Napa paper short comments
其实我在25年10月才认真看 Napa 的论文,确实有点太晚了。不过看完了感觉没看也不亏。只能说精髓还在 Graefe Goetz 发的那几篇 Paper 里头,介绍一些 Merging 的细节。没细节的东西看的还是不够劲。
Napa 是一个声称在广告之类的场景取代 Mesa 的系统。他的存储可以定义多个 Primary Key / Sort Key,用户从 ingestion framework 写入数据,写入的收据不是天然可查询的。然后对用户提供 Queryable Timestamp ( QT ) 的配置,允许用户给出一个软配置,然后定义 Non-queryable delta。
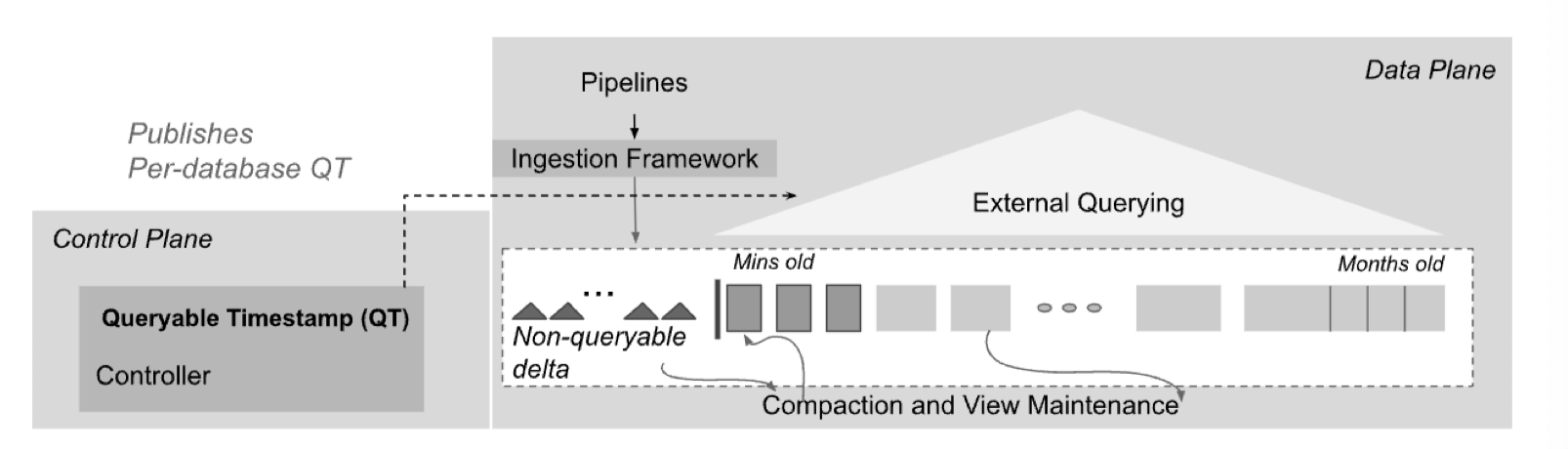
从后面来看,这套查询和时间戳的定义类似 BigQuery 的 Vortex 系统,见 Vortex: A Stream-oriented Storage Engine For Big Data Analytics,这里也定义了 non-queryable delta 和可以 query 的 QT,猜测 Google ad 的特征工程团队会有流式的特征,强依赖这个 QT。
QT 我理解某种程度上指导的是后台可以调度的资源。比方说,跑 Spark 之类的东西的时候,用户可能要从一个共享资源池中指定自己需要多上资源,然后针对不同的数据大小使用不同数量的资源,比如 Delta 小一点就配置小一点的资源,Delta 大一点就配置大一点的资源。我个人感觉 QT 本身是一个资源,协调了用户(前台)的 deadline 需求到后台的各种配置。不过这也是一家之言。
Napa 也会为基础表生成 View,这里似乎有「分区」「排序」两种属性,可以认为这里和大部分现代分析系统还是一样的,主要成员是分区和排序。
Napa 架构大概是:
- Colossus
- 以 F1 Query 系统提供查询
- Spanner 处理事务语义
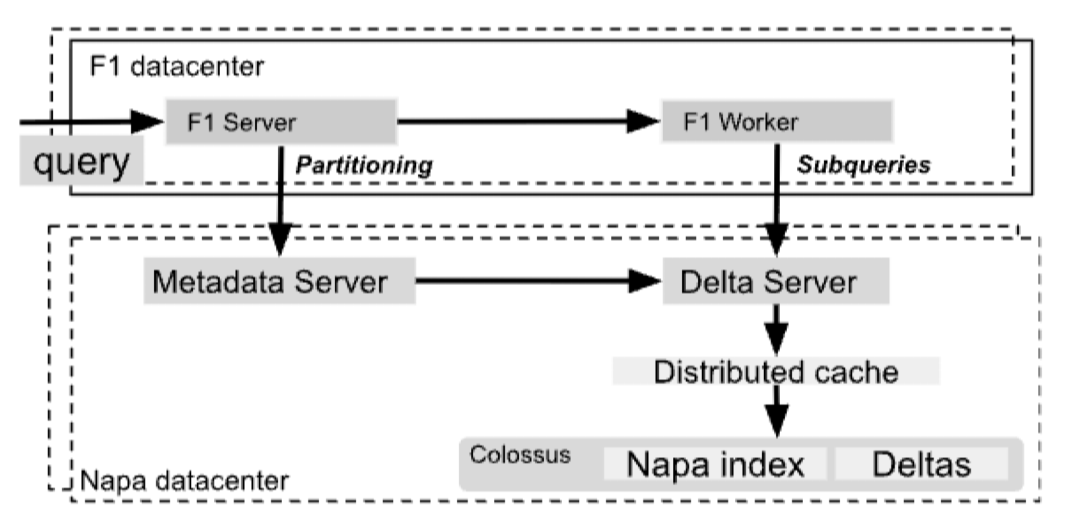
实现上,这里如上图,做了数据面控制面分离。Napa 选择了 Range Partition (猜测是 Range 在一些方面跑的稳,然后可以做的工程优化比较多,Hash 感觉其实不怎么优化都能跑的相对快)。
Ingest 的流程如下
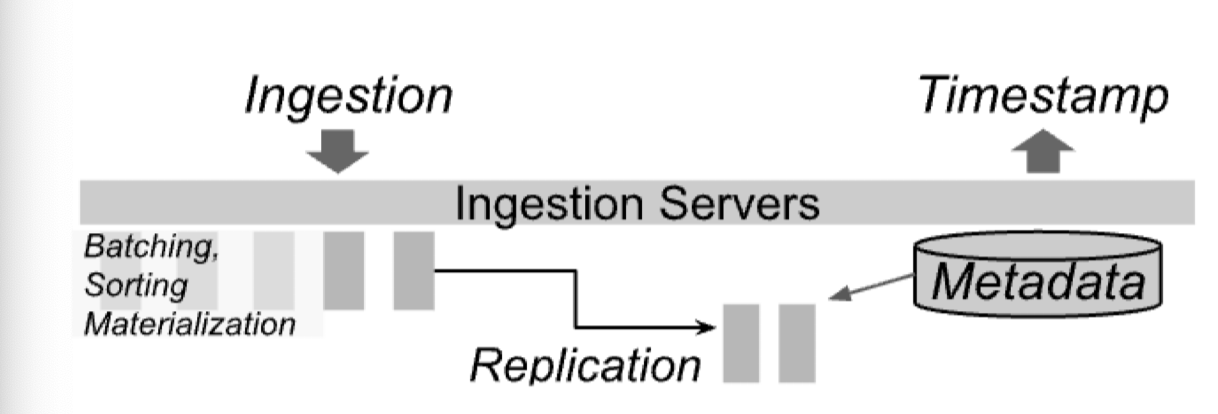
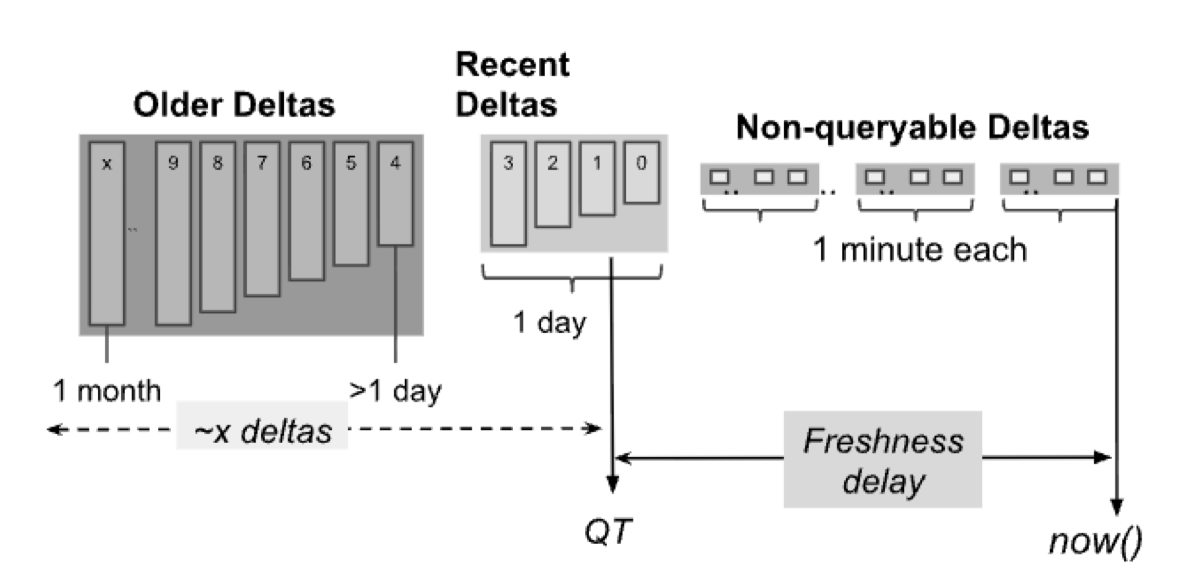
在 Build View 的时候,这里采用了 F1 的优化器来处理 skew 之类的(啊 skew handling 明明是我有点想看的)。
Napa 这里提了很多前缀优化,可以看到,这里在 Napa 中,有很多「根据一个 view 或者一个 dataset 去优化另一个 view 构建」的流程,这也让 OVC 之类的排序在这里变得非常起作用,因为需要很好的利用这个 Sort order 或者 sequence 的概念。在排序器实现中也有 tie 之类的东西,前缀排序还是很重要而且久经优化的领域了。
这里也提到了具体 compaction 过程的优化:
- 需要维护合并过程的 Sort Run 在一钱左右。这里提到,多个 Run 合并在前台 Query 是不太划算的,因为前台 query 的时候,1000个 Run 会导致长尾;但是后台任务看的是吞吐,可以提供更大一些的 fanout 来减少最终合并次数
- 靠预读 io 来减少读取开销。这里其实有个点是前面维护了 Sort Run 数量在一个比较大的位置。所以这里在消费完一个 run 后,可能会有一些处理需要配置,比如每个流的 io tuning 之类的。
论文第八章讲了一些线上 serving 的经验,暂时没有兴趣,先跳过。