高观点下的网络编程
「Linux多线程服务端编程」是毕业那会儿经常在网上刷到过推荐的书,当时本人还比较菜,入门了几次网络编程那套 API 都不是很成功。最近不知道为啥想回头看了,本来以为这本书是那种网络编程 api 推荐,但实际上像是一本「网络框架观点上的网络编程」,对于网络编程的 API,只是提到一部分,而且视作读者对其有着基本的了解(笔者开始看的时候只是依稀记得一些了),书的作者也提到他自己直接写裸的 Socket API 的地方并不多,这本书主要还是用上层视角介绍网络编程框架的基本视角,和在 Muduo 里面的对应实现。书里面有不少地方写的是成书时代(2013年)的硬件和 C++,看到书上硬件还在千兆网卡、没有async、也不讲 Kernel Bypass;C++ 的部分很多线程同步设施也是自己写的,然后花了很多部分介绍了 C++11 的 shared_ptr 怎么影响网络编程,这里部分同步设施还是很多是自己写的,虽然能看到一部分对 api 和资源的思考。
本书大概六百来页,还有一个 150页的切片 pdf。其实切片 PDF 那部分挺好的,很多地方不太啰嗦。剩下啰嗦的地方咱们可以仔细看看全书和代码。
本文的第三部分占的篇幅接近全书的 1/2,但很遗憾…就总有专门的书讲的更好,而且我大部分都看过。因此不浪费时间在上面了。
Part1: C++和多线程编程
shared_ptr 和 lifetime
这里第一节提到了生命周期管理,核心内容是 shared_ptr 和 weak_ptr,其实 bRPC 也有类似很多的部分,比如 https://github.com/apache/brpc/blob/master/docs/cn/bthread_id.md 和 https://github.com/apache/brpc/blob/master/docs/cn/io.md#socket 。这里问题其实比较清晰:
- 构造时期的安全性相对比较好保证(想起
shared_ptr,在构造的时候甚至是可以预期「外部在资源传递的时候已经同步过」),核心语义是构造的时候不要构造期泄漏 this。- 如果需要瞎搞一些逻辑的话(比如把 this 注册到一些列表中),或许可以考虑不那么 C++ 的二段式构造(
