Rethink SIMD Vectorization for In-Memory Databases
本文是 Oracle 和哥伦比亚大学工程师发表在 VLDB’15 上的论文,论文探讨了了几个 SIMD 原语(部分原语实际上是没有 SIMD 直接指令对应的,但是类似 SIMD 宏,可以用多条 SIMD intrinsics 实现,并且满足需要的并行度)。然后基于这些原语,提到了一些 SIMD 化的 Operator 实现,包含:
- Scan(Filter)
- HashTable
- BloomFilter
- Partition ( Shuffle, etc)
- Hash Join
本文可能15年不那么晚,然后也介绍了一些加速器用到的没有 OoO 的 CPU,比如 Intel Xeon Phi 作为评估。但是论文的一些核心观点还是比较站得住脚的,所以我们来细读一下。
硬件和一些定义
论文分成了 Mainstream CPU 和 MIC CPU,前者我们大家都很熟了。后者论文提到了 Intel Xeon Phi ,它的特点是多核心胶水核,砍掉了或者多了一些 SIMD 指令,没有 Out-of-order 模块,算是在 CPU 上抄 GPGPU 的一些设计吧。这种芯片在当时也提供了 gather 和 scatter 的支持。
论文提到了 fully vectorize 的定义:
Formally, assume an algorithm that solves a problem with optimal complexity, its simplest scalar implementation, and a vectorized implementation. We say that the algorithm can be fully vectorized, if the vector implementation executes O(f(n)/W) vector instructions instead of O(f(n)) scalar instructions where W is the vector length, excluding random memory accesses that are by definition not data-parallel.
这里还是说,以能否将计算拆分到 vector lane 上,然后让大家的操作都并行起来。关于 auto-vectorization 我之前的博客或许有一点参考意义:https://blog.mwish.me/2023/12/10/Compiler-Optimizations-Power-Limits-Auto-vetorize/ . 这么看 scatter-gather 一般也不一定划得来。
论文第二章提到了一些之前的工作和 auto-vectorization。可以看到大伙儿都挺行的,能 SIMD 化的东西感觉已经被犁地一样犁过一阵子了
论文使用的原语
论文使用的原语包含 Selectivity load/store, Gather, Scatter 。其实一些自动向量化也能检查到一些,
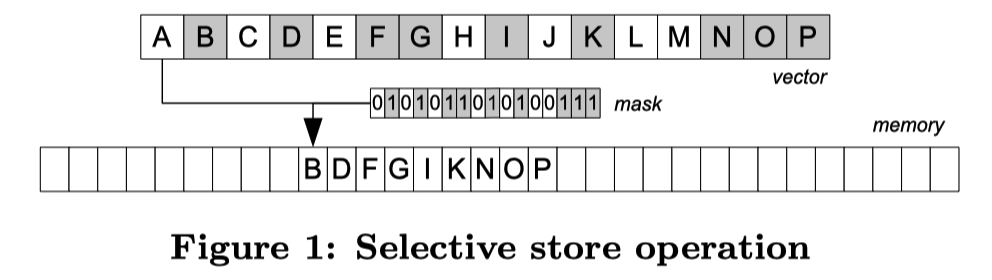
上面是 selective store,下面是 selective load(印象中 avx2 是一组 __mm256,avx512 有一组专门的寄存器)。分别是:
- 根据 mask 去 store,把不连续的 vector 写到连续的内存中
- 根据 mask 去 load,把连续内存根据 mask 写到不连续的 Vector 中
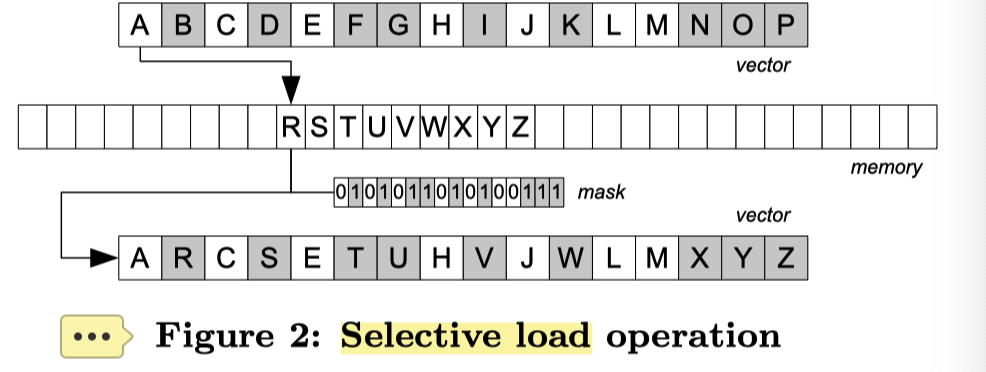
