Tournament Trees
如之前 Sort 的文章 [1] 所述,Tournament Tree 核心是减少 Winner 流切换的比较次数。本文不对败者树做概论,而是看一下工程实现。DuckDB 靠 Merge Path 算法来实现 Sort,而 DataFusion 和 Velox 都实现了败者树的接口。ClickHouse 也实现了一个 Queue 相关的接口,但并没有使用 Loser Tree
ClickHouse 的实现
代码在 [2],算是写文章这天的 Master。这里的核心是:
- 实现是一个标准的 Heap,而不是我们的败者树。
- Element 被抽象为
Cursor,然后 Cursor 一些接口满足了 STL 的定义,可以利用std::make_heap等接口。这样也没有中间节点了。 - 当
Cursor消费完的时候,从 Queue 中直接移除 - 按照标准的 Heap 算法调整堆
- 额外实现了一种 Batch 模式,在 batch 模式下,堆也会被 batch 处理
- 因为是 Heap,所以可以通过比较快速拿到第二大的流
- 定位到 最大的流 - 第二大的流 中的 batchSize
- 根据这个 BatchSize 来 Hint 用户的 nextBatch
具体的 next 靠 Cursor 来实现
ClickHouse 实现的亮点是 C++ 上很细的工程实现,比如这段代码:https://github.com/ClickHouse/ClickHouse/blob/6f88ada7a9b4aacaaa6c86e5341aecedeeb291f5/src/Core/SortCursor.h#L675 ,感觉这种特化肯定是比 Comparable Key 有前途的。不过这也是大家都可以做的优化。
Velox 的实现
Velox 实现了一个标准的 TreeOfLosers 接口,这套接口有下面的成员:
这里没有 next 的实现,其实是大家各显神通了,使用 MergeStream 其实也是 CRTP 的形式,令人唏嘘。
1 | /// Abstract class defining the interface for a stream of values to be merged by |
这里有两种实现:
MergeArray: 第一次构建的时候 Sort 所有序列,然后每次next()之后,把第一个元素调整位置。有点像简陋版的堆TreeOfLosers: 败者树
这两套接口的特征是:
- 都是以
Sorter的形式提供的 next返回MergeStreamImpl*, 然后下次next的时候做内部调整再返回
比较有意思的是,和 ClickHouse 的 Batch 模式类似,Velox 的 TreeOfLosers 提供了两套接口:
1 | /// Returns the stream with the lowest first element and a flag that is true |
内部实现逻辑
1 | class TreeOfLosers { |
这里的结构其实是一个逻辑的树结构:
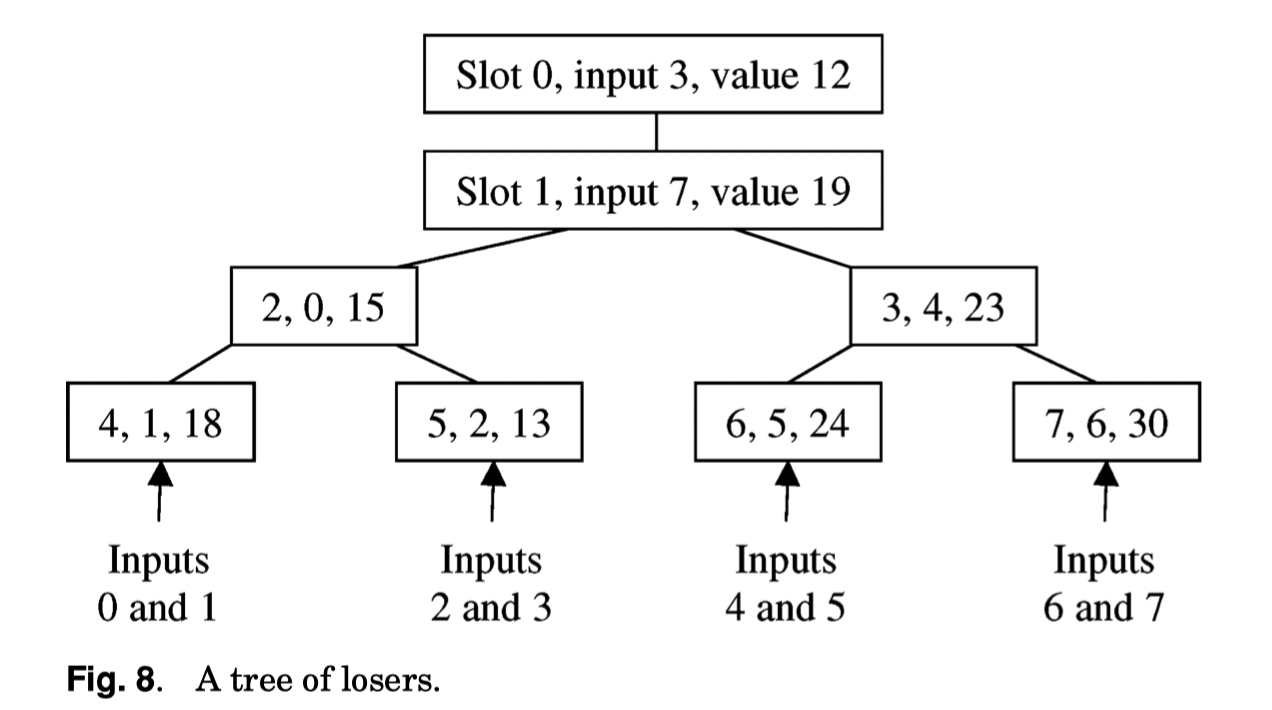
streams_是下游的inputs, 固定,即使 Stream 被消费完了,依旧存在于LoserOfTrees中 (但是values_标记为kEmpty)values_和equals_是核心,这里的树结构如上图:0的位置在 Velox 的实现中并不存在,取而代之的是特殊成员lastIndex_, 指向streams_,表示第一条流values_和equals_的 size 是firstStream_. 这句话有点抽象,举例来说,上图 Fig8 里面的 Inputs 是Stream,Stream不会出现在values_中。如果Stream大小不是 2 的倍数,那么树的形状就会和下面 ascii 图一样. 在这里,1有两个成员,3,4 有两个成员,这是 6个 stream 的TreeOfLosers.firstStream_在树中的逻辑位置是 5(虽然实际上values_中没有这个成员); 同样的,如果有一个 stream 有 4条流,那么firstStream_就是 3- 流里面所有
