Architecture and Design of the Linux Storage Stack: Block Layer
Introduction
上一篇介绍了 VFS 层和 Ext4 文件系统,用户层很多「目录/fsync/文件操作/Page Cache/…」在前面一层都可以通过之前一节的概念来理解。这节的内容相对来说相比之前的用户层,更贴近对硬件层调度的理解:
- 对上层提供多个块设备的抽象,是 FS <-> 驱动设备、存储设备之间的接口
- 提供多种抽象:
bio表示 fs 发出的块层请求,mapping layer 在块层之上做物理块设备和逻辑设备之间的映射
总的来说,块层离用户层其实是比较远的,它提供的是 vfs 到块设备(具体 io)的抽象映射,方便做这些 io。实际上大部分用户知道有个块设备抽象的话就行了,但是如果在意性能的话,又会离不开对这一层有一定的了解。近些年来,设备从慢速的 HDD 演化到 SSD,块层也要针对 SSD (和 NVMe SSD 的性能)去做很多优化。
内核在 Block Layer 之上还支持一个 Mapping Layer,在上层做了一层逻辑设备 <-> 物理设备的映射,其实这块也有做 LVM 或者备份啊各种管理的。
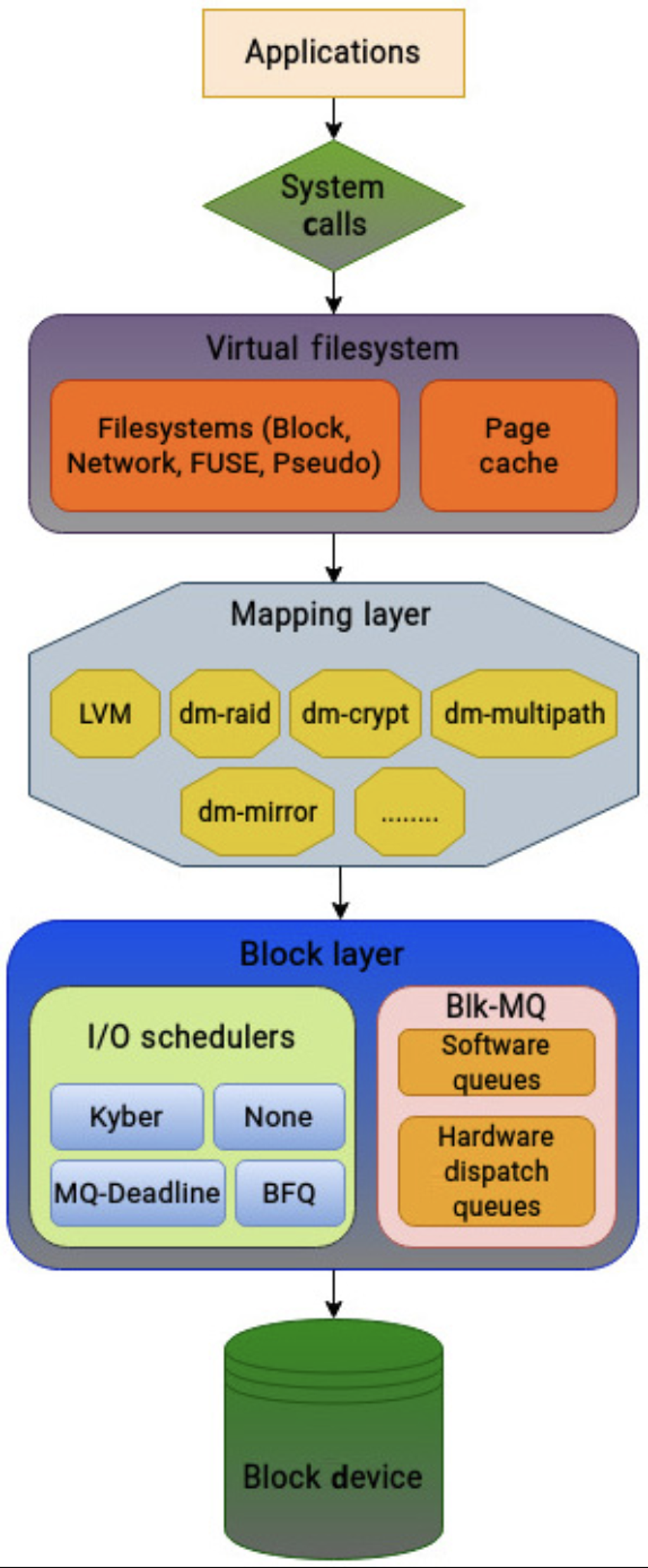
这里介绍一下 Block layer 主要的组成部分:
- Block layer 提供块的映射接口
- Fs 会创建
bio来表示 IO 请求,然后发送给块层。bio负责把 IO 请求传送给驱动,Mapping Layer 负责物理块设备映射和逻辑设备之间的映射。- 设备映射器为内核中的一些技术奠定了基础,包括卷管理、多路径、精简配置、加密和软件 RAID。其中最为人所知的是逻辑卷管理(LVM)。设备映射器将每个逻辑卷创建为映射设备。LVM 为存储管理员提供了很大的灵活性,并简化了存储管理。
- 块层有
blk-mq之类的框架,隔离了每个物理 CPU 的 io 请求,上层的 IO 请求会被 dispatch 给不同的 io 队列 - 块层有着可插拔的调度程序,可以选择对应的调度器。
- 块层也做了收集 IO Stats 的功能,来收集 IO 的状况
与块设备对应的有字符设备( character device ),上游的抽象是一个顺序的数据流,程序可以通过一次一个字符的方式来处理输入输出。键盘和基于文本的 console 大概都是这么处理的。对应的是块设备,内核以固定大小的 Block 访问,允许 Random Access,它 io 的基本单元是 sector,是在下层定义的 io 块大小,和物理设备可能挂钩。当然,Linux 或者说系统抽象也不只有这两种设备,除此之外我们还有 “network device” ( 比如物理网卡(如 eth0、ens33)、虚拟网卡(如 docker0、veth*), “bitmap display”
通常,块设备支持 Buffering I/O 和请求队列,读写都会某种形式进行 Buffering。系统中的块设备出现在 /dev 目录下:
| 类别 | 示例 | 说明 |
|---|---|---|
| 终端设备 | tty*, ttys*, ptmx, pty* |
用户输入输出、终端会话 |
| 磁盘设备(物理机) | sda, sdb, …(SCSI/SATA 磁盘)hda, hdb, …(老式 IDE 磁盘) |
物理机中的磁盘设备命名规则: - sda/sdb:SCSI 或 SATA 磁盘- hda/hdb:老式 IDE 磁盘 |
| 磁盘设备(虚拟化环境) | vda, vdb, … |
虚拟化环境中的虚拟磁盘 |
| 磁盘设备(NVMe 协议) | nvme0n1, nvme0n1p1, … |
