Sorting in Database System: Part1
Sorting 在 F1/Napa 很多地方都有用,这里看到实际存在的例子是非常多的:
- Index Creation, Index Maintenance, Index lookup
- Sort-Key 可能多于一组,有一部分有一些自己的 ordering
这里面,F1 Napa 的场景按照他们论文看,可能会有很多预排序或者部分有序的数据,这些数据可能有一些局部的 Interesting Order 性质。在这里面,排序的时候能感知这些性质就变得格外重要了,这些性质在 sorted stream 合并、Agg、Partition 等地方也有很大作用。总的来说,这篇论文可以当作 F1/Napa sort 优化的一个基础部分。
这里在早期,Graefe Goetz 在微软的时候就写了 Implementing Sorting in Database Systems,从后面来看,这里整块的优化思路实际上没有发生太多变化。在后面的论文中,直接看 G.G 的 OVC 会很困惑(我盯着论文看了一小时,感觉人要死了,他写的词特别晦涩),在这篇文章中,反而很通畅的介绍了 ovc 和 sort 的由来。可以看到 arrow-rs,duckdb 的 sorting 和这块基本上是能对应上的,对排序的 techniques 介绍非常的全面、具体。
排序是计算机非常古老的技术,一般可能大学就会学快排在哪的多种排序。G.G. 对数据库排序的观点是「Many of these techniques are public knowledge, but not widely known」。DB里面排序的主要需求还是:
- 可能会涉及多列、Orders、Nulls(first) 等语义
- 服务于 Index Creation, Index Maintenance, Index lookup, MV等维护语义;duplicate removal, verifying uniqueness, rank and top operations, grouping, roll-up 和 cube 等查询语义和 merge-join 算法;还包括一些软硬内容的维护,比如 unique-check。这里也能优化 non-cluster index 的 fetching (真的吗,数据量这么大?)
- 帮助 Log Recovery
这篇分为三节:
- in-memory sorting
- 介绍 DB 场景中对内存排序的优化,包括 Normalized Key 和生成策略、OVC 等手段
- External Sorting
- 如何减少 io 或者优雅的降级,和归并排序的优化等
- 数据库相关的排序特定优化
我们最后来再次介绍一下需求,来自 Gemini 翻译
假定的数据库环境是一个典型的关系型数据库。记录由多个字段组成,每个字段都有自己的类型和长度。有些字段是固定长度的,有些是可变长度的。排序键包括记录中的一些字段,但不一定是起始字段。它可能包括所有字段,但通常不这样。内存相当大,但通常不足以容纳整个输入。CPU速度很快,在某种程度上是通过使用缓存来实现的,而且磁盘驱动器的数量多于CPU。为了简洁或清晰起见,在某些地方假定了升序排序,但对降序排序或多属性混合排序的适应相当简单,不再进一步讨论。同样,排序算法的“稳定性”也被忽略,也就是说,不保证具有相同键的输入记录在输出中出现的顺序与输入中的顺序相同,因为任何排序算法都可以通过在输入中的每个键后面附加一个“排名”数字来使其稳定。
INTERNAL SORT: AVOIDING AND SPEEDING COMPARISONS
鉴于这部分内容很重要,作者介绍了一下自己写这块的心路历程:
- 一开始目标是降低比较次数(就像教科书上的排序一样)
- 后来作者发现,工程上 Offset-Value Coding 能很好的抓住数据 Row-Format Prefix Truncation 性质和 Column Format RLE 的性质. 这里也提供了一些 Native Execution 的方法
这里有几个点:
- normalized keys (which speed comparisons)
- order-preserving compression (which shortens keys, including those stretched by normalization)
- cache-optimized techniques
- algorithms and data structures for replacement selection and priority queues.
Distribution Sort
经典基数排序,我就不手动概括了,摇 gemini:
- 优点:
- 减少流水线停滞:避免了比较操作带来的分支预测失败。
- 减少缓存缺失:数据访问模式可能对缓存更友好。
- 缺点:
- 多趟扫描:如果键很长且存在重复键,可能需要多次扫描数据,影响效率。
- 数据分布假设:基数排序在数据值均匀分布时最有效,而实际数据可能并非如此。
- 近似有序输入:如果输入记录接近有序,基数排序的初始传递效率会很低。
- 短运行:缓存效率可能需要非常小的运行,而基数排序在这种情况下优势不明显。
结论
尽管分布式排序有潜在的优势,但由于上述缺点,它尚未在数据库系统中取代基于比较的排序。然而,一种有前景的方法是在使用基于比较的排序之前,先进行一轮或几轮分区,以减少后续比较次数。
Normalized Keys
这里核心是指出,排序最要优化的重点是什么:
The cost of in-memory sorting is dominated by two operations: key comparisons (or other inspections of the keys, e.g., in radix sort) and data movement.