然后是 gather 和 scatter. 这里 selective load/store 的操作数是 mask,这里就是对应的 index 了。这段也比较好理解
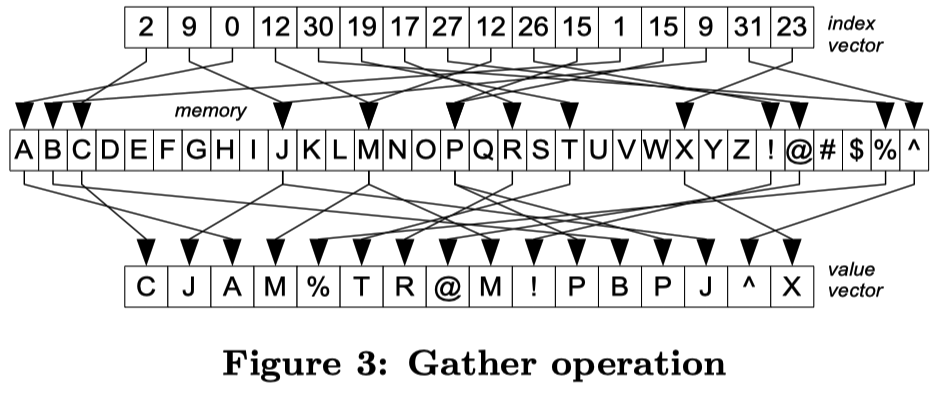
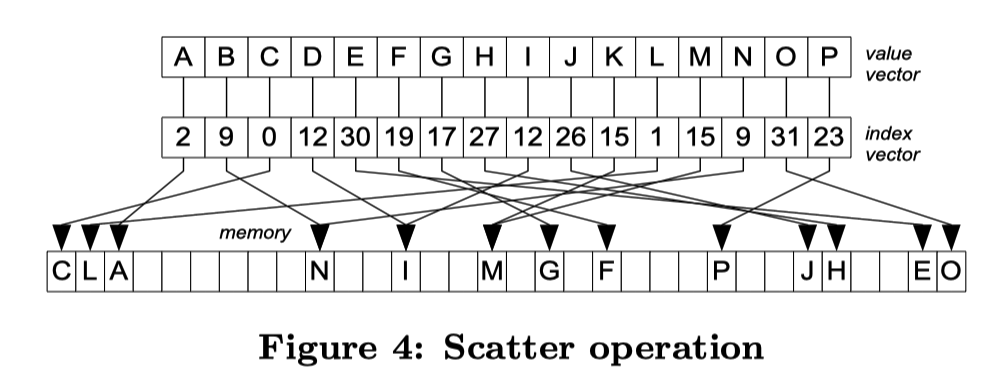
好,那么我们开始讨论这套操作的实现和性能
- Gather / Scatter 操作本身受限于 cache,见:https://blog.mwish.me/2024/03/04/SIMD-Extensions-and-AVX/ 。因为 CPU 每个周期可能只能做一定的 L1 cache 访存 . 这里也有个很好玩的 case: https://github.com/llvm/llvm-project/issues/53435 .
- Selective Load/Store 可以通过 permutation 实现. CPU 有 maskload 和 maskstore 指令,但是 maskload 和 maskstore 并不等价于 Selective Load 和 Selective Store。论文提到可以用 permute 之类的 shuffle 指令模拟。首先根据情况从 selective 生成一个 mask ( 这块论文提到可以使用一个 pre-generated table,我觉得 bmi2 也可以使用)。这里写入的时候可以生成table -> maskmove/maskstore 指令,读的时候可以先读上来再 shuffle ( https://stackoverflow.com/questions/62183557/how-to-most-efficiently-store-a-part-of-m128i-m256i-while-ignoring-some-num 题外话,我发现这个链接也很好)
- 需要注意的是,这里的 selective store / load 操作也是可能跨两个 cacheline 的
论文 appendix 3 中列举了 TableScan 的实现:
1 | /* load permutation mask for selective store */ |
关于 load:
1 | /* load permutation masks */ |
Selection Scans
关于 TableScan 的讨论,有一部分是在高效 Scan 压缩数据上的,包括下面的材料:
- SIMD-Scan: Ultra Fast in-Memory Table Scan using onChip Vector Processing Units
- BitSlice / BitWeaving
Scan 首先有个关键点是谓词处理。发表于 TODS’04 的论文
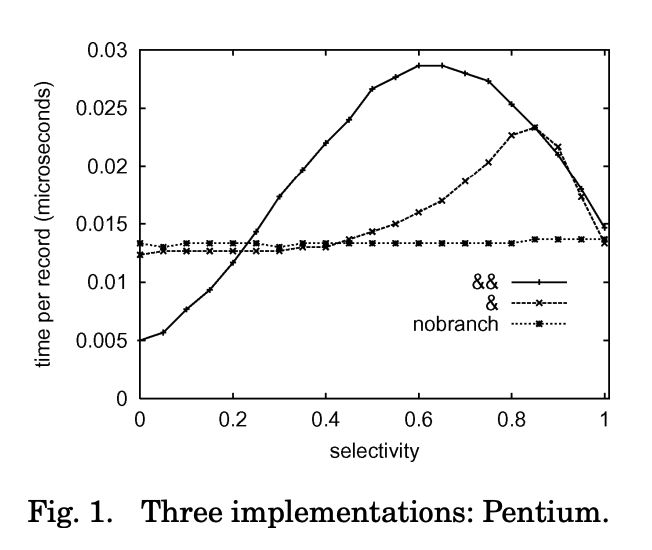
本章的 scan 介绍了 Scalar Scan -> Scalar Scan(branchless) -> Vectorize Scan 的基础思路:
设计要点:
- Branching 可以被避免,但是另一方面,如果选择率低,load 成本也过高,尤其是表比较宽的时候,复制这些 和谓词不相关的 Payload 是有一定的开销的
- Payload Store 可以考虑按照情况避免写入 cache,使用 bypass cache 的指令(见下图的 stream store 段)
- 通过 indices buffer 来操作 Payload ( 我也在想如果表就那几个字段或者 selectivity 高是不是也没必要,不过这个算法思路还是很完善的)

