VLDB'11: Efficiently Compiling Efficient Query Plans for Modern Hardware
在日新月异的db领域看一篇年代较早的论文有一些思路,要么是其实领域发展的没有那么快,比如大家搞了很多 btree 新结构的文章,但是感觉做 BTR 还是完全无法绕开 IBM的ARIES几件套,G.Gotez 的文章。要么就是给日渐复杂的模型找一个基本的出处。我刚翻15-721 的时候看他聊到 Vectorize 直接给我上 SIMD 了,心想这和 Monet/X100 的论文思路还是有区别的。不过仔细想想,可能 Vectorize 除开指令和数据有更好的局部性、避免哦了更多的 Volcano 这类的框架开销之外能够利用上的优化。
这篇论文由 TUM 在 11 年发表在 VLDB 上。本文主要贡献是 Codegen + 支持 codegen 的 Pipeline。现如今作为 ap 大内卷时代,这两项技术都在 DuckDB、ClickHouse、Velox 和无数分析数据库上跑着了。不是所有数据库都做了 Codegen,但是大家通常会实现一套 Pipeline 来做高效的调度和执行。但比较有意思的是,本文却是反过来的,为了 Codegen 而实现了 Pipeline。
从这个角度来看,在 codegen 的原点,作者的需求是:
- 希望直接生成 Monet/X100 的论文中那种 optimal 的代码。因为是直接生成的 Typed 代码,所以也避免了框架的开销
- 本身 codegen 如果从上层去 pull 的执行的话,作者认为其中还是会有很多 branching 的开销的。作者认为,避免这种开销的方式就是以数据为中心实现 execution。把多个 operator 按照性质组织成 Pipeline,来进行以数据为中心的执行。
当然,作者还举了个比较好玩的例子,在实现 Scan 的时候,如果有一些压缩之类的上下文,或者这样的处理方式,per-tuple 的执行可能 book-keeping 的开销会很大(感觉按他说法甚至类似于搞 streaming 解压了,不过看大部分实现可能不会这样做,都是 Page 解压然后再 Page 上读数据。但是传统 btr 在 Page 上处理 iterator 上下文也是有一定开销的)。
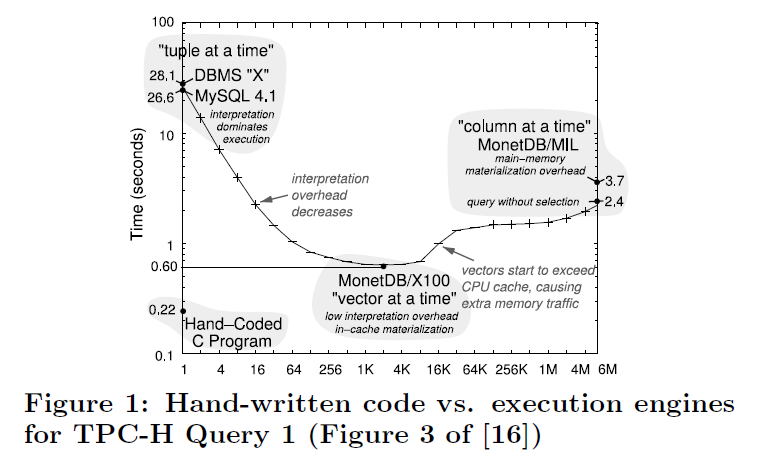
作者对 vectorize 当时的看法是:
This materialization has other advantages like allowing for vectorized operations [2], but in general the lack of pipelining is very unfortunate as it consumes more memory bandwidth.
As shown in Figure 1, still does not reach the speed of hand-written code.
(即本身对 memory bandwidth 依赖比较重。这个可以有一些工程优化,我保留态度)
关于为什么要做 Push-based 这套,作者的观点是:
- Data centric > Operator centric,来保证数据 keep 在 register 中。
- 作者认为 pull-based execution 依赖 function call,同时,它需要提供一个
next()的调用,这种调用很保持数据在寄存器中。 - 数据被 LLVM 转成 Native Code
此外,虽然文章的 1-4 节,作者介绍的都是 per-tuple 的执行,但是在文章的第五节,作为优化项目,这里也允许框架使用 Batch 的执行来利用 SIMD 等方式来优化。
执行模型
作者首先定义了:
- Pipeline-breaker: 对于给定的输入,如果会从寄存器丢到内存里,这就是 pipeline breaker. 这里视把数据 spill 到内存中为一个 pipeline-breaking op
- Full Pipeline breaker: 需要输入端 Materialize 所有的 input
关于这里的寄存器概念定义,可以查看:
LLVM hides the problem of register allocation by offering an unbounded number of registers (albeit in Single Static Assignment form).
