The Five-Minute Rule and the Cloud
在介绍内容之前,先讲讲我对共享存储和云存储和使用的理解,好久没仔细这着一块了。下面这块其实尽量只针对存储和负载概述,不做进一步展开。
对共享存储的一些看法
在 2025 年,共享存储已经不再是骗人的话题。尽管「计算存储分离」这个词显得太大太 Fancy 了,但是各种云存储和共享存储已经在各处被用上了。我们可以简单罗列一下:
对于数据而言,首先 AP 这类分析型的系统在 HDFS 时代就开始拥抱这种共享存储上的不可变文件了,如今,snowflake 之类的数据仓库(湖)存储乐于把数据存储在越来越快的对象存储上,对象存储的一个 Bucket 一般默认可以提供 100Gbp/s 的总带宽,然后如果用户用量大可以改大这个带宽(当然你也可以打散到不同 Bucket)。而平均延迟在今年的测试中大概比 TUM 那篇「Exploiting Cloud Object Storage for High-Performance Analytics」快个一倍,符合硬件发展的趋势。分析型任务我们可以粗糙分成两种类型(实际肯定远不止两种,写个博客我就不特别严谨了):T + 1 呀或者别的跑批之类的任务。这类任务 Scan 侧缓存几乎没有效果(可能任务整个大型作业内有某种形式的缓存,比如共享 Scan、某个 Stage 的数据能给多个下游 etc)、需要访问的数据量很大(虽然不能说瓶颈在 Scan,但 Scan 很重),购买弹性块存储的本地带宽,如果花钱少(举例:购买不是很多的阿里云 PL1 盘),可能访问盘总带宽会小于访问对象存储(这里也可以看后面的例子,即论文的 Figure1);另一类任务是 HSAP 之类的 Serving 类型任务,这类任务要么是 OLAP,要么很甚至很接近 OLTP 点查,依赖高效的 Pruning(甚至索引),数据访问量(Scan)和 Join 都不会很重,通常可以保持类似 TP 的高缓存命中率,所以在这个系统中吞吐不那么是重点,通常保持低延迟很重要, Memory Cache 和 Disk Cache 就会变得很重要。本地 NVMe 盘通常非常快,而且临时 Cache 数据不需要那么谨慎的设计,AWS Instance Cache 类的 Volatile 盘就能工作的比较好,也不需要那种三副本设计(当然云上可能用户还是会购买 ebs 盘,因为本地盘机器在很多云厂商都限定了规格)。总之对于 AP 而言,云存储对「读」非常友好,无论是高吞吐还是 Serving 的形式都合适。它缺点在于如果真的需要低延迟低吞吐实时导入的时候,在写入层需要一套比较完整的链路来处理;而这一点对于挂盘的 Sharding 的 AP 系统反而是比较熟悉的领域(当然,它们也有比较复杂的分布式系统问题,也不能说简单,都需要工程实践)。当然,高吞吐的导入,也是利好对象存储的,一般来说在对象存储上做这个又简单、性能又好,吞吐嗖嗖随便你打。然后你的计算节点和存储节点在同一个集群的时候,这里收费也不高,访问吞吐也高。我们回过头来看对象存储这个产品,某种意义上,S3 能卖的比 Cloudflare R2 贵,或许也是它有这样的计算资源。毕竟数据本身很值钱,访问、分析数据就更值得花钱了。
当然,和本文有关。在很长一段时间里,Snowflake 等公司意识到了 S3 这种计算的在存储 TCO 上的价值、这种接口的泛用性。S3 上构建出了很多了不起的东西。AWS 也慢慢回过味了,给 S3 这个已经有十年寿命的产品更大的投入。举例来说,在基础语义上 S3 也支持了 Conditional Update ( https://aws.amazon.com/cn/about-aws/whats-new/2024/08/amazon-s3-conditional-writes/ ),一致性保证 ( https://aws.amazon.com/cn/s3/consistency/ ) ;此外令人,感人更兴趣的在于另一部分的语义,包括 S3 Iceberg Table ( https://aws.amazon.com/about-aws/whats-new/2024/12/amazon-s3-tables-apache-iceberg-tables-analytics-workloads/ ) 和 Vector ( https://aws.amazon.com/cn/blogs/aws/introducing-amazon-s3-vectors-first-cloud-storage-with-native-vector-support-at-scale/ )。如果说,前面几个是非常有价值的性能优化,那么我们必须说,后面几个可能是 S3 对市场使用它们的语义探索。如果有客户而且正经的话,感觉 aws 的友商也会很快跟进。让我们拭目以待。
对 TP 数据产品,事情会复杂一点,尤其是当我们考虑到性能的时候,我们排除 Pangu 这类弹性块存储系统(废话,共享存储就是它们提供的)。在海外,Google 早期的 TP 产品就设计在 GFS 上,比如 BigTable Percolator,这类系统本身也会提供一些 sharding partition 之类的概念。微软的 Windows Azure Storage 是一个对海内外影响都很大的系统,Azure 写了一套 Append Only Storage,然后上层应用都设计在这个 Append Only Storage 上。似乎 Google 的 Colossus 也是这样的。WAS 也直接影响(或许有人直接过去了)阿里云的 Pangu,和国内别的做这一块的厂商。在 zhihu 看到过一个 comment,虽说不是 100% 认同,但是里面说法也能代表存储工程师的观点了(阿里云EBS架构演进 - 黄岩gg的文章 - 知乎 https://zhuanlan.zhihu.com/p/684333453 )。总之,这一块虽然不是大家都用上了,但是我说比较成熟应该也是对的。这里有个问题是,云厂商出于各种问题 (1) 接口使用难度 (2) 难易暴露 (3) 或许是成本原因,对外只提供了 ebs 这种地下挂着多副本的服务,在这种服务上构建共享存储还是有一定难度的,一个是盘本身数据可靠,但拉起时间长,等于虽然数据能保证可靠,但是不可用时间还是长;这里架构改造可能原本三副本盘,现在 standby 或者就够,但也至少需要 standby 的形式。