The former issue can be quite complex due to multiple columns within each key, each with its own type, length, collating sequence (e.g., case-insensitive German), sort direction (ascending or descending), etc.
Given that each record participates in many comparisons, it seems worthwhile to reformat each record both before and after sorting if the alternative format speeds-up the multiple operations in between. For example, when sorting a million records, each record will participate in more than 20 comparisons, and we can spend as many as 20 instructions to encode and decode each record for each instruction saved in a comparison. Note that each comparison might require hundreds of instructions if multiple columns, as well as their types, lengths, precision, and sort order must be considered. International strings and collation sequences can increase the cost per comparison by an order of magnitude.
The format that is most advantageous for fast comparisons is a simple binary string such that the transformation is both order-preserving and lossless. In other words, the entire complexity of key comparisons can be reduced to comparing binary strings, and the sorted output records can be recovered from the binary string.
这段大意是,本质上排序考虑 pointer, record 组织之类的都比较复杂,还有 offset 之类的,所以可能会处理成 Normalized Key(我看大部分实现都是这么做的). 在 DuckDB 的文章中也提到了这一点 [3]
关于这块的编码,有几个例子:
- Arrow-rs: https://github.com/apache/arrow-rs/blob/master/arrow-row/src/lib.rs#L147 [1]
- Velox Row-Container https://github.com/facebookincubator/velox/blob/db8875c425e8132f553adf12e106cd2e28a811c0/velox/exec/RowContainer.cpp#L133 [2]
编码这块真一大堆了,不过先提前说一点,如果某列不是排序列,那么其实是不需要考虑 order-preseving 编码的(我觉得 arrow-rs 这点搞的一般?)。我最早认识这个格式还是在 TiDB Key 和 MyRocks 的 Key
