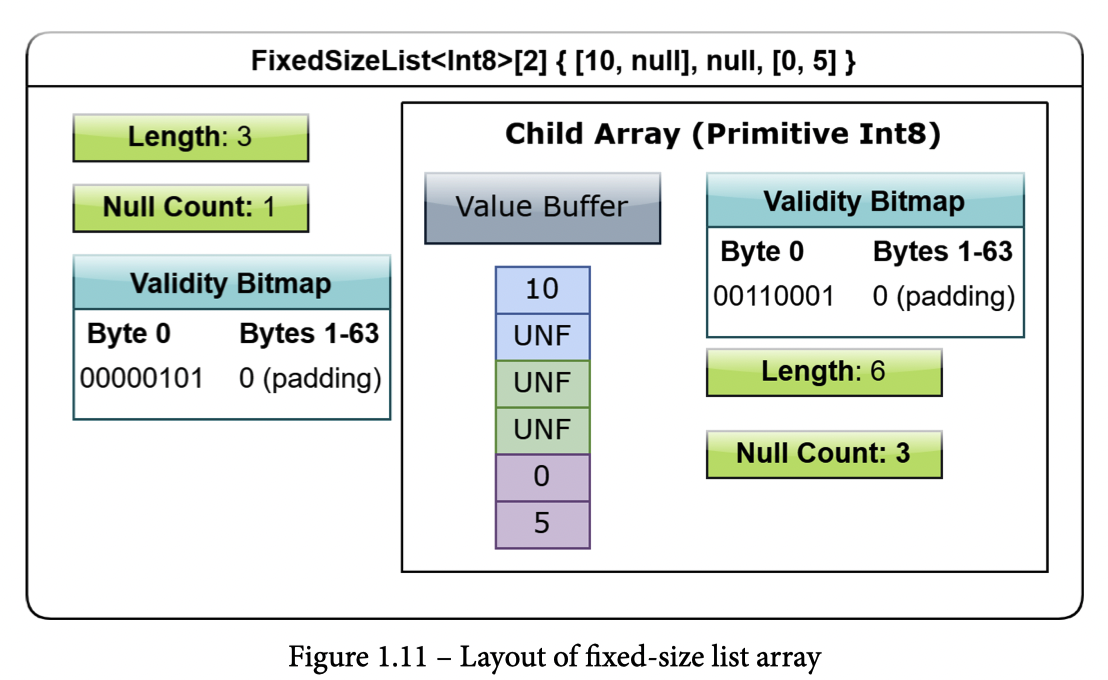
/// \brief Result for a single leaf array when running the builder on the /// its root. structMultipathLevelBuilderResult { /// \brief The Array containing only the values to write (after all nesting has /// been processed. /// /// No additional processing is done on this array (it is copied as is when /// visited via a DFS). /// /// leaf_array 是写入页面的整个 array, 即整列的数据 std::shared_ptr<::arrow::Array> leaf_array;
/// \brief Might be null. constint16_t* def_levels = nullptr;
/// \brief Might be null. constint16_t* rep_levels = nullptr;
/// \brief Number of items (int16_t) contained in def/rep_levels when present. /// def-level 和 rep-level 长度是一样的, 所以需要一个 level 来提示 int64_t def_rep_level_count = 0;
/// \brief Contains element ranges of the required visiting on the /// descendants of the final list ancestor for any leaf node. /// /// The algorithm will attempt to consolidate visited ranges into /// the smallest number possible. /// /// This data is necessary to pass along because after producing /// def-rep levels for each leaf array it is impossible to determine /// which values have to be sent to parquet when a null list value /// in a nullable ListArray is non-empty. /// /// This allows for the parquet writing to determine which values ultimately /// needs to be written. /// /// 写入的内容在 `leaf_array` 中的范围 std::vector<ElementRange> post_list_visited_elements;
/// Whether the leaf array is nullable. /// /// leaf 是否是 nullable 的 bool leaf_is_nullable; };
// Writes out all leaf parquet columns to the RowGroupWriter that this // object was constructed with. Each leaf column is written fully before // the next column is written (i.e. no buffering is assumed). // // Columns are written in DFS order. Status Write(ArrowWriteContext* ctx){ for (int leaf_idx = 0; leaf_idx < leaf_count_; leaf_idx++) { ColumnWriter* column_writer; PARQUET_CATCH_NOT_OK(column_writer = row_group_writer_->NextColumn()); for (auto& level_builder : level_builders_) { RETURN_NOT_OK(level_builder->Write( leaf_idx, ctx, [&](const MultipathLevelBuilderResult& result) { size_t visited_component_size = result.post_list_visited_elements.size(); DCHECK_GT(visited_component_size, 0); if (visited_component_size != 1) { return Status::NotImplemented( "Lists with non-zero length null components are not supported"); } const ElementRange& range = result.post_list_visited_elements[0]; std::shared_ptr<Array> values_array = result.leaf_array->Slice(range.start, range.Size());
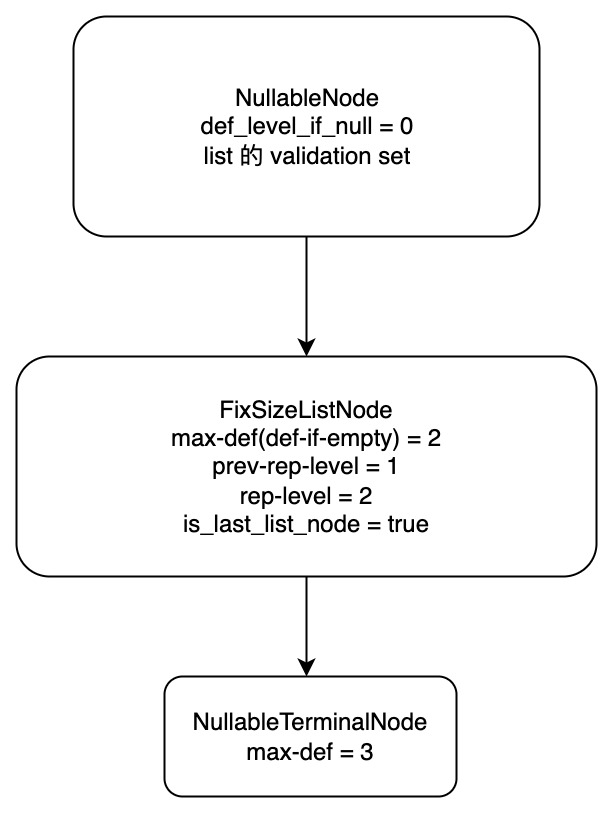
