Architecture and Design of the Linux Storage Stack: VFS
近年来,随着存储设备的发展,bypass kernel 逐渐成为 NVMe 版本的答案之一。其中很大一部分原因在于:
- 内核本身非常复杂,很多东西演化许久,已经成为「屎山」
- Syscall, Data Copies, Interrupt handling 之类的处理本身有一定开销
- 内核 io 软件栈其实很长,有非常多的层次,可以绕过这些层次
- 用户可以管理 NVMe 队列、提交命令、处理完成事件,实现更好的调度
俨然内核仿佛已经成为一个恶霸,拦在系统优化师面前。但真的如此吗,我们都知道工程也有「性能/通用性/可读性(复杂性)」不可能三角,一个是对于普通企业用户、中小型应用或没有专门存储研发团队的用户来说,完全绕过内核(如使用 SPDK 重写应用 I/O 部分)通常是不现实的,因为开发和维护成本太高,且可能牺牲了内核提供的稳定性和易用性。二个是遇到问题通常不好查。
另一种是内核 fs 配置得更适合 NVMe,比如使用 noop 的 I/O 调度器,使用 io_uring 和 O_DIRECT 来批量处理,减少一些处理的开销。我个人感觉,这套接口将长期存在,同时,内核尽管是个屎山,但是工程上感觉几年之内代码还是会走内核,然后 io_uring 这套接口和配套的东西潜力会被尽量挖掘。同时,内核又提供了很多观测工具,虽然是「屎山」,但是绕过它也基本相当于观测工具都要重新写一遍,如果有团队维护的话,感觉还可以;不然感觉又是个大牢。
说了很多个人不靠谱观点,毕竟笔者真没做过 OS,以上发言都是不负责任嘴炮。其实就是怀抱这样的想法,翻了翻 Architecture and Design of the Linux Storage Stack 这本书。这里会把内核 I/O Stack 分为了 VFS、块层、物理层。本篇介绍的是 VFS 层和 FS 层,这个话题很大,所以本篇感觉只是粗略掠过。
VFS 和 VFS 中的数据结构
x86 提供了 0-3 的 ring,用来(在指令层面)区分用户态,内核态。同时对于用户态的 api,我们可以看到下面的图,一个是 Linux 层次的 I/O Buffering
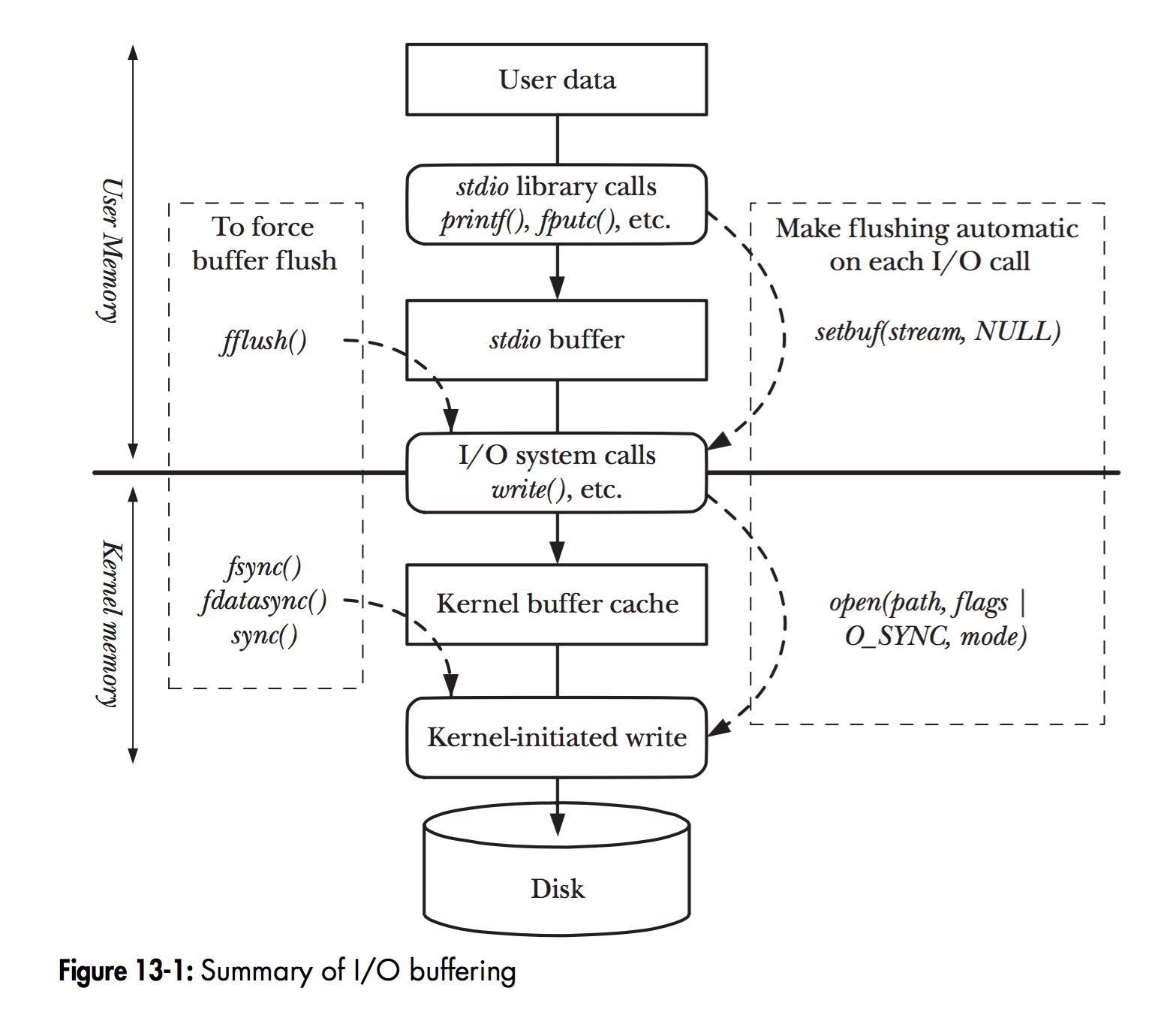
另一张图表示 VFS 在这里的位置
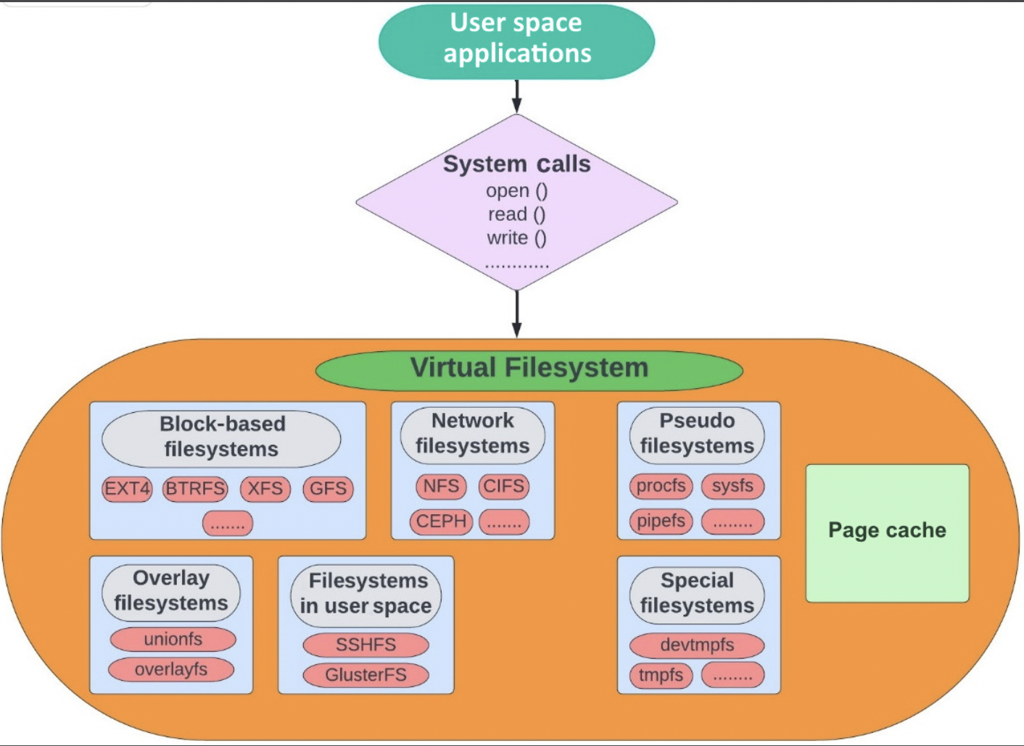
我们可以看到,VFS 层有很多 “underlying filesystem”:
- Block-based filesystem: 用户最主要接触的 fs,比如 Ext 2/3/4 或者 XFS、Btrfs、FAT、NTFS。这些文件系统以 Block 形式工作,在创建文件系统的时候设置 block size。可以按块访问的设备被称为块设备。它是单机的。
- Clustered filesystems: 这气势也是一种 block-based filesystem,对上层提供 block 的抽象,但是这里允许 fs 被多台主机挂载使用。
- Network filesystems (NFS): 允许远程文件共享数据的协议,有 client / server,通过网络来链接