包括最新被 DataBricks 收购的 Neon 数据库就自己写了一套 Log 协议,来快速 Bump 日志;SingleStore 系统上层也是手动写多副本存储,然后再把存储 ship 到对象存储上。对于有共享存储的系统,如果上层存储的节点只有 RW 单节点,那么这里做好 fencing 就行,有 RW 和 RO 。这里存储层可能需要提供一些特殊的 Leader 选举的能力,然后能够 fencing 掉不同的节点(比如提供 Lease 或者 storage epoch 类似的机制,协同工作);然后从节点也要能 Tail 到 RW 写的 Log。这套系统例子是经典的 Aurora,PolarDB,Socrates。数据库这么复杂的系统都能在共享存储跑了,一些不那么复杂简单的系统,比如 RocksDB 之类的,也能跑得很好。这类优化思路可以看 CloudJump 论文,在性能上要做好 Prefetch 之类的工作,处理好共享存储的高延迟。在整体系统分析上,我们可以看到有不同的思路,这个问题下面思考质量都比较高:( Spanner 系 share nothing 架构和Aurora系共享存储架构哪种在将来的竞争中更有优势 https://www.zhihu.com/question/547714000 )。当然比较悲剧的是,TP 大部分小用户主流还是 RDS,AP 大家已经确实实打实大部分开始拥抱共享存储了;然后另一方面,共享存储的存储上限没那么大,但系统设计确实会「舒服」很多,不用你在 planning 的时候去过多考虑分片这种完全估计不准的东西。
HPC 也有很多用户已经在跑在「并行文件系统」上了。这里有个点是,Pangu,Colossus 对外的抽象可能在公司内部有很多形式,但是很多用户其实最后还是希望看到个「(符合 POSIX 语义的)文件系统」,来跑他们的 checkpoint 大量 io 读写。这样的文件系统一部分实现可能是超大的和之前一样的下层存储(比如 Tectonic 就是这样抱了一层 Fuse 来承担业务),但终归是要一个 (尽量是)Posix 语义的接口的。这种被称为「并行文件系统」的系统通常有一些复杂一些的 POSIX Driver,可能有 Fuse、甚至自己做了内核模块然后也有一些专注性能的 Client。这里也要尽量做的更快更好。这一块元数据处理,特别是 Metadata 和处理并发(即事务层)的时候,可能会相对很复杂。
我们更进一步讨论 Manifest/元数据。这个词定义很多而且使用很复杂,我们需要首先定义一下讨论的是什么东西,我们简单定义为类似 InnoDB 的 dd、RocksDB 的 Manifest、Iceberg 的 Metadata 这样「描述数据文件如何存放」系统,在上面处理的事务。这一层只有我们打工仔会考虑,但其实还是蛮重要的。
对于 AP 而言,早期的 Hive 按照一定的目录规则摆放数据和分区,比如 partition by (a, b),可能最后分区目录会有 /a=10/b=hahaha (类似这样,实际上可能会有别的处理方式),然后有一层元数据管理,如果别的读者要读的话,要么走数据库这样的元数据管理来 load 各个分区下的数据路径;要么去 LIST 这些目录来处理。Iceberg / DeltaLake 吧数据目录做成了一些指向固定路径的 Manifest + 不固定路径的 ChangeLog,这样的方式下,写入采取类似 CAS 或者直接写入的方案(在 S3 不支持 CAS 的几年前,可能要依赖数据库和 DynamoDB)。另一种模式是依赖数据库,旧的方案比如 HMS (Hive Metastore),支持了元数据的访问,也是一层大家都认可的接口;新一代系统比如 DuckLake,依赖数据库管理这些 Manifest、Metadata,在我看来和 HMS 想做的事情也差不多。这里还是说,在这几年里面,数据库系统和硬件也卷起来了,因为它们卷的厉害,所以 SQL 系统也在变的越来越便宜、越来越好用,也能处理很多分布式的需求,也便于迁移,比如以前你单机 PG,容量上去了你可以换 RDS 换 Aurora 架构 换 Spanner 架构;另一层含义是,比如我们知道 Snowflake 是在 FoundationDB 上包了一层内容,有点像 TiDB 的 PD fork 了 Etcd,这个方案确实很好,但 AP 数据库的 Manifest 通常包含文件,也会包含裁剪文件、识别用户、鉴权、目录共享等各种逻辑,基于 kv 的接口需要自己包装,而 SQL 可以很方便的给你提供索引之类的东西,实际上相当于花小力气办大事了。令我印象最深刻的是 Google BigQuery 使用的 BigMeta,它认为在它的数据量下,「Metadata is bigdata」,并为 BigQuery Metadata 设计了一套非常轻量的类似 HTAP 的系统(意思是 Meta 快速导入,然后能转换到 BigQuery 里面便于分析的格式,笔者对通用 HTAP 不是很支持,因为这些系统过度复杂而且实际有用的场景并不多,反而经常一端拖累另一端功能的开发,但是这种特定功能的小系统笔者还是很认可的),笔者坚持认为(但可能被事实证明是错的),BigMeta 可能是正确的方向。
某种意义上,我们可以认为,这个时代之前(即 blob 之类的需求不是很重要的一版的分析型用户),在海外的分析领域数据湖领域,胜利者是 Iceberg,胜利的格式是 Parquet。无论你多么不喜欢它们,它们也已经是社区用户和分析型数据库厂商的最大公约数。新的时代有很多挑战者,不知道是挑战者能胜出,还是旧人物能够大象转身。但无论时代怎么用,用户体验大概是在变好的。但上面是数据的一端,实际 Metadata 和 Catalog 这样表管理上,则是大家还处在混乱的状态:DataBricks,Snowflake 都开源了一些自己的方案,也有一些创业公司搞这个,但短期来看还看不到任何大家能做到一起的迹象。
对于 TP 而言,这块则是一个细节问题,比如对于 RocksDB Cloud 和 MySQL,在论文中提到了几个问题:
- RW 节点不能和以前一样删除文件了,Secondary 节点读不到自己的数据是会挂的。这里在回收文件和回收日志上都带来了挑战,本来主节点只需要根据自己的状态来回收,但后来这个回收变成了一个分布式的决策了
- (InnoDB 而言)事务用什么方式同步给从节点,走 Binlog,还是 Redo Log 发送?还是走什么同步方式?