- Descending sorts simply invert all bits. NULL values, as defined in SQL, are encoded by a single 0-bit if NULL values sort low. Note that a leading 1-bit must be added to non-NULL values of fields that may be NULL in some records.
- For an unsigned integer in binary format, the value itself is the encoding after reversing the byte order for high-endian integers.
- For signed integers in the usual B-1 complement, the first (sign) bit must be inverted
- Floating-point numbers are encoded using first their overall (inverted) sign bit, then the exponent as a signed integer, and finally, the fractional value. The latter two components are placed in descending order if the overall sign bit is negative.
- 变长字符串应该是最复杂的一节,处理国际字符的字符串归一化是一个复杂的问题,但现代操作系统和编程库提供的内置函数可以帮助解决这个问题。虽然归一化结果可能变长,但它们通常具有良好的可压缩性。对于变长字符串,需要特殊处理终止符以确保排序正确。在论文提出了32B一个控制字符,然后 TiDB 我印象中好像是 8B ( https://github.com/pingcap/tidb/blob/v8.4.0-alpha/pkg/util/codec/bytes.go#L35 ), TiDB 也给了个 Collator 处理 collaction 问题:https://github.com/pingcap/tidb/blob/v8.4.0-alpha/pkg/util/collate/collate.go#L66

在这里,这部分可能会让 Key 大小变大,但作者也说,这些 Normalized Key 其实相对来说也会比较好压缩。其实问题可控。
Order-Preserving Compression
在 Normalized Key 的情况下,接下来可能要压缩它的大小,并保证有序性,来保证压缩的空间和带宽。
Huffman, Dictionary Etc
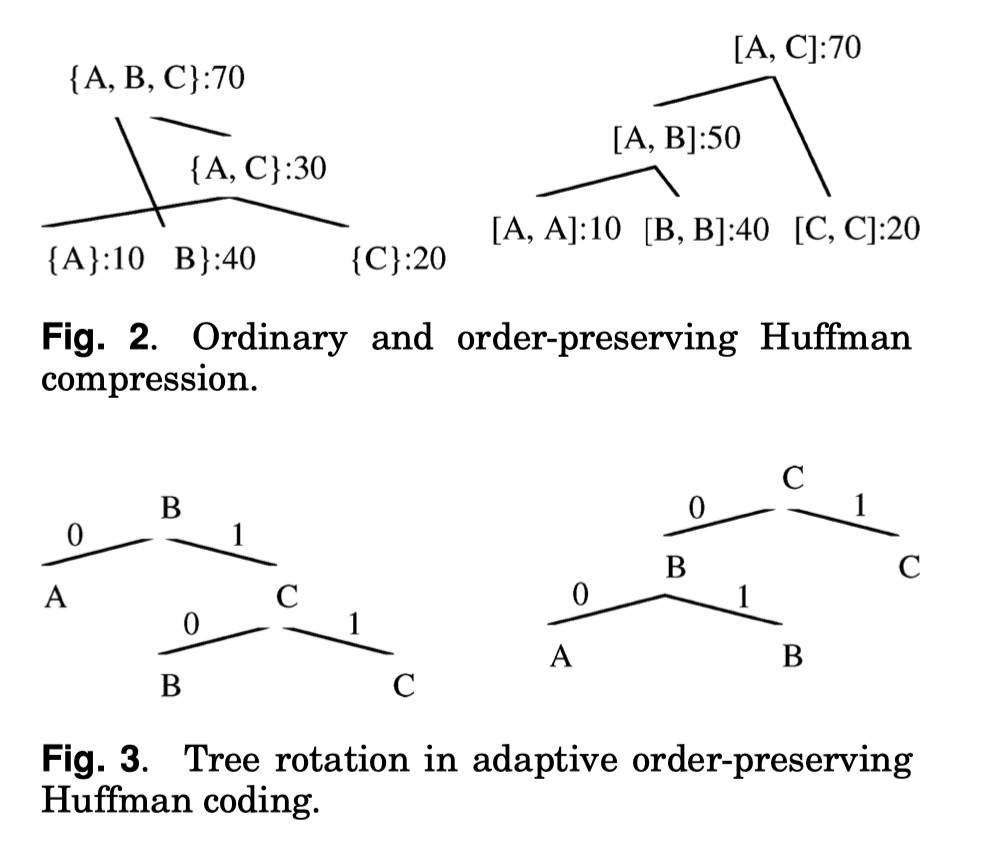
核心:Order-preserving Huffman code can only combine an immediate neighbor. Fig2 描述了这一过程,在 alphabet 里面合并多个单词
当然这要求一个全局静态的处理方式,实际上对于动态插入的方法,这里是插入的时候先分配一个 id,然后向下插入的时候根据 freq 来调整。
Huffman 编码的 decode 可能要包括这个字典(树)。
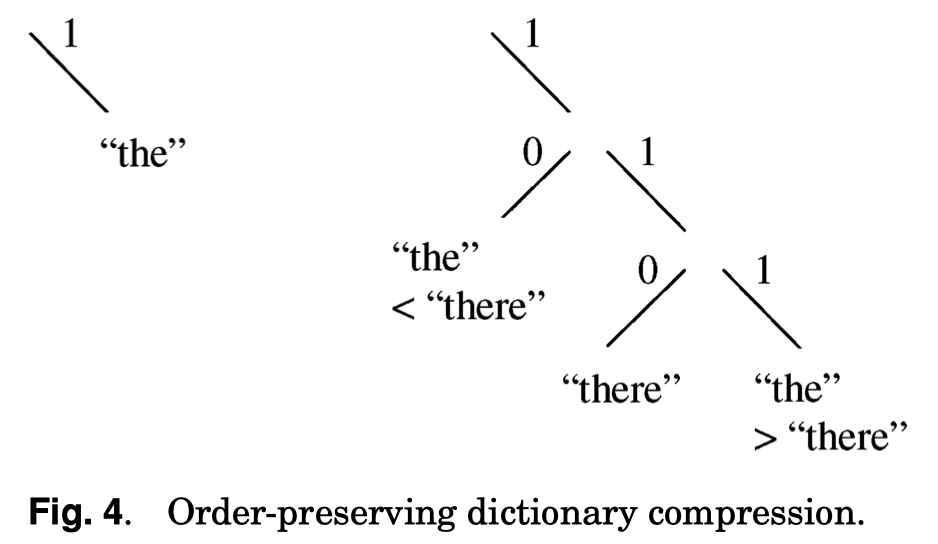
当用 RLE/Dictionary 的时候,必须考虑被替换字符串后面的符号。这是因为在有序压缩中,不仅要压缩数据,还要确保压缩后的数据能够按照原始顺序排序。 arrow-rs 使用了一个类似这节的策略。
When a new string is inserted into the dictionary, the longest preexisting prefix of a new string must be assigned two encodings, rather than only one [Antoshenkov et al. 1996].