NVMe SSD 设备: - nvme0:第一个 NVMe 控制器- nvme0n1:第一个控制器的第一个命名空间(整个 SSD)- nvme0n1p1:第一个命名空间的第一个分区 |
| 随机数与特殊设备 | random, urandom, zero, null |
生成随机数、空设备等 |
| 网络与数据包处理 | bpf* |
网络数据包捕获 |
| 系统调试与性能分析 | dtrace, fbt, lockstat |
系统跟踪与性能分析 |
| 其他功能设备 | autofs*, cu.*, auditpipe |
自动挂载、串口通信、审计等 |
| 虚拟控制台设备 | vcs*, vcsa* |
虚拟控制台的屏幕内容(二进制和 ASCII 格式) |
| 虚拟化相关设备 | vda, vdb, … |
虚拟化环境中的虚拟磁盘 |
比如在虚拟环境中,可能有下面这样的盘:
1 | ~ lsblk |
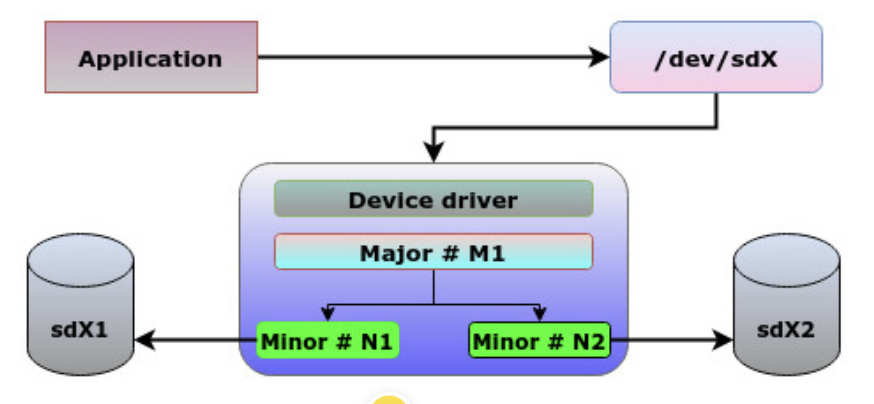
在设备文件中,这里有一点是 major 和 minor 的 device id。下面 Device type 这里 253, 1 就是 major 和 minor 的 device id。
(细心的你可以注意,这里对外 sector size 是 512B,虚拟化的设备可能为了兼容性会配置成 512B,然后在虚拟化层,即 qemu/hw/block/virtio-blk.c 上合并。实际上 io 可以在多层过程中合并,大家碰到一点合并一点)
1 | ➜ ~ ls -l /dev/vda1 |
这里设备号(的逻辑概念)如下:
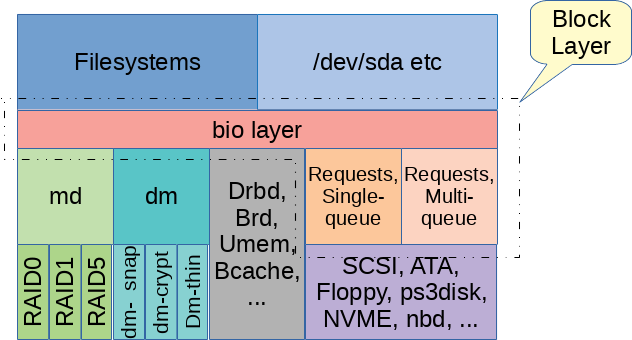
Data Structures
Block 层的主要定义如下。按照 LWN 帖子的说法,对「块层」包含哪些内容观点不一,但最简单说法是这里包含 Block Layer ( bio 相关 ) 和 Request Layer ( request, request-queue 相关 ):
register_blkdev- 注册块设备的函数。定义在 https://github.com/torvalds/linux/blob/master/include/linux/blkdev.h#L905-L909
- 注册一个 major device id
- 创建
block_device,绑定驱动设备名称、各种驱动操作
block_device- 描述块设备的结构体,定义在 https://github.com/torvalds/linux/blob/master/include/linux/blk_types.h#L41
- 块设备可以是整个磁盘或单个分区,block_device 结构可以代表其中任何一种。块设备有个虚拟的
inode* bd_inode,存在bdev的虚拟文件系统。 block_device结构体还提供了关于设备的信息,例如其名称、大小和块大小。它还包含了一个指向表示磁盘的gendisk结构体的指针bd_disk,以及一个用于处理 I/O 请求的 request_queuesstruct request_queue * bd_queue。- 块设备本身可以做分区,把这里硬件划分成多个子成分,这里
block_device能表示设备也能表示分区。
gendisk- General disk 的抽象,定义在:https://github.com/torvalds/linux/blob/master/include/linux/blkdev.h#L142
- 绑定了磁盘名称、device id 范围(包括 major id 和 minor 的范围),disk 允许的私有信息。此外这里还绑定了设备的 I/O 的