- (对于一些地方,比如 InnoDB)实际上,这里数据刷盘和内存不一定有直接关系。数据库可以被当成 Log is database,你主库一棵树,可以先刷叶子,再刷根;或者反过来。反正主库从日志都能看到这些变更,走 Recover 肯定成功。但是从库(或者 RO 节点)很奇怪,它不能每次看到更新都走一个 Recover,它实际上会消费主节点同步下来的日志和数据。我们可以看做这里面会有一些 implicit 的依赖关系,依赖关系不满足就会有问题。比如 Neon 实现了和 Socrates 一样的接口,简单说就是拆分 Page Server 和 Log Server,然后严格执行 Log Is Database,对 RO Page 读提供一种
GetPage@LSN的接口,这样写入侧 (RW)可以尽量写,不会被读者侧拖慢,在 SIGMOD’25 PolarDB 因为在 PolarFS 上 [2],fs 可以执行 overwrite,所以用比较复杂的方式来实现。
The Five-Minute Rule for the Cloud: Caching in Analytics Systems
The Five-Minute Rule 已经有 40 年的历史了,最初是 Jim Gray 和 Gianfranco Putzolu 在 1985 年做的一个分析,这个分析主要是指出什么数据应该放在盘上,什么数据应该放在内存上。比较意外的是这里有个比较弱的定量分析,指出「1KB records referenced every five minutes should be memory resident」。这里相当于一个缓存上的指导过程,即「如果一个数据块的平均访问间隔时间小于某个临界值,那么将它保存在内存中是值得的;如果访问间隔时间大于这个临界值,那么从磁盘中重新读取更划算。」不过当时这个也是一个基于「成本」的分析。
硬件是在不断发展的,我们可以列出不同年代的 Five minutes rule 论文:
- The 5 Minute Rule for Trading Memory for Disk Accesses and the 5 Byte Rule for Trading Memory for CPU Time. Gray, Putzolu, 1986
- The Five-Minute Rule Ten Years Later, and Other Computer Storage Rules of Thumb. Gray, GoetzG, 1997
- The Five-Minute Rule 20 Years Later (and How Flash Memory Changes the Rules), Goetz Graefe, 2009
- The Five-Minute Rule 30 Years Later and Its Impact on the Storage Hierarchy, Raja Appuswamy, Goetz Graefe, Renata Borovica-Gajic, Anastasia Ailamaki, 2019
最后是今天这篇 Cloud 上的分析。我们先花一点点时间来回顾一下这个结论是怎么得出的。所以我们也回顾一下19年的论文。
Without Cloud
下面是 19 年论文中硬件的各种成本:
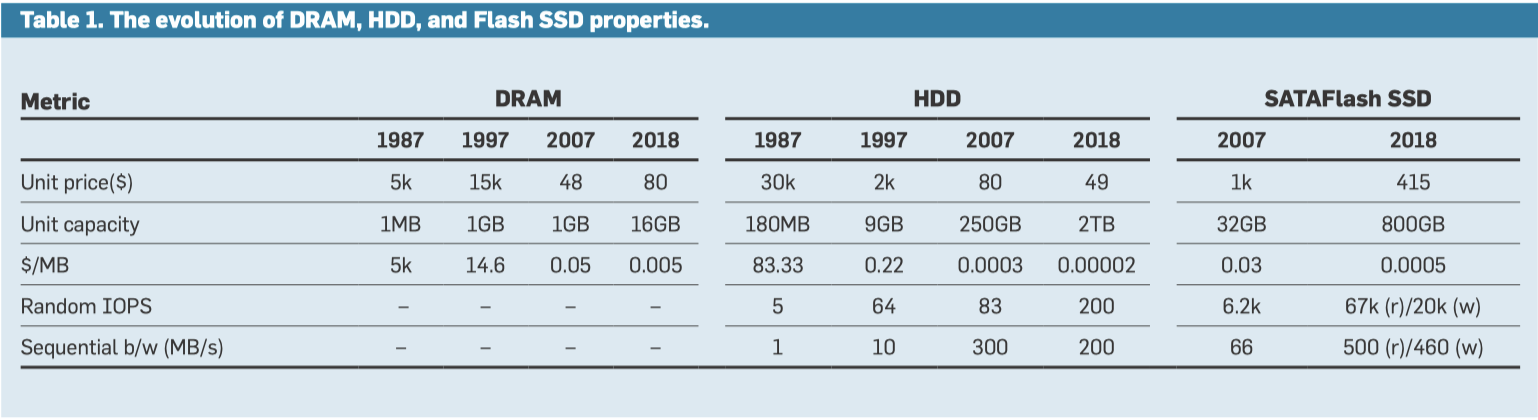
T 被称为 Break-even Interval,即 HDD 和 DRAM 读取成本平衡的时候,对页面访问的时间 Interval。乘法式左侧被称为技术比例( technology ratio ),即由技术决定。硬件有自己的 Page Size,但是这一块我们可以定义成软件的,比如现在 HDD ,即使在直觉上,访问越大块实际上。右侧被称为 economic ratio,它们也是由实际价格决定的。
分析流程可以如下 (注意这里是把硬件成本简化了,实际上硬件成本应该有一个购买的一次性成本和功耗上的成本):
缓存一个 Page T 秒的成本为 。对于一个 Page,每 T 秒访问一次磁盘的成本是 。这里等价时,建立等式,收支平衡时间间隔 (Break-Even Interval)即为最上面的式子。
这里的式子可以看出来,是一个表面上很定量,但是其实只是辅助思考的东西。你或许有点奇怪,为什么在最早的式子而言,DRAM 的成本是设备的直接 MB 成本,而 HDD 是 iops 呢?我个人感觉因为这里认为对于 DRAM-HDD 而言, HDD 在存储容量上有巨大优势,DRAM 在容量上则是瓶颈;DRAM 则在 iops / 带宽上有巨大优势,HDD 这方面完全不行(现在 HDD 瓶颈某种程度上说也是 iops,比较有趣的材料见: https://cloud.google.com/blog/products/storage-data-transfer/how-colossus-optimizes-data-placement-for-performance 和 https://www.usenix.org/system/files/atc23-zhao.pdf )。
下面的表格记录了 87年到18年的趋势:
- 对于 HDD-DRAM,访问实际上是越来越菜了。根据 Table2:
- 将⼤多数数据存 DRAM 中⽐存储在 HDD 中更经济
- 即使是罕见的对 HDD 的访问也应以⼤粒度进⾏
- DRAM-SSD: SSD 进步反而更快?
