Scheduling Blog Overview
今天本来打算看 Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age 这玩意,看了一点之后感觉自己理性上知道这篇文章是把 Task 切碎了,然后调度的时候根据数据亲和性来做处理,然后做了协同调度。但是看到这些词汇的时候,好像一点都想不起来咋做的,感觉我对调度系统理解是一片空白。知道它在讲啥也不能清晰的理解内容。
刚看了看陈海波的 os 书第六章,突然理解了很多名词,不过感觉记 notes 也不如原书这一章好,所以干脆做一个索引。来描述我对调度系统名词理解。
这篇文章是瞎几把写的,很多东西我也就先占坑,所以没啥必要看,主要是以后理清楚了可以在这里回过头来写写「原来是这样」
基本概念: OS
这里最好参考陈海波的 <现代操作系统:原理与实现> 来理解。
这里有一个任务(Task)的概念,Linux 里面线程/进程都是 task_struct 里面都是 Task。这里还会涉及别的东西,包括:
- 优先级(Priority)
- 时间片(Timeslice)
- Deadline
- …
关于调度目标,
性能相关指标有:吞吐量(单位时间内处理的任务数量)、周转时间(任务发起到结束的时间)、响应时间
非性能相关:公平性、资源利用率
任务可能有不同类型,比如批处理类型更希望有更大的吞吐量、更小的周转时间;交互式任务会希望有更小的响应时间;实时任务会希望有更好的实时性;移动设备可能希望开销小一点,它还大小核什么的。
同时,任务数量会很多,而且现代系统本身也向多核发展(详见:https://blog.mwish.me/2022/05/04/perfbook-notes-hardware/ 和 https://blog.mwish.me/2022/05/02/Arch-Blog-Overviews/ )。所以也会希望能用上所有的 CPU、调度开销小。
然后不同任务指标是不一样的(当时看这里不太理解,但是看 AP/TP/HSAP 等工业界需求,就会明白很多了),这里也有各种 trade-off:
- 调度开销 vs 调度效果
- 优先级 vs 公平性
- 性能 vs 能耗
关于上面的,还有一些 os 的博客指出它们的 trade-off ,比如 SOCC’14 的 Tales of the Tail: Hardware, OS, and Application-level Sources of Tail Latency
调度机制
长期、短期、中期调度,长期控制是否 spawn task,短期处理任务状态,中期根据 IO 等状况调整
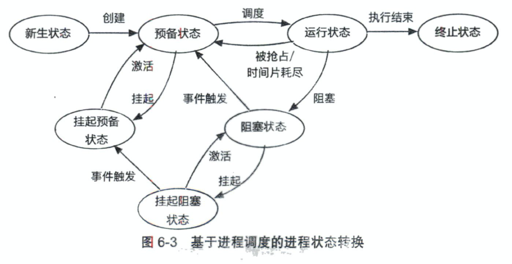
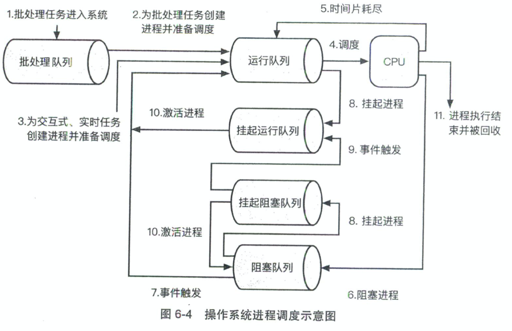
单核调度
FCFS/SJF/MLFQ/RR ,抢占/非抢占,是否有优先级(多级反馈队列),是否有份额(比如各个用户付了不同的钱,那么调度会根据 stride 或者彩票来调度)