假设字典中已经有字符串 “the”,现在要插入新字符串 “there”。此时,”the” 需要被分配两个编码:
- 一个用于后面跟着小于 “re” 的字符串的 “the”(比如 “then”)
- 一个用于后面跟着大于 “re” 的字符串的 “the”(比如 “they”)
这样,”then”、”there” 和 “they” 就可以基于这些编码正确排序。
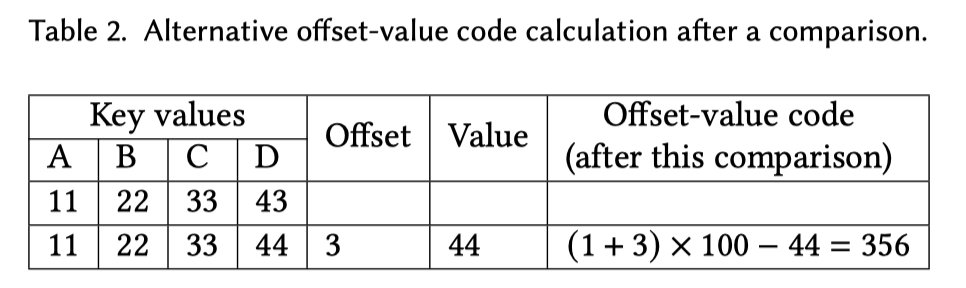
Arrow-rs Row 采用了这个一个变体: https://arrow.apache.org/blog/2022/11/07/multi-column-sorts-in-arrow-rust-part-2/ 见 Dictionary 一节,大概是用一个 trie 来维护这块。论文后面提到,类似 Dynamic Haffman 的 Rotation 也能对这块实现有帮助(我在想是否要维护一个前瞻窗口来着,总觉得怪怪的)。
论文提到一个非常非常有意思的地方,就是字典编码实际上可以和正常编码结合,比如存放:
- Null, 默认值, String 编码中一些特定 Terminator 模式
- 预训练常见词、高频字字典
这个很好理解,但是读起来感觉效果会非常好。
还有的优化是对整数特定的,比如下面的策略类似 variant,大多数值可以用较少位数表示的特点,对不同范围的值采用不同长度的编码。variant 前面是一位,这里可能抽取多位来表示每位对应的含义,比如 Fig5 中
- “00”:表示 NULL 值
- “01”:表示小于 -128 的八字节整数
- “10”:表示单字节整数(可正可负)
- “11”:表示大于 127 的八字节正整数
本质上,使用这种编码要求了解数据分布,有一些分布的先验知识。

Poolman’s key and Offset-Value code
Key Truncation 是一种 comparing 的思路,我们其实可以看到 Arrow [6], Umbra[7] 和 Velox[8] 里面都有一个短字符串:对一个长字符串,抽取前面的数据作为一个 Prefix Truncation 的摘要,这种操作被称为 Poolman’s key。这种摘要本身是「静态」的,它们的比较在 CPU 上可以做得很快(因为本身定长,指令确定),但对于 (1) 长字符串或者 (2) 多列中前面几列都相等的来说,等价于多了一层劣化。
OVC 是一种比较有意思的方式,它是:
- 基于和前一条记录的比较定义,对于最大(最小)的记录,前一条可以当成一条特殊的空记录
- 定义 Offset-Value Code 为