- 在 DRAM-HDD 和 DRAM-SSD 两种情况下,DRAM 每 MB 成 本的下降都主导了 economic ratio。但 technology ratio 上,SSD 反而占到了便宜
- 2019 的预测表明, 未来五年闪存密度预计每年增长 40%。相 ⽐之下,DRAM 的容量每三年翻⼀番。因 此,NAND 闪存的成本下降速度可能快于 DRAM。
- 现代 PCIe SSD 是⼀种高度并行的设备,可以通过同时处理多个未完成的 I/O 来提供⾮常⾼的随机 I/O 吞吐量。
- SSD 的功耗远低于 DRAM。英特尔 750 SSD 在空闲时功耗为 4W,在活动时功 耗为 22W。相⽐之下,服务器中的 1TB DRAM 在空闲时功耗为 50W,在活动时功 耗为 100W。众所周知,DRAM 功耗随容量 的增加呈⾮线性增长,因为⾼密度 DRAM ⽐低密度 DRAM 消耗更多的电量。
- SSD-HDD: Table3 可以看到,其实把大部分数据放到 SSD,然后 HDD 只做一个「容量层」成为了一个可选项。
- 在2019年,硬盘在 PMR 扩展上遇到瓶颈,从每年密度 40% 增长变成了 16% 左右的增长。
- 相反,磁带本身存储空间更大,一 33% 的速度增长。由于现代磁带 即使是低端磁带库也能实现 1-2GB/s 的累 积带宽。⾼端磁带库可以提供超过 40GB/s 的带宽。但磁带库在访问数据之前需要加载,它的随机访问延迟比 HDD 仍然高3个数量级(分钟 VS 毫秒级)。
- 3D-XPOINT 在 2025 年暂时不聊它了,暂时的冢中枯骨。
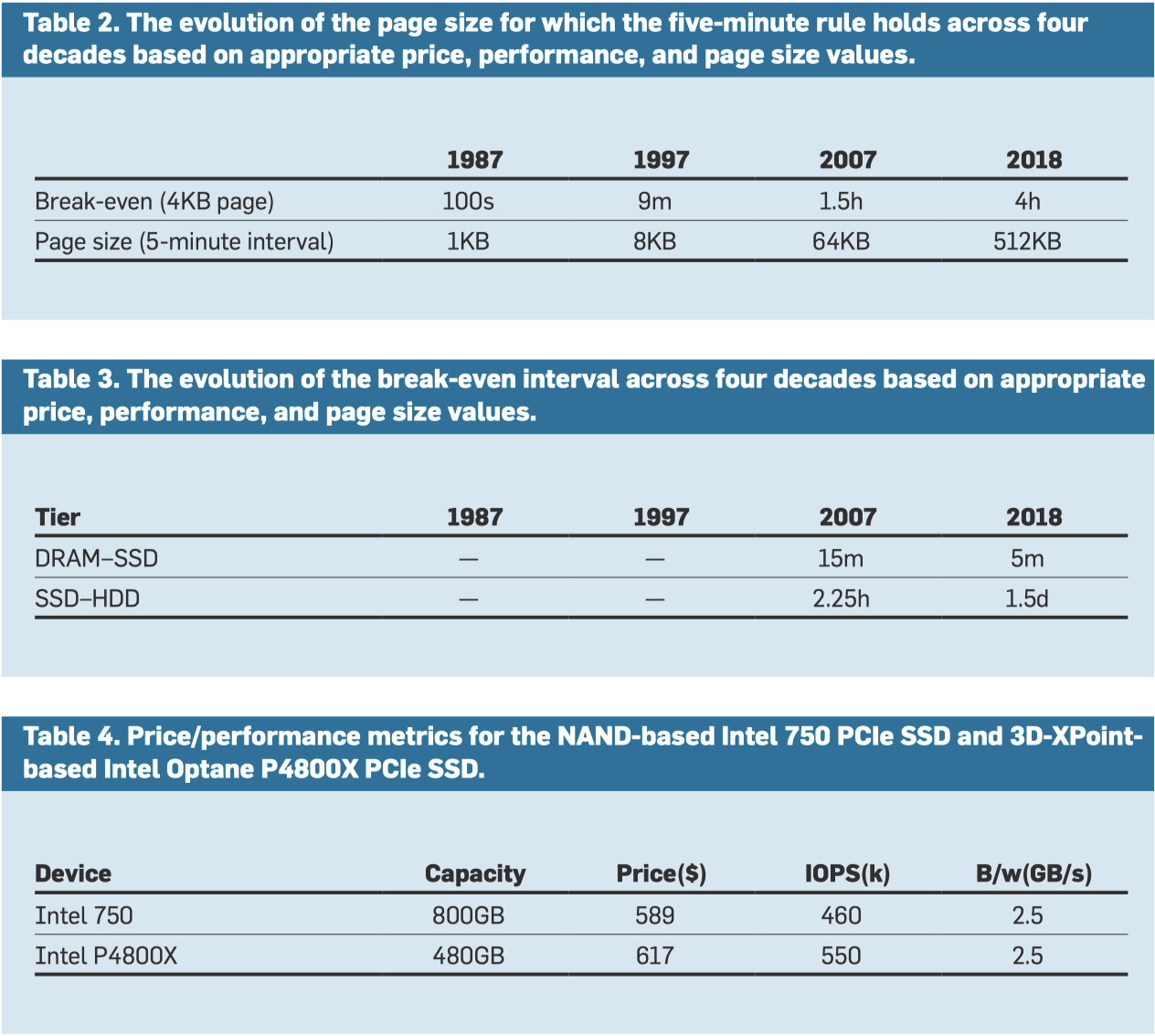
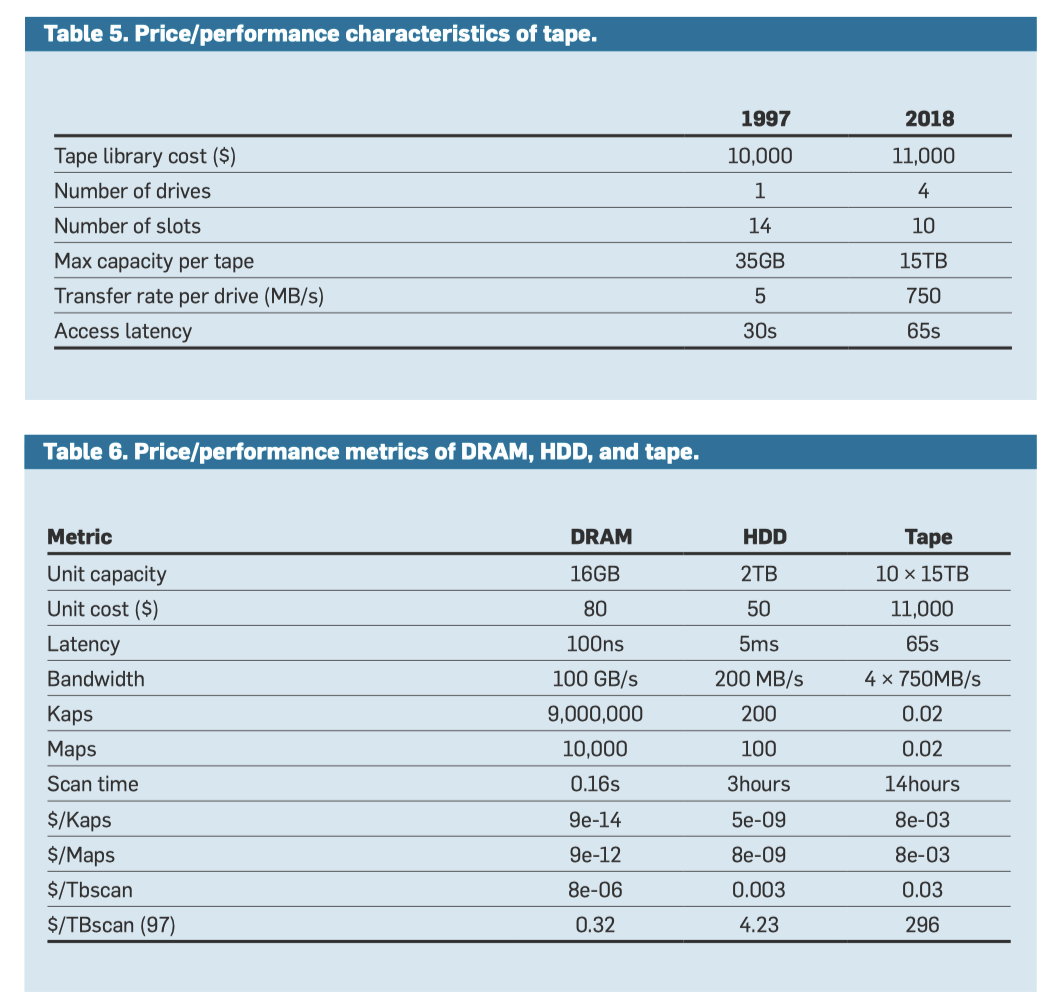
其实这里系统可以按照论文分成几层:按照论文的观点,HDD 本身是为了成本服务,能将主要数据存储在上面的,但是在这个新时代,对于⾼性能 Random Access 的应⽤不应该采用 HDD 了,它是为 了降低存储数据的每 GB 成本存在的,这样可以对这些数据执⾏对延迟不敏感的批处理分析。而也能看到,HDD 和 Tape 的差距某种意义上也在缩小,但是这里重点是 Tape 在 19 年容量扩大速度比 HDD 是快的。
这里我们关注 $/Maps,即 Table 6 中 1M 次操作的成本,可以看到,这里成为了后两者的主要红利区。
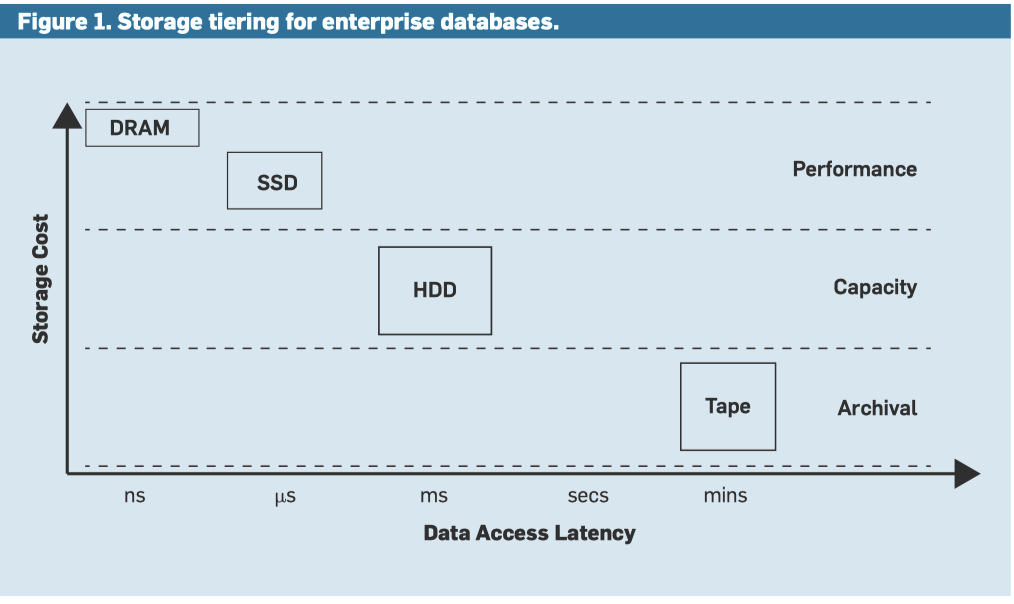
论文提到了个非常有意思的(也比较符合直觉的观点):