- Pseudo filesystems: 在内核中,动态生成内容,包含一些虚拟/临时的文件,例如
/proc和/sys。
如上图,用户通过 syscall 来访问文件,第一层交互的便是 VFS。上图会给人感觉 Block-based filesystem 之类的是 vfs 的一部分,实际上这里的逻辑如下图,VFS 也不是文件系统。它实际位于内核中实际文件系统之上。
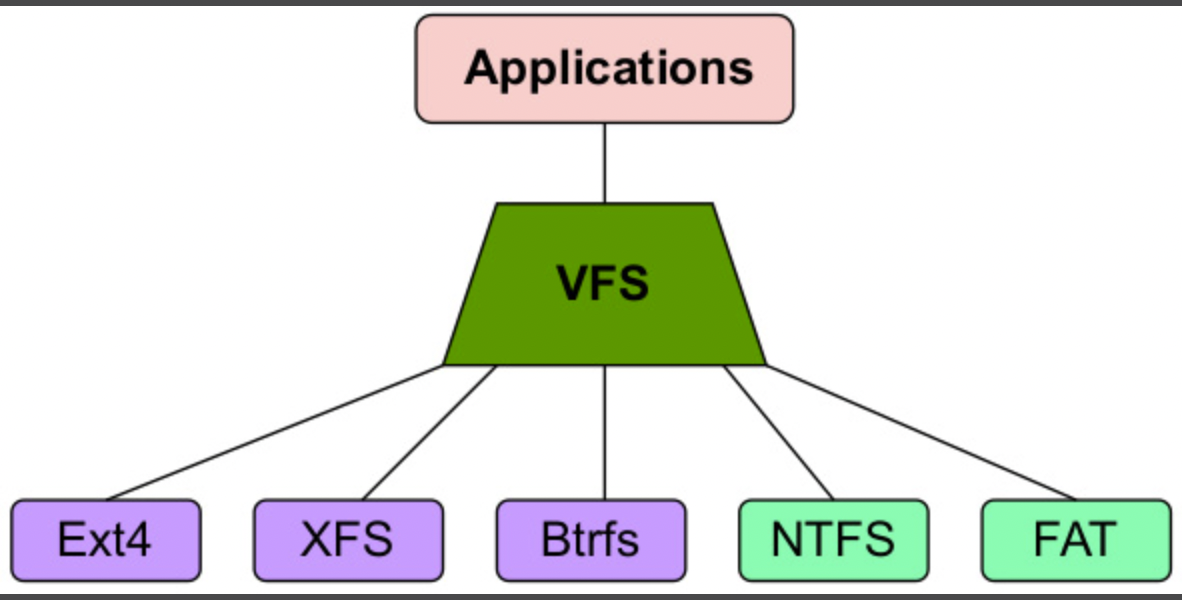
可以想象的是,NTFS、FAT 实际上和本地的 Ext4 之类的文件系统是不一样的,后者能支持的接口更多,前者则不一定支持 VFS 定义的所有操作。VFS 的操作基本基于 inode, superblock。比如 FAT 表示文件和目录的方式和 VFS 这套表示不一样,这就是一种模型上的不匹配。对于这种模型,VFS 会在内存中创建 inode / 目录等结构,这些东西是虚拟的(不存在 inode 的物理直接映射)、纯内存的。
同步过来的目录在:https://github.com/torvalds/linux/tree/master/fs
Bcc-tools 有工具叫 funccount ( https://github.com/brendangregg/perf-tools/blob/master/kernel/funccount ),可以用这个工具来 trace 对应的 vfs_ 调用,例如:
1 | funccount -p {processId} 'vfs_*' |
此外,/proc 和 /sys 都是伪文件系统,Linux 中,大部分实体(不是一切)都可以被抽象成文件,它们以稳健的形式展示在这两个目录下。
数据结构
这里比较结构的数据结构有:
- Inodes
- Directory entries (cache)
- File objects
- Superblocks
inode
对于 Linux 来说,文件描述数据(inode)和实际数据是隔离的。比如我在我的 Mac 上 stat 一下:
1 | stat /etc/hosts |
在 Linux 上:
1 | stat /etc/hosts |
inode 的编号在文件系统内不重复,不同分区内的文件可能有相同的 inode 编号。这也导致 hardlink 无法跨越文件系统。inode 定义如下:https://github.com/torvalds/linux/blob/master/include/linux/fs.h
1 | struct inode { |
const struct inode_operations 和 file_operations 类似于 C 语言经典的虚函数表:
inode_operations处理link、unlink、初始化、权限file_operations则对应某个文件系统的对应各种操作,我们会在后面介绍
