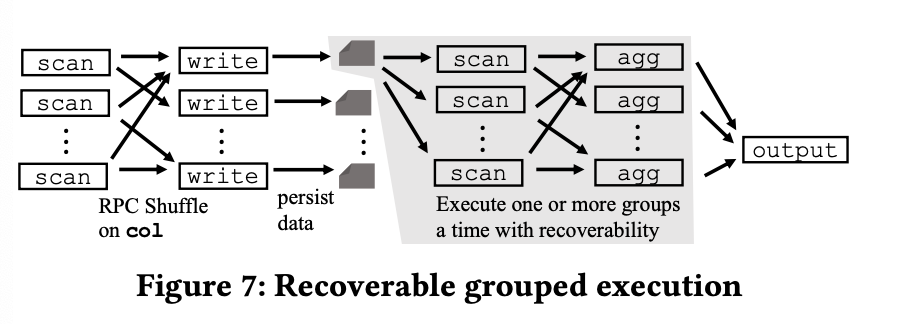
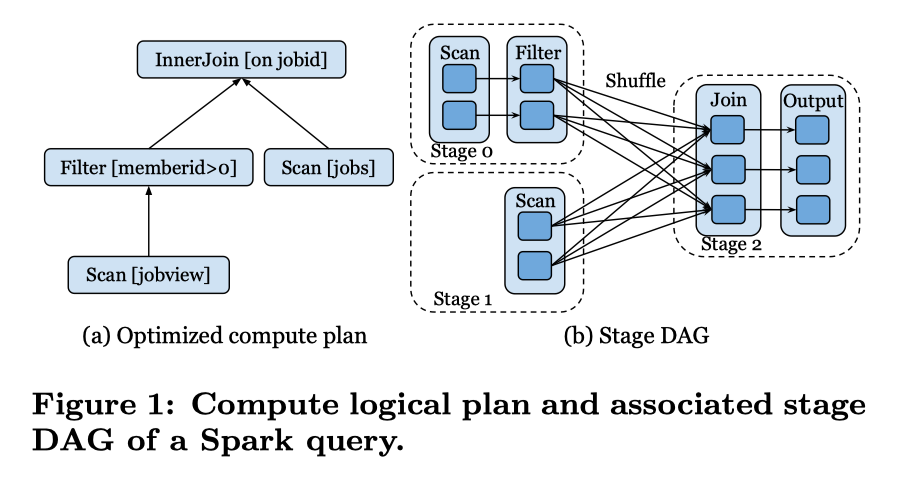
Velox Exchange/Shuffle Skeleton
Exchange 指的是数据的交换(废话),在 Presto 里面,我们可以看到下图所述的逻辑:
- 数据按照一定的格式(Presto 有 PrestoPage 的格式,Spark 也有自己的格式,Velox 见:https://facebookincubator.github.io/velox/develop/serde.html 和 https://prestodb.io/docs/current/develop/serialized-page.html ),Presto 默认的格式是 PrestoPage,别的地方也可以指定自己的格式
- Presto 本身是走网络的形式去 pull 数据,Spark 之类的会有不一样的搞法,它会输出端负责 Sort + 持久化数据,写到本地(或者是写到 Shuffle Service 来聚合),然后下游 Stage 在 Shuffle Write 完后,收集一些信息,启动 Shuffle Read
- 在一些系统中,一些 Join Build 之类的某端数据收集数据的也可能会走 Shuffle 这样的接口来做 Broadcast,不过这个看实现了。
下图是 Presto 对应的流程和 Spark 对应的流程
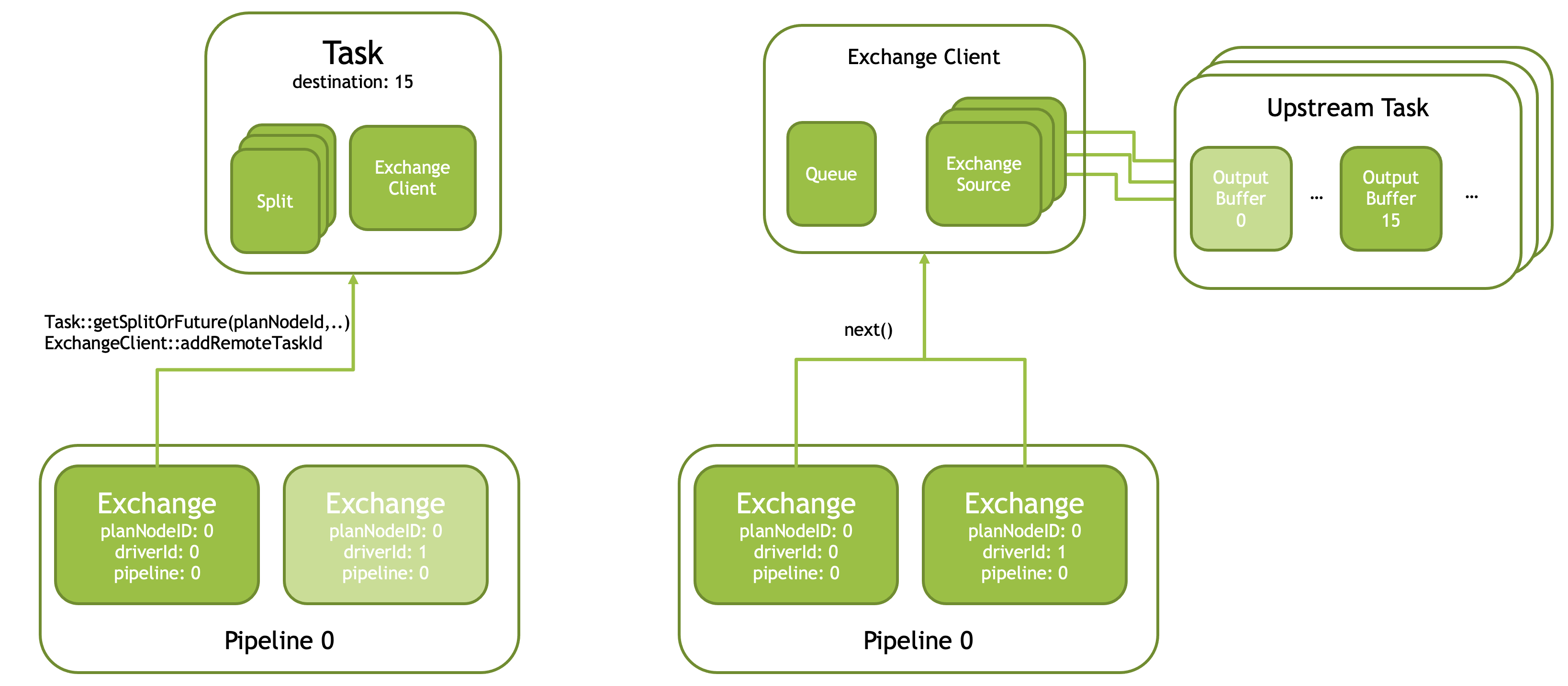
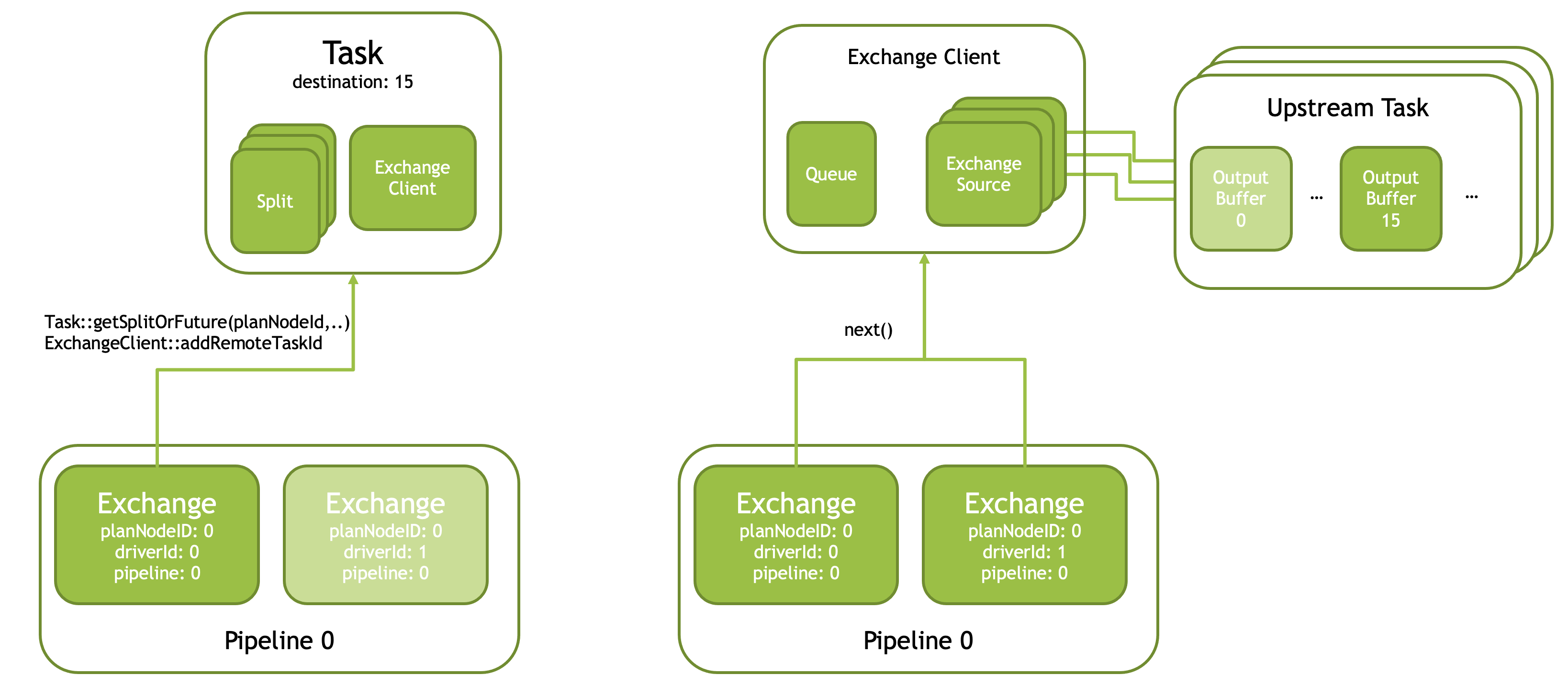
Presto 实现了 Pull-based Shuffle 的流程,实现了几个对应的基本的 Operator,然后实现者需要实现对应的 ExchangeClient, ExchangeSource( https://facebookincubator.github.io/velox/develop/task.html#exchange-clients )具体逻辑是:
- Task 对应有一个
width,感觉类似上层的分片,比如 Task Width = 4,那么对应的内容就会分成4份,感觉和 Grouped Execution 那种 Group 还不一样。这个设置在 Task 中会叫做destination。 - 输出端的 PartitionedOutput 没有把逻辑写在下图,它会:
- 进程会有一个对应的
OutputBufferManager,管理 Buffer 的输出,在 Task 需要启动的时候,会有一个类似的维护逻辑(参考LocalRunner::makeStages) - 这个是一个带限流的输出 Partitioned Buffer 池。Presto 采取 Pull 的模式,它实现了一个 Http Service( https://github.com/prestodb/presto/blob/6f09c5703159f1e0e897f50d8ccb87731c4220b4/presto-native-execution/presto_cpp/main/TaskResource.h ),然后允许读者从这里面来 Pull Page。Pull 的时候这里也有类似 TCP 的 Seq Id,来做一些 Buffer 的维护 。比方说上游发送 acknowledge = 10,那么可能这里之前的页面就可以回收了。这里拆分了不同的接口,比如
getData拿数据,acknowledge告诉你下游消费数据,很神秘 - 指定输出的模式,可以是 arbitarty, partition 或者 broadcast。
DestinationBuffer是一个重要的类型,描述了一端的输出,这里向内部发送shared_ptr,等待下游 pull。我为什么要写shared_ptr呢?想想broadcast的情况,不同的 dest 维护自己的水位,但是 Page 可能是共享的,所以需要引用计数维护。 - 输出的时候,逻辑上是会给 Dest 发送 Buffer,如果 Buffer 慢了的话,这里会注册一个 Callback,然后返回一个 Future;Pull 的时候同理,也会根据逻辑通知 Future,然后如果没有数据,可能注册对应的 Callback
- 进程会有一个对应的
- 输入端的 Exchange 建立了下面的抽象,首先用户绑定的 Exchange 逻辑也需要继承
Exchange/ExchangeNode,Exchange会和下面的内容关联:- 上层会需要关联对应的 Split,Split 有两种,这里需要标识一个 Task
- 数据的 File Split,即
velox::connector::ConnectorSplit,从某个 DataSource / Connector 中捞取的 Split - 来自某个 Task 的 Split,即