initialize())
- 如果需要瞎搞一些逻辑的话(比如把 this 注册到一些列表中),或许可以考虑不那么 C++ 的二段式构造(
- 析构的时候,自身的析构无论如何不能只靠指向自己的 raw pointer 来判断
(2) 某种程度上便指向了 shared_ptr 和 weak_ptr.
本节也讨论了 shared_ptr 的线程安全,但我觉得讲的不太好,我觉得最简短但又能让我印象深刻的回答应该是「 shared_ptr 的线程安全和 std::string 差不多」。
这里额外提了一些:
shared_ptr提到可能可以自己定义 dtor,但我没用到过这个功能- 可以丢给一个别的地方去 dtor,比如塞到 blocking queue
多线程服务器
线程相对 50 年历史的 Unix 还是相对年轻的(据书中说是 1993 年后才慢慢流行起来),这个新的概念也给很多老的系统(比如各种不安全的调用)带来了很多问题。时至今日,还有 PG 这样绑在多进程下的战车。这一节讨论了一些模型(但我觉得讲的并不细),写作稍微有点混乱
- 单线程服务器可以实现 Proactor 或者 Reactor 模式
- 很多 syscall 都能用 non-blocking 的方式批量处理;但坏处是对一些复杂不确定的长尾效果很不好,而且整个链路上请求都需要是 non-blocking 的
- 多线程服务器的模式
- One loop ( Reactor ) Per Thread: Usually a good start. 如果不涉及内部通信的话,同步开销小
- Io 任务少, 计算多: 或许可以分发给多线程的 io 线程,或许也可以参考 https://github.com/apache/brpc/blob/master/docs/cn/execution_queue.md
- 进程间通信只用 TCP: 作者认为这个好处是只有一套模型 + 能复用工具。其实我大致知道什么意思,但没有完全 Get 到点
