Lance file format
Lance is a modern columnar data format that is optimized for ML workflows and datasets.
格式的定位: 文件和 Dataset 层(组织文件的变更)。
- 支持 CPU/GPU 的 Vector Index (HNSW, IVF) 和基础的召回语义,此外也支持一些别的索引,目前包括
BTree,Bitmap,Full text search,Label list,NGrams - Versioning: 类似 iceberg 的版本 Manifest 等
- Encoding: 这个地方有点微妙,这里最早对外承诺说 Lance 可以快速点查,但官方配置是没有 Encoding 的。不 Encoding 做点查就感觉有点微妙。官方后续(24年)支持了 custom encoding,并且支持了一些新的编码和 List/Struct 等 Encoding 的设计,这才算有比较好的 Random Access 性质。
- Compression: 允许配置 Block Compression,做 Page 级别的压缩
- Nested Field 和一些特定数据类型: 支持子字段、blob 之类的类型,可以存图片之类的 blob
LanceDB 定位:(Datafusion 支持的)向量数据库。
Lance 有 V1 V2 版本,V1 应该是早期糊了一版本糊弄投资的,所以对外宣传有很多 PointLookup 的成分。下面的讨论基于 Lance V2 Format。
Lance 文件的基础结构设计
( 下图来自官方博客 [3] )
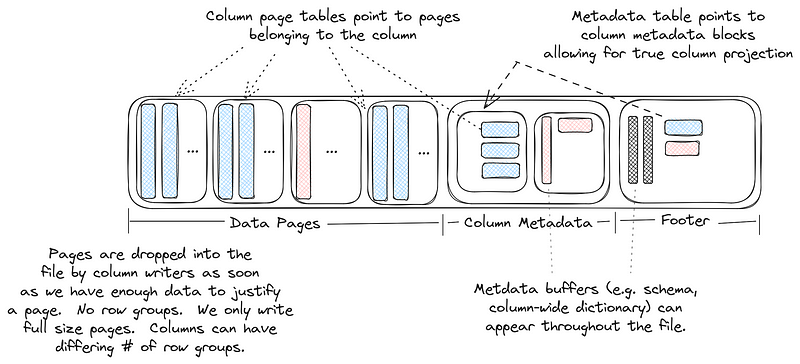
Lance 文件分为几个区域:
- Data Pages
- DataPages 由 Data Buffers 组成,一个 Page 可以由多个 Data Buffer 组成。每个 Buffer (通常可)对齐 4kb
- Page 允许乱序出现在文件中,不需要每个 Column 的 Page 连续存储
- Lance 推荐每个 Page 的大小应该不小于 8MB (笔者猜测和 Column Encoding 的设计和 io 的调度有关)。
- Column Metadatas
- 存放每个 Column 的 Metadata
- 存储 Page 的元信息(位置):包含 Buffer 的
[(offset, size)]组、(start_row, length)行信息和Encoding信息 - Lance 的 Encoding 信息是一个非常「宽」的 Encoding 信息,定义在
- Column Metadata Offset Table
- 存放 Column Metadata 本身的 Offsets
- Global Buffers Offset Table
- 指向一些全局用的 Buffer,这里第一个 Buffer 一定是 protobuf 的文件 Schema (
FileDescriptor)
- 指向一些全局用的 Buffer,这里第一个 Buffer 一定是 protobuf 的文件 Schema (
- Footer: 指向上述 Column Metadatas、Column Metadata Offset Table、Global Buffers Offset Table 三个元数据 Buffer。Footer 只是一个 40B 的 Buffer。
一些决策的讨论
这里讲几个设计决策:
(1) 注意到这里没有 RowGroup 的概念,只有列 Page,官方解释也挺有道理的。我们这也遇到过因为有很大的列 -> RowGroup 按照固定大小切效果不好 -> 读取的时候小碎 io 多导致慢的场景。不过本质上我理解还是某种程度上的 Trade-off ( RowGroup 大小调整本质是写入内存和写入模式 vs 读取效果,同时面临的问题是不好静态调整,实际上 Lance 的 Out-of-order Page 和无 RowGroup 应该对应的就是类似的事情,但是对写入者本身情况也做出了要求,可能默认限制内存的情况下能够当成1个 RowGroup 的大文件,然后大列可以按照自己的大小不断切分)
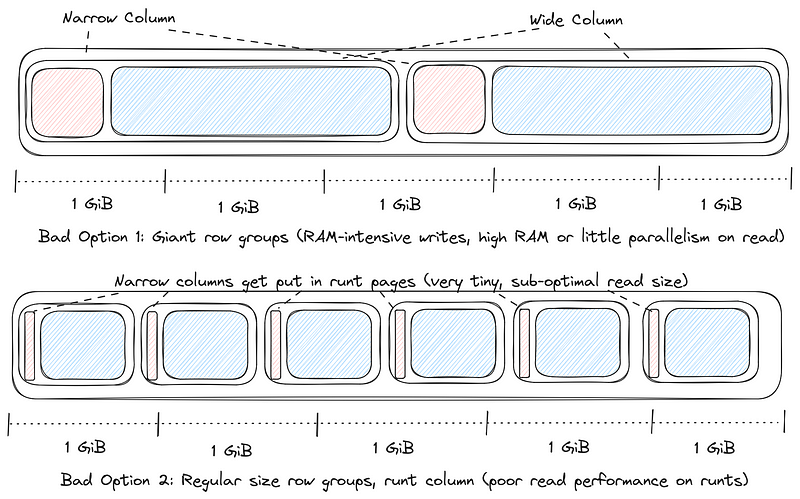
Picking a good row group size is impossible when a file has a wide column
(2) 这里聊到元数据的设计,原文说:
In Parquet, an encoding can only control what goes into the data page. This means that encodings have no access to the column or file metadata. For example, consider dictionary encoding, where we know the dictionary will be constant throughout a column. We would ideally like to put the dictionary in the column metadata but we are instead forced to put it into every single row group. Another use case is skip tables for run length encoded columns. If we can put these in the column metadata then we can trade slightly larger metadata for much faster point lookups into RLE encoded columns.
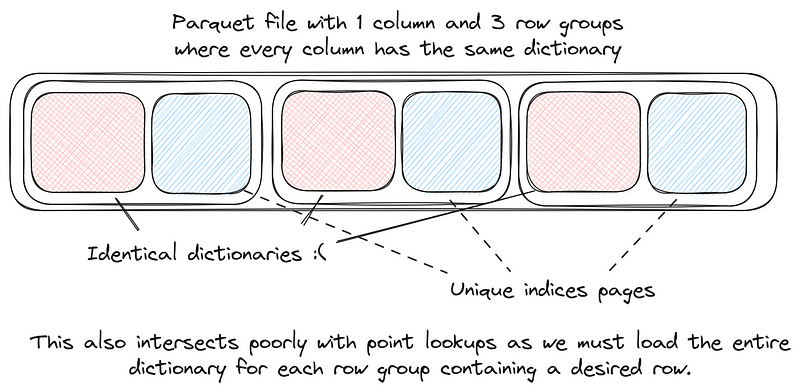
这里实际上逻辑应该是:因为这里 Column Metadata 从 Footer 拆分开来了,也没有使用 Thrift / Protobuf 这种并不好优化的结构 -> 所以实际上提供了优化空间,允许 Metadata 内容更多一些,把更多信息抽取到 Column Metadata 里面,也不需要 Data Page 自描述 -> 可以把更多信息放到 ColumnMetadata 上,包括我们下一节会提到的,这里会(允许)把 Dictionary 放到 Column Metadata 上。Lance 甚至允许多列字典编码,可以抽取多个列的字典,然后放到 Global Buffers 上。
Column Encoding
具体设计可以参考:Lance Columnar Encodings for Random Access https://docs.google.com/document/d/19QNZq7A-797CXt8Z5pCrDEcxcRxEE8J0_sw4goqqgIY/edit?tab=t.0#heading=h.ke4v23hrtsbz
这里 Column Encoding 的设计还是比较有意思的,具体见 Protobuf: protos/encodings.proto,这里有几个设计考量(除了 FSST Bitpack 之类的本身的编码之外):
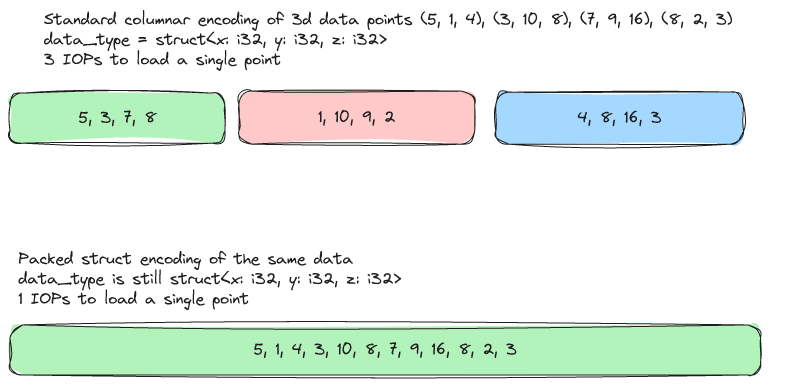
ZoneIndex类似的 min-max statsitics 存储在Encoding下面。在这里面,ZoneMap 也是以数据的形式存储的((min_value, max_value, null_count),我也在想 raw-size 这些如果要扩展的话能怎么搞 )- 允许有类似行存的方案 (
PackedStruct和PackedStructFixedWidthMiniBlock),存储多列在一起(类似下图)。这里称作 Zipped。注意 Zipped 本身不支持 RLE 等编码,本质上是类似行存的结构
这里顺手贴一下存储的 Buffer 类型的代码:
1 | // A pointer to a buffer in a Lance file |
- 字典的设计中,字典被当成是元数据,这里我觉得思路和之前说的地方是差不多的
In Parquet, an encoding can only control what goes into the data page. This means that encodings have no access to the column or file metadata. For example, consider dictionary encoding, where we know the dictionary will be constant throughout a column. We would ideally like to put the dictionary in the column metadata but we are instead forced to put it into every single row group. Another use case is skip tables for run length encoded columns. If we can put these in the column metadata then we can trade slightly larger metadata for much faster point lookups into RLE encoded columns.