velox::exec::RemoteConnectorSplit,表示一个运行的上游 Task
- 数据的 File Split,即
- Task 的每个 Pipeline 会有一个 ExchangeClient,在初始化的时候创建(
Task::createExchangeClientLocked)Pipeline 里面的所有 Driver 共享 ExchangeClient.MergeExchange比较特殊,强制 dop = 1,会自己创建 ExchangeClient。ExchangeClient实际上相当于(ExchangeQueue, Vec)的共享容器,而不是一个 Client。 Exchange初始化的时候,driverId == 0的第一个 task 会设置processSplits_ = true,这个 driver 的作业会开始处理所有的 Remote Split,最后收集出一组 TaskId (std::vector taskIds),这里会初始化所有的 Task,调用ExchangeClient::addRemoteTaskId,给每个(task, destination)目标创建一个ExchangeSource。ExchangeSource的创建是用户需要自己定义的逻辑,比如:https://github.com/prestodb/presto/blob/6f09c5703159f1e0e897f50d8ccb87731c4220b4/presto-native-execution/presto_cpp/main/PrestoExchangeSource.h#L31- 上层通过
ExchangeClient::next来拉取下游的 Split,这里通过ExchangeSource调用下游的 pull 请求,并通过ExchangeQueue来存储 Future/Promise,例:https://github.com/prestodb/presto/blob/db92976f0e438ee2b95872425d8a7b268a967187/presto-native-execution/presto_cpp/main/operators/BroadcastExchangeSource.cpp#L60
- 上层会需要关联对应的 Split,Split 有两种,这里需要标识一个 Task
Shuffle 的逻辑在 MapReduce 或者 Spark 论文中