// 添加对应的 def-level, voidMaybeAddNullable(const Array& array){ if (!nullable_in_parent_) { return; } info_.max_def_level++; // We don't use null_count() because if the null_count isn't known // and the array does in fact contain nulls, we will end up // traversing the null bitmap twice (once here and once when calculating // rep/def levels). Because this isn't terminal this might not be // the right decision for structs that share the same nullable // parents. if (LazyNoNulls(array)) { // Don't add anything because there won't be any point checking // null values for the array. There will always be at least // one more array to handle nullability. return; } // 反正都没了,不如 terminal 了 if (LazyNullCount(array) == array.length()) { info_.path.emplace_back(AllNullsTerminalNode(info_.max_def_level - 1)); return; } info_.path.emplace_back( NullableNode(array.null_bitmap_data(), array.offset(), /* def_level_if_null = */ info_.max_def_level - 1)); }
这里如果是父级 null,就会增加 max_def_level,然后添加对应的节点项。
访问 struct
1 2 3 4 5 6 7 8 9 10
Status Visit(const ::arrow::StructArray& array){ MaybeAddNullable(array); PathInfo info_backup = info_; for (int x = 0; x < array.num_fields(); x++) { nullable_in_parent_ = array.type()->field(x)->nullable(); RETURN_NOT_OK(VisitInline(*array.field(x))); info_ = info_backup; } return Status::OK(); }
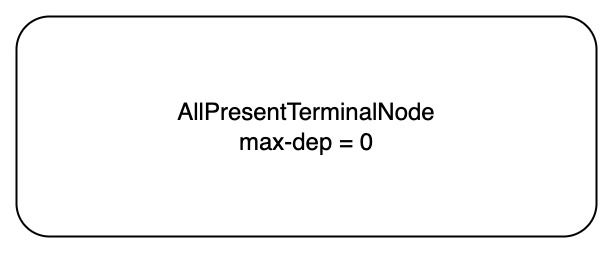
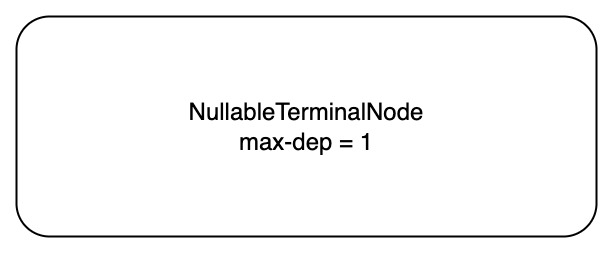
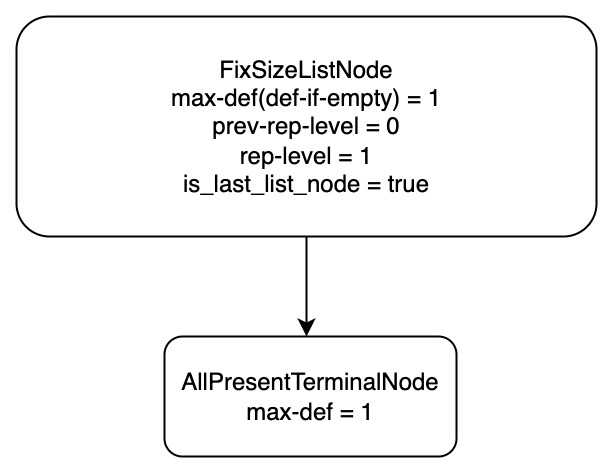
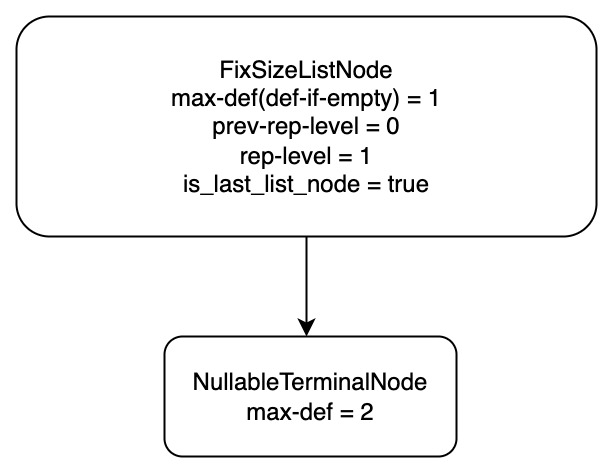
// We don't use null_count() because if the null_count isn't known // and the array does in fact contain nulls, we will end up // traversing the null bitmap twice (once here and once when calculating // rep/def levels). // // 处理: 没有 null, 都是 null, 可以为 null 的 case. 把这个加入 info_.path 中. if (LazyNoNulls(array)) { info_.path.emplace_back(AllPresentTerminalNode{info_.max_def_level}); } elseif (LazyNullCount(array) == array.length()) { info_.path.emplace_back(AllNullsTerminalNode(info_.max_def_level - 1)); } else { info_.path.emplace_back(NullableTerminalNode(array.null_bitmap_data(), array.offset(), info_.max_def_level)); } info_.primitive_array = std::make_shared<T>(array.data()); // 真正处理这个 dfs path, 把 fixup 的结果加入 paths. 这里面会处理 rep-level. paths_.push_back(Fixup(info_)); }
// FIXUP 会处理 rep-level. PathInfo Fixup(PathInfo info){ // We only need to fixup the path if there were repeated // elements on it. if (info.max_rep_level == 0) { return info; } FixupVisitor visitor; visitor.max_rep_level = info.max_rep_level; if (visitor.max_rep_level > 0) { visitor.rep_level_if_null = 0; } // 从 0-最后的顺序访问, 变更 visitor, 这个地方会把最上层的 rep-level 带下来. for (size_t x = 0; x < info.path.size(); x++) { std::visit(visitor, info.path[x]); } return info; }
voidoperator()(AllNullsTerminalNode& arg){ // Even though no processing happens past this point we // still need to adjust it if a list occurred after an // all null array. HandleIntermediateNode(arg); }
Nullable -> List -> Nullable -> List -> Int ,写入 1,2,null 和对应的 rep-level , def-level
回溯到上层,发现成员是 null,写入一个对应的 rep-level , def-level
发现栈有元素,到下层继续写入
具体实现
这里需要介绍 Iterator 类型,每一层会有一个 Run,拿到对应的范围。有可能:
kDone 做完了,应该向上层走
kNext 应该走进下一层
1 2 3 4 5 6 7 8 9 10
