External Sorting and Run Generation
之前写过两篇入门的排序的文章:
- https://blog.mwish.me/2024/09/27/Sorting-in-Database-System-Part1/
- https://blog.mwish.me/2025/01/02/Sorting-in-Database-System-Part2-External-Sort/
后面那篇 Paper 介绍了不少 Run Generation 的部分,但是 Napa 之类的系统实际没有这样做 Run Generation。在后面的一些论文中,提到 Napa 的 Run Generation 采取了另外的策略。下图来自 Robust and Efficient Sorting with Offset-Value Coding 。这里上下两部分分别出现在不同的论文中。
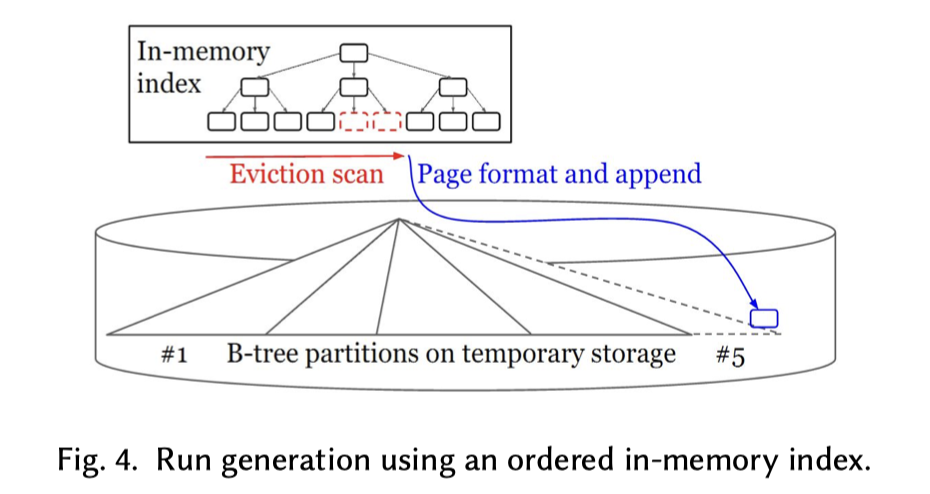
我们需要关注:
- External Sorting: Run Formation Revisited
- CIDR’03: Sorting And Indexing With Partitioned B-Trees
在之前论文的 part2 中,我们介绍了替换选择算法,但是没有对系统的内存管理提出什么意见,比较有意思的是下面的图。这里的意思是,在 Run Generation 的时候,如果用排序,那么本身排序会有排序的内存开销。如果是 Run Generation,也有 Run Generation 的内存管理。
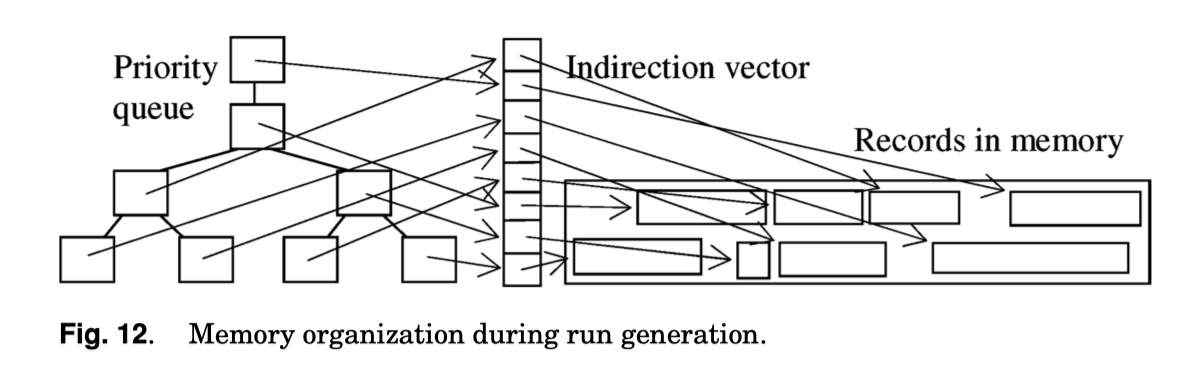
我们回顾一下一些老一些的论文,来回顾一下一个「标准」的 External Sorting 是如何 Run Generation 的。
Run Generation
Per-Åke Larson 在 98 年和 Graefe Goetz 一起发表过 Memory management during run generation in external sorting。
我们注意到,Run Generation 在现在,比较方便的方式是直接:
- 限制读取数据的内存大小
- 对数据进行 Sort,然后 sink。这个流程本身可能会消耗一倍的内存( column to row,最后消费 ordered tie,其实都是有可能的,具体看实现)。
这种方式通常使用 QuickSort 和 QuickSort 的变体,本身内存 Sort 大部分时候已经被比较好的实现了,这里有一些问题:
- 输出的大小相对受限于内存的大小
- 如果排序的集合只比内存稍大,这里处理上会有一点点尴尬,仍然要排序两轮
但它的好处也有,无论如何,排序的内存管理都是相对简单直接的。