Hash Tables
Hash Table 操作分为 Build / Probe 两步,在 Hash Join 和 Hash Agg 之类的地方都会遇到。论文把 Hash Table 的并行分为两种,对于 Probe 有:
- Horizontal vectorization: 对比一个 input probe 和多个存在的 hash table keys。对于 CPU,load 32bits 和 load 128bits 开销可能是一样的,这样能并行化 probe。swiss table 就用了这种策略,用 SSE 指令来 cmp 多个 flags。作者认为,单个 key 去比较还是很废的,假设一个 key 需要访问平均 1.5 个 bucket,打会儿的并行度就上不去了
- Vertical vectorization: 每个 vector lane 携带不同的 hash probe key,也访问不同的内存(这么看来,CPU Prefetch 对大 Hash Table 其实是很重要的)
论文写了 Linear Probing, Double Hashing, Cuckoo Hashing 等方式。Hash 函数论文介绍单个 Hash 函数选择 multiplicative hashing( 通过 (key * f) mod k 的方式处理,bucket 总共有 2^n 个,这里操作相当于 mul + shift,能很好的被 SIMD 支持)( 作为单个 hash 函数 https://www.zhihu.com/question/20820286/answer/2584176348 这篇文章或许是个好的入口)
Linear probing
设计选择:
- 每个 loop 处理 W 个不同的 probe input keys
- 每轮 vectorized probe 之后,有的key 找到了 empty bucket,有的 key 则没找到,这个时候
- 对于已经 Finished 的 keys,需要 load 下一轮的 keys
- 对于没有 FInished 的 keys,需要变更 probe offset。这里维护了一个 offset vector 作为每个 key 的 offset
- 这个算法不是 “stable” 的,旧的 probe keys 有的结束了有的没结束的话,新插入的 probe keys 可能会改变 probe 的输出顺序。比方旧的是是 0-10 匹配输出,vectorize 版本可能就是 1 - 0 - 2 - 3 这种顺序了。
- Probe 不需要考虑 key 冲突,反正不重复