Inode 包含数据指针和文件的元信息,总所周知,一般文件系统得存 inode 数据和 inode 表,然后 Ext4 用 256B 来保存一个 inode,而对于 /proc 之类的地方,inode 是纯内存的。对于数据,如下所示,这里使用 4B 一个 Pointer 只想数据的 block (实际上可能是文件系统中更大的数据 Extents),然后 Reserve 几个 Pointer 来索引 in-direct 的块数据,具体如下( 可参考 https://en.wikipedia.org/wiki/Inode_pointer_structure ):
- 12 direct pointers that directly point to blocks of the file’s data
- 1 singly indirect pointer (pointing to a block of direct pointers)
- 1 doubly indirect pointer (pointing to a block of single indirect pointers)
- 1 triply indirect pointer (pointing to a block of doubly indirect pointers)
文件名不会出现在 inode 中,它们是目录管理的。
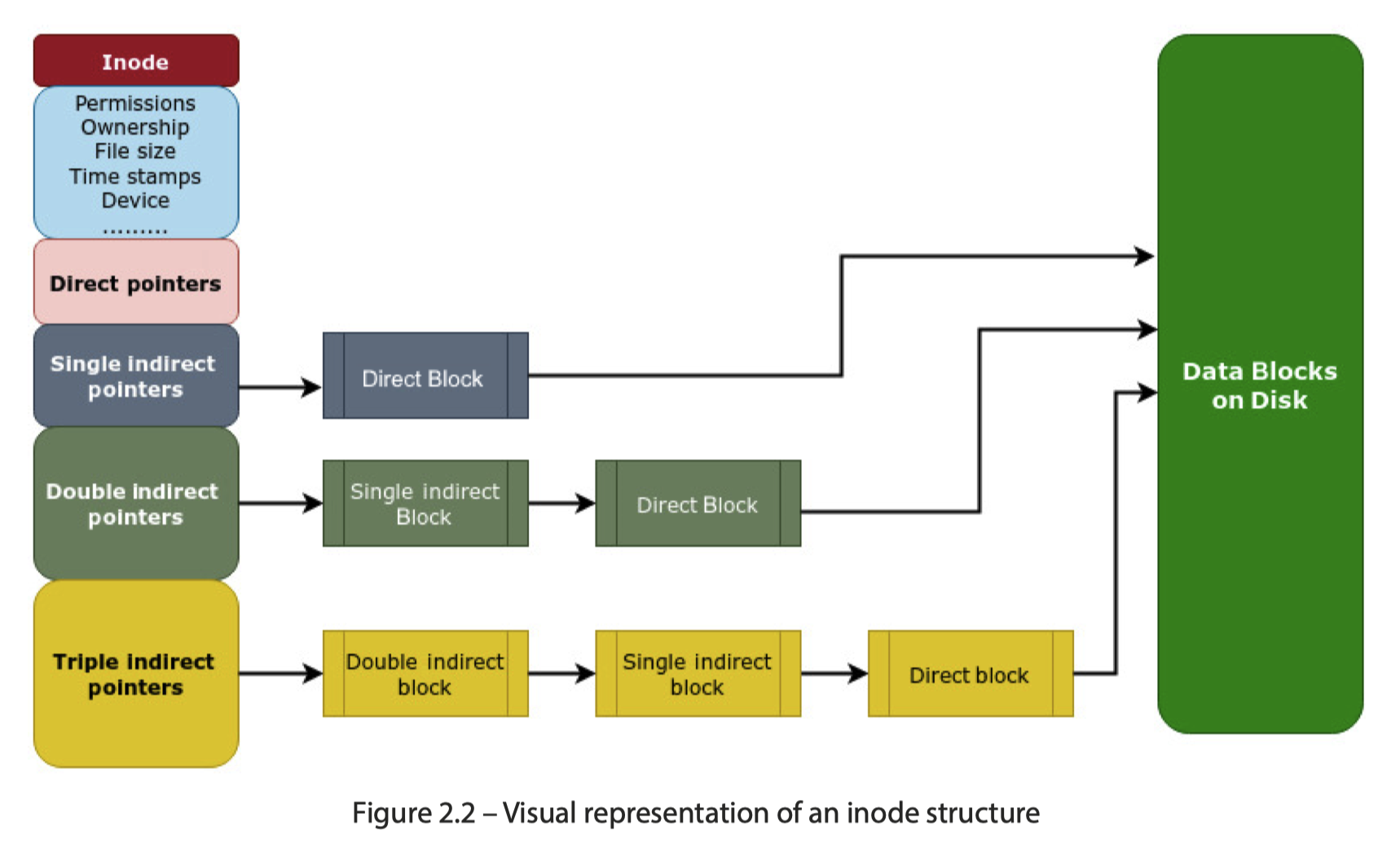
Inode 占用也可以看到对应的(这里没有管 fs 上的总磁盘空间占用,只衡量 fs 上的 inode 空间):
1 | ➜ ~ df -Thi |
dentry
目录则采取另一种教科书上大家都很熟悉的方式介绍
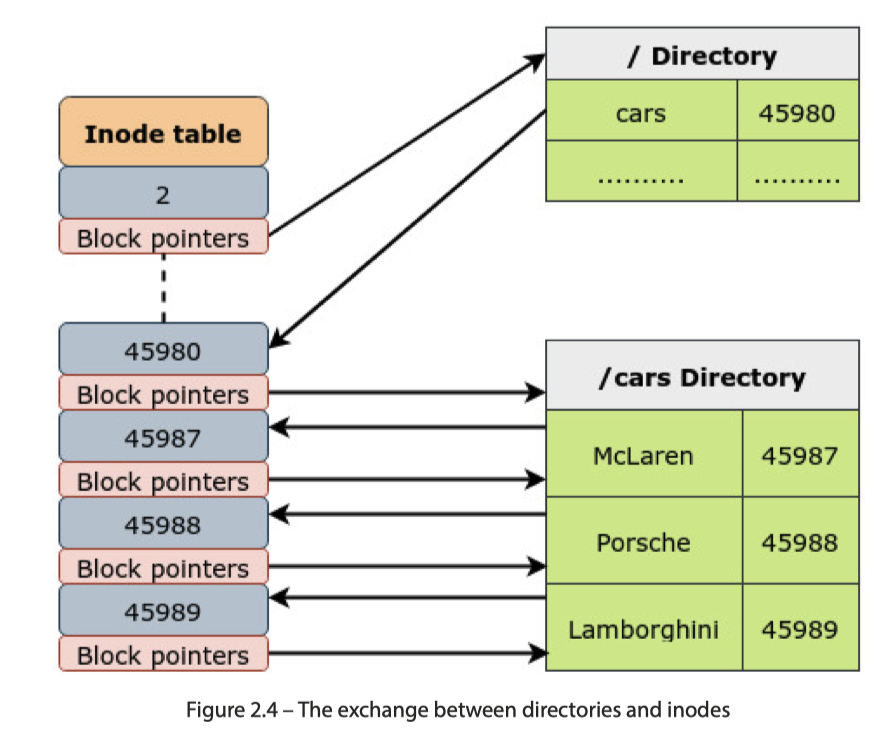
这个结构本身比较好理解,接下来需要引入的是 dentry,即 VFS 中目录的 cache。这部分代码在这里定义:https://github.com/torvalds/linux/blob/master/include/linux/dcache.h 。这里每一级别都会有自己的 dentry,如下图:
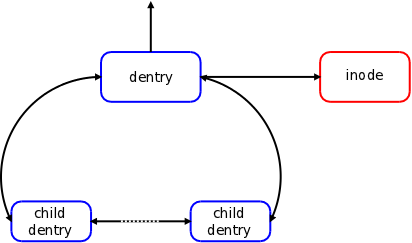
dentry 会有对应的一些状态:in-used( 正在被用), unused(没人在用,可以回收), negative (不存在,类似一些系统中的不存在的 key 的缓存),后两者在处理好并发的状态下空间可以被回收,一些细节可以参考 Linux中的VFS实现 [一] - 兰新宇的文章 - 知乎 https://zhuanlan.zhihu.com/p/100329177 ,这个系列的文章写的都很深入浅出。下面这样也能看到 dentry 的 state ( 参考:https://docs.kernel.org/admin-guide/sysctl/fs.html ) :
1 | cat /proc/sys/fs/dentry-state |
File
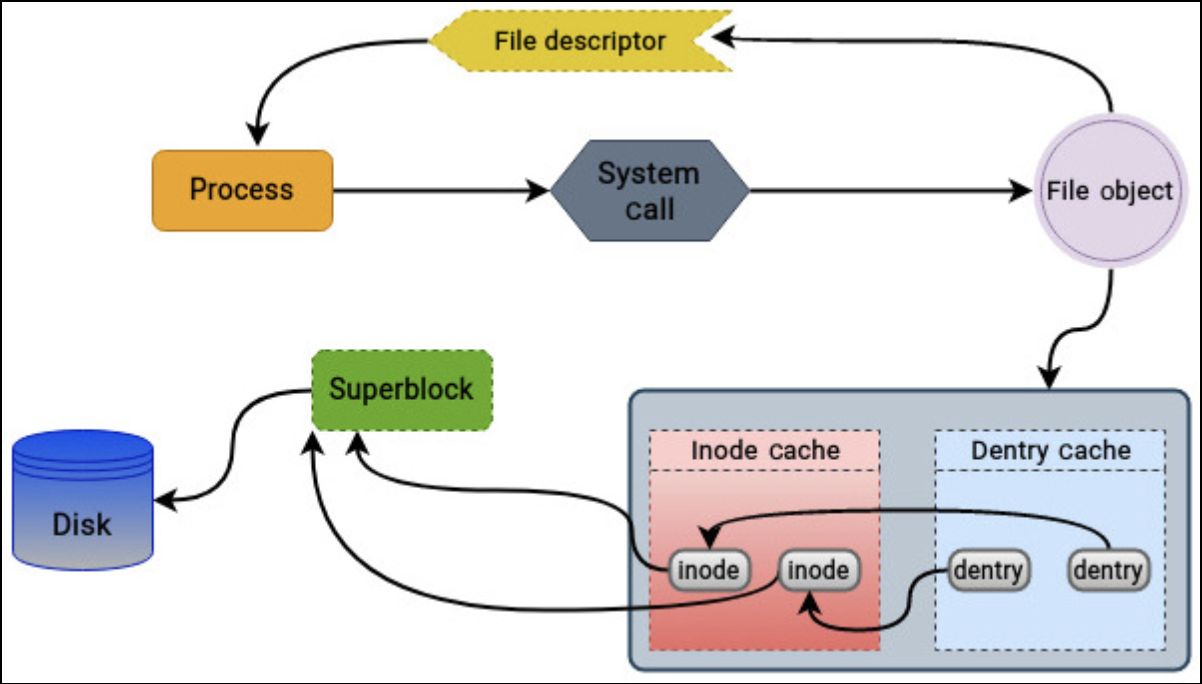
内核不只有 inode,众所周知,内核也有「内存中的进程打开的文件」这一概念,如下图(来自:https://unix.stackexchange.com/questions/4402/what-is-a-superblock-inode-dentry-and-a-file )