- 本质上,Offset Value Code 是一种 Poolman’s Key,但不是静态的,而是和前一条记录比较产生的,这样相当于「缓存了上一次比较的结果」,在 Merge Sort 和 Loser-Tree (这两个之后都会讲)中,能够进行不错的工程优化。之所以是 Poolman’s key,是因为有可能两条记录和同一条记录产生的 OVC 是相同的(比如 “abc” 和 “acc”, “acd” 产生的 ovc 可能都一样,指向
(2, "c")
下面是别的论文里面 OVC 的一个例子,对于 bytes 来说,domain 可以是 0-255,这里只是一个例子,这个例子把 100 当作 Domain;另一个例子里介绍了一些详细(也很粗略)的计算:
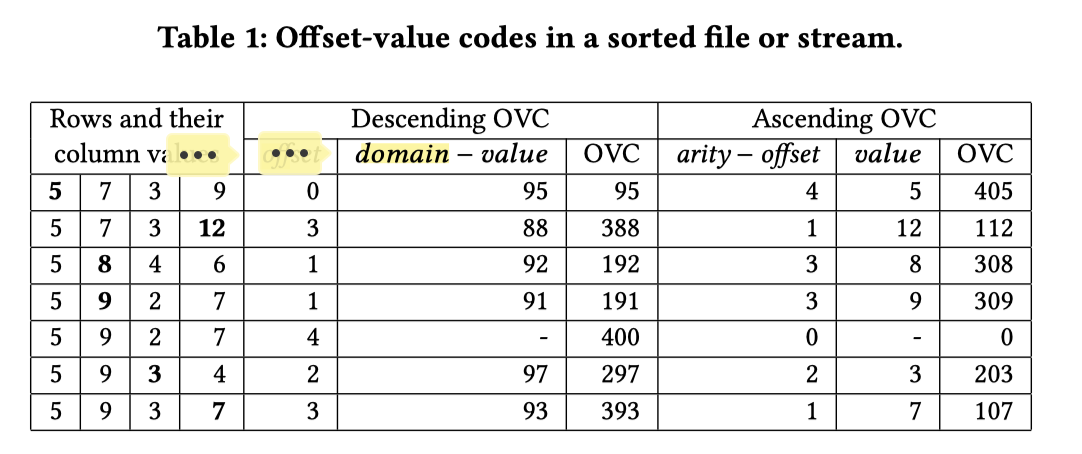
下面展示了 OVC 在 Merge 上的威力,这里尝试 merge 两条流到第三条。在这里(我怀疑上面 arity 只是个上限,卓或者可以当作 idx 的 big-endian 或者 sortable 化):
- “abc” 和 “aaa” ovc 都一样,真人快打之后 aaa 胜出,右边流的 ovc 保留,abc 变为
(254, b) - 两个
(254, b)大战,abc 输给 aba,变成(253, c) (253, c)胜出(254, e),因为 code 上 253 更小,然后 abc 输出(这里实际上隐藏了一个 OVC 的细节,我们之后会讲到)
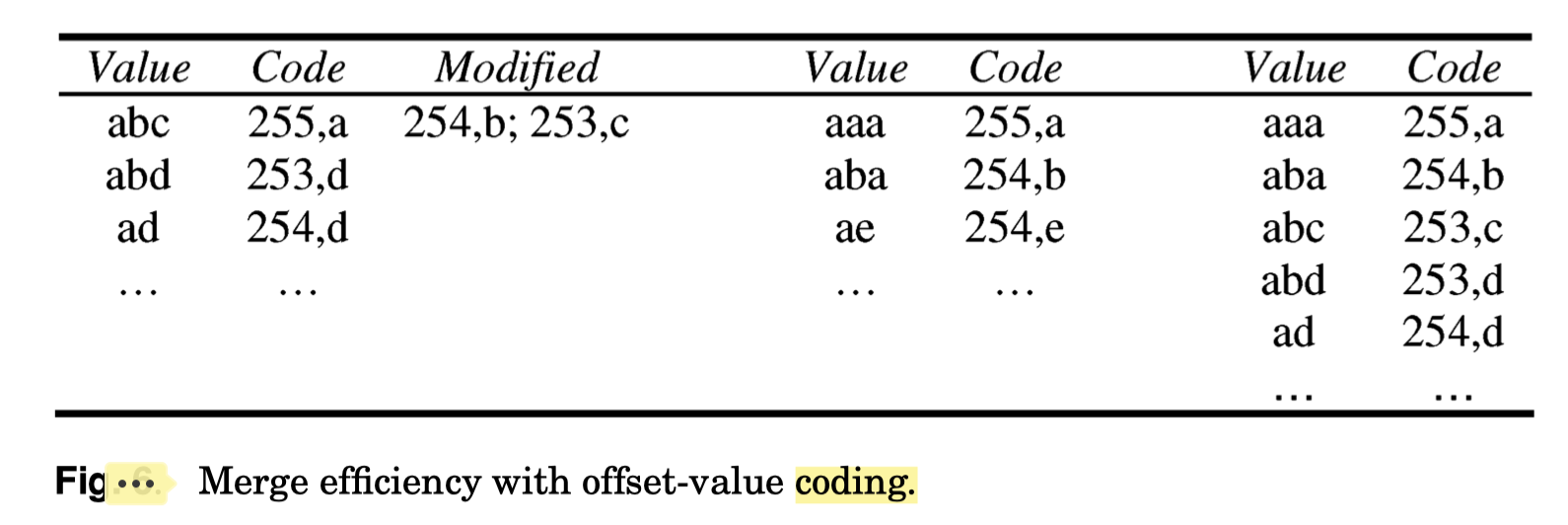
这里实际上隐藏了 OVC 的很多关键细节,所以说 Graefe Goetz 写作是晦涩的。
这里他还提到了 OVC 来实现快排,相当于每个分区对同一个数值做 OVC 计算,然后用这个来执行比较
Wrap-up
本质上,这里压缩的困难还是对数据分布的不完全理解。在开始排序的时候,根本不知道这一块的细节,导致很多地方无法进行下去。
Cache-Optimized Techniques
这里首先提到了 Cache 优化的几个因素,原文关键而简短,这里我直接摘抄了
A single cache fault in the level-2 cache can cost 50 or even 100 CPU cycles, that is, the equivalent of up to hundreds of instructions. Thus, it is no surprise that performance engineers focus at least as much on cache faults as on instruction-path length.