如今,企业⽣成的所有数据存储两次,⼀次存储在传统的基于 HDD 的 容量层中,⽤于⽀持批处理分析;另⼀次 存储在基于磁带的归档层中,⽤于满⾜法 规遵从性要求。HDD 和磁带之间 $/TBscan 差异的缩⼩表明,将容量层和归档层合并 为⼀个冷存储层可能在经济上是有益的。 然⽽,通过这种合并,冷存储层将不再是 灾难恢复期间很少使⽤的近线层,⽽是⼀ 个⽤于运⾏批处理分析应⽤的在线层。
Cloud
看这篇文章署名颇有一种不少新贵的感觉。

系统首先有个 insight,是发现在云机器上,盘的性能很菜,S3 的性能很好,论文认为(我不知道是否属实,在我印象中 Instance Storage 带宽是不低的)对 AWS 大部分机型,S3 之类的对象存储的带宽是有优势的。我们在旧的系统中,喜欢一个「存储层次山」的模型。作者们在这篇文章中提出的观点从下图中可以抽取出来:即在云上,Cloud Storage 不能被认为是更下面的一层,它提供的带宽是更大的。
我们之前一节讨论 Storage 的时候,提到 Five Minutes rule 是一个不是很严谨的式子,对比 DRAM-HDD 的时候,笔者认为它的核心是对比 DRAM 的容量和 HDD 的 iops。但在云上,作者认为 cloud 虽然延迟高,但是有更大的带宽,不能简单被看成是 storage 的「下一层」。
这里认为本地存储相对于 SSD:
- 走网络通常吞吐比本地或者 ebs 之类的服务大(比 ebs 大我相信,另一个我保持一定怀疑)
- 本地设备的延迟更低,此外本地设备收费取决于挂载设备的费用,和读写量无关
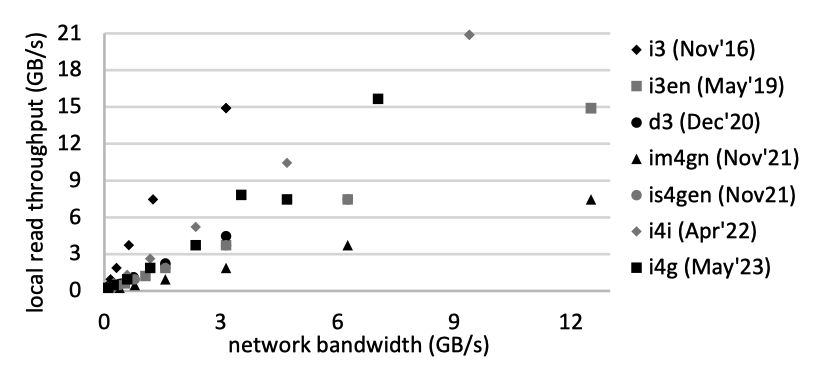
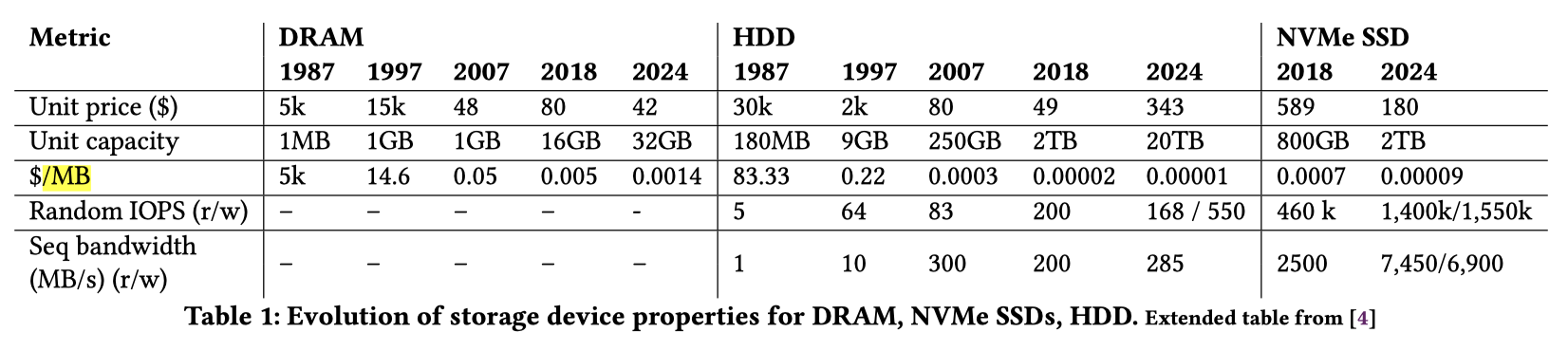
论文先总结了一下 Five Minutes rule,如下图。这里有一个很有 insight 的观点,先阅读一下下面的 Table1。这里核心发现比较有意思(可能在做硬件的人眼里都比较常识了):在 without cloud 一节,我们看到技术比例里面跟盘的容量无关。然后论文给出了个很有趣的例子,对于 HDD,2018 年 2T 盘和 2024 年 20T 盘 iops 差不多,所以技术比率差不多。但 20T 盘实际上贵很多(实际我比较简单的搜了一下,没看到 iops 有那么大的差别,但没啥长进倒是真的)。所以作者认为,云存储也是同样的情况,应该针对 five minutes rule 做一定的修改,来适应这个新的时代。
- https://www.seagate.com/www-content/datasheets/pdfs/exos-x16-DS2011-1-1904US-en_US.pdf