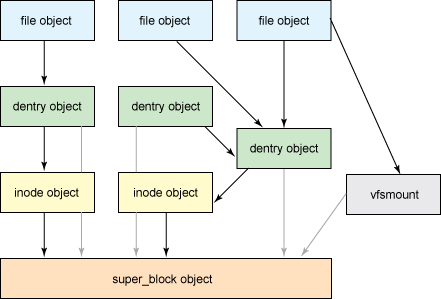
File 直接对应用户态的 fd 这个概念,见下图 open:
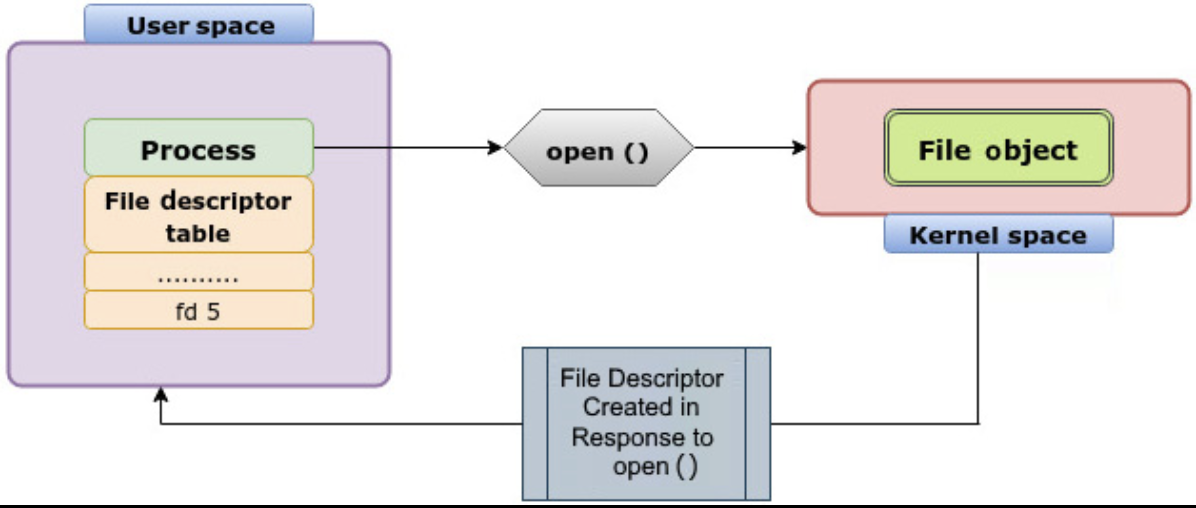
file 和 inode 一样,它和它的 operations 都定义在 https://github.com/torvalds/linux/blob/master/include/linux/fs.h 中:
- File 有对应的
inode File有对应的file_operationsfile_operations由下面的 fs 决定实现,封装了读写 ioctl mmap 甚至 iouring 等方法,同时接口没有实现可以设置为 NULL
super_block
super_block 存储文件系统的 metadata。每个 fs 有一个对应的 superblock,superblock 也有对应的磁盘数据( 同 一些 inode 一样,对于 /proc 之类的 fs,super_block 也是纯内存的),它也定义在 include/linux/fs.h 中,对应下面:https://github.com/torvalds/linux/blob/master/include/linux/fs.h#L1313
这里会 track 一些 blocks 的信息,比如根目录 inode 设备号、根目录、文件系统类型等。因为这玩意很重要,所以它可能会被备份多份。
Wrap up
VFS 内部还有 page cache,这里是针对 `` 的 cache,内容如下:
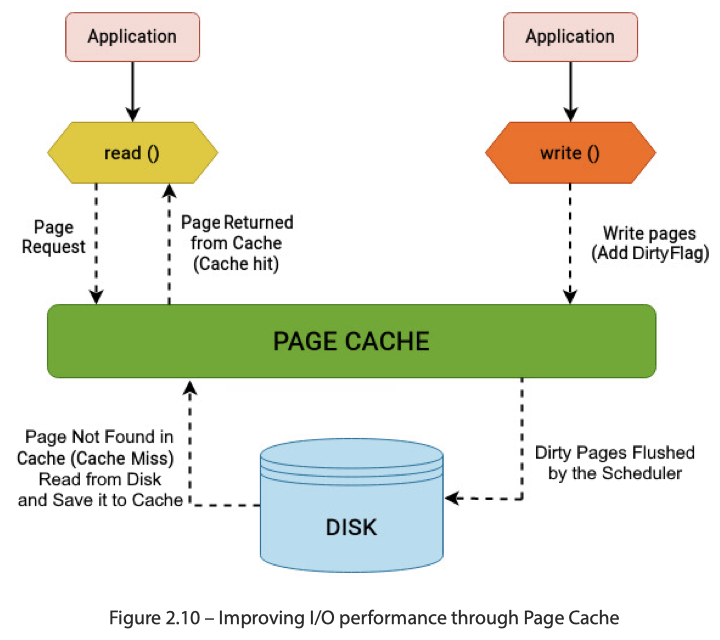
因为和 inode 挂钩,所以进程即使没了,这个 cache 可能还是存在的(没有被淘汰),一个有 io 的性能测试程序跑两遍可能还会收到 Page Cache 的影响。当然这里也类似数据库的 Buffer Pool,不止承担读的功能,也会承载刷脏之类的「写入」需求。
Linux Page Cache 大小也是根据系统负载来的,并不是静态写死的。因为内存 Buffer 这东西其实可以有很多个,同时用户也会需要自己的内存资源,协调本身就会变得很重要。(从某种意义上来说,数据库处理这种问题可能可以更专注一些,因为 db 能够介入上层各个 Operator 的实现和内存管控。虽然无法管用户实际运行的 SQL 负载,但是因为自身能介入自己的内存管理,所以可以更专注的用一些特定方式处理内存。OS 可能就需要考虑通用性了。)
Underlying FileSystem
下面是一些广泛支持的文件系统(NTFS 和 FAT 虽然能被支持,但是有点阻抗不匹配)
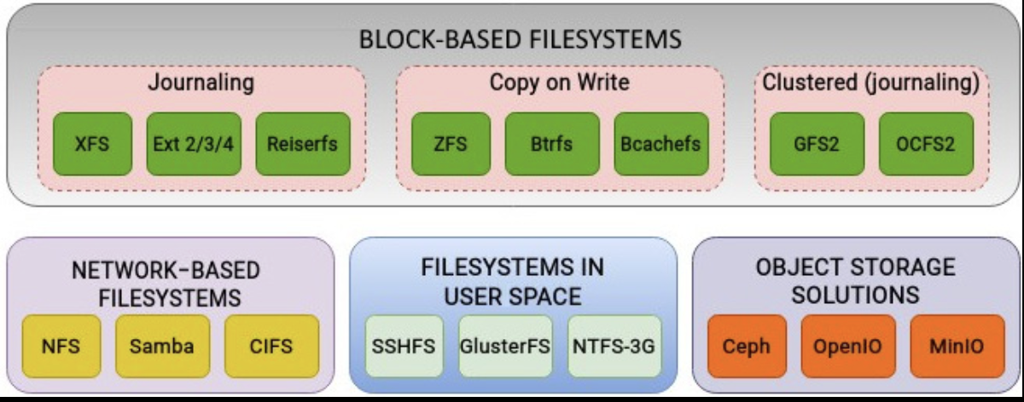
下面也会介绍一些文件系统的关键组成部分。
Journaling
即使硬件有一些4K原子写的操作,Fs 有些操作也不是原子的,比如说创建文件:
- 需要创建新的 inode
- 更新目录的时间戳和目录的 inode 的内容