Cache faults for instructions are as expensive as cache faults for data. Thus, reducing code size is important, especially the code within the “inner” loops, such as comparisons.
- 对于 Code Cache,这里核心是减少 inner loop 的 code size,即 compare 的开销。实际上 Normalized Key 本质上也会减少这块的开销,毕竟不需要根据代码类型来走一长串分发了( code required for traditional complex comparisons might well exceed the level-1 instruction cache, particularly if international strings and collation sequences are involved )
- 对于 Data Cache,这里有两个核心:
- Only use record surrogates in cache ( 比如尽量用 Poolmans key, ovc 之类的)
- 采用后文有关 Merge Sort 的技术
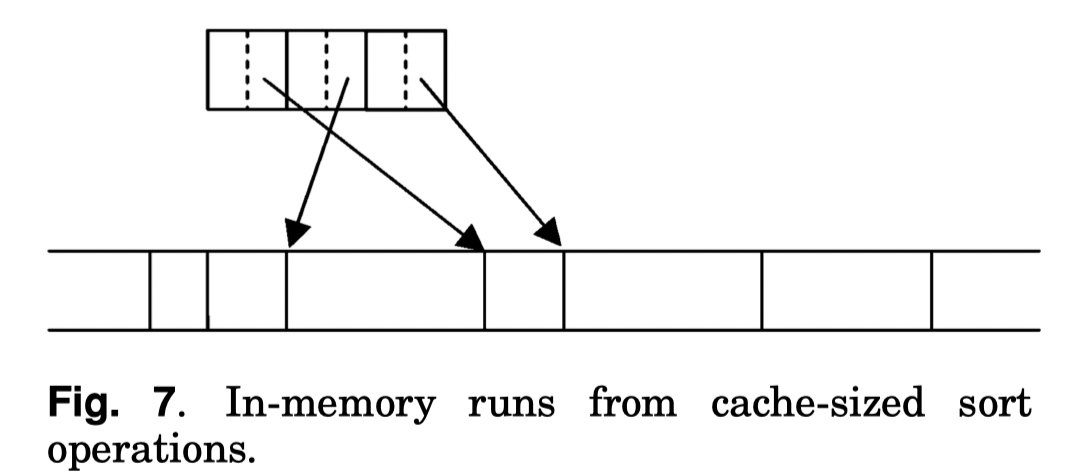
大部分实现使用上面的模式,具体到代码上,有一个 RowContainer 承载 Row,然后内存暴露给外面 idx 之类的
这里面前几字节也可以暴露成 Poor mans normalized key,下面介绍了一下具体的可能优化:
This is because the comparison of poor man’s normalized keys is compiled into a few instructions of machine code, and the branch prediction hardware of modern CPUs will ensure that such useless predictable comparisons will not stall the CPU pipeline.
当然,OVC 会是一种可能更有效的动态 Poor mans normalized key.
在 Merge 中,如果多流已知不重合,可以尝试把一个 Reference Key 编码到高位,来加速比较
对于 External Sort 的技巧,基本还是几点:
- create runs that are the size of the CPU cache and then to merge multiple such runs in memory before writing the result as a base-level run to disk.
- Sort each incoming data page into a minirun, and merge miniruns (and remove records from memory) as required to free space for incoming data pages or competing memory users.