在这里,数据流成为了:
data is always pushed from one pipeline-breaker into another pipeline-breaker
在这里做一个讨论,作者认为 pull-based execution 不太适合保持 Tuple 在寄存器中,这是为什么呢?这里和培神交流了下,对于 pull 可能把函数写成下面的样子:
1 | Optional<Nullable<T>> next(); |
对于 1/2 来说,其实都很难保证数据在寄存器中:
- https://wiki.osdev.org/System_V_ABI 可能最多保证 64B 的返回可以在寄存器中。这样对于 Schema 稍微复杂一点的 Tuple
- https://www.reddit.com/r/cpp/comments/ilujab/it_turns_out_stdtuple_is_not_a_zerocost/?rdt=58548
(当然,某种意义上,我觉得对于 Batch Exec 这里也不是那么重要。可能 Batch Exec 希望的是个类似的东西,就是数据全部在 L1 Cache 里头。ClickHouse 和 DuckDB 相对来说都觉得这块的流控之类的更加好做,而不是简单的 keep 数据在寄存器中。)
下面展示了一个带子查询的 SQL 和基本的执行计划:
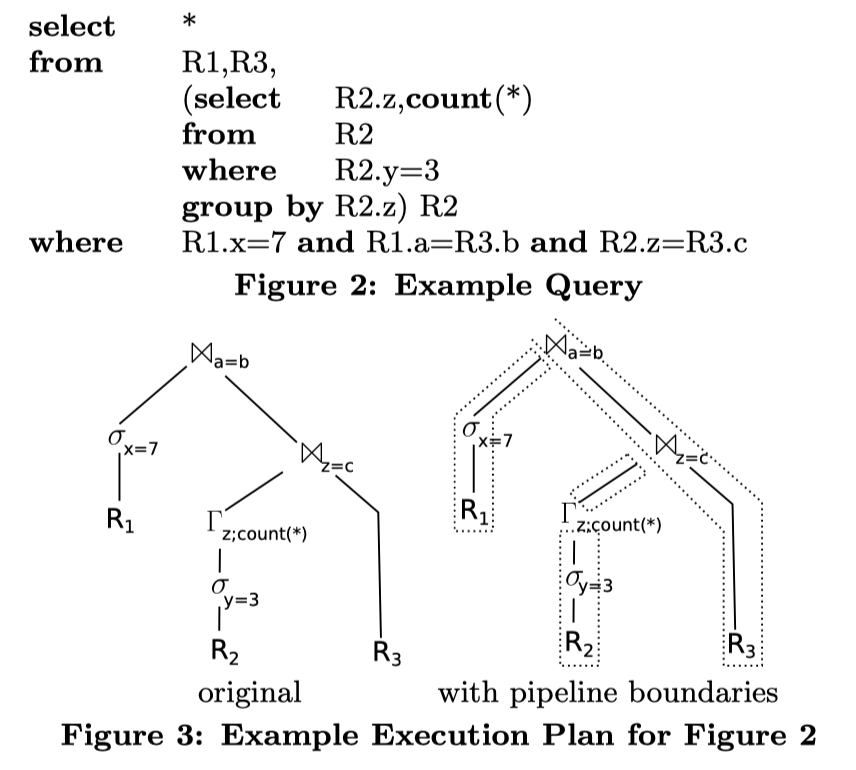
这里 Figure2 -> Figure3 左侧其实是比较好懂的。这里需要两次 Join,然后有一个的输入来自于子查询末端的 Group By 和 R3,另一份的输入来自于 R1 Selection 和 Join 的结果。左右关系可能来自优化器的估计(Hash Join 中,Build 侧可能希望小一些,来让内存的开销小一点)
上述的代码会被(逻辑上)处理成 Figure4 的样子。注意这里还是考虑的是串行处理的代码,对应从 Root 节点 pull 的代码结构。这样的代码在执行的时候会划分成下面四个 pipeline 的部分:
- 从 R1 中读数据,然后 materialize (去 build)
- R2 中读取 -> Filter -> Materialize ( Hash Agg )
- 从 Hash Aggregate 中再构建 Build 阶段的 Table
- 从 R3 推上来,先 Join (3) 再 Join (1) 的结果。这部分 Join 的处理还是很有意思的。

编译出这样的代码是有难度的,尤其是考虑可能插入一些并发操作的时候。同时需要处理 Join 这样的结构。所有算子可以准备下面的逻辑结构:
1 | produce(); // 声明操作,要求你可以产生数据了 |
显然,我们之前看过 Acero 的代码,它也有类似的结构。

这里注意 Join 的 Consume 的结构。
Code Generation
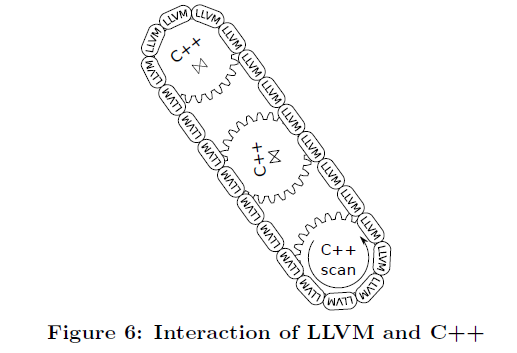
作者使用 LLVM 连接 C++ 代码,并不适用直接生成汇编的方式,如图6,C++的“齿轮”是预编译的;只有用于组合它们的LLVM“链条”是动态生成的。这样可以实现非常低的查询编译时间。直接编译 C++ 代码则要耗费数秒的时间。
有些代码比如 Sort 之类的相对复杂,LLVM 这里是用胶水把它们连接起来。然后主要编写 C++ 代码。
While staying in LLVM, we can keep the tuples in CPU registers all the time, which is about as fast as we can expect to be. When calling an external function all registers have to be spilled to memory, which is somewhat expensive. In absolute terms it is very cheap, of course, as the registers will be spilled on the stack, which is usually in cache, but if this is done millions of times it becomes noticeable.