struct request_queue *queue - 当 gendisk 具有分区表时,可以与多个 block_device 结构关联。将有一个 block_device 表示整个 gendisk,可能还有一些表示 gendisk 内分区的其他结构。
buffer_head- Linux IO 的 Block 层 Buffer ( 类似数据库读到内存 Page 用 Buffer,这里看来 Buffer 无处不在)。块设备会频繁使用 Page Cache ( VFS 那层也介绍那个)
- 见博客 [5],
bio在 Linux 2.6 和之后,bio代替buffer_head描述内核中的 IO
bio- bio 是内核块层基本 IO 单元。定义在:https://github.com/torvalds/linux/blob/master/include/linux/blk_types.h#L214
- 携带读写请求和各种其他控制请求的数据结构,它从
block_device经过gendisk,并传递到驱动程序。 bio关联了bi_next,以链的形式管理,同时有一个bio_vec函数,用于处理vread这样的请求,处理 gather-scatter io。创建bio后,它可以被submit_bio/generic_make_request提交
bio_vec: 处理 gather scatter IO: https://github.com/torvalds/linux/blob/master/include/linux/bvec.hrequest: 对于bio而言,它们会被包装成request,来表示最终将传递给底层设备的单个 I/O 请求,这里 IO 必须是连续的。request是块层对一个或多个bio进行 聚合、调度和管理 的结构,它是 I/O 调度器和设备驱动程序交互的主要单位。它包含了更多的调度和驱动程序所需的信息,例如请求的优先级、提交时间等。request_queue:和块设备对应的请求队列,这里有我们后面讲的 multi-queue,io 调度,合并之类的逻辑
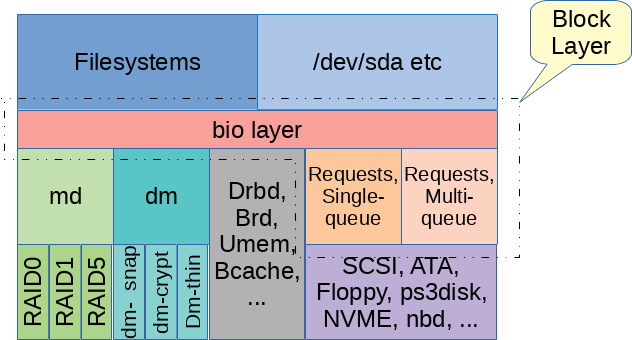
Requests, mq
这里会有单队列和多队列的概念,现东家最近小半年刚从内核 3.x 升级到了内核 5.x,其实可以看到,这些年因为 SSD, NVMe 这样的设备,IO 调度器也发生了一些改变,不过遗憾的是,我们用块存储的用户很多时候还是略显性能跟不上的,比如本地 NVMe 盘已经快如闪电了,但实际上,云盘吞吐不一定比得上对象存储(当然,这也取决于你花了多少钱,不过显而易见的,我这里讲的问题是可能「现代」的云上硬件并没有那么快 XD)。这里具体可以参考:https://help.aliyun.com/zh/ecs/user-guide/elastic-block-storage-devices 。以阿里云 ESSD 产品作为例子:
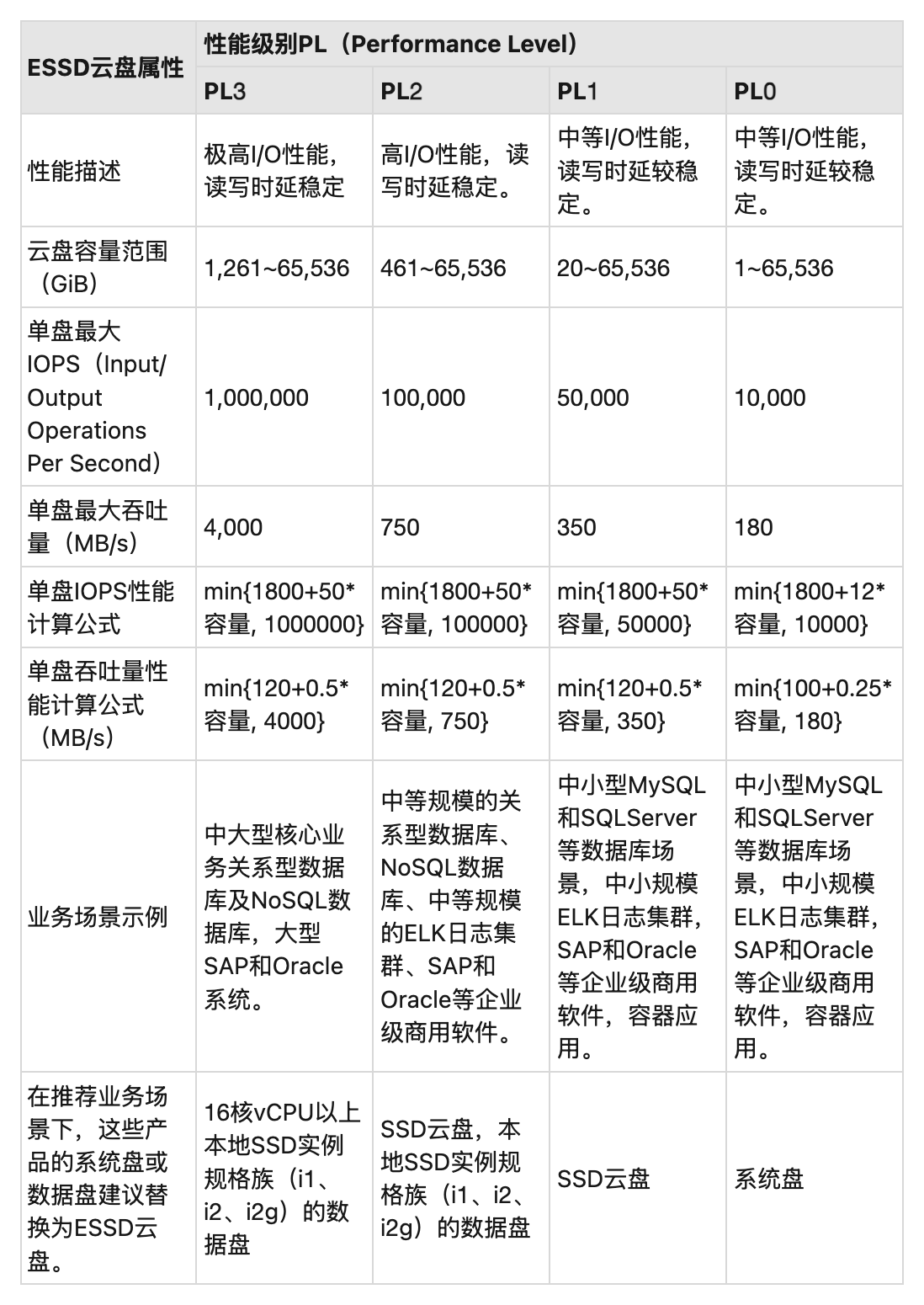
本地盘实际上性能会好不少,在之前链接也有本地盘性能的地方,我们来贴一下图占用一下宝贵的空间:
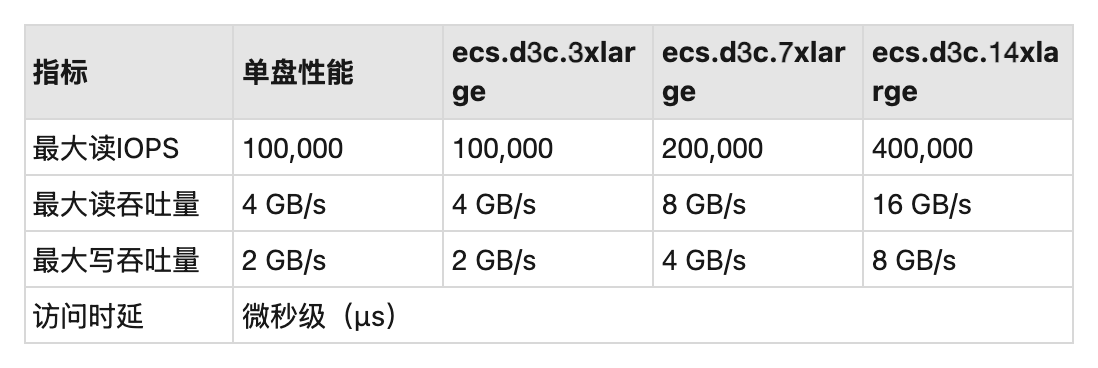
扯远了,我们回到这个话题,这里实际上在比较现代的设备中,硬件栈已经快如闪电卷到极致了。内核块层的最初设计是针对机械驱动器作为首选存储介质的时期。这些传统硬盘最多只能处理几百个 IOPS。但如今,多核 CPU 和硬件进步也改变了这一切。在新一代的系统上,软件栈成为某种程度上的 IO 的瓶颈。
在老一代的系统中,这里调度的流程大概是:
- Block Layer 的请求层维护一个 single-request queue,使用 linked-list,来处理 IO 请求,新请求插入到队列尾部,(因为 IOPS 受限、延迟高),block layer 会牺牲一部分的 CPU 来尝试合并临近 io,然后把请求发送给 Driver
- 有的时候希望 bypass request queue,来直接把请求发送给 driver
这里有几个对应问题:
- 多核 issue 请求的时候数据争用问题,这里会有个多核发送的时候,同时写一个 linkedlist,大家都是抢占状态
- 多核 issue 请求时候的缓存问题,L1 L2 的 false sharing 之类的
- 中断数量的增加
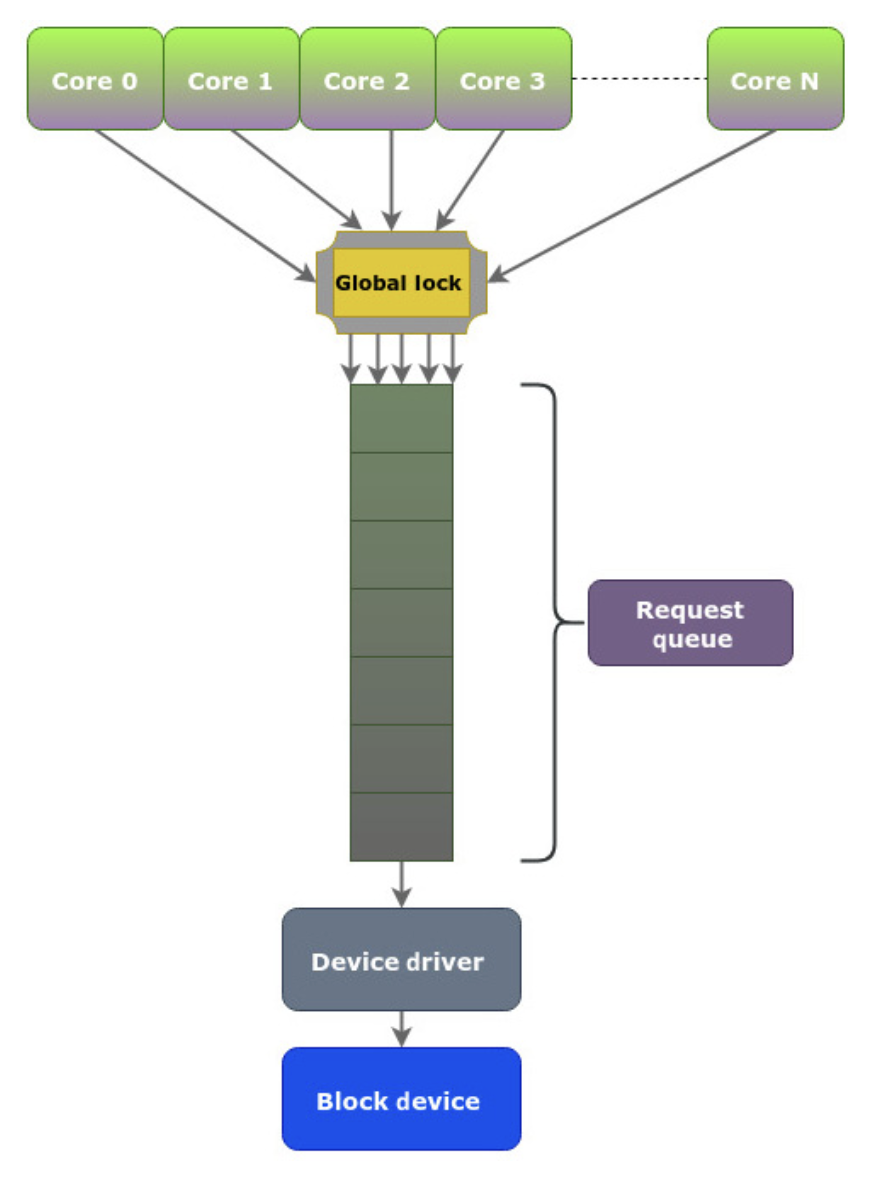
因为上述的几个原因,这里会导致性能不佳。因此这里
在 Linux 中,存储层次结构的组织方式在某种程度上与 Linux 网络堆栈有些相似。它们都是多层的,并且严格定义了堆栈中每一层的角色。涉及设备驱动程序和物理接口,这决定了整体性能。与块层的行为类似,当一个网络数据包准备传输时,它被放置在一个单一的队列中。这种方法使用了多年,直到网络硬件发展到支持多个队列。因此,对于具有多个队列的设备,这种方法已经过时了。
这个问题与内核中的块层后来面临的问题非常相似。Linux 内核中的网络栈比存储栈更早地解决了这个问题。因此,内核的存储栈从中汲取灵感,这导致为 Linux 块层创建了一个新的框架,称为多队列块 I/O 排队机制,简称为 blk-mq。
这里新设计下内容如下。在 LWN 的帖子 [4] 里面,17年的时候这块还在过渡的状态,但恐怕现在应该还挺管用的。我们这里可以看到,这里分成「软件的多队列」和「硬件的多队列」:
- 一般来说,硬件会带有 CPU Nums 的
bio提交队列,提交到硬件队列中。这里 Scheduler 会调度一些软件中的队列的请求 - 当 I/O 请求到达块层且块设备没有关联的 I/O 调度程序时,blk-mq 将直接将请求发送到硬件队列。硬件队列是设备驱动程序用来与设备的提交队列(Submission Queue,通常是设备内存中的 DMA 环形缓冲区)进行映射的结构。这些队列中的请求会直接发送给设备进行处理。现代高性能存储设备(如 NVMe SSD)可以支持多个 I/O 通道,即拥有多个硬件提交队列。blk-mq 允许设备驱动程序向块层报告其支持的硬件队列数量和深度。一旦请求进入硬件队列,通常不再进行 I/O 调度或重新排序。这是因为硬件设备本身可能已经有高效的内部调度机制,并且在该层面进行额外的调度会增加不必要的开销。
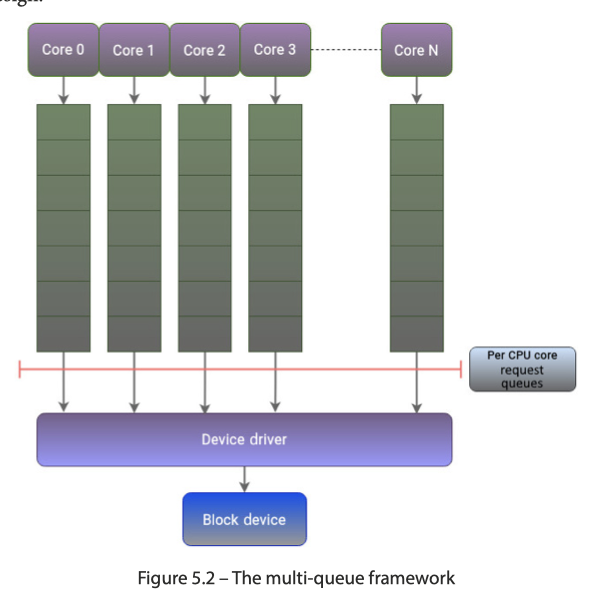
Device Mapper
内核使用 Device Mapper 将物理块设备映射到更高级别的虚拟块设备。设备映射器框架的主要目标是在物理设备之上创建一个高级抽象层。设备映射器提供了一种机制来修改传输中的 bio 结构,并将其映射到块设备。使用设备映射器框架为实施逻辑卷管理等功能奠定了基础。
设备映射器提供了一种通用的方式来在物理设备之上创建块设备的虚拟层,并实现条带、镜像、快照和多路径等功能。与 Linux 中的大多数事物一样,设备映射器框架的功能被划分为内核空间和用户空间。定义物理到逻辑的映射等策略相关的工作在用户空间中进行,而实现这些映射的策略的功能则位于内核空间。
这里实际上,Device Mapper 维护了一个 Block Layer 上层的 虚拟块设备 <—> 物理块设备的映射。Device Mapper 没有实际做这些。他只是是内核中的一个通用框架,接收 LVM 工具发送的指令,并根据这些指令创建和管理底层的 虚拟块设备。下面有 LVM 之类的一些具体的实现。