- 为了支持 Point Lookup,Null 数据也会预留对应的空间。
String类型的存储使用 Offsets + Value 两组 Buffer 的方式来存储。List类型的存储,也需要 Offsets。这里的特征是内外两层 Validity。存储方式如文:「We can broadcast the outer validity into the inner validity but that would be slightly less efficient and we don’t need to in this case. Instead, we zip the outer validity into the list offsets and zip the inner validity into the list values.」- Struct 的存储比较淳朴:
- 类似于 Parquet 存储一组 DefLevel 然后用 int def level 来修复,这里实现方式类似 Concat 每层的 Null List,感觉本质都一样,但是这里存储方式不是像 Parquet 一样给出不同的 Def Level Count,而是通过 Zipped 的方式拼接数字
- 和 Parquet 一样,只会存储 Leaf Column
- 不同的是允许 “Zipped” column,拼接多组 column。然后尽量去压缩 validity
- Validity 可以和数据压缩在一起,比方说可以根据 validity 或者数据的 Min-Max,把多层的 validity 拼凑到一起
- Validity 可以和数据数据一起处理,这种压缩也是一种 “Zipped”,相当于可以把 validity buffer 和数据 buffer 合在一起。(
FullZipLayout)和分开处理 (MiniBlockLayout)两种方式,见 (prefers_miniblock)。本质相当于根据 row-size 选择是否把 Buffer 来变换之后压缩处理(用一些 Zipped 方式,来尽量用一些 Bitpack 的手段压缩 Buffer 大小,具体见后文)
List支持 O(1) lookup,类似 ORC。这里实现的方式是最外层存 Offsets,然后下面存内容。这里举个例子,List>>只会有4个处理存储列,List>则会有三个列。这里 Offset 也能做内部的压缩。
这里可以分析一下:
- 如果做 Primitive Type 类型的 io,Null 和 Values 交织的情况下,因为 Parquet 只存 Values,同时因为只存 Values 便于 Encoding,所以 Parquet 压缩率可能会高一些,也可以采用一些特定 Encoding (但实际上现在 Encoding 本身都比较简陋)。Lance 本身方案是 PointGet,对于定长类型,它即使是 NULL 也会存储(虽然有一些方案来降低这部分开销),比如和 validity buffer 一起 transmute。
- 对于 List 类型(实际上对 Map 类型也是),这里可能会有多轮的 io。Parquet 这里本身没有单独存 Offset,会直接根据 RowId 定位到对应的 Pages,然后根据 Pages 走一轮拿。Parquet 在 Page 内必须通过解析 Rep-Def Levels 的方式,消耗更多的 CPU 资源来定位数据。Lance 可能需要多走一轮 IO 拿 Offset Buffer,再去拿行对应的数据 Buffer,相当于一种延迟换 CPU 的方式?