Replacement Selection,根据我们的 Part-2 那篇博客,这里能构造出尽量长的序列。这里的构造流程大概是构造一个 LoserTree,然后对每个流 fetch ,如果流新的最小元素小于输出的最小元素,那么就停止构建。直到构建下一个文件。
在 Part-2 提到了不少优化。在这篇论文中提到的内容结合了上面一些想法:
- 先对输入的数据进行一些预排序,然后构建一些局部有序的 Miniruns
- 对这些预排序过的 Minirun 进行 Merge
本质上,Merge Sorted Run 也是一个消耗有序流的操作,但是每条流自己 pointer 都是只会后移的;然后 Batch by batch 的内存管理,终归上比一些直接的方法还是简单一些,相当于用简单的方式跳过一些相对复杂的内存管理流程了。
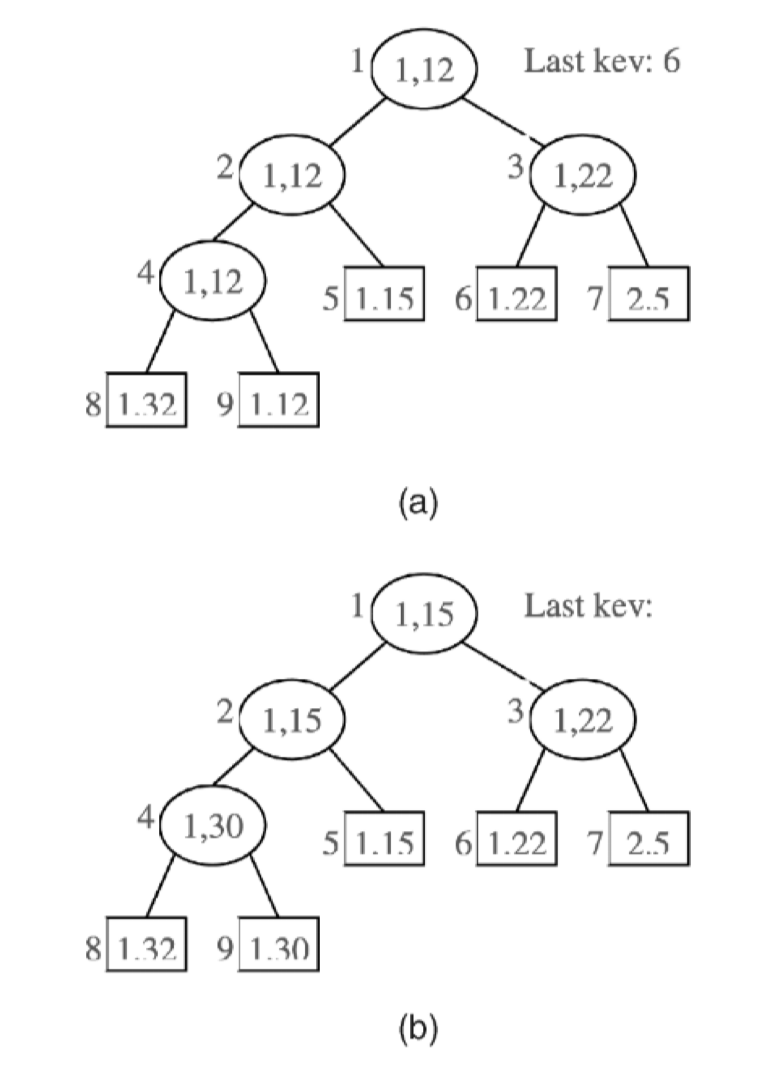
Partitioned Btree
Run 应该怎么管理呢?对于 ap 系统,这里可能本身有 spill 的格式或者存储的格式。然后 Sorting with runs 可以当成 Sorting with spill,可以用 spill 出来的格式来管。用户可以选择 Parquet 之类的格式或者自定义的 spill 格式。具体也可以参考 Velox: https://facebookincubator.github.io/velox/develop/spilling.html#orderby 。在这里,它可以以 RowFormat 或者 PrestoPage 格式来 spill。但本质上,笔者认为,这个地方如何 Merge 在于要执行什么样的逻辑。 Run Generation 的内存管理相对复杂是因为它等价于合并过多个无序的流,这样要么搞得很复杂,要么最大的 Run 比较小。预排序可以取得一些相对的平衡状态,但本身也是需要一定的内存管理的(我们可以实际想,无论是行存列存,Row Fetch 都是有一定粒度的,要么是列存获取一组列,要么是行存拿到一个 Page,要么是列存拿到一组 Page)。
这篇文章的说法是,对于 Btree,增加一个 partition 的 id 作为前缀。然后可以用这种 Partitioned Btree 来管理 Run 之类的东西。作者主要认为,对于当时的 TP 库,Btree 本身 io 之类的是高度调优的,重用一套格式相对是有开发上的很多优势的。作者提到了一些优势:
- 所有最初生成的 Sorted Run 可以放到同一颗 Btree 中管理。Btree 的 async io 和 memory management 的的方案比较成熟
- 作者认为,(可能是 Run 数量有限的情况下?)这个 Btree 是可查询的,一定程度下,效果可能比 Full Scan 好
- 结合 (1)(2) 对于 Sorting 给出了一个中间的事务性结构,某种程度上避免提供了执行的 checkpoint