/// \brief Simple result of a iterating over a column to determine values. enumIterationResult { /// Processing is done at this node. Move back up the path /// to continue processing. kDone = -1, /// Move down towards the leaf for processing. kNext = 1, /// An error occurred while processing. kError = 2 };
IterationResult Run(ElementRange* range, ElementRange* child_range, PathWriteContext* context){ if (new_range_) { // Reset the reader each time we are starting fresh on a range. // We can't rely on continuity because nulls above can // cause discontinuities. valid_bits_reader_ = MakeReader(*range); } child_range->start = range->start; ::arrow::internal::BitRun run = valid_bits_reader_.NextRun(); if (!run.set) { range->start += run.length; RETURN_IF_ERROR(FillRepLevels(run.length, rep_level_if_null_, context)); RETURN_IF_ERROR(context->AppendDefLevels(run.length, def_level_if_null_)); run = valid_bits_reader_.NextRun(); } if (range->Empty()) { new_range_ = true; return kDone; } child_range->end = child_range->start = range->start; child_range->end += run.length;
/// Contains logic for writing a single leaf node to parquet. /// This tracks the path from root to leaf. /// /// |writer| will be called after all of the definition/repetition /// values have been calculated for root_range with the calculated /// values. It is intended to abstract the complexity of writing /// the levels and values to parquet. Status WritePath(ElementRange root_range, PathInfo* path_info, ArrowWriteContext* arrow_context, MultipathLevelBuilder::CallbackFunction writer){ // 栈表示为 range 栈 std::vector<ElementRange> stack(path_info->path.size()); MultipathLevelBuilderResult builder_result; builder_result.leaf_array = path_info->primitive_array; builder_result.leaf_is_nullable = path_info->leaf_is_nullable;
// 不需要处理递归、特殊场景,嗯写就是了 if (path_info->max_def_level == 0) { // This case only occurs when there are no nullable or repeated // columns in the path from the root to leaf. int64_t leaf_length = builder_result.leaf_array->length(); builder_result.def_rep_level_count = leaf_length; builder_result.post_list_visited_elements.push_back({0, leaf_length}); returnwriter(builder_result); } // root_range 为行的 offset, 是最外层的 range stack[0] = root_range; RETURN_NOT_OK( arrow_context->def_levels_buffer->Resize(/*new_size=*/0, /*shrink_to_fit*/false)); PathWriteContext context(arrow_context->memory_pool, arrow_context->def_levels_buffer); // We should need at least this many entries so reserve the space ahead of time. RETURN_NOT_OK(context.def_levels.Reserve(root_range.Size())); if (path_info->max_rep_level > 0) { RETURN_NOT_OK(context.rep_levels.Reserve(root_range.Size())); }