- 分布式系统使用 TCP 长连接: 感觉也是 TCP 熟练用者的想法,
netstat快速定位对应端口和相关的Recv-Q/Send-Q,希望在一般服务中Send-Q和Recv-Q来定位服务状况
这里作者还提到了
在进入下一节介绍之前,笔者可以顺手推荐一下 brpc 在这方面的思考:https://github.com/apache/brpc/blob/master/docs/cn/benchmark.md#%E6%B5%8B%E8%AF%95%E6%96%B9%E6%B3%95
多线程付出这么大的代价是为了隔离请求间的影响。一个计算复杂或索性阻塞的过程不会影响到其他请求,1%的长尾最终只会影响到1%的性能。而多个独立的线程是保证不了这点的,一个请求进入了一个线程就等于“定了终生”,如果前面的请求慢了一下,那也只能跟着慢了。1%的长尾会影响远超1%的请求,最终表现不佳。换句话说,乍看上去多线程模型“慢”了,但在真实应用中反而会获得更好的综合性能。
Mutex 等设施
这节我扫了一遍,没啥看的必要,随手列几个可以随便答的点:
pthread_cancel和 thread cancel 之类的,虽然埋了一些调度点,但是大部分时候并不能够算上靠谱的同步设施(我个人觉得或许定义stop_token是个说得过去的行为)- 谨慎对待 rwlock 和信号量
- Rwlock 的部分 paul 的 perfbook 讲了不少
- 信号量或许可以看看一些好的 practice
fork能够fork的资源和多线程可能会打架,虽然这部分 fork 获取的一部分资源种类能被比较好的定义- 线程安全的单例: 2024 了,once 之类的东西早八百年进标准了
sleep(3)不是同步原语- 不过我个人看,其实很多基于「足够长的时间」的操作在分布式系统里面也是会用到的,比如定义一个「足够长的时间」没收到信息就 suicide,然后在管控节点给出一个更长不少的时间作为保证,来很粗糙的避免脑裂,虽然不是一个那么那么完美又规范的行为,不过感觉 work 是能 work 的?