这里论文比较有意思,先提劣势,提到了六点劣势和作者认为这些劣势可以被工程优化的方案。
- 增加了记录长度,从⽽增加了总磁 ⽤量以及读取或写⼊整个 B 树时所需的磁盘带宽
- 可以采用 Prefix Truncation 来优化
- Page 内的 Search Cost 更高
- 可以采用 Prefix Truncation 来优化
- B 树中的搜索⽐传统的 B 树索引更复杂、更昂贵,尤 其是在存在多个分区的情况下
- 类似 PostgreSQL 那种索引支持多列的情况,优化器自动补充 Search Prefix
- B 树要排序输出
- 借助外部的 Sort 和 MergeSort 来实现,反正那个时候的数据库都做好了这个,不像现在 Velox 对 Sort 优化都不多
- Unique check 代价变高
- 作者认为没啥办法,但是这种 key 不会有很多(我觉得还好?甚至可以延后处理?)
- Key Estimation 如何估计?
- 但现代数据库系统根据采样数据构建直⽅图,并刷新直⽅图的频率⽐重建 B 树索引的频率要⾼得多
这里其实可以看到,很多地方这里感觉是工程上的考量。文章没提 Bulk Insert,但我觉得在 Run 场景中,应该大部分时候是最右侧插入的(对了,往之前的分区插入行不行呢?因为 Run Generation 本质上按照统计,Run 会越来越大?)。这个工程优化还是比较重要的,核心原因是本身 Merge 的复杂性:
- 需要管理多流的 Merge io
- 流大小不一样,比如有几个 Run 特别大的时候,需要大流去更积极的 async io。这里需要有一些东西管理 Run 大小之类的
- 允许并行工作
- Btree 本身天然支持 In Prediction,可以像 RocksDB SubCompaction 一样,分成多个 Sub-Range 去处理
作者认为(类似 Napa Partition 的文章:https://blog.mwish.me/2023/09/08/VLDB-23-Query-Partition-in-Napa/ ),Btree 的 Non-Leaf 本身就有充足的统计,天然适合干这些,而且空间开销较少(作为 LSM,RocksDB 提供了 GetSstFilesBoundaryKeys )。
这里还提到了「虚拟串联」,即如果两个 Run 的 Key 不 Overlap,这个可以视作同一个 Run 来参与合并,但笔者遇到这种场景不多,思考也不多,就不写了。
这里提到了两点:
- 在线构建索引的时候,可以用 Btree 的方式来快速构建索引。增量的形式以 Insert 和 Tombstone 形式插入分区 0,来简化冲突管理
- Bulk load 的时候,可以以分区为对象插入,并且定期调整 Btree 的结构。