这两个类似 DB 事务需要是原子的,所以这里要么有 CoW 类似的操作,要么是某种日志来更新。系统恢复的时候,也需要检查文件系统。文件系统日志记录的概念源于数据库系统的设计(原来不是独立发明的吗)。因为我是 DB 懂哥(不是),所以就不展开了
CoW
某种程度上,CoW 也是一种「恢复数据友好」型玩法(真的吗,我没有体验过),我突然想到,好像「现代」一点的数据,从 Neon 到 Iceberg,很大程度上都是某种 Page Log 的 CoW 混合物,这对 GC 提出了一定的要求,可能是不是源于现代(应用层)存储空间的极大富余?书上只讲了 CoW 和日志做对比,当然我们 DB 的玩法要走的更远(x)
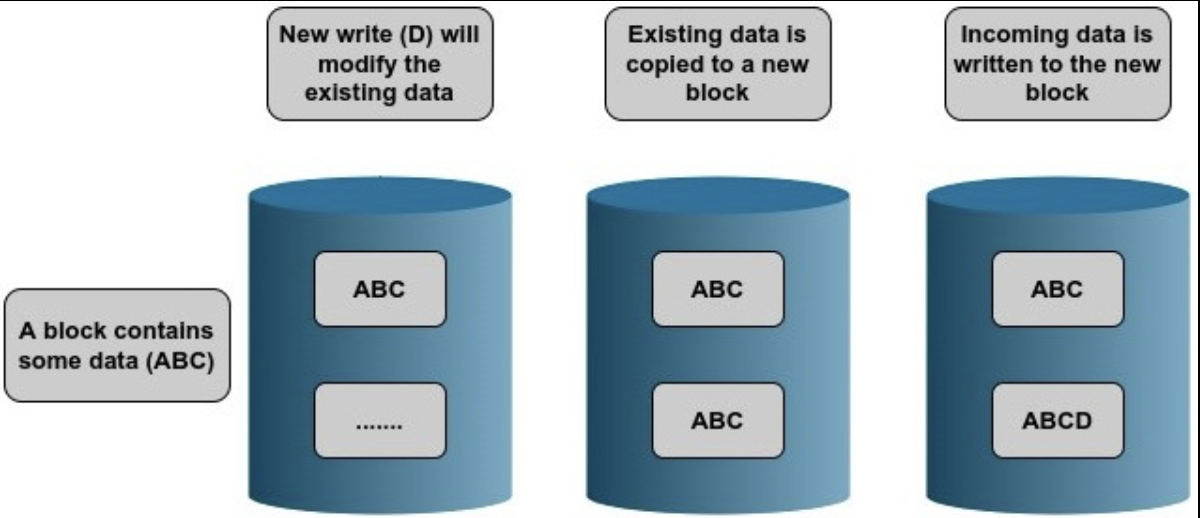
基于 CoW 的 FS 包含 ZFS, Btrfs 和 Bcachefs。Btrfs 也用这些东西支持了一些好玩的功能:
它的一些功能包括快照、校验和、加密、重复数据删除和压缩,这些通常在常规块文件系统中是不可用的。所有这些特性大大简化了存储管理。
Ext
「就 Linux 发行版而言,Ext4 可能是最常被部署的文件系统」。
这里有几个 building blocks:
- Block
- 应该是 Storage 的 Sector/Page 大小的
2^n倍 - 小于或等于内存页大小
- FS 创建后,不能动态更改 block size
- 应该是 Storage 的 Sector/Page 大小的
- Block 被 organize 到被称为 Block Group 的单元里面,开始的 SuperBlock 会有个 1024B offsets。
- SuperBlock 的定义如下:https://github.com/torvalds/linux/blob/master/fs/ext4/ext4.h#L1333
s_log_block_size用于定义 block sizes_log_cluster_size: ext4 允许 bigalloc 去分配一些大一点的块单元,即 block cluster,它的大小由这个值定义s_inodes_per_group: block group 上的 inode sizes_state,s_mnt_count,s_max_mnt_count描述文件挂载时候的一些状态,用于恢复和检测(这些 16b 不会 overflow 吗?)- Block reservatio:为系统准备的预留块,给 root/super 准备 5% 左右的预留空间。
- First inode number: 第一个用户 inode 的 id
s_feature_compat表示 fs 的 feature/版本(感觉对于 storage 这种 feature pattern 已经被广泛使用了,看 iceberg/deltalake 也有这种版本检测机制)
- Inode bitmap and inode table
- Inode 有自己的 bitmap,来跟踪是否分配
- Inode table 存放 inode,定义如下 (
ext4_inode):https://github.com/torvalds/linux/blob/master/fs/ext4/ext4.h#L802 。这里定义了 fs 的 inode 结构