对于 Build 而言,这里也差不多,需要找到一个空 bucket 来插入,但是相对 probe 而言,这里的区别是:
- Probe 的输出是个 selecitivity store,而 Build 是个 Scatter Store。
- 这里需要做冲突检查,scatter 本身不需要特殊处理,左侧的写会被右侧的写覆盖(如 Figure 4 的 12),scatter 向量
<0, 1, 2, ...>之后再跟一个 gather 这些值(这里应该 cache 访问开销相对较小),如果两边匹配(表示写入的 index 是能够匹配的),才表示这一次写成功。一些新的指令(in AVX512 like_mm256_conflict_epi32)能够省掉这一轮的开销。如果已经是 input key 是 unique 的,这里可以直接 scatter keys 这个地方可以直接 scatter keys 到结果集中,避免一轮<0, 1, 2, ...>向量的中间操作。 - 这里还提到了用 wider scatter 来避免 cache 开销,比如 32bit-32payload,这里可以尽量拆分成8-way 64bit gather + shuffle,来避免 cache 开销,这里下面也列了代码(我倒是觉得有这必要么)

这里是冲突检测的代码和写入的代码,这里可以看到对应的逻辑
1 | /* gather keys from buckets */ |
上面这段代码中,先拿到了 m 看这一轮 probe 的结果( tab 是 gather 到的本轮的 bucket 中的 slot),然后去 scatter mask_unique,再读 hash 上的所有变量读回来做一轮验证,最后再去写真的值。
To halve the number of cache accesses, we pack multiple gathers into fewer wider gathers. For example, when using 32-bit keys and 32-bit payloads, the two consecutive 16-way 32-bit gathers of the above code can be replaced with two 8-way 64-bit gathers and a few shuffle operations to split keys and payloads. The same applies to scatters (see Appendix E for details).
Double Hashing
重复的 key 可以有下列的处理方式:
- 把 Payload 存在额外的表上,类似
key->[values]-> 当大部分 key 是 repeated 的时候效果很好 - 重复存储这些 key -> 在 Linear Probe 的时候, 当大多数 key 是 unique key 时效果很好,但是 cluster 的时候效果不那么好
Double Hashing 使用两个 Hash Function,相当于 offset + 1, 这里采取前进 hashFunction(value) % (bucketSize - 1)

这里有个 m 是 probe 的时候遇到冲突的 bucket. 注意最后一步的细节:使用减法来避免 mod 的开销,因为修正前的 hash + hash 肯定不过超过两倍 hash bucket size 大小
Cuckoo Hashing
Cuckoo 可以当成是 horizontal vectorization 的典范之一,probe 代码如下,这里还是没那种向量化比较槽,而是按位操作过去的。这里 Cuckoo Hashing 不支持 key repeats.