- https://documents.westerndigital.com/content/dam/doc-library/en_us/assets/public/western-digital/product/data-center-drives/ultrastar-dc-hc500-series/data-sheet-ultrastar-dc-hc580.pdf
- https://tauruseu.com/seagate-enterprise-drives/
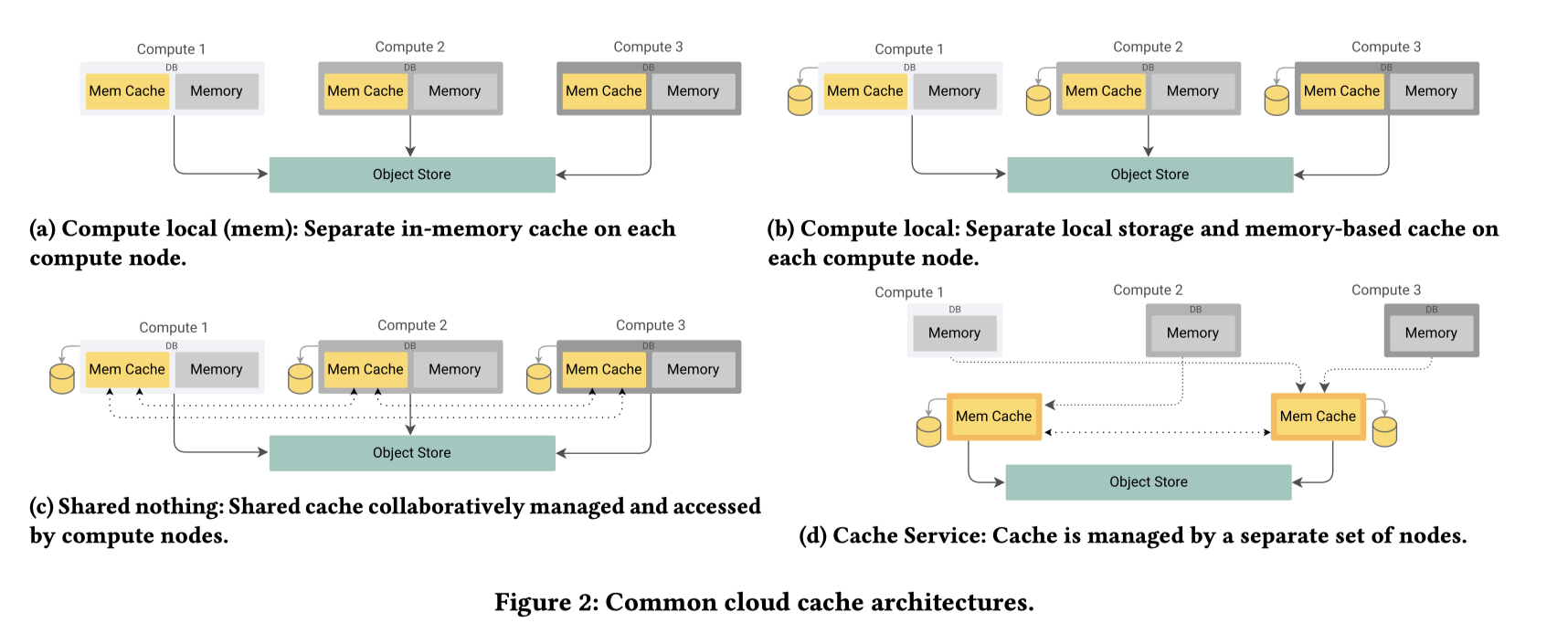
缓存架构
这章感觉在灌水,而且感觉写作质量很没 insight,不知道是不是有些人因为利益相关不好点草。这里简单抽象
- Compute local: 每个 compute node 缓存之前的对象在内存中,计算节点独立运行。上层不要求强制性的分片
- 在 (1) 的基础上用内存换个本地存储来做缓存(这里倒不提 ebs 了)。Redshift, Snowflake virtual warehouse, databricks delta cache 都是这么搞的。
- 在 (2) 的基础上,需要协调对象访问,节点之间建立一个联系,能够从别的节点拉取对象。(论文对这种架构的介绍很粗浅,我感觉这里核心问题还是一个是复杂性,第二个是给 compute node 需要分一部分资源去干这种事情。ClickHouse 好像做了类似的事情,但我个人持怀疑态度)
- 用专门的节点运行 cache service。Alluxio, Napa distributed shared cache 是这么搞的。
论文3.2 总结了一下这里 core ideas,基本在 Table2 中。我个人感觉还是看需求。

New rule
论文的核心问题是希望根据 Latency 建模,但最后我看下来感觉这个建模有点意思,但是其实是有点强行的。
How often must an application access an object to justify caching instead of directly fetching from object storage, given a latency target?
这里建立了两个等式
对应的缓存成本公式(假设程序化您托管在分离的节点上)为:
- 这里是 ( 存储成本 + 实例成本) x 缓存大小 x 缓存的生命周期(小时)+ 缓存未命中的成本