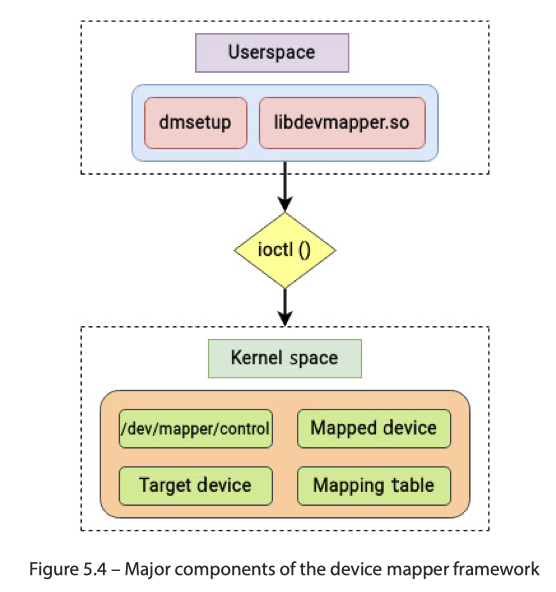
这里通常以 :
dm_table定义映射- 在
mapped_device中定义逻辑的设备,通常存在于/dev/mapper中 dm_target中,定义被映射的 target
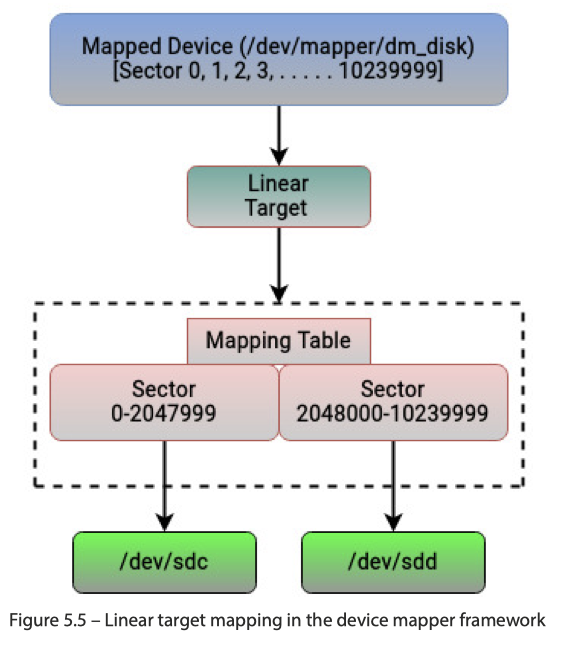
如下所示:
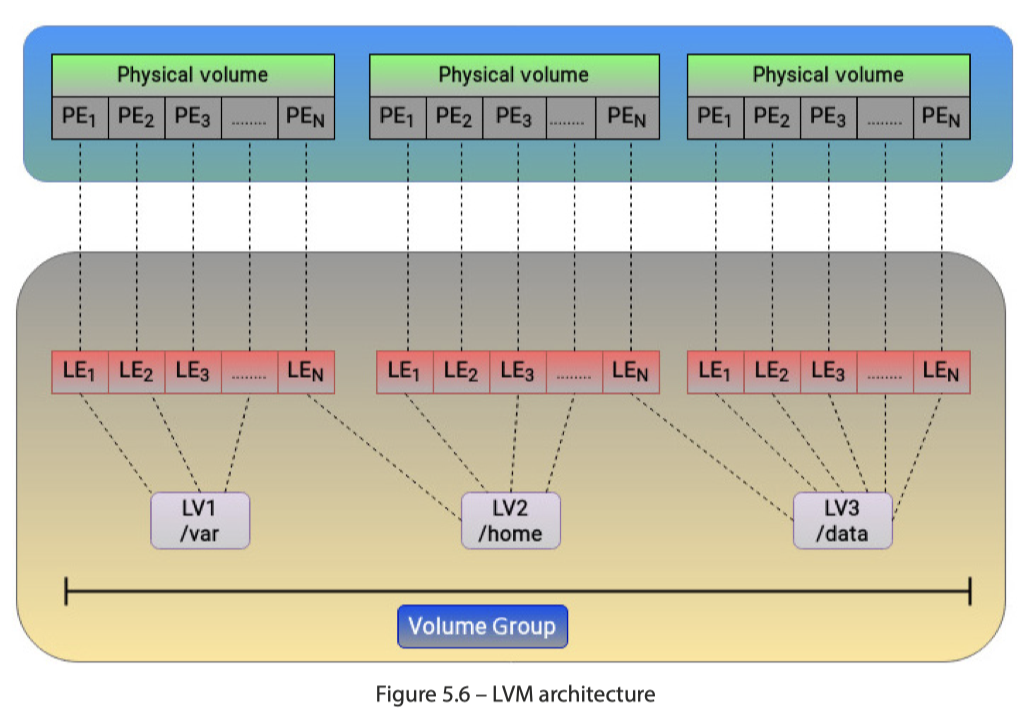
LVM (Logical Volume Manager) 是 Linux 下一个强大的磁盘管理工具,它通过将底层的物理存储抽象化,提供比传统分区方式更灵活的存储管理功能。LVM 的核心思想是将物理磁盘空间动态地分配给逻辑卷。LVM 利用 Device Mapper 实现了物理卷 (PV)、卷组 (VG) 和逻辑卷 (LV) 的概念,提供了灵活的存储空间管理,如在线扩容、缩减、快照等。LVM 是基于 Device Mapper 框架构建的。 换句话说,Device Mapper 是 LVM 的底层实现机制。这里可以看下图:
这里也画了个表格(push ai 做的)看看给我们提供的工具:
| Device Mapper Target (目标驱动) | 主要功能 (Function) | 详细描述 (Description) |
|---|---|---|
| dm-linear | 线性映射 (Linear Mapping) | 将一个或多个底层物理设备上的连续区域,线性地组合成一个更大的虚拟块设备。这是 LVM 实现逻辑卷的基础目标之一,允许简单地扩展卷。 |
| dm-striped | 条带化 (Striping) / 软件 RAID 0 | 将数据以条带(stripe)的形式均匀地分布到多个底层物理设备上。这可以提高 I/O 吞吐量,因为多个设备可以并行处理请求。同样是 LVM 的核心目标,用于创建条带化逻辑卷。 |
| dm-mirror | 镜像 (Mirroring) / 软件 RAID 1 | 将数据同时写入到两个或多个底层物理设备上,形成镜像副本,以提供数据冗余。如果其中一个设备发生故障,数据仍然可以通过其他镜像副本访问。 |
| dm-raid | 软件 RAID 阵列 (Software RAID Array) | 比 dm-linear 和 dm-striped/dm-mirror 更全面的 RAID 实现,支持 RAID 0, RAID 1, RAID 4, RAID 5, RAID 6, RAID 10 等多种 RAID 级别,并提供冗余和性能优化。它与 mdadm 在功能上有所重叠,但基于 Device Mapper 框架。 |
| dm-crypt | 块设备加密 (Block Device Encryption) | 提供透明的块设备层加密。所有写入到 Device Mapper 设备的数据都会被加密,从设备读取时则自动解密。这通常与 LUKS (Linux Unified Key Setup) 结合使用,用于保护整个分区或磁盘的数据安全。 |
| dm-multipath | 多路径 I/O (Multipath I/O) | 管理到同一存储设备的多个 I/O 路径。当服务器通过多条物理连接(如光纤通道、iSCSI)访问 SAN 存储时,它可以实现 I/O 负载均衡和路径故障切换,提高存储的可用性和性能。 |
| dm-snapshot | 写时复制快照 (Copy-on-Write Snapshot) | 创建现有逻辑卷的一个时间点视图。当原始卷或快照卷的数据被修改时,只有被修改的块才会被复制到快照存储空间,从而保存原始数据状态,用于备份、测试或恢复。 |