- Group descriptors (GDT) and Reserved GDT Blocks
- GDT 是 Block Group 的管理信息,见:https://github.com/torvalds/linux/blob/master/fs/ext4/ext4.h#L410
- Ext4 大小可以扩大,所以这里会预留一些 GDT 空间,来方便做这些变更
下图是 Ext4 的 Layout,非 block group 0 的 group 允许备份 superblock 之类的结构,但是不会像 Data block bitmap 一样是必须的。这里的大小由 superblock 上的信息决定。下图是 Gemini 爹给我画的。
1 | +---------------------+ |

Journaling mode
Ext4 在内部维护 journal,同时它由不同的 journal mode,包括:
- Ordered: In ordered mode, only metadata is journaled. The actual data is directly written to disk. The order of the operations is strictly followed. First, the metadata is written to the journal; second, the actual data is written to disk; and last, the metadata is written to disk. If there is a crash, filesystem structures are preserved. However, the data being written at the time of the crash may be lost.
- Writeback: The writeback mode also only journals metadata. The difference is that actual data and metadata can be written in any order. This is a slightly more risky approach than ordered mode but offers much better performance.
- Journal: In journal mode, both data and metadata are written to the journal first, before being committed to the disk. This offers the highest level of security and consistency but can adversely affect performance, as all write operations have to be performed twice.
代码见:
https://github.com/torvalds/linux/blob/master/fs/ext4/ext4.h#L1393
这里可能由 jdb2 具体处理这些日志。
Filesystem Extents
我们之前在 File 一层描述过文件如何用 inode 的简介索引来存储大文件。Ext4 用 Extent 来维护多个连续的 block。这里结构如下:https://github.com/torvalds/linux/blob/master/fs/ext4/ext4_extents.h#L63
Block allocation policies
Ext4 will then select an appropriate block group for that file. The design of Ext4 makes sure that maximum effort is made to do the following:
- Allocate the inode in the block group that contains the parent directory of the file
- Allocate a file to the block group that contains the file’s inode
Once a file has been saved on disk, after some time, the user wants to add new data to the file. Ext4 will start a search for free blocks, from the block that was most recently allocated to the file.
When writing data to an Ext3 filesystem, the block allocator only allocated a single 4 KB block at a time. Assuming a block size of 4KB, for a single 100 MB file, the block allocator would need to be called 25,600 times. Similarly, when a file is extended and new blocks are allocated from the block group, they can be in random order. This random allocation can result in excessive disk seeking. This approach does not scale well and causes fragmentation and performance issues. The Ext4 filesystem offers a significant improvement on this through the use of a multi-block allocator. When a new file is created, the multi-block