exit(3)需要注意全局安全- exit(3) 的文档 ( ) 提到 exit 的线程安全标志是
The exit() function uses a global variable that is not protected, so it is not thread-safe.所以不是线程安全的。
- exit(3) 的文档 ( ) 提到 exit 的线程安全标志是
shared_ptr实现 CoW: 基操__thread_local对象比较重要,但也要注意线程数量和开销(题外话,感觉这个在 io 或者全局资源固定的情况下是个好东西,但是很多时候也要看用户 io 资源的管理,线程数不多的、动态创建少时候,对 threadlocal 利用是更充分的)
高效的多线程日志
这节基本上讲的还是日志系统,感觉每个项目都有,因为太熟了所以看着感觉没啥…基本上就大概是:
- Logger 的 Stream 模式或者 macro/function 模式
- Logger 的一些工具(比如日志采集、压缩之类的)不应该由 Logger Client 提供,最好由一些脚本提供,Rotate 之类的功能则不一样
- Async Logger 的基本实现
我用 spdlog: https://github.com/gabime/spdlog . 不懂捏
IO, 线程和模型
网络编程本质论
作者认为,网络编程本质论主要在处理三个半事件:
- 连接建立: 包含 server
accept和 clientconnect, TCP 是全双工协议- Client: 发起连接被拒绝后,如何 back-off 重试
- 连接断开: 包括主动的
closeshutdown和被动断开 (read(2)返回0)- 如果应用层有缓冲,需要在请求关闭之前发送应用层的缓冲
- 消息到达,文件描述符可读: 比较重要,决定了网络编程的风格是:
- 阻塞还是非阻塞
- 非阻塞应该 Edge Trigger 还是 Level Trigger? 这几个怎么衡量性能
- 如何分包
- 这里也要求了一部分的缓存实现。一方面这里来了数据,如果频繁 syscall 的话,性能也不一定高,所以缓冲区准备大一点可能好,但是另一方面,缓冲区过大可能利用率也会比较低