上面其实不是谁比谁更优,而要考虑各种 功能需求 / trade-off
实时调度
TBD
多核调度

首先考虑协同调度/群组调度,上层知道任务的分组/协同情况,就更能利用多核的性能。例如 BSP 模型(常用于类似 MR/图计算)。
这里还要考虑两级调度,这样能保证调度的开销是小的(考虑 NUMA 等情况):
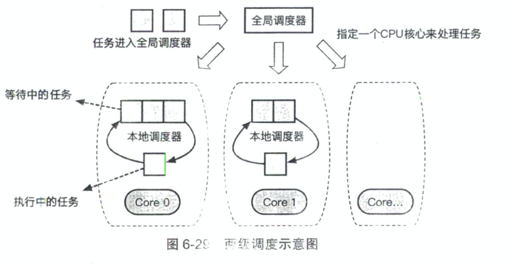
调度要考虑调度的开销,Linux 有一个 Per-Entity Load Tracing 机制来考虑。
然后调度到不同 core 开销也不同,所以有:
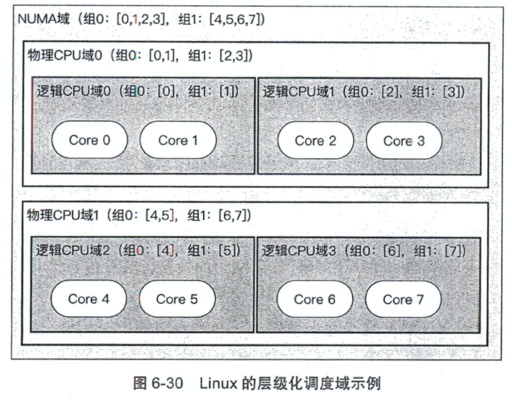
Linux 调度
CFS 等:
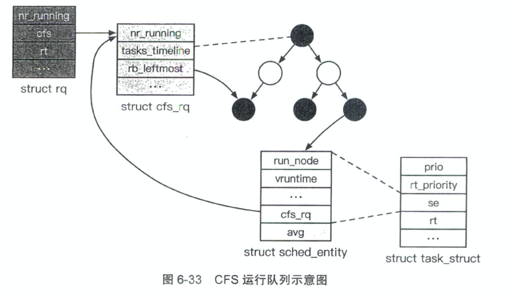
其他
- Tokio 调度,在 coroutine 上引入了一些 ts 等:https://tokio.rs/blog/2019-10-scheduler 和 https://tokio.rs/blog/2020-04-preemption
分布式调度系统
《大数据日知录》第四章。
静态划分是很好的方法,但是资源利用率不高,更期望把资源当作整体管理:
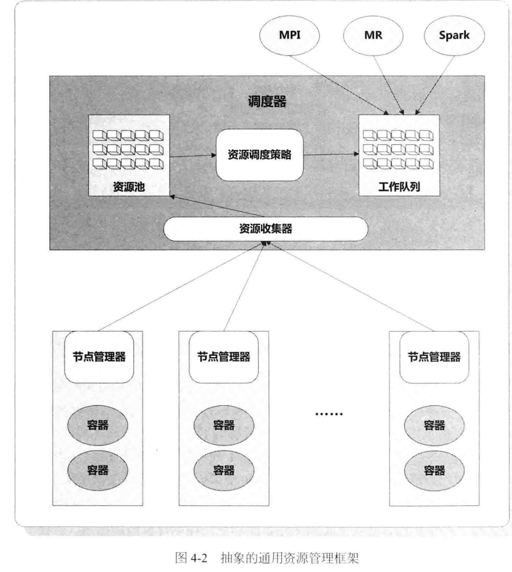
这里要考虑:workload 的资源的性质(CPU/Disk/GPU,有无状态);数据局部性(Node -> Rack -> Cluster);调度的是否抢占(能否暂停/干死正在跑的任务,还是只能从 spare 中分配资源)
也要考虑单机各种资源隔离的方法,是否饿死任务等。
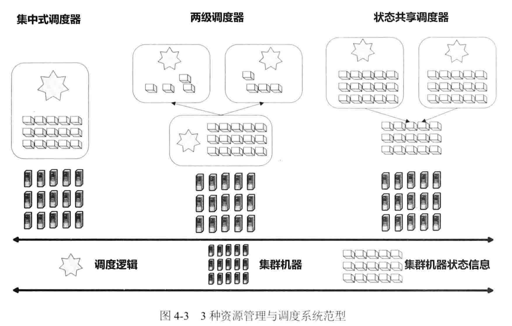
调度器也有不同的类型:
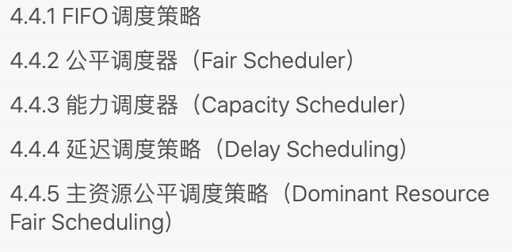
还有不同的调度算法:
DB 的调度系统
相对我们之前提的 OS 调度来说,DB 调度系统可能可以:
- 根据 Plan 和 Catalog 预估各种开销
- 更好的并行,协同调度,比如 Exchange 算子
- 单机还好,分布式的话,开销会引入网络开销,还算未知
材料有:
- Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
- Scaling Up Concurrent Main-Memory Column-Store Scans: Towards Adaptive NUMA-aware Data and Task Placement
- SQL 查询的分布式执行与调度 https://zhuanlan.zhihu.com/p/100949808
- PolarDB 并行计算框架 https://zhuanlan.zhihu.com/p/346320114
Spark, Presto, StarRocks 等