| dm-thin | 精简配置 (Thin Provisioning) | 允许创建比实际物理存储容量更大的虚拟卷。存储空间只有在数据真正写入时才会被分配。这可以提高存储利用率,并简化存储管理,尤其适用于虚拟化环境和云平台。 |
| dm-cache | 块级缓存 (Block-level Caching) | 将快速存储设备(如 SSD)用作慢速存储设备(如 HDD)的缓存层。常用数据块会被缓存到快速设备上,从而显著提升 I/O 性能。 |
| dm-era | 写入时代追踪 (Write Era Tracking) | 追踪块设备在不同“时代”下的写入情况。可以用于识别自上次检查后哪些数据块被修改过,对于实现高效的增量备份或数据同步非常有用。 |
| dm-verity | 数据完整性校验 (Data Integrity Verification) | 确保块设备上的数据未被篡改。它通过在设备上存储一个加密哈希树(Merkle Tree),可以在读取数据时实时验证数据的完整性,常用于 Android 等嵌入式系统的启动链和防止恶意软件篡改。 |
| dm-zero | 全零设备 (Zero Device) | 创建一个虚拟块设备,所有读取操作都返回零,所有写入操作都被丢弃。主要用于测试目的或创建临时的数据填充设备。 |
| dm-error | 错误模拟设备 (Error Simulation Device) | 创建一个虚拟块设备,它会根据配置返回 I/O 错误。主要用于测试应用程序或文件系统在面对底层存储错误时的行为和鲁棒性。 |
IO Scheduler ( blk-mq )
如果你阅读前几节细心的话,其实会看到我们这里之前讨论单队列的时候,说到有一些调度;然后讨论多队列的时候,我们会说软件队列是支持一些 io 合并的。
对于 HDD 来说,这种调度很重要,因为硬件通常是主要瓶颈,同时 IO 调度的时候,顺序 io 效率会更高一些。实际上在做 object store 访问层的时候,这里也有一些 io 调度的逻辑。这里要解决的问题有的是类似的。
这里调度会采用 Sorting, Merging, Coalescing, Plugging。
在机制上,前三个都很好理解,看下图即可:
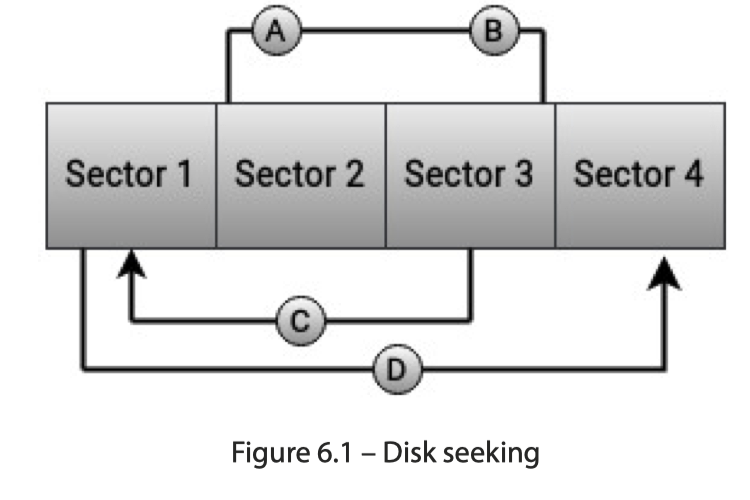
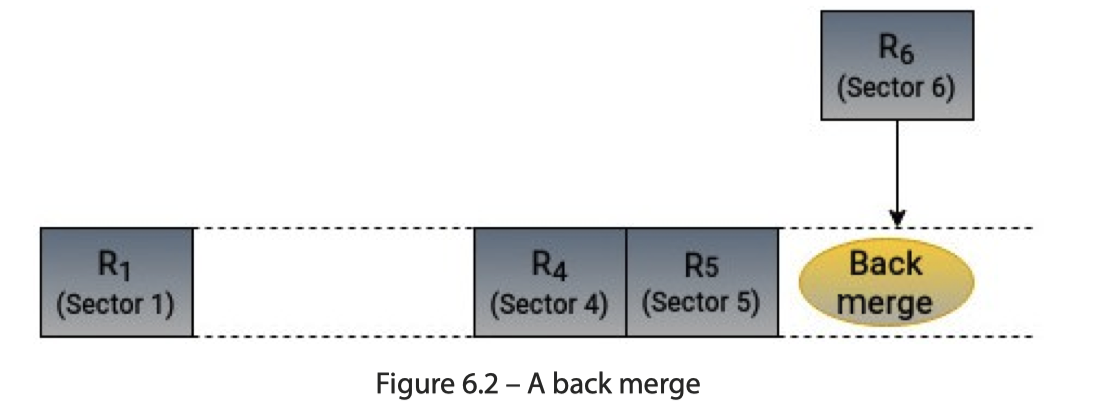
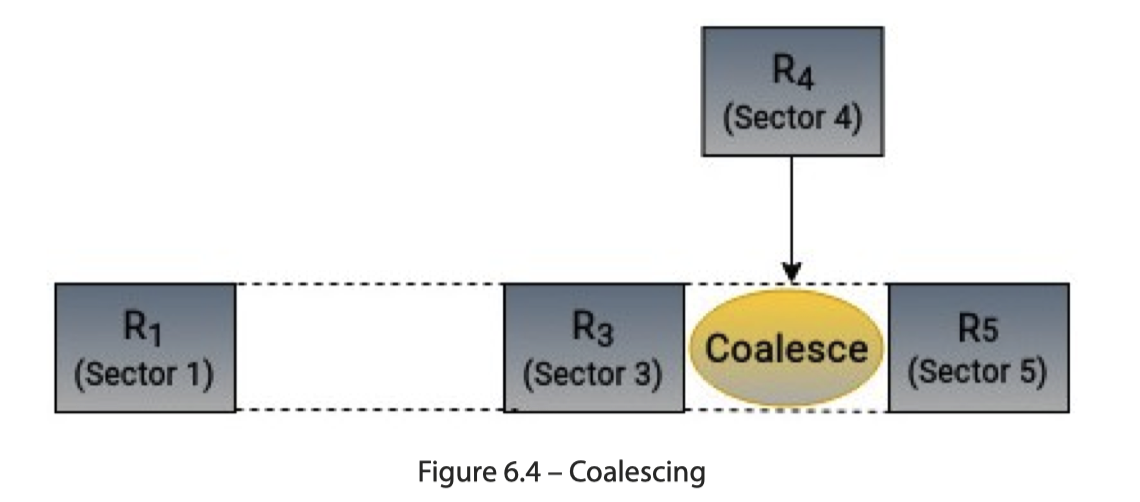
Plug 表示抽出一个等待调度的阶段,因为这里请求实际上是动态提交的(作为对比,读单个 Parquet 文件实际上做的是静态的把 io 请求 plan 出来,再做 merging。实际上我觉得静态处理复杂度会低不少)。这里抽出了一个 Plug 阶段来合并这些请求:
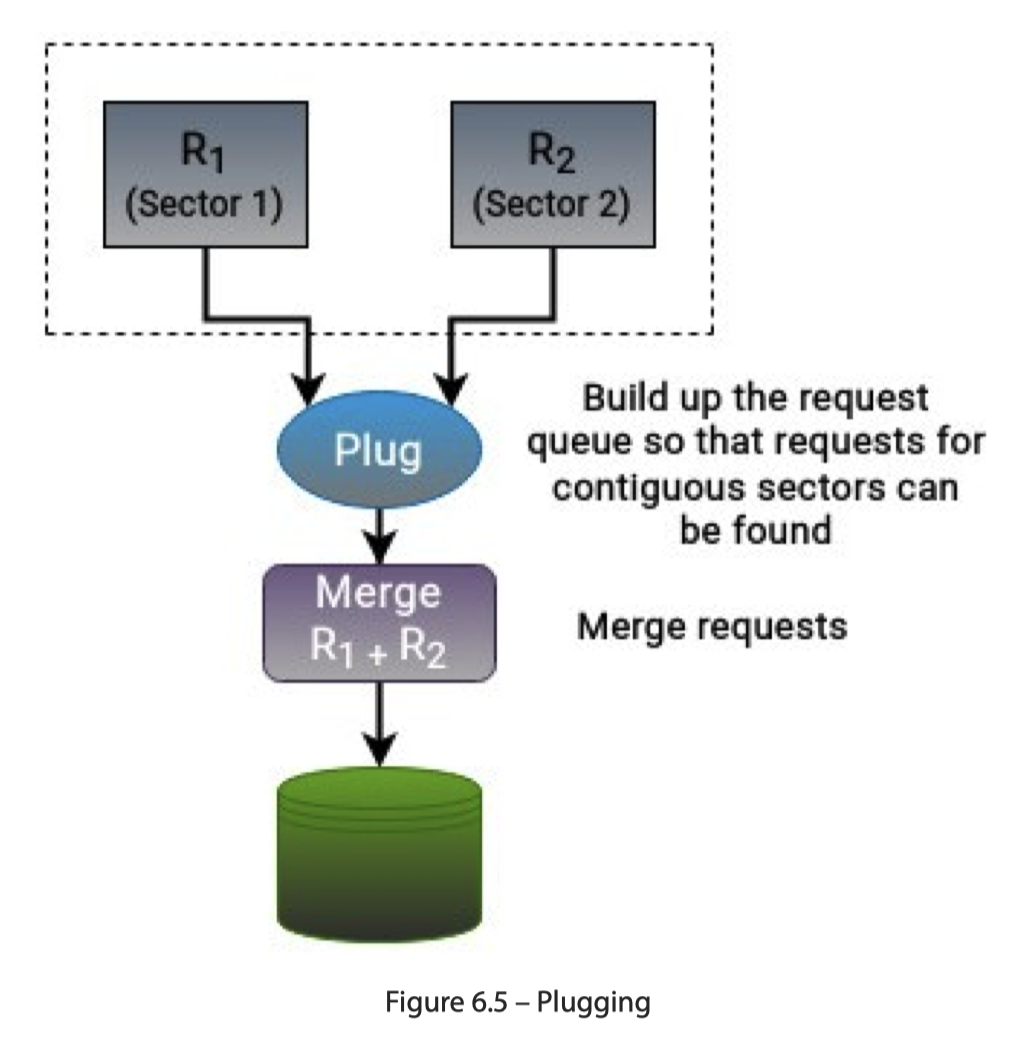
上面是这里的原理,下面是这里实际的调度器。「调度」本身实际上肯定是有调度目标的,类似 CFS 和 EEVDF 的比较 ( 见:【管中窥豹】浅谈调度器演进的思考,从 CFS 到 EEVDF 有感 - rsy56640的文章 - 知乎https://zhuanlan.zhihu.com/p/680182553 )。这里是:
- Reducing disk seeking
- Ensuring fairness among I/O requests
- Maximizing disk throughput
- Reducing latency for time-sensitive tasks
其实不同调度器处理这些上面这些需求,均衡程度也有不同。而新硬件(SSD,NVMe)也扩展了这个纬度。对于个人用户,其实感觉咋用都好,但是对于服务器来说,调整这块收益可能会比较高。而单队列调度器曾经火热,但是在 Linux 内核 5.0 中,这些东西全都没了,取而代之的是,这里只有多队列的 IO 调度。