values_被初始化为kEmpty,lastIndex_也被初始化为kEmpty
- 流比较的时候,如果是 Equal 系接口,调用
compare;否则直接拿operator< - 第一次调用的时候 (即
lastIndex_ = kEmpty的时候),递归的 build 整个树的 equals 和 values - 后续从
lastIndex_向上propagate - 边界处理:空流对外返回
kEmpty做为 Index。values_中的内容也是 Index。当整棵树都为kEmpty的时候,树被消费完成,对外返回nullptr做为next的结果
1 | 0 |
外部用例
GroupingSet 是一个这个的 user-case, 存放 Spill 的结果,这里会按照行来消费。我也不知道为啥没有 Batch 消费的实现。
Datafusion
这里实现和 Velox 大致相同,目前 Datafusion 使用 SortPreservingMergeStream 来处理 Loser Tree
它的基础成员是 PartitionedStream:
1 | /// A [`Stream`](futures::Stream) that has multiple partitions that can |
读者们可以看出这是个 Async 的玩意。它生成的成员被当作 CursorValues:
1 | /// A fallible [`PartitionedStream`] of [`Cursor`] and [`RecordBatch`] |
此外,这里还有 Cursor 的抽象,做为「单一的 Comparable 成员」,是 CursorValues 中某个 Index 的引用。
1 |
|
在 SortPreservingMergeStream 中,生成的目标会是 Batch,以 BatchBuilder 做为成员,在内部完成 BuildBatch,而 Velox 则是把 Stream* 传给外部,便于直接给 RowContainer 之类的 Build Row。
我们只关注这里面 Async 的部分,逻辑层和 Velox 几乎没有区别,我们就不赘述了
Async 的处理
1 |
|
如上所述,PartitionedStream 是异步的。这里会记录 Stream 的 async 信息,然后放到 uninitiated_partitions 中,来做初始化队列。这部分只会在初始化的时候使用
在后续读取中,只有 Winner Cursor 会被消费,所以只有 Winner 需要被 check async。
Oceanbase
https://github.com/oceanbase/oceanbase/blob/develop/deps/oblib/src/lib/container/ob_loser_tree.h#L54
OceanBase 的 Tree 看着像 winner-loser 混合,它的结构相比 Velox,记录的东西稍微多一些 ( is_draw 等价于 equal ):
这里同时记录了 winner 和 loser 和 replay。这里似乎是因为这个 LoserTree 是动态的,在 push 加入 Player 的时候,这部分能够快速调整 Loser Tree 的信息。当成员变更的时候,ob 得以快速 replay
1 | struct MatchResult |