allocator in Ext4 allocates multiple blocks in a single call. This reduces the overhead and increases performance. If the file uses those blocks, the data is written in a single multi-block extent. If the file does not use the extra allocated blocks, they are freed.
本质上是:
- 会尽量和父级别分配在一起(局部性)
- 通过攒 buffer 来惰性,尽量做连续的分配
NFS
NFS 协议由 Sun Microsystems 在 1984 年创建。NFS 是一种分布式文件系统,允许访问存储在远程位置的文件。区分 client/server,用 RPC/XDR 来通信,如下图:
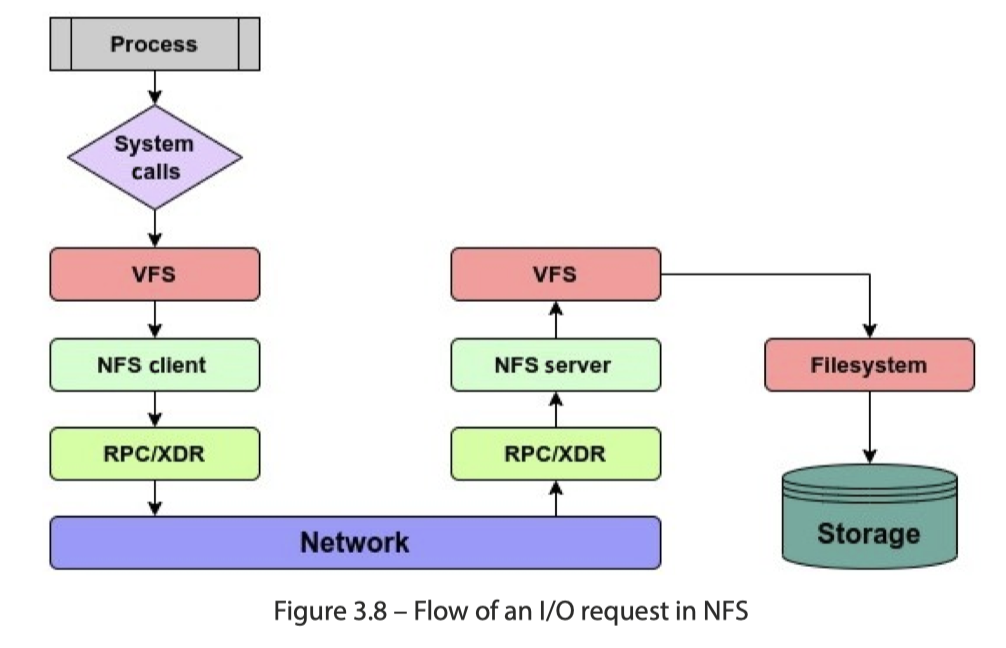
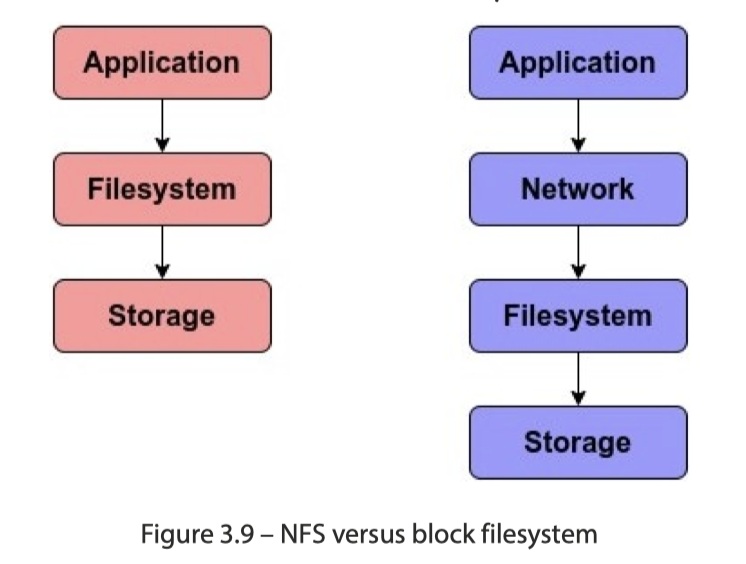
NFS 文件系统交互的逻辑为下图:
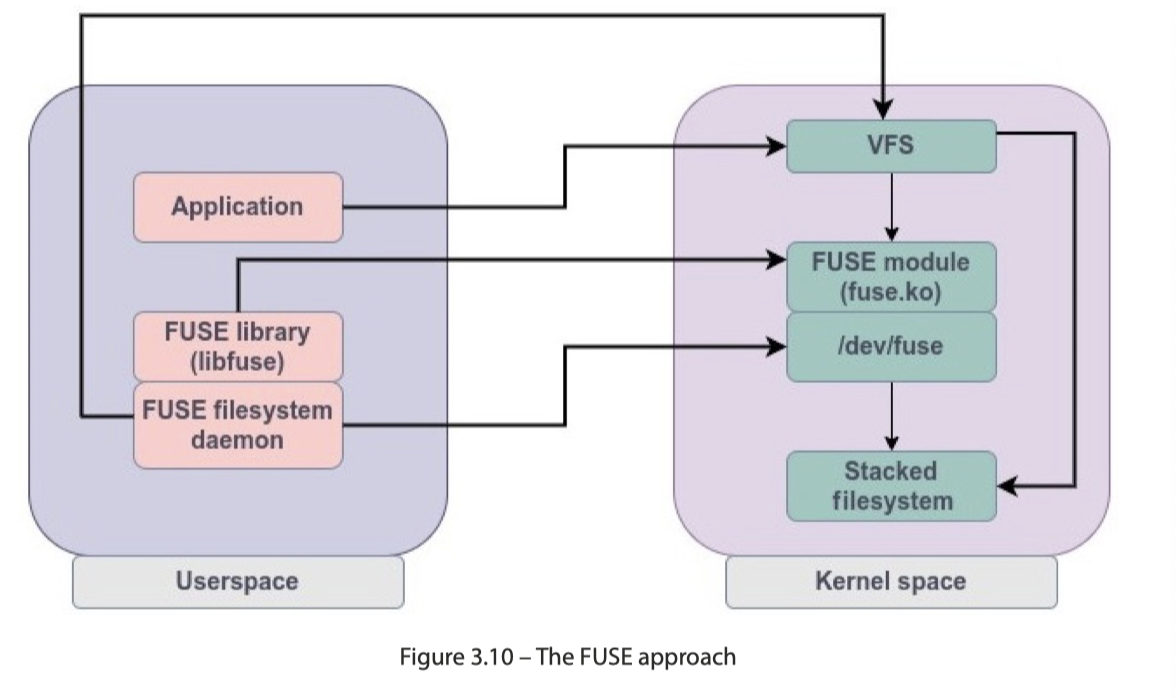
Fuse
Fuse 模块在内核态注册文件系统,然后和用户态 libfuse 交互,请求被发送给 /dev/fuse,然后处理。fuse 程序可以自己处理,也可以再次把请求发送给内核
GlusterFS 是一种比较著名的跑 Fuse 上的文件系统。Fuse 的好处是不用改内核,用户层面适配很轻松,同时 debug 也比较简单。限制则是: daemon 占用的资源、内核用户态切换的开销,甚至可能有多重的缓存(比如用户 api 写了一层缓存,然后你再开发又是一层缓存)。
一般来说,像阿里云这种有 Fisc 这种 fs,也有 pangu 这种块存储,就让你虚拟化努努力。
References
https://static.linaro.org/connect/bkk19/presentations/bkk19-510.pdf
https://github.com/torvalds/linux/blob/master/block/bfq-iosched.c#L182
Linux 内核IO 调度器之 none vs kyber vs BFQ - fasttt的文章 - 知乎 https://zhuanlan.zhihu.com/p/610113020
- https://www.sobyte.net/post/2022-03/linux-io-and-zero-copy/ <— 这一系列讲的是 Linux 上操作的 zero-copy,笔者阅读的时候确实感觉深入浅出
- Linux中的VFS实现 [一] - 兰新宇的文章 - 知乎 https://zhuanlan.zhihu.com/p/100329177 <— 这一系列的文章有很高的水平
- https://www.slideshare.net/slideshow/linux-kernel-virtual-file-system/250698998