如果和请求程序在同一节点(感觉这里论证不太严谨,pod 也有资源开销?),这里应该减少 Instance 成本项
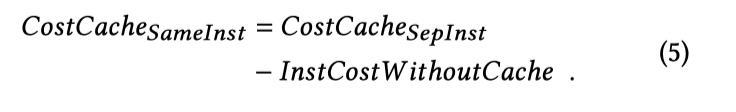
不缓存的成本如下( 𝑅𝑒𝑝𝑒𝑎𝑡𝑠𝑇𝑜𝐺𝑢𝑎𝑟𝑎𝑛𝑡𝑒𝑒𝐿𝑎𝑡𝑒𝑛𝑐𝑦 来自于 Hedged read,即为了保证延迟多读的成本,7 描述了它的开销,n 是平均的读取次数,这个次数来自越界的概率 P,可以算出重复的次数):
评估
因为大人的原因(怀疑是不想算云厂商成本,交给用户了),这里并没有给出5minutes 之类的 break even interval。下面是对应的开销。
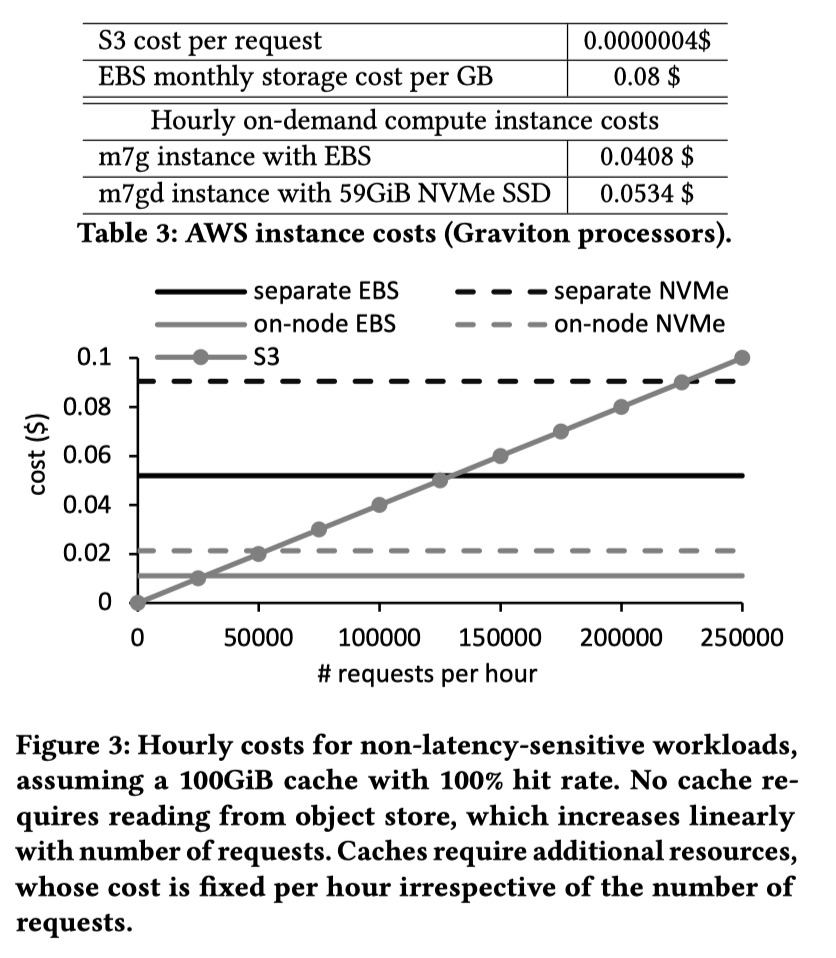
非延迟敏感
非延迟敏感型,这里比较的是成本。这里图比较直观,看 Figure3 就行。结论大概模糊的是,如果每秒没有7次读取,那么缓存会比直接访问更加昂贵。批处理其实应该走 Object store。
延迟敏感型
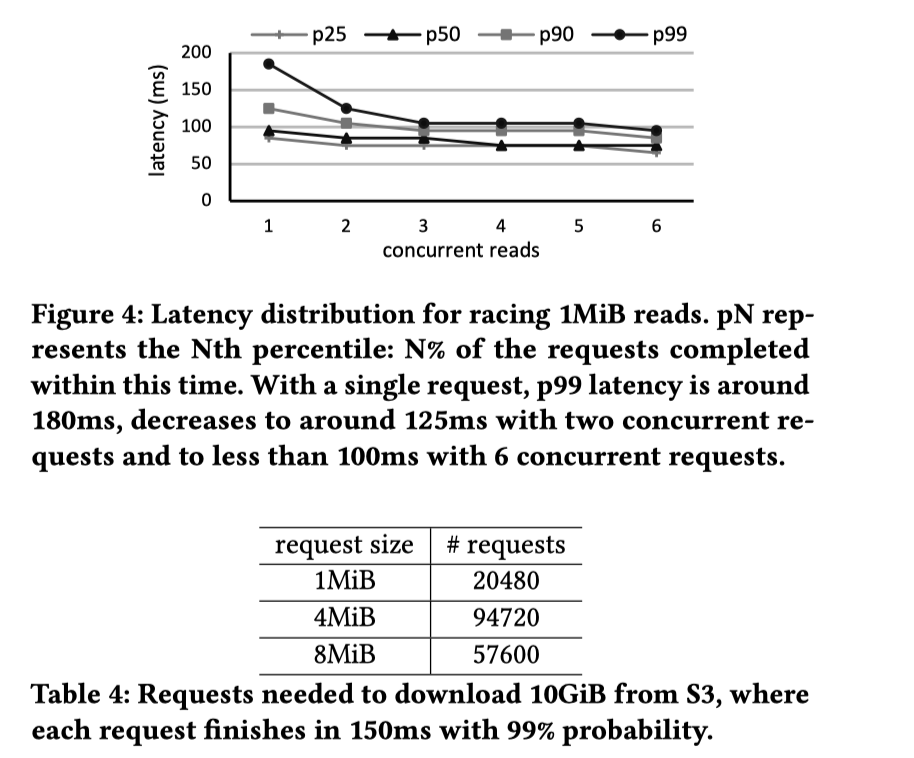
延迟敏感型中,论文核心要点是备份读。考虑延迟 + 备份读,效果如 Table4,作者认为要保证 150ms 的延迟情况下,因为备份读,1M 左右的请求大小反而更好,这种情况下,数据每小时被访问 2-4 次,都是有「成本优势」的。
Reference
- 阿里云EBS架构演进 - 黄岩gg的文章 - 知乎 https://zhuanlan.zhihu.com/p/684333453
- CloudJump II: Optimizing Cloud Databases for Shared Storage
- Spanner 系 share nothing 架构和Aurora系共享存储架构哪种在将来的竞争中更有优势 https://www.zhihu.com/question/547714000
- https://www.seagate.com/www-content/datasheets/pdfs/exos-x16-DS2011-1-1904US-en_US.pdf
- https://documents.westerndigital.com/content/dam/doc-library/en_us/assets/public/western-digital/product/data-center-drives/ultrastar-dc-hc500-series/data-sheet-ultrastar-dc-hc580.pdf