- run internal activities not one record at a time, but in batches, as this may reduce cache faults instructions and global data structures
Priority Queues and Binary Heaps
这段主要介绍了胜者树和败者树(Loser-Tree , 或者叫 tree of losers ). 这块 G.G. 很早的论文就提到过用它来做排序,不过我看到的最好的 PPT 还是首尔大学的 [9],讲的非常清晰
论文花了一点时间介绍败者树,我建议看首尔大学 PPT。Loser Tree 核心是「Can reduce the work when the winner value is changed」
Trees of losers 如下所述,这是一个 DB 专用的 Loser Tree,这里有几个工程实现点,比如使用 Poolman’s Key 作为比较。下列的核心是 Sentinel value,即在 Key 前缀或者编码上预留一些空间,给最大/最小的 Key 或者完成了输出的流 (dummy)。同时,有一个坑点是,两个 Dummy 流可能会遇到一样的值情况(即下面的 Second),所以为了处理这种情况,会给 Dummy Run 在 Dummy 内一个编码。
在 third 一节里面作者说,除了 dummy stream 这种情况,也可以编码 Run Number 到 Normalized Key (的最后?)来区分 Stream。另一种方式是,给本 run 一个 bit,然后别的 Run Key 都设置为另一组 key。
- First, priority heaps may contain invalid entries, indicating, for example, that during a merge step an input run has been exhausted. This is also how a dummy run, if necessary, is represented. Invalid heap entries can have special values as their poor man’s normalized keys, called sentinel values hereafter.
- Second, in order to simplify the logic after two poor man’s normalized keys are found to be equal, two sentinel values in the priority heap should never compare as equal. To safeguard against this, each possible heap entry (each record slot in the workspace during run generation or each input run during a merge step) must have its own early and late sentinel values.
- Third, during run generation, when the heap may simultaneously contain records designated for the current output run as well as those for the next output run, the poor man’s normalized key can also encode the run number of valid entries those such that records designated for different runs compare correctly, based solely on their poor man’s normalized keys. Note that the run number can be determined when a record is first inserted into the priority heap, which is when its poor man’s normalized key value to be used in the priority heap is determined.
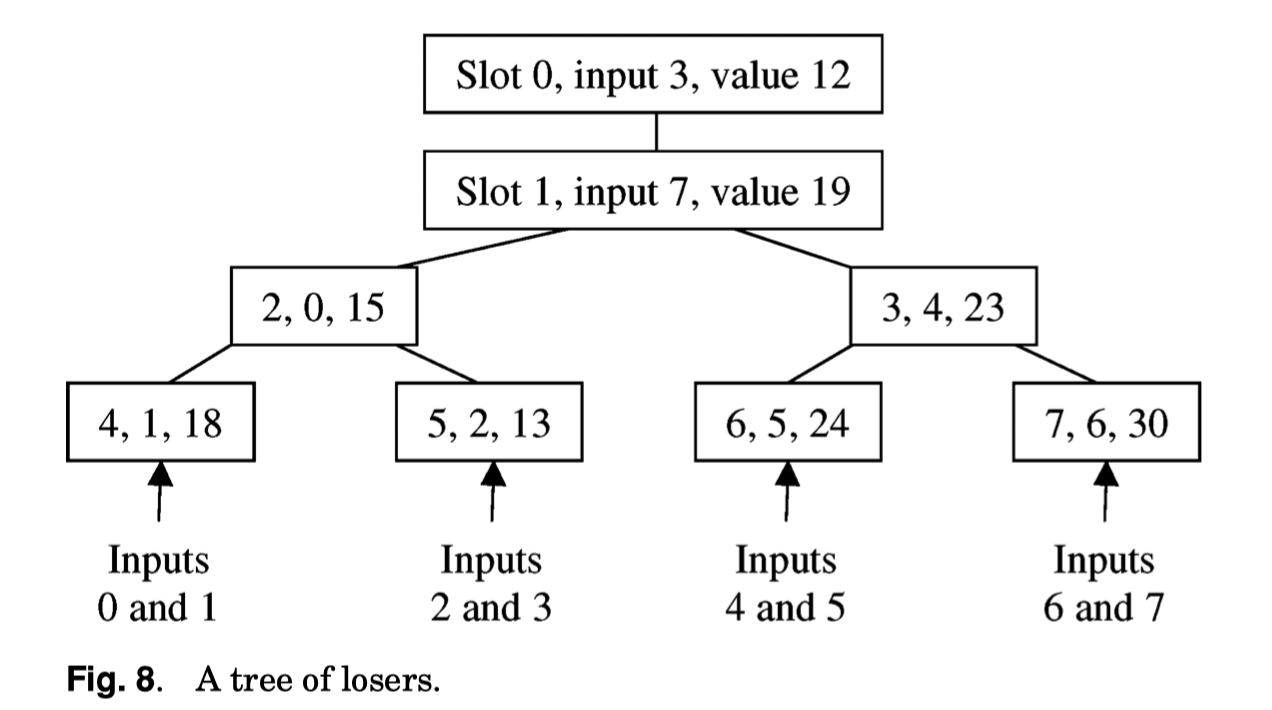
下面是上面规则的一个编码例子:

下面这段的前半段我没完全看懂,主要是不懂这个地方提到 Run Generation 有什么用意,下面一段写可以有一些 hint 来提示结构调整是 top-to-down 还是 down-to-top