我们有必要简单的介绍一下 Shuffle 是什么和 Shuffle 对应的逻辑。实际上有的地方在在代码里不一定直接有 Shuffle 这个类型,我们以 Velox / Presto 为例,对应的 Operator 有下面的逻辑:
LocalPartitionNode: 在单节点内对数据进行本地分区或合并,不涉及网络传输。输出算子。LocalMergeNode: Local 的 Merge,合并多个并发的子 Pipeline,不涉及网络传输。输入算子。PartitionedOutputNode: Shuffle 输出的 Node,将数据按分区键切分并输出,为后续的ExchangeNode提供分区的数据源。ExchangeNode: Exchange 读取 Shuffle 数据的节点,这里按照任意的(指定)顺序来合并MergeExchangeNode: 给 Merge Sort 之类用的合并有序数据的 Node,是ExchangeNode的子类。它需要单线程执行,dop 锁死 1。
https://facebookincubator.github.io/velox/develop/operators.html#local-exchange Local Exchange 的模式如下图
这里还有个比较特别的算子,和 Shuffle 没有一毛钱关系:TableWriteMergeNode, 这个是汇总多个 Operator 输出的时候聚合 Metadata 然后返回的。也比较有意思。不过和本文无关。
Velox 上层调用的代码可以参考 https://github.com/prestodb/presto/blob/99ea15b7d528b08f49ee559b4c29a518bb3daa3d/presto-native-execution/presto_cpp/main/operators/ShuffleRead.cpp#L27 ,它也封装了一个 ShuffleReaderOperator
Local
Local 用于切本地执行的时候一些并发度和 pipeline Task::createLocalExchangeQueuesLocked 创建本地的上下文,通过 LocalExchangeQueue 来同步。
值得一提的是,pr https://github.com/facebookincubator/velox/pull/11702 引入了 Scalable Writer。它在 Scan 也有类似的机制,比较好玩,就是 adaptive 的扩展并发空间。