- https://tauruseu.com/seagate-enterprise-drives/
- https://aws.amazon.com/cn/about-aws/whats-new/2024/08/amazon-s3-conditional-writes/
- https://aws.amazon.com/cn/s3/consistency/
- https://aws.amazon.com/about-aws/whats-new/2024/12/amazon-s3-tables-apache-iceberg-tables-analytics-workloads/
- https://aws.amazon.com/cn/blogs/aws/introducing-amazon-s3-vectors-first-cloud-storage-with-native-vector-support-at-scale/
- https://cloud.google.com/blog/products/storage-data-transfer/how-colossus-optimizes-data-placement-for-performance
- https://www.usenix.org/system/files/atc23-zhao.pdf
- The 5 Minute Rule for Trading Memory for Disc Accesses and the 5 Byte Rule for Trading Memory for CPU Time. Gray, Putzolu, 1986
- The Five-Minute Rule Ten Years Later, and Other Computer Storage Rules of Thumb. Gray, GoetzG, 1997
- The Five-Minute Rule 20 Years Later (and How Flash Memory Changes the Rules), Goetz Graefe, 2009
- The Five-Minute Rule 30 Years Later and Its Impact on the Storage Hierarchy, Raja Appuswamy, Goetz Graefe, Renata Borovica-Gajic, Anastasia Ailamaki, 2019
- The Five-Minute Rule for the Cloud: Caching in Analytics Systems