Prior to forming the special poor man’s normalized key for use in the priority heap, a prefix of the key can be used to speed several decisions for which slightly conservative approximations suffice. For example, during run generation, the poor man’s normalized key alone might determine whether an input record is assigned to the current run or the next run. Note that an input record must be assigned to the next initial run, not only if its poor man’s normalized key is less than that of the record most recently written to the current run, but also if it is equal to the prior poor man’s normalized key—a tradeoff between quick decisions and small losses in decision accuracy and run length. Similarly, when replacing a record in the priority heap with its successor, we might want to repair the heap either by a root-to-leaf or leaf-to-root pass, depending on the incoming key, the key it replaces, and the key in the appropriate leaf of the priority heap.
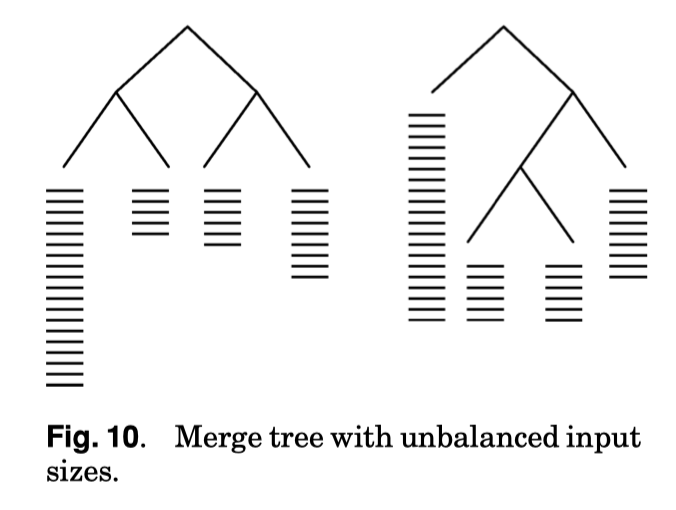
论文还介绍了在 Run 的大小有 Skew 情况下的实践,有几种情况:
- Run 大小比例简单的不均等,这个 情况类似 Fig 10,可以给它留多个 Entry Point,让这条路的比较次数尽量的少
- 在上述 case 满足的情况下,有一条 Run 特别大,这种方式可以尝试用别的组一个 Run Output,找到这个 Output 在最大的 Run 里面的位置,来避免这一 Run 的比较
References
- https://github.com/apache/arrow-rs/blob/master/arrow-row/src/lib.rs#L147 arrow-rs 的 Row 模块
- Velox RowContainer https://github.com/facebookincubator/velox/blob/db8875c425e8132f553adf12e106cd2e28a811c0/velox/exec/RowContainer.cpp#L133
- https://duckdb.org/2021/08/27/external-sorting.html#columns-or-rows DuckDB 排序的文章,这节讨论了排序是 Row-based 还是 Column-based
- TiDB Key Encoding 规则: https://github.com/pingcap/tidb/blob/v8.4.0-alpha/pkg/util/codec/bytes.go#L35
- TiDB Key Collactor: https://github.com/pingcap/tidb/blob/v8.4.0-alpha/pkg/util/collate/collate.go#L66
- https://arrow.apache.org/docs/format/Columnar.html#variable-size-binary-view-layout BinaryView Type
- https://facebookincubator.github.io/velox/develop/types.html
- https://db.in.tum.de/~freitag/papers/p29-neumann-cidr20.pdf Umbra
- https://ocw.snu.ac.kr/sites/default/files/NOTE/490.pdf