Build 要复杂一些:

Bloom Filter
Bloom Filter 可以帮助 semi join,或者谓词 pushdown 到 scan 之类的地方。这里:
- 论文提供了 VBF:https://news.ycombinator.com/item?id=14385540 和 https://dl.acm.org/doi/10.1145/2619228.2619234
- https://www.cs.amherst.edu/~ccmcgeoch/cs34/papers/cacheefficientbloomfilters-jea.pdf 这篇应该是个比较经典的文章,感觉主流的 BF 都是 vectorized 的 Split Block Bloom Filter 了
- 然后感觉现在最流行的只读 Filter 是 XOR Filter
这里的要点还是 SIMD并行化操作、Cache Resident
Partition
Paritition 把数据集切成多个不重合的小块,Radix/Hash/Range Shuffle 可能都依赖它,或者 Agg 这种也有可能依赖它。被切分的小块也最好能适配在 cache 中,便于后续的高效计算。
Partition 有两个部分:
- Compute Histogram: 在移动数据之前,这里需要通过 histogram 来手机
- Shuffling: 根据 Histogram 的结果去收集数据
Radix & Hash Histogram

这里有两点需要注意的:
- 维护了
H作为 bucket count * vector-lane 的大小,总觉得这块虽然悪くない,但是内存会不会开销比较高?内部检查冲突之类的会不会好一些? - 这里还是用 gather -> inc -> scatter 来处理数据,有什么更好的 inc 方式吗?
Range Histogram
Range histogram 会显著慢于 Hash/Radix Partition。这里的逻辑主要靠在 cache resident array 中做 binary search 来实现。
这里代码是靠 gather instr 来收集多个 split point,然后每个子 batch 去批量搜索查找(下面的代码应该只是比较一个子 batch)

Shuffle
这里处理的逻辑还是比较简单的,先算出分区位置,再写具体的 value,当然这里还要面对一个我们之前面对过两次的问题:一个 vector 内的冲突处理。这里也是用了 gather 和 scatter 的方式

这个处理方式比较 sb,基本上还是每个向量内部去处理,因为每次写入的是最右侧的,所以 mask 是一个 “reversed mask”,来得到正确的顺序。有了这个处理之后,实现也会很简单了(这里还提到了算法稳定性有的时候会比较重要):
Stable partitioning is essential for algorithms such as LSB radixsort.

Buffered Shuffling
上面那个实现用脚看都看得出性能不好,因为每个 Batch 写实在开销太高了,当结果集比 cache 大的时候,这里论文给出了两个显然的缺点:
- 当 partition fanout 大于 TLB 时,会造成 TLB thrashing ( 这里提到了论文:What happens during a join? dissecting CPU and memory optimization effects.
- 论文 Fast sort on CPUs and GPUs: a case for bandwidth oblivious SIMD sort 指出,这里会生成很多的 cache conflicts ( 额,还是因为组相联 cache 不够大)
- normal stores 会引入 load -> store,目标的内存部分只会被写,这部分会增大开销,降低实际 workload 用的内存带宽 (参考论文: Engineering a multi core radix sort. )
这里策略是:
- 先写入小的 cache resident buffer
- 如果某个 lane 准备 overflow,就需要刷真实 buffer,刷的时候去 stream store bypass

Sort
这里参考了论文 A comprehensive study of main-memory partitioning and its application to large-scale comparison- and radix-sort
Hash Join
这里根据 Partition 方式来分类
- No partition:在(Build 侧)所有线程共享一个哈希表,并且使用原子操作来更新表中的计数器。这种方法在现代多核CPU上可能会受到锁竞争的影响。Probe 测并发访问
- Minimal-partition:每个 Build 线程都有自己的哈希表,从而避免了锁竞争。Probe 操作需要选定
- Maximum partition:将两个表的数据分到足够小的分区,以至于每个分区都可以适应缓存。这样可以在L1或L2缓存中进行哈希表的操作,从而实现高的性能。