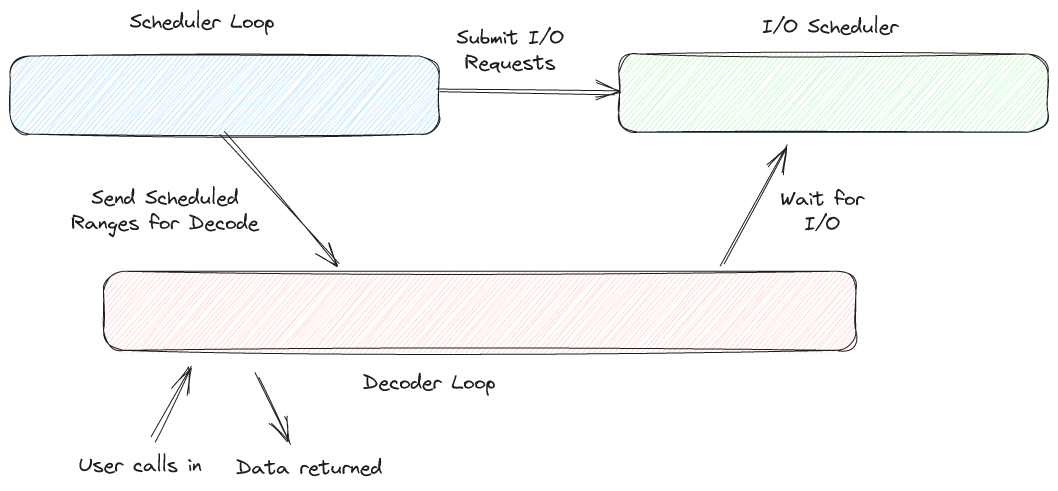
IO 调度
这里实现了一个2层( Global - File )的 IOScheduler 系统。
- 全局有一个
EncodingsIo类型,实现是一个全局的FileScheduler,会有一个类似 Linux io 合并的机制,把请求投递到一个队列中,然后尽量合并这个队列中的请求。- 这里和 Parquet 可以做的 io 调度是不一样的,因为 Encoding 上 Parquet 做裁剪并没有 Lance 这种多层 Buffer 的机制,所以给出一个 Filter,Parquet 可以拿到对应的 io range。我理解 Lance 相当于用多轮的读延迟换了更大的带宽上限?
- 下层会有一个
SchedulerDecoderConfig,存储对应的 io 配置和cache类型,然后用这个在create_scheduler_decoder创建顶层的DecodeBatchScheduler,这里通过schedule_range来调度 row 的读取 DecodeBatchScheduler持有FieldScheduler,FieldScheduler是 io 调度的基本单元,接收 io 的行,用来调度List,String等各个类型的 ioDecodeBatchScheduler里面有一个 mpmc queuempsc::UnboundedSender>,Scheduler接受这个 queue,并向 queue 中写入DecodeMessage. 在消费端,create_decode_stream会创建对应的 decoder 来消费这些 batch
Blob 设计
Blob 这里实现了一个对应的 Encoding: https://github.com/lancedb/lance/pull/2868/files . 在内容中记录文件的 struct(offset, size),然后允许去间接访问这块的内容。可以看下面的内容:
Index & Vector Index
Lance 支持一些对应的 Index,见 proto: https://github.com/lancedb/lance/blob/main/protos/index.proto
Lance V2 之后的 Index 文件都是 Lance 数据文件,这里支持:
- Scalar Index
- Full Text Search Index
- Vector Index
这里希望是用数据的编码,来召回到存储的 Lance rowId。
Wrap up
写入的基础流程
写入的时候,这里会尝试建立 Encoder,Encoder 会给每列尝试攒 8M-32M的 Page,然后尝试给每个 Page 创建写入的 Task,来异步的写入多列。
读取的基础流程
具体代码在 rust/lance-file/src/v2 下(上层目录是 v1)。这里打开文件的顺序是:
- 先尝试读一个
block_size(默认 4KB )的 Footer - 然后尝试 planning 所有需要的 metadata,进行
- 读取 global offset table
- 根据 schema 读取所有的 column metadata
这里解析 footer 可能要 3轮 io,不过运气好可能会有 cache 什么的。
读数据的时候,通过 schedule 和优先级,调度文件的 batch 来获得更优先的读取顺序。
Reference
- https://blog.lancedb.com/designing-a-table-format-for-ml-workloads/
- https://blog.lancedb.com/the-case-for-random-access-i-o/
- https://blog.lancedb.com/lance-v2/
- https://blog.lancedb.com/columnar-file-readers-in-depth-backpressure/
- https://blog.lancedb.com/splitting-scheduling-from-decoding/
- https://blog.lancedb.com/file-readers-in-depth-parallelism-without-row-groups/
- Lance Columnar Encodings for Random Access https://docs.google.com/document/d/19QNZq7A-797CXt8Z5pCrDEcxcRxEE8J0_sw4goqqgIY/edit?tab=t.0#heading=h.ke4v23hrtsbz