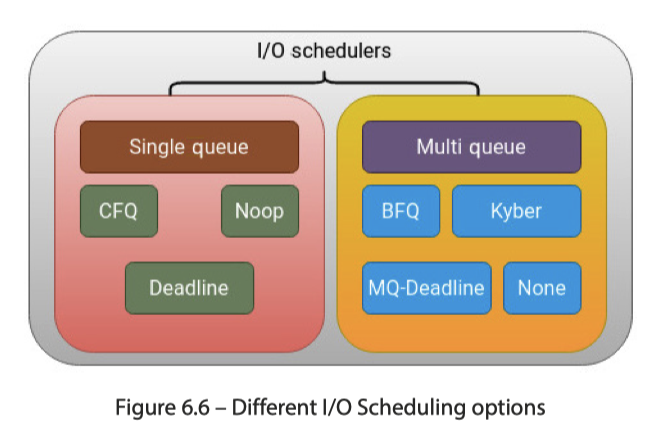
下图列出了对应的调度队列:
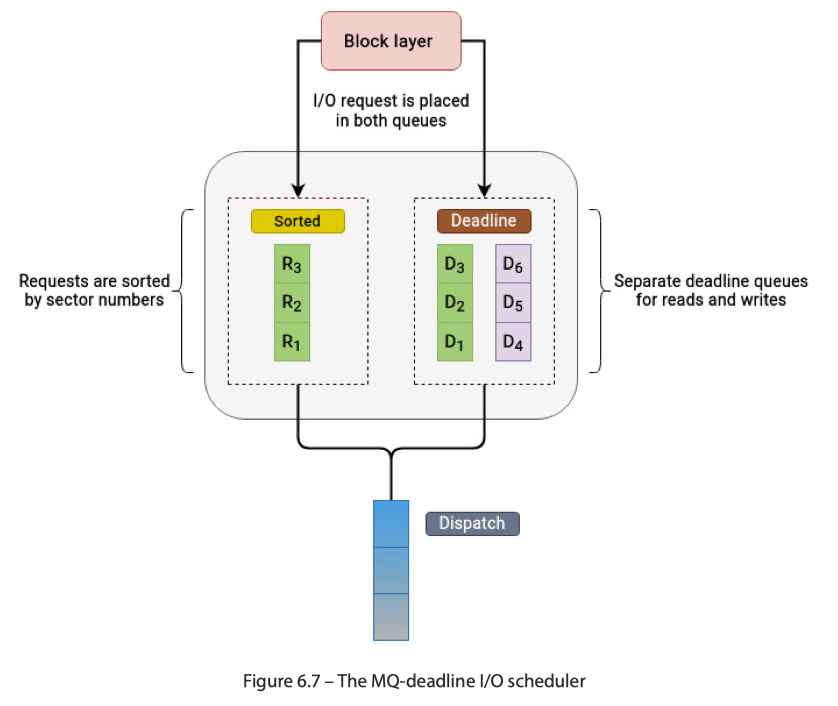
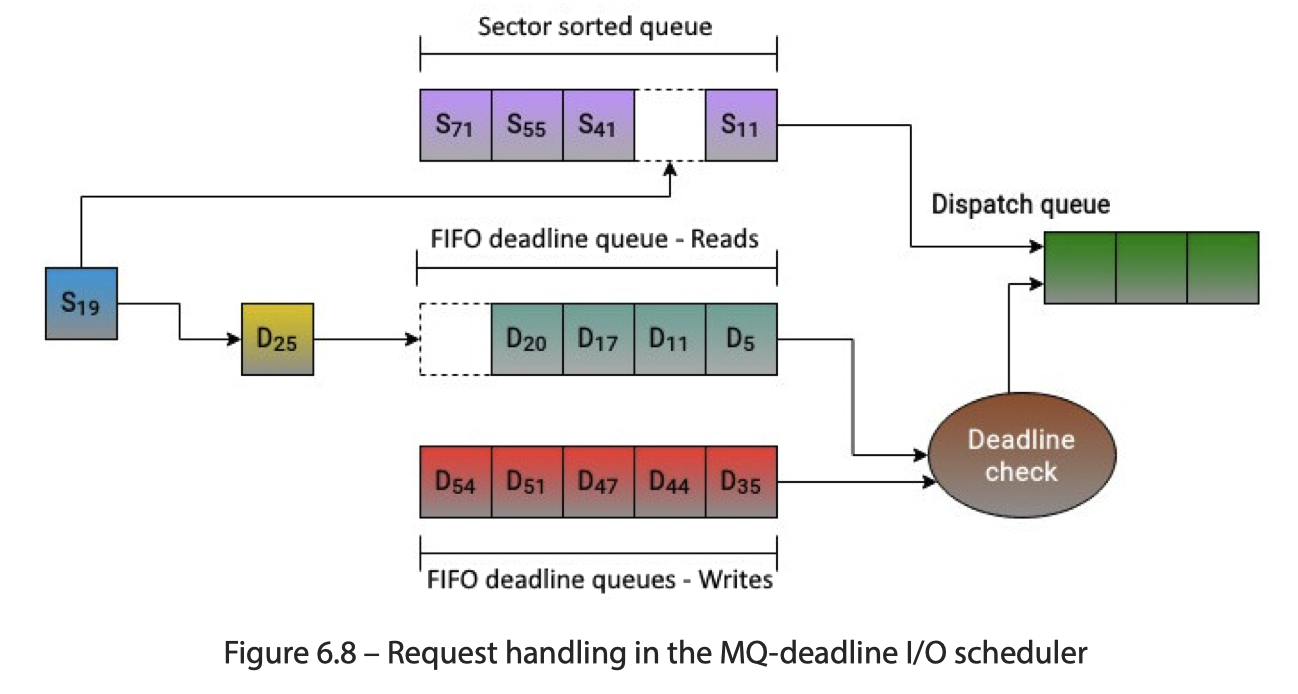
MQ-deadline: 保证一个 start service time
- latency-oriented design, often used for latency-sensitive workloads
- enforcing a deadline on all I/O operations
- 维护两个队列,然后 (1) Sorting by sector numbers (2) using the FIFO queue that contains requests sorted by their deadlines。没有 dead line 的时候,会尝试去 sector sorted queue 来读取;否则走 deadline queue 来读取
- Deadline 队列区分读写队列。读/写比例:
mq-deadline会维护一个内部状态,确保读写操作之间有一定的公平性,例如,在连续派发了一定数量的读请求后,会考虑派发一些写请求,反之亦然。这避免了写操作被读操作完全饿死。批量提交: 对于blk-mq,一旦调度器选择了一批请求,它们会被作为单个批次提交到底层硬件请求队列,以利用多队列设备的并行性。
Budget Fair Queuing (BFQ)
BFQ 类似 CFQ,对其评价是:「It provides fairly good response times and is considered particularly suitable for slower devices.」它在Linux-4.12上合入主线,主要针对的是慢速器件,如机械硬盘。这也是调度程序中更复杂的一个。这里有两种队列:
- Per-device queue for async I/O requests: 存放 async io requests
- Per-process queues for sync I/O requests: 存放进程的同步 io requests
BFQ 用 Worst-case Fair Weighted Fair Queuing+(B-WF2Q+) 算法来辅助调度。这里流程是:
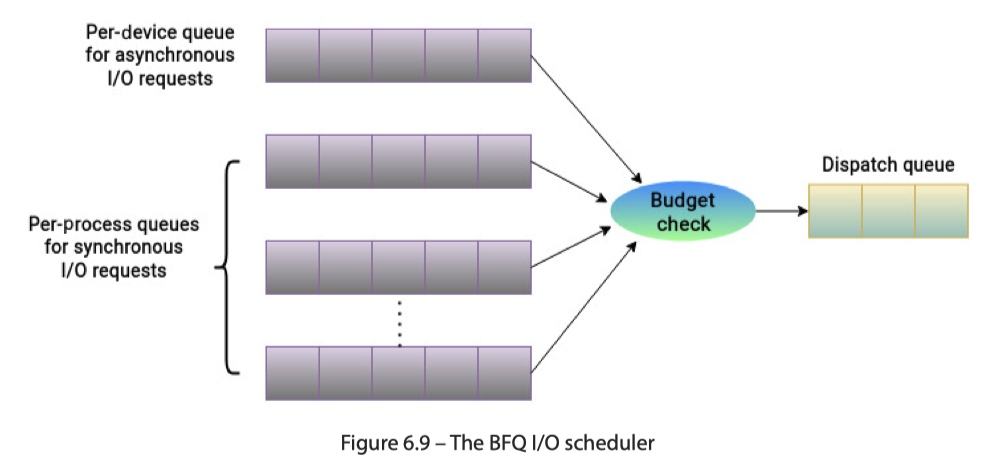
- 每个 queue 被塞入一个初始化的 Budget,这个 Budget 是可以配置的 Num of sectors
- The major factors in this calculation are the I/O weight and the recent I/O activity of the process. Based on these observations, the scheduler assigns a budget that is proportional to a process’s I/O activity. The I/O weight of a process has a default value, but it can be changed. The assignment of the budget is such that a single process is not able to hog all the bandwidth of available storage resources.