- 应用层如何设计缓存
- 阻塞还是非阻塞
- 消息交付: 交给框架或者 os 层的缓冲区
- 本质上非阻塞网络对 Buffer 提供了一定的要求,网络库可以一定程度上缓存用户写入,同时做顺序保证。但这个这个也要考虑数据堆积的处理
下面这张表是灌水用的,其实可以结合 brpc 那边和自己的想法来思考。有几个点:
- 对于 IO 来说,某种程度上,“IO 复用”其实复 用的不是 IO 连接,而是复用线程。使用 select/poll 几乎肯定要配合 non-blocking IO, 而使用 non-blocking IO 肯定要使用应用层 buffer
- 这里核心原因是,IO Multiplexing 你 busy loop 总不好吧;然后面对 IO 你不能卡住整个线程吧
Connection需要有 Output buffer,来防止 block 在 output,同时管理好输出的状态Connection需要有 input buffer,处理不同协议的 input handling ( 比如切分不同格式的输入)
- 程序按情况可能要发挥多核的性能去 scale,这种有的是连接、IO上的,有的是 CPU 等资源上的
- 下图方案9中,有一个线程接收连接,然后把请求分配给绑定为 CPU 数,有一个 main Reactor 负责 accept(2) 连接,然后把 连接挂在某个 sub Reactor 中(muduo 采用 round-robin 的方式来选择 sub Reactor), 这样该连接的所有操作都在那个 sub Reactor 所处的线程中完成。
- 线程池和 Ordering 之类的需要协调清楚,比如一个线程的资源给多个地方计算的话,需要协调好顺序(P.S. 我感觉在 brpc 这种地方就不会管你这块了,让用户层直接自己处理 bthread 或者用线程池。这里还提到了一个 io 固定 pin 一个计算或者别的线程的方式,感觉特定负载下算是有意义的方案吧)
- 线程池也可以执行阻塞操作,难以想象卡死