auto stack_base = &stack[0]; auto stack_position = stack_base; // This is the main loop for calculated rep/def levels. The nodes // in the path implement a chain-of-responsibility like pattern // where each node can add some number of repetition/definition // levels to PathWriteContext and also delegate to the next node // in the path to add values. The values are added through each Run(...) // call and the choice to delegate to the next node (or return to the // previous node) is communicated by the return value of Run(...). // The loop terminates after the first node indicates all values in // |root_range| are processed. while (stack_position >= stack_base) { PathInfo::Node& node = path_info->path[stack_position - stack_base]; struct { IterationResult operator()(NullableNode& node){ return node.Run(stack_position, stack_position + 1, context); } IterationResult operator()(ListNode& node){ return node.Run(stack_position, stack_position + 1, context); } IterationResult operator()(NullableTerminalNode& node){ return node.Run(*stack_position, context); } IterationResult operator()(FixedSizeListNode& node){ return node.Run(stack_position, stack_position + 1, context); } IterationResult operator()(AllPresentTerminalNode& node){ return node.Run(*stack_position, context); } IterationResult operator()(AllNullsTerminalNode& node){ return node.Run(*stack_position, context); } IterationResult operator()(LargeListNode& node){ return node.Run(stack_position, stack_position + 1, context); } ElementRange* stack_position; PathWriteContext* context; } visitor = {stack_position, &context};
IterationResult result = std::visit(visitor, node);
if (context.rep_levels.length() > 0) { // This case only occurs when there was a repeated element that needs to be // processed. builder_result.rep_levels = context.rep_levels.data(); std::swap(builder_result.post_list_visited_elements, context.visited_elements); // If it is possible when processing lists that all lists where empty. In this // case no elements would have been added to post_list_visited_elements. By // added an empty element we avoid special casing in downstream consumers. if (builder_result.post_list_visited_elements.empty()) { builder_result.post_list_visited_elements.push_back({0, 0}); } } else { builder_result.post_list_visited_elements.push_back( {0, builder_result.leaf_array->length()}); builder_result.rep_levels = nullptr; }
// List nodes handle populating rep_level for Arrow Lists and def-level for empty lists. // Nullability (both list and children) is handled by other Nodes. By // construction all list nodes will be intermediate nodes (they will always be followed by // at least one other node). // // Type parameters: // |RangeSelector| - A strategy for determine the the range of the child node to // process. // this varies depending on the type of list (int32_t* offsets, int64_t* offsets of // fixed. template <typename RangeSelector> classListPathNode;
using ListNode = ListPathNode<VarRangeSelector<int32_t>>; using LargeListNode = ListPathNode<VarRangeSelector<int64_t>>; using FixedSizeListNode = ListPathNode<FixedSizedRangeSelector>;