- 按照 C-LOOK 算法选择 queue,然后单独给这个 queue 服务。通常,会有不同的前台请求模式:(1) 小 + random io 请求 (2) 大量顺序 I/O 请求。后者会有更大的 Budget
- 对于上层来说,通常读是阻塞的,写入是异步的( io_uring 之类的可能还会受影响,估摸着需要调参)。
- 允许
slice_idle之类的参数,在处理完一个地方的请求的时候(或者剩下一个同步请求的时候),adaptive 的等待上游发送下来新的请求,可以尝试等待一会儿/进行 merging
这里还有一块读写的调整。如果是 async 操作,这里会增大它们对应的带宽(相当于某种性质上的读/同步优先)
1 | /* |
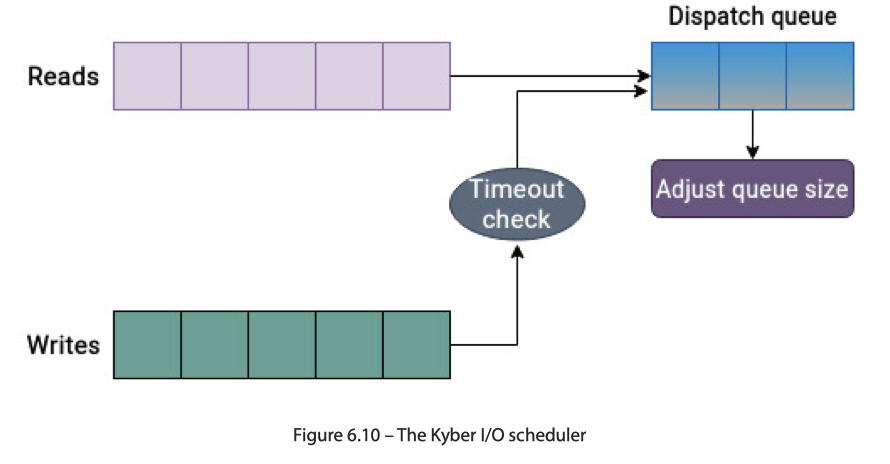
Kyber
Kyber 为 SSD/NVMe 之类的设计,为了避免过大复杂开销,它维护了 Sync 队列和 Async 操作的队列,然后调整 dispatch queue 的大小。
这里可以看这块代码:https://github.com/torvalds/linux/blob/master/block/kyber-iosched.c#L60 。可以看到,Kyber 为不同操作维护了不同的队列大小,然后根据动态调整队列 timeout 来做到尽量达到用户的目标延迟。
None
none (或在某些旧版本内核中称为 noop,即 “no operation”) 调度器是 Linux I/O 调度器家族中最简单的一个。它的核心理念就是 不做任何调度,直接将 I/O 请求传递给块设备驱动程序。
在高端存储环境中,比如智能 SAN (Storage Area Network) 存储系统,存储通常都包含自己的调度逻辑,因为它们对底层设备的细微差异有更深入的了解。因此,I/O 请求的调度通常发生在较低的层次。在使用 raid 控制器时,主机系统没有有关底层磁盘的完整知识。即使调度程序对 I/O 请求应用了某些优化,也可能没有太大差异,因为主机系统缺乏准确重排请求以降低寻道时间的可见性。在这种情况下,直接将请求发送到 raid 控制器是合理的。
大多数调度器优化都是针对缓慢的机械硬盘而进行的。如果环境由固态硬盘和 NVMe 驱动器组成,这些调度优化所带来的处理开销可能会显得过度。
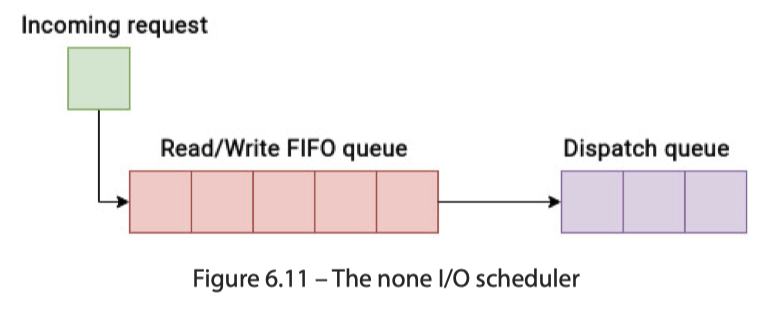
这里能够查看对应的 io 调度器:
1 | cat /sys/block/sda/queue/scheduler |
下面有一张简单的表,简而言之,对于一些现代一些的应用,应该以快为主,本身 NVMe 之类的设置 None 之类的就行了,但是云上一些东西又给一些老的技术赋予了新的空间。我们可以利用类似的技术来实现类似的调度,这些 Scheduler 就是一个很好的参考。
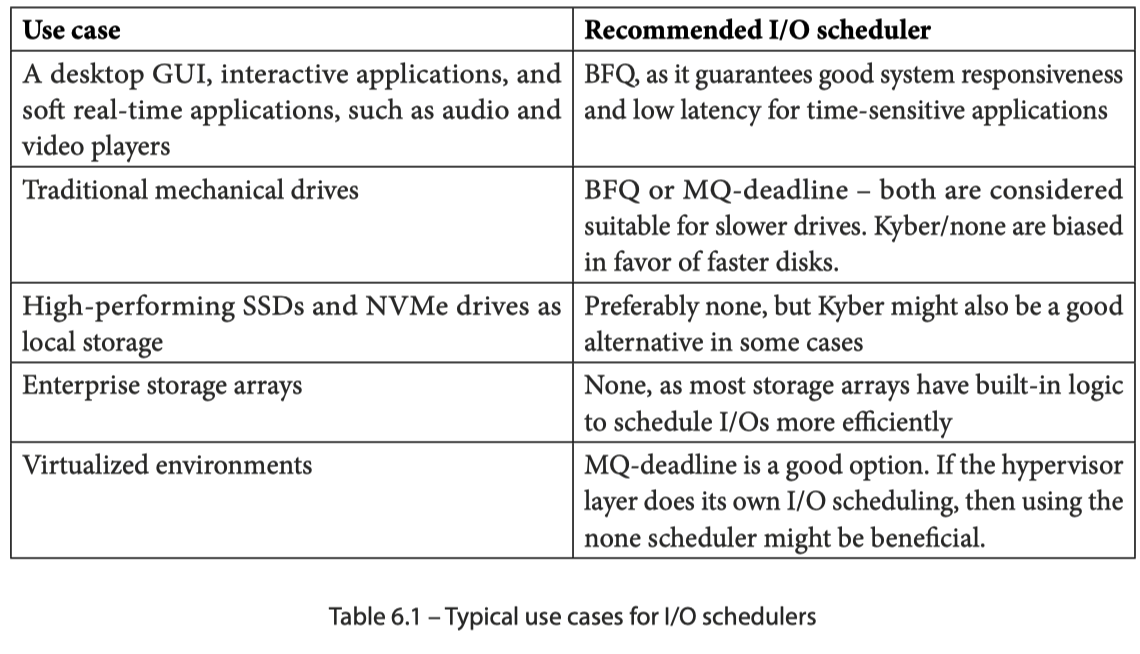
Please note that these are not strict use cases, as often, several conditions might be overlapping. The type of application, workload, host system, and storage media are just some of the factors that must be kept in mind before deciding on a scheduler. Typically, the deadline scheduler is regarded as a versatile choice, due to its modest CPU overhead. BFQ performs well in desktop environments, whereas none and Kyber are better suited for high-end storage devices.
还有一篇(不一定可信,笔者不是特别了解这个领域)论文,比较了 NVMe 时代的 scheduler:BFQ, Multiqueue-Deadline, or Kyber? Performance Characterization of Linux Storage Schedulers in the NVMe Era
Reference
- virtio 虚拟化系列之一:从 virtio 论文开始 - smartx的文章 - 知乎 https://zhuanlan.zhihu.com/p/68154666
- https://unix.stackexchange.com/questions/520231/what-are-nvme-namespaces-how-do-they-work
- A block layer introduction part 1: the bio layer https://lwn.net/Articles/736534/
- Block layer introduction part 2: the request layer https://lwn.net/Articles/738449/
- [转载] Linux内核Page Cache和Buffer Cache关系及演化历史 - Zero的文章 https://zhuanlan.zhihu.com/p/429548733 。这篇介绍了一下
buffer_head和 Page Cache - page到folio的变迁 - PilgrimTao的文章 - https://zhuanlan.zhihu.com/p/1902473318315058208
- 阿里云云盘块存储性能:https://help.aliyun.com/zh/ecs/user-guide/block-storage-performance