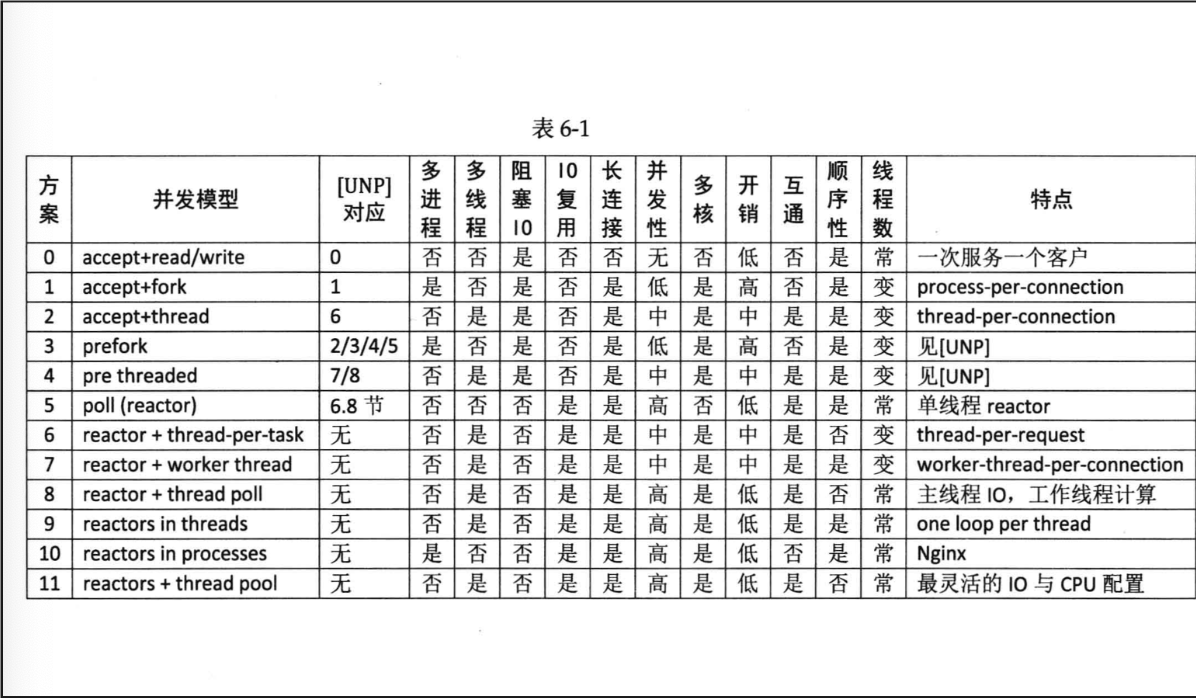
模型9如下图 Figure 所示
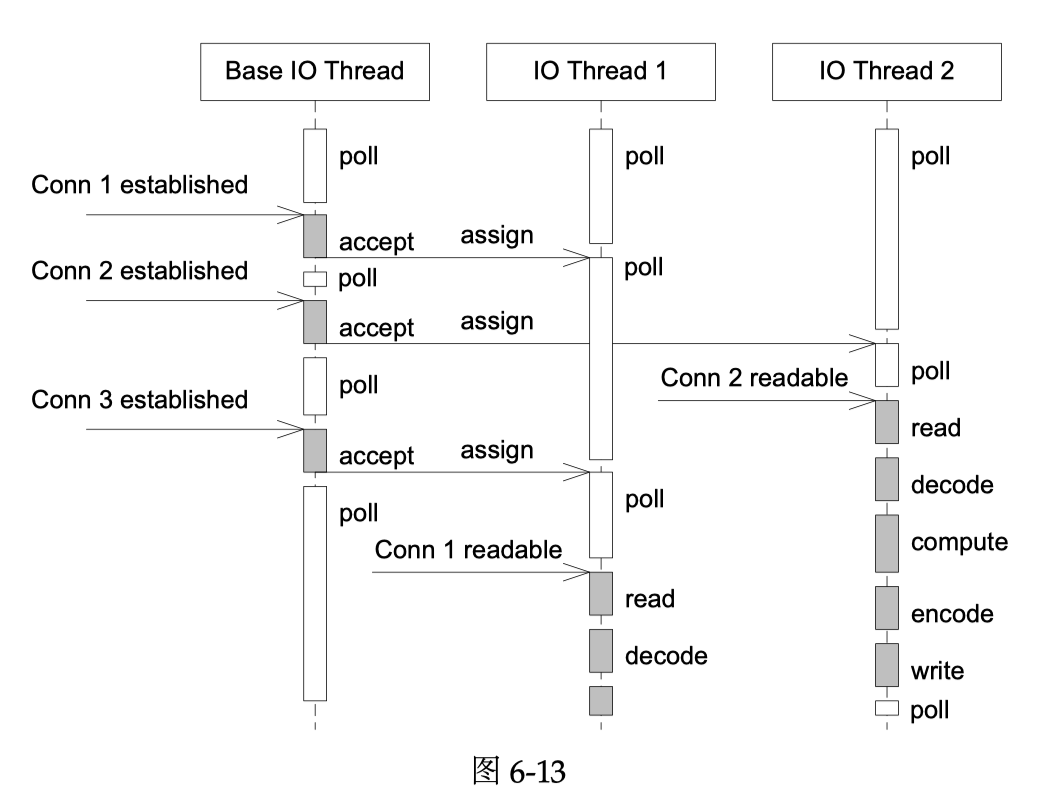
Muduo 感觉也是支持了 (9) 这样的模式,然后为别的模式提供了设施。需要知道的是,本身 EventLoop ( Reactor ) 的线程数量本身也和负载之类的有关,所以相当于提供了支持别的模式(比如分发给别的线程)的相关的扩展。
有用的工具
关于解析消息,或许需要一套公共的 Message / Codec (反正叫什么都好)的类型,然后处理到来的消息,然后也处理消息没有完全 Ready 时候的状况
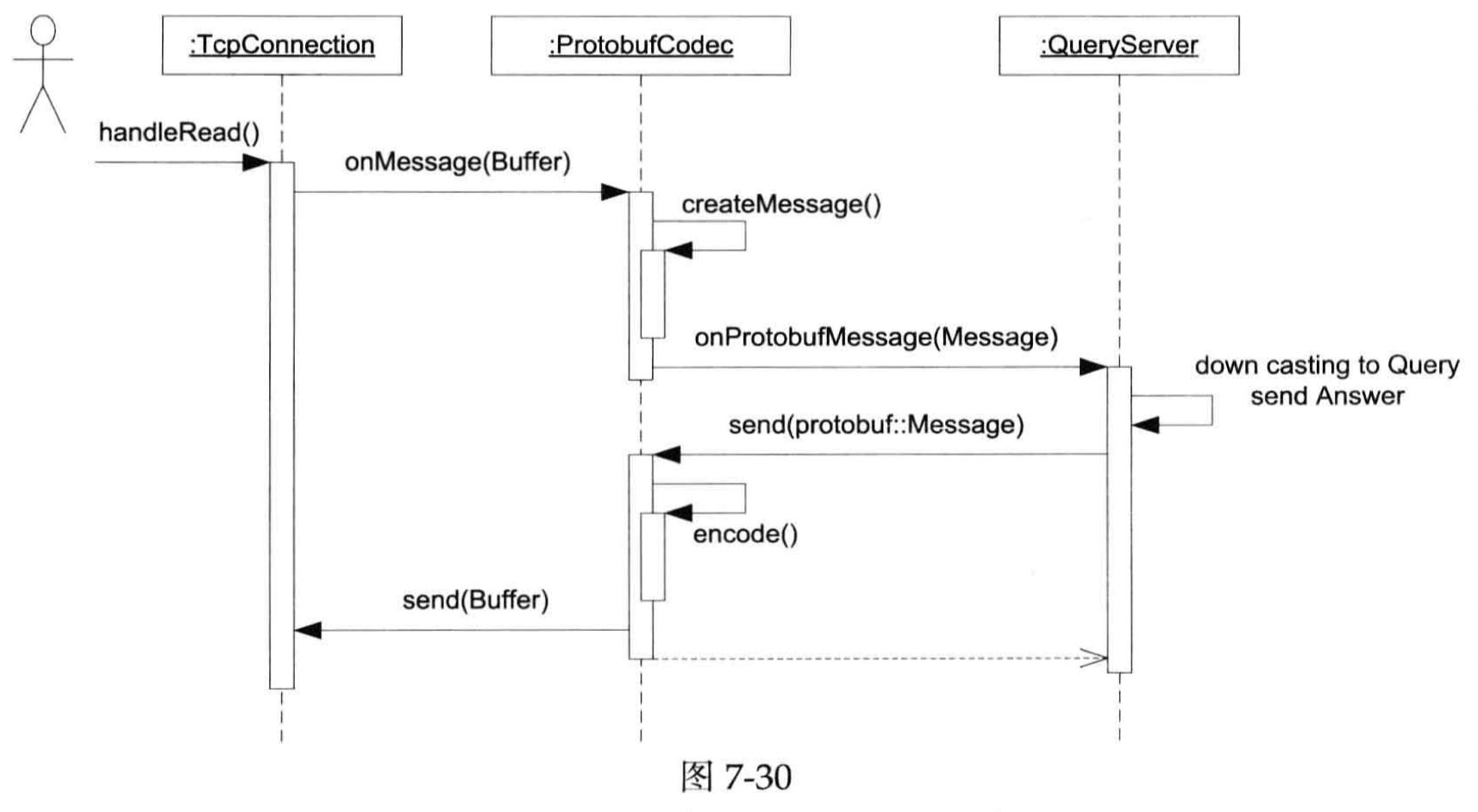
这里又增加了一层中间层,就是按照类型去 Dispatch,不过你知道吗,我感觉看完这块,最大的感觉是「静态语言搞这块真麻烦」。具体而言,在类型的分发上,这里大部分市县还是靠 registerHandler的方案(有点像我们 Arrow / Velox 注册函数?)
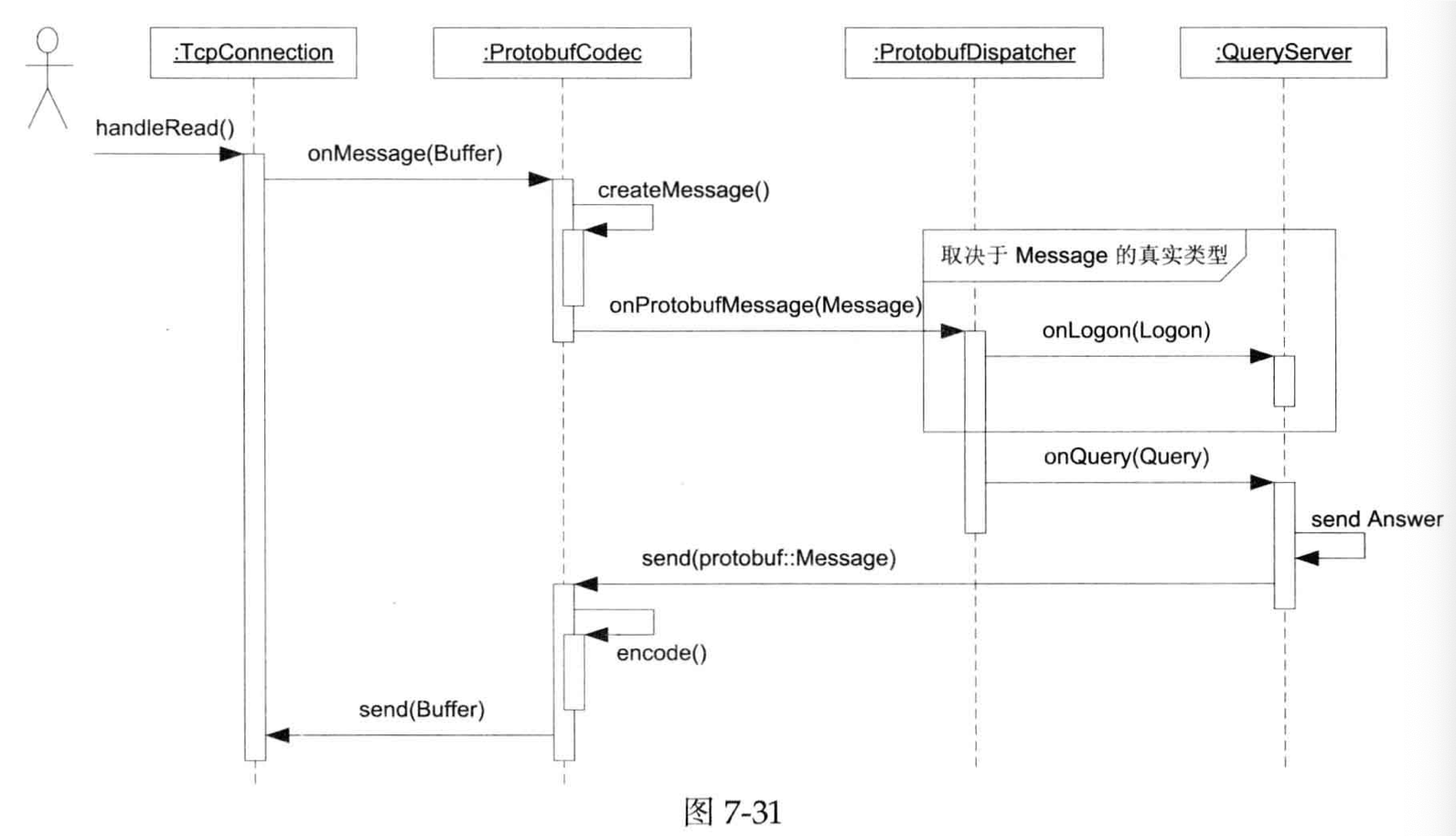
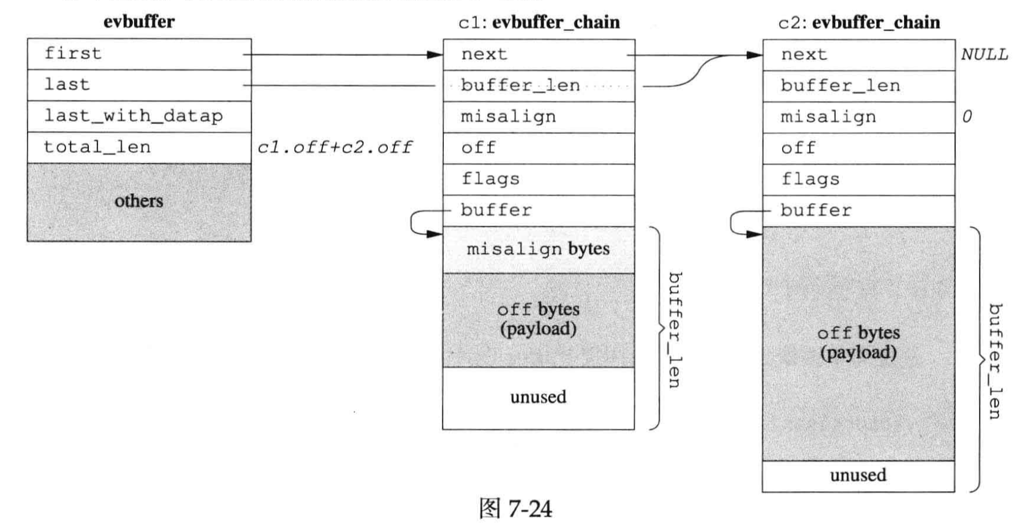
此外,我们刚刚论述了 Buffer 的必要性,下面是 Buffer 的设计。需要说明的是,下图似乎是 libevent 的 zero-copy 设计。这里要考虑 Buffer 需要控制读写:
- 有一端在写入数据
- 另一端在消费数据
此外这里也可以考虑 Thread Local 等优化(在线程资源相对固定的情况下)。
这里还提到了限制并发数,作者聊到了 fd 耗尽时,accept(2) 的麻烦 (本质上类似 oom,处理这块也是需要资源开销的),然后说可以设置 soft-limit 和 hard-limit,然后到了 soft limit 就开始处理。并通过这个例子,介绍了限制 fd 数量/并发数的必要性(有趣,我以前从没碰到过这个问题)(仔细想想总觉得这个可以在 rpc framework 的地方做到框架里?)
