采样30秒的结果
旧代码:
1 | Useful 41.66% |
新代码:
1 | Useful 86.75% |
看看汇编
接下来我们看看汇编差异。我使用的是:https://github.com/pacak/cargo-show-asm 工具。这样对比一下可以看到一边少做了很多事情。
小插曲
Perf 采集 benchmark?
我当然在 cargo bench 生成了结果,但是这中间还是经历了一些波折。
- Cargo flamegraph?
- 你在 perf 的时候如果开 cargo flamegraph,你会发现这个进程会经常在自己调用一些 stacktrace 之类的,对于火焰图来说这个很科学,但是你自己调用的时候…开什么玩笑。所以这里应该就自己跑跑 benchmark 就行
- Benchmark 的长度?
- 你可以看到,我这里上面为了结果能尽快跑出来,设置了
row_size = 1024,我们假设你设置 1024,这里测试能很快跑完,但是perf观测到的东西可能就会包含 benchmark 框架上的东西了,结果难免有一些失真。这里我们可以把row_size设置成一个比较大的值,让这里进程能长期做有意义的事情,perf 观测到的能够尽量不包含这些不该有的状态。 - 在这里我又碰到个小插曲,我个人 Mac Air 为 16G 内存(穷鬼是这样的)(对了我为什么不用 PC 测我傻逼吗)。
- 你可以看到,我这里上面为了结果能尽快跑出来,设置了
总结
总结:这个问题其实分析完是个特别简单的问题,感觉意识到了之后好像就特别好理解,和呼吸一样自然。