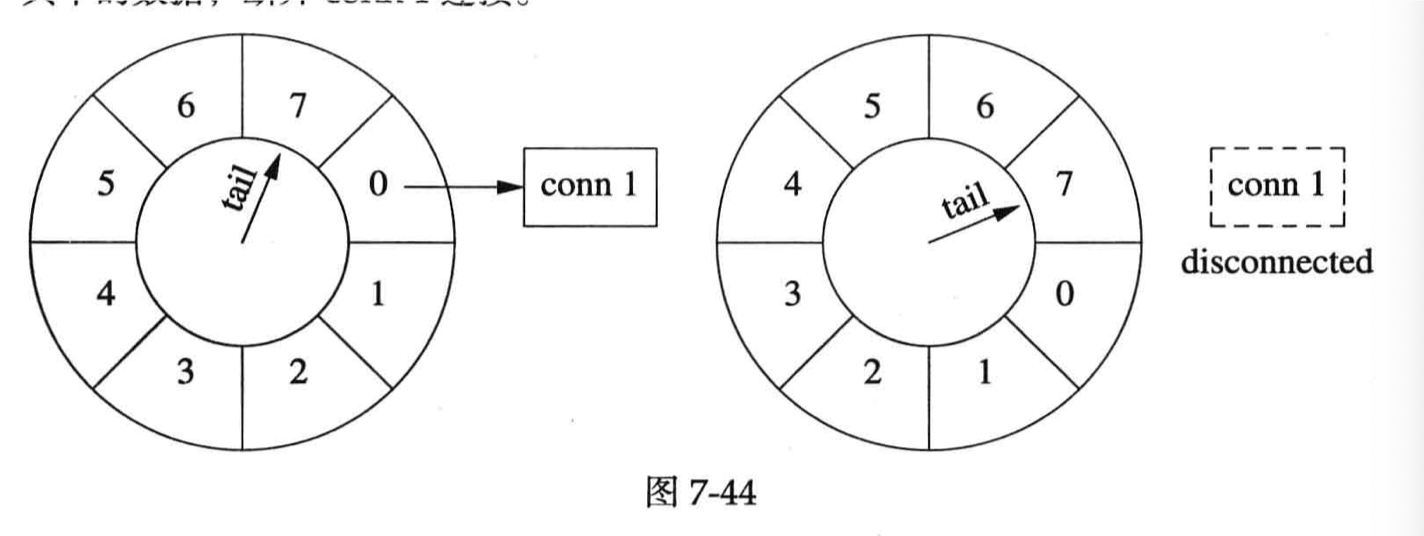
这里还介绍了定时器和时间,陈硕有个别的文章介绍计算机中的时间,见:https://www.cnblogs.com/Solstice/archive/2010/08/15/1800275.html ,在网上找的时候也看到一篇很好的博客,见:https://gu.ink/2022/date-and-time-in-computer/index.html 。这里也介绍了非阻塞定时器时系统里需要的,和对应的实现(我现在感觉,这是不是本质上是一套用户态 Scheduler)。这里还写了个很蹩脚(?)的例子,用 Timing Wheel 踢走不活跃的连接。作者为了找补补充了一句,意思是成熟的应用应该自己设计 Keep Alive 机制,我倒是觉得很有道理。timing wheel 我找了下,Kafka 里面经常用,感觉本质上是一种类似 Clock 算法的批量处理方式,找了个博客:一张图理解Kafka时间轮(TimingWheel) - https://zhuanlan.zhihu.com/p/121483218
第三章:杂谈
感觉都是废话。